
Cursus
Principes fondamentaux des agents IA
6 h
DeepSeek V4 est la dernière génération de modèles de langage Mixture-of-Experts (MoE) de DeepSeek AI. La série comprend deux variantes :
Plusieurs innovations architecturales distinguent V4 de ses prédécesseurs :
Figure : architecture de la série DeepSeek V4 (rapport technique DeepSeek)
Les deux modèles prennent en charge trois modes d’effort de raisonnement distincts, Non-think, Think High et Think Max, que nous allons explorer et comparer dans ce tutoriel.
L’équipe DeepSeek a comparé les performances du modèle V4 à celles de ses homologues. Voici les principaux résultats :
Figure : performances de benchmark de la série DeepSeek V4 (rapport technique DeepSeek)
L’histogramme de gauche situe V4-Pro-Max par rapport aux modèles propriétaires de pointe sur des tâches de connaissances, de raisonnement et d’agentivité. Les deux graphiques de droite montrent pourquoi les gains d’efficacité comptent — et ce sont les résultats les plus surprenants. DeepSeek-V4-Pro-Max (le mode de raisonnement Think Max) obtient des résultats compétitifs face aux modèles propriétaires de premier plan :
|
Benchmark |
DeepSeek-V4-Pro Max |
Claude Opus 4.6 Max |
Gemini-3.1-Pro High |
|
LiveCodeBench (Pass@1) |
93,5 |
88,8 |
91,7 |
|
Codeforces Rating |
3206 |
— |
3052 |
|
GPQA Diamond (Pass@1) |
90,1 |
91,3 |
94,3 |
|
SWE Verified (Resolved) |
80,6 |
80,8 |
80,6 |
La note Codeforces de 3206 place V4-Pro-Max au niveau « Legendary Grandmaster », ce qui rend les tâches de code de notre arène particulièrement intéressantes comme test de résistance.
Avant de construire l’appli, il vaut la peine de comprendre ce que fait chaque mode :
Non-think : le modèle répond directement, sans chaîne de pensée interne. Idéal lorsque la vitesse prime sur la profondeur : conversion de format, recherches simples, résumés en une phrase.Think High : le modèle raisonne étape par étape avant de s’engager sur une réponse. Bon compromis entre profondeur et coût pour des tâches modérément complexes comme le débogage, la conception de systèmes et la planification.Think Max : le modèle pousse le raisonnement au maximum, explore plusieurs approches, vérifie rigoureusement sa logique et ne s’engage qu’une fois sûr de sa réponse. C’est le meilleur choix pour les preuves mathématiques difficiles, les refactorings multi-fichiers complexes, ou toute tâche où une réponse fausse mais assurée est pire qu’une réponse plus lente mais vérifiée.L’enseignement clé de ce tutoriel est que Think Max ne gagne pas toujours. Sur des tâches triviales, il gaspille du calcul pour une qualité identique. L’objectif de l’arène est de révéler quel mode vaut réellement la peine selon le type de tâche, sur la base de la latence réelle, des tokens, du coût et des évaluations utilisateur.
Si vous souhaitez voir comment le modèle se compare à d’autres LLM de pointe, nous vous recommandons de lire nos articles Claude Opus 4.7 vs DeepSeek V4 et GPT-5.5 vs DeepSeek V4.
Dans ce tutoriel, nous allons construire une application Streamlit qui :
Accepte un prompt et une catégorie de tâche fournis par l’utilisateur
Lance trois appels API en parallèle, un par mode de raisonnement, avec ThreadPoolExecutor de Python
Extrait les traces de réflexion des blocs <think>...</think> dans la sortie du modèle
Suit la latence, le nombre de tokens et le coût estimé par mode
Présente une comparaison côte à côte avec métriques, système de notation utilisateur et récapitulatif du gagnant
L’application complète tient dans un unique fichier app.py, sans base de données ni services en arrière-plan.
Le code complet de ce tutoriel est disponible dans mon dépôt GitHub.
Créez d’abord un dossier de projet et installez les deux packages requis :
mkdir deepseek-arena && cd deepseek-arena
pip install streamlit>=1.32.0 openai>=1.12.0La bibliothèque openai est utilisée ici car l’API de DeepSeek est compatible avec OpenAI, ce qui signifie que nous pouvons simplement diriger le client OpenAI vers l’URL de base de DeepSeek sans autre changement. Aucun SDK spécifique à DeepSeek n’est nécessaire.
Récupérez une clé API sur platform.deepseek.com et définissez-la comme variable d’environnement :
export DEEPSEEK_API_KEY="sk-..."Maintenant que l’environnement est prêt, passons à la configuration des modèles et de leurs modes.
Avant d’écrire la logique, définissons les imports, les identifiants des modèles, les configurations des modes de raisonnement et les constantes de prix. Ces dictionnaires pilotent le comportement global de l’appli : liste déroulante des modèles, paramètres API propres à chaque mode, palette de couleurs de l’UI et estimations de coût affichées dans le panneau de comparaison.
import os
import time
import concurrent.futures
from dataclasses import dataclass
from typing import Optional, Dict
import streamlit as st
from openai import OpenAI
DEEPSEEK_BASE_URL = "https://api.deepseek.com"
DEEPSEEK_API_KEY_ENV = "DEEPSEEK_API_KEY"
MODELS = {
"DeepSeek-V4-Flash (default)": "deepseek-v4-flash",
"DeepSeek-V4-Pro": "deepseek-v4-pro",
}
MODES: Dict[str, dict] = {
"Non-think": {
"icon": "",
"color": "#10b981",
"badge": "green",
"desc": "Réponses rapides et directes — sans raisonnement interne",
"thinking_type": "disabled",
"reasoning_effort": None,
},
"Think High": {
"icon": "",
"color": "#3b82f6",
"badge": "blue",
"desc": "Raisonnement pas à pas avant de répondre",
"thinking_type": "enabled",
"reasoning_effort": "high",
},
"Think Max": {
"icon": "",
"color": "#ef4444",
"badge": "red",
"desc": "Raisonnement exhaustif — pousser l’analyse au maximum",
"thinking_type": "enabled",
"reasoning_effort": "max",
},
}
PRICING = {
"deepseek-v4-flash": {
"input_cache_hit": 0.0028,
"input_cache_miss": 0.14,
"output": 0.28,
},
"deepseek-v4-pro": {
"input_cache_hit": 0.003625,
"input_cache_miss": 0.435,
"output": 0.87,
},
}Quelques choix de conception méritent d’être détaillés :
Paramètres du mode de réflexion : chaque entrée de MODES fournit deux champs d’API plutôt qu’un system prompt. Il s’agit de thinking_type et reasoning_effort ("high", "max" ou None). thinking_type est transmis via extra_body={"thinking": {"type": ...}}, et reasoning_effort est un paramètre de requête de premier niveau. Non-think définit thinking_type sur "disabled" et laisse reasoning_effort à None, de sorte qu’aucun corps de réflexion n’est envoyé.
Flash comme modèle par défaut : Flash active 13 B de paramètres par token contre 49 B pour Pro, ce qui rend les triples appels parallèles suffisamment économiques pour l’expérimentation. Pro reste disponible dans le menu déroulant quand vous avez besoin de performances de pointe, mais Think Max sur Pro consomme vite le quota ; le garder en opt-in plutôt qu’en valeur par défaut constitue un garde-fou de coûts délibéré.
Remarque : les valeurs du code ci-dessus reflètent V4-Pro à son tarif promotionnel actuel. Vérifiez toujours les tarifs à jour sur api-docs.deepseek.com/quick_start/pricing avant de publier des comparaisons de coûts, car les tarifs de base et les promotions évoluent souvent après la sortie d’un nouveau modèle.
La conception des tâches est l’élément le plus sous-estimé pour comparer des modes de raisonnement. Si toutes les tâches sont difficiles et ouvertes, Think Max gagne à chaque fois et la démo n’enseigne rien. L’ensemble doit couvrir tout l’éventail de difficulté afin que chaque mode gagne au moins dans une catégorie.
TASKS = {
"Trivial / Lookup": {
"prompt": (
"Complete both tasks below:\n\n"
"Task A — Convert this JSON to YAML:\n"
'{"name": "Alice", "age": 30, "skills": ["Python", "ML", "LLMs"],\n'
' "address": {"city": "San Francisco", "zip": "94105"}}\n\n'
"Task B — Summarize this paragraph in exactly one sentence:\n"
'"Large language models have rapidly transformed natural language processing '
"by demonstrating unprecedented capabilities across translation, summarization, "
"reasoning, and code generation, driven by scale and alignment techniques like RLHF "
'that bring model outputs closer to human intent."'
),
"expected_winner": "Non-think",
"tip": "Non-think should dominate here. No reasoning is required.",
},
"Coding / Debugging": {
"prompt": (
"Find every bug in the Python code below, explain each bug clearly, "
"and provide a fully corrected version:\n\n"
"```python\n"
"def binary_search(arr, target):\n"
" left, right = 0, len(arr)\n"
" while left < right:\n"
" mid = (left + right) // 2\n"
" if arr[mid] == target:\n"
" return mid\n"
" elif arr[mid] < target:\n"
" left = mid\n"
" else:\n"
" right = mid - 1\n"
" return -1\n\n"
"print(binary_search([1, 3, 5, 7, 9], 7))\n"
"```"
),
"expected_winner": "Think High",
"tip": "Think High usually finds the bugs and explains them well.",
},
"System Design": {
"prompt": (
"Design a scalable vector search system for 100 million documents.\n\n"
"Address each of the following:\n"
"1. Indexing strategy and pipeline\n"
"2. ANN algorithm selection (HNSW vs IVF-PQ vs ScaNN — justify your choice)\n"
"3. Sharding and replication strategy\n"
"4. p99 query latency target (< 50 ms) — how do you hit it?\n"
"5. Real-time document update handling\n"
"6. Top 3 failure modes and their mitigations"
),
"expected_winner": "Think High",
"tip": "Think High often gives the best quality-per-dollar design answer.",
},
"Planning": {
"prompt": (
"Create a detailed 6-month roadmap for deploying an enterprise RAG system.\n\n"
"Include:\n"
"- Month-by-month phases with concrete, measurable milestones\n"
"- Top 5 risks and mitigation strategies\n"
"- Team roles and headcount required per phase\n"
"- Evaluation metrics for each phase (how do you know it's working?)\n"
"- Go / no-go production checklist"
),
"expected_winner": "Think High",
"tip": "Think High should produce a more structured, complete roadmap.",
},
"Math (IMO-style)": {
"prompt": (
"Solve this problem completely and verify your answer:\n\n"
"Find all positive integers n such that n² + 1 is divisible by n + 1.\n\n"
"Your answer must include:\n"
"1. A complete proof with clear logical steps\n"
"2. Verification with at least 3 concrete numerical examples\n"
"3. A rigorous argument for why your solution set is complete "
"(i.e., there are no other solutions)"
),
"expected_winner": "Think Max",
"tip": "Think Max earns its cost when thorough verification matters.",
},
}Ces cinq tâches couvrent clairement les trois gagnants attendus :
|
Tâche |
Gagnant attendu |
Raisonnement |
|
Trivial / Lookup |
Non-think |
Aucun surcoût de raisonnement nécessaire ; le temps de réflexion est du pur gaspillage |
|
Coding / Debugging |
Think High |
Un passage méthodique suffit à trouver tous les bugs ; Max n’ajoute qu’une valeur marginale |
|
System Design |
Think High |
La profondeur améliore la qualité ; l’exhaustivité n’apporte pas d’architecture utile |
|
Planning |
Think High |
La structure prime sur la puissance brute ; une feuille de route n’est pas une preuve |
|
Math (IMO-style) |
Think Max |
La vérification est critique ; une mauvaise preuve est pire qu’une bonne, plus lente |
Chaque tâche comporte aussi un champ expected_winner. L’appli l’affiche après réception des résultats, pour que les utilisateurs puissent vérifier si le gagnant attendu s’est confirmé… ou non.
Maintenant que les modèles de tâches sont définis, il nous faut une structure pour stocker les résultats de chaque appel API. Plutôt que de propager des objets de réponse bruts dans l’appli, nous définissons une dataclass RunResult unique qui regroupe toutes les métriques nécessaires au panneau de comparaison.
@dataclass
class RunResult:
mode: str
answer: str = ""
thinking: str = ""
latency: float = 0.0
input_tokens: int = 0
output_tokens: int = 0
cost_usd: float = 0.0
error: Optional[str] = None
@property
def tokens_per_second(self) -> Optional[float]:
if self.latency > 0 and self.output_tokens > 0:
return self.output_tokens / self.latency
return None
@property
def thinking_word_count(self) -> int:
return len(self.thinking.split()) if self.thinking else 0Le champ thinking est séparé de answer car l’API DeepSeek V4 renvoie la chaîne de pensée dans un champ dédié reasoning_content, au même niveau que content. Les garder séparés permet à l’UI d’afficher une trace de raisonnement repliable à côté d’une réponse finale propre, rendant la différence de mode évidente — notamment sur les tâches de maths où la trace Think Max peut atteindre des milliers de mots.
La propriété tokens_per_second mesure le débit de génération indépendamment de la longueur du prompt. Utile pour comparer l’efficience entre modes quand les sorties diffèrent fortement. Notez que Think Max produit naturellement plus de tokens, donc comparer uniquement la latence brute peut être trompeur sans visualiser aussi la vitesse de génération.
Avant d’écrire la logique d’appel API, définissons deux petites fonctions intermédiaires entre la réponse brute du SDK et RunResult. Faciles à négliger, elles comptent pourtant beaucoup pour l’exactitude des coûts.
def get_cached_prompt_tokens(usage) -> int:
prompt_details = getattr(usage, "prompt_tokens_details", None)
if prompt_details is None:
return 0
cached_tokens = getattr(prompt_details, "cached_tokens", None)
if cached_tokens is not None:
return cached_tokens or 0
if isinstance(prompt_details, dict):
return prompt_details.get("cached_tokens", 0) or 0
return 0
def estimate_cost_usd(
model: str,
prompt_tokens: int,
completion_tokens: int,
cached_prompt_tokens: int,
) -> float:
pricing = PRICING.get(model, PRICING["deepseek-v4-flash"])
cached_tokens = min(cached_prompt_tokens, prompt_tokens)
uncached_tokens = max(prompt_tokens - cached_tokens, 0)
return (
cached_tokens / 1_000_000 * pricing["input_cache_hit"]
+ uncached_tokens / 1_000_000 * pricing["input_cache_miss"]
+ completion_tokens / 1_000_000 * pricing["output"]
)La fonction get_cached_prompt_tokens() n’accède pas directement au champ car la structure prompt_tokens_details n’est pas garantie stable selon les versions du SDK. Elle tente d’abord un attribut typé, puis un accès dict, puis renvoie zéro plutôt que de lever une exception. C’est important dans un ThreadPoolExecutor, où une erreur silencieuse dans un thread donnerait un coût artificiellement bas pour ce mode, sans échec visible.
Le helper estimate_cost_usd() sépare les tokens du prompt en parties servies depuis le cache et hors cache avant d’appliquer les tarifs. DeepSeek ayant divisé par dix le prix des hits de cache par rapport aux misses, la différence entre un prompt « chaud » et « froid » peut être spectaculaire. Sur des relances répétées, Non-think peut sembler presque gratuit face à Think Max — non pas parce qu’il a généré moins de tokens, mais parce que son prompt plus court a bien plus de chances d’être servi depuis le cache.
C’est le cœur architectural de l’arène. Les trois modes partent simultanément via un ThreadPoolExecutor, donc le temps total au mur correspond au mode le plus lent, pas à la somme des trois.
def call_mode(client: OpenAI, model: str, mode_name: str, user_prompt: str) -> RunResult:
result = RunResult(mode=mode_name)
mode_cfg = MODES[mode_name]
start = time.perf_counter()
try:
request_kwargs = {
"model": model,
"messages": [{"role": "user", "content": user_prompt}],
"max_tokens": 4096,
"extra_body": {"thinking": {"type": mode_cfg["thinking_type"]}},
}
if mode_cfg["reasoning_effort"]:
request_kwargs["reasoning_effort"] = mode_cfg["reasoning_effort"]
response = client.chat.completions.create(**request_kwargs)
result.latency = time.perf_counter() - start
message = response.choices[0].message
result.thinking = (getattr(message, "reasoning_content", None) or "").strip()
result.answer = (message.content or "").strip()
usage = response.usage
result.input_tokens = getattr(usage, "prompt_tokens", 0) or 0
result.output_tokens = getattr(usage, "completion_tokens", 0) or 0
result.cost_usd = estimate_cost_usd(
model=model,
prompt_tokens=result.input_tokens,
completion_tokens=result.output_tokens,
cached_prompt_tokens=get_cached_prompt_tokens(usage),
)
except Exception as exc:
result.latency = time.perf_counter() - start
result.error = str(exc)
return result
def run_parallel(client: OpenAI, model: str, prompt: str) -> Dict[str, RunResult]:
results: Dict[str, RunResult] = {}
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as pool:
futures = {
pool.submit(call_mode, client, model, mode_name, prompt): mode_name
for mode_name in MODES
}
for fut in concurrent.futures.as_completed(futures):
results[futures[fut]] = fut.result()
return resultsPlusieurs décisions de conception méritent d’être soulignées :
Construction conditionnelle de request_kwargs : le mode Non-think envoie thinking_type: "disabled" et omet reasoning_effort. Think High et Think Max envoient thinking_type: "enabled" et leur niveau d’effort respectif. Le garde if mode_cfg["reasoning_effort"] garantit que le paramètre est entièrement omis pour Non-think plutôt qu’envoyé avec None, ce qui pourrait déclencher une erreur de validation API.
Lecture directe de reasoning_content : la trace de chaîne de pensée est lue depuis message.reasoning_content via getattr() avec repli sur une chaîne vide. C’est plus robuste que d’analyser des balises <think>...</think> dans le contenu. On utilise le champ officiel de la réponse, on gère le cas où aucune trace n’est émise (Non-think) et on évite toute ambiguïté si le mot « think » apparaît ailleurs.
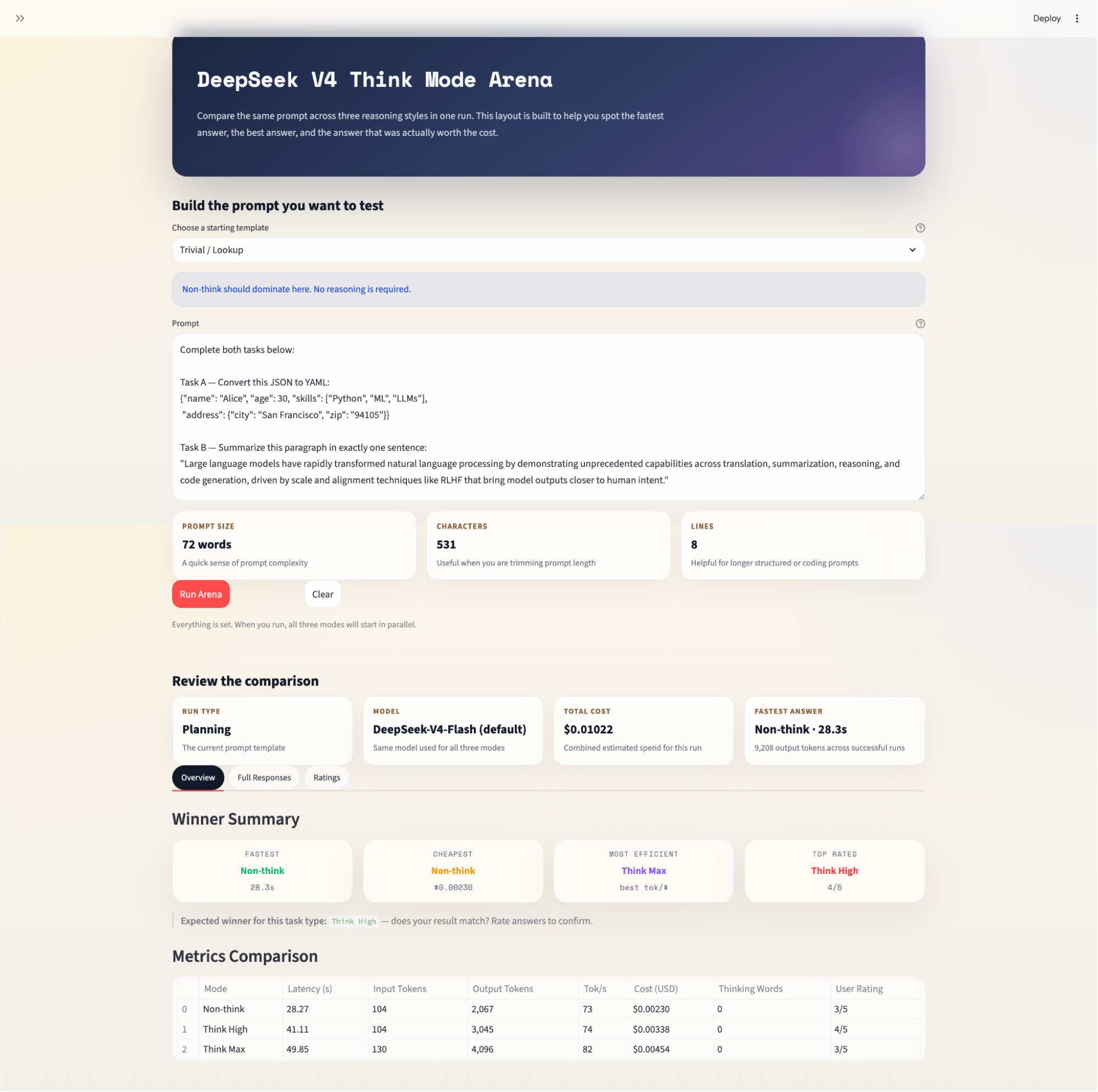
getattr() défensif sur les champs d’usage : les champs d’usage sont accédés avec getattr(..., 0) or 0 plutôt qu’en accès direct. Ainsi, si un champ manque dans une ancienne version du SDK ou une réponse atypique, on retombe sur zéro plutôt que de lever une AttributeError qui ferait échouer tout le run.
Gestion des erreurs : si un appel échoue, la dataclass RunResult stocke la chaîne d’erreur au lieu de lever l’exception. L’UI vérifie result.error et affiche une carte informative sans faire planter l’exécution des trois modes.
Cette étape couvre la couche de présentation : la mise en page, le design system CSS, la colonne de résultats par mode et la structure d’onglets qui organise la comparaison sans submerger l’utilisateur au premier chargement.
L’appli utilise st.set_page_config avec layout="wide" pour donner suffisamment d’espace horizontal à la comparaison en trois colonnes :
def main():
st.set_page_config(
page_title="DeepSeek V4 Think Mode Arena",
layout="wide",
initial_sidebar_state="expanded",
)
inject_css()La fonction inject_css() injecte un design system complet via st.markdown. Elle applique un fond parchemin chaleureux, Space Mono pour les en-têtes monospace et les pastilles de métriques, et DM Sans pour le texte courant.
def render_mode_column(result: RunResult, mode_name: str):
cfg = MODES[mode_name]
badge_cls = f"mode-{cfg['badge']}"
st.markdown(
f'<div class="mode-header {badge_cls}">{mode_name}</div>',
unsafe_allow_html=True,
)
st.markdown(f'<div class="subtle-copy">{cfg["desc"]}</div>', unsafe_allow_html=True)
if result.error:
st.error(f"**API Error:** {result.error}")
return
chips = [
("Latency", f"{result.latency:.1f}s"),
("Output tokens", f"{result.output_tokens:,}"),
("Cost", f"${result.cost_usd:.5f}"),
]
if result.tokens_per_second:
chips.append(("Tok/s", f"{result.tokens_per_second:.0f}"))
chip_html = "".join(
f'<span class="metric-chip">{label} <span>{val}</span></span>'
for label, val in chips
)
st.markdown(chip_html, unsafe_allow_html=True)
if result.thinking:
with st.expander(f" Thinking trace — {result.thinking_word_count:,} words"):
preview = result.thinking[:5000]
if len(result.thinking) > 5000:
preview += "\n\n[… truncated for display …]"
st.text(preview)
elif mode_name != "Non-think":
st.caption("_No thinking trace emitted_")
st.markdown('<div class="answer-label">Final answer</div>', unsafe_allow_html=True)
st.markdown(result.answer if result.answer else "_No answer returned._")L’accordéon de trace de réflexion rend la différence entre modes très palpable : la trace Think Max peut s’étirer sur des milliers de mots d’auto-correction et de vérifications sur un problème de maths complexe, alors que Non-think n’en aura parfois aucune.
La mise en page principale utilise des onglets Streamlit pour séparer les vues sans tout entasser sur un seul défilement :
overview_tab, answers_tab, ratings_tab = st.tabs(
["Overview", "Full Responses", "Ratings"]
)L’onglet « Overview » affiche le récapitulatif des gagnants et le tableau de métriques. « Full Responses » présente la comparaison en trois colonnes avec les traces, et « Ratings » propose des curseurs de notation (1–5) par mode.
Cette dernière étape construit les deux composants de l’onglet Overview : un tableau plat de métriques qui aligne toutes les dimensions mesurées et un récapitulatif qui désigne le gagnant selon quatre catégories.
def render_metrics_table(results: Dict[str, RunResult], ratings: Dict[str, int]):
rows = []
for mode_name, res in results.items():
ok = not res.error
rows.append({
"Mode": mode_name,
"Latency (s)": f"{res.latency:.2f}" if ok else "—",
"Input Tokens": f"{res.input_tokens:,}" if ok else "—",
"Output Tokens": f"{res.output_tokens:,}" if ok else "—",
"Tok/s": f"{res.tokens_per_second:.0f}" if (ok and res.tokens_per_second) else "—",
"Est. Cost (USD)": f"${res.cost_usd:.5f}" if ok else "—",
"Thinking Words": f"{res.thinking_word_count:,}" if ok else "—",
"User Rating": f"{ratings.get(mode_name)}/5" if ratings.get(mode_name) else "—",
})
st.table(rows)
def render_winner_summary(results: Dict[str, RunResult], ratings: Dict[str, int], expected: str):
valid = {k: v for k, v in results.items() if not v.error}
fastest = min(valid, key=lambda k: valid[k].latency)
cheapest = min(valid, key=lambda k: valid[k].cost_usd)
most_efficient = max(
valid,
key=lambda k: valid[k].output_tokens / max(valid[k].cost_usd, 1e-9),
)
top_rated = max(ratings, key=ratings.get) if ratings else NoneVoici un aperçu rapide de ce que font ces deux fonctions :
render_metrics_table() itère sur chaque RunResult et construit une ligne par mode. Les huit colonnes couvrent l’ensemble de la comparaison : temps (latence, tok/s), échelle (tokens d’entrée et de sortie, mots de réflexion), coût (estimation) et jugement humain (note utilisateur).
render_winner_summary() filtre d’abord les exécutions en échec avant de calculer les gagnants, de sorte qu’une seule erreur API ne fausse pas les résultats. Elle désigne ensuite le champion sur quatre dimensions indépendantes : vitesse réelle, coût brut, efficience de sortie et note utilisateur.
Ces quatre catégories sont volontairement séparées plutôt que combinées en un score unique, car un agrégat pondéré impliquerait de décider que la latence compte plus que le coût — un choix produit, pas un choix de framework.
L’appli affiche aussi le gagnant prédit par type de tâche, en invitant l’utilisateur à confirmer si cela correspond :
st.markdown(
f"> **Expected winner for this task type:** {expected} — "
"does your result match? Rate answers to confirm.",
)Toute l’appli tient dans un fichier app.py avec deux dépendances, et le démarrage se fait en deux commandes :
# Set your API key
export DEEPSEEK_API_KEY="sk-..."
# Run
streamlit run app.pyL’appli s’ouvre dans votre navigateur à l’adresse localhost:8501. Sélectionnez un modèle de tâche dans la liste, modifiez éventuellement le prompt, puis cliquez sur Run Arena. Une barre de progression se met à jour à mesure que chaque mode termine. Les résultats sont conservés dans st.session_state afin que vous puissiez changer d’onglet et noter les réponses sans relancer l’exécution.
Remarque sur les tarifs : DeepSeek a fortement révisé les tarifs de l’API V4 depuis le lancement. V4-Pro bénéficie actuellement d’une promotion, et en avril 2026, les prix cache-hit ont été réduits à un dixième des prix cache-miss. Les coûts affichés dans l’appli reflètent ces tarifs actuels mais peuvent évoluer. Vérifiez toujours sur api-docs.deepseek.com/quick_start/pricing avant d’utiliser un modèle.
Dans ce tutoriel, nous avons construit une application Streamlit qui exécute le même prompt sur les trois modes de raisonnement de DeepSeek V4 en parallèle et compare les résultats selon la latence, le coût, l’usage des tokens, la profondeur de la trace de réflexion et la qualité notée par les utilisateurs. Les choix architecturaux clés étaient :
ThreadPoolExecutor pour un parallélisme réel, ce qui signifie que le temps total au mur correspond au mode le plus lent et non à la somme des trois
Les paramètres d’API thinking et reasoning_effort pour garantir un pilotage clair et explicite des modes, aligné sur l’API DeepSeek plutôt que sur un system prompt
Une estimation de coût tenant compte du cache, qui sépare les tokens d’entrée en parts cache-hit et cache-miss, pour des chiffres sensiblement plus justes — surtout lors des exécutions répétées où les remises « cache chaud » peuvent rendre Non-think quasi gratuit
Pour prolonger ce projet, envisagez d’ajouter une couche LLM-as-judge (en utilisant un modèle séparé comme Claude ou GPT-4 pour noter automatiquement), de mettre en cache les réponses sur le hash du prompt pour éviter les relances identiques, ou d’ajouter un axe inter-modèles opposant Flash Think Max à Pro Think High : une vraie question de parité-coût soulevée par le papier V4 mais pas entièrement tranchée.
Meilleures formations en IA
Cursus
Cours
Cours
blog
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
Kurtis Pykes
15 min
Tutoriel
Tutoriel
Matt Crabtree

