Curso
Limpeza de dados com o PySpark
4 h
33.2K
Os dados que podem ser categorizados, mas não têm uma hierarquia ou ordem inerente, são conhecidos como dados categóricos. Em outras palavras, não há conexão matemática entre as categorias. O gênero de uma pessoa (masculino/feminino), a cor dos olhos (azul, verde, marrom etc.), o tipo de veículo que dirige (sedã, SUV, caminhão etc.) ou o tipo de fruta que consome (maçã, banana, laranja etc.) são exemplos de dados categóricos.
Neste tutorial, descreveremos os métodos de manuseio e pré-processamento de dados categóricos. Antes de discutir a importância de preparar dados categóricos para modelos de aprendizado de máquina, primeiro definiremos dados categóricos e seus tipos. Além disso, veremos vários métodos de codificação, análise de dados categóricos e métodos de visualização em Python e ideias mais avançadas, como dados categóricos de grande cardinalidade e vários métodos de codificação.
As informações são representadas por meio de duas formas diferentes de dados: dados categóricos e dados numéricos. Os dados que podem ser categorizados ou agrupados são chamados de dados categóricos. Homens e mulheres se enquadram na categoria de gênero, as cores vermelho, verde e azul se enquadram na categoria de cores e a categoria de países pode incluir os EUA, o Canadá, o México etc.
Dados numéricos referem-se a dados que podem ser expressos como um número. Exemplos de dados numéricos incluem altura, peso e temperatura.
Em termos simples, os dados categóricos são informações que podem ser colocadas em categorias, enquanto os dados numéricos são informações que podem ser expressas como um número. Como a maioria dos algoritmos de aprendizado de máquina é criada para operar com dados numéricos, os dados categóricos são tratados de forma diferente dos dados numéricos nesse campo. Antes que os dados categóricos possam ser utilizados como entrada para um modelo de aprendizado de máquina, eles devem primeiro ser transformados em dados numéricos. Esse processo de conversão de dados categóricos em representação numérica é conhecido como codificação.
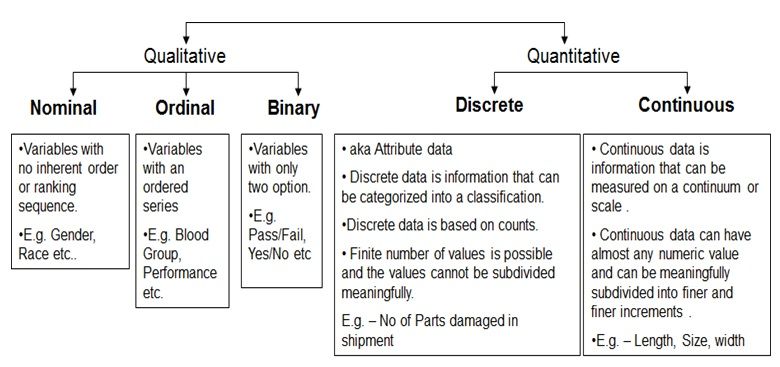
Dados qualitativos e quantitativos - Fonte da imagem
Há dois tipos de dados categóricos: nominais e ordinais.
Os dados nominais são dados categóricos que podem ser divididos em grupos, mas esses grupos não têm nenhuma hierarquia ou ordem intrínseca. Exemplos de dados nominais incluem nomes de marcas (Coca-Cola, Pepsi, Sprite), variedades de coberturas de pizza (pepperoni, cogumelos, cebolas) e cor do cabelo (loiro, marrom, preto etc.).
Os dados ordinais, por outro lado, descrevem informações que podem ser categorizadas e têm uma ordem ou classificação distinta. Níveis de educação (ensino médio, bacharelado, mestrado), níveis de satisfação no trabalho (extremamente satisfeito, satisfeito, neutro, insatisfeito, muito insatisfeito) e classificações por estrelas (1 estrela, 2 estrelas, 3 estrelas, 4 estrelas, 5 estrelas) são alguns exemplos de dados ordinais.
Ao atribuir a cada categoria um valor numérico que reflete sua ordem ou classificação, os dados ordinais podem ser transformados em dados numéricos e usados no aprendizado de máquina. Isso pode ser útil para algoritmos que são sensíveis ao tamanho dos dados de entrada.
A distinção entre dados nominais e ordinais nem sempre é óbvia na prática e pode variar dependendo do caso de uso específico. Por exemplo, enquanto algumas pessoas podem ver a "classificação por estrelas" como dados ordinais, outras podem vê-la como dados nominais. O mais importante é estar ciente da natureza de seus dados e selecionar a estratégia de codificação que melhor capture as relações em seus dados.
A biblioteca de código aberto pandas, amplamente utilizada em Python, é usada para análise e manipulação de dados. Ele tem recursos avançados para lidar com dados estruturados, inclusive como quadros de dados e séries que podem lidar com dados tabulares com linhas e colunas rotuladas.
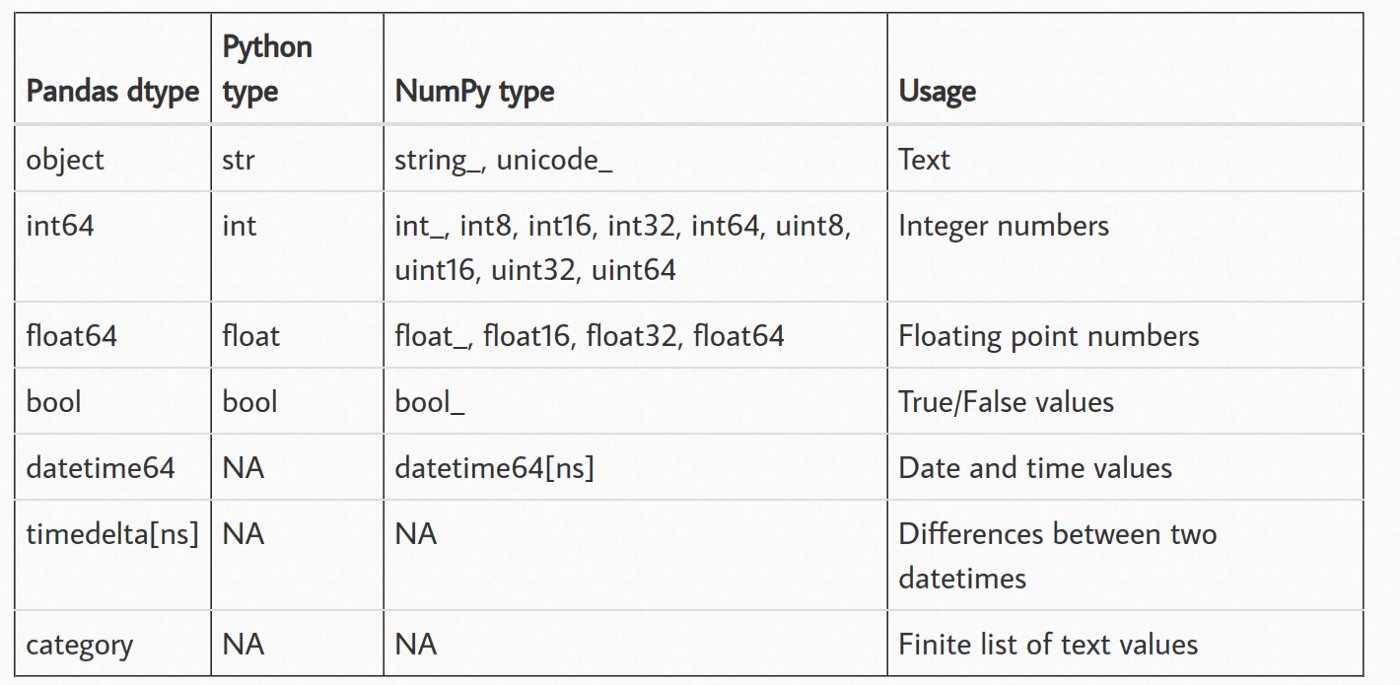
O pandas também fornece várias funções para ler e gravar diferentes tipos de arquivos (csv, parquet, banco de dados etc.). Quando você lê um arquivo usando o pandas, cada coluna recebe um tipo de dados com base na inferência. Aqui estão todos os tipos de dados que o pandas pode atribuir:
Os dados que não se encaixam em outros tipos de dados, incluindo strings, tipos mistos ou outros objetos, são representados pelos tipos de dados de categoria e objeto no pandas. No entanto, eles têm algumas diferenças significativas que afetam seu funcionamento e desempenho.
O tipo de dados categóricos foi criado para informações que têm apenas alguns valores possíveis, como categorias ou rótulos. Internamente, os dados categóricos são representados como uma coleção de números, o que pode acelerar algumas operações e economizar memória em comparação com o tipo de dados de objeto correspondente. Além disso, os dados categóricos podem ser organizados de forma lógica e facilitam procedimentos eficazes de agrupamento e agregação.
Por outro lado, o tipo de dados objeto serve como um apanhado de informações que não se encaixam nos outros tipos de dados. Listas, dicionários e outros objetos são apenas alguns exemplos dos vários tipos de dados que ele pode incluir. Embora os dados de objeto tenham uma grande flexibilidade, eles também podem ser mais lentos e consumir mais memória do que os dados categóricos do mesmo tamanho e não podem ser submetidos a algumas das operações especializadas que são possíveis com os dados de categoria.
Em geral, você pode pensar em utilizar o tipo de dados categóricos se os seus dados tiverem um pequeno número de valores possíveis e você pretender realizar muitos agrupamentos ou agregações. O tipo de dados de objeto é normalmente uma opção segura em todos os outros casos. No entanto, o tipo de dados ideal depende, em última análise, de seu caso de uso exclusivo e das propriedades de seus dados.
Vamos ver um exemplo lendo um arquivo csv do GitHub.
# read csv using pandas
data = pd.read_csv(‘https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv’)
# check the head of dataframe
data.head()Saída:
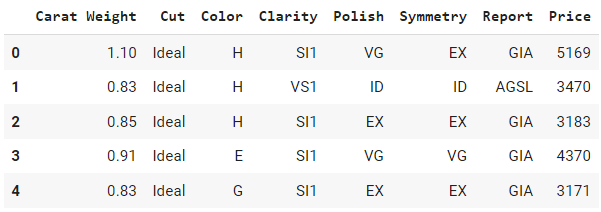
Você consegue identificar quais dessas colunas são categóricas ou numéricas? Bem, todas as colunas desse exemplo são categóricas, exceto `Carat Weight` e `Price`. Vamos ver se estamos certos sobre isso verificando os tipos de dados padrão.
# check the data types
data.dtypesSaída:

Observe como `Price` é atribuído ao tipo `int64`, `Carat Weight` como `float64` e o restante das colunas são objetos, exatamente como esperávamos.
Existem algumas funções no pandas, uma biblioteca popular de análise de dados em Python, que permitem analisar rapidamente tipos de dados categóricos em seu conjunto de dados. Vamos examiná-las uma a uma:
`value_counts()` é uma função da biblioteca pandas que retorna a frequência de cada valor exclusivo em uma coluna de dados categóricos. Essa função é útil quando você deseja obter uma compreensão rápida da distribuição de uma variável categórica, como as categorias mais comuns e sua frequência.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# check value counts of Cut column
data['Cut'].value_counts()Saída:

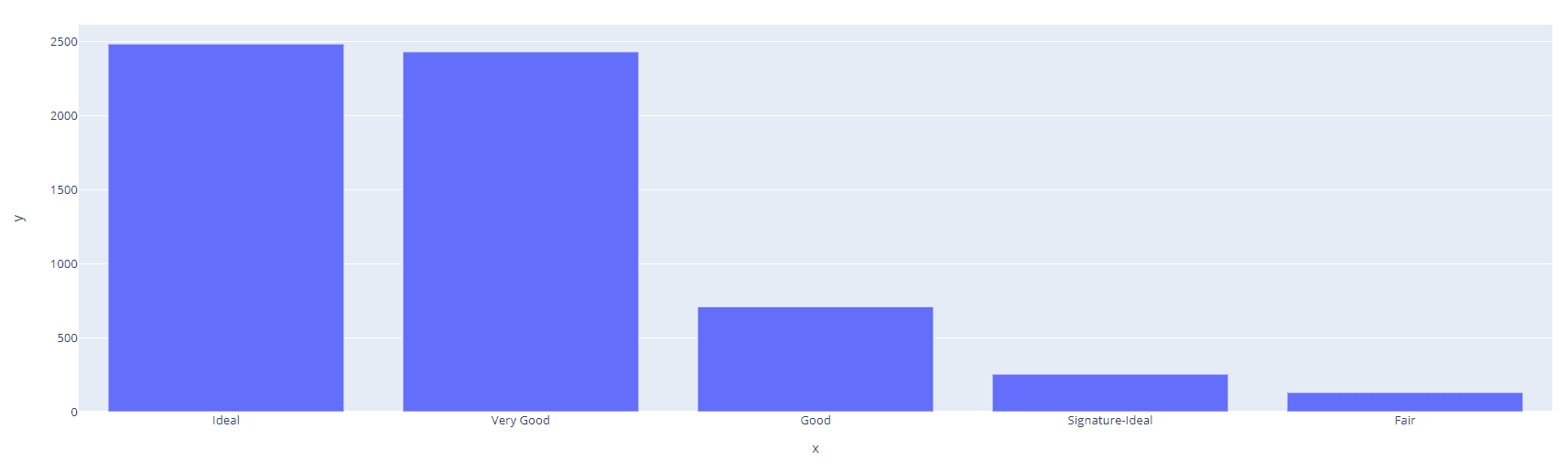
Se quiser visualizar a distribuição, você pode usar a biblioteca `plotly` para desenhar um gráfico de barras interativo.
import plotly.express as px
cut_counts = data['Cut'].value_counts()
fig = px.bar(x=cut_counts.index, y=cut_counts.values)
fig.show()Saída:
O `groupby()` é uma função do Pandas que permite agrupar dados por uma ou mais colunas e aplicar funções de agregação, como soma, média e contagem. Essa função é útil quando você deseja realizar análises mais complexas em dados categóricos, como calcular a média de uma variável numérica para cada categoria. Vejamos um exemplo:
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# average carat weight and price by Cut
data.groupby(by = 'Cut').mean()Saída:
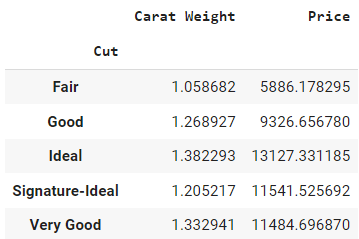
Ele retornará apenas um quadro de dados com colunas numéricas. O parâmetro `by` dentro do método `groupby` define a coluna na qual você deseja executar a operação de agrupar por e, em seguida, `mean()`, fora dos parênteses, é o método de agregação.
O resultado pode ser interpretado como o preço médio de um diamante com lapidação justa é de 5.886, e o peso médio é de 1,05, em comparação com o preço médio de 11.485 para um diamante com lapidação muito boa.
`crosstab()` é uma função do pandas que cria uma tabela de tabulação cruzada, que mostra a distribuição de frequência de duas ou mais variáveis categóricas. Essa função é útil quando você deseja ver a relação entre duas ou mais variáveis categóricas, por exemplo, como a frequência de uma variável está relacionada a outra variável.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# cross tab of Cut and Color
pd.crosstab(index=data['Cut'], columns=data['Color'])
Saída:
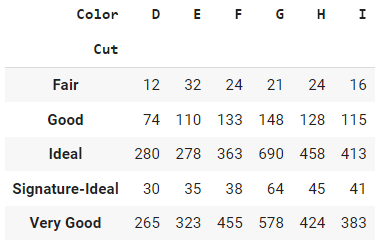
A saída da função crosstab no pandas é uma tabela que mostra a distribuição de frequência de duas ou mais variáveis categóricas. Cada linha da tabela representa uma categoria exclusiva em uma das variáveis, e cada coluna representa uma categoria exclusiva na outra variável. As entradas na tabela são as contagens de frequência das combinações de categorias nas duas variáveis.
A `pivot_table()` é uma função do Pandas que cria tabelas dinâmicas, que são semelhantes às tabelas de tabulação cruzada, mas com mais flexibilidade. Essa função é útil quando você deseja analisar diversas variáveis categóricas e sua relação com uma ou mais variáveis numéricas. As tabelas dinâmicas permitem agregar dados de várias maneiras e exibir os resultados em um formato compacto.
# read csv using pandas
import pandas as pd
data = pd.read_csv('https://raw.githubusercontent.com/pycaret/pycaret/master/datasets/diamond.csv')
# create pivot table
pd.pivot_table(data, values='Price', index='Cut', columns='Color', aggfunc=np.mean)
Saída:
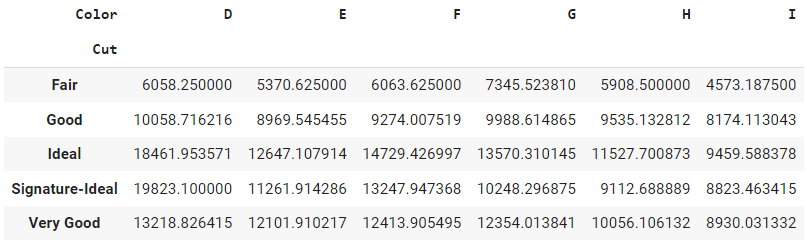
Essa tabela mostra o preço médio de cada lapidação de diamante para cada cor. As linhas representam os diferentes cortes de diamante, as colunas representam as diferentes cores de diamante e as entradas na tabela são o preço médio do diamante.
A função pivot_table é útil quando se deseja resumir e comparar os dados numéricos de várias variáveis em um formato de tabela. A função permite agregar os dados usando várias funções (como média, soma, contagem etc.) e organizá-los em um formato fácil de ler e analisar.
Em geral, os dados categóricos não podem ser tratados diretamente por algoritmos de aprendizado de máquina, pois a maioria dos algoritmos é projetada principalmente para operar apenas com dados numéricos. Portanto, antes que os recursos categóricos possam ser usados como entradas para algoritmos de aprendizado de máquina, eles devem ser codificados como valores numéricos.
Há várias técnicas para codificar recursos categóricos, incluindo codificação de um ponto, codificação ordinal e codificação de alvo. A escolha da técnica de codificação depende das características específicas dos dados e dos requisitos do algoritmo de aprendizado de máquina que está sendo usado.
Uma codificação quente é um processo de representação de dados categóricos como um conjunto de valores binários, em que cada categoria é mapeada para um valor binário exclusivo. Nessa representação, apenas um bit é definido como 1, e os demais são definidos como 0, daí o nome "one hot". Isso é comumente usado no aprendizado de máquina para converter dados categóricos em um formato que os algoritmos possam processar.
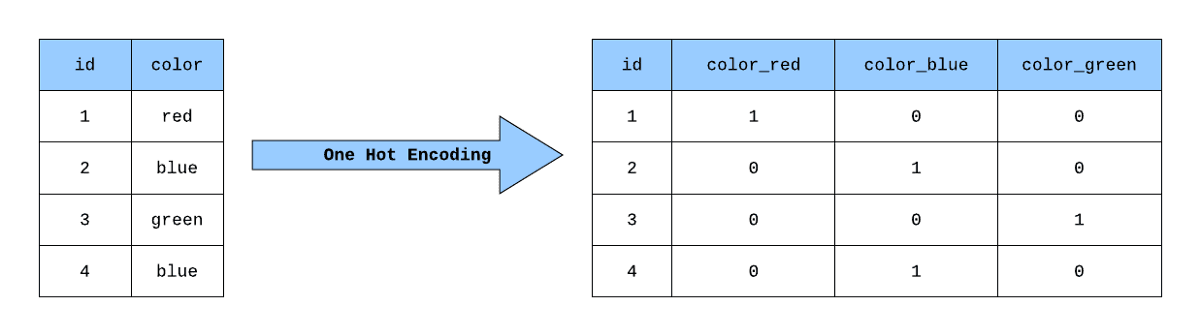
Uma maneira de conseguir isso no pandas é usar o método `pd.get_dummies()`. É uma função da biblioteca do Pandas que pode ser usada para realizar a codificação de um ponto em variáveis categóricas em um DataFrame. Ele recebe um DataFrame e retorna um novo DataFrame com colunas binárias para cada categoria. Aqui está um exemplo de como usá-lo:
Suponha que tenhamos um quadro de dados com uma coluna "fruit" (fruta) contendo dados categóricos:
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# show head
df = pd.DataFrame(data)
df.head()
Saída:

# apply get_dummies function
df_encoded = pd.get_dummies(df["fruit"])
df_encoded .head()
Saída:
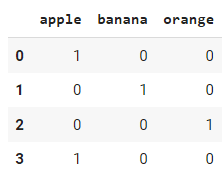
Embora o `pandas.get_dummies` seja fácil de usar, uma abordagem mais comum é usar o `OneHotEncoder` da biblioteca sklearn, especialmente quando você estiver realizando tarefas de aprendizado de máquina. A principal diferença é que o `pandas.get_dummies` não pode aprender codificações; ele só pode executar uma codificação de disparo no conjunto de dados que você passar como entrada. Por outro lado, `sklearn.OneHotEncoder` é uma classe que pode ser salva e usada para transformar outros conjuntos de dados de entrada no futuro.
import pandas as pd
# generate df with 1 col and 4 rows
data = {
"fruit": ["apple", "banana", "orange", "apple"]
}
# one-hot-encode using sklearn
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoded_results = encoder.fit_transform(df).toarray()
Saída:
A codificação de rótulos é uma técnica para codificar variáveis categóricas como valores numéricos, com cada categoria atribuída a um número inteiro exclusivo. Por exemplo, suponha que tenhamos uma variável categórica "cor" com três categorias: "vermelho", "verde" e "azul". Podemos codificar essas categorias usando a codificação de rótulos da seguinte forma (vermelho: 0, verde: 1, azul: 2).
A codificação de rótulos pode ser útil para alguns algoritmos de aprendizado de máquina que exigem entradas numéricas, pois permite que os dados categóricos sejam representados de uma forma que os algoritmos possam entender. Entretanto, é importante ter em mente que a codificação de rótulos introduz uma ordenação arbitrária das categorias, que pode não refletir necessariamente qualquer relação significativa entre elas. Em alguns casos, isso pode levar a problemas na análise, especialmente se a ordenação for interpretada como tendo algum tipo de relação ordinal.
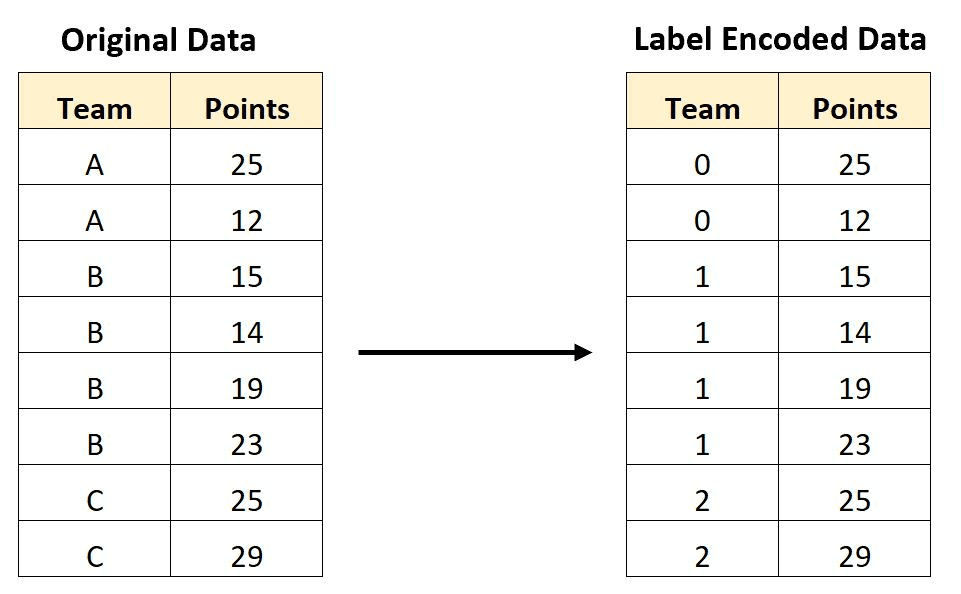
Rotular dados codificados. Fonte da imagem
A codificação one-hot e a codificação de rótulo são técnicas para codificar variáveis categóricas como valores numéricos, mas têm propriedades diferentes e são apropriadas para casos de uso diferentes.
A codificação one-hot representa cada categoria como uma coluna binária, com um 1 indicando a presença da categoria e um 0 indicando sua ausência. Por exemplo, suponha que tenhamos uma variável categórica "cor" com três categorias: "vermelho", "verde" e "azul". A codificação one-hot representaria essa variável como três colunas binárias:
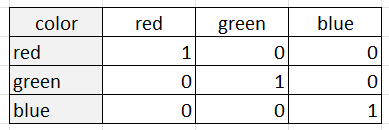
A codificação one-hot é adequada quando as categorias não têm uma ordenação ou relação intrínseca entre si. Isso ocorre porque a codificação one-hot trata cada categoria como uma entidade separada, sem relação com as outras categorias. A codificação one-hot também é útil quando o número de categorias é relativamente pequeno, pois o número de colunas pode se tornar difícil de manejar para um número muito grande de categorias.
A codificação de rótulos, por outro lado, representa cada categoria como um número inteiro exclusivo. Por exemplo, a variável "cor" com três categorias poderia ser codificada como rótulo:
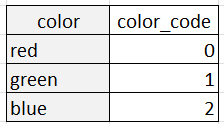
A codificação de rótulos é adequada quando as categorias têm uma ordem ou relação natural entre si, como no caso de variáveis ordinais como "pequeno", "médio" e "grande". Nesses casos, os valores inteiros atribuídos às categorias devem refletir a ordem das categorias. A codificação de rótulos também pode ser útil quando o número de categorias é muito grande, pois reduz a dimensionalidade dos dados.
Em geral, a codificação one-hot é mais comumente usada em aplicativos de aprendizado de máquina, pois é mais flexível e evita os problemas de ambiguidade e ordenação arbitrária que podem surgir com a codificação de rótulos. No entanto, a codificação de rótulos pode ser útil em determinados contextos em que as categorias têm uma ordem natural ou ao lidar com um número muito grande de categorias.
Alta cardinalidade refere-se a um grande número de categorias exclusivas em um recurso categórico. Lidar com alta cardinalidade é um desafio comum na codificação de dados categóricos para modelos de aprendizado de máquina. A alta cardinalidade pode levar a uma representação esparsa dos dados e pode ter um impacto negativo no desempenho de alguns modelos de aprendizado de máquina. Aqui estão algumas técnicas que podem ser usadas para lidar com a alta cardinalidade em recursos categóricos:
Isso envolve a combinação de categorias pouco frequentes em uma única categoria. Isso reduz o número de categorias exclusivas e também reduz a esparsidade na representação dos dados.
A codificação do alvo substitui os valores categóricos pelo valor médio do alvo daquela categoria. Ele fornece uma representação mais contínua dos dados categóricos e pode ajudar a capturar a relação entre o recurso categórico e a variável de destino.
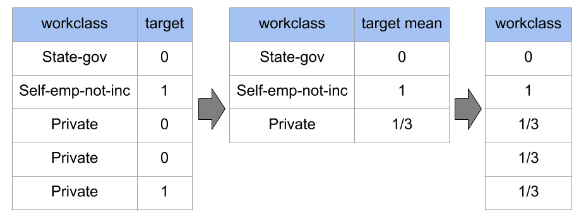
A codificação do Peso da Evidência é semelhante à codificação do alvo, mas leva em conta a distribuição da variável alvo para cada categoria. O WOE de uma categoria é calculado como o logaritmo da proporção da média do alvo para a categoria em relação à média de toda a população.
A engenharia de recursos é uma etapa importante na preparação de dados para modelos de aprendizado de máquina. Isso envolve a criação de novos recursos a partir dos recursos existentes para melhorar o desempenho dos modelos. Aqui estão algumas maneiras de realizar a engenharia de recursos em dados categóricos:
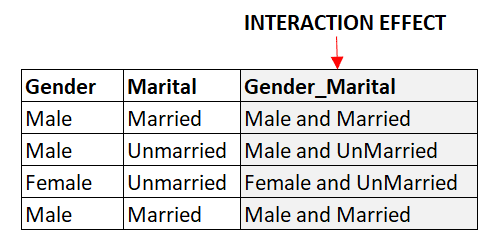
As variáveis de interação são novos recursos criados pela combinação de dois ou mais recursos existentes. Por exemplo, se tivermos dois recursos categóricos, "Gênero" e "Estado Civil", poderemos criar um novo recurso, "Gênero-Estado Civil", para capturar a interação entre os dois recursos. Isso pode ajudar a capturar relações não lineares entre os recursos e a variável-alvo.
Binning é o processo de divisão de variáveis numéricas contínuas em compartimentos discretos. Isso pode ajudar a reduzir o número de valores exclusivos no recurso, o que pode ser benéfico para a codificação de dados categóricos. A classificação também pode ajudar a capturar relações não lineares entre os recursos e a variável-alvo.
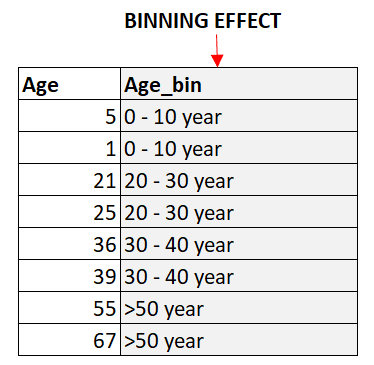
As variáveis cíclicas são variáveis que se repetem em um período específico. Por exemplo, a hora do dia é uma variável cíclica, pois se repete a cada 24 horas. A codificação de variáveis cíclicas pode ajudar a capturar os padrões periódicos nos dados. Uma abordagem comum para codificar variáveis cíclicas é criar dois novos recursos, um representando o seno da variável e o outro representando o cosseno da variável.
O tratamento de dados categóricos é um aspecto importante de muitos projetos de aprendizado de máquina. Neste tutorial, exploramos várias técnicas para analisar e codificar variáveis categóricas em Python, incluindo a codificação de um ponto e a codificação de rótulo, que são duas técnicas comumente usadas.
Começamos introduzindo o conceito de dados categóricos e por que é importante lidar com eles adequadamente nos modelos de aprendizado de máquina. Em seguida, fornecemos um guia passo a passo sobre como realizar a codificação one-hot usando o pandas e o scikit-learn, juntamente com exemplos de código para ilustrar o processo.
Esse tutorial também aborda alguns conceitos avançados, como lidar com dados categóricos de alta cardinalidade, engenharia de recursos, codificação WOE e muito mais. Se você quiser se aprofundar nesse tópico, confira nosso curso Working with Categorical Data in Python.
Se preferir a linguagem R, talvez tenha interesse em nossos cursos, Categorical Data in the Tidyverse ou Inference for Categorical Data in R. Ambos são cursos incríveis para usuários do R.
Saiba mais sobre Python
Curso
Curso
Curso
Tutorial
Avinash Navlani
Tutorial
Moez Ali
