Curso
Manipulación de series temporales en Python
4 h
71.6K
El tiempo es una dimensión fundamental en el análisis de datos. Con el tiempo, los valores pueden fluctuar, evolucionar o mantenerse estables. Cuando analizamos cómo evolucionan los datos a lo largo del tiempo, estamos trabajando con series temporales.
Una tarea habitual en el análisis de series temporales es ajustar la frecuencia de fechas y horas dentro de nuestros datos, una técnica conocida como resampling o remuestreo. En este tutorial, aprovecharemos Pandas, una biblioteca con herramientas robustas para la manipulación intuitiva y eficiente de series temporales.
Empezaremos por lo básico y progresaremos gradualmente hacia técnicas de remuestreo más avanzadas. Proporcionaremos ejemplos prácticos y compartiremos las mejores prácticas para garantizar que nuestro análisis de series temporales sea eficaz y eficiente.
Si quieres aprender más sobre series temporales, consulta este curso sobre manipulación de datos de series en Python.
Al igual que podemos agrupar los datos por categorías, el remuestreo nos permite agrupar los datos en distintos intervalos de tiempo. Esto es valioso tanto para la limpieza de datos como para el análisis en profundidad de series temporales. Por ejemplo, podríamos necesitar alinear dos series temporales a una frecuencia común antes de compararlas.
Existen dos tipos principales de remuestreo:
Podemos realizar un remuestreo con pandas utilizando dos métodos principales: .asfreq() y .resample().
Para empezar a utilizar estos métodos, primero tenemos que importar la biblioteca pandas utilizando el alias convencional pd. También importaremos matplotlib para visualizar los resultados.
import pandas as pd
import matplotlib.pyplot as pltEmpecemos por el método .asfreq(). Este método convierte una serie temporal a una frecuencia especificada, devolviendo los datos originales alineados con un nuevo índice a esa frecuencia.
Trabajaremos con un conjunto de datos que contiene lecturas diarias de temperatura en Madrid desde 1997 hasta 2015. Empecemos con algunos pasos de preprocesamiento antes de sumergirnos en el remuestreo.
url = 'https://raw.githubusercontent.com/jcanalesluna/courses_materials/master/datasets/Madrid%20Daily%20Weather%201997-2015.csv'
df = pd.read_csv(url, usecols=['CET', 'Max TemperatureC', 'Mean TemperatureC', 'Min TemperatureC'])
# Change column names
df.columns = ['time', 'max_temp', 'mean_temp', 'min_temp']
# Convert string column to datetime
df['time'] = pd.to_datetime(df['time'])
# Set time column as index
df = df.set_index('time')
df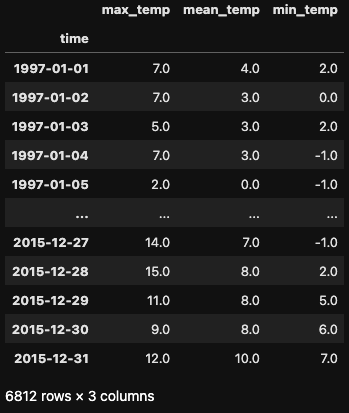
Para ilustrar el muestreo ascendente, imaginemos que queremos convertir nuestras lecturas diarias de temperatura en lecturas horarias. Podemos conseguirlo utilizando el método .asfreq() con el parámetro freq='H'.
df_hour = df.asfreq('H')
df_hour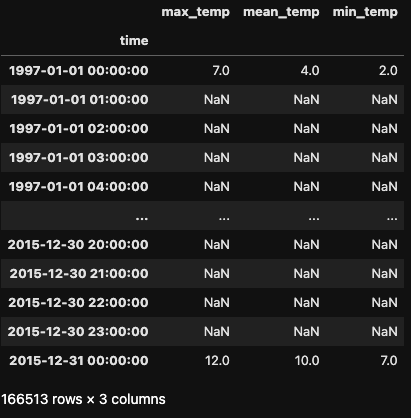
El conjunto de datos resultante es notablemente mayor, ya que se han creado nuevas filas con datos horarios en lugar de diarios. Por defecto, .asfreq() toma la primera entrada del índice original y rellena las horas restantes con valores nulos.
El conjunto de datos resultante es considerablemente mayor, ya que se han creado nuevas filas con datos horarios en lugar de diarios. Por defecto, .asfreq() toma la primera entrada del índice original y crea valores nulos para las horas restantes.
Pandas ofrece tres estrategias para rellenar estos valores nulos:
ffill): propaga hacia adelante la última observación válida.bfill): utiliza la siguiente observación válida para rellenar el hueco.Las dos primeras estrategias se aplican mediante el parámetro method del método .asfreq(), mientras que el valor de relleno se especifica con el parámetro fill_value.
df_mean_temp = df[['mean_temp']]
df_mean_temp_hour= df_mean_temp.asfreq('H')
df_mean_temp_hour['ffill'] = df_mean_temp.asfreq('H', method='ffill')
df_mean_temp_hour['bfill'] = df_mean_temp.asfreq('H', method='bfill')
df_mean_temp_hour['value'] = df_mean_temp.asfreq('H', fill_value=0)
df_mean_temp_hour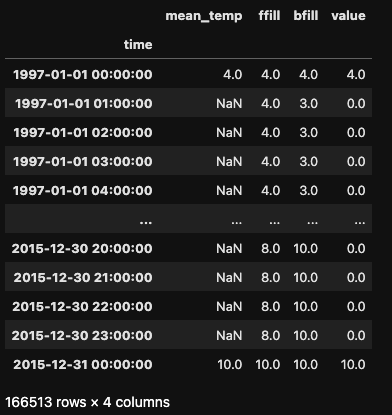
Ahora vamos a explorar el muestreo descendente. Supongamos que queremos cambiar la frecuencia diaria por una mensual. Podemos conseguirlo utilizando .asfreq() con el parámetro freq='M'.
En este caso, estamos reduciendo la frecuencia de nuestros datos, pasando de diarios a mensuales. El DataFrame resultante sólo tiene 228 filas, frente a las 6812 del DataFrame original.
df_month = df.asfreq(freq='M')
df_month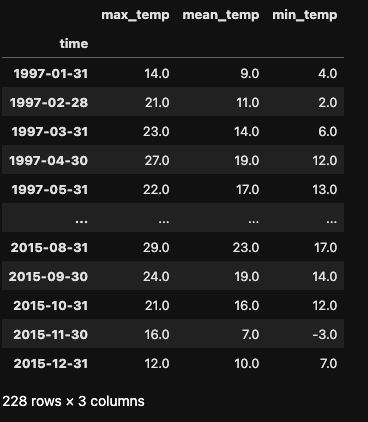
Observa que .asfreq() simplemente selecciona el último día de cada mes y utiliza su valor para representar el mes completo. No se realiza ninguna agregación (por ejemplo, calcular la temperatura media mensual). Para realizar tales agregaciones, recurriremos al método .resample() en la siguiente sección.
Mientras que .asfreq() es útil para visualizar datos de series temporales a una frecuencia diferente, el método .resample() es la herramienta de elección cuando se realizan agregaciones junto con el remuestreo.
El método .resample() funciona de forma muy similar a .groupby(): agrupa los datos dentro de un intervalo de tiempo especificado y, a continuación, aplica una o varias funciones a cada grupo. El resultado de estas funciones se asigna a una nueva fecha dentro de ese intervalo.
Utilizamos .resample() tanto para el muestreo ascendente (completar o interpolar los datos que faltan) como para el muestreo descendente (agrupando datos).
Volvamos a nuestra conversión horaria para ver cómo funciona el muestreo ascendente con .resample(). Aplicando .resample() se obtiene un objeto Resampler, al que podemos aplicar otro método para obtener un DataFrame.
print(df.resample('H'))DatetimeIndexResampler [freq=<Hour>, axis=0, closed=left, label=left, convention=start, origin=start_day]En cuanto al remuestreo, el método .resample() puede realizar las mismas tareas que .asfreq().
df.mean_temp.resample('H').asfreq()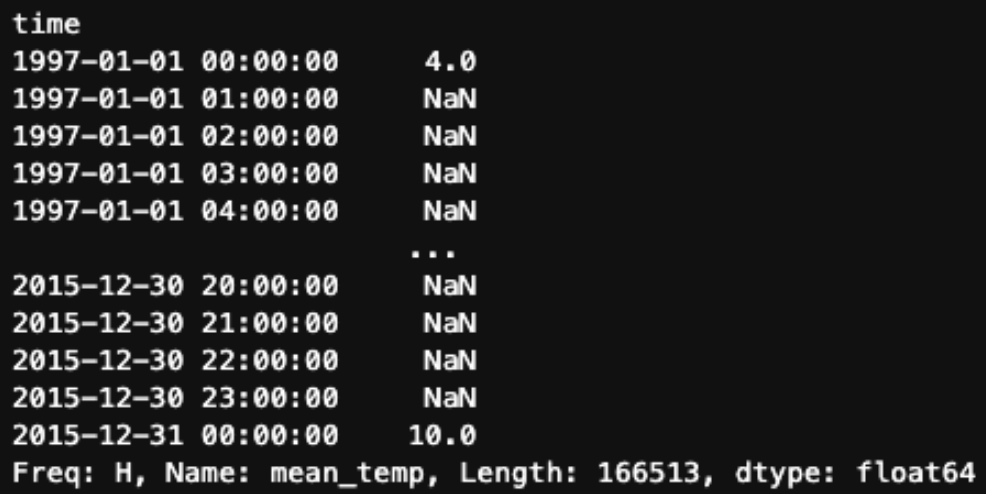
También podemos aplicar las mismas estrategias de relleno e interpolación que utilizamos con .asfreq(). Por ejemplo, para utilizar el relleno hacia delante:
df.mean_temp.resample('H').ffill()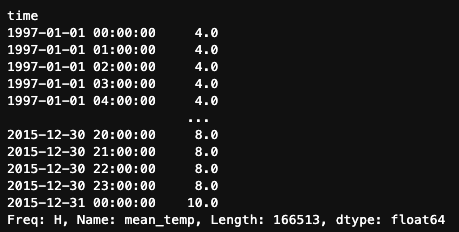
Pero .resample() también ofrece métodos adicionales no disponibles en .asfreq(). Por ejemplo, podríamos utilizar el método .interpolate(), que estima valores en nuevos puntos temporales encontrando puntos a lo largo de una línea recta entre puntos de datos existentes.
df.mean_temp.resample('H').interpolate()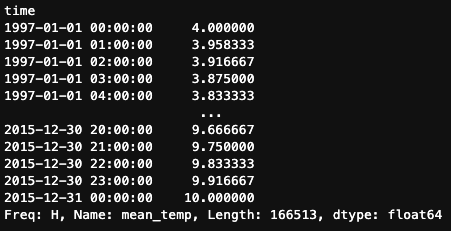
El método .resample() brilla realmente cuando se trata de reducir el muestreo, ya que nos permite aplicar varios métodos de agregación para resumir nuestros datos. Por ejemplo, calculemos la temperatura media mensual y la temperatura media trimestral de Madrid utilizando .resample().
df.mean_temp.resample('M').mean()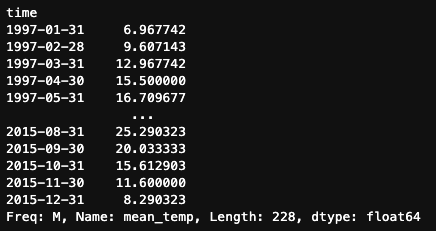
df.mean_temp.resample('Q').median()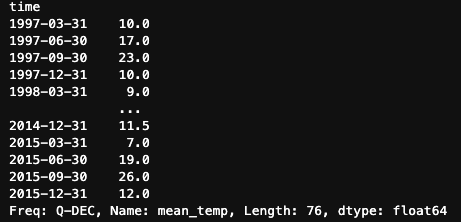
Más allá de las operaciones básicas que hemos cubierto, los métodos de remuestreo de Pandas también pueden manejar escenarios más avanzados. Veamos algunas de las más comunes.
El remuestreo nos permite crear una nueva serie temporal con una frecuencia adaptada a nuestras necesidades específicas. Algunas de las frecuencias más utilizadas son:
W: frecuencia semanal (finaliza el domingo)M: frecuencia de fin de mesQ: frecuencia trimestralH: frecuencia horariaSin embargo, Pandas ofrece muchas más opciones en función de nuestras necesidades. Podemos definir frecuencias basadas en fechas de inicio o fin, utilizar días laborables en lugar de días naturales o incluso crear frecuencias totalmente personalizadas.
df.mean_temp.resample('M').mean() # calendar month end
df.mean_temp.resample('MS').mean() # calendar month start
df.mean_temp.resample('BM').mean() # business calendar end
df.mean_temp.resample('BMS').mean() # business calendar startAl igual que el método groupby(), .resample() nos permite aplicar múltiples agregaciones simultáneamente. Podemos utilizar el método .agg() y pasar una lista de funciones de agregación, como media, mediana y desviación estándar.
df.mean_temp.resample('M').agg(['mean','median','std'])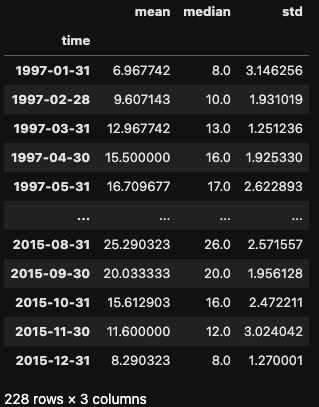
Pandas está altamente optimizado para manejar grandes conjuntos de datos, pero a medida que el tamaño de nuestros DataFrames crece, el procesamiento y la manipulación pueden llegar a ser exigentes en cuanto a capacidad computacional. Esto es especialmente cierto durante el muestreo ascendente. Imagina el remuestreo de una serie temporal horaria en segundos: ¡el DataFrame resultante podría ser enorme!
Si tenemos problemas de rendimiento con grandes conjuntos de datos, podemos utilizar estas estrategias:
Afortunadamente, las versiones 2.0 y posteriores de pandas incorporan técnicas avanzadas para un procesamiento más eficiente. Puedes obtener más información en este artículo sobre Pandas 2.0.
El remuestreo es una técnica fundamental en el análisis de series temporales, que nos permite ajustar la frecuencia de nuestros datos agregando (downsampling) o interpolando (upsampling) valores. Hemos explorado cómo pandas proporciona potentes herramientas como .asfreq() y .resample() para hacer este proceso intuitivo y eficiente.
Para profundizar en el remuestreo y la manipulación de series temporales en Python, consulta estos recursos:
Consigue más información sobre series temporales con estos cursos
Curso
Curso
Curso
Tutorial
Karlijn Willems
Tutorial
DataCamp Team
Tutorial
DataCamp Team
Tutorial
Satyam Tripathi
Tutorial
Elena Kosourova

