
Program
Dasar-Dasar Agen Kecerdasan Buatan
6 Hr
DeepSeek V4 adalah generasi terbaru model bahasa Mixture-of-Experts (MoE) dari DeepSeek AI. Seri ini mencakup dua varian:
Beberapa peningkatan arsitektural membedakan V4 dari pendahulunya:
Gambar: Arsitektur Seri DeepSeek V4 (Laporan Teknis DeepSeek)
Kedua model mendukung tiga mode upaya penalaran yang berbeda, Non-think, Think High, dan Think Max, yang akan kita jelajahi dan bandingkan dalam tutorial ini.
Tim DeepSeek membandingkan kinerja model V4 dengan padanannya, dan berikut temuan mereka:
Gambar: Kinerja benchmark seri DeepSeek V4 (Laporan Teknis DeepSeek)
Diagram batang di kiri menunjukkan posisi V4-Pro-Max relatif terhadap model sumber tertutup terdepan di berbagai tugas pengetahuan, penalaran, dan agensi. Dua plot di kanan menunjukkan mengapa keuntungan efisiensi itu penting, dan hasil tersebut lebih mengejutkan. DeepSeek-V4-Pro-Max (mode penalaran Think Max) meraih hasil kompetitif melawan model sumber tertutup terdepan:
|
Benchmark |
DeepSeek-V4-Pro Max |
Claude Opus 4.6 Max |
Gemini-3.1-Pro High |
|
LiveCodeBench (Pass@1) |
93.5 |
88.8 |
91.7 |
|
Peringkat Codeforces |
3206 |
— |
3052 |
|
GPQA Diamond (Pass@1) |
90.1 |
91.3 |
94.3 |
|
SWE Verified (Resolved) |
80.6 |
80.8 |
80.6 |
Peringkat Codeforces 3206 menempatkan V4-Pro-Max pada level Legendary Grandmaster, sehingga tugas pemrograman di arena kita menjadi uji stres yang benar-benar menarik.
Sebelum membangun aplikasi, ada baiknya memahami apa yang sebenarnya dilakukan tiap mode:
Non-think: Model merespons langsung, tanpa rantai pemikiran internal. Mode ini ideal untuk tugas yang mengutamakan kecepatan dibanding kedalaman, seperti konversi format, pencarian sederhana, dan ringkasan satu kalimat.Think High: Model bernalar selangkah demi selangkah sebelum memberikan jawaban. Mode ini seimbang antara kedalaman dan biaya untuk tugas cukup kompleks seperti debugging, desain sistem, dan perencanaan.Think Max: Model mendorong penalaran sampai batas maksimal, mengeksplorasi beberapa pendekatan, memverifikasi logikanya dengan ketat, dan baru berkomitmen pada jawaban final saat yakin. Jadi, mode Think Max paling tepat untuk pembuktian matematika sulit, refaktor multi-berkas kompleks, atau tugas apa pun di mana jawaban salah yang percaya diri lebih buruk daripada jawaban benar yang lebih lambat namun terverifikasi.Wawasan penting yang ditunjukkan tutorial ini adalah Think Max tidak selalu menang. Pada tugas remeh, ia memboroskan komputasi untuk kualitas yang identik. Tujuan arena adalah menonjolkan mode mana yang benar-benar layak digunakan untuk tiap jenis tugas, berdasarkan latensi nyata, jumlah token, biaya, dan penilaian pengguna.
Jika Anda tertarik melihat bagaimana model ini dibandingkan dengan LLM mutakhir lainnya, saya sarankan membaca artikel kami tentang Claude Opus 4.7 vs DeepSeek V4 dan GPT-5.5 vs DeepSeek V4.
Dalam tutorial ini, kita akan membangun aplikasi Streamlit yang:
Menerima prompt dan kategori tugas dari pengguna
Menjalankan tiga panggilan API paralel, satu per mode penalaran, menggunakan ThreadPoolExecutor milik Python
Mengurai jejak pemikiran dari blok <think>...</think> pada keluaran model
Melacak latensi, jumlah token, dan estimasi biaya per mode
Menyajikan perbandingan berdampingan dengan metrik, sistem penilaian pengguna, dan ringkasan pemenang
Aplikasi lengkapnya hanyalah satu berkas app.py tanpa memerlukan basis data eksternal atau layanan latar belakang.
Kode lengkap untuk tutorial ini tersedia di repositori GitHub saya.
Mulailah dengan membuat folder proyek dan memasang dua paket yang diperlukan:
mkdir deepseek-arena && cd deepseek-arena
pip install streamlit>=1.32.0 openai>=1.12.0Pustaka openai digunakan di sini karena API DeepSeek kompatibel dengan OpenAI, yang berarti kita dapat mengarahkan klien OpenAI ke base URL DeepSeek tanpa perubahan lain. Tidak diperlukan SDK khusus DeepSeek.
Dapatkan kunci API dari platform.deepseek.com dan aturkan sebagai variabel lingkungan:
export DEEPSEEK_API_KEY="sk-..."Sekarang lingkungan sudah siap, kita bisa lanjut ke konfigurasi model dan mode-nya.
Sebelum menulis logika apa pun, kita mendefinisikan impor, pengenal model, konfigurasi mode penalaran, dan konstanta harga. Kamus-kamus ini mengontrol perilaku seluruh aplikasi, seperti dropdown model, parameter API yang menggerakkan setiap mode penalaran, skema warna UI, dan estimasi biaya yang ditampilkan di panel perbandingan.
import os
import time
import concurrent.futures
from dataclasses import dataclass
from typing import Optional, Dict
import streamlit as st
from openai import OpenAI
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
DEEPSEEK_API_KEY_ENV = "DEEPSEEK_API_KEY"
MODELS = {
"DeepSeek-V4-Flash (default)": "deepseek-v4-flash",
"DeepSeek-V4-Pro": "deepseek-v4-pro",
}
MODES: Dict[str, dict] = {
"Non-think": {
"icon": "",
"color": "#10b981",
"badge": "green",
"desc": "Fast, direct answers — no internal reasoning",
"thinking_type": "disabled",
"reasoning_effort": None,
},
"Think High": {
"icon": "",
"color": "#3b82f6",
"badge": "blue",
"desc": "Careful step-by-step reasoning before responding",
"thinking_type": "enabled",
"reasoning_effort": "high",
},
"Think Max": {
"icon": "",
"color": "#ef4444",
"badge": "red",
"desc": "Exhaustive reasoning — push analysis to the limit",
"thinking_type": "enabled",
"reasoning_effort": "max",
},
}
PRICING = {
"deepseek-v4-flash": {
"input_cache_hit": 0.0028,
"input_cache_miss": 0.14,
"output": 0.28,
},
"deepseek-v4-pro": {
"input_cache_hit": 0.003625,
"input_cache_miss": 0.435,
"output": 0.87,
},
}Beberapa pilihan desain layak diuraikan di sini:
Parameter untuk mode berpikir: Setiap entri di MODES membawa dua kolom API alih-alih system prompt. Ini mencakup thinking_type dan reasoning_effort (”high”, "max", atau None). thinking_type dikirim via extra_body={"thinking": {"type": ...}}, dan reasoning_effort adalah parameter permintaan tingkat atas. Non-think menyetel thinking_type ke "disabled" dan membiarkan reasoning_effort sebagai None, sehingga tidak ada badan pemikiran yang dikirim sama sekali.
Flash sebagai model default: Flash mengaktifkan 13B parameter per token dibanding 49B milik Pro, yang membuat panggilan paralel tiga arah cukup murah untuk dijalankan berulang selama eksperimen. Pro tersedia melalui dropdown untuk kebutuhan kinerja terdepan, namun Think Max pada Pro membakar kuota dengan cepat, sehingga mempertahankannya sebagai opt-in, bukan default, merupakan pagar pembatas biaya yang disengaja.
Catatan: Nilai yang digunakan dalam kode di atas mencerminkan V4-Pro pada diskon promosi saat ini. Jadi, selalu verifikasi tarif terbaru di api-docs.deepseek.com/quick_start/pricing sebelum menerbitkan perbandingan biaya, karena tarif dasar dan diskon promosi sering berubah setelah rilis model baru.
Desain tugas adalah bagian yang paling kurang dihargai saat membangun perbandingan penalaran. Jika semua tugas sulit dan terbuka, Think Max akan selalu menang, dan demo tidak mengajarkan apa pun. Kumpulan tugas harus mencakup seluruh rentang kesulitan agar setiap mode punya setidaknya satu kategori tempat ia menang.
TASKS = {
"Trivial / Lookup": {
"prompt": (
"Complete both tasks below:\n\n"
"Task A — Convert this JSON to YAML:\n"
'{"name": "Alice", "age": 30, "skills": ["Python", "ML", "LLMs"],\n'
' "address": {"city": "San Francisco", "zip": "94105"}}\n\n'
"Task B — Summarize this paragraph in exactly one sentence:\n"
'"Large language models have rapidly transformed natural language processing '
"by demonstrating unprecedented capabilities across translation, summarization, "
"reasoning, and code generation, driven by scale and alignment techniques like RLHF "
'that bring model outputs closer to human intent."'
),
"expected_winner": "Non-think",
"tip": "Non-think should dominate here. No reasoning is required.",
},
"Coding / Debugging": {
"prompt": (
"Find every bug in the Python code below, explain each bug clearly, "
"and provide a fully corrected version:\n\n"
"```python\n"
"def binary_search(arr, target):\n"
" left, right = 0, len(arr)\n"
" while left < right:\n"
" mid = (left + right) // 2\n"
" if arr[mid] == target:\n"
" return mid\n"
" elif arr[mid] < target:\n"
" left = mid\n"
" else:\n"
" right = mid - 1\n"
" return -1\n\n"
"print(binary_search([1, 3, 5, 7, 9], 7))\n"
"```"
),
"expected_winner": "Think High",
"tip": "Think High usually finds the bugs and explains them well.",
},
"System Design": {
"prompt": (
"Design a scalable vector search system for 100 million documents.\n\n"
"Address each of the following:\n"
"1. Indexing strategy and pipeline\n"
"2. ANN algorithm selection (HNSW vs IVF-PQ vs ScaNN — justify your choice)\n"
"3. Sharding and replication strategy\n"
"4. p99 query latency target (< 50 ms) — how do you hit it?\n"
"5. Real-time document update handling\n"
"6. Top 3 failure modes and their mitigations"
),
"expected_winner": "Think High",
"tip": "Think High often gives the best quality-per-dollar design answer.",
},
"Planning": {
"prompt": (
"Create a detailed 6-month roadmap for deploying an enterprise RAG system.\n\n"
"Include:\n"
"- Month-by-month phases with concrete, measurable milestones\n"
"- Top 5 risks and mitigation strategies\n"
"- Team roles and headcount required per phase\n"
"- Evaluation metrics for each phase (how do you know it's working?)\n"
"- Go / no-go production checklist"
),
"expected_winner": "Think High",
"tip": "Think High should produce a more structured, complete roadmap.",
},
"Math (IMO-style)": {
"prompt": (
"Solve this problem completely and verify your answer:\n\n"
"Find all positive integers n such that n² + 1 is divisible by n + 1.\n\n"
"Your answer must include:\n"
"1. A complete proof with clear logical steps\n"
"2. Verification with at least 3 concrete numerical examples\n"
"3. A rigorous argument for why your solution set is complete "
"(i.e., there are no other solutions)"
),
"expected_winner": "Think Max",
"tip": "Think Max earns its cost when thorough verification matters.",
},
}Kelima tugas dipetakan dengan jelas ke tiga pemenang yang diharapkan:
|
Tugas |
Pemenang yang Diharapkan |
Alasan |
|
Trivial / Lookup |
Non-think |
Tidak perlu overhead penalaran; waktu berpikir murni pemborosan |
|
Coding / Debugging |
Think High |
Satu kali logika metodis menangkap semua bug; Max menambah nilai marjinal |
|
System Design |
Think High |
Kedalaman meningkatkan kualitas; kelelahan tidak menambah arsitektur yang berguna |
|
Planning |
Think High |
Struktur lebih unggul daripada komputasi mentah; peta jalan bukanlah bukti |
|
Math (IMO-style) |
Think Max |
Verifikasi adalah penopang; bukti yang salah lebih buruk daripada yang benar namun lambat |
Setiap tugas juga membawa kolom expected_winner. Aplikasi menampilkannya setelah hasil tiba, sehingga pengguna dapat memeriksa apakah pemenang yang diharapkan terbukti atau justru kalah.
Dengan templat tugas didefinisikan, kita sekarang membutuhkan struktur untuk menampung hasil dari tiap panggilan API. Alih-alih meneruskan objek respons mentah di seluruh aplikasi, kita mendefinisikan satu dataclass RunResult yang menangkap semua metrik yang diperlukan panel perbandingan.
@dataclass
class RunResult:
mode: str
answer: str = ""
thinking: str = ""
latency: float = 0.0
input_tokens: int = 0
output_tokens: int = 0
cost_usd: float = 0.0
error: Optional[str] = None
@property
def tokens_per_second(self) -> Optional[float]:
if self.latency > 0 and self.output_tokens > 0:
return self.output_tokens / self.latency
return None
@property
def thinking_word_count(self) -> int:
return len(self.thinking.split()) if self.thinking else 0Kolom thinking dipisahkan dari answer karena API DeepSeek V4 mengembalikan chain-of-thought di kolom reasoning_content khusus, setingkat dengan content dalam struktur respons. Menjaganya terpisah memungkinkan UI merender jejak penalaran yang dapat dilipat di samping jawaban akhir yang bersih, yang membuat perbedaan mode menjadi langsung dan nyata, terutama pada tugas matematika di mana jejak Think Max bisa mencapai ribuan kata.
Properti tokens_per_second mengukur throughput generasi terlepas dari panjang prompt. Ini berguna untuk membandingkan efisiensi antarmode saat jumlah token keluaran berbeda signifikan. Perlu dicatat bahwa Think Max secara alami menghasilkan lebih banyak token, sehingga perbandingan latensi mentah saja bisa menyesatkan tanpa juga melihat seberapa cepat tiap mode menghasilkan.
Sebelum menulis logika panggilan API, kita mendefinisikan dua pembantu kecil yang berada di antara respons SDK mentah dan RunResult. Mereka mudah terlewat tetapi sangat penting untuk akurasi biaya.
def get_cached_prompt_tokens(usage) -> int:
prompt_details = getattr(usage, "prompt_tokens_details", None)
if prompt_details is None:
return 0
cached_tokens = getattr(prompt_details, "cached_tokens", None)
if cached_tokens is not None:
return cached_tokens or 0
if isinstance(prompt_details, dict):
return prompt_details.get("cached_tokens", 0) or 0
return 0
def estimate_cost_usd(
model: str,
prompt_tokens: int,
completion_tokens: int,
cached_prompt_tokens: int,
) -> float:
pricing = PRICING.get(model, PRICING["deepseek-v4-flash"])
cached_tokens = min(cached_prompt_tokens, prompt_tokens)
uncached_tokens = max(prompt_tokens - cached_tokens, 0)
return (
cached_tokens / 1_000_000 * pricing["input_cache_hit"]
+ uncached_tokens / 1_000_000 * pricing["input_cache_miss"]
+ completion_tokens / 1_000_000 * pricing["output"]
)Fungsi get_cached_prompt_tokens() tidak menyediakan akses kolom langsung karena struktur prompt_tokens_details tidak dijamin konsisten di seluruh versi SDK. Ia memeriksa atribut bertipe lebih dulu, kemudian fallback ke akses dict, lalu mengembalikan nol alih-alih melempar pengecualian. Ini penting di dalam ThreadPoolExecutor di mana kesalahan sunyi di satu thread dapat menghasilkan estimasi biaya yang menyesatkan rendah untuk mode itu tanpa menampilkan kegagalan yang terlihat.
Pembantu estimate_cost_usd() memisahkan jumlah token prompt menjadi bagian yang di-cache dan tidak di-cache sebelum menerapkan tarif. Karena DeepSeek memotong harga cache-hit menjadi sepersepuluh dari tarif miss, perbedaan antara prompt dingin dan hangat bisa dramatis. Pada tugas yang dijalankan berulang, Non-think bisa tampak hampir gratis dibanding Think Max, bukan karena menghasilkan lebih sedikit token, tetapi karena promptnya yang lebih pendek sangat mungkin dalam keadaan cache hangat.
Ini adalah inti arsitektural arena. Ketiga mode ditembakkan secara bersamaan menggunakan ThreadPoolExecutor, sehingga total waktu dinding sama dengan mode tunggal paling lambat, bukan jumlah dari ketiganya.
def call_mode(client: OpenAI, model: str, mode_name: str, user_prompt: str) -> RunResult:
result = RunResult(mode=mode_name)
mode_cfg = MODES[mode_name]
start = time.perf_counter()
try:
request_kwargs = {
"model": model,
"messages": [{"role": "user", "content": user_prompt}],
"max_tokens": 4096,
"extra_body": {"thinking": {"type": mode_cfg["thinking_type"]}},
}
if mode_cfg["reasoning_effort"]:
request_kwargs["reasoning_effort"] = mode_cfg["reasoning_effort"]
response = client.chat.completions.create(**request_kwargs)
result.latency = time.perf_counter() - start
message = response.choices[0].message
result.thinking = (getattr(message, "reasoning_content", None) or "").strip()
result.answer = (message.content or "").strip()
usage = response.usage
result.input_tokens = getattr(usage, "prompt_tokens", 0) or 0
result.output_tokens = getattr(usage, "completion_tokens", 0) or 0
result.cost_usd = estimate_cost_usd(
model=model,
prompt_tokens=result.input_tokens,
completion_tokens=result.output_tokens,
cached_prompt_tokens=get_cached_prompt_tokens(usage),
)
except Exception as exc:
result.latency = time.perf_counter() - start
result.error = str(exc)
return result
def run_parallel(client: OpenAI, model: str, prompt: str) -> Dict[str, RunResult]:
results: Dict[str, RunResult] = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as pool:
futures = {
pool.submit(call_mode, client, model, mode_name, prompt): mode_name
for mode_name in MODES
}
for fut in concurrent.futures.as_completed(futures):
results[futures[fut]] = fut.result()
return resultsBeberapa keputusan desain patut disorot di sini:
Membangun request_kwargs secara kondisional: Mode Non-think mengirim thinking_type: "disabled" dan tanpa kunci reasoning_effort. Think High dan Think Max mengirim thinking_type: "enabled" dan tingkat upaya masing-masing. Penjaga if mode_cfg["reasoning_effort"] memastikan parameter dihilangkan sepenuhnya untuk Non-think alih-alih dikirim sebagai None, yang dapat memicu kesalahan validasi API.
Membaca reasoning_content secara langsung: Jejak chain-of-thought dibaca dari message.reasoning_content menggunakan getattr() dengan fallback ke string kosong. Ini lebih tangguh daripada mengurai tag <think>...</think> dari string konten. Ia memakai kolom respons resmi, menangani kasus tanpa jejak (Non-think), dan tidak rusak jika keluaran model kebetulan mengandung kata "think" untuk alasan lain.
getattr() defensif pada kolom usage: Kolom usage diakses dengan getattr(..., 0) or 0 alih-alih akses atribut langsung. Ini berarti jika objek usage kehilangan kolom dalam versi SDK yang lebih lama atau respons yang tidak biasa, fallback menghasilkan nol alih-alih AttributeError yang akan menandai seluruh run sebagai gagal.
Penanganan kesalahan: Jika panggilan gagal, maka dataclass RunResult menyimpan string error alih-alih melempar. UI memeriksa result.error dan merender kartu informatif tanpa menjatuhkan seluruh run tiga mode.
Langkah ini mencakup lapisan presentasi: tata letak halaman, sistem desain CSS, kolom hasil per mode, dan struktur tab yang mengorganisasi perbandingan tanpa membebani pengguna saat pertama kali memuat.
Aplikasi menggunakan st.set_page_config dengan layout="wide" untuk memberi ruang horizontal yang cukup bagi perbandingan tiga kolom:
def main():
st.set_page_config(
page_title="DeepSeek V4 Think Mode Arena",
layout="wide",
initial_sidebar_state="expanded",
)
inject_css()Fungsi inject_css() menyuntikkan sistem desain lengkap melalui st.markdown. Ia menggunakan latar perkamen hangat dengan Space Mono untuk header monospace dan chip metrik, serta DM Sans untuk teks utama.
def render_mode_column(result: RunResult, mode_name: str):
cfg = MODES[mode_name]
badge_cls = f"mode-{cfg['badge']}"
st.markdown(
f'<div class="mode-header {badge_cls}">{mode_name}</div>',
unsafe_allow_html=True,
)
st.markdown(f'<div class="subtle-copy">{cfg["desc"]}</div>', unsafe_allow_html=True)
if result.error:
st.error(f"**API Error:** {result.error}")
return
chips = [
("Latency", f"{result.latency:.1f}s"),
("Output tokens", f"{result.output_tokens:,}"),
("Cost", f"${result.cost_usd:.5f}"),
]
if result.tokens_per_second:
chips.append(("Tok/s", f"{result.tokens_per_second:.0f}"))
chip_html = "".join(
f'<span class="metric-chip">{label} <span>{val}</span></span>'
for label, val in chips
)
st.markdown(chip_html, unsafe_allow_html=True)
if result.thinking:
with st.expander(f" Thinking trace — {result.thinking_word_count:,} words"):
preview = result.thinking[:5000]
if len(result.thinking) > 5000:
preview += "\n\n[… truncated for display …]"
st.text(preview)
elif mode_name != "Non-think":
st.caption("_No thinking trace emitted_")
st.markdown('<div class="answer-label">Final answer</div>', unsafe_allow_html=True)
st.markdown(result.answer if result.answer else "_No answer returned._")Ekspander jejak pemikiran sangat berguna karena membuat perbedaan mode terasa jelas, sebab jejak Think Max bisa mencapai ribuan kata koreksi diri dan verifikasi pada soal matematika sulit, sementara mode Non-think mungkin tidak memiliki jejak sama sekali.
Tata letak utama menggunakan tab Streamlit untuk memisahkan fokus tanpa menjejalkan semuanya dalam satu guliran:
overview_tab, answers_tab, ratings_tab = st.tabs(
["Overview", "Full Responses", "Ratings"]
)Tab “Overview” menampilkan ringkasan pemenang dan tabel metrik. Tab “Full Responses” menampilkan perbandingan tiga kolom berdampingan dengan jejak pemikiran, sementara tab “Ratings” menunjukkan slider untuk penilaian kualitas pengguna (1–5) per mode.
Langkah terakhir ini membangun dua komponen di tab Overview, yakni tabel metrik datar yang menempatkan setiap dimensi terukur berdampingan, dan ringkasan pemenang yang menyebutkan pemenang dalam empat kategori berbeda.
def render_metrics_table(results: Dict[str, RunResult], ratings: Dict[str, int]):
rows = []
for mode_name, res in results.items():
ok = not res.error
rows.append({
"Mode": mode_name,
"Latency (s)": f"{res.latency:.2f}" if ok else "—",
"Input Tokens": f"{res.input_tokens:,}" if ok else "—",
"Output Tokens": f"{res.output_tokens:,}" if ok else "—",
"Tok/s": f"{res.tokens_per_second:.0f}" if (ok and res.tokens_per_second) else "—",
"Est. Cost (USD)": f"${res.cost_usd:.5f}" if ok else "—",
"Thinking Words": f"{res.thinking_word_count:,}" if ok else "—",
"User Rating": f"{ratings.get(mode_name)}/5" if ratings.get(mode_name) else "—",
})
st.table(rows)
def render_winner_summary(results: Dict[str, RunResult], ratings: Dict[str, int], expected: str):
valid = {k: v for k, v in results.items() if not v.error}
fastest = min(valid, key=lambda k: valid[k].latency)
cheapest = min(valid, key=lambda k: valid[k].cost_usd)
most_efficient = max(
valid,
key=lambda k: valid[k].output_tokens / max(valid[k].cost_usd, 1e-9),
)
top_rated = max(ratings, key=ratings.get) if ratings else NoneBerikut sekilas tentang apa yang dilakukan kedua fungsi ini:
Fungsi render_metrics_table() mengiterasi setiap RunResult dan membangun kamus baris untuk tiap mode. Delapan kolom mencakup perbandingan lengkap, termasuk waktu (latensi, tok/s), skala (token masukan dan keluaran, kata pemikiran), uang (estimasi biaya), dan penilaian manusia (rating pengguna).
Fungsi render_winner_summary() terlebih dahulu menyaring run yang gagal sebelum menghitung pemenang, sehingga satu kesalahan API tidak pernah mengubah hasil. Kemudian ia menemukan juara di empat dimensi independen seperti kecepatan waktu dinding, biaya mentah, efisiensi keluaran, dan penilaian pengguna.
Keempat kategori ini sengaja dipisahkan daripada digabung menjadi satu skor karena komposit berbobot akan mengharuskan aplikasi memutuskan bahwa latensi lebih penting daripada biaya, yang merupakan keputusan produk, bukan keputusan kerangka kerja.
Aplikasi juga menampilkan pemenang yang diprediksi per tugas, mendorong pengguna untuk mengonfirmasi apakah cocok:
st.markdown(
f"> **Expected winner for this task type:** {expected} — "
"does your result match? Rate answers to confirm.",
)Seluruh aplikasi berada dalam satu berkas app.py dengan dua dependensi, dan untuk memulainya diperlukan dua perintah:
# Set your API key
export DEEPSEEK_API_KEY="sk-..."
# Run
streamlit run app.pyAplikasi akan terbuka di peramban Anda pada localhost:8501. Pilih templat tugas dari dropdown, opsional sunting prompt, lalu klik Run Arena. Bilah progres akan diperbarui saat tiap mode selesai. Hasil disimpan di st.session_state sehingga Anda dapat beralih tab dan memberi penilaian tanpa memicu run ulang.
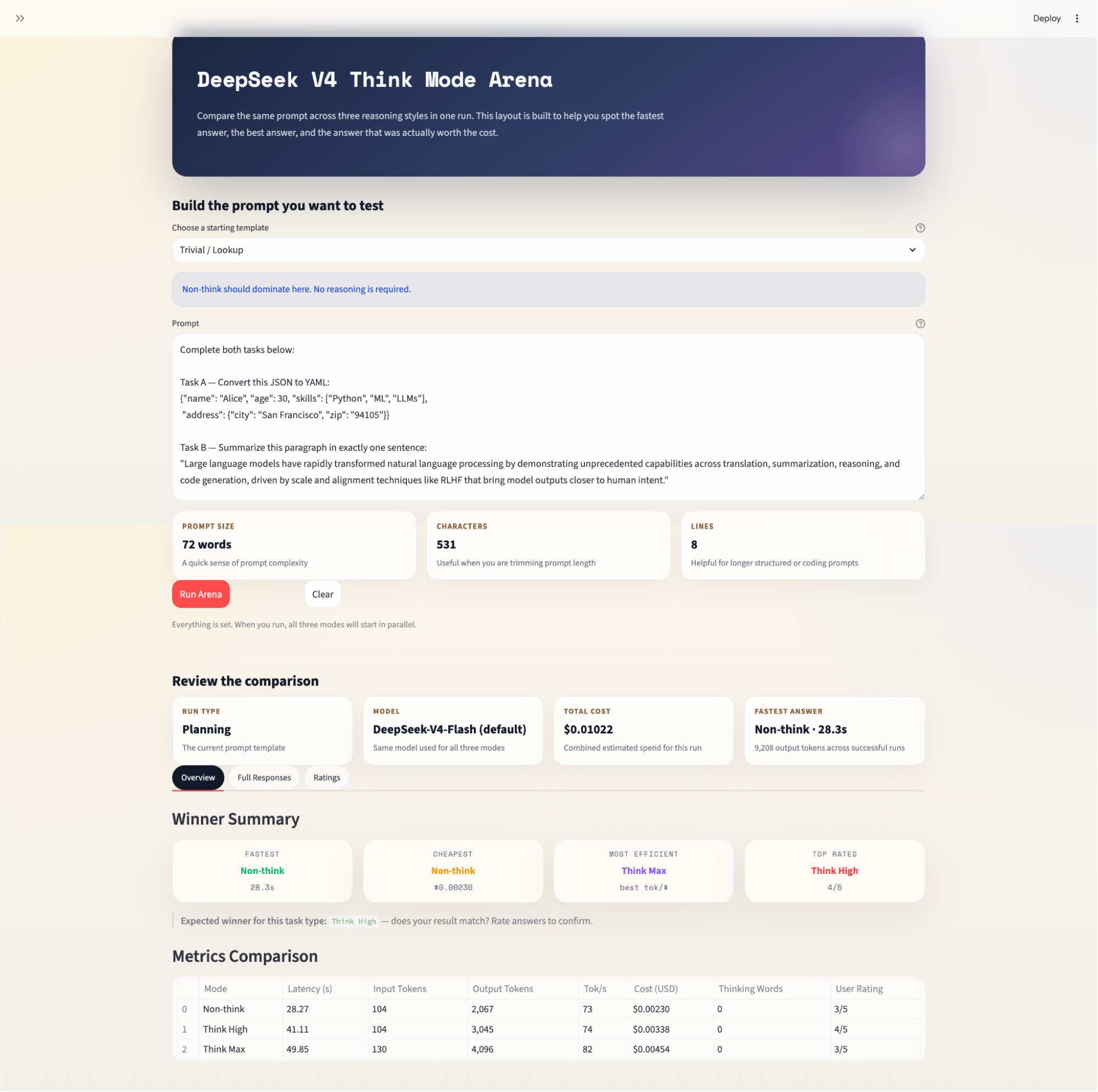
Catatan tentang harga: DeepSeek telah menyesuaikan tarif API V4 secara signifikan sejak peluncuran. V4-Pro saat ini sedang diskon promosi, dan harga cache-hit dipotong menjadi sepersepuluh dari tarif miss pada April 2026. Angka biaya yang ditampilkan di aplikasi mencerminkan tarif saat ini namun dapat berubah. Selalu verifikasi di api-docs.deepseek.com/quick_start/pricing sebelum menggunakan model apa pun.
Dalam tutorial ini, kita membangun aplikasi Streamlit yang menjalankan prompt yang sama di tiga mode penalaran DeepSeek V4 secara paralel dan membandingkan hasilnya pada latensi, biaya, penggunaan token, kedalaman jejak pemikiran, dan kualitas yang dinilai pengguna. Pilihan arsitektural kunci adalah:
ThreadPoolExecutor untuk paralelisme sejati, yang berarti total waktu dinding sama dengan mode paling lambat, bukan jumlah ketiganya
Parameter API thinking dan reasoning_effort membantu memastikan kontrol mode yang bersih, eksplisit, dan selaras dengan API DeepSeek alih-alih bergantung pada pengarah system prompt
Estimasi biaya yang menyadari cache membantu memisahkan token masukan menjadi bagian cache-hit dan cache-miss, menghasilkan angka biaya yang secara material lebih akurat, terutama pada run berulang di mana diskon cache hangat dapat membuat Non-think tampak hampir gratis
Untuk memperluas proyek ini, pertimbangkan menambahkan lapisan LLM-as-judge (menggunakan model terpisah seperti Claude atau GPT-4 untuk menilai jawaban secara otomatis), melakukan caching respons berdasarkan hash prompt untuk menghindari menjalankan ulang kueri identik, atau menambahkan sumbu antar-model yang mempertandingkan Flash Think Max melawan Pro Think High, yang merupakan pertanyaan paritas biaya yang benar-benar menarik yang diangkat paper V4 namun belum sepenuhnya dijawab.
Kursus AI Teratas
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
