Course
Data Manipulation in SQL
4 hr
324.1K
In SQL, it’s common for datasets to be unordered, which can make the analysis challenging. To understand how rows relate within a dataset, we can use the ROW_NUMBER() function.
This function assigns sequential numbers to rows within a result set, providing a clear order for further manipulation and analysis. This can be done for the dataset as a whole or for different groups of data within the dataset.
This article assumes prior knowledge of the fundamentals of SQL. We’ll cover the basics of the commonly used ROW_NUMBER() function and provide examples of increasing difficulty.
ROW_NUMBER() SyntaxHere's the basic syntax for the ROW_NUMBER() function:
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Let's break down the key components:
ROW_NUMBER(): This is the function itself, which generates sequential row numbers.OVER (...): This clause is mandatory for window functions like ROW_NUMBER(). It defines the context in which row numbers are calculated.PARTITION BY value_expression: This optional clause divides the result set into partitions based on the specified column(s) or expression(s). Row numbers are then calculated independently within each partition.ORDER BY order_by_clause: This optional clause specifies the order in which row numbers are assigned within each partition (or the entire result set if no PARTITION BY is used).To illustrate, here's how we might use ROW_NUMBER() within a broader SQL query:
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() ExamplesIn the following three examples, we’ll use the free DataLab IDE. We’ll use the Employees sample dataset (already incorporated into DataLab), which has the following four columns:
first_name: string fieldlast_name: string fieldgender: string field with two values (“M” or “F”)hire_date: the date the employee was hiredWe can query the dataset using the following SQL code:
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output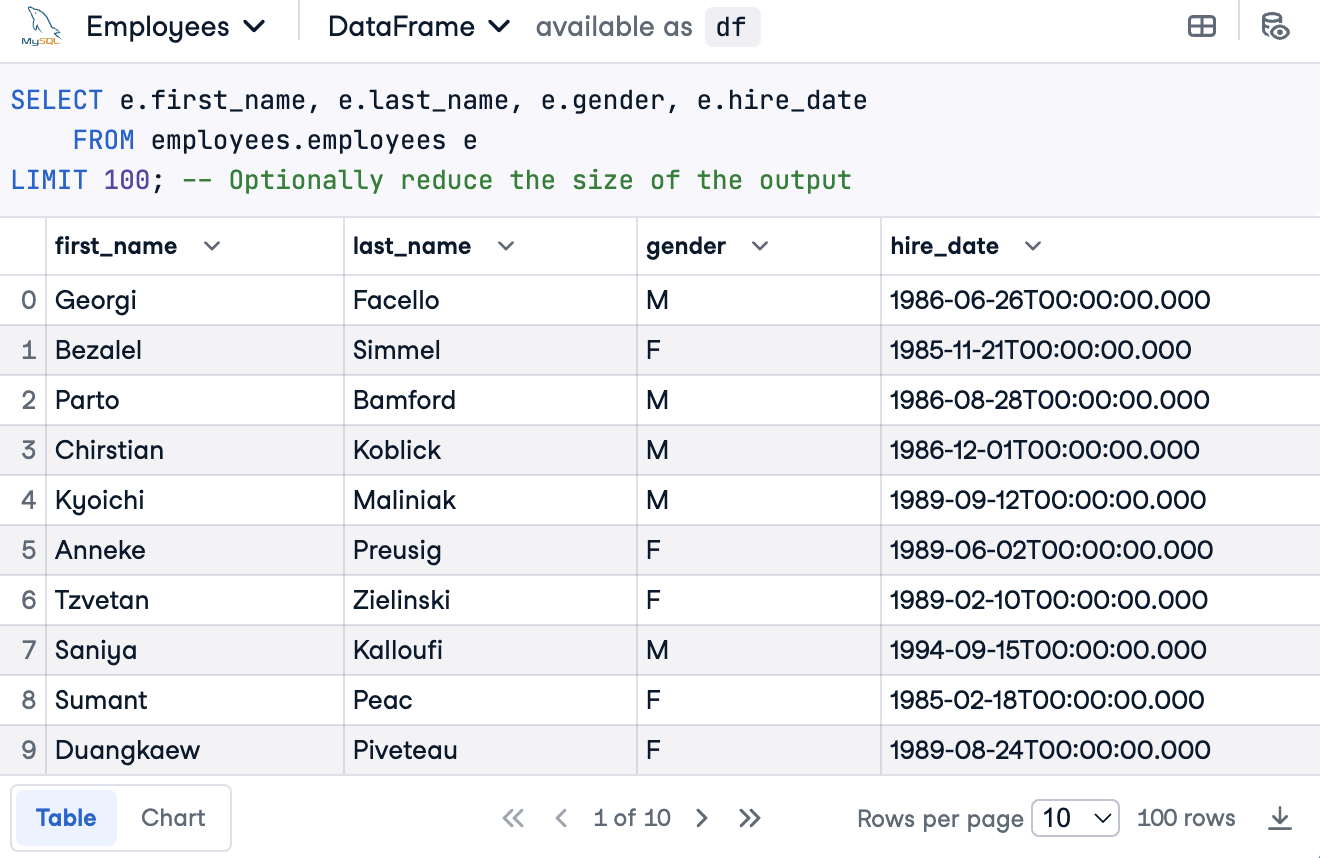
Before using ROW_NUMBER(), it's important to define our goal—this will clarify if and how we want to partition and order. In this example, we’d like to order all employees alphabetically. We don’t need a PARTITION BY clause because we order all employees in the dataset. We’ll order customers by their last name (last_name). We’ll name our numbering name_row_number.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;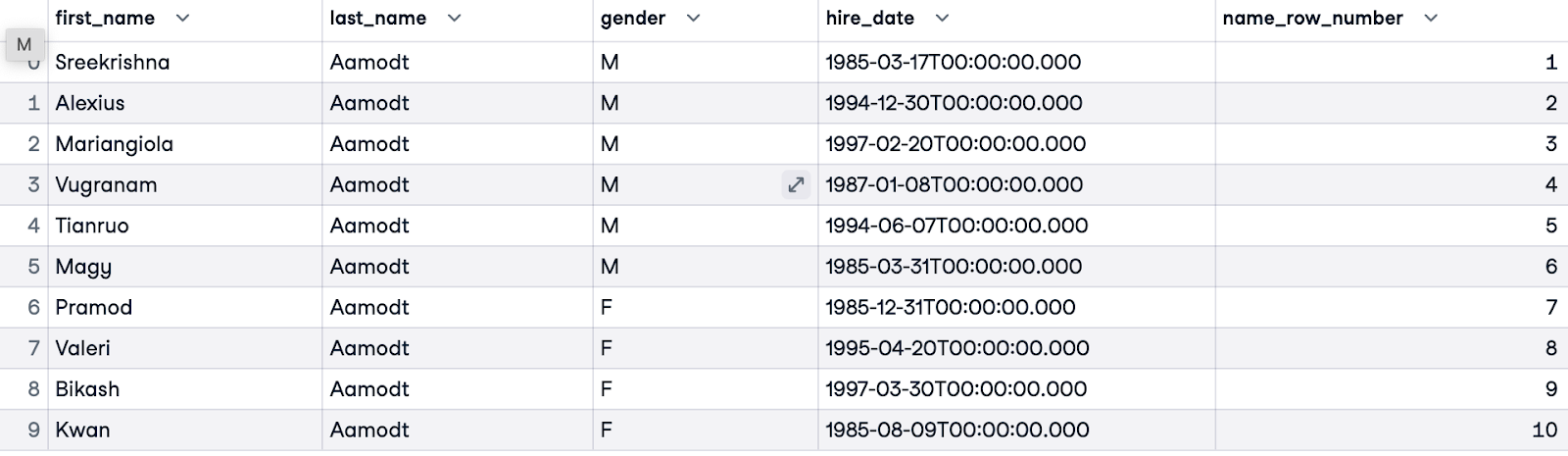
To handle ties (employees with the same last name), we can refine the ordering by adding more columns. In the example below, we order first by last_name, and then, in cases where an employee’s last name is the same as someone else's, we’ll order by their first name (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;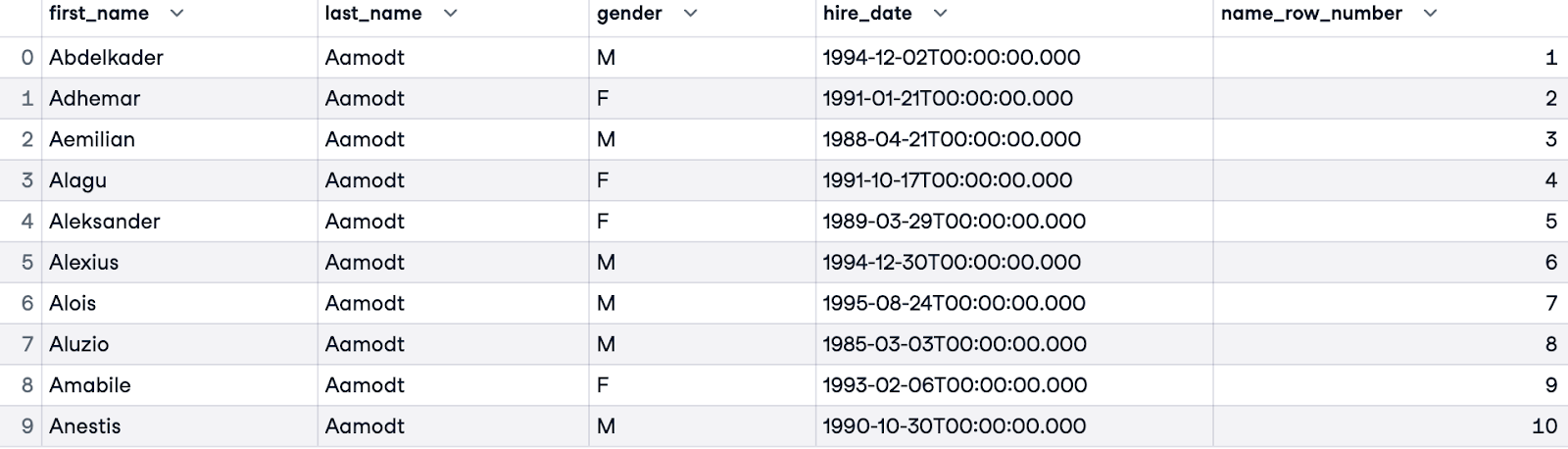
Now, let's order employees from newest to oldest hire date within their respective genders. We'll again use the ORDER BY clause to sort by hire_date, but this time in descending order (using DESC) to prioritize the most recent hires.
To achieve separate numbering for each gender, we'll introduce the PARTITION BY gender clause. This means row numbers will restart from 1 for each distinct gender.
Here's the complete query:
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;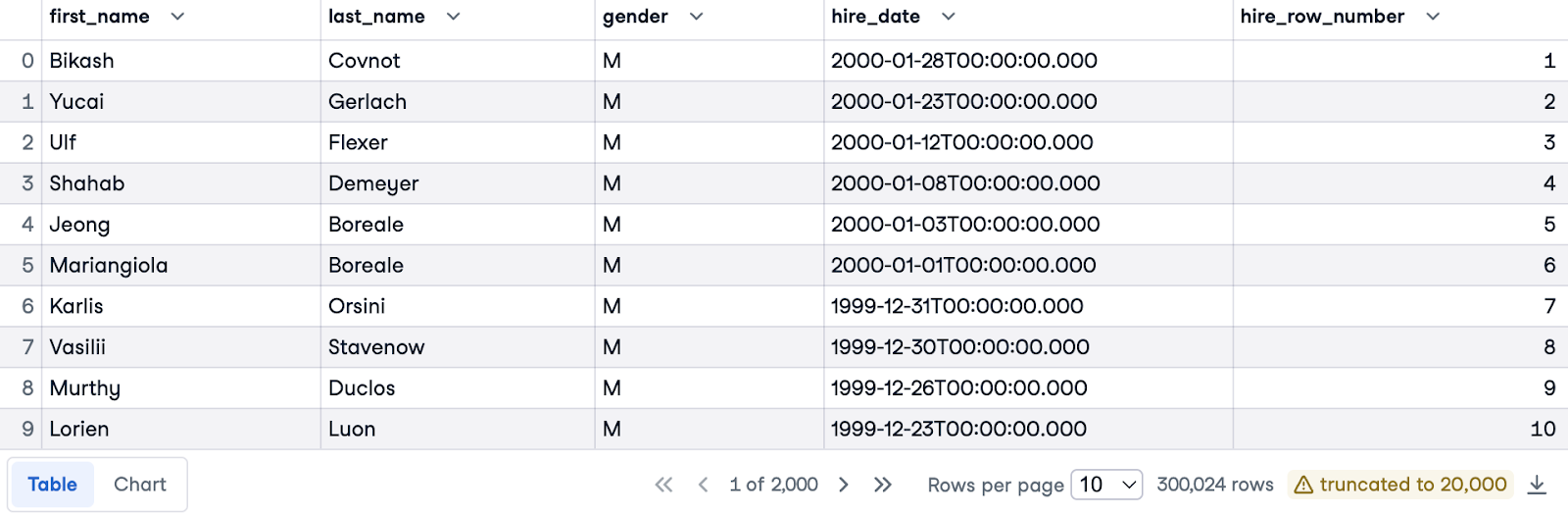
We could then query this data using a WHERE clause to find the most experienced employee in each gender:
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
In our final example, we'll rank employees by their salary, considering their gender. To achieve this, we'll join the employees table with the salaries table based on the emp_no column:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;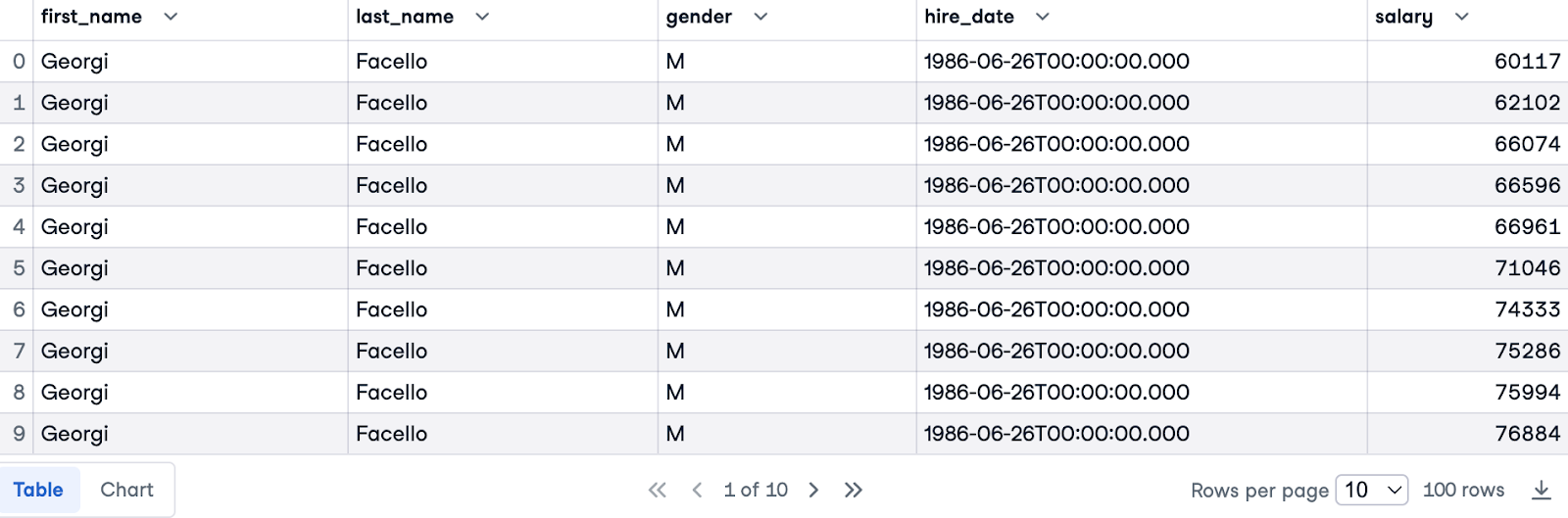
Now, we'll use both PARTITION BY and ORDER BY. We'll partition by gender to have separate rankings for each gender and order by salary in descending order to rank the highest earners first.
Here's the complete query:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;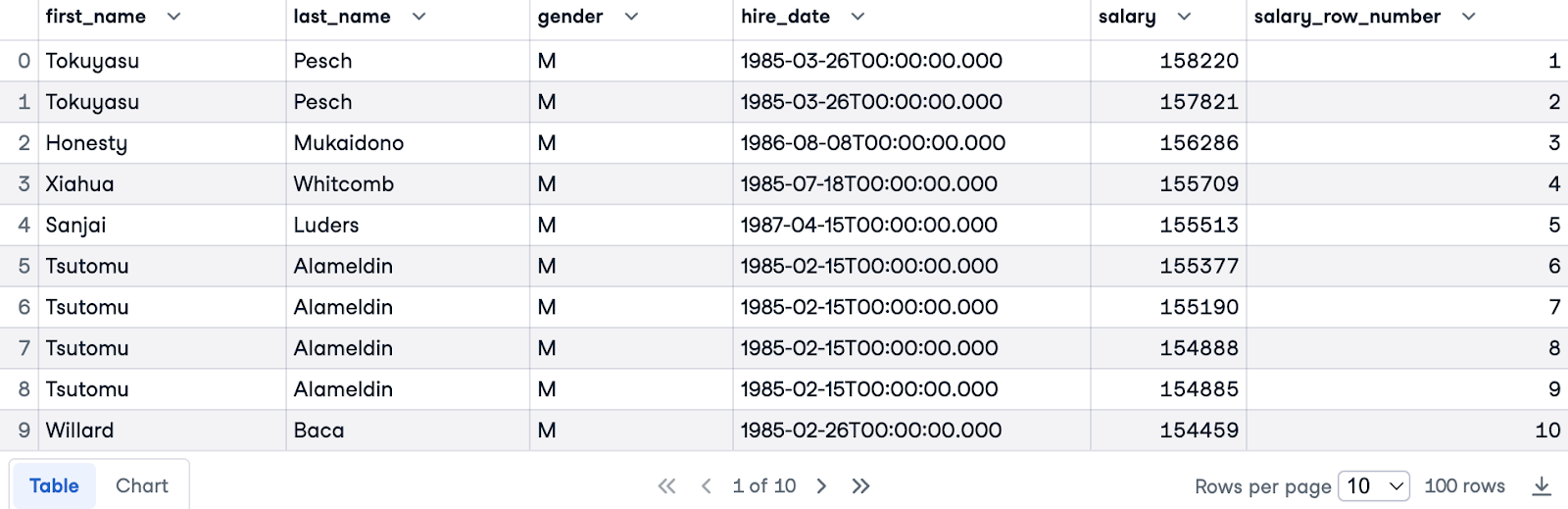
To compare the top salaries for each gender, we can filter the results using a WHERE clause. The query below will return the top 5 earners for each gender, ordered by their rank within their gender group. Such queries can provide insights into pay equity within the dataset.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;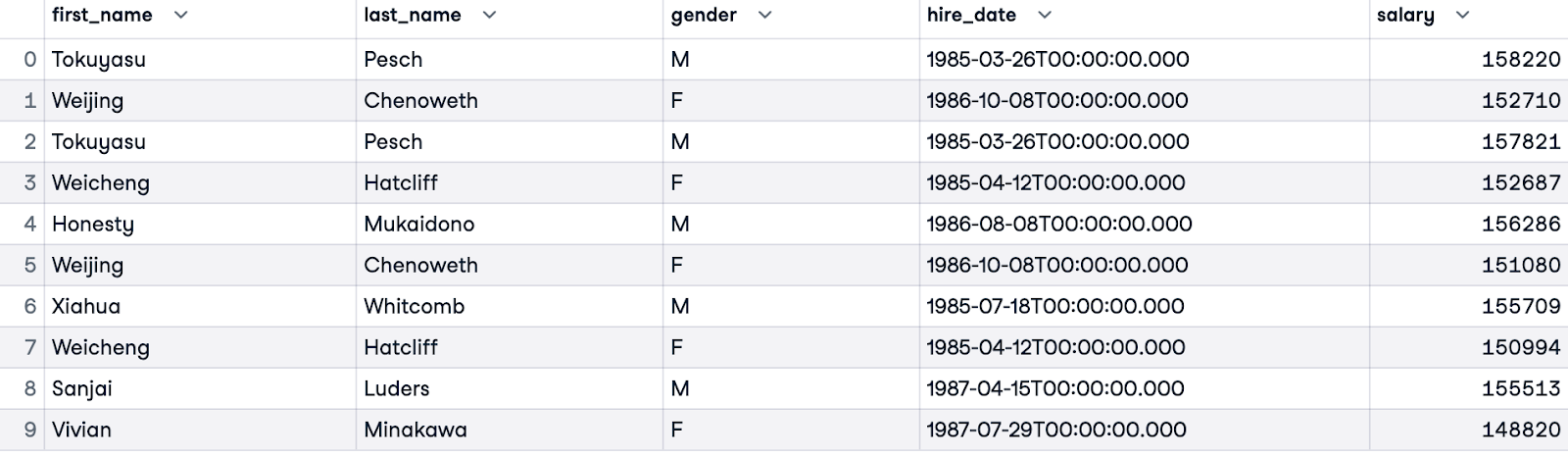
The ROW_NUMBER() function is useful when we have an unordered dataset and want to assign a clear sequential numbering of the rows for further analysis. We define the specific order of these numbers using ORDER BY and define separate numbering sequences for distinct groups within the data using PARTITION BY.
If you found this article useful and want to learn more about SQL, check out our other SQL courses.
Learn more about SQL with these courses!
Course
Course
Course
Tutorial
Allan Ouko
Tutorial
Travis Tang
Tutorial
Sayak Paul
Tutorial
Allan Ouko
Tutorial
Islam Salahuddin
Tutorial
Laiba Siddiqui