track
Fundamentele agenților AI
6 oră
DeepSeek V4 este cea mai nouă generație de modele lingvistice Mixture-of-Experts (MoE) de la DeepSeek AI. Seria include două variante:
Mai multe îmbunătățiri arhitecturale diferențiază V4 de predecesorii săi:
Figura: Arhitectura seriei DeepSeek V4 (Raportul tehnic DeepSeek)
Ambele modele acceptă trei moduri distincte de efort de raționare, Non-think, Think High și Think Max, pe care le vom explora și compara în acest tutorial.
Echipa DeepSeek a comparat performanța modelului V4 cu omologii săi, iar iată concluziile:
Figura: Performanța la benchmark a seriei DeepSeek V4 (Raportul tehnic DeepSeek)
Diagrama cu bare din stânga arată unde se plasează V4-Pro-Max în raport cu modelele închise de vârf, pe sarcini de cunoaștere, raționament și agenți. Cele două grafice din dreapta arată de ce câștigurile de eficiență contează și sunt rezultatele mai surprinzătoare. DeepSeek-V4-Pro-Max (modul de raționare Think Max) obține rezultate competitive în raport cu modelele închise de top:
|
Benchmark |
DeepSeek-V4-Pro Max |
Claude Opus 4.6 Max |
Gemini-3.1-Pro High |
|
LiveCodeBench (Pass@1) |
93.5 |
88.8 |
91.7 |
|
Rating Codeforces |
3206 |
— |
3052 |
|
GPQA Diamond (Pass@1) |
90.1 |
91.3 |
94.3 |
|
SWE Verified (Rezolvat) |
80.6 |
80.8 |
80.6 |
Ratingul Codeforces de 3206 plasează V4-Pro-Max la nivelul Legendary Grandmaster, ceea ce face ca sarcinile de codare din arena noastră să fie un test de stres cu adevărat interesant.
Înainte de a construi aplicația, merită să înțelegem ce face de fapt fiecare mod:
Non-think: Modelul răspunde direct, fără un lanț intern al raționamentului. Acest mod este ideal pentru sarcini unde viteza contează mai mult decât profunzimea, precum conversii de format, căutări simple și rezumate într-o singură propoziție.Think High: Modelul raționează pas cu pas înainte de a se angaja într-un răspuns. Acest mod oferă un echilibru bun între profunzime și cost pentru sarcini moderat complexe precum depanare, proiectare de sisteme și planificare.Think Max: Modelul împinge raționamentul la maximum, explorează mai multe abordări, își verifică riguros logica și oferă un răspuns final doar când este sigur. Astfel, modul Think Max este cel mai potrivit pentru demonstrații matematice dificile, refactorizări complexe pe mai multe fișiere sau orice sarcină unde un răspuns greșit și sigur e mai rău decât unul mai lent, dar verificat.Intuiția critică pe care o demonstrează acest tutorial este că Think Max nu câștigă întotdeauna. La sarcini triviale, irosește compute pentru o calitate identică. Scopul arenei este să evidențieze ce mod merită cu adevărat folosit pentru fiecare tip de sarcină, pe baza latenței reale, numărului de tokeni, costului și evaluărilor utilizatorilor.
Dacă vă interesează să vedeți cum se compară modelul cu alte LLM-uri de ultimă generație, vă recomand articolele noastre despre Claude Opus 4.7 vs DeepSeek V4 și GPT-5.5 vs DeepSeek V4.
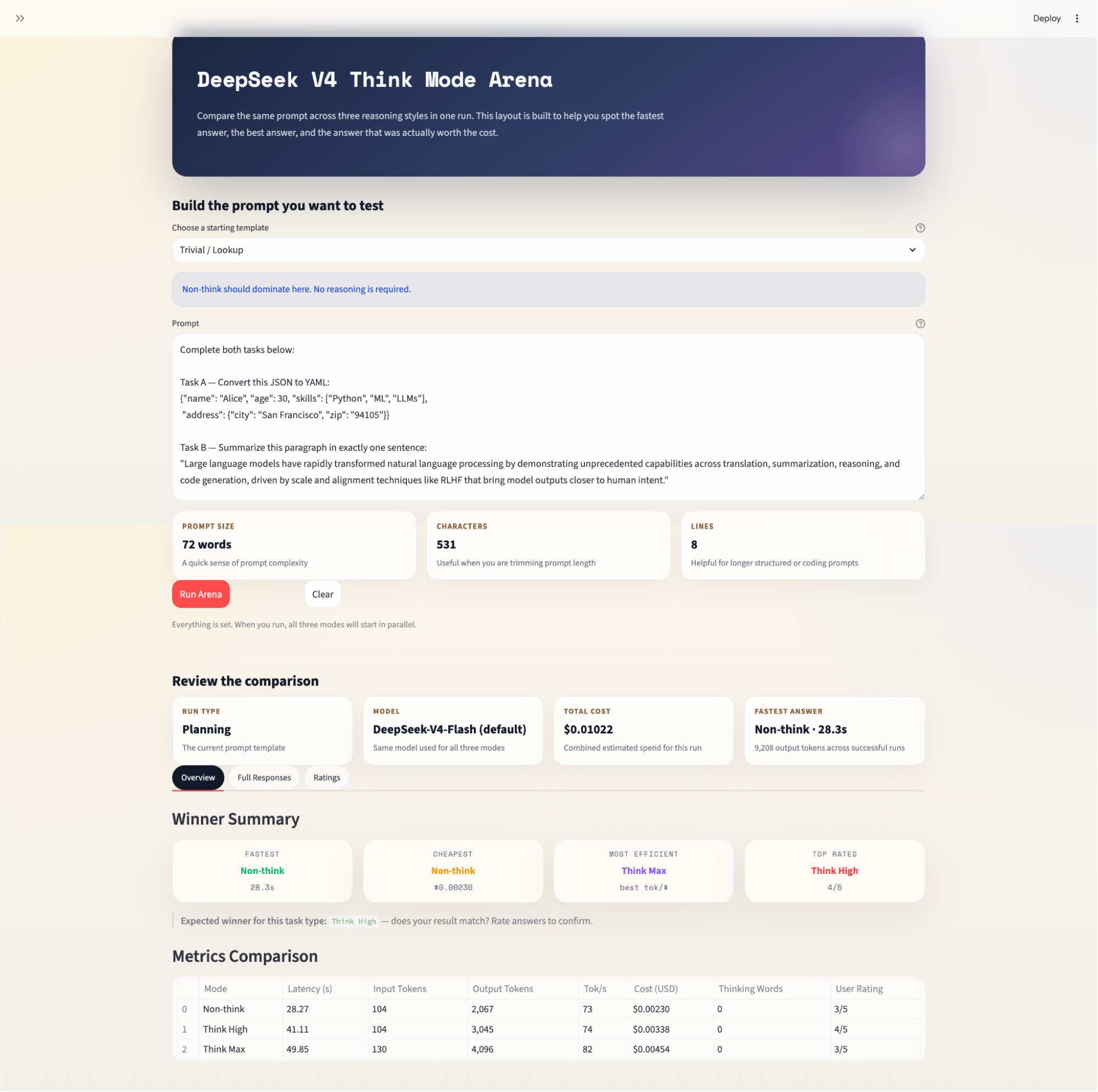
În acest tutorial, vom construi o aplicație Streamlit care:
Primește de la utilizator un prompt și o categorie de sarcini
Lansează trei apeluri API paralele, câte unul per mod de raționare, folosind ThreadPoolExecutor din Python
Parsează urmele de gândire din blocurile <think>...</think> din ieșirea modelului
Urmărește latența, numărul de tokeni și costul estimat per mod
Prezintă o comparație alăturată cu metrici, un sistem de evaluare a utilizatorilor și un rezumat al câștigătorului
Aplicația complet funcțională este un singur fișier app.py, fără baze de date externe sau servicii de fundal necesare.
Codul complet pentru acest tutorial este disponibil în repository-ul meu GitHub.
Începeți prin a crea un dosar de proiect și a instala cele două pachete necesare:
mkdir deepseek-arena && cd deepseek-arena
pip install streamlit>=1.32.0 openai>=1.12.0Biblioteca openai este folosită aici deoarece API-ul DeepSeek este compatibil cu OpenAI, ceea ce înseamnă că putem direcționa clientul OpenAI către URL-ul de bază al DeepSeek fără alte modificări. Nu este necesar niciun SDK specific DeepSeek.
Obțineți o cheie API de la platform.deepseek.com și setați-o ca variabilă de mediu:
export DEEPSEEK_API_KEY="sk-..."Acum că mediul este setat, putem trece la configurarea modelelor și a modurilor acestora.
Înainte de a scrie logica, definim importurile, identificatorii de model, configurațiile modurilor de raționare și constantele de preț. Aceste dicționare controlează comportamentul întregii aplicații: meniul derulant de modele, parametrii API care guvernează fiecare mod, schema de culori din UI și estimările de cost afișate în panoul de comparație.
import os
import time
import concurrent.futures
from dataclasses import dataclass
from typing import Optional, Dict
import streamlit as st
from openai import OpenAI
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
DEEPSEEK_API_KEY_ENV = "DEEPSEEK_API_KEY"
MODELS = {
"DeepSeek-V4-Flash (default)": "deepseek-v4-flash",
"DeepSeek-V4-Pro": "deepseek-v4-pro",
}
MODES: Dict[str, dict] = {
"Non-think": {
"icon": "",
"color": "#10b981",
"badge": "green",
"desc": "Fast, direct answers — no internal reasoning",
"thinking_type": "disabled",
"reasoning_effort": None,
},
"Think High": {
"icon": "",
"color": "#3b82f6",
"badge": "blue",
"desc": "Careful step-by-step reasoning before responding",
"thinking_type": "enabled",
"reasoning_effort": "high",
},
"Think Max": {
"icon": "",
"color": "#ef4444",
"badge": "red",
"desc": "Exhaustive reasoning — push analysis to the limit",
"thinking_type": "enabled",
"reasoning_effort": "max",
},
}
PRICING = {
"deepseek-v4-flash": {
"input_cache_hit": 0.0028,
"input_cache_miss": 0.14,
"output": 0.28,
},
"deepseek-v4-pro": {
"input_cache_hit": 0.003625,
"input_cache_miss": 0.435,
"output": 0.87,
},
}Câteva alegeri de design merită detaliate aici:
Parametri pentru modul de gândire: Fiecare intrare din MODES include două câmpuri API, nu un system prompt. Acestea sunt thinking_type și reasoning_effort („high”, "max" sau None). thinking_type este transmis prin extra_body={"thinking": {"type": ...}}, iar reasoning_effort este un parametru de nivel superior în cerere. Non-think setează thinking_type la "disabled" și lasă reasoning_effort ca None, astfel încât nu se trimite deloc corp de gândire.
Flash ca model implicit: Flash activează 13B parametri per token față de 49B la Pro, ceea ce face ca apelurile paralele în trei direcții să fie suficient de ieftine pentru a fi rulate în mod repetat în timpul experimentării. Pro este disponibil în dropdown pentru când aveți nevoie de performanță de top, dar Think Max pe Pro consumă rapid cota, așa că a-l păstra opțional și nu implicit este o barieră deliberată de cost.
Notă: Valorile folosite în codul de mai sus reflectă V4-Pro la reducerea promoțională actuală. Așadar, verificați întotdeauna tarifele curente pe api-docs.deepseek.com/quick_start/pricing înainte de a publica comparații de cost, deoarece atât tarifele de bază, cât și reducerile promoționale se schimbă frecvent după lansarea unui model nou.
Proiectarea sarcinilor este partea cea mai subestimată din construirea unei comparații de raționament. Dacă toate sarcinile sunt grele și deschise, Think Max câștigă de fiecare dată, iar demonstrația nu învață nimic. Setul de sarcini trebuie să acopere întregul spectru de dificultate astfel încât fiecare mod să aibă cel puțin o categorie în care câștigă.
TASKS = {
"Trivial / Lookup": {
"prompt": (
"Complete both tasks below:\n\n"
"Task A — Convert this JSON to YAML:\n"
'{"name": "Alice", "age": 30, "skills": ["Python", "ML", "LLMs"],\n'
' "address": {"city": "San Francisco", "zip": "94105"}}\n\n'
"Task B — Summarize this paragraph in exactly one sentence:\n"
'"Large language models have rapidly transformed natural language processing '
"by demonstrating unprecedented capabilities across translation, summarization, "
"reasoning, and code generation, driven by scale and alignment techniques like RLHF "
'that bring model outputs closer to human intent."'
),
"expected_winner": "Non-think",
"tip": "Non-think should dominate here. No reasoning is required.",
},
"Coding / Debugging": {
"prompt": (
"Find every bug in the Python code below, explain each bug clearly, "
"and provide a fully corrected version:\n\n"
"```python\n"
"def binary_search(arr, target):\n"
" left, right = 0, len(arr)\n"
" while left < right:\n"
" mid = (left + right) // 2\n"
" if arr[mid] == target:\n"
" return mid\n"
" elif arr[mid] < target:\n"
" left = mid\n"
" else:\n"
" right = mid - 1\n"
" return -1\n\n"
"print(binary_search([1, 3, 5, 7, 9], 7))\n"
"```"
),
"expected_winner": "Think High",
"tip": "Think High usually finds the bugs and explains them well.",
},
"System Design": {
"prompt": (
"Design a scalable vector search system for 100 million documents.\n\n"
"Address each of the following:\n"
"1. Indexing strategy and pipeline\n"
"2. ANN algorithm selection (HNSW vs IVF-PQ vs ScaNN — justify your choice)\n"
"3. Sharding and replication strategy\n"
"4. p99 query latency target (< 50 ms) — how do you hit it?\n"
"5. Real-time document update handling\n"
"6. Top 3 failure modes and their mitigations"
),
"expected_winner": "Think High",
"tip": "Think High often gives the best quality-per-dollar design answer.",
},
"Planning": {
"prompt": (
"Create a detailed 6-month roadmap for deploying an enterprise RAG system.\n\n"
"Include:\n"
"- Month-by-month phases with concrete, measurable milestones\n"
"- Top 5 risks and mitigation strategies\n"
"- Team roles and headcount required per phase\n"
"- Evaluation metrics for each phase (how do you know it's working?)\n"
"- Go / no-go production checklist"
),
"expected_winner": "Think High",
"tip": "Think High should produce a more structured, complete roadmap.",
},
"Math (IMO-style)": {
"prompt": (
"Solve this problem completely and verify your answer:\n\n"
"Find all positive integers n such that n² + 1 is divisible by n + 1.\n\n"
"Your answer must include:\n"
"1. A complete proof with clear logical steps\n"
"2. Verification with at least 3 concrete numerical examples\n"
"3. A rigorous argument for why your solution set is complete "
"(i.e., there are no other solutions)"
),
"expected_winner": "Think Max",
"tip": "Think Max earns its cost when thorough verification matters.",
},
}Cele cinci sarcini se asociază clar cu cei trei câștigători așteptați:
|
Sarcină |
Câștigător așteptat |
Motivare |
|
Trivial / Lookup |
Non-think |
Nu este nevoie de raționament; timpul de gândire este irosit |
|
Coding / Debugging |
Think High |
O trecere metodică surprinde toate bug-urile; Max adaugă valoare marginală |
|
System Design |
Think High |
Profunzimea îmbunătățește calitatea; epuizarea nu adaugă arhitectură utilă |
|
Planning |
Think High |
Structura contează mai mult decât compute brut; o foaie de parcurs nu este o demonstrație |
|
Math (stil IMO) |
Think Max |
Verificarea este esențială; o demonstrație greșită e mai rea decât una corectă dar lentă |
Fiecare sarcină are și un câmp expected_winner. Aplicația îl afișează după sosirea rezultatelor, astfel încât utilizatorii pot verifica dacă așteptarea s-a confirmat sau a fost contrazisă.
Cu șabloanele de sarcini definite, avem nevoie de o structură pentru a reține rezultatele din fiecare apel API. În loc să transmitem obiecte brute de răspuns în toată aplicația, definim o singură clasă de date RunResult care captează toți indicatorii necesari pentru panoul de comparație.
@dataclass
class RunResult:
mode: str
answer: str = ""
thinking: str = ""
latency: float = 0.0
input_tokens: int = 0
output_tokens: int = 0
cost_usd: float = 0.0
error: Optional[str] = None
@property
def tokens_per_second(self) -> Optional[float]:
if self.latency > 0 and self.output_tokens > 0:
return self.output_tokens / self.latency
return None
@property
def thinking_word_count(self) -> int:
return len(self.thinking.split()) if self.thinking else 0Câmpul thinking este separat de answer deoarece API-ul DeepSeek V4 returnează lanțul de gândire într-un câmp dedicat, reasoning_content, la același nivel cu content în structura răspunsului. Păstrarea lor separate permite UI-ului să redea o urmă de raționament pliabilă alături de răspunsul final curat, ceea ce face diferența de mod imediată și tangibilă, mai ales la sarcina de matematică, unde urma Think Max poate ajunge la mii de cuvinte.
Proprietatea tokens_per_second măsoară debitul de generare independent de lungimea promptului. Este utilă pentru compararea eficienței între moduri atunci când numerele de tokeni de ieșire diferă semnificativ. Observați că Think Max produce natural mai mulți tokeni, astfel încât comparațiile brute ale latenței pot induce în eroare fără a vedea și viteza de generare pentru fiecare mod.
Înainte de a scrie logica apelurilor API, definim doi mici helperi care fac legătura între răspunsul brut al SDK-ului și RunResult. Sunt ușor de trecut cu vederea, dar contează mult pentru acuratețea costului.
def get_cached_prompt_tokens(usage) -> int:
prompt_details = getattr(usage, "prompt_tokens_details", None)
if prompt_details is None:
return 0
cached_tokens = getattr(prompt_details, "cached_tokens", None)
if cached_tokens is not None:
return cached_tokens or 0
if isinstance(prompt_details, dict):
return prompt_details.get("cached_tokens", 0) or 0
return 0
def estimate_cost_usd(
model: str,
prompt_tokens: int,
completion_tokens: int,
cached_prompt_tokens: int,
) -> float:
pricing = PRICING.get(model, PRICING["deepseek-v4-flash"])
cached_tokens = min(cached_prompt_tokens, prompt_tokens)
uncached_tokens = max(prompt_tokens - cached_tokens, 0)
return (
cached_tokens / 1_000_000 * pricing["input_cache_hit"]
+ uncached_tokens / 1_000_000 * pricing["input_cache_miss"]
+ completion_tokens / 1_000_000 * pricing["output"]
)Funcția get_cached_prompt_tokens() nu oferă acces direct la câmp deoarece structura prompt_tokens_details nu este garantată a fi consecventă între versiunile SDK. Verifică mai întâi un atribut tastat, apoi revine la acces dicționar, apoi returnează zero în loc să ridice o excepție. Acest lucru contează în interiorul unui ThreadPoolExecutor, unde o eroare tăcută într-un fir ar produce o estimare de cost în mod înșelător scăzută fără a afișa vreun eșec vizibil.
Helperul estimate_cost_usd() separă numărul de tokeni din prompt în porțiuni cache-hit și cache-miss înainte de a aplica tarifele. Deoarece DeepSeek a redus prețurile pentru cache-hit la o zecime din rata de miss, diferența între un prompt rece și unul cald poate fi dramatică. La o rulare repetată pe aceeași sarcină, Non-think poate părea aproape gratuit comparativ cu Think Max, nu pentru că a generat mai puțini tokeni, ci pentru că promptul său mai scurt are șanse covârșitoare să fie în cache cald.
Aceasta este partea arhitecturală centrală a arenei. Toate cele trei moduri pornesc simultan folosind un ThreadPoolExecutor, astfel încât timpul total de execuție pe perete este egal cu cel al celui mai lent mod, nu suma tuturor celor trei.
def call_mode(client: OpenAI, model: str, mode_name: str, user_prompt: str) -> RunResult:
result = RunResult(mode=mode_name)
mode_cfg = MODES[mode_name]
start = time.perf_counter()
try:
request_kwargs = {
"model": model,
"messages": [{"role": "user", "content": user_prompt}],
"max_tokens": 4096,
"extra_body": {"thinking": {"type": mode_cfg["thinking_type"]}},
}
if mode_cfg["reasoning_effort"]:
request_kwargs["reasoning_effort"] = mode_cfg["reasoning_effort"]
response = client.chat.completions.create(**request_kwargs)
result.latency = time.perf_counter() - start
message = response.choices[0].message
result.thinking = (getattr(message, "reasoning_content", None) or "").strip()
result.answer = (message.content or "").strip()
usage = response.usage
result.input_tokens = getattr(usage, "prompt_tokens", 0) or 0
result.output_tokens = getattr(usage, "completion_tokens", 0) or 0
result.cost_usd = estimate_cost_usd(
model=model,
prompt_tokens=result.input_tokens,
completion_tokens=result.output_tokens,
cached_prompt_tokens=get_cached_prompt_tokens(usage),
)
except Exception as exc:
result.latency = time.perf_counter() - start
result.error = str(exc)
return result
def run_parallel(client: OpenAI, model: str, prompt: str) -> Dict[str, RunResult]:
results: Dict[str, RunResult] = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as pool:
futures = {
pool.submit(call_mode, client, model, mode_name, prompt): mode_name
for mode_name in MODES
}
for fut in concurrent.futures.as_completed(futures):
results[futures[fut]] = fut.result()
return resultsMai multe decizii de design merită evidențiate aici:
Construirea condiționată a request_kwargs: Modul Non-think trimite thinking_type: "disabled" și fără cheia reasoning_effort. Think High și Think Max trimit thinking_type: "enabled" și nivelul lor de efort respectiv. Garda if mode_cfg["reasoning_effort"] asigură omiterea completă a parametrului pentru Non-think, în loc să fie trimis ca None, ceea ce ar putea declanșa o eroare de validare API.
Citirea directă a reasoning_content: Urma lanțului de gândire este citită din message.reasoning_content folosind getattr() cu fallback la șir gol. Este mai robust decât parsarea etichetelor <think>...</think> din conținut. Utilizează câmpul oficial din răspuns, gestionează cazul în care nu s-a emis urmă (Non-think) și nu se rupe dacă ieșirea modelului conține cuvântul „think” din alte motive.
getattr() defensiv pe câmpurile de utilizare: Câmpurile de utilizare sunt accesate cu getattr(..., 0) or 0 în loc de acces direct. Astfel, dacă obiectul de utilizare nu are un câmp într-o versiune mai veche a SDK-ului sau într-un răspuns neobișnuit, fallback-ul produce zero în loc de un AttributeError care ar marca întreaga rulare ca eșuată.
Gestionarea erorilor: Dacă un apel eșuează, dataclasa RunResult stochează șirul de eroare în loc să ridice excepția. UI-ul verifică result.error și redă un card informativ fără a prăbuși întreaga rulare în trei moduri.
Acest pas acoperă stratul de prezentare: layout-ul paginii, sistemul de design CSS, coloana de rezultate per mod și structura cu taburi care organizează comparația fără a copleși utilizatorul la încărcarea inițială.
Aplicația folosește st.set_page_config cu layout="wide" pentru a oferi suficient spațiu orizontal comparației pe trei coloane:
def main():
st.set_page_config(
page_title="DeepSeek V4 Think Mode Arena",
layout="wide",
initial_sidebar_state="expanded",
)
inject_css()Funcția inject_css() injectează un sistem de design complet prin st.markdown. Utilizează un fundal cald, de pergament, cu Space Mono pentru antete monospațiate și chip-uri de metrici, și DM Sans pentru textul de corp.
def render_mode_column(result: RunResult, mode_name: str):
cfg = MODES[mode_name]
badge_cls = f"mode-{cfg['badge']}"
st.markdown(
f'<div class="mode-header {badge_cls}">{mode_name}</div>',
unsafe_allow_html=True,
)
st.markdown(f'<div class="subtle-copy">{cfg["desc"]}</div>', unsafe_allow_html=True)
if result.error:
st.error(f"**API Error:** {result.error}")
return
chips = [
("Latency", f"{result.latency:.1f}s"),
("Output tokens", f"{result.output_tokens:,}"),
("Cost", f"${result.cost_usd:.5f}"),
]
if result.tokens_per_second:
chips.append(("Tok/s", f"{result.tokens_per_second:.0f}"))
chip_html = "".join(
f'<span class="metric-chip">{label} <span>{val}</span></span>'
for label, val in chips
)
st.markdown(chip_html, unsafe_allow_html=True)
if result.thinking:
with st.expander(f" Thinking trace — {result.thinking_word_count:,} words"):
preview = result.thinking[:5000]
if len(result.thinking) > 5000:
preview += "\n\n[… truncated for display …]"
st.text(preview)
elif mode_name != "Non-think":
st.caption("_No thinking trace emitted_")
st.markdown('<div class="answer-label">Final answer</div>', unsafe_allow_html=True)
st.markdown(result.answer if result.answer else "_No answer returned._")Expandorul pentru urma de gândire este deosebit de util deoarece face diferența dintre moduri palpabilă: urma Think Max poate ajunge la mii de cuvinte de autocorecție și verificare pe o problemă grea de matematică, în timp ce modul Non-think poate să nu aibă nicio urmă.
Layout-ul principal folosește taburi Streamlit pentru a separa aspectele, fără a înghesui totul într-un singur scroll:
overview_tab, answers_tab, ratings_tab = st.tabs(
["Overview", "Full Responses", "Ratings"]
)Tabul „Overview” afișează rezumatul câștigătorilor și tabelul cu metrici. Tabul „Full Responses” arată comparația alăturată pe trei coloane, cu urmele de gândire, în timp ce „Ratings” afișează slider-e pentru evaluările de calitate ale utilizatorilor (1–5) per mod.
Acest pas final construiește cele două componente din tabul Overview, adică un tabel plat de metrici care pune alături fiecare dimensiune măsurată și un rezumat al câștigătorilor care evidențiază câștigătorul în patru categorii distincte.
def render_metrics_table(results: Dict[str, RunResult], ratings: Dict[str, int]):
rows = []
for mode_name, res in results.items():
ok = not res.error
rows.append({
"Mode": mode_name,
"Latency (s)": f"{res.latency:.2f}" if ok else "—",
"Input Tokens": f"{res.input_tokens:,}" if ok else "—",
"Output Tokens": f"{res.output_tokens:,}" if ok else "—",
"Tok/s": f"{res.tokens_per_second:.0f}" if (ok and res.tokens_per_second) else "—",
"Est. Cost (USD)": f"${res.cost_usd:.5f}" if ok else "—",
"Thinking Words": f"{res.thinking_word_count:,}" if ok else "—",
"User Rating": f"{ratings.get(mode_name)}/5" if ratings.get(mode_name) else "—",
})
st.table(rows)
def render_winner_summary(results: Dict[str, RunResult], ratings: Dict[str, int], expected: str):
valid = {k: v for k, v in results.items() if not v.error}
fastest = min(valid, key=lambda k: valid[k].latency)
cheapest = min(valid, key=lambda k: valid[k].cost_usd)
most_efficient = max(
valid,
key=lambda k: valid[k].output_tokens / max(valid[k].cost_usd, 1e-9),
)
top_rated = max(ratings, key=ratings.get) if ratings else NoneIată pe scurt ce fac aceste două funcții:
Funcția render_metrics_table() iterează peste fiecare RunResult și construiește un rând pentru fiecare mod. Cele opt coloane acoperă comparația completă, incluzând timpul (latență, tok/s), anvergura (tokeni de intrare și ieșire, cuvinte în urma de gândire), banii (cost estimat) și judecata umană (evaluarea utilizatorului).
Funcția render_winner_summary() filtrează mai întâi rulările eșuate înainte de a calcula câștigătorii, astfel încât o singură eroare API să nu distorsioneze rezultatele. Apoi găsește campionul în patru dimensiuni independente: viteză la perete, cost brut, eficiență a ieșirii și evaluare a utilizatorului.
Aceste patru categorii sunt păstrate intenționat separate, nu combinate într-un scor unic, deoarece un compozit ponderat ar impune aplicației să decidă că latența contează mai mult decât costul, ceea ce este o decizie de produs, nu de cadru.
Aplicația afișează, de asemenea, câștigătorul preconizat per sarcină, solicitând utilizatorului să confirme dacă s-a potrivit:
st.markdown(
f"> **Expected winner for this task type:** {expected} — "
"does your result match? Rate answers to confirm.",
)Întreaga aplicație se află într-un singur fișier app.py cu două dependențe, iar pornirea ei necesită două comenzi:
# Set your API key
export DEEPSEEK_API_KEY="sk-..."
# Run
streamlit run app.pyAplicația se deschide în browser la localhost:8501. Selectați un șablon de sarcină din meniul derulant, editați opțional promptul și faceți clic pe Run Arena. O bară de progres se actualizează pe măsură ce fiecare mod se finalizează. Rezultatele sunt stocate în st.session_state astfel încât să puteți schimba taburile și să evaluați răspunsurile fără a declanșa o rerulare.
Notă privind prețurile: DeepSeek a ajustat semnificativ tarifele API V4 de la lansare. V4-Pro se află în prezent la o reducere promoțională, iar prețurile pentru cache-hit au fost reduse la o zecime din rata de miss în aprilie 2026. Cifrele de cost afișate în aplicație reflectă aceste tarife curente, dar se pot schimba. Verificați întotdeauna pe api-docs.deepseek.com/quick_start/pricing înainte de a folosi orice model.
În acest tutorial, am construit o aplicație Streamlit care rulează același prompt în paralel pe cele trei moduri de raționare ale DeepSeek V4 și compară rezultatele după latență, cost, utilizare de tokeni, adâncimea urmei de gândire și calitatea evaluată de utilizatori. Alegerile arhitecturale cheie au fost:
ThreadPoolExecutor pentru paralelism real, ceea ce înseamnă că timpul total la perete este egal cu cel al celui mai lent mod, nu suma tuturor celor trei
Parametrii API thinking și reasoning_effort asigură că controlul modului este curat, explicit și aliniat cu API-ul DeepSeek, în loc să se bazeze pe dirijarea prin system prompt
Estimarea costului ținând cont de cache ajută la separarea tokenilor de intrare în porțiuni cache-hit și cache-miss, producând cifre de cost semnificativ mai precise, în special la rulări repetate, unde reducerile pentru cache cald pot face ca Non-think să pară aproape gratuit
Pentru a extinde proiectul, luați în considerare adăugarea unui strat LLM-as-judge (folosind un model separat precum Claude sau GPT-4 pentru a puncta automat răspunsurile), cache-uirea răspunsurilor pe hash-ul promptului pentru a evita rerularea interogărilor identice sau adăugarea unei axe cross-model care îl pune pe Flash Think Max împotriva lui Pro Think High, o întrebare de paritate a costurilor cu adevărat interesantă pe care o ridică lucrarea V4, dar la care nu răspunde complet.
Cursuri AI de top
track
course
course