Kurs
Datenbearbeitung in SQL
4 Std.
324.1K
In SQL ist es üblich, dass Datensätze ungeordnet sind, was die Analyse erschweren kann. Um zu verstehen, wie Zeilen innerhalb eines Datensatzes zusammenhängen, können wir die Funktion ROW_NUMBER() verwenden.
Diese Funktion weist den Zeilen innerhalb einer Ergebnismenge fortlaufende Nummern zu und sorgt so für eine klare Reihenfolge bei der weiteren Bearbeitung und Analyse. Dies kann für den gesamten Datensatz oder für verschiedene Gruppen von Daten innerhalb des Datensatzes geschehen.
In diesem Artikel werden Vorkenntnisse über die Grundlagen von SQL vorausgesetzt. Wir werden die Grundlagen der häufig verwendeten Funktion ROW_NUMBER() behandeln und Beispiele mit steigendem Schwierigkeitsgrad geben.
ROW_NUMBER() SyntaxHier ist die grundlegende Syntax für die Funktion ROW_NUMBER():
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Schauen wir uns die wichtigsten Komponenten an:
ROW_NUMBER(): Dies ist die Funktion selbst, die fortlaufende Zeilennummern erzeugt.OVER (...): Diese Klausel ist obligatorisch für Fensterfunktionen wie ROW_NUMBER(). Sie definiert den Kontext, in dem die Zeilennummern berechnet werden.PARTITION BY value_expression: Diese optionale Klausel teilt die Ergebnismenge anhand der angegebenen Spalte(n) oder des Ausdrucks/der Ausdrücke in Partitionen ein. Die Zeilennummern werden dann innerhalb jeder Partition unabhängig voneinander berechnet.ORDER BY order_by_clause: Diese optionale Klausel legt die Reihenfolge fest, in der die Zeilennummern innerhalb jeder Partition (oder der gesamten Ergebnismenge, wenn keine PARTITION BY verwendet wird) vergeben werden.Zur Veranschaulichung sehen wir hier, wie wir ROW_NUMBER() innerhalb einer breiteren SQL-Abfrage verwenden können:
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() BeispieleIn den folgenden drei Beispielen verwenden wir die kostenlose DataLab IDE. Wir verwenden den Beispieldatensatz Arbeitnehmer (der bereits in DataLab enthalten ist), der die folgenden vier Spalten enthält:
first_name: String-Feldlast_name: String-Feldgender: Stringfeld mit zwei Werten ("M" oder "F")hire_date: das Datum, an dem der Arbeitnehmer eingestellt wurdeWir können den Datensatz mit folgendem SQL-Code abfragen:
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output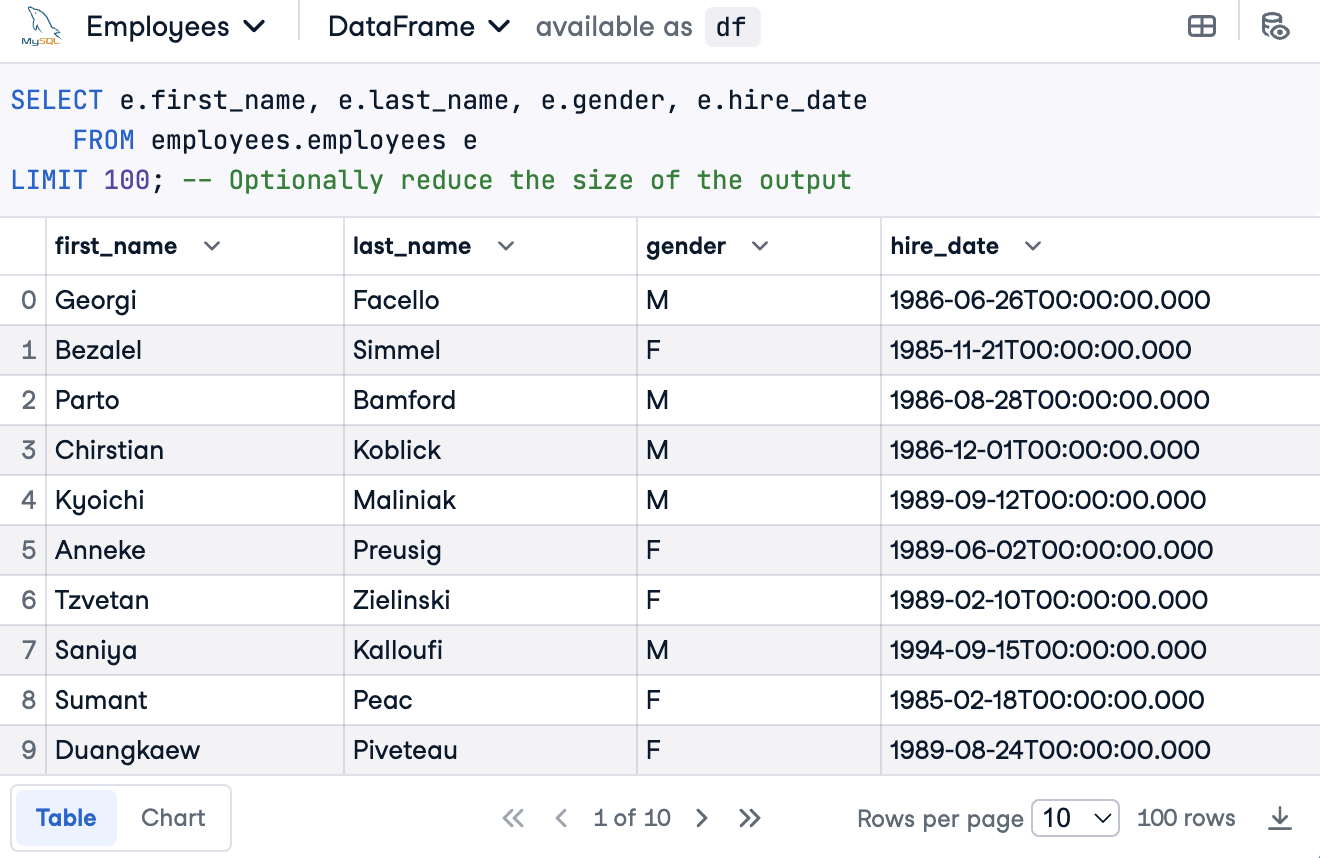
Bevor du ROW_NUMBER() verwendest, ist es wichtig, unser Ziel zu definieren - so wird klar, ob und wie wir aufteilen und ordnen wollen. In diesem Beispiel möchten wir alle Mitarbeiter alphabetisch ordnen. Wir brauchen keine PARTITION BY Klausel, weil wir alle Mitarbeiter im Datensatz ordnen. Wir ordnen die Kunden nach ihrem Nachnamen (last_name). Wir werden unsere Nummerierung name_row_number nennen.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;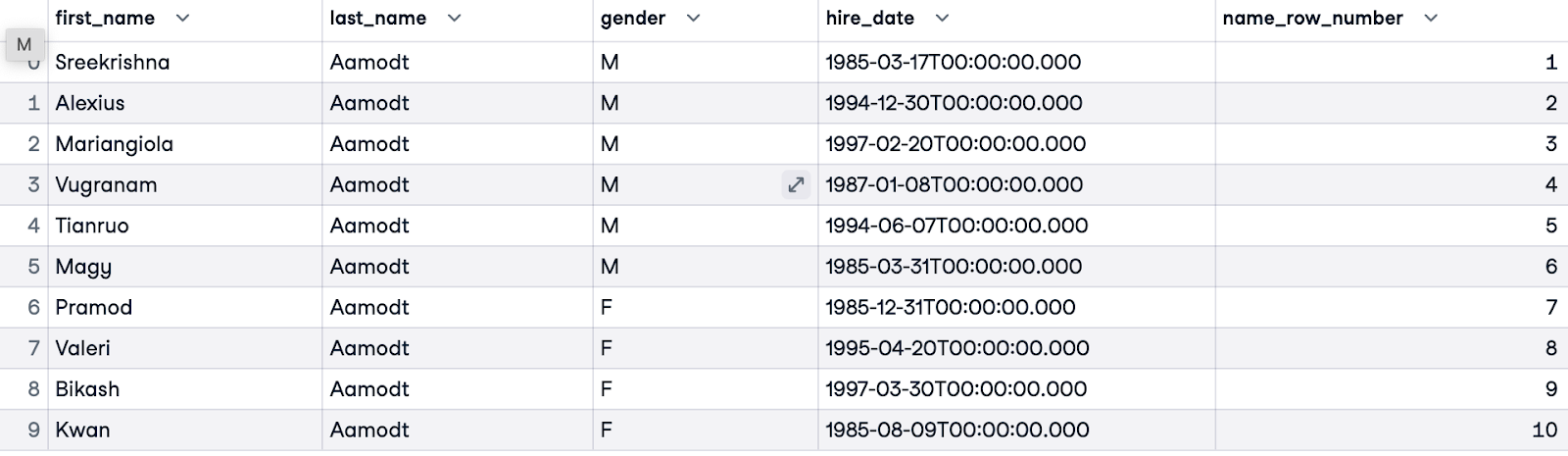
Um Gleichheiten (Mitarbeiter mit demselben Nachnamen) zu behandeln, können wir die Reihenfolge verfeinern, indem wir weitere Spalten hinzufügen. Im folgenden Beispiel ordnen wir zuerst nach last_name und dann, wenn der Nachname eines Mitarbeiters mit dem einer anderen Person identisch ist, nach dem Vornamen (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;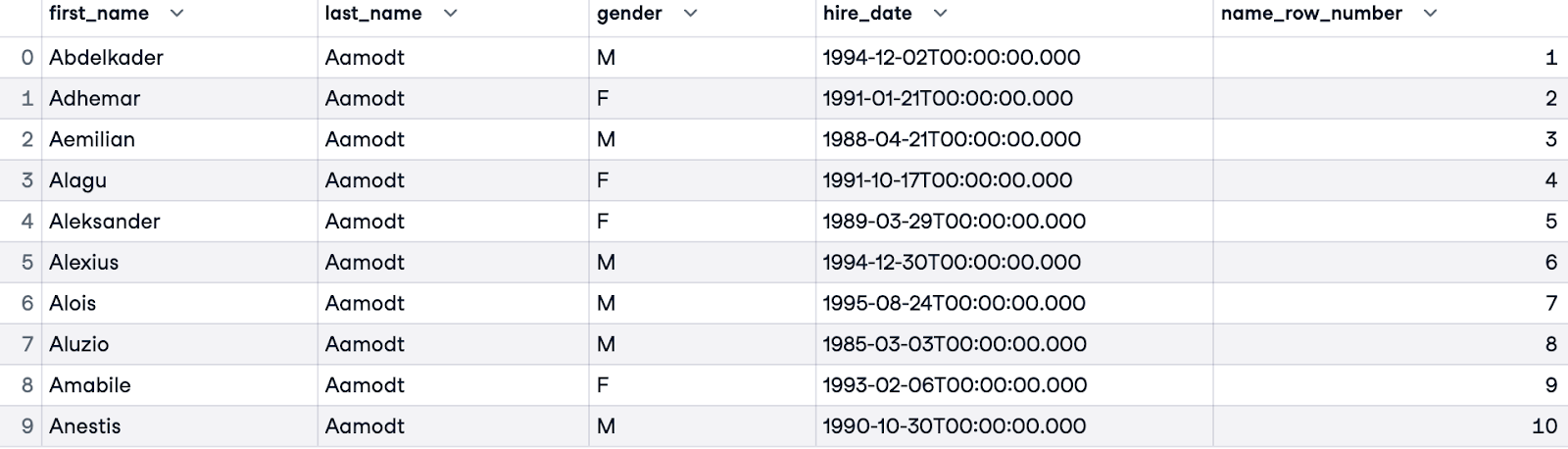
Jetzt ordnen wir die Mitarbeiter nach dem neuesten und ältesten Einstellungsdatum innerhalb ihres jeweiligen Geschlechts. Wir verwenden wieder die ORDER BY Klausel, um nach hire_date zu sortieren, aber dieses Mal in absteigender Reihenfolge (mit DESC), um die jüngsten Einstellungen zu priorisieren.
Um eine getrennte Nummerierung für jedes Geschlecht zu erreichen, führen wir die PARTITION BY gender Klausel ein. Das bedeutet, dass die Zeilennummern für jedes unterschiedliche Geschlecht wieder bei 1 beginnen.
Hier ist die vollständige Abfrage:
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;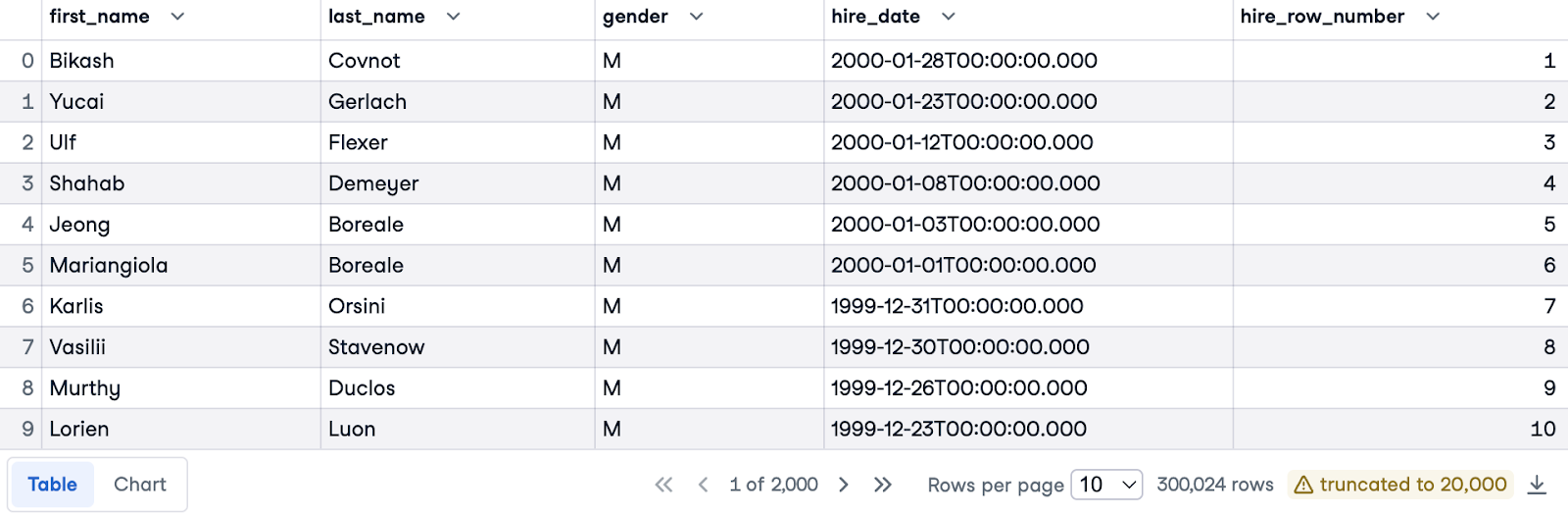
Wir könnten diese Daten dann mit einer WHERE Klausel abfragen, um den erfahrensten Arbeitnehmer in jedem Geschlecht zu finden:
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
In unserem letzten Beispiel ordnen wir die Mitarbeiter nach ihrem Gehalt ein und berücksichtigen dabei ihr Geschlecht. Dazu verknüpfen wir die Tabelle employees mit der Tabelle salaries über die Spalte emp_no:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;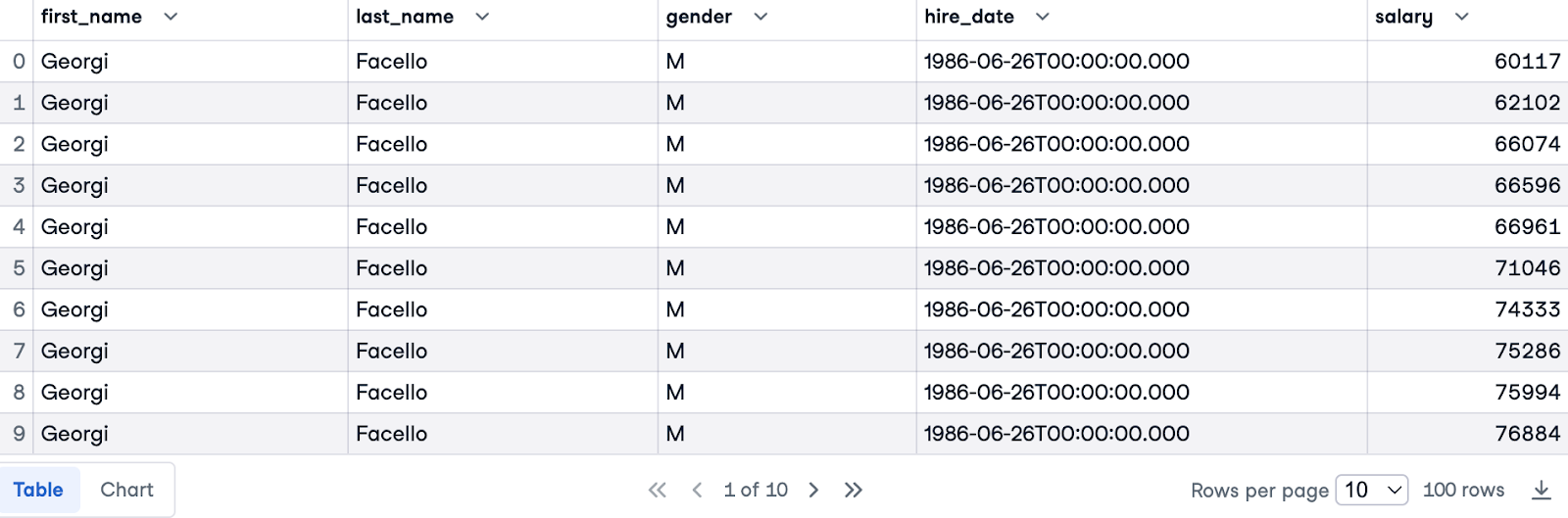
Jetzt werden wir sowohl PARTITION BY als auch ORDER BY verwenden. Wir teilen nach gender auf, um getrennte Ranglisten für jedes Geschlecht zu erhalten, und ordnen nach salary in absteigender Reihenfolge, um die Spitzenverdiener zuerst zu nennen.
Hier ist die vollständige Abfrage:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;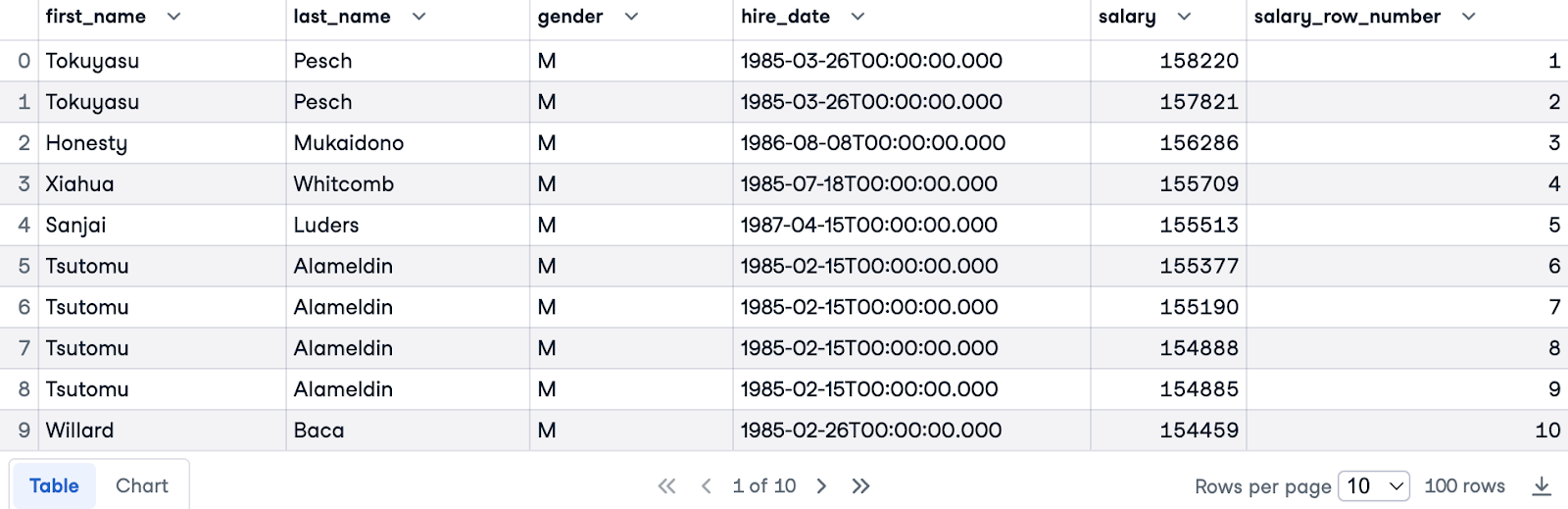
Um die Spitzengehälter für jedes Geschlecht zu vergleichen, können wir die Ergebnisse mit einer WHERE Klausel filtern. Die folgende Abfrage liefert die 5 Spitzenverdiener für jedes Geschlecht, geordnet nach ihrem Rang innerhalb ihrer Geschlechtergruppe. Solche Abfragen können Einblicke in die Lohngerechtigkeit innerhalb des Datensatzes geben.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;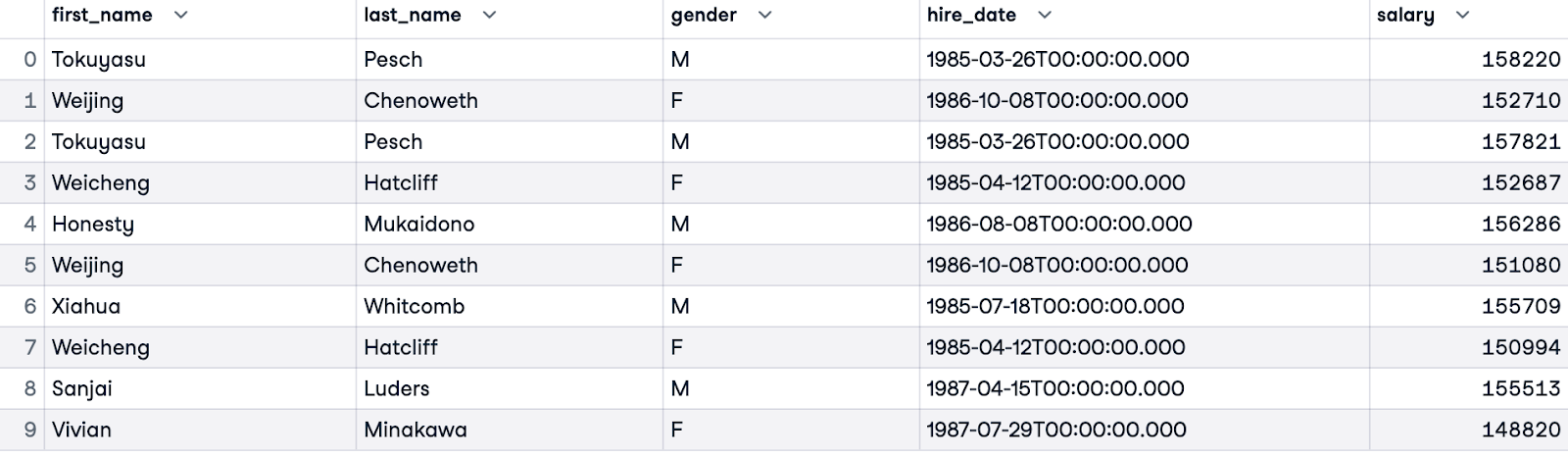
Die Funktion ROW_NUMBER() ist nützlich, wenn wir einen ungeordneten Datensatz haben und den Zeilen eine eindeutige fortlaufende Nummerierung für die weitere Analyse zuweisen wollen. Wir legen die Reihenfolge dieser Nummern mit ORDER BY fest und definieren separate Nummerierungssequenzen für verschiedene Gruppen innerhalb der Daten mit PARTITION BY.
Wenn du diesen Artikel nützlich fandest und mehr über SQL lernen möchtest, schau dir unsere anderen SQL-Kurse an.
Lerne mehr über SQL mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
Allan Ouko
Tutorial
Aditya Sharma
Tutorial
Laiba Siddiqui
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
DataCamp Team

