Cours
Manipulation de données en SQL
4 h
324.1K
En SQL, il est courant que les ensembles de données ne soient pas ordonnés, ce qui peut compliquer l'analyse. Pour comprendre les relations entre les lignes d'un ensemble de données, nous pouvons utiliser la fonction ROW_NUMBER().
Cette fonction attribue des numéros séquentiels aux lignes d'un ensemble de résultats, ce qui permet d'établir un ordre clair en vue d'une manipulation et d'une analyse ultérieures. Cette opération peut être effectuée pour l'ensemble de l'ensemble de données ou pour différents groupes de données au sein de l'ensemble de données.
Cet article suppose une connaissance préalable des principes fondamentaux de SQL. Nous aborderons les bases de la fonction ROW_NUMBER() couramment utilisée et fournirons des exemples de difficulté croissante.
ROW_NUMBER() SyntaxVoici la syntaxe de base de la fonction ROW_NUMBER():
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Décortiquons les éléments clés :
ROW_NUMBER(): Il s'agit de la fonction elle-même, qui génère des numéros de ligne séquentiels.OVER (...): Cette clause est obligatoire pour les fonctions de fenêtre telles que ROW_NUMBER(). Il définit le contexte dans lequel les numéros de ligne sont calculés.PARTITION BY value_expression: Cette clause facultative divise l'ensemble des résultats en partitions sur la base de la ou des colonnes ou expressions spécifiées. Les numéros de ligne sont ensuite calculés indépendamment au sein de chaque partition.ORDER BY order_by_clause: Cette clause facultative spécifie l'ordre dans lequel les numéros de ligne sont attribués dans chaque partition (ou dans l'ensemble des résultats si aucune adresse PARTITION BY n'est utilisée).Pour illustrer ce propos, voici comment nous pourrions utiliser ROW_NUMBER() dans le cadre d'une requête SQL plus large :
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() ExemplesDans les trois exemples suivants, nous utiliserons l'IDE gratuit DataLab. Nous utiliserons l'échantillon de données Employés (déjà intégré dans DataLab), qui comporte les quatre colonnes suivantes :
first_name: champ de type chaîne de caractèreslast_name: champ de type chaîne de caractèresgenderchamp de type string avec deux valeurs ("M" ou "F")hire_datela date d'embauche de l'employéNous pouvons interroger l'ensemble de données à l'aide du code SQL suivant :
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output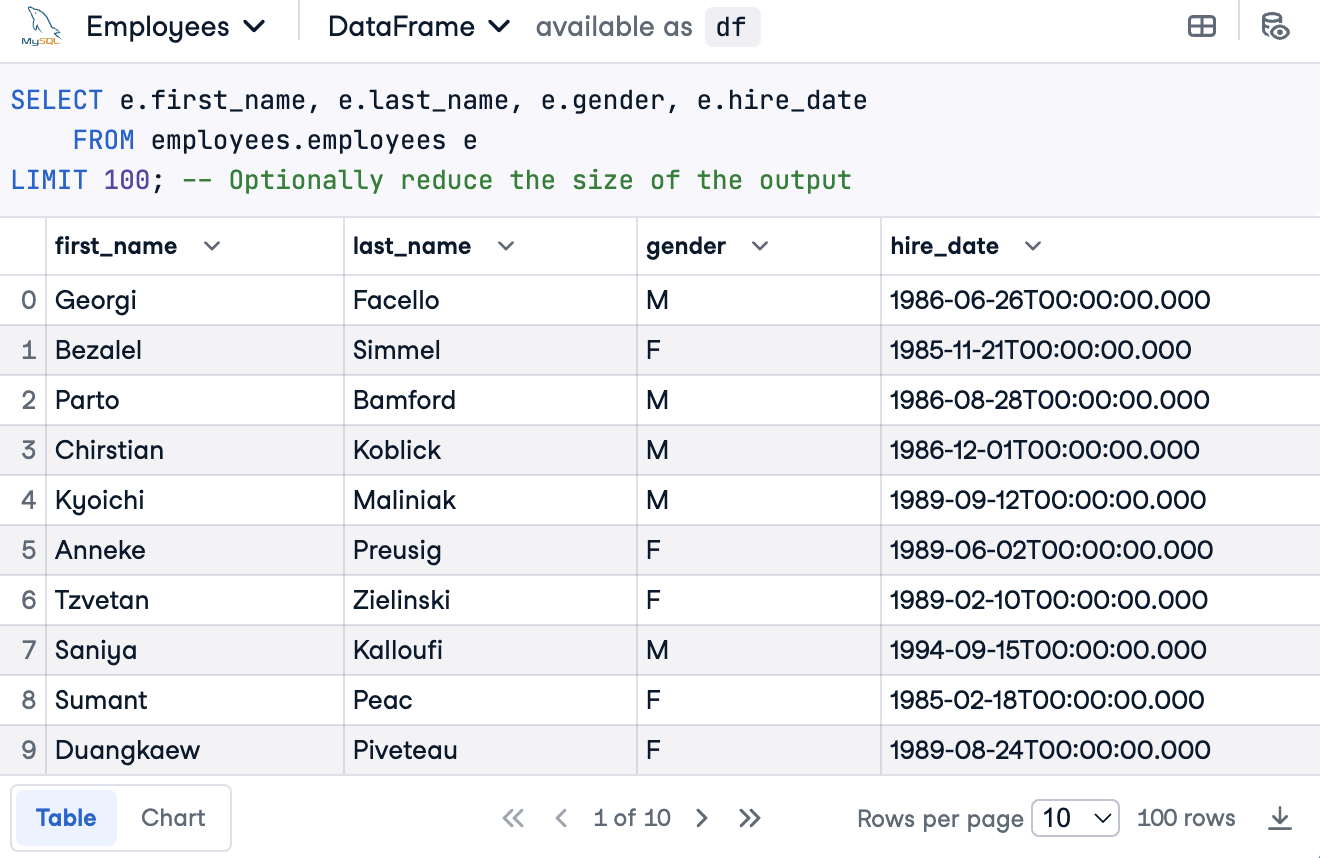
Avant d'utiliser ROW_NUMBER(), il est important de définir notre objectif - cela permettra de savoir si et comment nous voulons partitionner et ordonner. Dans cet exemple, nous souhaitons classer tous les employés par ordre alphabétique. Nous n'avons pas besoin d'une clause PARTITION BY car nous classons tous les employés dans l'ensemble de données. Nous classerons les clients par leur nom de famille (last_name). Nous appellerons notre numérotation name_row_number.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;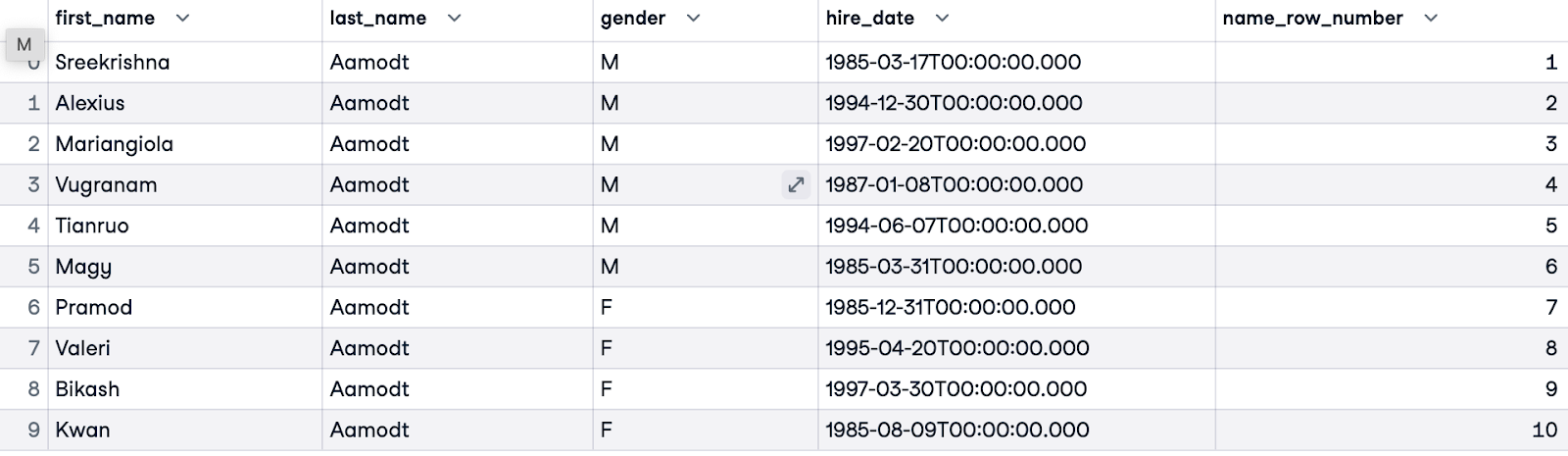
Pour gérer les liens (employés ayant le même nom de famille), nous pouvons affiner l'ordre en ajoutant des colonnes supplémentaires. Dans l'exemple ci-dessous, nous classons d'abord par last_name, puis, dans les cas où le nom de famille d'un employé est le même que celui d'une autre personne, nous classons par son prénom (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;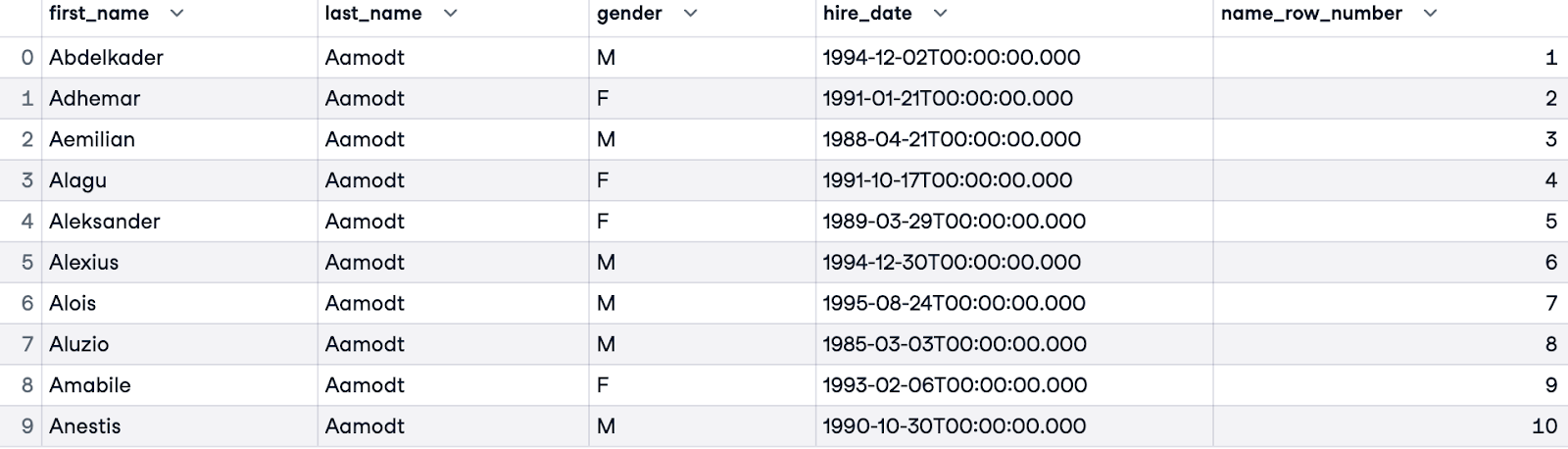
Classons maintenant les salariés par ordre de date d'embauche, du plus récent au plus ancien, en fonction de leur sexe respectif. Nous utiliserons à nouveau la clause ORDER BY pour trier par hire_date, mais cette fois par ordre décroissant (en utilisant DESC) pour donner la priorité aux embauches les plus récentes.
Pour obtenir une numérotation distincte pour chaque sexe, nous introduirons la clause PARTITION BY gender. Cela signifie que les numéros de ligne recommenceront à partir de 1 pour chaque sexe distinct.
Voici la requête complète :
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;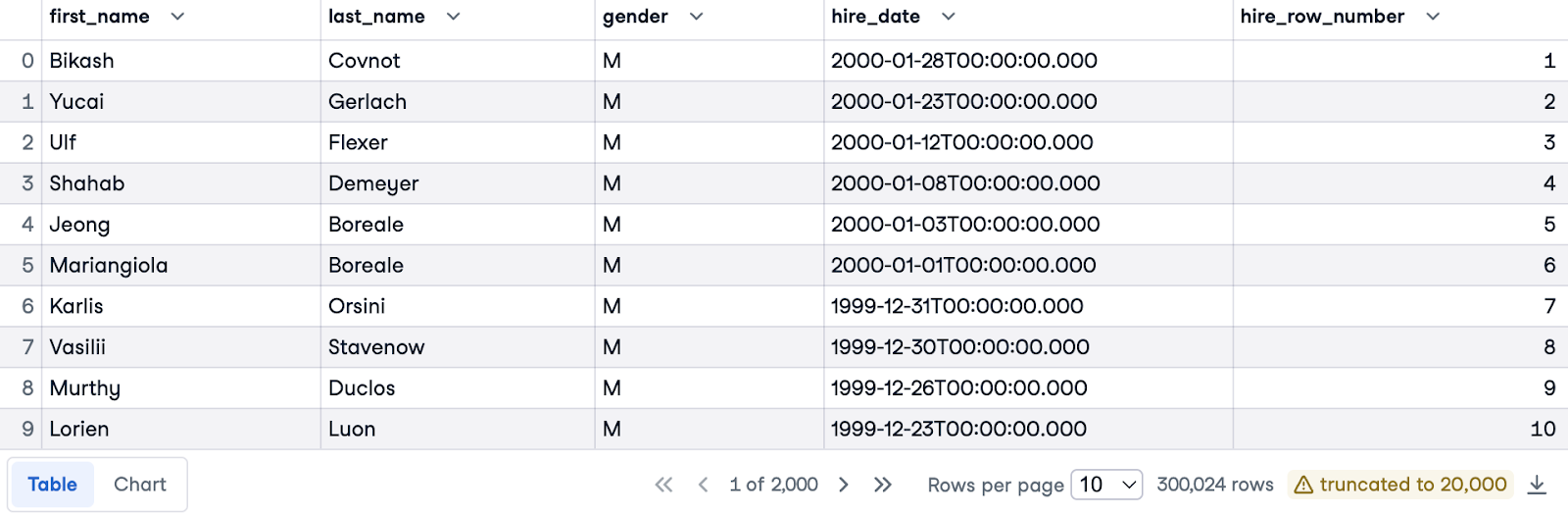
Nous pouvons ensuite interroger ces données à l'aide d'une clause WHERE pour trouver l'employé le plus expérimenté dans chaque sexe :
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
Dans notre dernier exemple, nous classerons les employés selon leur salaire, en tenant compte de leur sexe. Pour ce faire, nous joindrons le tableau employees au tableau salaries sur la base de la colonne emp_no:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;
Nous allons maintenant utiliser PARTITION BY et ORDER BY. Nous diviserons les données par gender afin d'obtenir des classements distincts pour chaque sexe et nous classerons les données par salary dans l'ordre décroissant afin de classer en premier les personnes qui gagnent le plus.
Voici la requête complète :
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;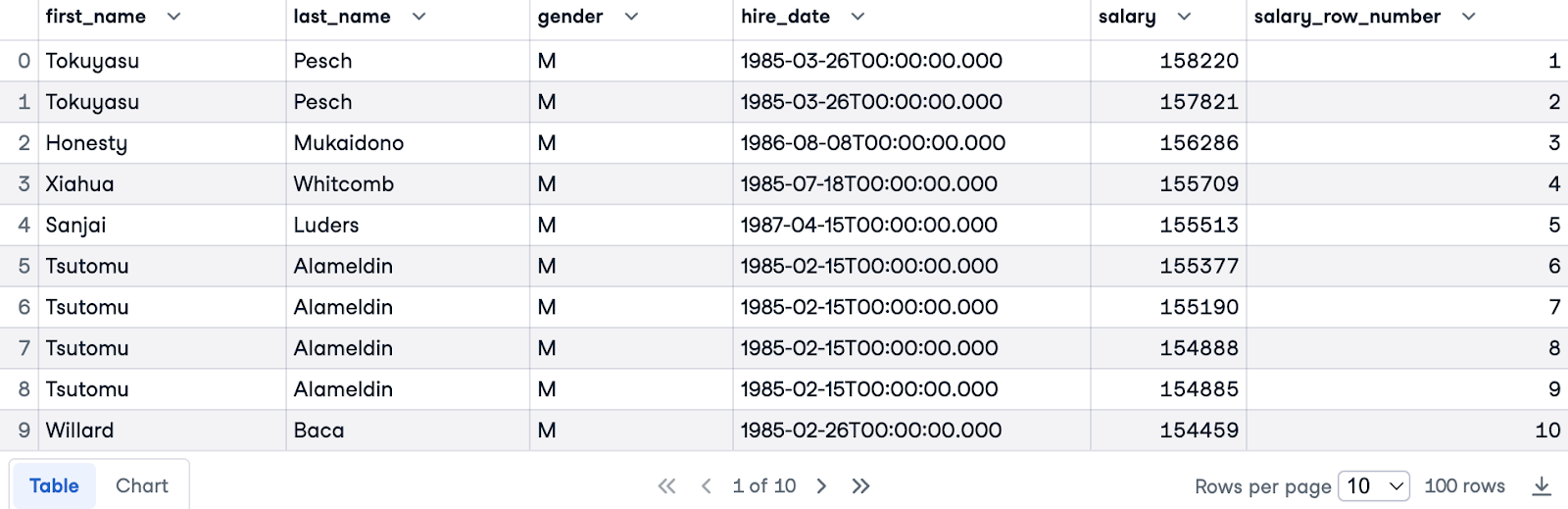
Pour comparer les salaires les plus élevés pour chaque sexe, nous pouvons filtrer les résultats à l'aide d'une clause WHERE. La requête ci-dessous renvoie les 5 premiers salaires pour chaque sexe, classés par ordre d'importance au sein de leur groupe. Ces requêtes peuvent fournir des informations sur l'équité salariale au sein de l'ensemble de données.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;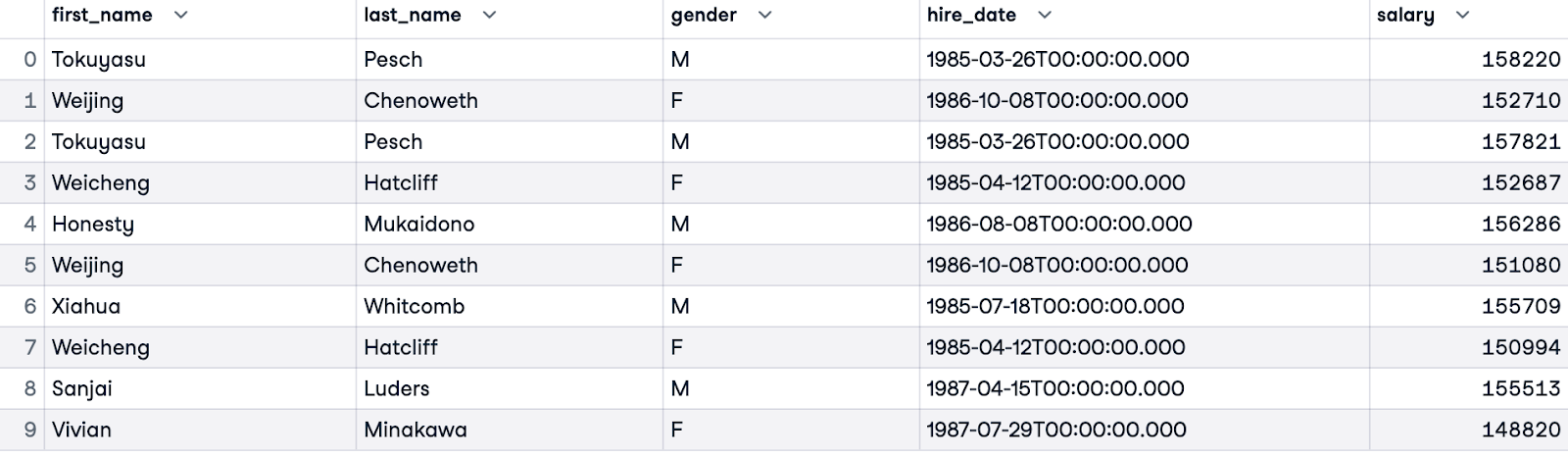
La fonction ROW_NUMBER() est utile lorsque nous disposons d'un ensemble de données non ordonné et que nous souhaitons attribuer une numérotation séquentielle claire aux lignes en vue d'une analyse ultérieure. Nous définissons l'ordre spécifique de ces numéros à l'aide de ORDER BY et nous définissons des séquences de numérotation distinctes pour des groupes distincts au sein des données à l'aide de PARTITION BY.
Si cet article vous a été utile et que vous souhaitez en savoir plus sur le langage SQL, consultez nos autres cours sur le langage SQL.
Apprenez-en plus sur SQL avec ces cours !
Cours
Cours
Cours
Tutoriel
DataCamp Team
Tutoriel
Allan Ouko
Tutoriel
Aditya Sharma
Tutoriel
Allan Ouko
Tutoriel
Sejal Jaiswal
Tutoriel
Laiba Siddiqui

