
Programa
Fundamentos de dados Python
28 h
Uma lista ligada é uma estrutura de dados que tem um papel essencial na organização e no gerenciamento de dados. Ela contém uma sequência de nós armazenados em locais aleatórios na memória, o que permite uma gestão eficiente de memória. Cada nó em uma lista ligada tem dois componentes principais: a parte dos dados e uma referência para o próximo nó na sequência.
Se isso parecer complexo à primeira vista, calma!
Vamos voltar aos fundamentos para explicar o que são listas ligadas, por que usamos esse recurso e quais vantagens ele oferece.
Listas ligadas surgiram para contornar várias desvantagens de armazenar dados em listas e arrays convencionais, como vemos abaixo:
Em listas, ao inserir ou remover um elemento em qualquer posição que não seja o final, é preciso deslocar todos os itens seguintes para outra posição. Esse processo tem complexidade de tempo O(n) e pode prejudicar bastante a performance, especialmente à medida que a lista cresce. Se você ainda não está familiarizado com o funcionamento ou a implementação de listas, confira nosso tutorial sobre listas em Python.
Listas ligadas, por outro lado, funcionam de forma diferente. Elas armazenam elementos em locais de memória não contíguos e os conectam por meio de ponteiros para os nós seguintes. Essa estrutura permite adicionar ou remover elementos em qualquer posição apenas modificando os links para incluir um novo elemento ou pular o que foi removido.
Depois que você tem uma referência direta ao nó no ponto de inserção ou remoção, a operação em si é O(1). Ainda assim, encontrar essa posição exige uma travessia O(n), então o benefício O(1) só se aplica quando você já tem um ponteiro para o nó relevante (como quando trabalha na cabeça da lista).
Listas em Python são arrays dinâmicos, o que significa que oferecem flexibilidade para mudar de tamanho.
Porém, isso envolve uma série de operações complexas, incluindo realocar o array para um bloco de memória maior. Essa realocação é ineficiente, pois os elementos precisam ser copiados para um novo bloco, possivelmente reservando mais espaço do que o necessário naquele momento.
Já as listas ligadas podem crescer e encolher dinamicamente sem precisar de realocação ou redimensionamento. Isso as torna uma opção melhor quando é preciso muita flexibilidade.
Listas alocam memória para todos os elementos em um bloco contíguo. Se uma lista precisar crescer além do tamanho inicial, ela deve alocar um novo bloco contíguo maior e copiar todos os elementos para esse novo bloco. Esse processo é demorado e ineficiente, especialmente em listas grandes. Por outro lado, se o tamanho inicial for superestimado, a memória não utilizada é desperdiçada.
Em contraste, listas ligadas alocam memória separadamente para cada elemento. Essa estrutura leva a uma melhor utilização da memória, já que a memória para novos elementos pode ser alocada conforme eles são adicionados.
Embora listas ligadas ofereçam vantagens sobre listas e arrays comuns, como tamanho dinâmico e eficiência de memória, elas também têm limitações. Como é preciso armazenar ponteiros para cada elemento apontar para o próximo nó, o uso de memória por elemento é maior em listas ligadas. Além disso, essa estrutura não permite acesso direto aos dados. Para acessar um elemento, é necessário percorrer a lista sequencialmente desde o início, resultando em complexidade O(n) para busca.
A escolha entre usar uma lista ligada ou um array depende das necessidades do aplicativo. Listas ligadas são mais úteis quando:
Existem três tipos de listas ligadas, cada uma com vantagens específicas para diferentes cenários. São elas:
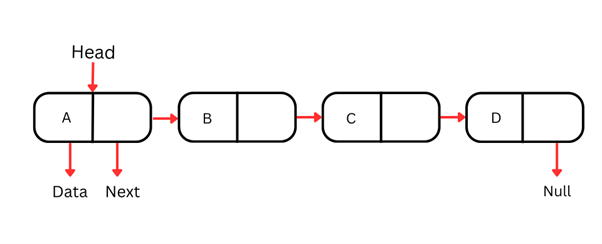
Singly-linked list
Uma lista simplesmente ligada é o tipo mais simples, em que cada nó contém dados e uma referência para o próximo nó da sequência. Ela só pode ser percorrida em um único sentido — da cabeça (primeiro nó) para a cauda (último nó).
Cada nó em uma lista simplesmente ligada geralmente tem duas partes:
Como essas estruturas só podem ser percorridas em uma direção, acessar um elemento específico por valor ou índice exige começar pela cabeça e avançar nó a nó até encontrar o desejado. Essa operação tem complexidade O(n), sendo menos eficiente para listas grandes.
Inserir e remover um nó no começo de uma lista simplesmente ligada é muito eficiente, com complexidade O(1). Já inserções e remoções no meio ou no fim exigem percorrer a lista até o ponto desejado, levando a complexidade O(n).
O desenho das listas simplesmente ligadas as torna úteis quando as operações acontecem no início da lista.
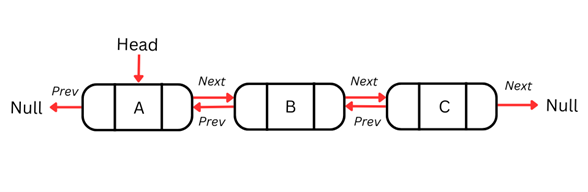
Doubly-linked list
Uma desvantagem das listas simplesmente ligadas é que só podemos percorrê-las em um sentido e não dá para voltar ao nó anterior quando necessário. Essa restrição limita operações que exigem navegação bidirecional.
Listas duplamente ligadas resolvem esse problema incorporando um ponteiro adicional em cada nó, permitindo percorrer a lista nos dois sentidos. Cada nó em uma lista duplamente ligada contém três elementos: os dados, um ponteiro para o próximo nó e um ponteiro para o nó anterior.
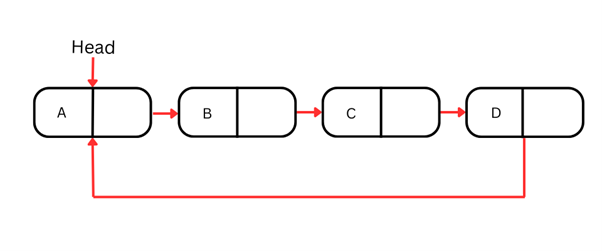
Circular linked list
Listas circulares são uma forma especializada de lista ligada em que o último nó aponta de volta para o primeiro, criando uma estrutura circular. Isso significa que, ao contrário das listas simplesmente e duplamente ligadas que vimos, a lista circular não termina; ela dá a volta.
A natureza cíclica das listas circulares é ideal para cenários que precisam de iteração contínua, como jogos de tabuleiro que retornam do último jogador ao primeiro, ou algoritmos de computação como o escalonamento round-robin.
É útil comparar rapidamente listas ligadas com listas em Python:
| Operação | Lista simplesmente ligada | Array/lista Python |
|---|---|---|
| Acesso por índice | O(n) | O(1) |
| Busca por valor | O(n) | O(n) |
| Inserir no início | O(1) | O(n) |
| Inserir no fim | O(n) | O(1) amortizado |
| Inserir no meio | O(n) | O(n) |
| Remover no início | O(1) | O(n) |
| Remover no fim | O(n) | O(1) amortizado |
Conclusão: listas ligadas são melhores para inserções e remoções na cabeça (O(1)), mas perdem no resto. Se você não está adicionando ou removendo elementos com frequência no início da sua estrutura, provavelmente uma lista Python tradicional é a melhor escolha.
Agora que entendemos o que são listas ligadas, por que usá-las e suas variações, vamos implementar essas estruturas em Python. O notebook deste tutorial também está disponível neste workbook do DataLab; se você criar uma cópia, poderá editar e executar o código. É uma ótima opção caso encontre problemas para rodar o código localmente!
Como vimos, um nó é um elemento da lista ligada que armazena dados e uma referência para o próximo nó da sequência. Veja como definir um nó em Python:
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"O código acima inicializa um nó realizando duas ações principais: o atributo "data" do nó recebe um valor que representa a informação a ser armazenada. Já o atributo "next" representa o endereço do próximo nó. Ele está definido como None no momento, indicando que ainda não há ligação com outro nó na lista. À medida que adicionarmos nós à lista ligada, esse atributo será atualizado para apontar para o nó seguinte.
Em seguida, precisamos criar a classe da lista ligada. Ela vai encapsular todas as operações para gerenciar os nós, como inserção e remoção. Vamos começar inicializando a lista ligada:
class LinkedList:
def __init__(self):
self.head = None # Initialize head as NoneAo definir self.head como None, informamos que a lista ligada começa vazia e não há nós para apontar. Agora vamos popular a lista inserindo novos nós.
Dentro da classe LinkedList, vamos adicionar um método para criar um novo nó e colocá-lo no começo da lista:
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new nodeSempre que você chamar esse método, um novo nó será criado com os dados informados. O ponteiro next desse novo nó é definido como a cabeça atual da lista, posicionando o nó à frente dos já existentes. Por fim, o novo nó passa a ser a cabeça da lista.
Agora vamos popular essa lista ligada com uma sequência de palavras para entender melhor como funciona a inserção. Para isso, primeiro crie um método para percorrer e imprimir o conteúdo da lista:
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new lineO método acima imprime o conteúdo da nossa lista ligada. Agora, vamos usar os métodos definidos para popular a lista com as palavras: “the quick brown fox”.
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()O código acima deve gerar a seguinte saída:
"the quick brown fox"
Agora vamos criar um método chamado insertAtEnd dentro da classe LinkedList para criar um novo nó no final da lista. Se a lista estiver vazia, o novo nó se tornará a cabeça. Caso contrário, ele será anexado ao último nó atual da lista. Veja como isso funciona na prática:
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_nodeO método acima começa criando um novo nó. Em seguida, verifica se a lista está vazia; se estiver, o novo nó é definido como a cabeça. Caso contrário, percorre a lista até encontrar o último nó e ajusta o ponteiro desse nó para o novo nó.
Agora precisamos incluir esse método na nossa classe LinkedList e usá-lo para adicionar uma palavra ao fim da lista. Para isso, ajuste sua função principal para ficar assim:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()Note que apenas chamamos o método insertAtEnd para inserir a palavra “jumps” no final da lista. O código acima deve gerar:
"the quick brown fox jumps"
Remover o primeiro nó de uma lista ligada é simples: basta apontar a cabeça da lista para o segundo nó. Assim, o primeiro nó deixa de fazer parte da lista. Para isso, inclua o método abaixo na classe LinkedList:
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new headPara remover o último nó de uma lista ligada, precisamos percorrê-la para encontrar o penúltimo nó e alterar seu ponteiro next para None. Assim, o último nó deixa de fazer parte da lista. Copie e cole o método a seguir na sua classe LinkedList:
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to NoneO método acima primeiro verifica se a lista está vazia e retorna uma mensagem ao usuário caso esteja. Se houver apenas um nó, ele é removido. Para listas com vários nós, o método localiza o penúltimo nó e atualiza sua referência para que o próximo seja None.
Agora vamos atualizar a função principal para remover elementos do início e do fim da lista ligada:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()O código acima imprime a lista antes e depois das remoções, mostrando como funcionam as operações de inserir e remover em listas ligadas. Você deve ver a seguinte saída ao executá-lo:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown foxA última operação deste capítulo é recuperar um valor específico na lista ligada. Para isso, o método deve começar na cabeça da lista e iterar por cada nó, verificando se os dados do nó correspondem ao valor buscado. Veja uma implementação prática:
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" Para buscar valores específicos na lista que criamos, atualize sua função principal para incluir o método de busca recém-criado:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to findO código acima produzirá a seguinte saída:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the listA palavra “quick” foi encontrada com sucesso na lista ligada, pois está na primeira posição. Já “lazy” não faz parte da lista, por isso não foi encontrada.
Se você chegou até aqui, parabéns! Agora você tem uma base sólida sobre os princípios das listas ligadas: sua estrutura, tipos, como adicionar e remover elementos e como percorrê-las.
Mas a jornada não termina aqui. Listas ligadas são só o começo no universo de estruturas de dados e algoritmos. Aqui vão alguns próximos passos para aprofundar seu conhecimento no assunto:
Explore aplicações práticas de listas ligadas integrando-as a um projeto de programação ou de data science. Elas são usadas para desenvolver sistemas de arquivos, construir tabelas hash e até criar sistemas de navegação por GPS e jogos de tabuleiro. Para começar seus próprios projetos, confira nossos projetos guiados gratuitos que ensinam a resolver problemas do mundo real em Python, R e SQL.
Aprender outras estruturas, como árvores, pilhas e filas, é um passo natural após entender listas ligadas. Essas estruturas expandem os princípios das listas ligadas e ajudam você a resolver um leque maior de problemas computacionais com eficiência. Árvores e árvores binárias de busca, por exemplo, estendem o conceito de listas ligadas para um formato hierárquico, permitindo que cada nó se conecte a múltiplos elementos na estrutura.
Se esses conceitos ainda soam estranhos, não se preocupe! O Datacamp tem um curso completo de estruturas de dados e algoritmos em Python que aprofunda esses tópicos. Primeiro você aprende estruturas como pilhas, árvores, tabelas hash, filas e grafos. Depois, avança para algoritmos de busca e ordenação, que vão ajudar você a programar e resolver problemas com mais eficiência.
Neste tutorial, implementamos listas simplesmente ligadas e cobrimos operações como inserção, remoção e travessia.
Você pode dar um passo além aprendendo a implementação de listas duplamente ligadas e circulares. Skip lists são outra extensão de listas ligadas que permitem buscas mais rápidas, facilitando o acesso aos elementos.
Aprender essas estruturas avançadas vai levar suas habilidades técnicas para o próximo nível e melhorar bastante sua capacidade de programar, preparando você para desafios mais complexos em áreas como data science, desenvolvimento de software e engenharia de machine learning.
Se você prefere uma introdução mais amigável à programação antes de encarar tópicos avançados, explore a trilha de carreira Python Programmer. Ela oferece uma série de cursos que ensinam os fundamentos da linguagem.
Continue aprendendo Python!
Programa
Programa
Curso
Tutorial
Abid Ali Awan
Tutorial
Allan Ouko
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team
