Data Types in Python
BeginnerSkill Level
4 h
66.8K learners
Execute e edite o código deste tutorial online
Executar código
Se você observar a saída das variáveis dataScientist e dataEngineer acima, observe que os valores no conjunto não estão na ordem em que foram adicionados. Isso ocorre porque os conjuntos não são ordenados.
Os conjuntos que contêm valores também podem ser inicializados com o uso de chaves.
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
dataEngineer = {'Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'}
Lembre-se de que as chaves só podem ser usadas para inicializar um conjunto de valores. A imagem abaixo mostra que o uso de chaves sem valores é uma das maneiras de inicializar um dicionário e não um conjunto.

Para adicionar ou remover valores de um conjunto, primeiro você precisa inicializar um conjunto.
# Initialize set with values
graphicDesigner = {'InDesign', 'Photoshop', 'Acrobat', 'Premiere', 'Bridge'}Você pode usar o método add para adicionar um valor a um conjunto.
graphicDesigner.add('Illustrator')
É importante observar que você só pode adicionar um valor que seja imutável (como uma cadeia de caracteres ou uma tupla) a um conjunto. Por exemplo, você receberia um TypeError se tentasse adicionar uma lista a um conjunto.
graphicDesigner.add(['Powerpoint', 'Blender'])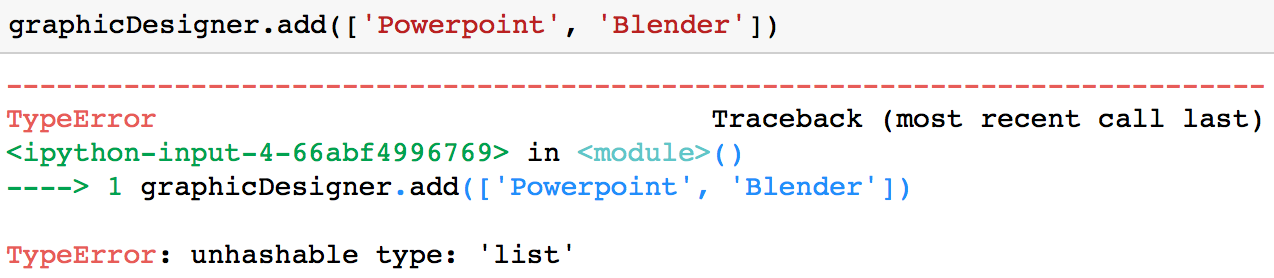
Há algumas maneiras de remover um valor de um conjunto.
Opção 1: Você pode usar o método remove para remover um valor de um conjunto.
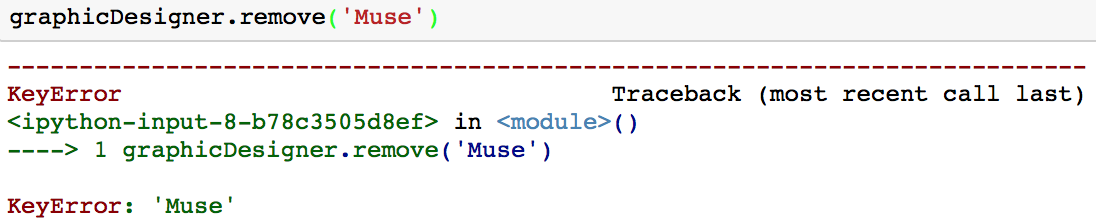
graphicDesigner.remove('Illustrator')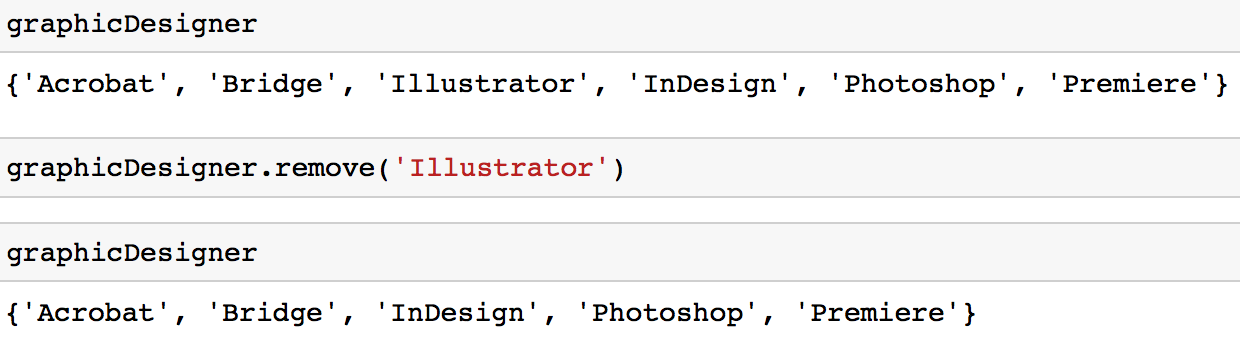
A desvantagem desse método é que, se você tentar remover um valor que não está em seu conjunto, receberá um KeyError.
Opção 2: Você pode usar o método discard para remover um valor de um conjunto.
graphicDesigner.discard('Premiere')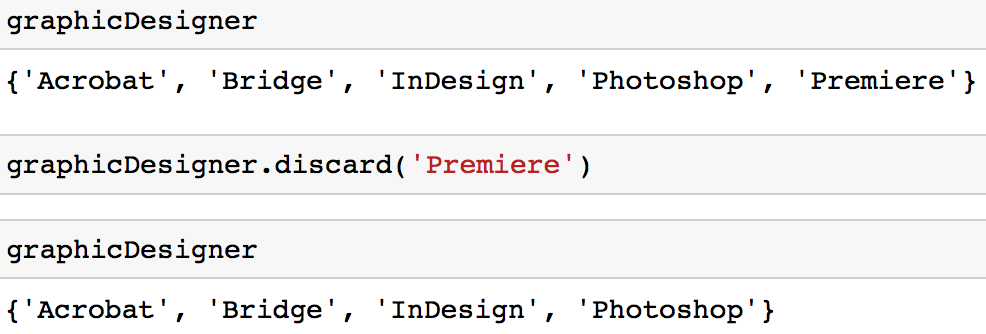
A vantagem dessa abordagem em relação ao método remove é que, se você tentar remover um valor que não faz parte do conjunto, não receberá um KeyError. Se você estiver familiarizado com dicionários, poderá perceber que isso funciona de forma semelhante ao método get do dicionário.
Opção 3: Você também pode usar o método pop para remover e retornar um valor arbitrário de um conjunto.
graphicDesigner.pop()
É importante observar que o método gera um KeyError se o conjunto estiver vazio.
Você pode usar o método clear para remover todos os valores de um conjunto.
graphicDesigner.clear()
O método de atualização adiciona os elementos de um conjunto a um conjunto. Requer um único argumento que pode ser um conjunto, lista, tuplas ou dicionário. O método .update() converte automaticamente outros tipos de dados em conjuntos e os adiciona ao conjunto.
No exemplo, inicializamos três conjuntos e usamos uma função de atualização para adicionar elementos do conjunto2 ao conjunto1 e, em seguida, do conjunto3 ao conjunto1.
# Initialize 3 sets
set1 = set([7, 10, 11, 13])
set2 = set([11, 8, 9, 12, 14, 15])
set3 = {'d', 'f', 'h'}
# Update set1 with set2
set1.update(set2)
print(set1)
# Update set1 with set3
set1.update(set3)
print(set1)
Como muitos tipos de dados padrão do Python, é possível iterar em um conjunto.
# Initialize a set
dataScientist = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
for skill in dataScientist:
print(skill)
Se você observar o resultado da impressão de cada um dos valores em dataScientist, observe que os valores impressos no conjunto não estão na ordem em que foram adicionados. Isso ocorre porque os conjuntos não são ordenados.
Este tutorial enfatizou que os conjuntos não são ordenados. Se você achar que precisa obter os valores do seu conjunto em uma forma ordenada, poderá usar a função sorted, que gera uma lista ordenada.
type(sorted(dataScientist))
O código abaixo gera os valores no conjunto dataScientist em ordem alfabética decrescente (Z-A, nesse caso).
sorted(dataScientist, reverse = True)
Parte do conteúdo desta seção foi explorada anteriormente no tutorial 18 Most Common Python List Questions (18 perguntas mais comuns sobre listas em Python), mas é importante enfatizar que os conjuntos são a maneira mais rápida de remover duplicatas de uma lista. Para demonstrar isso, vamos estudar a diferença de desempenho entre duas abordagens.
Abordagem 1: Use um conjunto para remover duplicatas de uma lista.
print(list(set([1, 2, 3, 1, 7])))Abordagem 2: Use uma compreensão de lista para remover duplicatas de uma lista (se você quiser saber mais sobre compreensões de lista, consulte este tutorial).
def remove_duplicates(original):
unique = []
[unique.append(n) for n in original if n not in unique]
return(unique)
print(remove_duplicates([1, 2, 3, 1, 7]))A diferença de desempenho pode ser medida usando a biblioteca timeit, que permite cronometrar o tempo do código Python. O código abaixo executa o código de cada abordagem 10.000 vezes e gera o tempo total necessário em segundos.
import timeit
# Approach 1: Execution time
print(timeit.timeit('list(set([1, 2, 3, 1, 7]))', number=10000))
# Approach 2: Execution time
print(timeit.timeit('remove_duplicates([1, 2, 3, 1, 7])', globals=globals(), number=10000))
A comparação dessas duas abordagens mostra que o uso de conjuntos para remover duplicatas é mais eficiente. Embora possa parecer uma pequena diferença de tempo, isso pode economizar muito tempo se você tiver listas muito grandes.
Um uso comum de conjuntos em Python é a computação de operações matemáticas padrão, como união, interseção, diferença e diferença simétrica. A imagem abaixo mostra algumas operações matemáticas padrão em dois conjuntos A e B. A parte vermelha de cada diagrama de Venn é o conjunto resultante de uma determinada operação de conjunto.
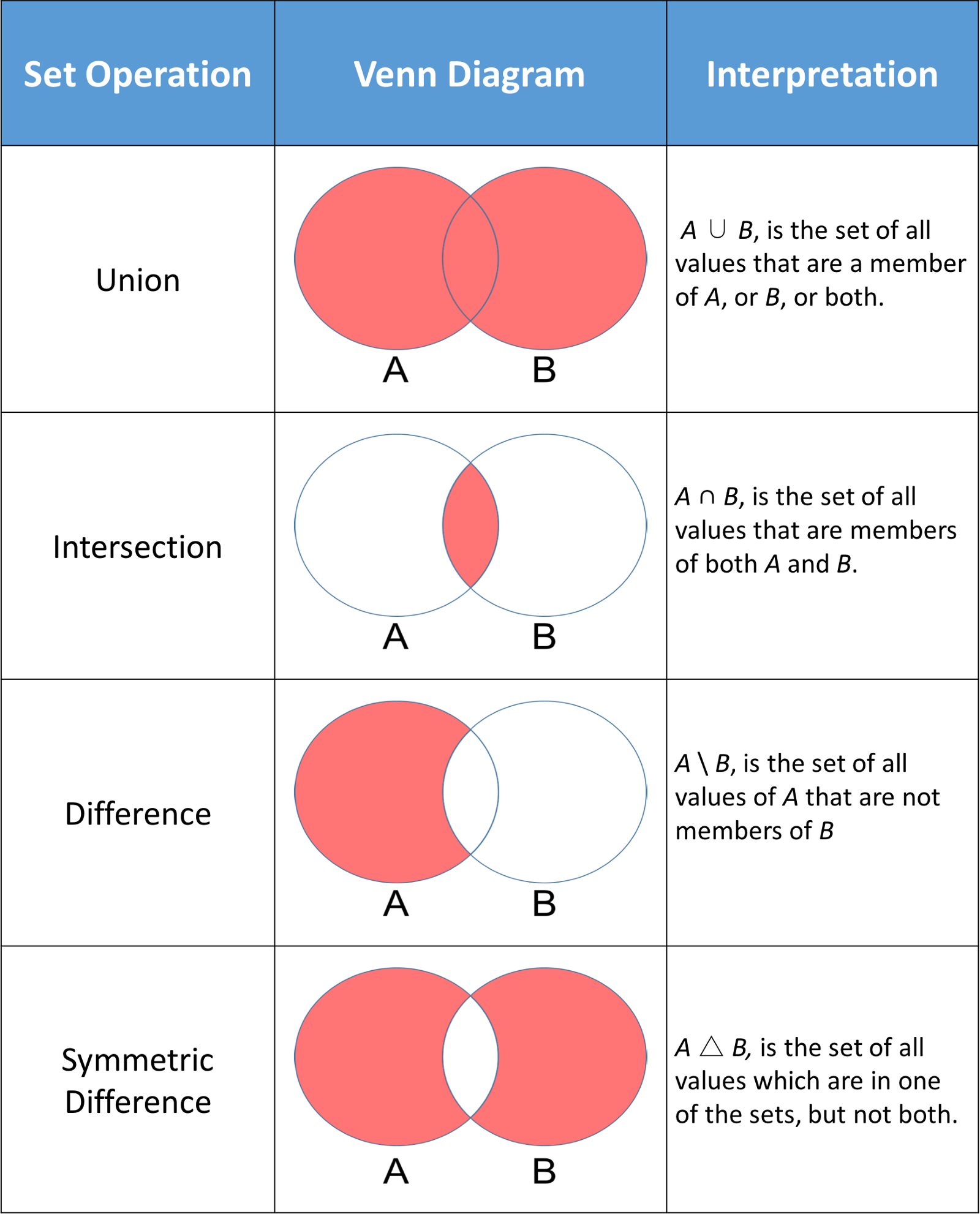
Os conjuntos Python têm métodos que permitem realizar essas operações matemáticas, bem como operadores que fornecem resultados equivalentes.
Antes de explorar esses métodos, vamos começar inicializando dois conjuntos dataScientist e dataEngineer.
dataScientist = set(['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'])
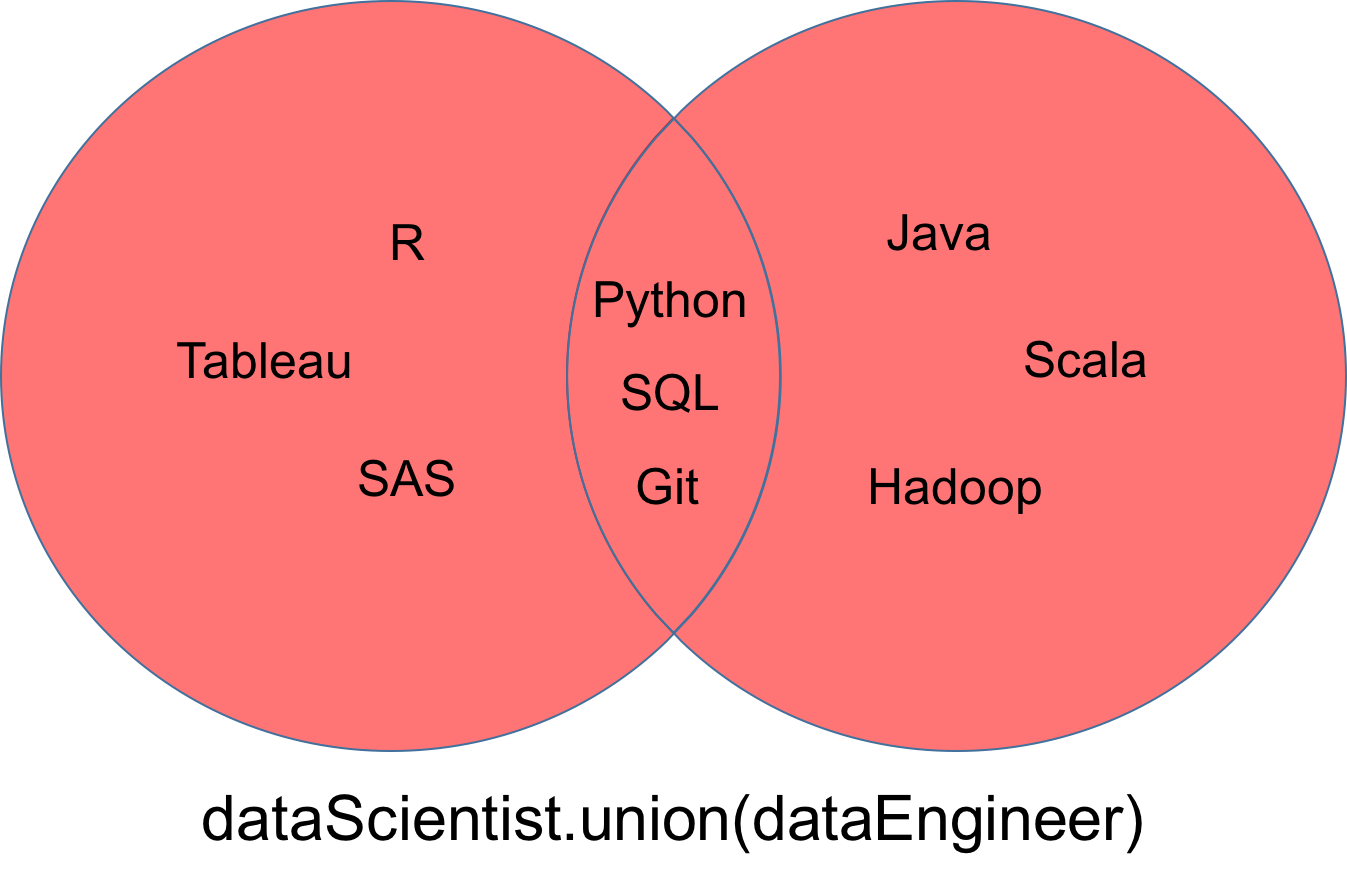
dataEngineer = set(['Python', 'Java', 'Scala', 'Git', 'SQL', 'Hadoop'])Uma união, denotada por dataScientist ∪ dataEngineer, é o conjunto de todos os valores que são valores de dataScientist, dataEngineer ou ambos. Você pode usar o método union para descobrir todos os valores exclusivos em dois conjuntos.
# set built-in function union
dataScientist.union(dataEngineer)
# Equivalent Result
dataScientist | dataEngineer
O conjunto retornado da união pode ser visualizado como a parte vermelha do diagrama de Venn abaixo.
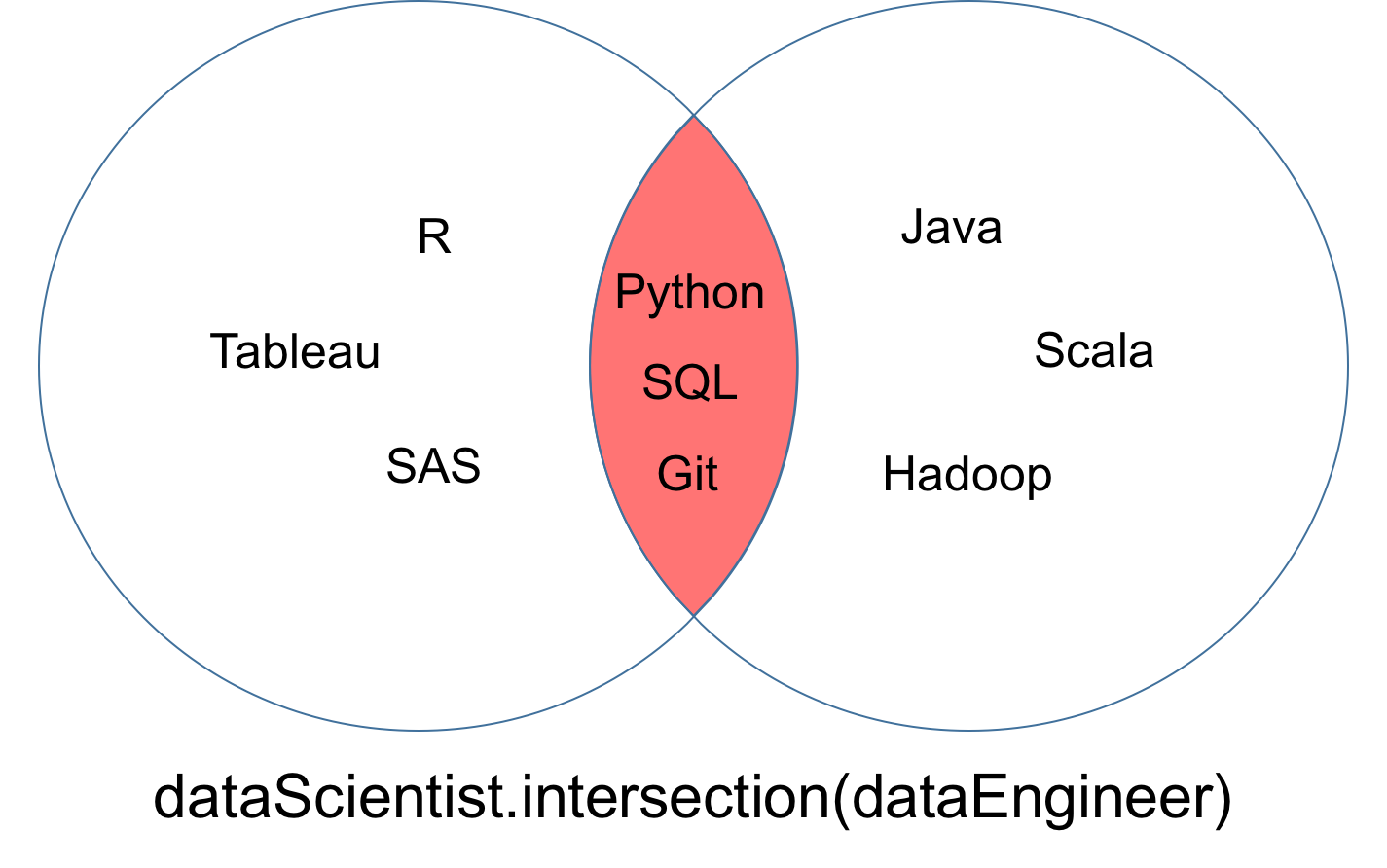
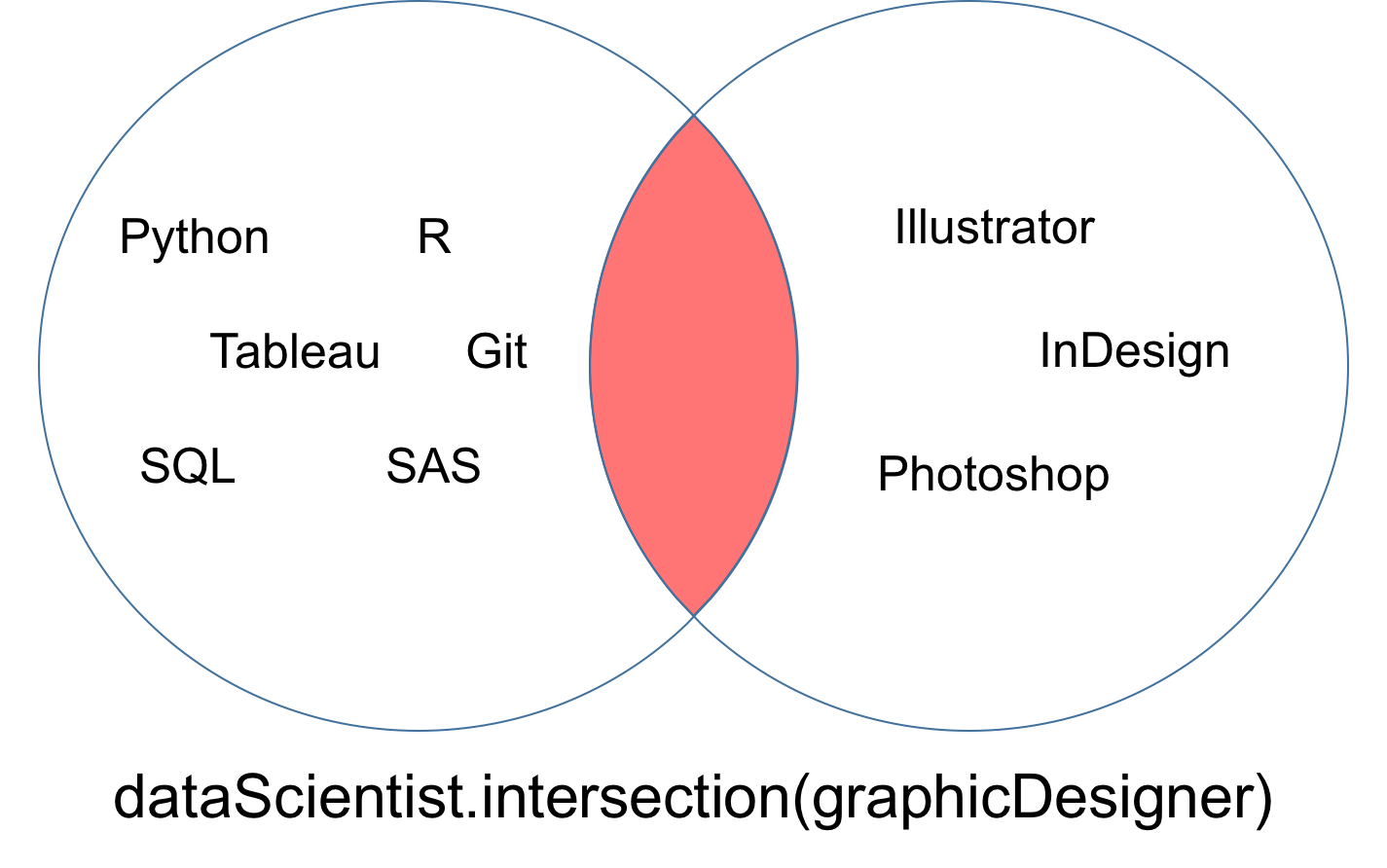
Uma interseção de dois conjuntos dataScientist e dataEngineer, denotada dataScientist ∩ dataEngineer, é o conjunto de todos os valores que são valores de dataScientist e dataEngineer.
# Intersection operation
dataScientist.intersection(dataEngineer)
# Equivalent Result
dataScientist & dataEngineer
O conjunto retornado da interseção pode ser visualizado como a parte vermelha do diagrama de Venn abaixo.
Talvez você se depare com um caso em que queira garantir que dois conjuntos não tenham nenhum valor em comum. Em outras palavras, você quer dois conjuntos que tenham uma interseção vazia. Esses dois conjuntos são chamados de conjuntos disjuntos. Você pode testar a existência de conjuntos disjuntos usando o método isdisjoint.
# Initialize a set
graphicDesigner = {'Illustrator', 'InDesign', 'Photoshop'}
# These sets have elements in common so it would return False
dataScientist.isdisjoint(dataEngineer)
# These sets have no elements in common so it would return True
dataScientist.isdisjoint(graphicDesigner)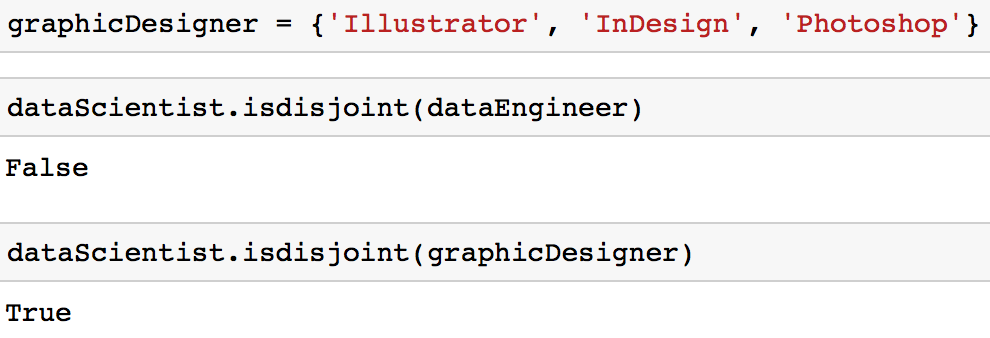
Você pode observar na interseção mostrada no diagrama de Venn abaixo que os conjuntos disjuntos dataScientist e graphicDesigner não têm valores em comum.
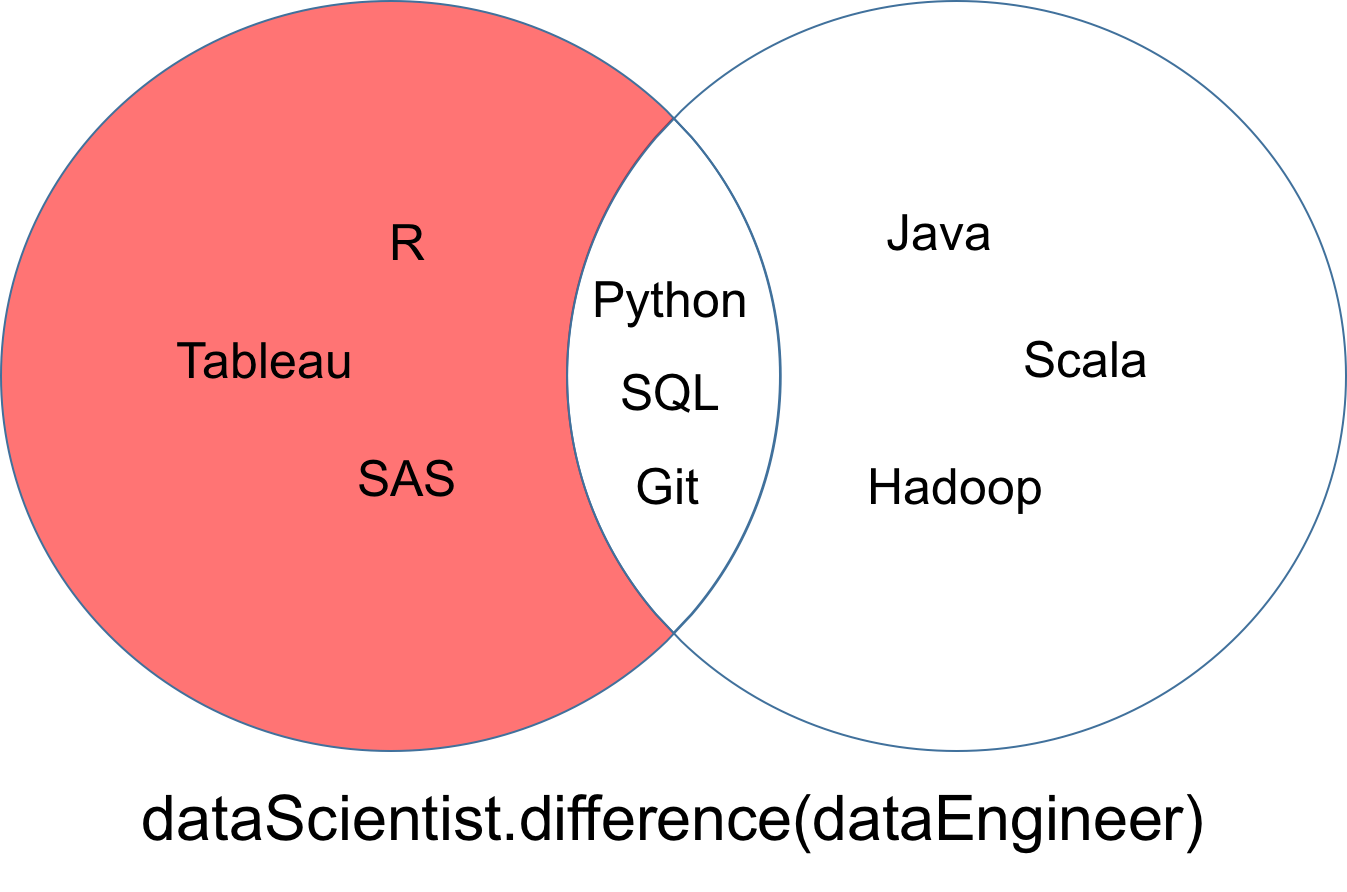
Uma diferença de dois conjuntos dataScientist e dataEngineer, denotada por dataScientist \ dataEngineer, é o conjunto de todos os valores de dataScientist que não são valores de dataEngineer.
# Difference Operation
dataScientist.difference(dataEngineer)
# Equivalent Result
dataScientist - dataEngineer
O conjunto retornado da diferença pode ser visualizado como a parte vermelha do diagrama de Venn abaixo.
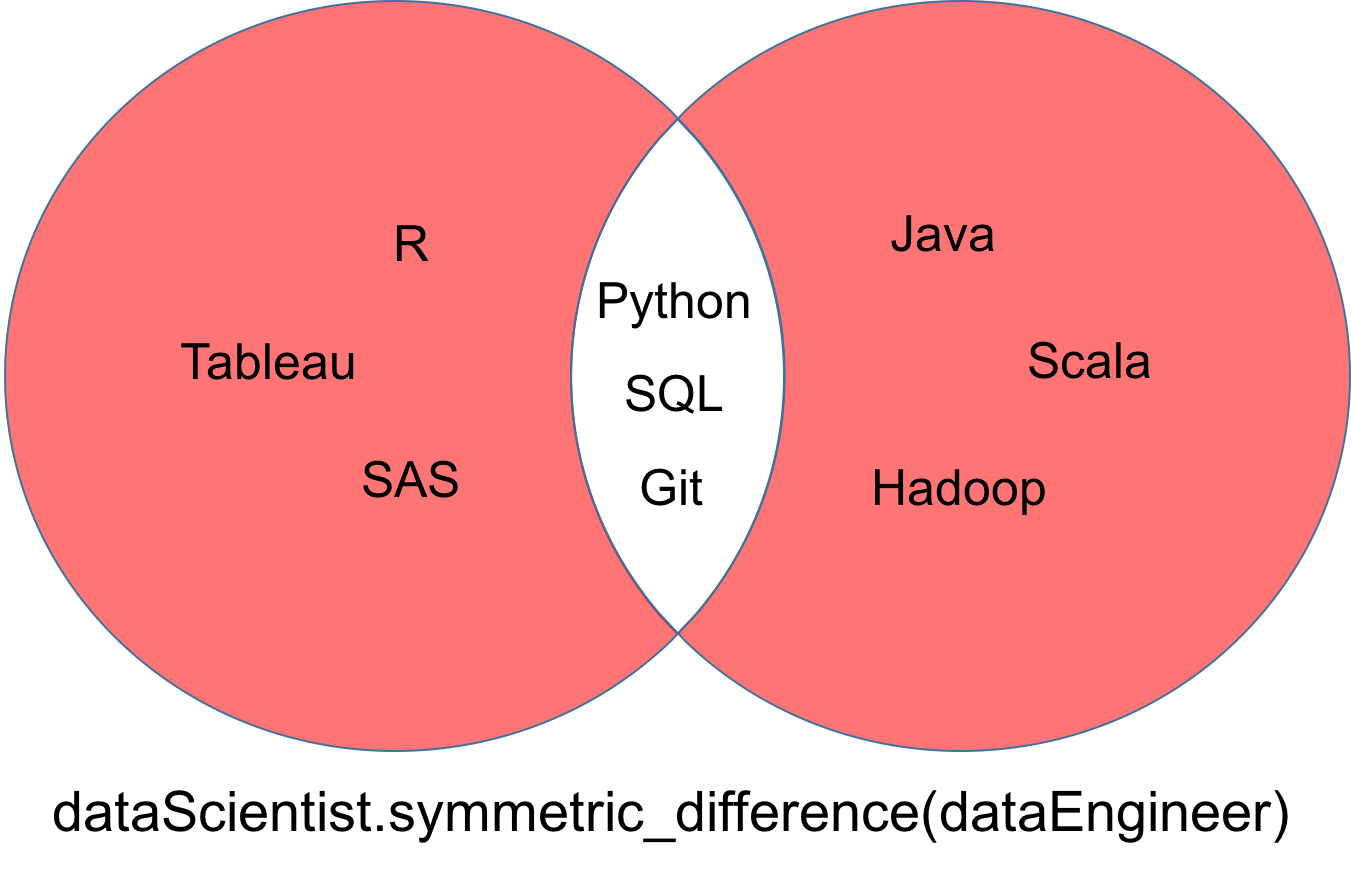
Uma diferença simétrica de dois conjuntos dataScientist e dataEngineer, denotada dataScientist △ dataEngineer, é o conjunto de todos os valores que são valores de exatamente um dos dois conjuntos, mas não de ambos.
# Symmetric Difference Operation
dataScientist.symmetric_difference(dataEngineer)
# Equivalent Result
dataScientist ^ dataEngineer
O conjunto retornado da diferença simétrica pode ser visualizado como a parte vermelha do diagrama de Venn abaixo.
Você pode ter aprendido anteriormente sobre compreensões de lista, compreensões de dicionário e compreensões de gerador. Há também as compreensões de conjuntos do Python. As compreensões de conjunto são muito semelhantes. As compreensões de conjunto em Python podem ser construídas da seguinte forma:
{skill for skill in ['SQL', 'SQL', 'PYTHON', 'PYTHON']}
O resultado acima é um conjunto de 2 valores porque os conjuntos não podem ter várias ocorrências do mesmo elemento.
A ideia por trás do uso de compreensões de conjuntos é permitir que você escreva e raciocine no código da mesma forma que faria com a matemática à mão.
{skill for skill in ['GIT', 'PYTHON', 'SQL'] if skill not in {'GIT', 'PYTHON', 'JAVA'}}O código acima é semelhante a uma diferença de conjunto sobre a qual você aprendeu anteriormente. A aparência é um pouco diferente.
Os testes de associação verificam se um elemento específico está contido em uma sequência, como strings, listas, tuplas ou conjuntos. Uma das principais vantagens de usar conjuntos em Python é que eles são altamente otimizados para testes de associação. Por exemplo, os conjuntos fazem testes de associação com muito mais eficiência do que as listas. Caso você tenha formação em ciência da computação, isso se deve ao fato de que a complexidade do tempo médio dos testes de associação em conjuntos é O(1) versus O(n) para listas.
O código abaixo mostra um teste de associação usando uma lista.
# Initialize a list
possibleList = ['Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala']
# Membership test
'Python' in possibleList
Algo semelhante pode ser feito para conjuntos. Os conjuntos são mais eficientes.
# Initialize a set
possibleSet = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS', 'Java', 'Spark', 'Scala'}
# Membership test
'Python' in possibleSet
Como possibleSet é um conjunto e o valor 'Python' é um valor de possibleSet, isso pode ser denotado como 'Python' ∈ possibleSet.
Se você tivesse um valor que não fizesse parte do conjunto, como 'Fortran', ele seria denotado como 'Fortran' ∉ possibleSet.
Uma aplicação prática da compreensão da associação são os subconjuntos.
Vamos primeiro inicializar dois conjuntos.
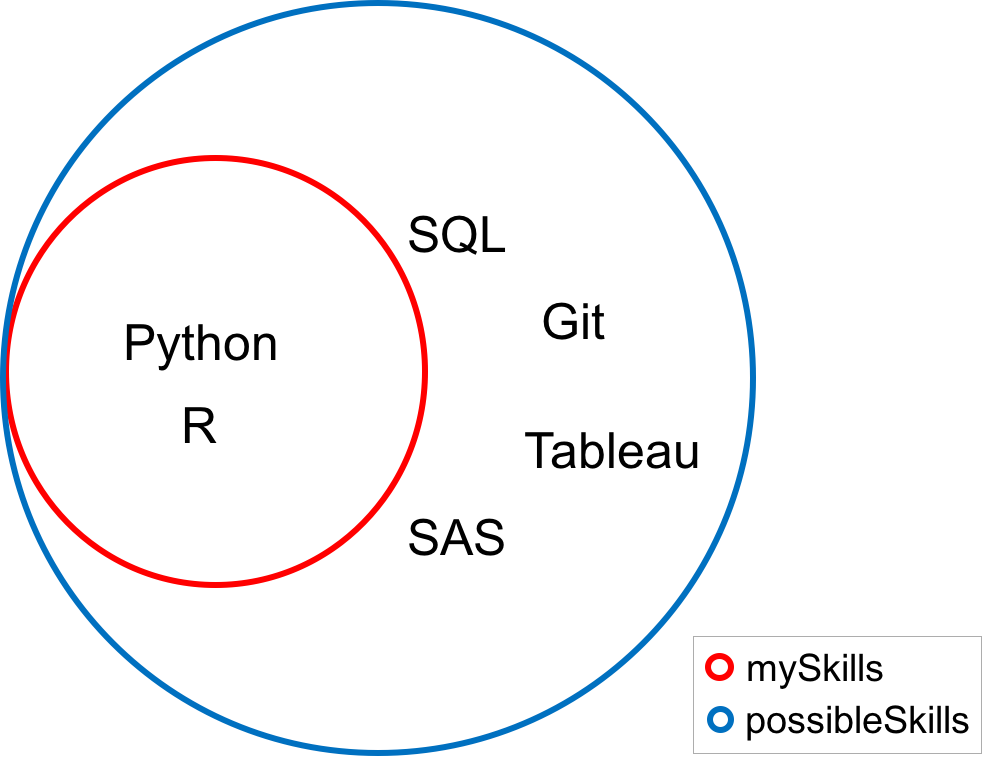
possibleSkills = {'Python', 'R', 'SQL', 'Git', 'Tableau', 'SAS'}
mySkills = {'Python', 'R'}Se todo valor do conjunto mySkills também for um valor do conjunto possibleSkills, então mySkills é considerado um subconjunto de possibleSkills, matematicamente escrito mySkills ⊆ possibleSkills.
Você pode verificar se um conjunto é um subconjunto de outro usando o método issubset.
mySkills.issubset(possibleSkills)
Como o método retorna True nesse caso, ele é um subconjunto. No diagrama de Venn abaixo, observe que todo valor do conjunto mySkills também é um valor do conjunto possibleSkills.
Você já se deparou com listas e tuplas aninhadas.
# Nested Lists and Tuples
nestedLists = [['the', 12], ['to', 11], ['of', 9], ['and', 7], ['that', 6]]
nestedTuples = (('the', 12), ('to', 11), ('of', 9), ('and', 7), ('that', 6))
O problema com os conjuntos aninhados é que normalmente não é possível ter conjuntos aninhados no Python, pois os conjuntos não podem conter valores mutáveis, inclusive conjuntos.
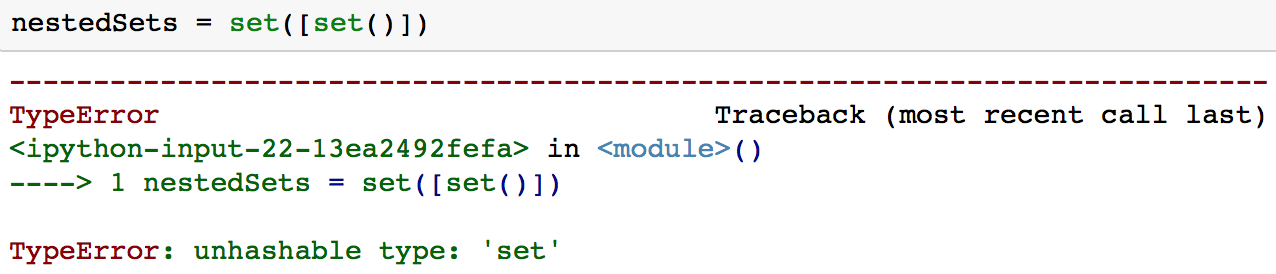
Essa é uma situação em que você pode querer usar um frozenset. Um frozenset é muito semelhante a um conjunto, exceto pelo fato de que um frozenset é imutável.
Você cria um frozenset usando o site frozenset().
# Initialize a frozenset
immutableSet = frozenset()
Você pode criar um conjunto aninhado se utilizar um frozenset semelhante ao código abaixo.
nestedSets = set([frozenset()])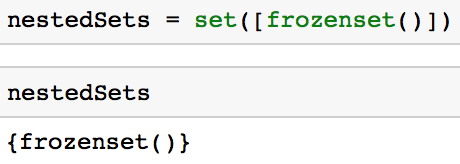
É importante ter em mente que uma das principais desvantagens de um frozenset é que, como ele é imutável, isso significa que você não pode adicionar ou remover valores.
Os conjuntos Python são muito úteis para remover com eficiência valores duplicados de uma coleção, como uma lista, e para realizar operações matemáticas comuns, como uniões e interseções. Alguns dos desafios que as pessoas encontram com frequência são quando usar os vários tipos de dados. Por exemplo, se você acha que não tem certeza de quando é vantajoso usar um dicionário em vez de um conjunto, recomendo que confira o modo de prática diária do DataCamp. Se você tiver alguma dúvida ou opinião sobre o tutorial, sinta-se à vontade para entrar em contato nos comentários abaixo ou pelo Twitter.
Cursos de Python
Curso
Curso
Curso
Tutorial
DataCamp Team
Tutorial
Théo Vanderheyden
Tutorial
Théo Vanderheyden