Tracks
AIエージェントの基礎
6時間
DeepSeek V4は、DeepSeek AIによる最新世代のMixture-of-Experts(MoE)言語モデルです。シリーズには2つのバリアントがあります。
いくつかのアーキテクチャ上の改良点により、V4は従来世代と一線を画しています。
図:DeepSeek V4シリーズのアーキテクチャ(DeepSeekテクニカルレポート)
両モデルは、Non-think、Think High、Think Maxという3つの明確に異なる推論努力モードをサポートしており、本チュートリアルで掘り下げて比較します。
DeepSeekチームはV4モデルの性能を同等モデルと比較しました。結果は以下のとおりです。
図:DeepSeek V4シリーズのベンチマーク性能(DeepSeekテクニカルレポート)
左の棒グラフは、知識、推論、エージェント的タスクにおいてV4-Pro-Maxがクローズドソース最前線モデル群の中でどの位置にいるかを示します。右の2つのプロットは、効率向上がなぜ重要かを示し、より意外性のある結果です。DeepSeek-V4-Pro-Max(Think Max推論モード)は、クローズドソース最前線モデルに対して競争力のある結果を達成しています。
|
ベンチマーク |
DeepSeek-V4-Pro Max |
Claude Opus 4.6 Max |
Gemini-3.1-Pro High |
|
LiveCodeBench(Pass@1) |
93.5 |
88.8 |
91.7 |
|
Codeforcesレーティング |
3206 |
— |
3052 |
|
GPQA Diamond(Pass@1) |
90.1 |
91.3 |
94.3 |
|
SWE Verified(Resolved) |
80.6 |
80.8 |
80.6 |
Codeforcesのレーティング3206はV4-Pro-MaxをLegendary Grandmasterに位置づけ、アリーナにおけるコーディング課題は本格的なストレステストと言えます。
アプリを作る前に、各モードが実際に何をするのかを理解しておきましょう。
Non-think:モデルは内部の思考連鎖なしに直接応答します。形式変換、簡単な検索、1文サマリーなど、深さより速度が重要なタスクに最適です。Think High:回答を確定する前に段階的に推論します。デバッグ、システム設計、計画など、適度に複雑なタスクで深さとコストのバランスが良好です。Think Max:推論を最大限まで深め、複数のアプローチを模索し、論理を厳密に検証し、確信が持てた時点でのみ最終回答を出します。そのため、Think Maxは困難な数学証明、複雑なマルチファイルのリファクタリング、または誤った自信満々の回答が遅くても検証済みの回答より悪い場合に最適です。このチュートリアルが示す重要な洞察は、Think Maxが常に勝つわけではないという点です。些細なタスクでは、同等の品質に対して計算資源を浪費します。アリーナの目的は、実際のレイテンシ、トークン数、コスト、ユーザー評価に基づいて、タスクごとに本当に使う価値があるモードを明らかにすることです。
他の最先端LLMとの比較に興味がある場合は、Claude Opus 4.7とDeepSeek V4の比較やGPT-5.5とDeepSeek V4の比較の記事をおすすめします。
このチュートリアルでは、次のことを行うStreamlitアプリケーションを構築します。
ユーザーからプロンプトとタスクカテゴリを受け取る
PythonのThreadPoolExecutorを使い、各推論モードに対して並列に3つのAPI呼び出しを実行
モデルの出力中の<think>...</think>ブロックから思考トレースを解析
モードごとにレイテンシ、トークン数、推定コストを追跡
指標、ユーザー評価システム、勝者サマリーを備えた横並び比較を提示
完成版のアプリは単一のapp.pyで動作し、外部データベースやバックグラウンドサービスは不要です。
このチュートリアルの完全なコードは私のGitHubリポジトリで公開しています。
まずプロジェクトフォルダを作成し、必要な2つのパッケージをインストールします。
mkdir deepseek-arena && cd deepseek-arena
pip install streamlit>=1.32.0 openai>=1.12.0openaiライブラリを使うのは、DeepSeekのAPIがOpenAI互換だからです。つまり、OpenAIクライアントのベースURLをDeepSeekに向けるだけで他の変更は不要です。DeepSeek専用SDKは必要ありません。
APIキーを platform.deepseek.comから取得し、環境変数に設定します。
export DEEPSEEK_API_KEY="sk-..."環境設定が済んだら、モデルとモードの構成に進みます。
ロジックを書く前に、インポート、モデル識別子、推論モードの構成、料金の定数を定義します。これらの辞書が、モデル選択のドロップダウン、各モードを駆動するAPIパラメータ、UIのカラースキーム、比較パネルに表示するコスト見積もりなど、アプリ全体の挙動を制御します。
import os
import time
import concurrent.futures
from dataclasses import dataclass
from typing import Optional, Dict
import streamlit as st
from openai import OpenAI
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
DEEPSEEK_API_KEY_ENV = "DEEPSEEK_API_KEY"
MODELS = {
"DeepSeek-V4-Flash (default)": "deepseek-v4-flash",
"DeepSeek-V4-Pro": "deepseek-v4-pro",
}
MODES: Dict[str, dict] = {
"Non-think": {
"icon": "",
"color": "#10b981",
"badge": "green",
"desc": "Fast, direct answers — no internal reasoning",
"thinking_type": "disabled",
"reasoning_effort": None,
},
"Think High": {
"icon": "",
"color": "#3b82f6",
"badge": "blue",
"desc": "Careful step-by-step reasoning before responding",
"thinking_type": "enabled",
"reasoning_effort": "high",
},
"Think Max": {
"icon": "",
"color": "#ef4444",
"badge": "red",
"desc": "Exhaustive reasoning — push analysis to the limit",
"thinking_type": "enabled",
"reasoning_effort": "max",
},
}
PRICING = {
"deepseek-v4-flash": {
"input_cache_hit": 0.0028,
"input_cache_miss": 0.14,
"output": 0.28,
},
"deepseek-v4-pro": {
"input_cache_hit": 0.003625,
"input_cache_miss": 0.435,
"output": 0.87,
},
}いくつかの設計上の選択について補足します。
思考モードのパラメータ: MODESの各エントリは、システムプロンプトではなく2つのAPIフィールドを持ちます。thinking_typeとreasoning_effort("high"、"max"、None)です。thinking_typeはextra_body={"thinking": {"type": ...}}経由で、reasoning_effortはリクエストのトップレベルで渡します。Non-thinkではthinking_typeを"disabled"に設定し、reasoning_effortはNoneのままにするため、思考ボディ自体が送信されません。
デフォルトモデルはFlash: Flashはトークンごとに13Bパラメータを有効化するのに対し、Proは49Bです。そのため、3モード並列呼び出しでも実験を繰り返しやすいコストで実行できます。フロンティア性能が必要なときはドロップダウンからProを選べますが、ProのThink Maxはクオータ消費が速いため、デフォルトではなくオプトインに留めるのが意図的なコストのガードレールです。
注意:上記コードの値は、現行のV4-Proのプロモーション割引を反映しています。コスト比較を公開する前に、必ず api-docs.deepseek.com/quick_start/pricingで最新料金を確認してください。新モデルのリリース後は、基本料金とプロモーション割引が頻繁に変動します。
推論比較を作る上で、タスク設計は最も見落とされがちな要素です。すべてが難しくオープンエンドなタスクだと、Think Maxが常勝となり、デモから学びが得られません。各モードが少なくとも1カテゴリで勝てるよう、難易度の全範囲を網羅するタスクセットが必要です。
TASKS = {
"Trivial / Lookup": {
"prompt": (
"Complete both tasks below:\n\n"
"Task A — Convert this JSON to YAML:\n"
'{"name": "Alice", "age": 30, "skills": ["Python", "ML", "LLMs"],\n'
' "address": {"city": "San Francisco", "zip": "94105"}}\n\n'
"Task B — Summarize this paragraph in exactly one sentence:\n"
'"Large language models have rapidly transformed natural language processing '
"by demonstrating unprecedented capabilities across translation, summarization, "
"reasoning, and code generation, driven by scale and alignment techniques like RLHF "
'that bring model outputs closer to human intent."'
),
"expected_winner": "Non-think",
"tip": "Non-think should dominate here. No reasoning is required.",
},
"Coding / Debugging": {
"prompt": (
"Find every bug in the Python code below, explain each bug clearly, "
"and provide a fully corrected version:\n\n"
"```python\n"
"def binary_search(arr, target):\n"
" left, right = 0, len(arr)\n"
" while left < right:\n"
" mid = (left + right) // 2\n"
" if arr[mid] == target:\n"
" return mid\n"
" elif arr[mid] < target:\n"
" left = mid\n"
" else:\n"
" right = mid - 1\n"
" return -1\n\n"
"print(binary_search([1, 3, 5, 7, 9], 7))\n"
"```"
),
"expected_winner": "Think High",
"tip": "Think High usually finds the bugs and explains them well.",
},
"System Design": {
"prompt": (
"Design a scalable vector search system for 100 million documents.\n\n"
"Address each of the following:\n"
"1. Indexing strategy and pipeline\n"
"2. ANN algorithm selection (HNSW vs IVF-PQ vs ScaNN — justify your choice)\n"
"3. Sharding and replication strategy\n"
"4. p99 query latency target (< 50 ms) — how do you hit it?\n"
"5. Real-time document update handling\n"
"6. Top 3 failure modes and their mitigations"
),
"expected_winner": "Think High",
"tip": "Think High often gives the best quality-per-dollar design answer.",
},
"Planning": {
"prompt": (
"Create a detailed 6-month roadmap for deploying an enterprise RAG system.\n\n"
"Include:\n"
"- Month-by-month phases with concrete, measurable milestones\n"
"- Top 5 risks and mitigation strategies\n"
"- Team roles and headcount required per phase\n"
"- Evaluation metrics for each phase (how do you know it's working?)\n"
"- Go / no-go production checklist"
),
"expected_winner": "Think High",
"tip": "Think High should produce a more structured, complete roadmap.",
},
"Math (IMO-style)": {
"prompt": (
"Solve this problem completely and verify your answer:\n\n"
"Find all positive integers n such that n² + 1 is divisible by n + 1.\n\n"
"Your answer must include:\n"
"1. A complete proof with clear logical steps\n"
"2. Verification with at least 3 concrete numerical examples\n"
"3. A rigorous argument for why your solution set is complete "
"(i.e., there are no other solutions)"
),
"expected_winner": "Think Max",
"tip": "Think Max earns its cost when thorough verification matters.",
},
}これら5つのタスクは、3つの期待勝者にきれいに対応します。
|
タスク |
期待される勝者 |
理由 |
|
Trivial / Lookup |
Non-think |
推論のオーバーヘッドは不要。思考時間は純粋な無駄 |
|
Coding / Debugging |
Think High |
一度の丁寧なロジックで全バグを捕捉。Maxの追加価値は限定的 |
|
System Design |
Think High |
深さは品質を高めるが、やり尽くしても有用なアーキテクチャは増えない |
|
Planning |
Think High |
構造化が鍵。ロードマップは証明ではない |
|
Math (IMO-style) |
Think Max |
検証が本質的。誤った証明は、遅くても正しい証明より悪い |
各タスクにはexpected_winnerフィールドも含まれます。アプリは結果表示後にこれを示し、予想勝者が維持されたのか、覆されたのかを確認できるようにします。
タスクテンプレートを定義したら、各API呼び出しの結果を保持する構造が必要です。アプリ全体で生のレスポンスオブジェクトを渡す代わりに、比較パネルに必要な指標をすべて保持するRunResultデータクラスを定義します。
@dataclass
class RunResult:
mode: str
answer: str = ""
thinking: str = ""
latency: float = 0.0
input_tokens: int = 0
output_tokens: int = 0
cost_usd: float = 0.0
error: Optional[str] = None
@property
def tokens_per_second(self) -> Optional[float]:
if self.latency > 0 and self.output_tokens > 0:
return self.output_tokens / self.latency
return None
@property
def thinking_word_count(self) -> int:
return len(self.thinking.split()) if self.thinking else 0thinkingフィールドはanswerと分離しています。これはDeepSeek V4のAPIが、応答構造においてcontentと同階層のreasoning_contentフィールドに思考連鎖を返すためです。分離しておくことで、UIは最終回答の横に折りたたみ式の推論トレースを表示でき、モードの違いが直感的にわかります。特に数学タスクではThink Maxのトレースが数千語に及ぶことがあります。
tokens_per_secondプロパティは、プロンプト長に依存しない生成スループットを測定します。出力トークン数が大きく異なる場合に、モード間の効率を比較するのに有用です。なお、Think Maxは自然にトークン数が増えるため、純粋なレイテンシだけの比較は、各モードの生成速度も併せて見ないと誤解を招きます。
APIコールのロジックを書く前に、生のSDKレスポンスとRunResultの間に位置する小さなヘルパー関数を2つ定義します。見落としがちですが、コストの精度に大きく関わります。
def get_cached_prompt_tokens(usage) -> int:
prompt_details = getattr(usage, "prompt_tokens_details", None)
if prompt_details is None:
return 0
cached_tokens = getattr(prompt_details, "cached_tokens", None)
if cached_tokens is not None:
return cached_tokens or 0
if isinstance(prompt_details, dict):
return prompt_details.get("cached_tokens", 0) or 0
return 0
def estimate_cost_usd(
model: str,
prompt_tokens: int,
completion_tokens: int,
cached_prompt_tokens: int,
) -> float:
pricing = PRICING.get(model, PRICING["deepseek-v4-flash"])
cached_tokens = min(cached_prompt_tokens, prompt_tokens)
uncached_tokens = max(prompt_tokens - cached_tokens, 0)
return (
cached_tokens / 1_000_000 * pricing["input_cache_hit"]
+ uncached_tokens / 1_000_000 * pricing["input_cache_miss"]
+ completion_tokens / 1_000_000 * pricing["output"]
)get_cached_prompt_tokens()は直接フィールドアクセスを行いません。prompt_tokens_detailsの構造はSDKのバージョン間で一貫しない可能性があるためです。まず型付き属性を確認し、次に辞書アクセスにフォールバックし、最後に例外を出さず0を返します。これはThreadPoolExecutor内で重要です。スレッドの1つで静かなエラーが起きると、そのモードのコスト見積もりが不当に低くなり、目に見える失敗が表面化しない恐れがあるからです。
estimate_cost_usd()は、プロンプトトークン数をキャッシュヒット分とミス分に分けてから料金を適用します。DeepSeekはキャッシュヒット価格をミスの1/10に引き下げたため、コールドプロンプトとウォームプロンプトの差は劇的です。同一タスクを繰り返す場合、Non-thinkはThink Maxに比べてほとんど無料のように見えることがあります。これは生成トークンが少ないからではなく、短いプロンプトがキャッシュウォームである可能性が極めて高いからです。
ここがアリーナのアーキテクチャの核です。3つのモードはThreadPoolExecutorで同時に発火し、総経過時間は3つの合計ではなく、最も遅い1つと等しくなります。
def call_mode(client: OpenAI, model: str, mode_name: str, user_prompt: str) -> RunResult:
result = RunResult(mode=mode_name)
mode_cfg = MODES[mode_name]
start = time.perf_counter()
try:
request_kwargs = {
"model": model,
"messages": [{"role": "user", "content": user_prompt}],
"max_tokens": 4096,
"extra_body": {"thinking": {"type": mode_cfg["thinking_type"]}},
}
if mode_cfg["reasoning_effort"]:
request_kwargs["reasoning_effort"] = mode_cfg["reasoning_effort"]
response = client.chat.completions.create(**request_kwargs)
result.latency = time.perf_counter() - start
message = response.choices[0].message
result.thinking = (getattr(message, "reasoning_content", None) or "").strip()
result.answer = (message.content or "").strip()
usage = response.usage
result.input_tokens = getattr(usage, "prompt_tokens", 0) or 0
result.output_tokens = getattr(usage, "completion_tokens", 0) or 0
result.cost_usd = estimate_cost_usd(
model=model,
prompt_tokens=result.input_tokens,
completion_tokens=result.output_tokens,
cached_prompt_tokens=get_cached_prompt_tokens(usage),
)
except Exception as exc:
result.latency = time.perf_counter() - start
result.error = str(exc)
return result
def run_parallel(client: OpenAI, model: str, prompt: str) -> Dict[str, RunResult]:
results: Dict[str, RunResult] = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as pool:
futures = {
pool.submit(call_mode, client, model, mode_name, prompt): mode_name
for mode_name in MODES
}
for fut in concurrent.futures.as_completed(futures):
results[futures[fut]] = fut.result()
return resultsいくつかの設計判断を強調しておきます。
request_kwargsの条件構築: Non-thinkはthinking_type: "disabled"を送り、reasoning_effortキーは送信しません。Think HighとThink Maxはthinking_type: "enabled"とそれぞれのeffortレベルを送ります。if mode_cfg["reasoning_effort"]のガードにより、Non-thinkではNoneを送るのではなく、パラメータ自体を完全に省くため、APIのバリデーションエラーを避けられます。
reasoning_contentの直接読み取り: 思考トレースはmessage.reasoning_contentからgetattr()で空文字フォールバック付きで取得します。これは<think>...</think>タグをcontent文字列からパースするより堅牢です。公式のレスポンスフィールドを使い、トレースが出ない(Non-think)ケースにも対応し、出力内にたまたま「think」という語が含まれても壊れません。
usageフィールドの防御的なgetattr(): usageの各フィールドはgetattr(..., 0) or 0でアクセスします。古いSDKやまれなレスポンスでフィールドが欠けていても、ゼロでフォールバックし、AttributeErrorで実行全体を失敗にしないようにします。
エラーハンドリング: 呼び出しが失敗した場合、RunResultにエラー文字列を保持し、例外を投げません。UIはresult.errorを確認し、3モード実行全体を落とさずに情報カードを表示します。
このステップはプレゼンテーション層を扱います。ページレイアウト、CSSデザインシステム、モードごとの結果カラム、初回表示で情報過多にならないよう整理するタブ構成です。
アプリはst.set_page_configでlayout="wide"を指定し、3カラム比較に十分な横幅を確保します。
def main():
st.set_page_config(
page_title="DeepSeek V4 Think Mode Arena",
layout="wide",
initial_sidebar_state="expanded",
)
inject_css()inject_css()はst.markdown経由でフルのデザインシステムを注入します。温かみのあるパーチメント背景、等幅見出しやメトリックチップにSpace Mono、本文にDM Sansを用います。
def render_mode_column(result: RunResult, mode_name: str):
cfg = MODES[mode_name]
badge_cls = f"mode-{cfg['badge']}"
st.markdown(
f'<div class="mode-header {badge_cls}">{mode_name}</div>',
unsafe_allow_html=True,
)
st.markdown(f'<div class="subtle-copy">{cfg["desc"]}</div>', unsafe_allow_html=True)
if result.error:
st.error(f"**API Error:** {result.error}")
return
chips = [
("Latency", f"{result.latency:.1f}s"),
("Output tokens", f"{result.output_tokens:,}"),
("Cost", f"${result.cost_usd:.5f}"),
]
if result.tokens_per_second:
chips.append(("Tok/s", f"{result.tokens_per_second:.0f}"))
chip_html = "".join(
f'<span class="metric-chip">{label} <span>{val}</span></span>'
for label, val in chips
)
st.markdown(chip_html, unsafe_allow_html=True)
if result.thinking:
with st.expander(f" Thinking trace — {result.thinking_word_count:,} words"):
preview = result.thinking[:5000]
if len(result.thinking) > 5000:
preview += "\n\n[… truncated for display …]"
st.text(preview)
elif mode_name != "Non-think":
st.caption("_No thinking trace emitted_")
st.markdown('<div class="answer-label">Final answer</div>', unsafe_allow_html=True)
st.markdown(result.answer if result.answer else "_No answer returned._")思考トレースのエクスパンダはモードの違いを直感的に示すのに有効です。難しい数学問題ではThink Maxのトレースが自己修正や検証を重ねて数千語に達する一方、Non-thinkではトレースがない場合もあります。
メインレイアウトはStreamlitのタブで情報を分離し、1画面に詰め込みすぎないようにします。
overview_tab, answers_tab, ratings_tab = st.tabs(
["Overview", "Full Responses", "Ratings"]
)「Overview」タブは勝者サマリーと指標テーブルを表示。「Full Responses」タブは思考トレース付きの3カラム比較を表示し、「Ratings」タブはモードごとのユーザー品質評価(1–5)のスライダーを表示します。
最後のステップではOverviewタブに配置する2つのコンポーネント、すなわち全ての測定次元を横並びにするフラットな指標テーブルと、4つのカテゴリで勝者を示すサマリーを構築します。
def render_metrics_table(results: Dict[str, RunResult], ratings: Dict[str, int]):
rows = []
for mode_name, res in results.items():
ok = not res.error
rows.append({
"Mode": mode_name,
"Latency (s)": f"{res.latency:.2f}" if ok else "—",
"Input Tokens": f"{res.input_tokens:,}" if ok else "—",
"Output Tokens": f"{res.output_tokens:,}" if ok else "—",
"Tok/s": f"{res.tokens_per_second:.0f}" if (ok and res.tokens_per_second) else "—",
"Est. Cost (USD)": f"${res.cost_usd:.5f}" if ok else "—",
"Thinking Words": f"{res.thinking_word_count:,}" if ok else "—",
"User Rating": f"{ratings.get(mode_name)}/5" if ratings.get(mode_name) else "—",
})
st.table(rows)
def render_winner_summary(results: Dict[str, RunResult], ratings: Dict[str, int], expected: str):
valid = {k: v for k, v in results.items() if not v.error}
fastest = min(valid, key=lambda k: valid[k].latency)
cheapest = min(valid, key=lambda k: valid[k].cost_usd)
most_efficient = max(
valid,
key=lambda k: valid[k].output_tokens / max(valid[k].cost_usd, 1e-9),
)
top_rated = max(ratings, key=ratings.get) if ratings else Noneこれら2つの関数の概要は以下のとおりです。
render_metrics_table()は各RunResultを走査し、モードごとに行ディクショナリを生成します。8列で比較を網羅し、時間(レイテンシ、Tok/s)、スケール(入力・出力トークン数、思考語数)、費用(推定コスト)、人間の判断(ユーザー評価)を含みます。
render_winner_summary()はまず失敗した実行を除外してから勝者を計算し、単一のAPIエラーで結果が歪まないようにします。そのうえで、ウォールクロックの速さ、純コスト、出力効率、ユーザー評価という4つの独立した次元で勝者を見つけます。
これら4つのカテゴリは、単一スコアに統合せずにあえて分離しています。重み付き合成には「レイテンシの重みはコストより大きい」といった判断が必要になりますが、それはフレームワークの決定ではなくプロダクトの決定だからです。
アプリはタスクごとの予想勝者も提示し、結果が一致したかを確認するよう促します。
st.markdown(
f"> **Expected winner for this task type:** {expected} — "
"does your result match? Rate answers to confirm.",
)このアプリは単一のapp.pyに収まり、依存は2つだけ。起動は次の2コマンドです。
# Set your API key
export DEEPSEEK_API_KEY="sk-..."
# Run
streamlit run app.pyアプリはブラウザのlocalhost:8501で開きます。ドロップダウンからタスクテンプレートを選び、必要に応じてプロンプトを編集し、Run Arenaをクリックしてください。進捗バーは各モードの完了に合わせて更新されます。結果はst.session_stateに保存され、タブを切り替えて評価しても再実行は発生しません。
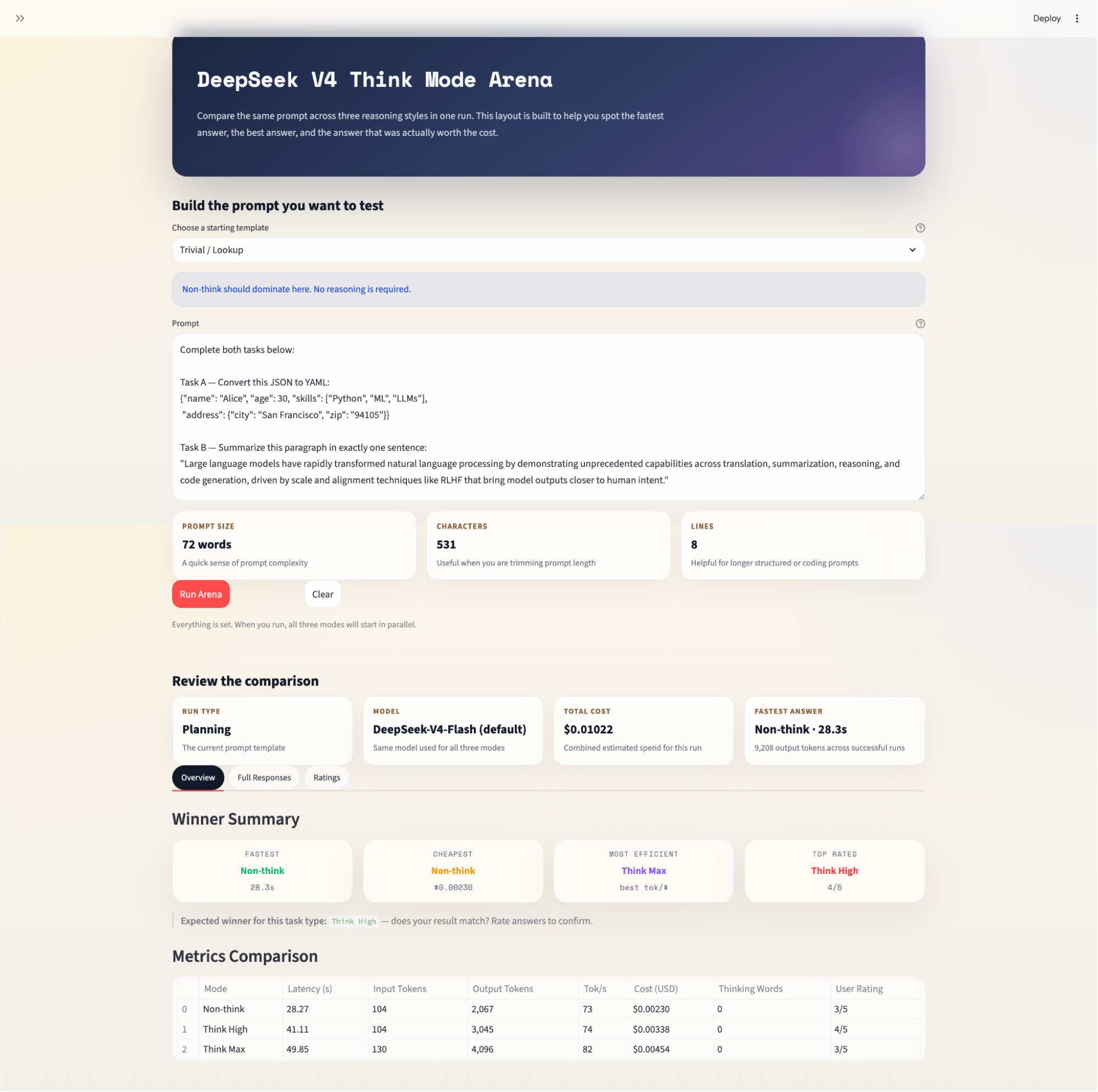
料金に関する注意: DeepSeekはローンチ以降、V4 APIの料金を大幅に調整しています。現在、V4-Proはプロモーション割引中で、キャッシュヒット価格は2026年4月にミスの1/10に引き下げられました。アプリに表示されるコストは現行料金を反映していますが、変更される可能性があります。常に api-docs.deepseek.com/quick_start/pricingで最新情報を確認してからモデルを使用してください。
このチュートリアルでは、同一プロンプトをDeepSeek V4の3つの推論モードで並列実行し、レイテンシ、コスト、トークン使用量、思考トレースの深さ、ユーザー評価の品質で比較するStreamlitアプリを構築しました。主なアーキテクチャ上の選択は次のとおりです。
ThreadPoolExecutorによる真の並列化。総経過時間は3つの合計ではなく、最も遅いモードに等しくなります。
APIパラメータthinkingとreasoning_effortを用い、システムプロンプトに頼らず、DeepSeekのAPIと整合した明確なモード制御を実現
キャッシュを考慮したコスト見積もりにより、入力トークンをキャッシュヒットとミスに分割。特に繰り返し実行では、ウォームキャッシュ割引によりNon-thinkがほぼ無料に見えるなど、実質的に精度の高いコスト数値を生成
このプロジェクトを拡張するなら、LLM-as-judgeレイヤー(ClaudeやGPT-4など別モデルで自動採点)、同一プロンプトのハッシュで応答をキャッシュして再実行を回避、あるいはFlashのThink MaxとProのThink Highを対決させるクロスモデル軸の追加などが考えられます。これはV4論文が提起している、コスト同等性に関する本質的に興味深い問いであり、まだ完全には答えが出ていません。
トップAI講座
Tracks
Courses
Courses