Curso
Manipulação de dados em SQL
4 h
324.1K
No SQL, é comum que os conjuntos de dados não sejam ordenados, o que pode tornar a análise desafiadora. Para entender como as linhas se relacionam em um conjunto de dados, podemos usar a função ROW_NUMBER().
Essa função atribui números sequenciais a linhas em um conjunto de resultados, fornecendo uma ordem clara para manipulação e análise adicionais. Isso pode ser feito para o conjunto de dados como um todo ou para diferentes grupos de dados dentro do conjunto de dados.
Este artigo pressupõe que você tenha conhecimento prévio dos fundamentos do SQL. Abordaremos os conceitos básicos da função ROW_NUMBER() comumente usada e forneceremos exemplos de dificuldade crescente.
ROW_NUMBER() SyntaxAqui está a sintaxe básica da função ROW_NUMBER():
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Vamos detalhar os principais componentes:
ROW_NUMBER(): Essa é a função em si, que gera números de linha sequenciais.OVER (...): Essa cláusula é obrigatória para funções de janela como ROW_NUMBER(). Ele define o contexto no qual os números de linha são calculados.PARTITION BY value_expression: Essa cláusula opcional divide o conjunto de resultados em partições com base na(s) coluna(s) ou expressão(ões) especificada(s). Em seguida, os números de linha são calculados independentemente em cada partição.ORDER BY order_by_clause: Essa cláusula opcional especifica a ordem em que os números de linha são atribuídos em cada partição (ou em todo o conjunto de resultados, se não for usado PARTITION BY ).Para ilustrar, veja como podemos usar ROW_NUMBER() em uma consulta SQL mais ampla:
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() ExemplosNos três exemplos a seguir, usaremos o DataLab IDE gratuito. Usaremos o conjunto de dados de amostra Employees (já incorporado ao DataLab), que tem as quatro colunas a seguir:
first_name: campo de stringlast_name: campo de stringgenderCampo de string com dois valores ("M" ou "F")hire_date: a data em que o funcionário foi contratadoPodemos consultar o conjunto de dados usando o seguinte código SQL:
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output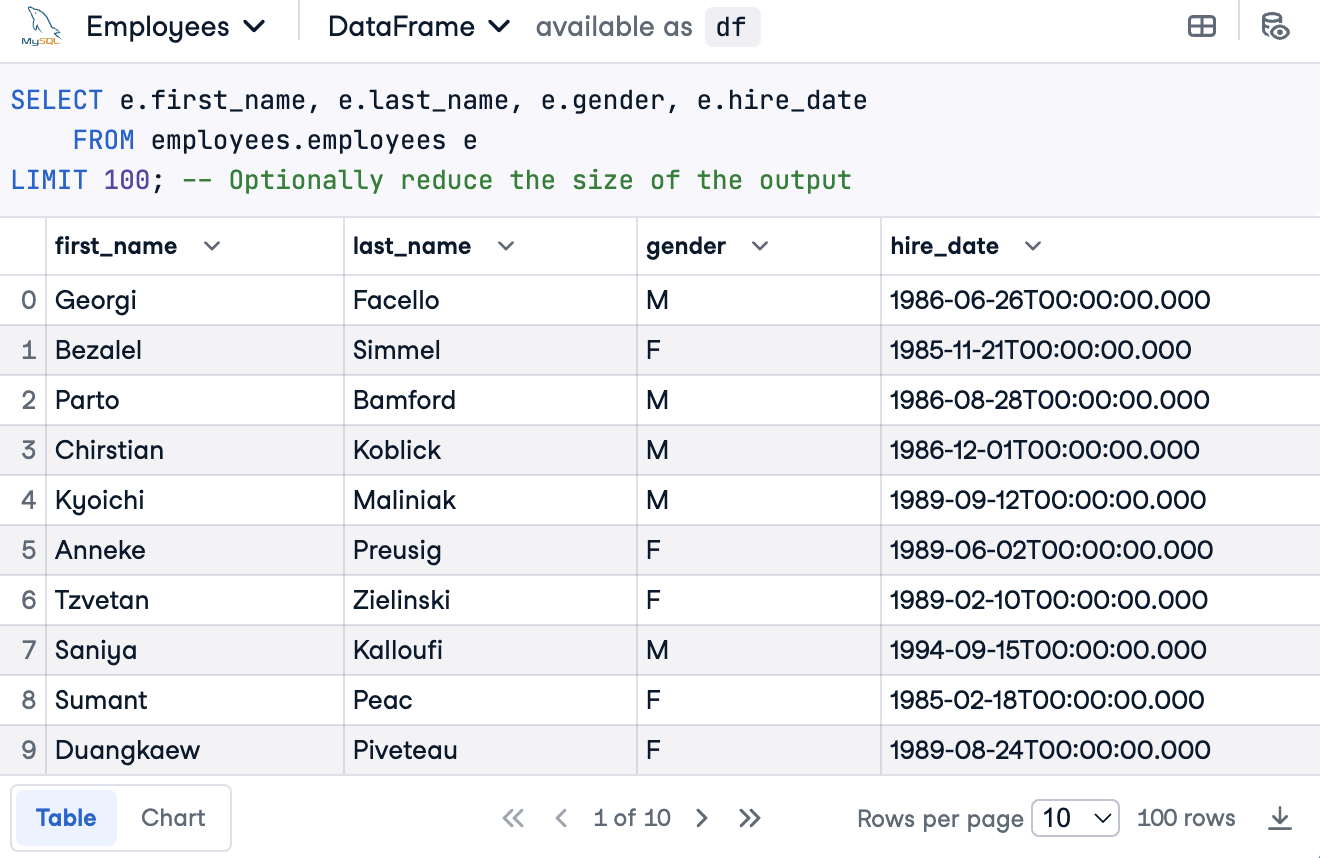
Antes de usar o ROW_NUMBER(), é importante definir nosso objetivo - isso esclarecerá se e como queremos particionar e ordenar. Neste exemplo, gostaríamos de ordenar todos os funcionários em ordem alfabética. Não precisamos de uma cláusula PARTITION BY porque ordenamos todos os funcionários no conjunto de dados. Vamos ordenar os clientes pelo sobrenome (last_name). Daremos um nome à nossa numeração name_row_number.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;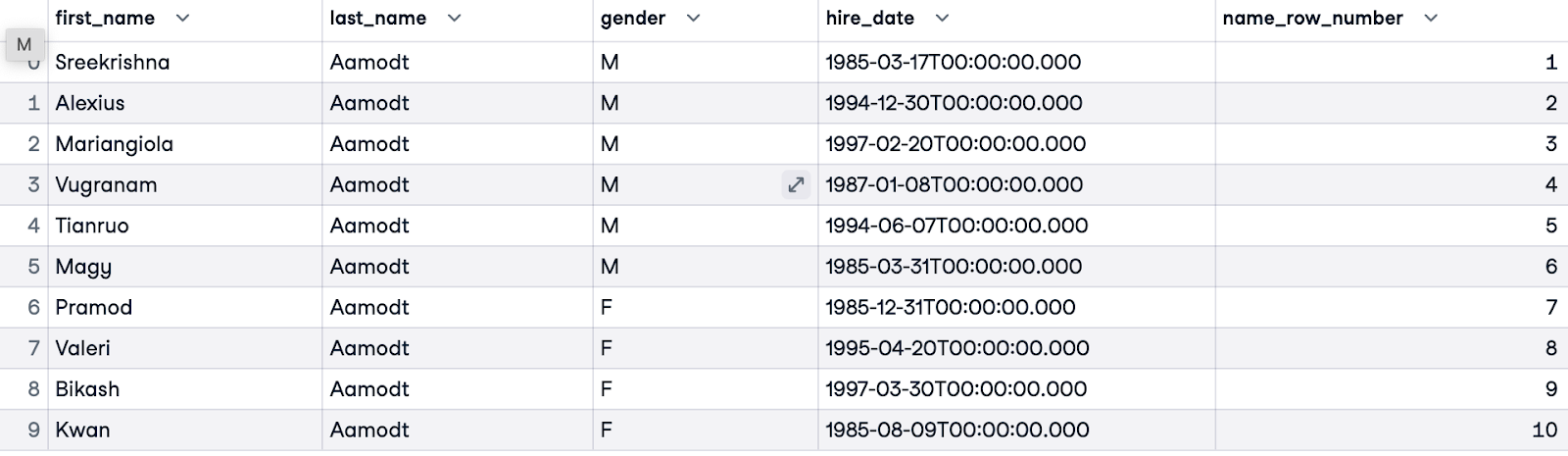
Para lidar com empates (funcionários com o mesmo sobrenome), podemos refinar a ordenação adicionando mais colunas. No exemplo abaixo, ordenamos primeiro por last_name e, em seguida, nos casos em que o sobrenome de um funcionário for igual ao de outra pessoa, ordenaremos pelo primeiro nome (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;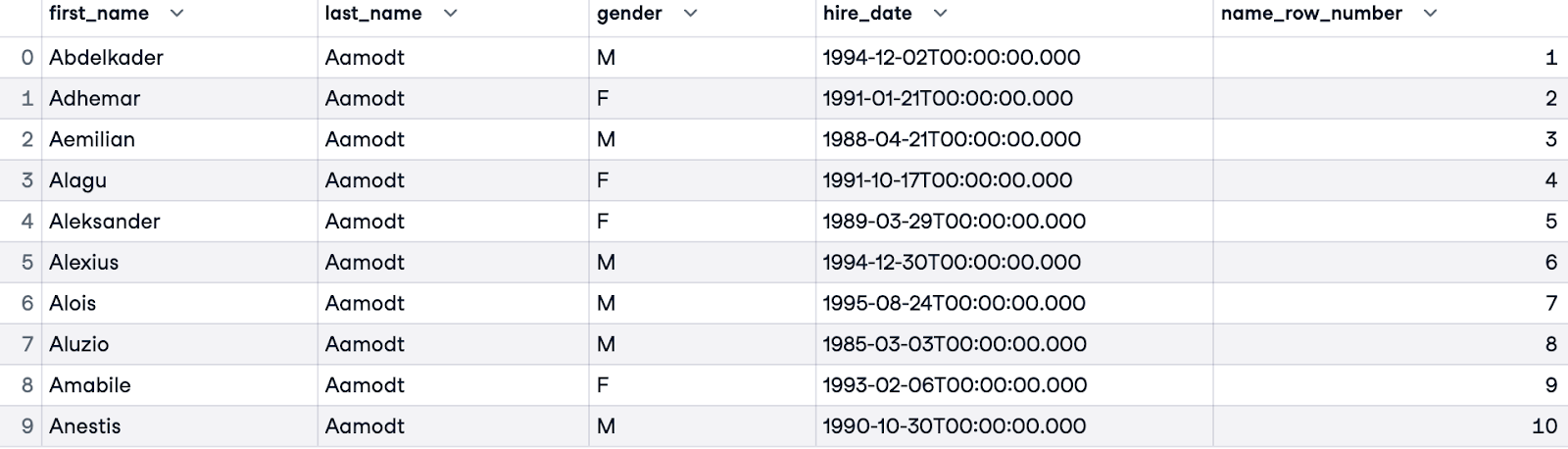
Agora, vamos ordenar os funcionários da data de contratação mais recente para a mais antiga dentro de seus respectivos gêneros. Usaremos novamente a cláusula ORDER BY para classificar por hire_date, mas desta vez em ordem decrescente (usando DESC) para priorizar as contratações mais recentes.
Para obter uma numeração separada para cada gênero, introduziremos a cláusula PARTITION BY gender. Isso significa que os números das linhas serão reiniciados a partir de 1 para cada gênero distinto.
Aqui está a consulta completa:
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;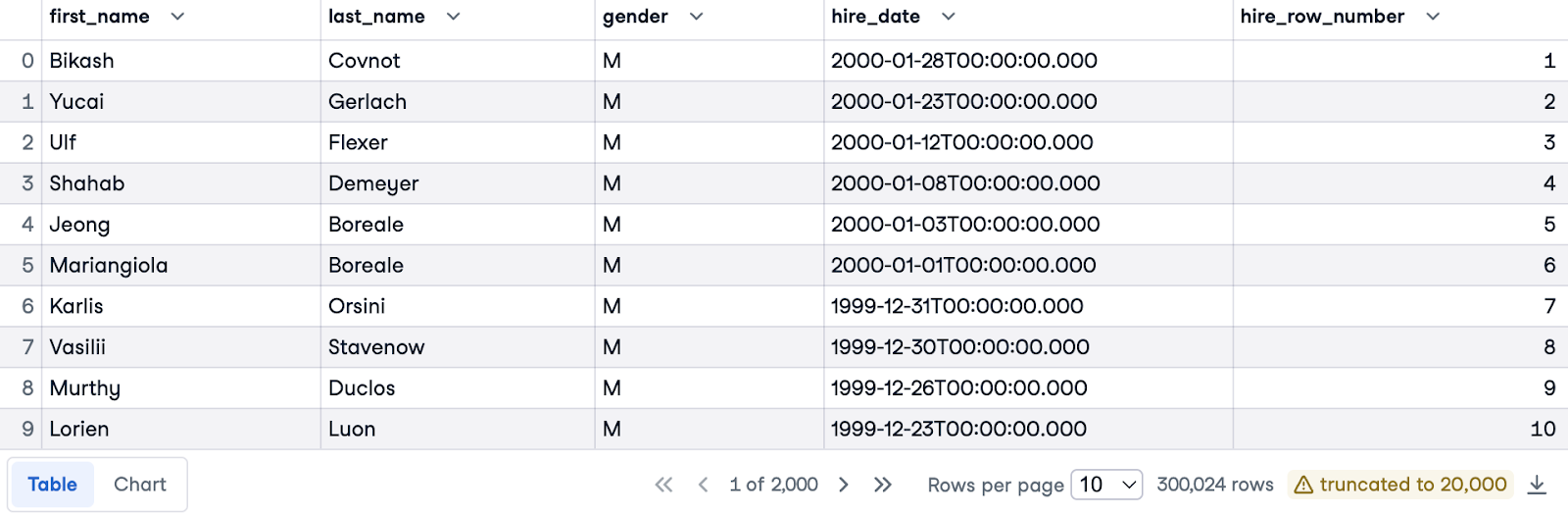
Poderíamos então consultar esses dados usando uma cláusula WHERE para encontrar o funcionário mais experiente em cada gênero:
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
Em nosso exemplo final, classificaremos os funcionários pelo salário, considerando o gênero. Para isso, uniremos a tabela employees com a tabela salaries com base na coluna emp_no:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;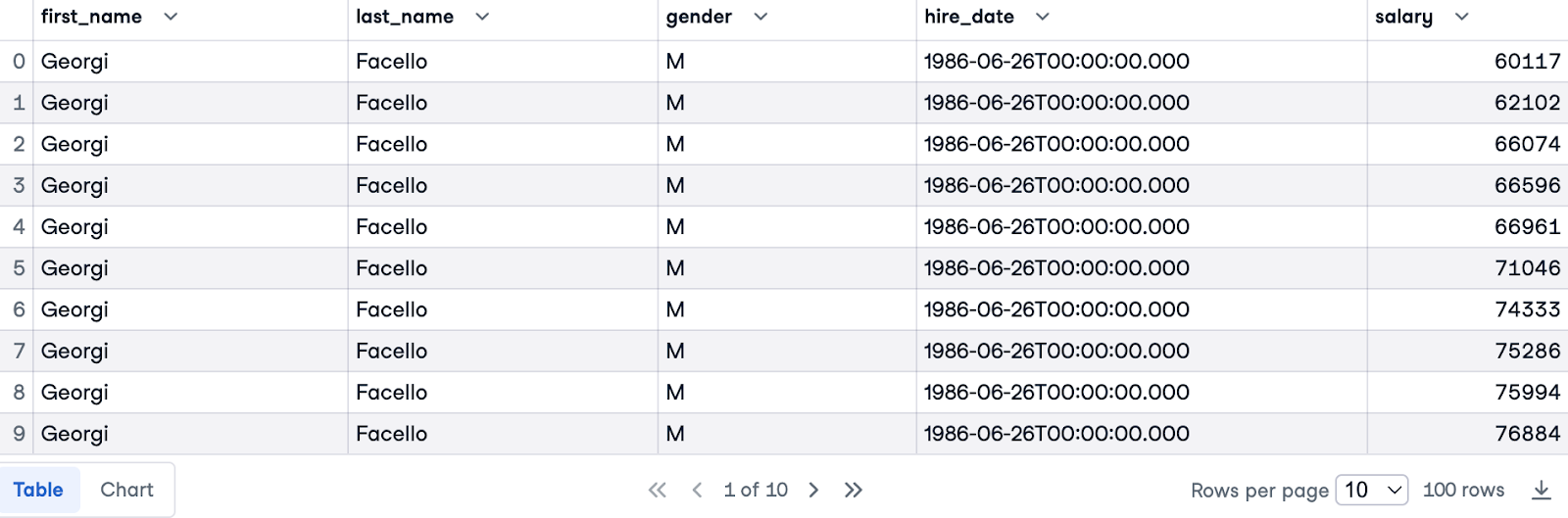
Agora, usaremos os sites PARTITION BY e ORDER BY. Vamos dividir por gender para ter classificações separadas para cada gênero e ordenar por salary em ordem decrescente para classificar os que ganham mais primeiro.
Aqui está a consulta completa:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;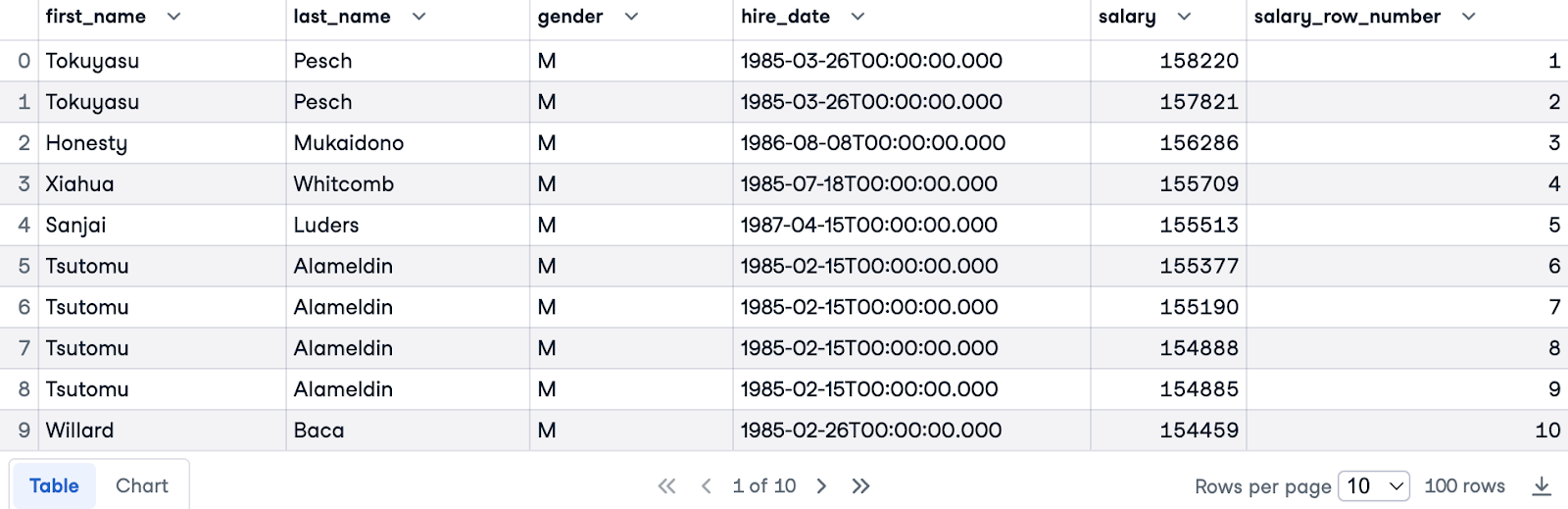
Para comparar os salários mais altos de cada gênero, podemos filtrar os resultados usando uma cláusula WHERE. A consulta abaixo retornará os 5 maiores ganhadores de cada gênero, ordenados por sua classificação dentro do grupo de gênero. Essas consultas podem fornecer informações sobre a igualdade de remuneração no conjunto de dados.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;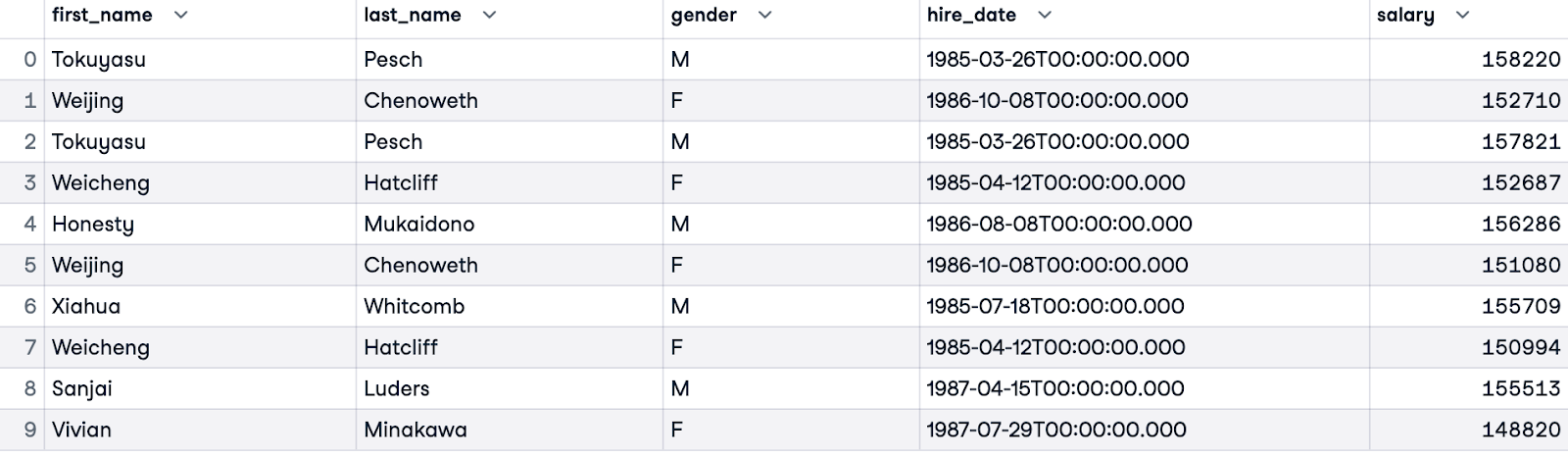
A função ROW_NUMBER() é útil quando temos um conjunto de dados não ordenado e queremos atribuir uma numeração sequencial clara das linhas para análise posterior. Definimos a ordem específica desses números usando ORDER BY e definimos sequências de numeração separadas para grupos distintos dentro dos dados usando PARTITION BY.
Se você achou este artigo útil e quer aprender mais sobre SQL, confira nossos outros cursos de SQL.
Aprenda mais sobre SQL com estes cursos!
Curso
Curso
Curso
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
Travis Tang
Tutorial
DataCamp Team
Tutorial
Travis Tang
Tutorial
DataCamp Team
