
Programa
Desenvolvimento de aplicativos de IA
21 h
Técnicas avançadas para sistemas RAG (Retrieval-Augmented Generation)
Geração aumentada por recuperação (RAG) combina a recuperação de documentos com a geração de linguagem natural, criando respostas mais precisas e contextualmente conscientes.
Embora o RAG básico seja eficaz, ele tem dificuldades com consultas complexas, alucinações e manutenção do contexto em conversas com várias voltas.
Neste blog, explorarei técnicas avançadas que abordam esses desafios, melhorando a precisão da recuperação, a qualidade da geração e o desempenho geral do sistema.
Se você estiver lendo este artigo em preparação para uma entrevista, não deixe de conferir as As 30 principais perguntas e respostas da RAG para entrevistas artigo.
Embora as implementações básicas do RAG possam ser úteis, elas têm suas limitações, especialmente quando aplicadas em contextos mais exigentes.
Um dos problemas mais proeminentes é a alucinação, em que o modelo gera conteúdo que é factualmente incorreto ou não é suportado pelos documentos recuperados. Isso pode prejudicar a confiabilidade do sistema, especialmente em áreas que exigem alta precisão, como medicina ou direito.
Os modelos RAG padrão podem ter dificuldades ao lidar com consultas específicas do domínio. Sem adaptar os processos de recuperação e geração às nuances dos domínios especializados, o sistema corre o risco de recuperar informações irrelevantes ou imprecisas.
Outro desafio é gerenciar consultas complexas de várias etapas ou conversas de várias voltas. Os sistemas RAG básicos geralmente têm dificuldades para manter o contexto nas interações, o que resulta em respostas desarticuladas ou incompletas. À medida que as consultas dos usuários se tornam mais complexas, os sistemas RAG precisam evoluir para lidar com essa complexidade crescente.
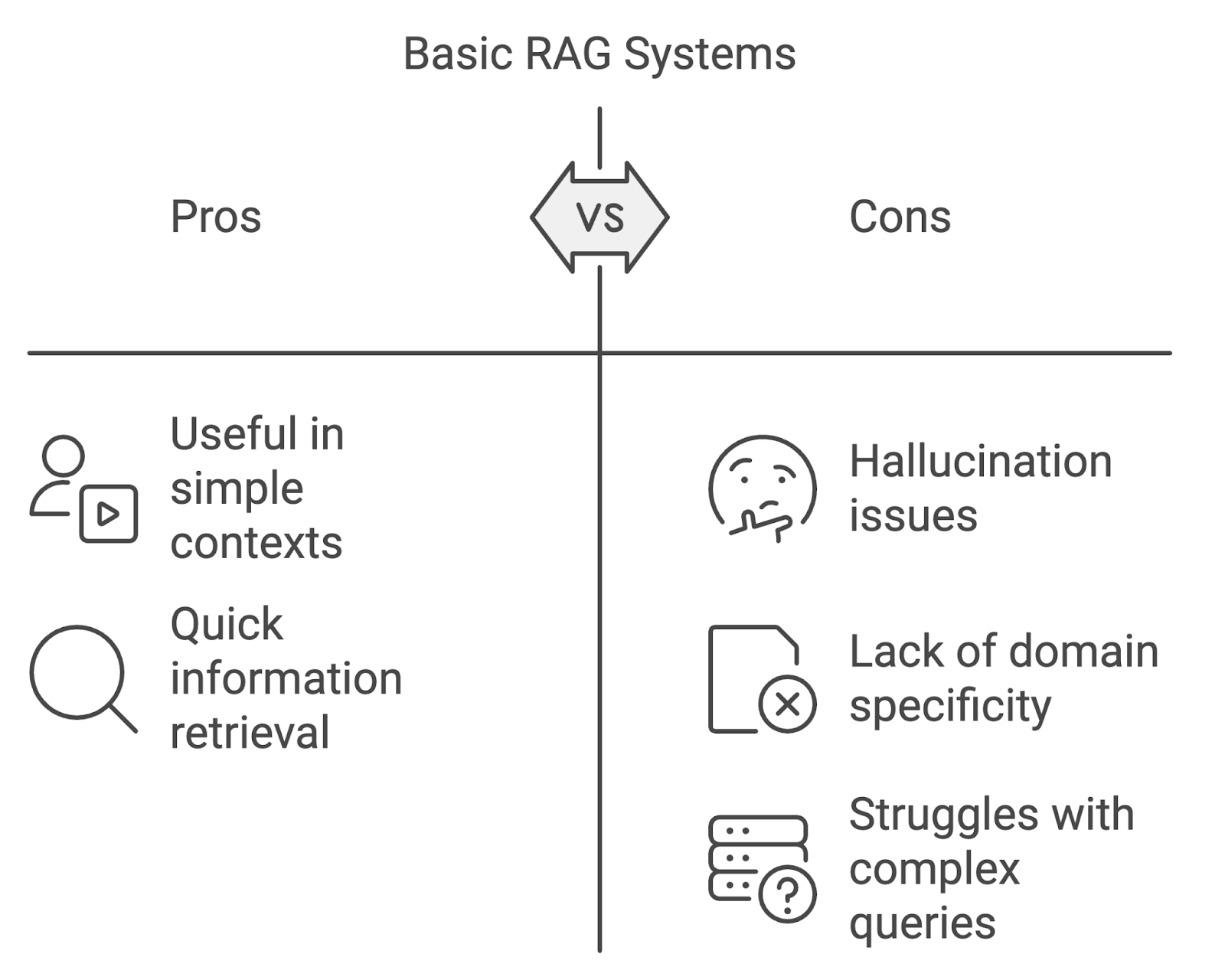
Diagrama gerado com o napkin.ai
As técnicas avançadas de recuperação se concentram em aprimorar a relevância e o escopo dos documentos recuperados. Essas técnicas, que incluem recuperação densa, pesquisa híbrida, reranking e expansão de consultas, abordam as limitações da recuperação baseada em palavras-chave.
A recuperação densa e a pesquisa híbrida são técnicas fundamentais para melhorar a precisão e a relevância da recuperação. Métodos como o TF-IDF ou o BM25 geralmente têm dificuldades com a compreensão semântica quando as consultas são formuladas de forma diferente dos documentos.
A recuperação densa, como a DPR (Dense Passage Retrieval), usa aprendizado profundo para mapear consultas e documentos em representações vetoriais densas representações vetoriaiscapturando o significado do texto além das palavras-chave exatas.
A pesquisa híbrida combina a recuperação esparsa e densa, equilibrando a precisão e a recuperação ao combinar a correspondência baseada em palavras-chave com a similaridade semântica, tornando-a eficaz para consultas mais complexas.
O ranqueamento é outra técnica avançada usada para refinar a lista de documentos recuperados antes de serem passados para o componente de geração. Em um sistema RAG típico, a fase de recuperação inicial pode produzir um grande conjunto de documentos que variam em relevância.
A função do reranking é reordenar esses documentos para que os mais relevantes sejam priorizados para uso pelo modelo de linguagem. A reclassificação pode ser obtida a partir de uma pontuação simples baseada na similaridade entre consulta e documento, até modelos mais complexos de aprendizado de máquina treinados para prever a relevância de cada documento.
Você pode aprender como implementar o reranking neste tutorial sobre classificação por ordem de classificação com o RankGPT.
A expansão da consulta envolve o enriquecimento da consulta do usuário com termos adicionais que aumentam as chances de recuperação de documentos relevantes. Isso pode ser alcançado por meio de:
Por exemplo, se a consulta original for "inteligência artificial no setor de saúde", a expansão da consulta poderá incluir termos relacionados, como "IA", "aprendizado de máquina" ou "tecnologia de saúde", garantindo uma rede de recuperação mais ampla.
Nos sistemas RAG, a simples recuperação de documentos não é suficiente; garantir a relevância e a qualidade desses documentos é fundamental para melhorar o resultado final. Para isso, são essenciais técnicas avançadas que refinam e filtram o conteúdo recuperado.
Esses métodos funcionam para reduzir o ruído, aumentar a relevância e concentrar o modelo de linguagem nas informações mais importantes durante o processo de geração.
Técnicas avançadas de filtragem usam metadados ou regras baseadas em conteúdo para excluir documentos irrelevantes ou de baixa qualidade, garantindo que apenas os resultados mais relevantes sejam transmitidos.
A destilação de contexto é o processo de resumir ou condensar documentos recuperados para concentrar o modelo de linguagem nas informações mais importantes. Isso é útil quando os documentos recuperados contêm muito conteúdo irrelevante ou quando a consulta envolve um raciocínio complexo e de várias etapas.
Ao destilar o contexto, o sistema extrai os principais insights e as passagens mais relevantes dos documentos recuperados, garantindo que o modelo de linguagem tenha as informações mais claras e pertinentes para trabalhar.
Depois que os documentos relevantes tiverem sido recuperados e refinados, a próxima etapa em um sistema RAG é o processo de geração. Otimizar a forma como o modelo de linguagem gera respostas é essencial para estabelecer a precisão, a coerência e a relevância.
Engenharia de prompts refere-se ao processo de projetar e estruturar os prompts que são inseridos no modelo de linguagem. A qualidade do prompt afeta diretamente a qualidade do resultado gerado pelo modelo, pois o prompt fornece as instruções iniciais ou o contexto para a tarefa de geração.
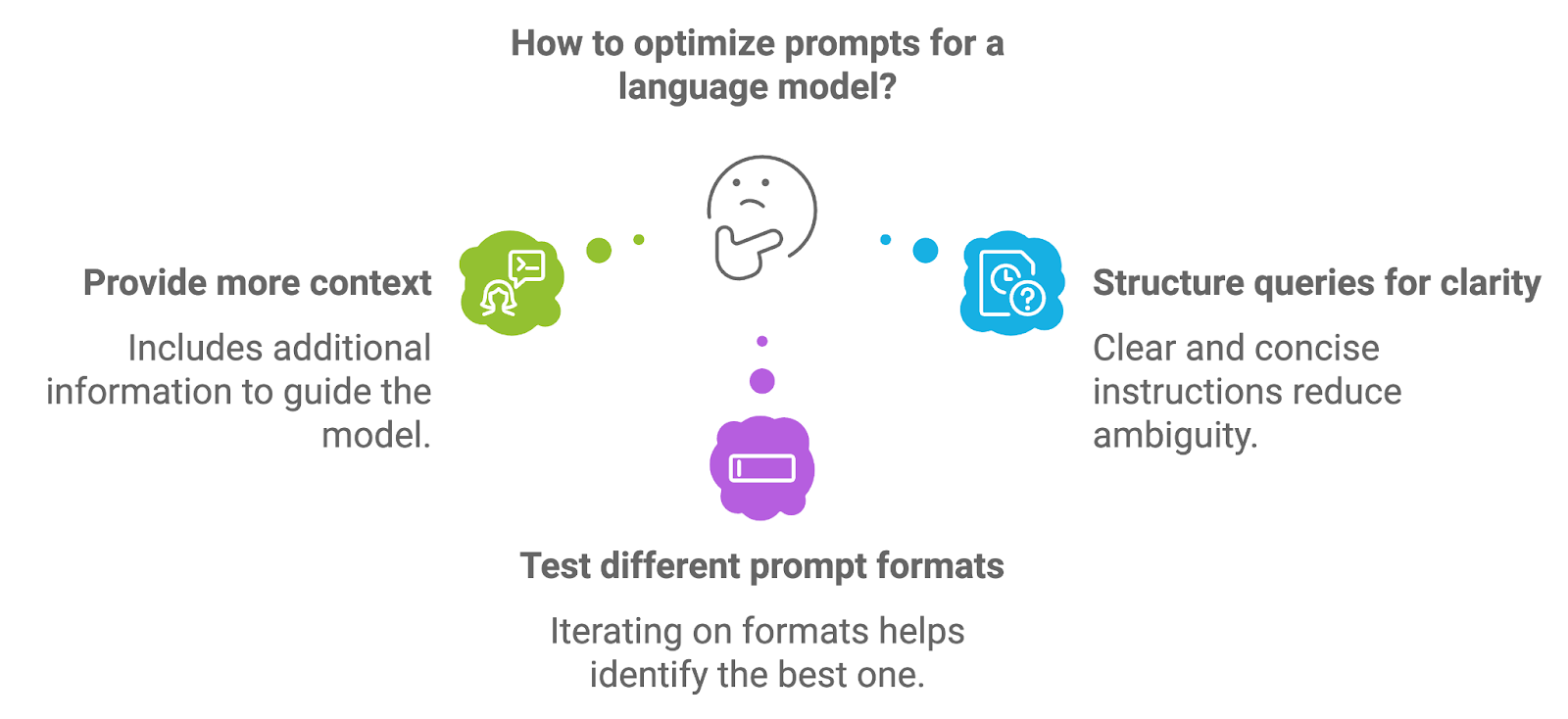
Diagrama gerado com o napkin.ai
Para otimizar os prompts, os desenvolvedores podem experimentar algumas abordagens diferentes.
A inclusão de informações adicionais, como instruções explícitas ou termos-chave, pode orientar o modelo para respostas mais precisas e contextualmente relevantes. Por exemplo, em um sistema RAG médico, um prompt pode solicitar explicitamente que o modelo forneça um resumo do diagnóstico com base nos documentos recuperados.
Prompts bem estruturados, com instruções claras e concisas, ajudam a reduzir a ambiguidade e levam a resultados de geração mais focados. A formulação do prompt como uma pergunta ou solicitação direta pode, muitas vezes, produzir melhores resultados.
A iteração nos formatos de prompt, como reformular as perguntas, ajustar o nível de especificidade ou fornecer exemplos, pode ajudar a identificar o formato que oferece os melhores resultados para um caso de uso específico.
Saiba mais neste blog: Técnicas de otimização do prompt.
Muitas consultas, especialmente em áreas como pesquisa, direito ou suporte técnico, envolvem várias etapas ou exigem raciocínio complexo. O raciocínio em várias etapas é o processo pelo qual um sistema divide uma consulta complexa em subtarefas gerenciáveis e as processa sequencialmente para chegar a uma resposta abrangente.
Podemos implementar o raciocínio em várias etapas em um sistema RAG de várias maneiras:
Conforme mencionado brevemente, um dos principais desafios dos modelos de geração, inclusive os usados nos sistemas RAG, é a alucinação. Várias técnicas podem ajudar a reduzir as alucinações nos sistemas RAG:
Como os sistemas RAG são cada vez mais aplicados a tarefas do mundo real, eles devem ser capazes de lidar com interações complexas, com várias voltas e com consultas ambíguas.
Um dos principais desafios dos sistemas RAG conversacionais é gerenciar o fluxo de informações em várias interações. Em muitos cenários do dia a dia, como suporte ao cliente ou discussões técnicas contínuas, os usuários costumam participar de conversas com vários turnos em que o contexto deve ser mantido em várias trocas.
O fato de o sistema rastrear e lembrar partes relevantes da conversa é fundamental para que você possa fornecer respostas coerentes e consistentes. Para lidar com conversas com vários turnos de forma eficaz, os sistemas RAG podem usar as seguintes técnicas:
As consultas dos usuários nem sempre são simples. Muitas vezes, elas podem ser vagas, ambíguas ou envolver um raciocínio complexo que desafia os recursos de um sistema RAG.
Uma maneira de lidar com a ambiguidade é solicitar que o sistema busque esclarecimentos do usuário. Por exemplo, se a consulta for muito vaga, o sistema poderá gerar uma pergunta de acompanhamento solicitando mais detalhes. Esse processo interativo ajuda a restringir a intenção do usuário antes de prosseguir com as fases de recuperação e geração.
Para consultas complexas que envolvem vários aspectos ou subtópicos, o sistema pode dividir a consulta em partes menores e mais gerenciáveis. Isso envolve a recuperação de informações em etapas, em que cada etapa aborda um aspecto específico da consulta. O resultado final é então sintetizado a partir de várias etapas de recuperação e geração, garantindo que todos os componentes da consulta sejam abordados.
Para lidar com a ambiguidade, o sistema pode usar pistas contextuais da consulta ou do histórico da conversa. Ao analisar interações anteriores ou tópicos relacionados, o sistema RAG pode inferir a intenção do usuário com mais precisão, reduzindo a probabilidade de gerar respostas irrelevantes ou incorretas.
Para consultas particularmente desafiadoras, os sistemas RAG podem implementar métodos avançados de recuperação, como a resposta a perguntas com vários saltos, em que o sistema recupera informações de vários documentos e faz conexões lógicas entre eles para responder a consultas complexas.
Embora os sistemas RAG ofereçam soluções poderosas para recuperação de informações e geração de texto, eles também apresentam desafios específicos que precisam ser abordados.
Viés nos modelos de linguagem, inclusive os usados nos sistemas RAG, é um problema bem conhecido que pode afetar negativamente a imparcialidade e a precisão dos resultados gerados. O viés pode entrar no sistema por meio das fases de recuperação e geração, resultando em resultados distorcidos ou discriminatórios que refletem vieses sociais, culturais ou específicos do domínio presentes nos conjuntos de dados subjacentes.
Para atenuar a tendência nos sistemas RAG, podemos aplicar várias estratégias:
À medida que os sistemas RAG se tornam mais complexos com a integração de técnicas avançadas de recuperação e geração, as demandas computacionais também aumentam. Esse desafio se manifesta em áreas como tamanho do modelo, velocidade de processamento e latência, que podem afetar a eficiência e a escalabilidade do sistema.
Para gerenciar as despesas gerais de computação, os desenvolvedores podem empregar as seguintes otimizações:
Os sistemas RAG dependem muito da qualidade e do escopo dos dados que eles recuperam e geram. Em aplicativos de domínio específico, as limitações de dados podem ser um grande desafio, principalmente quando os dados de treinamento disponíveis são insuficientes, desatualizados ou de baixa qualidade.
Podemos abordar as limitações de dados nos sistemas RAG com algumas abordagens.
Quando os dados de treinamento específicos do domínio são limitados, as técnicas de aumento de dados podem ajudar a expandir artificialmente o conjunto de dados. Isso pode incluir a geração de dados sintéticos, a paráfrase de documentos existentes ou o uso de fontes externas para complementar o conjunto de dados original. O aumento de dados garante que o modelo tenha acesso a uma gama mais ampla de exemplos, melhorando sua capacidade de lidar com diversas consultas.
O ajuste fino de modelos de linguagem pré-treinados em conjuntos de dados pequenos e específicos do domínio pode ajudar os sistemas RAG a se adaptarem a casos de uso especializados, mesmo com dados limitados. A adaptação do domínio permite que o modelo compreenda melhor a terminologia e as nuances específicas do setor, melhorando a qualidade das respostas geradas.
Nos casos em que os dados de treinamento de alta qualidade são escassos, a aprendizagem ativa pode ser empregada para melhorar o conjunto de dados iterativamente. Ao identificar os pontos de dados mais informativos e concentrar os esforços de anotação neles, os desenvolvedores podem aprimorar gradualmente o conjunto de dados sem precisar de grandes quantidades de dados rotulados desde o início.
A implementação de técnicas avançadas em sistemas RAG requer uma sólida compreensão das ferramentas, estruturas e estratégias disponíveis. À medida que essas técnicas se tornam mais complexas, o aproveitamento de bibliotecas e estruturas especializadas simplifica a integração de fluxos de trabalho sofisticados de recuperação e geração.
Muitas estruturas e bibliotecas surgiram para dar suporte à implementação de técnicas avançadas de RAG, oferecendo soluções modulares e dimensionáveis para desenvolvedores e pesquisadores. Essas ferramentas aprimoram o processo de criação de sistemas RAG, fornecendo componentes para recuperação, classificação, filtragem e geração.
O LangChain é uma estrutura popular projetada especificamente para trabalhar com modelos de linguagem e integrá-los a fontes de dados externas. Ele oferece suporte a técnicas avançadas de recuperação aumentada, incluindo indexação de documentos, consultas e encadeamento de diferentes etapas de processamento (recuperação, geração e raciocínio).
LangChain também oferece integrações prontas para uso com bancos de dados de vetores e vários recuperadores, o que o torna uma opção versátil para a criação de sistemas RAG personalizados.
Saiba mais sobre LangChain e RAG neste curso: Crie sistemas RAG com LangChain
Haystack é uma estrutura de código aberto especializada na criação de sistemas RAG para uso em produção. Ele fornece ferramentas para recuperação densa, classificação e filtragem de documentos, bem como geração de linguagem natural.
O Haystack é particularmente eficiente em aplicativos que exigem pesquisa específica de domínio, resposta a perguntas ou resumo de documentos. Com suporte para uma variedade de back-ends e integração com modelos de linguagem populares, o Haystack simplifica a implantação de sistemas RAG em cenários do mundo real.
A API API OpenAI permite que os desenvolvedores integrem modelos de linguagem avançados, como o GPT-4, aos fluxos de trabalho do RAG. Embora não sejam específicos para tarefas aumentadas por recuperação, os modelos da OpenAI podem ser usados em conjunto com estruturas de recuperação para gerar respostas com base nas informações recuperadas, permitindo recursos avançados de geração.
Para integrar técnicas avançadas em um sistema RAG existente, é essencial seguir uma abordagem estruturada.
Comece selecionando uma estrutura ou biblioteca que se alinhe ao seu caso de uso. Por exemplo, se você precisar de um sistema altamente dimensionável com recursos de recuperação densos, estruturas como LangChain ou Haystack são ideais.
A primeira etapa é configurar o componente de recuperação, o que envolve a indexação da fonte de dados e a configuração do método de recuperação. Dependendo do seu caso de uso, você pode escolher a recuperação densa (usando embeddings de vetores) ou a pesquisa híbrida (combinando métodos esparsos e densos). Por exemplo, o LangChain ou o Haystack podem ser usados para criar o pipeline de recuperação.
Quando o sistema de recuperação estiver operacional, a próxima etapa é aumentar a relevância por meio de técnicas de classificação e filtragem. Isso pode ser feito usando os módulos de reranking incorporados no Haystack ou personalizando seus modelos de reranking com base em tipos de consulta específicos.
Após a recuperação, otimize o processo de geração, aproveitando a engenharia de prompt, a destilação de contexto e o raciocínio em várias etapas. Com o LangChain, você pode encadear as etapas de recuperação e geração para lidar com consultas em várias etapas ou usar modelos de prompt que condicionam o modelo para uma geração mais precisa.
Se a alucinação for um problema, concentre-se em fundamentar a geração nos documentos recuperados, garantindo que o modelo gere resultados com base no conteúdo desses documentos.
Testes regulares são essenciais para refinar o desempenho do sistema RAG. Use métricas de avaliação como precisão, relevância e satisfação do usuário para avaliar a eficácia de técnicas avançadas, como reranking e destilação de contexto. Execute testes A/B para comparar diferentes abordagens e ajustar o sistema com base no feedback.
À medida que o sistema cresce, as despesas gerais de computação podem se tornar uma preocupação. Para gerenciar isso, use técnicas de otimização, como destilação ou quantização de modelos, e garanta que os processos de recuperação sejam eficientes. A utilização da aceleração ou paralelização da GPU também pode ajudar a manter o desempenho em escala.
Os sistemas RAG precisam evoluir para se adaptar a novas consultas e dados. Configure ferramentas de monitoramento para acompanhar o desempenho do sistema em tempo real e atualize continuamente o modelo e o índice de recuperação para lidar com as tendências e os requisitos emergentes.
A implementação de técnicas avançadas em um sistema RAG é apenas o começo. Ao usar métricas de avaliação métricas de avaliação e métodos de teste como o teste A/B, podemos avaliar se o sistema responde bem às consultas dos usuários e se aperfeiçoa com o tempo.
A precisão mede a frequência com que o sistema recupera e gera a resposta correta ou relevante. No caso de sistemas de resposta a perguntas, isso poderia envolver uma comparação direta das respostas geradas com dados de verdade. O aumento da precisão indica que o sistema está interpretando com precisão as consultas e fornecendo resultados precisos.
Essa métrica avalia a relevância dos documentos recuperados e a qualidade da resposta gerada com base em quão bem eles respondem à consulta do usuário. Métricas como Mean Reciprocal Rank (MRR) ou Precision@K são comumente usadas para quantificar a relevância, avaliando o nível em que o documento mais relevante aparece na classificação.
Embora a precisão e a relevância sejam essenciais, o desempenho em tempo real também é importante. A latência refere-se ao tempo de resposta do sistema - a velocidade com que o sistema recupera documentos e gera respostas. A baixa latência é particularmente importante em aplicativos em que respostas oportunas são vitais, como suporte ao cliente ou sistemas de perguntas e respostas ao vivo.
A cobertura mede a capacidade do sistema RAG de lidar com uma ampla variedade de consultas. Em aplicativos de domínio específico, garantir que o sistema possa lidar com todo o escopo de possíveis consultas do usuário é fundamental para fornecer suporte abrangente.
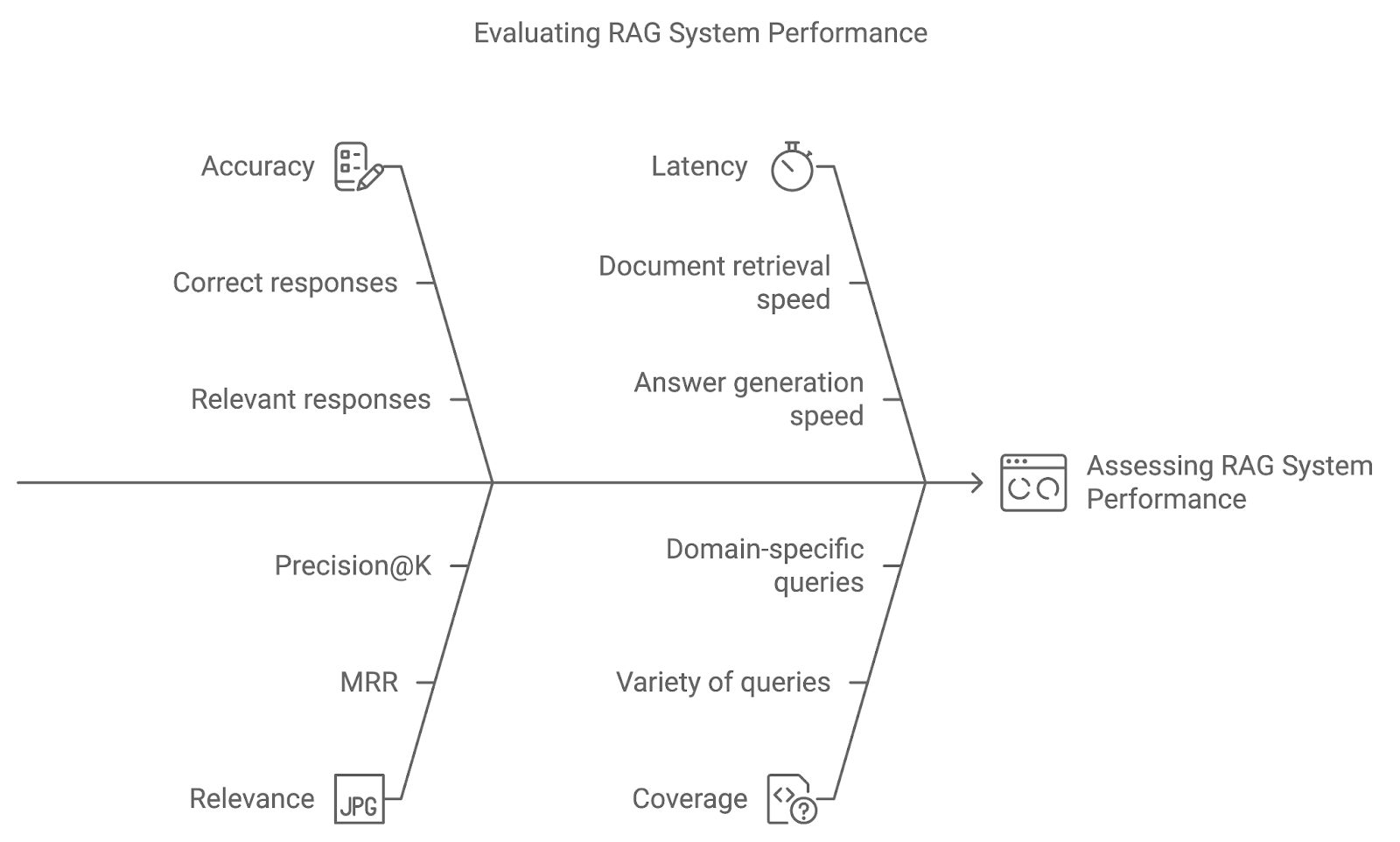
Diagrama gerado com o napkin.ai
As técnicas avançadas de RAG abrem uma ampla gama de possibilidades em diferentes setores e aplicações.
Um dos casos de uso mais impactantes das técnicas avançadas de RAG é em sistemas complexos de resposta a perguntas (QA). Esses sistemas exigem mais do que a simples recuperação de documentos - eles precisam entender o contexto, decompor as consultas em várias etapas e fornecer respostas abrangentes com base nos documentos recuperados.
Nos setores em que o conhecimento específico do domínio é importante, os sistemas RAG avançados podem ser criados para recuperar e gerar conteúdo altamente especializado. Alguns aplicativos dignos de nota incluem:
Os sistemas de recomendação personalizados são outro caso de uso importante para as técnicas avançadas de RAG. Ao combinar as preferências, o comportamento e as fontes de dados externas do usuário, os sistemas RAG podem gerar recomendações personalizadas de produtos, serviços ou conteúdo, inclusive:
A próxima geração de sistemas RAG integrará fontes de dados mais diversificadas, aprimorando os recursos de raciocínio e abordando as limitações atuais, como ambiguidade e tratamento de consultas complexas.
Uma das principais áreas de desenvolvimento é a integração de várias fontes de dados, indo além da dependência de conjuntos de dados únicos. Os sistemas futuros combinarão informações de diversas fontes, como bancos de dados, APIs e feeds em tempo real, permitindo respostas mais abrangentes e multidimensionais a consultas complexas.
O tratamento de consultas ambíguas ou incompletas é outro desafio que os futuros sistemas RAG abordarão. Ao combinar o raciocínio probabilístico com uma melhor compreensão contextual, esses sistemas gerenciarão a incerteza de forma mais eficaz.
Além disso, o raciocínio em várias etapas se tornará mais integral à forma como os sistemas RAG processam consultas complexas, dividindo-as em componentes menores e sintetizando os resultados em vários documentos ou etapas. Isso será especialmente benéfico em áreas como pesquisa jurídica, descoberta científica e suporte ao cliente, em que as consultas geralmente exigem a conexão de diversas informações.
Como a personalização e o reconhecimento do contexto continuam a melhorar, os futuros sistemas RAG adaptarão suas respostas com base no histórico, nas preferências e nas interações anteriores do usuário. A adaptação em tempo real a novas informações permitirá conversas mais dinâmicas e produtivas.
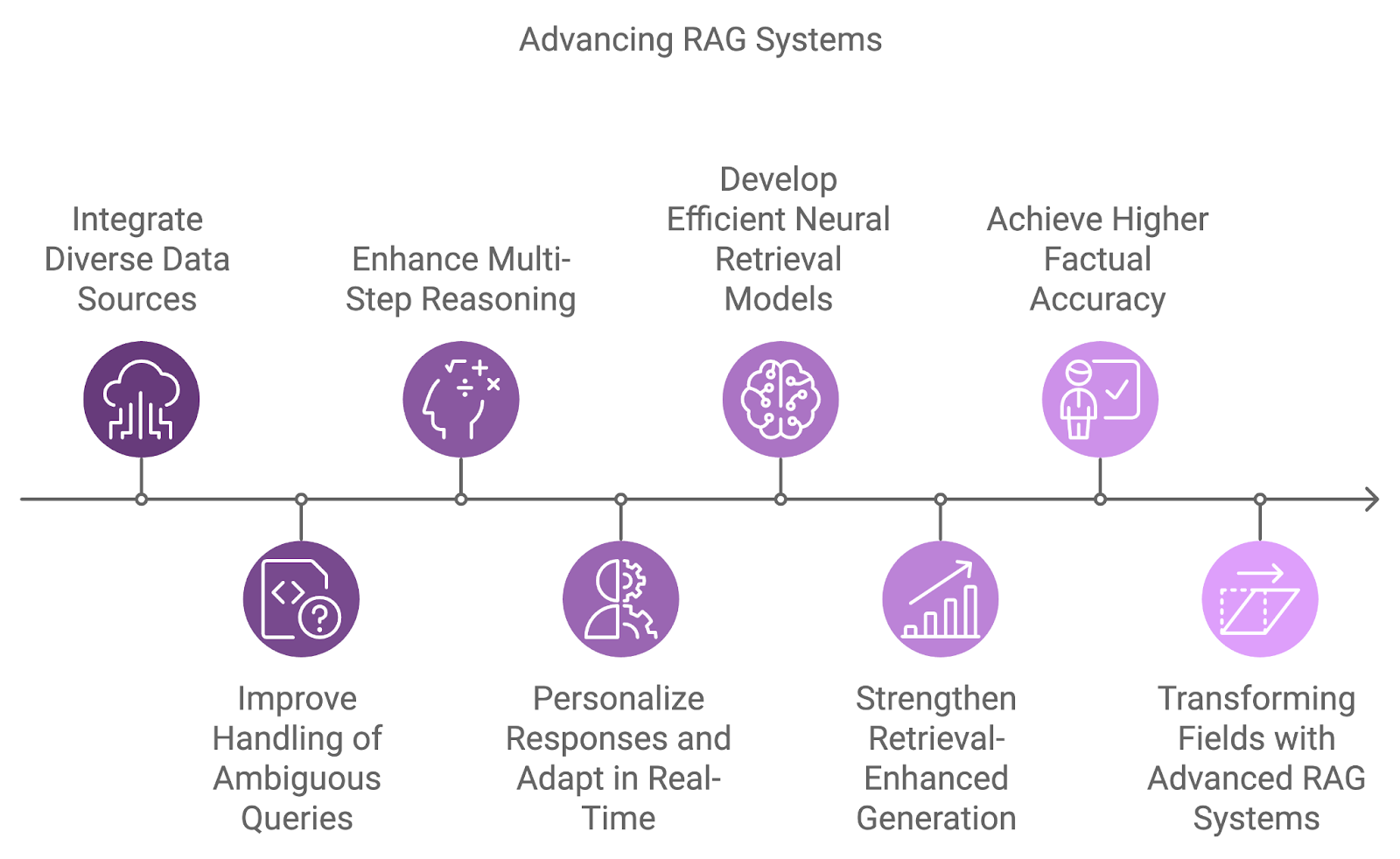
Diagrama gerado com o napkin.ai
Os modelos atuais de recuperação densa são altamente eficazes, mas há pesquisas em andamento para desenvolver modelos de recuperação neural ainda mais eficientes e precisos. Esses modelos têm como objetivo capturar melhor as semelhanças semânticas em uma gama mais ampla de pares consulta-documento e, ao mesmo tempo, aumentar a eficiência em tarefas de recuperação em grande escala.
Artigos como Karpukhin et al. (2020) introduziu o Dense Passage Retrieval (DPR) como um método central para responder a perguntas de domínio aberto, enquanto estudos mais recentes como Izacard et al. (2022) concentram-se no aprendizado de poucos disparos para adaptar os sistemas RAG a tarefas específicas do domínio.
Outra área de pesquisa emergente se concentra em melhorar a conexão entre recuperação e geração por meio de modelos de geração aprimorados por recuperação. Esses modelos visam integrar perfeitamente os documentos recuperados ao processo de geração, permitindo que o modelo de linguagem condicione sua saída mais diretamente ao conteúdo recuperado.
Isso pode reduzir as alucinações e melhorar a precisão factual das respostas geradas, tornando o sistema mais confiável. Trabalhos notáveis incluem Huang et al. (2023) com o modelo RAVEN, que aprimora o aprendizado no contexto usando modelos de codificador-decodificador com reforço de recuperação.
A integração de técnicas avançadas de RAG, como recuperação densa, reranking e raciocínio em várias etapas, garante que os sistemas RAG possam atender às demandas de aplicativos do mundo real, desde a área da saúde até recomendações personalizadas.
No futuro, a evolução dos sistemas RAG será impulsionada por inovações como recursos multilíngues, geração personalizada e manipulação de fontes de dados mais diversificadas.
Se você quiser continuar aprendendo e se familiarizar mais com os sistemas RAG, recomendo estes tutoriais:
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Natassha Selvaraj
10 min
blog
Hesam Sheikh Hassani
15 min
blog
Stanislav Karzhev
9 min
Tutorial
Ryan Ong
Tutorial
Zoumana Keita
Tutorial
Arunn Thevapalan
