
Course
Introduction to Functions in Python
3 hr
466.5K
Python applications, especially those dealing with large datasets or complex computations, can consume excessive memory, leading to slowdowns, crashes, or out-of-memory errors. Memory profiling is a technique that allows you to analyze your Python code's memory usage, identify memory leaks and bottlenecks, and optimize memory consumption for improved performance and stability.
In this tutorial, we will explore memory profiling, the tools available, and practical examples of how to use these tools to profile your Python code.
Memory profiling is the technique of monitoring and evaluating a program's memory utilization while running. This method assists developers in finding memory leaks, optimizing memory utilization, and comprehending their programs' memory consumption patterns. Memory profiling is crucial to prevent applications from using more memory than necessary and causing sluggish performance or crashes.
Memory profiling offers several key advantages that are essential for maintaining efficient and robust applications:
Let’s explore several popular memory profiling tools, detailing their features, installation, and usage. Specifically, we will look at tools like memory_profiler for line-by-line memory analysis, tracemalloc for taking and comparing memory snapshots, and objgraph for visualizing object relationships.
memory_profiler is a powerful tool in Python that provides detailed insight into your code's memory usage. It works by providing a granular, line-by-line breakdown of memory usage, which is handy for pinpointing the exact lines of code responsible for high memory consumption. By understanding memory usage at this level of detail, developers can make informed decisions about where to focus their optimization efforts.
To install memory_profiler and any additional packages needed, follow these steps:
The following command installs the memory_profiler package:
pip install memory_profilerIf you want to visualize memory usage with plots, you can install matplotlib by running:
pip install matplotlibTo use memory_profiler, follow these steps:
We decorate the functions we want to profile.
Open your Python script in either a text editor or IDE.
Import the profile decorator from memory_profiler and apply it to the functions you want to profile.
Here's an example script:
from memory_profiler import profile
@profile
def allocate_memory():
# Allocate a list with a range of numbers
a = [i for i in range(10000)]
# Allocate another list with squares of numbers
b = [i ** 2 for i in range(10000)]
return a, b
if __name__ == "__main__":
allocate_memory()I import the profile decorator from the memory_profiler package here. This decorator will help us monitor the decorated function's memory usage.
from memory_profiler import profileI apply the @profile decorator to the allocate_memory() function. This means that when allocate_memory() is executed, memory_profiler will track its memory usage and provide a detailed report.
@profileInside the allocate_memory() function, I create two lists. The first list contains numbers from 0 to 9999; the second list contains the squares of numbers from 0 to 9999.
a = [i for i in range(10000)] # List of numbers from 0 to 9999
b = [i**2 for i in range(10000)] # List of squares of numbers from 0 to 9999The following block ensures that the allocate_memory() function is called only when the script is run directly, not when imported as a module. When you run this script, memory_profiler will output the memory usage of the allocate_memory() function, allowing you to see how much memory is used during the creation of the two lists, a and b.
if __name__ == "__main__":
allocate_memory()In your terminal or command prompt, navigate to the directory where your script is located. Run your script with the -m memory_profiler option.
-m memory_profiler your_script.py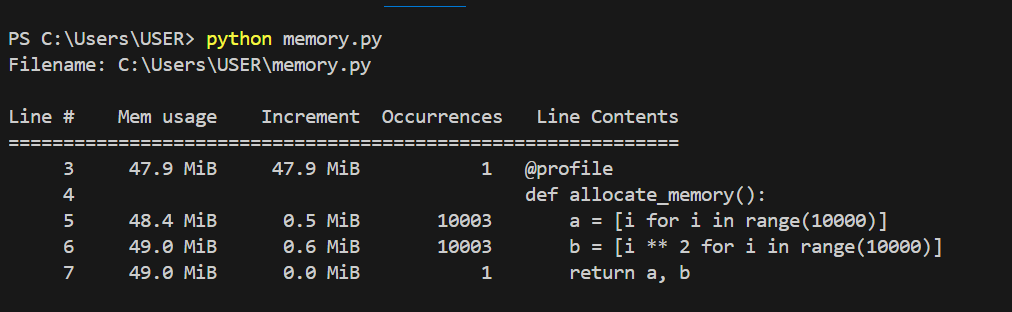
Memory usage for each line of code. Image by Author.
In the above graphic, we can see the memory usage of each line of code and the increments for each line of code. The graph below shows how each line uses memory in greater detail and how it increases with each iteration.
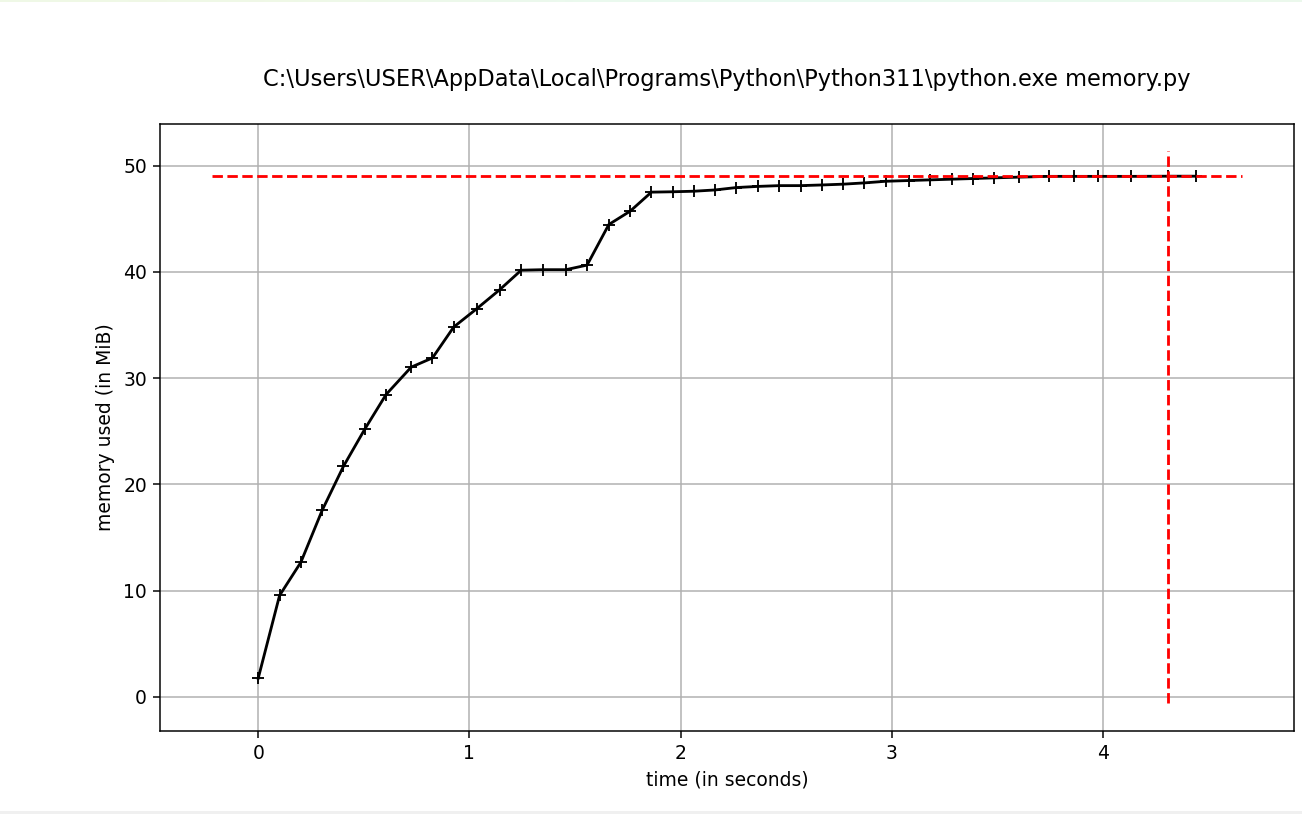
Memory usage over time. Image by Author.
tracemalloc is a powerful built-in module in Python that tracks memory allocations and deallocations. Understanding how your application uses memory is crucial for optimizing performance and identifying memory leaks. Tracemalloc provides an easy-to-use interface for capturing and analyzing memory usage snapshots, making it an invaluable tool for any Python developer.
Let’s examine how tracemalloc takes snapshots of memory usage, compares those snapshots to identify memory leaks, and then analyzes the top memory consumers
tracemalloc allows you to take snapshots of memory usage at specific points in your program. A snapshot captures the state of memory allocations, providing a detailed view of where memory is used.
Here's how you can take a snapshot with tracemalloc:
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Code block for which memory usage is to be tracked
def allocate_memory():
a = [i for i in range(10000)] # List of numbers from 0 to 9999
b = [i**2 for i in range(10000)] # List of squares of numbers from 0 to 9999
return a, b
# Keep the allocated lists in scope
allocated_lists = allocate_memory()
# Take a snapshot
snapshot = tracemalloc.take_snapshot()
# Stop tracing memory allocations
tracemalloc.stop()
# Analyze the snapshot to see memory usage
top_stats = snapshot.statistics('lineno')
# Write the memory usage data to a text file
with open('memory_usage.txt', 'w') as f:
f.write("[ Top 10 memory consumers ]\n")
for stat in top_stats[:10]:
f.write(f"{stat}\n")
# Detailed traceback for the top memory consumer
f.write("\n[ Detailed traceback for the top memory consumer ]\n")
for stat in top_stats[:1]:
f.write('\n'.join(stat.traceback.format()) + '\n')
print("Memory usage details saved to 'memory_usage.txt'")I tracked and examined memory use in my Python application using the tracemalloc module. By taking a snapshot of memory allocations and looking at the top memory consumers, I determined which sections of my code used the most memory. I then put this analysis in a text file for further reading and reference.
One of the most powerful features of tracemalloc is the ability to compare snapshots taken at different points in your program to identify memory leaks. By analyzing the differences between snapshots, you can pinpoint where additional memory is being allocated and not released.
Here's how to compare snapshots:
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Function to allocate memory
def allocate_memory():
a = [i for i in range(10000)] # List of numbers from 0 to 9999
b = [i**2 for i in range(10000)] # List of squares of numbers from 0 to 9999
return a, b
# Initial memory usage snapshot
snapshot1 = tracemalloc.take_snapshot()
# Perform memory allocations
allocated_lists = allocate_memory()
# Memory usage snapshot after allocations
snapshot2 = tracemalloc.take_snapshot()
# Further memory allocations (simulate more work to find potential leaks)
allocated_lists += allocate_memory()
# Memory usage snapshot after additional allocations
snapshot3 = tracemalloc.take_snapshot()
# Stop tracing memory allocations
tracemalloc.stop()
# Compare the snapshots
stats1_vs_2 = snapshot2.compare_to(snapshot1, 'lineno')
stats2_vs_3 = snapshot3.compare_to(snapshot2, 'lineno')
# Save the comparison results to a text file
with open('memory_leak_analysis.txt', 'w') as f:
f.write("[ Memory usage increase from snapshot 1 to snapshot 2 ]\n")
for stat in stats1_vs_2[:10]:
f.write(f"{stat}\n")
f.write("\n[ Memory usage increase from snapshot 2 to snapshot 3 ]\n")
for stat in stats2_vs_3[:10]:
f.write(f"{stat}\n")
# Detailed traceback for the top memory consumers
f.write("\n[ Detailed traceback for the top memory consumers ]\n")
for stat in stats2_vs_3[:1]:
f.write('\n'.join(stat.traceback.format()) + '\n')
print("Memory leak analysis saved to 'memory_leak_analysis.txt'")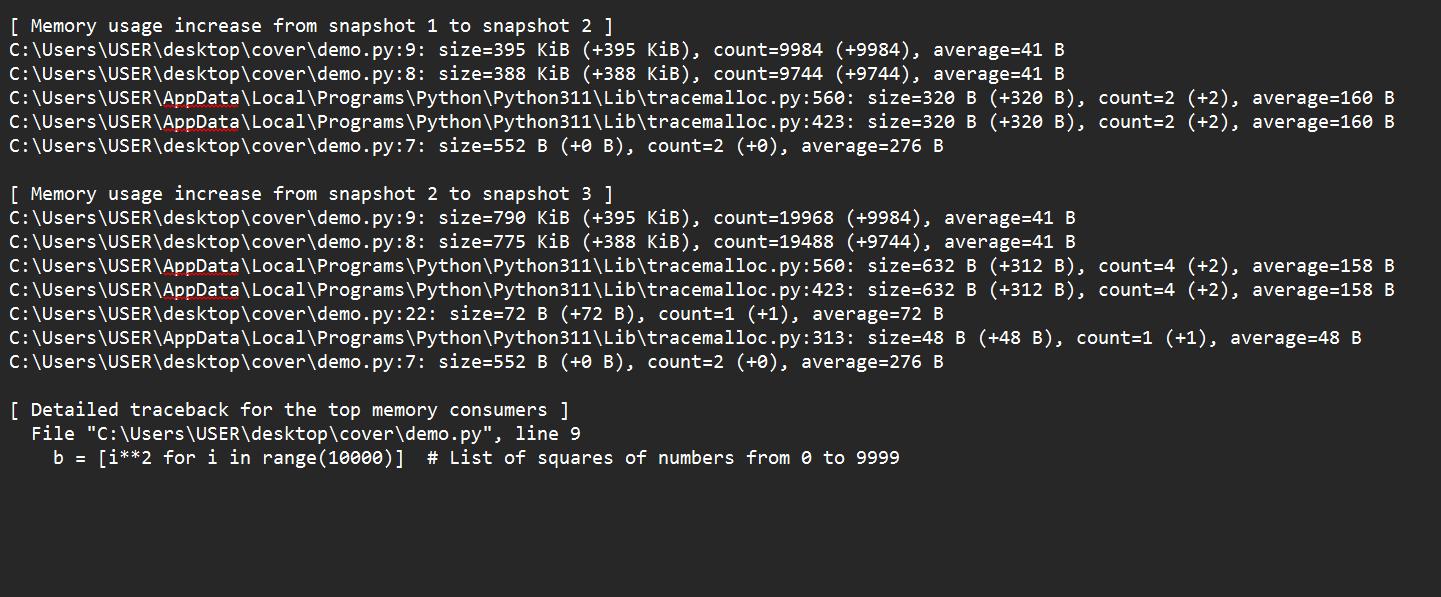
Moving from snapshot 1 to snapshot 2, we see that the establishment of lists a and b was the leading cause of a spike in memory use. Moving from snapshot 2 to snapshot 3, we also see that more allocations of lists a and b increased memory utilization.
By comparing these snapshots, we discover that the leading cause of increasing memory usage is the recurrent allocation of big lists. These allocations may indicate a memory leak if they are unneeded in real-world applications. Comprehensive traceback can identify the precise code lines causing these allocations.
tracemalloc also provides tools for analyzing your application's top memory consumers. This can help you focus on optimizing the parts of your code that use the most memory.
Here's how to analyze top memory consumers:
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Code block for which memory usage is to be tracked
def allocate_memory():
a = [i for i in range(10000)]
b = [i**2 for i in range(10000)]
allocate_memory()
# Take a snapshot
snapshot = tracemalloc.take_snapshot()
# Analyze top memory consumers
top_stats = snapshot.statistics('lineno')
print("[ Top 10 memory consumers ]")
for stat in top_stats[:10]:
print(stat)
# Stop tracing memory allocations
tracemalloc.stop()In this example, after taking a snapshot, I use snapshot. Statistics ('lineno') to get statistics about memory usage grouped by line number. This output helps you quickly identify which parts of your code consume the most memory, allowing you to target those areas for optimization.
Objgraph is a Python library designed to help developers visualize and analyze object references in their code. It provides tools to create visual graphs that show how objects in memory reference each other. This visualization is beneficial for understanding the structure and relationships within your program, identifying memory leaks, and optimizing memory usage.
First, let's install the objgraph library. You can install it using pip:
pip install objgraphobjgraphobjgraph offers several critical features for memory profiling and visualization:
objgraph, you can create visual representations of objects and their references. This helps you understand how objects are interconnected, making debugging and optimizing your code more accessible.Let's dive into some examples to see how objgraph can be used in practice.
Example 1: Generating an object reference graph
Suppose we have a simple class and create some instances:
class Node:
def __init__(self, value):
self.value = value
self.children = []
# Create some nodes
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
# Establish relationships
node1.children.append(node2)
node2.children.append(node3)
import Objgraph
# Generate a graph of object references
objgraph.show_refs([node1], filename='object_refs.png')In this example, we define a Node class and create instances of nodes with relationships. The objgraph.show_refs() function generates a visual graph of the object references starting from node1 and saves it as object_refs.png. This graph helps us understand how the nodes are interconnected.
Example 2: Detecting circular references
To detect circular references, we can use the objgraph.find_backref_chain() function:
# Create a circular reference
node 3.children.append(node1)
# Detect circular references
chain = objgraph.find_backref_chain(node1, objgraph.is_proper_module)
objgraph.show_chain(chain, filename='circular_refs.png')Here, we create a circular reference by adding node1 to the children of node3. The objgraph.find_backref_chain() function detects this circular reference, and objgraph.show_chain visualizes it, saving the output as circular_refs.png.
Example 3: Analyzing object types and sizes
To analyze the types and sizes of objects, we can use objgraph.show_most_common_types and objgraph.by_type:
# Show the most common object types
objgraph.show_most_common_types()
# Get the details of a specific object type
objs = objgraph.by_type('Node')
objgraph.show_refs(objs[:3], refcounts=True, filename='node_details.png')In this example, objgraph.show_most_common_types displays the most common object types currently in memory. The objgraph.by_type() function retrieves all instances of the Node class, and we visualize their references, including reference counts, by generating another graph saved as node_details.png.
Let’s now take a look at various techniques for using memory profiling tools effectively. We will focus on profiling specific functions, tracking overall memory usage, and visualizing object graphs.
Target specific functions with memory_profiler or tracemalloc.
memory_profilermemory_profiler offers a straightforward way to monitor memory consumption line-by-line within your functions, helping you pinpoint areas where memory usage can be reduced.
from memory_profiler import profile
@profile
def allocate_memory():
a = [i for i in range(10000)]
b = [i ** 2 for i in range(10000)]
return a, b
if __name__ == "__main__":
allocate_memory()tracemallocimport tracemalloc
tracemalloc.start()
def allocate_memory():
a = [i for i in range(10000)]
b = [i ** 2 for i in range(10000)]
return a, b
allocate_memory()
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
for stat in top_stats[:10]:
print(stat)To monitor the total memory usage of our program over time, we can use the built-in tracemalloc module. Here’s how we can track overall memory usage and interpret the results to identify trends.
Steps to use tracemalloc
We begin by initializing memory tracing at the start of our script.
import tracemalloc
tracemalloc.start()We then execute our code by running the sections of our code that we want to monitor.
def run_heavy_computation():
a = [i for i in range(10000)]
b = [i**2 for i in range(10000)]
return a, b
run_heavy_computation()We take snapshots of memory usage. This lets us capture the state of memory allocations at different points.
snapshot1 = tracemalloc.take_snapshot()
run_heavy_computation()
snapshot2 = tracemalloc.take_snapshot()Finally, we compare snapshots to understand memory usage patterns and detect leaks.
stats = snapshot2.compare_to(snapshot1, 'lineno')
for stat in stats[:10]:
print(stat)Example
import tracemalloc
# Start tracing memory allocations
tracemalloc.start()
# Function to run heavy computation
def run_heavy_computation():
a = [i for i in range(10000)]
b = [i**2 for i in range(10000)]
return a, b
# Initial memory usage snapshot
snapshot1 = tracemalloc.take_snapshot()
# Perform memory allocations
run_heavy_computation()
# Memory usage snapshot after allocations
snapshot2 = tracemalloc.take_snapshot()
# Compare the snapshots
stats = snapshot2.compare_to(snapshot1, 'lineno')
# Print the top memory-consuming lines of code
print("[ Top 10 memory consumers ]")
for stat in stats[:10]:
print(stat)
# Stop tracing memory allocations
tracemalloc.stop()Here are some tips to help you make sense of your profiling data:
Using the objgraph library, we can create visualizations of object relationships. This helps us analyze memory usage, detect leaks, and understand object lifetimes.
Here is the step-by-step process to visualize object graphs. First, we will generate an object reference graph; then, we will detect circular references; finally, we will analyze the graphs.
import objgraph
class Node:
def __init__(self, value):
self.value = value
self.children = []
# Create some nodes and establish relationships
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node1.children.append(node2)
node2.children.append(node3)
# Generate a graph of object references
objgraph.show_refs([node1], filename='object_refs.png')# Create a circular reference
node3.children.append(node1)
# Detect circular references
chain = objgraph.find_backref_chain(node1, objgraph.is_proper_module)
objgraph.show_chain(chain, filename='circular_refs.png')# Show the most common object types
objgraph.show_most_common_types()
# Get details of a specific object type
nodes = objgraph.by_type('Node')
objgraph.show_refs(nodes[:3], refcounts=True, filename='node_details.png')Example
import objgraph
class Node:
def __init__(self, value):
self.value = value
self.children = []
# Create some nodes and establish relationships
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node1.children.append(node2)
node2.children.append(node3)
# Generate a graph of object references
objgraph.show_refs([node1], filename='object_refs.png')
# Create a circular reference
node3.children.append(node1)
# Detect circular references
chain = objgraph.find_backref_chain(node1, objgraph.is_proper_module)
objgraph.show_chain(chain, filename='circular_refs.png')
# Show the most common object types
objgraph.show_most_common_types()
# Get details of a specific object type
nodes = objgraph.by_type('Node')
objgraph.show_refs(nodes[:3], refcounts=True, filename='node_details.png')As a final step, we analyze the graphs. We consider the following steps in order:
Here are some key tips and best practices to help you get the most out of your profiling efforts:
In this tutorial, we explored essential tools and techniques for understanding and optimizing memory usage in your Python applications. These techniques included memory_profiler which offers a straightforward way to monitor memory consumption line-by-line within your function, and objgraph, which provides powerful visualization capabilities, allowing you to analyze object relationships, detect circular references, and understand the structure of your memory usage.
Integrating memory profiling tools into your development workflow allows you to gain valuable insights into how your code manages memory, helps you to make informed optimization decisions, and helps you to enhance your applications' overall performance and reliability. Whether you are working on small scripts or large-scale systems, memory profiling is an essential practice for any Python developer aiming to write efficient and robust code.
To deepen your understanding and skills in memory profiling and writing efficient code, consider taking the Writing Efficient Code in Python Course. Additionally, our Python Programming course offers a comprehensive overview of best practices and advanced techniques to help you become a proficient developer.
Learn Python with DataCamp
Course
Course
Course
Tutorial
Arunn Thevapalan
Tutorial
Satyam Tripathi
Tutorial
Aditya Sharma
Tutorial
Kurtis Pykes
Tutorial
Karlijn Willems
Tutorial
Derrick Mwiti

