Curso
Manipulando dados de séries temporais em Python
4 h
71.6K
O tempo é uma dimensão fundamental na análise de dados. Com o passar do tempo, os valores podem flutuar, apresentar tendências ou se manter estáveis. Quando analisamos como os dados evoluem ao longo do tempo, estamos trabalhando com séries temporais.
Uma tarefa comum na análise de séries temporais é ajustar a frequência de datas e horários em nossos dados, uma técnica conhecida como reamostragem. Neste tutorial, usaremos o pandas, uma biblioteca com ferramentas robustas para a manipulação intuitiva e eficiente de séries temporais.
Começaremos com os conceitos básicos e avançaremos gradualmente para técnicas de reamostragem mais avançadas. Forneceremos exemplos práticos e compartilharemos as práticas recomendadas para garantir que nossa análise de séries temporais seja eficaz e eficiente.
Se você quiser saber mais sobre séries temporais, confira este curso sobre manipulação de dados de séries em Python.
Da mesma forma que podemos agrupar os dados por categoria, a reamostragem nos permite agrupar os dados em diferentes intervalos de tempo. Isso é valioso tanto para a limpeza de dados quanto para a análise aprofundada de séries temporais. Por exemplo, talvez seja necessário alinhar duas séries temporais a uma frequência comum antes de compará-las.
Há dois tipos principais de reamostragem:
Você pode realizar a reamostragem com o pandas usando dois métodos principais: .asfreq() e .resample().
Para começar a usar esses métodos, primeiro precisamos importar a biblioteca pandas usando o alias convencional pd. Também importaremos matplotlib para que você possa visualizar os resultados.
import pandas as pd
import matplotlib.pyplot as pltVamos começar com o método .asfreq(). Esse método converte uma série temporal em uma frequência especificada, retornando os dados originais alinhados com um novo índice nessa frequência.
Trabalharemos com um conjunto de dados que contém leituras diárias de temperatura em Madri de 1997 a 2015. Vamos começar com algumas etapas de pré-processamento antes de mergulhar na reamostragem.
url = 'https://raw.githubusercontent.com/jcanalesluna/courses_materials/master/datasets/Madrid%20Daily%20Weather%201997-2015.csv'
df = pd.read_csv(url, usecols=['CET', 'Max TemperatureC', 'Mean TemperatureC', 'Min TemperatureC'])
# Change column names
df.columns = ['time', 'max_temp', 'mean_temp', 'min_temp']
# Convert string column to datetime
df['time'] = pd.to_datetime(df['time'])
# Set time column as index
df = df.set_index('time')
df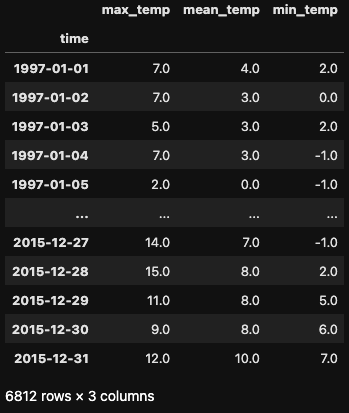
Para ilustrar o aumento da amostragem, imagine que queremos converter nossas leituras diárias de temperatura em leituras por hora. Você pode fazer isso usando o método .asfreq() com o parâmetro freq='H'.
df_hour = df.asfreq('H')
df_hour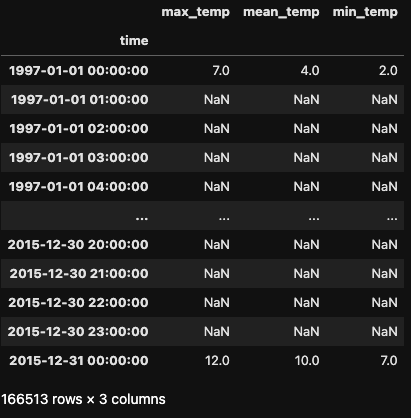
O conjunto de dados resultante é notavelmente maior, pois novas linhas foram criadas com dados horários em vez de diários. Por padrão, .asfreq() usa a primeira entrada no índice original e preenche as horas restantes com valores nulos.
O conjunto de dados resultante é consideravelmente maior, pois novas linhas foram criadas com dados por hora em vez de dados diários. Por padrão, .asfreq() usa a primeira entrada no índice original e cria valores nulos para as horas restantes.
O pandas oferece três estratégias para preencher esses valores nulos:
ffill): Propaga a última observação válida para frente.bfill): Usa a próxima observação válida para preencher a lacuna.As duas primeiras estratégias são implementadas usando o parâmetro method no método .asfreq(), enquanto o valor de preenchimento é especificado com o parâmetro fill_value.
df_mean_temp = df[['mean_temp']]
df_mean_temp_hour= df_mean_temp.asfreq('H')
df_mean_temp_hour['ffill'] = df_mean_temp.asfreq('H', method='ffill')
df_mean_temp_hour['bfill'] = df_mean_temp.asfreq('H', method='bfill')
df_mean_temp_hour['value'] = df_mean_temp.asfreq('H', fill_value=0)
df_mean_temp_hour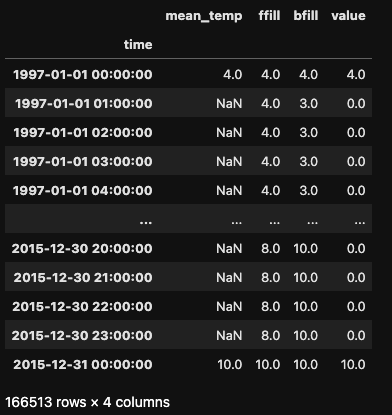
Agora vamos explorar a redução da amostragem. Suponha que você queira alterar a frequência diária para mensal. Você pode fazer isso usando .asfreq() com o parâmetro freq='M'.
Nesse caso, estamos reduzindo a frequência dos nossos dados, passando de diária para mensal. O DataFrame resultante tem apenas 228 linhas, em comparação com as 6.812 do DataFrame original.
df_month = df.asfreq(freq='M')
df_month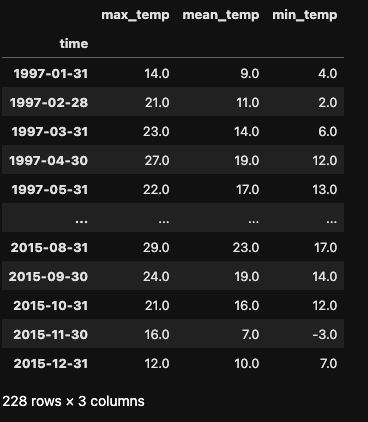
Observe que .asfreq() simplesmente seleciona o último dia de cada mês e usa seu valor para representar o mês inteiro. Nenhuma agregação é realizada (por exemplo, o cálculo da temperatura média mensal). Para realizar essas agregações, usaremos o método .resample() na próxima seção.
Embora .asfreq() seja útil para exibir dados de séries temporais em uma frequência diferente, o método .resample() é a ferramenta preferida para realizar agregações e reamostragem.
O método .resample() funciona de forma muito semelhante ao .groupby(): ele agrupa os dados em um intervalo de tempo especificado e, em seguida, aplica uma ou mais funções a cada grupo. O resultado dessas funções é atribuído a uma nova data dentro desse intervalo.
Usamos .resample() tanto para aumento da amostragem (preenchimento ou interpolação de dados ausentes) quanto para redução da amostragem (agregação de dados).
Vamos revisitar nossa conversão por hora para ver como o aumento da amostragem funciona com .resample(). A aplicação de .resample() retorna um objeto Resampler, ao qual podemos aplicar outro método para obter um DataFrame.
print(df.resample('H'))DatetimeIndexResampler [freq=<Hour>, axis=0, closed=left, label=left, convention=start, origin=start_day]Com relação ao aumento da amostragem, o método .resample() pode realizar as mesmas tarefas que o .asfreq().
df.mean_temp.resample('H').asfreq()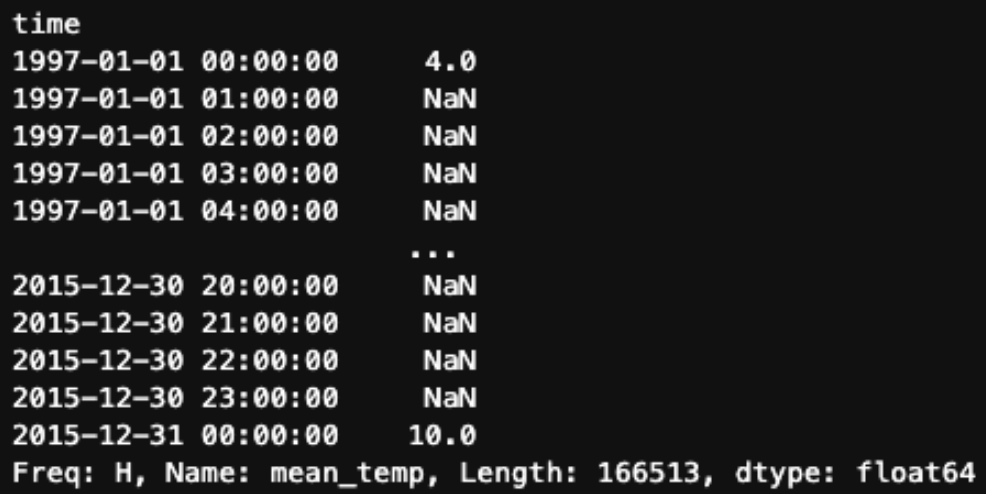
Também podemos aplicar as mesmas estratégias de preenchimento e interpolação que usamos com .asfreq(). Por exemplo, para usar o preenchimento para frente:
df.mean_temp.resample('H').ffill()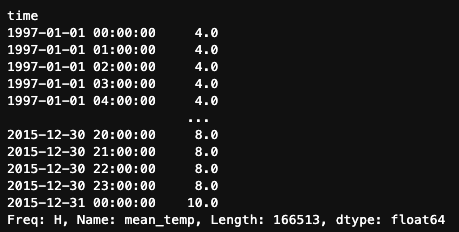
Mas .resample() também oferece métodos adicionais que não estão disponíveis com .asfreq(). Por exemplo, podemos usar o método .interpolate(), que estima os valores em novos pontos de tempo encontrando pontos ao longo de uma linha reta entre os pontos de dados existentes.
df.mean_temp.resample('H').interpolate()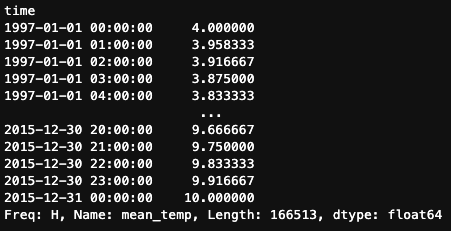
O método .resample() realmente se destaca quando se trata de reduzir a amostragem, pois nos permite aplicar vários métodos de agregação para resumir nossos dados. Por exemplo, vamos calcular a média mensal e a mediana trimestral das temperaturas em Madri usando .resample().
df.mean_temp.resample('M').mean()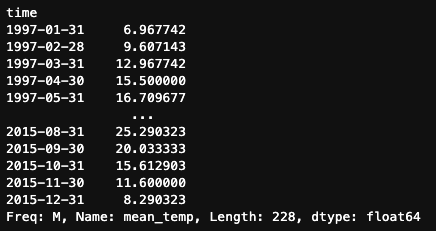
df.mean_temp.resample('Q').median()
Além das operações básicas que abordamos, os métodos de reamostragem do pandas também podem lidar com cenários mais avançados. Vamos explorar alguns dos mais comuns.
A reamostragem nos permite criar uma nova série temporal com uma frequência adaptada às nossas necessidades específicas. Algumas frequências comumente usadas incluem:
W: Frequência semanal (terminando no domingo)M: Frequência de fim de mêsQ: Frequência de fim de trimestreH: Frequência horáriaNo entanto, o pandas oferece muitas outras opções, dependendo de nossas necessidades. Podemos definir frequências com base em datas de início ou término, usar dias úteis em vez de dias do calendário ou até mesmo criar frequências totalmente personalizadas.
df.mean_temp.resample('M').mean() # calendar month end
df.mean_temp.resample('MS').mean() # calendar month start
df.mean_temp.resample('BM').mean() # business calendar end
df.mean_temp.resample('BMS').mean() # business calendar startAssim como o método groupby(), .resample() nos permite aplicar várias agregações simultaneamente. Podemos usar o método .agg() e passar uma lista de funções de agregação, como média, mediana e desvio padrão.
df.mean_temp.resample('M').agg(['mean','median','std'])
O pandas é altamente otimizado para lidar com grandes conjuntos de dados, mas à medida que o tamanho de nossos DataFrames aumenta, o processamento e a manipulação podem se tornar computacionalmente exigentes. Isso é especialmente verdadeiro durante o aumento da amostragem. Imagine reamostrar uma série temporal de hora em hora para segundos; o DataFrame resultante poderia ser enorme!
Se tivermos problemas de desempenho com grandes conjuntos de dados, podemos usar essas estratégias:
Felizmente, as versões 2.0 e posteriores do pandas incorporam técnicas avançadas para um processamento mais eficiente. Você pode saber mais neste artigo sobre o Pandas 2.0.
A reamostragem é uma técnica fundamental na análise de séries temporais, que nos permite ajustar a frequência de nossos dados agregando (reduzindo a amostragem) ou interpolando (aumentando a amostragem) valores. Exploramos como o pandas fornece ferramentas poderosas, como .asfreq() e .resample(), para tornar esse processo intuitivo e eficiente.
Para aprofundar seu conhecimento sobre reamostragem e manipulação de séries temporais em Python, confira estes recursos:
Aprenda mais sobre séries temporais com estes cursos!
Curso
Curso
Curso