
Program
Yapay Zeka Uygulamaları Geliştirme
21 sa
Recall ile zenginleştirilmiş üretim (RAG), belge getirimi ile doğal dil üretimini birleştirerek daha doğru ve bağlamsal olarak farkında yanıtlar oluşturur.
Temel RAG etkili olsa da, karmaşık sorgular, halüsinasyonlar ve çok turlu konuşmalarda bağlamı koruma konularında zorlanır.
Bu blogda, getirimin doğruluğunu, üretimin kalitesini ve genel sistem performansını artırarak bu zorlukları ele alan gelişmiş teknikleri inceleyeceğim.
Bunu bir mülakat hazırlığı için okuyorsanız, En İyi 30 RAG Mülakat Sorusu ve Cevabı makalesine mutlaka göz atın.
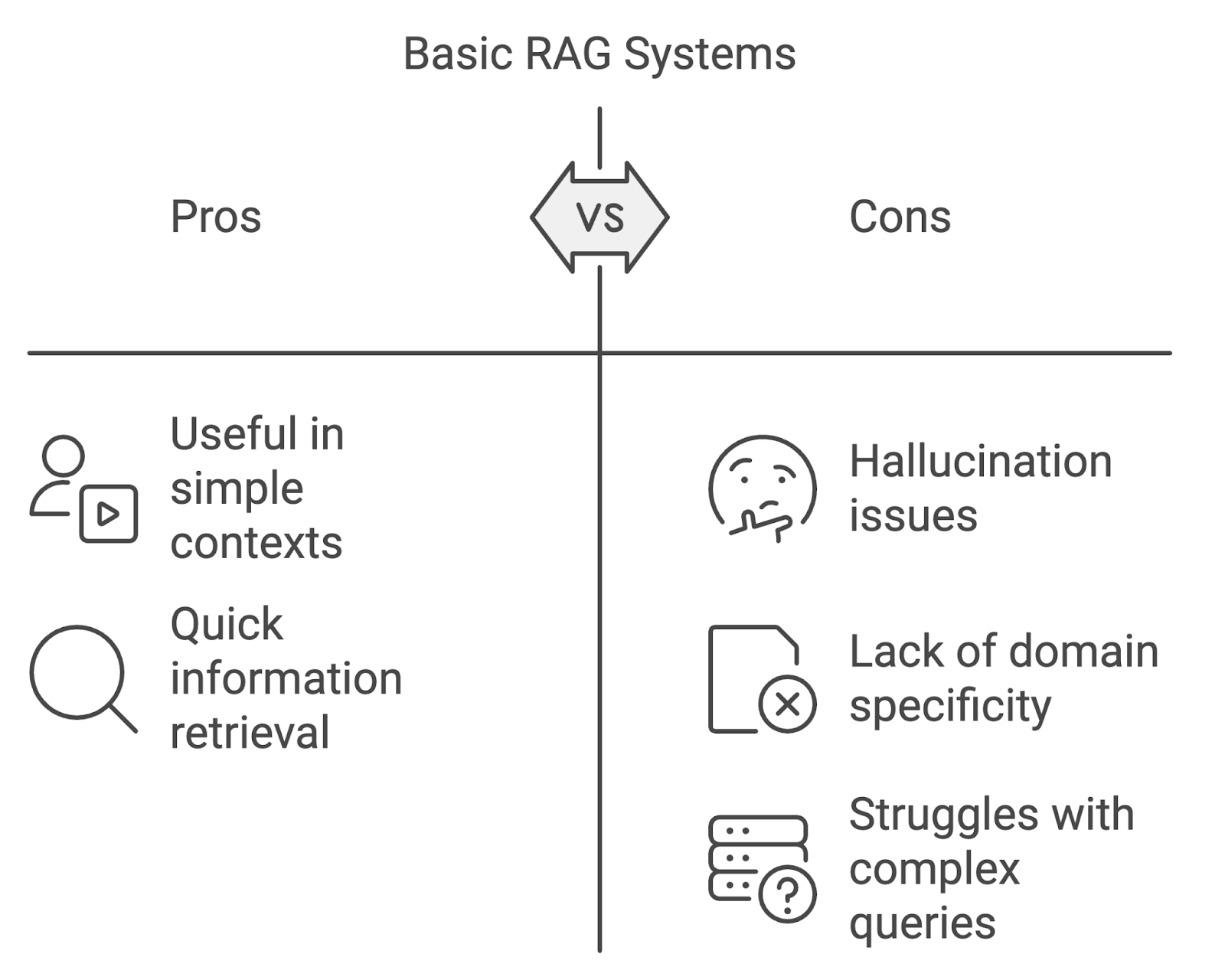
Temel RAG uygulamaları faydalı olsa da, özellikle daha talepkâr bağlamlarda uygulandıklarında bazı sınırlamalara sahiptir.
En belirgin sorunlardan biri, modelin, getirilen belgeler tarafından desteklenmeyen veya olgusal olarak yanlış içerik üretmesi olan halüsinasyondur. Bu durum, özellikle tıp veya hukuk gibi yüksek doğruluk gerektiren alanlarda sistemin güvenilirliğini zedeler.
Standart RAG modelleri alan-özel sorgularla uğraşırken zorlanabilir. Getirim ve üretim süreçleri uzmanlaşmış alanların inceliklerine göre uyarlanmadığında, sistem alakasız veya yanlış bilgi getirme riski taşır.
Bir diğer zorluk, karmaşık, çok adımlı sorguları veya çok turlu konuşmaları yönetmektir. Temel RAG sistemleri, etkileşimler boyunca bağlamı korumakta sıklıkla zorlanır ve bu da kopuk veya eksik yanıtlara yol açar. Kullanıcı sorguları daha karmaşık hale geldikçe, RAG sistemlerinin de bu artan karmaşıklığı ele alacak şekilde evrilmesi gerekir.
Şema napkin.ai ile oluşturulmuştur
Gelişmiş getirim teknikleri, getirilen belgelerin hem alaka düzeyini hem de kapsamını artırmaya odaklanır. Yoğun getirim, hibrit arama, yeniden sıralama ve sorgu genişletme gibi teknikler, anahtar kelime tabanlı getirimin sınırlamalarını ele alır.
Yoğun getirim ve hibrit arama, getirim doğruluğunu ve alaka düzeyini iyileştirmek için temel tekniklerdir. TF-IDF veya BM25 gibi yöntemler, sorgular belgelerden farklı şekilde ifade edildiğinde anlamsal kavrayışta genellikle zorlanır.
DPR (Dense Passage Retrieval) gibi yoğun getirim, sorguları ve belgeleri yoğun vektör temsillerine eşleyen derin öğrenmeden yararlanır ve metnin anlamını salt anahtar kelimelerin ötesinde yakalar.
Hibrit arama, seyrek ve yoğun getirimi harmanlayarak, anahtar kelime eşleştirmeyi anlamsal benzerlikle birleştirir; bu da karmaşık sorgular için etkili olmasını sağlar.
Yeniden sıralama, getirilen belgelerin, üretim bileşenine iletilmeden önce listesini iyileştirmek için kullanılan bir diğer gelişmiş tekniktir. Tipik bir RAG sisteminde, ilk getirim aşaması alaka düzeyi değişen geniş bir belge kümesi üretebilir.
Yeniden sıralamanın rolü, bu belgeleri dil modelinin kullanımı için en alakalı olanları önceliklendirecek şekilde yeniden düzenlemektir. Yeniden sıralama, sorgu-belge benzerliğine dayalı basit bir puanlamadan, her bir belgenin alaka düzeyini tahmin etmek üzere eğitilmiş daha karmaşık makine öğrenimi modellerine kadar farklı şekillerde yapılabilir.
Yeniden sıralamayı nasıl uygulayacağınızı, RankGPT ile yeniden sıralama konulu bu öğreticide öğrenebilirsiniz.
Sorgu genişletme, kullanıcının sorgusunu, alakalı belgeleri getirme olasılığını artıran ek terimlerle zenginleştirmeyi içerir. Şu yollarla gerçekleştirilebilir:
Örneğin, özgün sorgu “sağlık hizmetlerinde yapay zeka” ise, sorgu genişletmeye “AI”, “makine öğrenimi” veya “sağlık teknolojisi” gibi ilgili terimler eklenebilir; böylece daha geniş bir getirim ağı sağlanır.
RAG sistemlerinde yalnızca belgeleri getirmek yeterli değildir; bu belgelerin alaka düzeyi ve kalitesini sağlamak nihai çıktıyı iyileştirmenin anahtarıdır. Bu amaçla, getirilen içeriği arıtıp filtreleyen gelişmiş teknikler hayati önem taşır.
Bu yöntemler, gürültüyü azaltır, alakayı artırır ve üretim sürecinde dil modelini en önemli bilgilere odaklar.
Gelişmiş filtreleme teknikleri, alakasız veya düşük kaliteli belgeleri hariç tutmak için meta veriler veya içerik tabanlı kurallar kullanır; böylece yalnızca en alakalı sonuçların iletilmesini sağlar.
Bağlam damıtma, getirilen belgeleri özetleyerek veya yoğunlaştırarak dil modelini en önemli bilgi parçalarına odaklama sürecidir. Bu, getirilen belgeler çok fazla alakasız içerik içerdiğinde veya sorgu karmaşık, çok adımlı akıl yürütme gerektirdiğinde kullanışlıdır.
Bağlam damıtma yoluyla, sistem getirilen belgelerden temel içgörüleri ve en alakalı pasajları çıkarır; böylece dil modelinin çalışacağı en net ve en uygun bilgiye sahip olmasını sağlar.
İlgili belgeler getirildi ve arıtıldıktan sonra, bir RAG sisteminde sıradaki adım üretim sürecidir. Dil modelinin yanıtları nasıl ürettiğini optimize etmek; doğruluk, tutarlılık ve alaka düzeyi sağlamak için gereklidir.
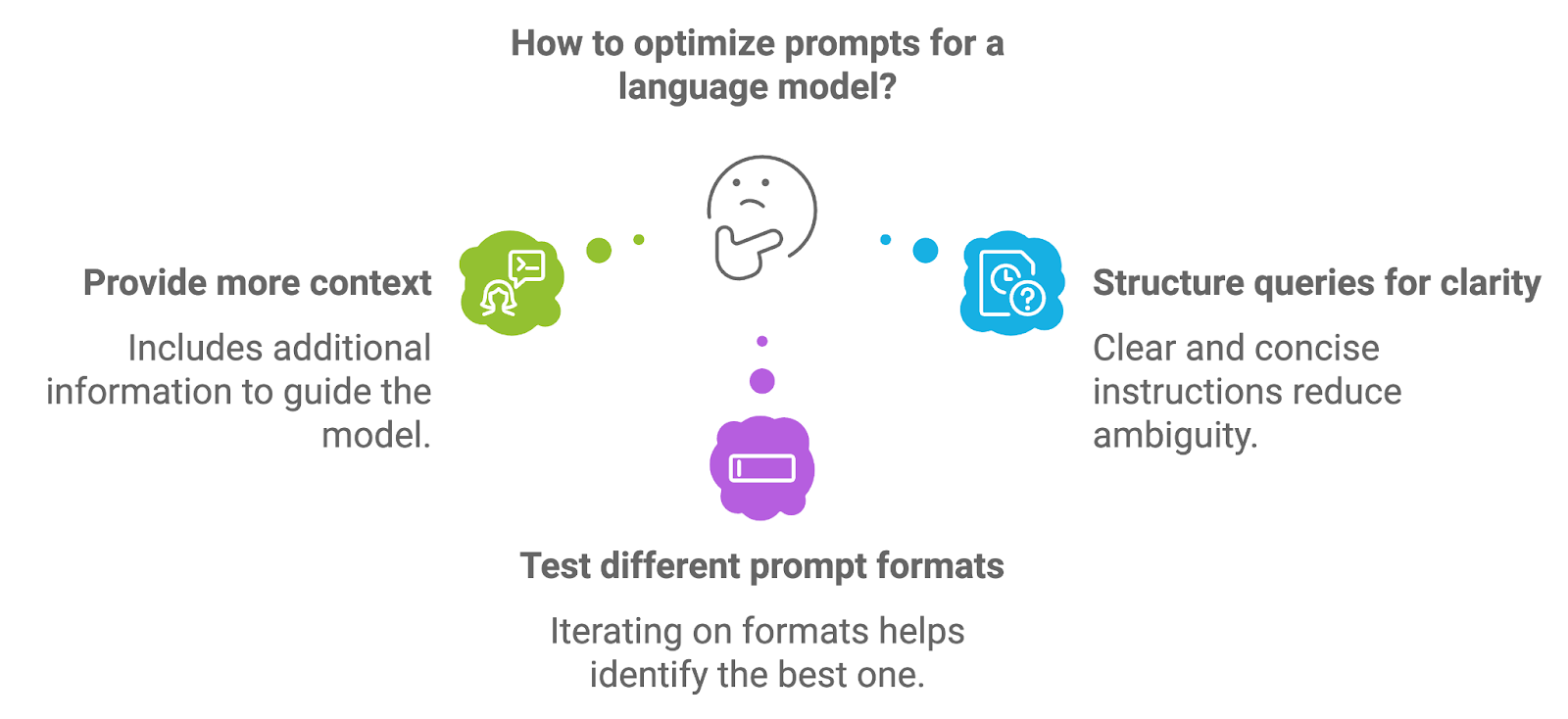
İstem tasarımı dil modeline verilen istemlerin tasarlanması ve yapılandırılması sürecini ifade eder. İstemin kalitesi, modelin ürettiği çıktının kalitesini doğrudan etkiler; çünkü istem, üretim görevi için başlangıç talimatlarını veya bağlamı sağlar.
Şema napkin.ai ile oluşturulmuştur
İstemleri optimize etmek için geliştiriciler birkaç farklı yaklaşımla deneyebilir.
Açık talimatlar veya anahtar terimler gibi ek bilgilerin dahil edilmesi, modeli daha doğru ve bağlamsal olarak ilgili yanıtlara yönlendirebilir. Örneğin, tıbbi bir RAG sisteminde, bir istem, getirilen belgelere dayanarak modelden açıkça bir tanı özeti sunmasını isteyebilir.
Açık ve öz talimatlara sahip iyi yapılandırılmış istemler, belirsizliği azaltır ve daha odaklı üretim sonuçlarına yol açar. İstemi doğrudan bir soru veya istek olarak ifade etmek çoğu zaman daha iyi sonuç verir.
Soruları yeniden ifade etmek, özgüllük düzeyini ayarlamak veya örnekler sağlamak gibi istem biçimlerinde yineleme yapmak, belirli bir kullanım durumu için en iyi sonuç veren biçimi bulmaya yardımcı olabilir.
Daha fazlasını bu blogda öğrenin: İstem Optimizasyon Teknikleri.
Özellikle araştırma, hukuk veya teknik destek gibi alanlardaki birçok sorgu birden çok adım içerir veya karmaşık akıl yürütme gerektirir. Çok adımlı akıl yürütme, bir sistemin karmaşık bir sorguyu yönetilebilir alt görevlere ayırarak bunları sıralı biçimde işleyip kapsamlı bir yanıta ulaşması sürecidir.
Çok adımlı akıl yürütmeyi bir RAG sistemi içinde çeşitli yollarla uygulayabiliriz:
Kısaca değinildiği gibi, RAG sistemlerinde kullanılanlar dahil üretim modellerindeki temel zorluklardan biri halüsinasyondur. RAG sistemlerinde halüsinasyonları azaltmaya yardımcı olabilecek birkaç teknik vardır:
RAG sistemleri giderek daha fazla gerçek dünya görevlerine uygulanırken, karmaşık, çok turlu etkileşimleri ve muğlak sorguları ele alabilmeleri gerekir.
Sohbete dayalı RAG sistemlerindeki temel zorluklardan biri, birden çok etkileşim boyunca bilgi akışını yönetmektir. Müşteri desteği veya devam eden teknik tartışmalar gibi günlük senaryolarda kullanıcılar sıklıkla çok turlu konuşmalara girer; burada bağlamın birkaç değiş tokuş boyunca korunması gerekir.
Sistemin konuşmanın ilgili kısımlarını takip etmesi ve hatırlaması, tutarlı ve tutarlı yanıtlar sunmanın anahtarıdır. Çok turlu konuşmaları etkili biçimde ele almak için RAG sistemleri şu teknikleri kullanabilir:
Kullanıcı sorguları her zaman net olmayabilir; çoğu zaman muğlak, belirsiz olabilir veya bir RAG sisteminin yeteneklerini zorlayan karmaşık akıl yürütme gerektirebilir.
Belirsizliği ele almanın bir yolu, sistemi kullanıcıdan açıklama istemeye yönlendirmektir. Örneğin, sorgu çok muğlaksa, sistem daha fazla ayrıntı isteyen takip soruları üretebilir. Bu etkileşimli süreç, getirim ve üretim aşamalarına geçmeden önce kullanıcının niyetini daraltmaya yardımcı olur.
Birden çok yön veya alt konu içeren karmaşık sorgular için, sistem sorguyu daha küçük ve yönetilebilir parçalara ayırabilir. Bu, her aşamanın sorgunun belirli bir yönünü ele aldığı kademeli bilgi getirimi anlamına gelir. Nihai çıktı, birden fazla getirim ve üretim adımının sentezinden oluşturulur; böylece sorgunun tüm bileşenleri ele alınır.
Belirsizliği ele almak için sistem, sorgudan veya konuşma geçmişinden gelen bağlamsal ipuçlarını kullanabilir. Önceki etkileşimleri veya ilgili konuları analiz ederek RAG sistemi, kullanıcının niyetini daha doğru biçimde çıkarabilir ve alakasız veya hatalı yanıtlar üretme olasılığını azaltır.
Özellikle zorlu sorgular için, RAG sistemleri; sistemin birden fazla belgeden bilgi getirip bunlar arasında mantıksal bağlantılar kurarak karmaşık sorguları yanıtlamasını sağlayan çok sıçramalı soru-cevaplama gibi gelişmiş getirim yöntemlerini uygulayabilir.
RAG sistemleri bilgi getirimi ve metin üretimi için güçlü çözümler sunarken, ayrıca ele alınması gereken belirli zorluklar da getirir.
Önyargı, RAG sistemlerinde kullanılanlar dahil dil modellerinde iyi bilinen bir sorundur ve üretilen çıktıların adilliğini ve doğruluğunu olumsuz etkileyebilir. Önyargı, hem getirim hem üretim aşamalarından sisteme sızabilir; bu da altta yatan veri kümelerinde bulunan toplumsal, kültürel veya alan-özel önyargıları yansıtan taraflı veya ayrımcı çıktılarla sonuçlanır.
RAG sistemlerinde önyargıyı azaltmak için birkaç strateji uygulayabiliriz:
Gelişmiş getirim ve üretim tekniklerinin entegrasyonuyla RAG sistemleri daha karmaşık hale geldikçe, hesaplama talepleri de artar. Bu zorluk; model boyutu, işlem hızı ve gecikme gibi alanlarda kendini gösterir ve bunların tümü, sistemin verimliliğini ve ölçeklenebilirliğini etkileyebilir.
Hesaplama yüklerini yönetmek için geliştiriciler şu optimizasyonları uygulayabilir:
RAG sistemleri, getirdikleri ve ürettikleri verilerin kalitesine ve kapsamına büyük ölçüde bağımlıdır. Alan-özel uygulamalarda, mevcut eğitim verileri yetersiz, güncel olmayan veya düşük kaliteli olduğunda veri sınırlamaları önemli bir zorluk olabilir.
RAG sistemlerindeki veri sınırlamalarını birkaç yaklaşımla ele alabiliriz.
Alan-özel eğitim verileri sınırlı olduğunda, veri artırma teknikleri veri kümesini yapay olarak genişletmeye yardımcı olabilir. Bu; sentetik veri üretmeyi, mevcut belgeleri yeniden ifade etmeyi veya özgün veri kümesini tamamlamak için dış kaynaklar kullanmayı içerebilir. Veri artırma, modelin daha geniş bir örnek yelpazesine erişmesini sağlayarak çeşitli sorgularla başa çıkma yeteneğini geliştirir.
Önceden eğitilmiş dil modellerini küçük, alan-özel veri kümeleri üzerinde ince ayarlamak, sınırlı veriye rağmen RAG sistemlerinin uzmanlaşmış kullanım durumlarına uyum sağlamasına yardımcı olabilir. Alana uyarlama, modelin sektöre özgü terminoloji ve incelikleri daha iyi anlamasını sağlayarak üretilen yanıtların kalitesini artırır.
Yüksek kaliteli eğitim verisinin kıt olduğu durumlarda, veri kümesini yinelemeli olarak iyileştirmek için etkin öğrenme kullanılabilir. En bilgilendirici veri noktalarını belirleyip açıklama çabalarını bunlara odaklayarak, geliştiriciler baştan itibaren çok miktarda etiketli veriye ihtiyaç duymadan veri kümesini kademeli olarak zenginleştirebilir.
RAG sistemlerinde gelişmiş teknikleri uygulamak, mevcut araçlar, çerçeveler ve stratejiler hakkında sağlam bir anlayış gerektirir. Bu teknikler karmaşıklaştıkça, uzmanlaşmış kütüphane ve çerçevelerden yararlanmak, sofistike getirim ve üretim iş akışlarını entegre etmeyi kolaylaştırır.
Gelişmiş RAG tekniklerinin uygulanmasını desteklemek için birçok çerçeve ve kütüphane ortaya çıkmıştır; bunlar geliştiriciler ve araştırmacılar için modüler ve ölçeklenebilir çözümler sunar. Bu araçlar, getirim, sıralama, filtreleme ve üretim için bileşenler sağlayarak RAG sistemi kurma sürecini iyileştirir.
LangChain, dil modelleriyle çalışmak ve bunları harici veri kaynaklarıyla entegre etmek için özel olarak tasarlanmış popüler bir çerçevedir. Belge indeksleme, sorgulama ve farklı işleme adımlarını (getirim, üretim ve akıl yürütme) zincirleme dahil olmak üzere gelişmiş recall ile zenginleştirilmiş teknikleri destekler.
LangChain ayrıca vektör veritabanları ve çeşitli getiricilerle hazır entegrasyonlar sunarak, özel RAG sistemleri oluşturmak için çok yönlü bir seçenek haline gelir.
LangChain ve RAG hakkında daha fazlasını bu derste öğrenin: LangChain ile RAG Sistemleri Kurun
Haystack, üretimde kullanılacak RAG sistemleri kurma konusunda uzmanlaşmış, açık kaynaklı bir çerçevedir. Yoğun getirim, belge sıralama ve filtreleme ile doğal dil üretimi için araçlar sağlar.
Haystack, alan-özel arama, soru-cevaplama veya belge özetleme gerektiren uygulamalarda özellikle güçlüdür. Çeşitli arka uçlar ve popüler dil modelleriyle entegrasyon desteği sayesinde, Haystack gerçek dünya senaryolarında RAG sistemlerinin devreye alınmasını kolaylaştırır.
OpenAI API, geliştiricilerin GPT-4 gibi güçlü dil modellerini RAG iş akışlarına entegre etmelerini sağlar. Getirimle zenginleştirilmiş görevlere özel olmasa da, OpenAI’nin modelleri getirilen bilgilere dayalı yanıtlar üretmek için getirim çerçeveleriyle birlikte kullanılabilir ve gelişmiş üretim yetenekleri sunar.
Gelişmiş teknikleri mevcut bir RAG sistemine entegre etmek için yapılandırılmış bir yaklaşım izlemek esastır.
Kullanım durumunuzla uyumlu bir çerçeve veya kütüphane seçerek başlayın. Örneğin, yoğun getirim yeteneklerine sahip yüksek ölçekte bir sisteme ihtiyacınız varsa LangChain veya Haystack gibi çerçeveler idealdir.
İlk adım, veri kaynağınızı indekslemeyi ve getirim yöntemini yapılandırmayı içeren getirim bileşenini kurmaktır. Kullanım durumunuza bağlı olarak, yoğun getirim (vektör gömmeleri kullanarak) veya hibrit arama (seyrek ve yoğun yöntemleri birleştirerek) seçebilirsiniz. Örneğin, getirim hattını oluşturmak için LangChain veya Haystack kullanılabilir.
Getirim sistemi çalışır hale geldikten sonra, yeniden sıralama ve filtreleme teknikleriyle alaka düzeyini artırma adımına geçilir. Bu, Haystack’te yerleşik yeniden sıralama modüllerini kullanarak veya belirli sorgu türlerinize göre yeniden sıralama modellerinizi özelleştirerek yapılabilir.
Getirimden sonra, istem tasarımı, bağlam damıtma ve çok adımlı akıl yürütmeden yararlanarak üretim sürecini optimize edin. LangChain ile, çok adımlı sorguları ele almak için getirim ve üretim adımlarını zincirleyebilir veya daha doğru üretim için modeli koşullandıran istem şablonları kullanabilirsiniz.
Halüsinasyon bir sorun ise, üretimi getirilen belgelere dayandırmaya odaklanın ve modelin çıktıyı bu belgelerin içeriğine göre üretmesini sağlayın.
RAG sisteminin performansını iyileştirmek için düzenli testler çok önemlidir. Doğruluk, alaka ve kullanıcı memnuniyeti gibi değerlendirme ölçütlerini kullanarak yeniden sıralama ve bağlam damıtma gibi gelişmiş tekniklerin etkinliğini değerlendirin. Farklı yaklaşımları karşılaştırmak için A/B testleri yapın ve geri bildirimlere göre sistemi ince ayar yapın.
Sistem büyüdükçe hesaplama yükleri endişe kaynağı olabilir. Bunu yönetmek için model damıtma veya niceleme gibi optimizasyon tekniklerini uygulayın ve getirim süreçlerinin verimli olduğundan emin olun. GPU hızlandırma veya paralelleştirme kullanmak da ölçekta performansın korunmasına yardımcı olabilir.
RAG sistemlerinin yeni sorgulara ve verilere uyum sağlamak için evrilmesi gerekir. Sistemin performansını gerçek zamanlı izlemek için izleme araçları kurun ve ortaya çıkan eğilimler ve gereksinimlerle başa çıkmak için modeli ve getirim indeksini sürekli güncelleyin.
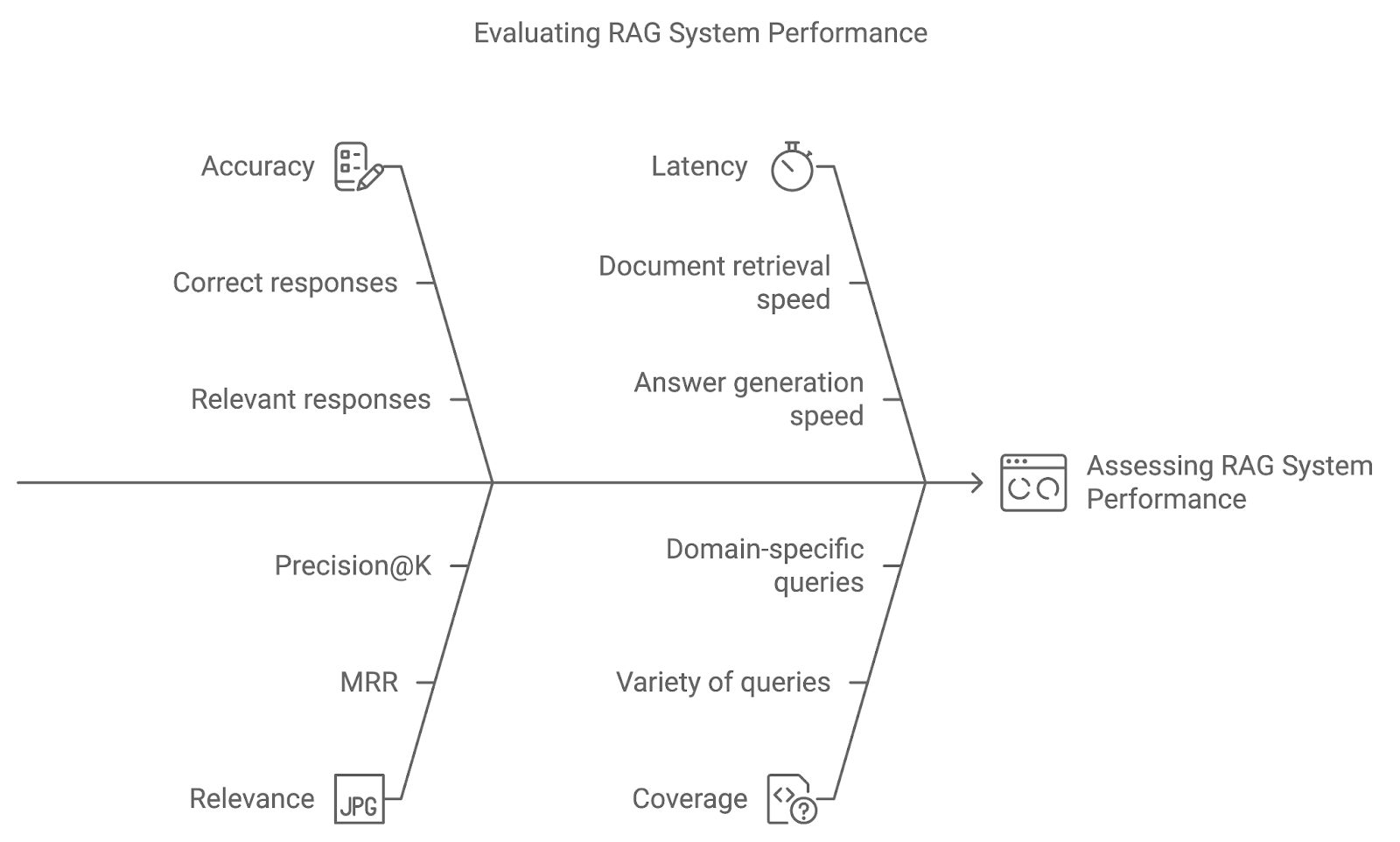
Bir RAG sisteminde gelişmiş teknikleri uygulamak yalnızca başlangıçtır. Uygun değerlendirme ölçütleri ve A/B testi gibi yöntemleri kullanarak, sistemin kullanıcı sorgularına ne kadar iyi karşılık verdiğini ve zaman içinde nasıl iyileştiğini değerlendirebiliriz.
Doğruluk, sistemin doğru veya ilgili yanıtı ne sıklıkla getirdiğini ve ürettiğini ölçer. Soru-cevap sistemlerinde bu, üretilen yanıtların yerleşik gerçeklerle doğrudan karşılaştırılmasını içerebilir. Artan doğruluk, sistemin sorguları doğru yorumladığını ve kesin sonuçlar sunduğunu gösterir.
Bu ölçüt, getirilen belgelerin ve üretilen yanıtın, kullanıcının sorgusunu ne kadar iyi yanıtladığına bağlı olarak alaka düzeyini ve kaliteyi değerlendirir. En Alakalı Belgenin Sırasının Ortalaması (MRR) veya Precision@K gibi ölçütler, en alakalı belgenin sıralamada ne kadar üstte göründüğünü nicelendirmek için yaygın olarak kullanılır.
Doğruluk ve alaka hayati olsa da, gerçek zamanlı performans da önemlidir. Gecikme, sistemin yanıt süresini—belgeleri getirme ve yanıt üretme hızını—ifade eder. Düşük gecikme, müşteri desteği veya canlı S&C sistemleri gibi zamanında yanıtın kritik olduğu uygulamalarda özellikle önemlidir.
Kapsam, RAG sisteminin geniş bir sorgu yelpazesini ne kadar iyi ele aldığını ölçer. Alan-özel uygulamalarda, sistemin potansiyel kullanıcı sorgularının tüm kapsamını karşılayabilmesi, kapsamlı destek sağlamak için anahtardır.
Şema napkin.ai ile oluşturulmuştur
Gelişmiş RAG teknikleri, farklı sektörler ve uygulamalar genelinde geniş bir olasılık yelpazesinin kapısını açar.
Gelişmiş RAG tekniklerinin en etkileyici kullanım alanlarından biri karmaşık soru-cevaplama (QA) sistemleridir. Bu sistemler yalnızca basit belge getiriminin ötesine geçer—bağlamı anlamalı, çok adımlı sorguları parçalamalı ve getirilen belgelere dayanarak kapsamlı yanıtlar sunmalıdır.
Alan-özel bilginin önemli olduğu sektörlerde, oldukça uzmanlaşmış içerik getiren ve üreten gelişmiş RAG sistemleri kurulabilir. Bazı dikkat çekici uygulamalar şunlardır:
Kişiselleştirilmiş öneri sistemleri, gelişmiş RAG teknikleri için bir diğer önemli kullanım alanıdır. Kullanıcı tercihleri, davranışları ve harici veri kaynaklarını birleştirerek, RAG sistemleri ürünler, hizmetler veya içerikler için kişiselleştirilmiş öneriler üretebilir; bunlara şunlar dahildir:
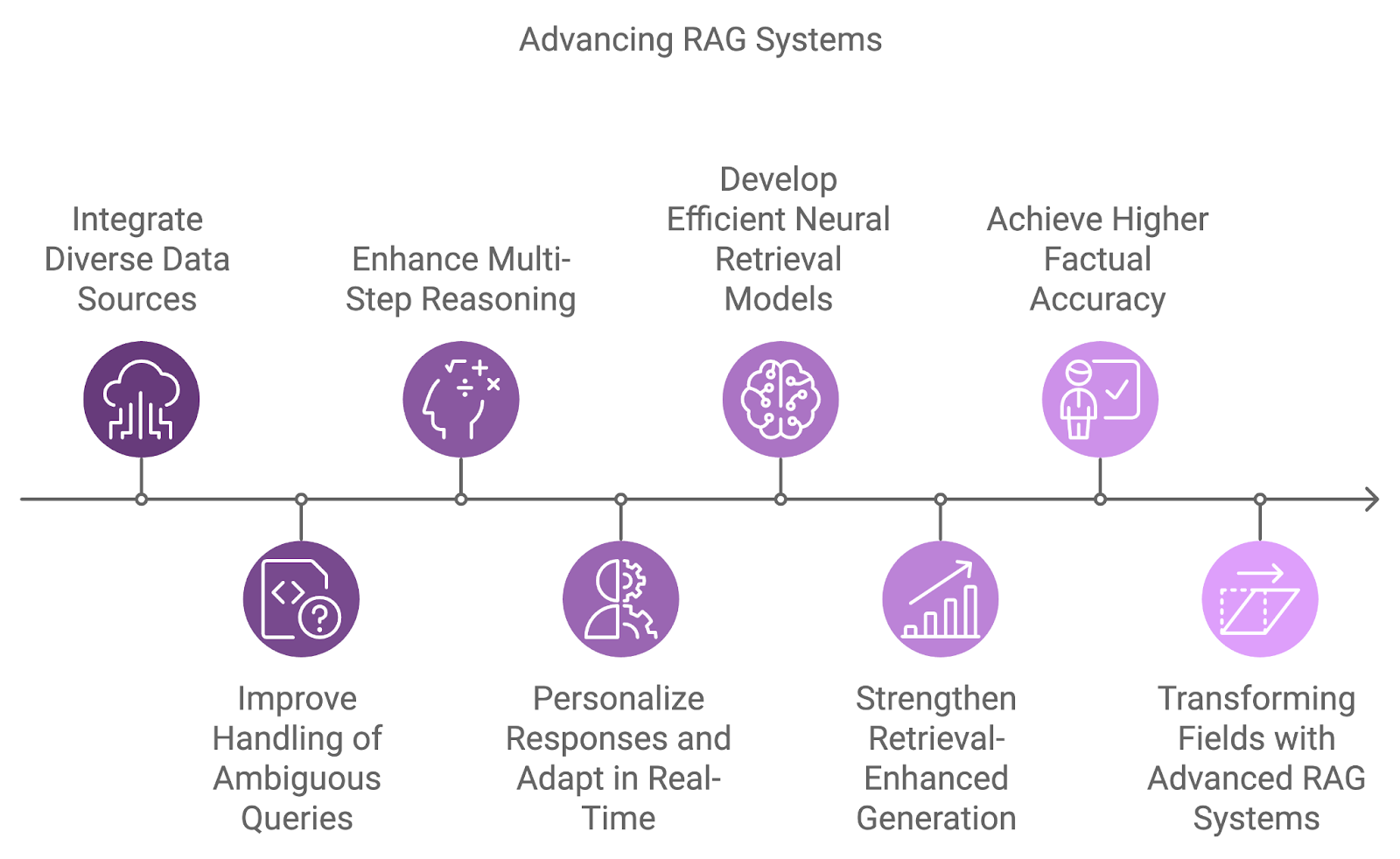
RAG sistemlerinin bir sonraki nesli, daha çeşitli veri kaynaklarını entegre ederek akıl yürütme yeteneklerini geliştirecek ve belirsizlik ile karmaşık sorgu işleme gibi mevcut sınırlamaları ele alacaktır.
Temel gelişim alanlarından biri, tek veri kümelerine bağımlılığın ötesine geçerek çeşitli veri kaynaklarının entegrasyonudur. Gelecekteki sistemler, veritabanları, API’ler ve gerçek zamanlı akışlar gibi farklı kaynaklardan gelen bilgileri birleştirerek karmaşık sorgulara daha kapsamlı ve çok boyutlu yanıtlar sağlayacaktır.
Muğlak veya eksik sorguları ele almak, geleceğin RAG sistemlerinin üstesinden geleceği bir diğer zorluktur. Olasılıksal akıl yürütmeyi daha iyi bağlamsal anlayışla birleştirerek, bu sistemler belirsizliği daha etkili biçimde yönetecektir.
Ayrıca, çok adımlı akıl yürütme, RAG sistemlerinin karmaşık sorguları işlemesinin daha ayrılmaz bir parçası haline gelecek; sorguları daha küçük bileşenlere ayırıp sonuçları birden çok belge veya adım arasında sentezleyecektir. Bu, özellikle hukuki araştırma, bilimsel keşif ve müşteri desteği gibi, sorguların sıklıkla çeşitli bilgi parçalarını ilişkilendirmeyi gerektirdiği alanlarda faydalı olacaktır.
Kişiselleştirme ve bağlam farkındalığı iyileştikçe, gelecekteki RAG sistemleri yanıtlarını kullanıcı geçmişine, tercihlerine ve geçmiş etkileşimlerine göre uyarlayacaktır. Yeni bilgilere gerçek zamanlı uyum sağlama, daha dinamik ve verimli sohbetlere olanak tanıyacaktır.
Şema napkin.ai ile oluşturulmuştur
Mevcut yoğun getirim modelleri oldukça etkilidir; ancak daha da verimli ve doğru sinirsel getirim modelleri geliştirmek için araştırmalar sürmektedir. Bu modeller, daha geniş bir sorgu-belge çifti yelpazesinde anlamsal benzerlikleri daha iyi yakalamayı ve büyük ölçekli getirim görevlerinde verimliliği artırmayı hedefler.
Karpukhin ve diğ. (2020) gibi makaleler, açık alan soru-cevaplama için temel bir yöntem olarak Yoğun Pasaj Getirimi’ni (DPR) tanıtırken, daha yeni çalışmalar olan Izacard ve diğ. (2022), RAG sistemlerini alan-özel görevlere uyarlamak için az örnekli öğrenmeye odaklanır.
Bir başka yükselen araştırma alanı, getirim ile üretim arasındaki bağlantıyı, getirimle zenginleştirilmiş üretim modelleri aracılığıyla iyileştirmeye odaklanır. Bu modeller, getirilen belgelerin üretim sürecine sorunsuz biçimde entegre edilmesini, dil modelinin çıktısını getirilen içeriğe daha doğrudan dayandırmasını amaçlar.
Bu, halüsinasyonları azaltabilir ve üretilen yanıtların olgusal doğruluğunu artırarak sistemi daha güvenilir hale getirebilir. Dikkate değer çalışmalar arasında, RAVEN modeliyle Huang ve diğ. (2023), getirimle zenginleştirilmiş kodlayıcı-çözücü modeller kullanarak bağlam içi öğrenmeyi iyileştirir.
Yoğun getirim, yeniden sıralama ve çok adımlı akıl yürütme gibi gelişmiş RAG tekniklerinin entegrasyonu, RAG sistemlerinin sağlık hizmetlerinden kişiselleştirilmiş önerilere kadar gerçek dünya uygulamalarının gereksinimlerini karşılamasını sağlar.
İleriye dönük olarak, RAG sistemlerinin evrimi; diller arası yetenekler, kişiselleştirilmiş üretim ve daha çeşitli veri kaynaklarının ele alınması gibi yenilikler tarafından yönlendirilecektir.
Öğrenmeye devam etmek ve RAG sistemleriyle daha fazla uygulamalı deneyim kazanmak istiyorsanız bu öğreticileri öneririm:
Bu kurslarla yapay zekayı öğrenin!
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
