
Program
Pengembangan Aplikasi Kecerdasan Buatan
21 Hr
Retrieval-augmented generation (RAG) menggabungkan pengambilan dokumen dengan generasi bahasa alami, menghasilkan respons yang lebih akurat dan peka konteks.
Meskipun RAG dasar efektif, metode ini kesulitan menghadapi kueri kompleks, halusinasi, dan menjaga konteks dalam percakapan multi-giliran.
Dalam blog ini, saya akan membahas teknik lanjutan yang mengatasi tantangan tersebut dengan meningkatkan akurasi pengambilan, kualitas generasi, dan kinerja sistem secara keseluruhan.
Jika Anda membaca ini untuk persiapan wawancara, pastikan untuk melihat artikel 30 Pertanyaan dan Jawaban Wawancara RAG Teratas.
Walau implementasi RAG dasar dapat bermanfaat, tetap ada keterbatasannya, terutama saat digunakan dalam konteks yang lebih menuntut.
Salah satu isu paling menonjol adalah halusinasi, ketika model menghasilkan konten yang secara faktual salah atau tidak didukung dokumen yang diambil. Ini dapat merusak keandalan sistem, terutama di bidang yang menuntut akurasi tinggi seperti kedokteran atau hukum.
Model RAG standar mungkin kesulitan menangani kueri spesifik domain. Tanpa menyesuaikan proses pengambilan dan generasi dengan seluk-beluk domain khusus, sistem berisiko mengambil informasi yang tidak relevan atau tidak akurat.
Tantangan lain adalah mengelola kueri multi-langkah yang kompleks atau percakapan multi-giliran. Sistem RAG dasar sering kesulitan mempertahankan konteks di antara interaksi, sehingga jawaban menjadi terputus-putus atau tidak lengkap. Seiring kueri pengguna makin kompleks, sistem RAG perlu berevolusi untuk mengatasinya.
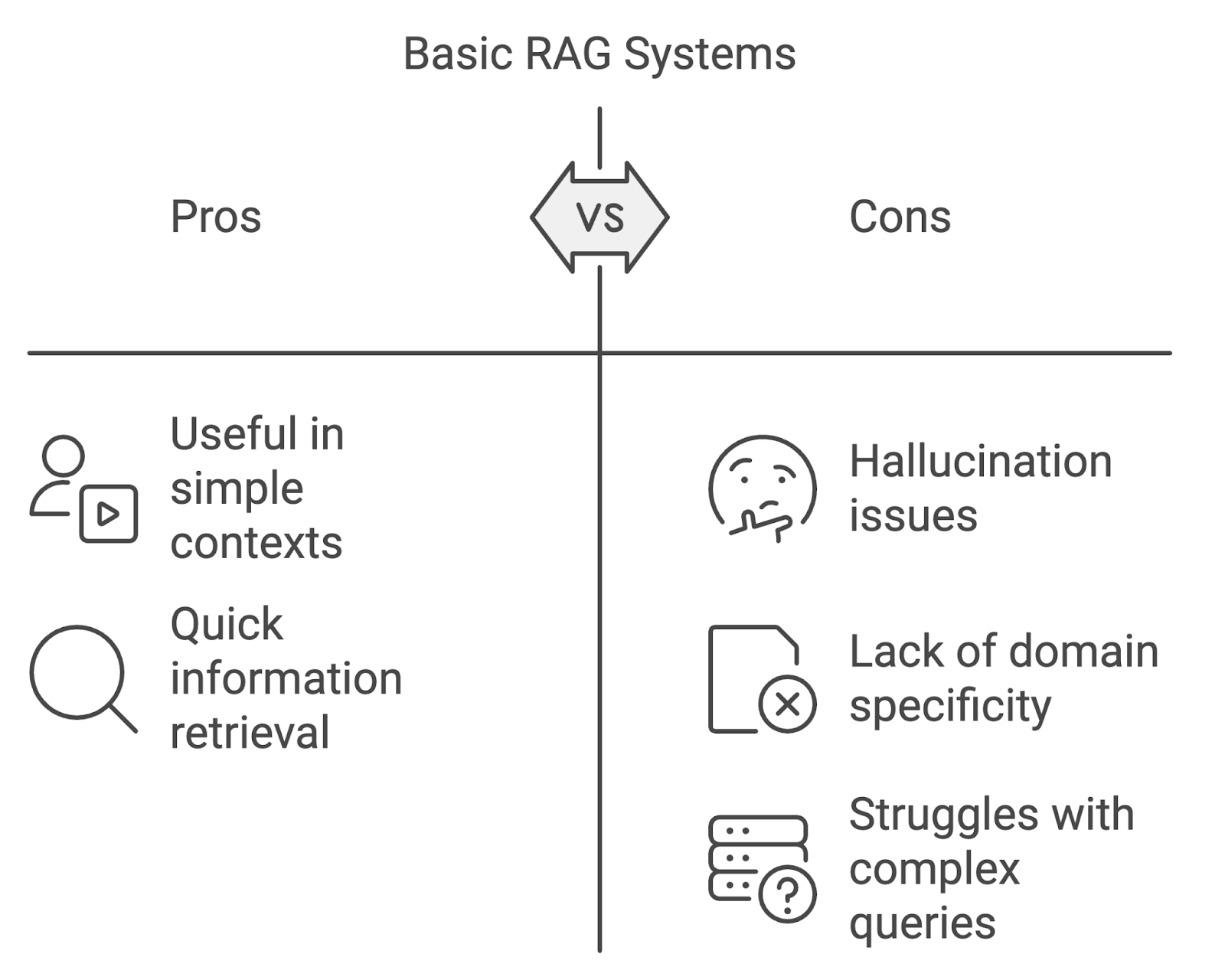
Diagram dibuat dengan napkin.ai
Teknik pengambilan lanjutan berfokus pada peningkatan relevansi dan cakupan dokumen yang diambil. Teknik-teknik ini, termasuk dense retrieval, pencarian hibrida, reranking, dan perluasan kueri, mengatasi keterbatasan pengambilan berbasis kata kunci.
Dense retrieval dan pencarian hibrida adalah teknik kunci untuk meningkatkan akurasi dan relevansi pengambilan. Metode seperti TF-IDF atau BM25 sering kesulitan memahami semantik ketika kueri dirumuskan berbeda dari dokumen.
Dense retrieval, seperti DPR (Dense Passage Retrieval), menggunakan pembelajaran mendalam untuk memetakan kueri dan dokumen ke representasi vektor yang padat, menangkap makna teks melampaui kecocokan kata kunci persis.
Pencarian hibrida memadukan retrieval jarang dan padat, menyeimbangkan presisi dan jangkauan dengan menggabungkan pencocokan berbasis kata kunci dengan kemiripan semantik, sehingga efektif untuk kueri yang lebih kompleks.
Reranking adalah teknik lanjutan untuk menyaring daftar dokumen yang diambil sebelum diteruskan ke komponen generasi. Dalam sistem RAG tipikal, fase pengambilan awal dapat menghasilkan banyak dokumen dengan tingkat relevansi yang beragam.
Peran reranking adalah mengurutkan ulang dokumen-dokumen tersebut agar yang paling relevan diprioritaskan untuk digunakan oleh model bahasa. Reranking dapat dilakukan mulai dari penskoran sederhana berbasis kemiripan kueri-dokumen hingga model pembelajaran mesin yang lebih kompleks untuk memprediksi relevansi setiap dokumen.
Anda dapat mempelajari cara mengimplementasikan reranking melalui tutorial tentang reranking dengan RankGPT.
Perluasan kueri melibatkan memperkaya kueri pengguna dengan istilah tambahan yang meningkatkan peluang mengambil dokumen relevan. Ini dapat dilakukan melalui:
Sebagai contoh, jika kueri asli adalah “artificial intelligence in healthcare,” perluasan kueri dapat mencakup istilah terkait seperti “AI,” “machine learning,” atau “health tech,” sehingga jaring pengambilan menjadi lebih luas.
Dalam sistem RAG, sekadar mengambil dokumen tidaklah cukup; memastikan relevansi dan kualitas dokumen-dokumen tersebut adalah kunci untuk meningkatkan keluaran akhir. Untuk itu, teknik lanjutan yang memperhalus dan menyaring konten yang diambil sangat penting.
Metode-metode ini bekerja untuk mengurangi kebisingan, meningkatkan relevansi, dan memfokuskan model bahasa pada informasi terpenting selama proses generasi.
Teknik penyaringan lanjutan menggunakan metadata atau aturan berbasis konten untuk mengecualikan dokumen yang tidak relevan atau berkualitas rendah, memastikan hanya hasil paling relevan yang diteruskan.
Distilasi konteks adalah proses meringkas atau memadatkan dokumen yang diambil untuk memfokuskan model bahasa pada potongan informasi paling penting. Ini berguna ketika dokumen yang diambil berisi terlalu banyak konten yang tidak relevan atau ketika kueri melibatkan penalaran multi-langkah yang kompleks.
Dengan mendistilasi konteks, sistem mengekstrak wawasan kunci dan bagian paling relevan dari dokumen yang diambil, memastikan model bahasa memiliki informasi yang paling jelas dan tepat untuk digunakan.
Setelah dokumen relevan diambil dan diperhalus, langkah selanjutnya dalam sistem RAG adalah proses generasi. Mengoptimalkan cara model bahasa menghasilkan respons penting untuk memastikan akurasi, koherensi, dan relevansi.
Prompt engineering merujuk pada proses merancang dan menyusun prompt yang diberikan ke model bahasa. Kualitas prompt berdampak langsung pada kualitas keluaran model, karena prompt memberikan instruksi atau konteks awal untuk tugas generasi.
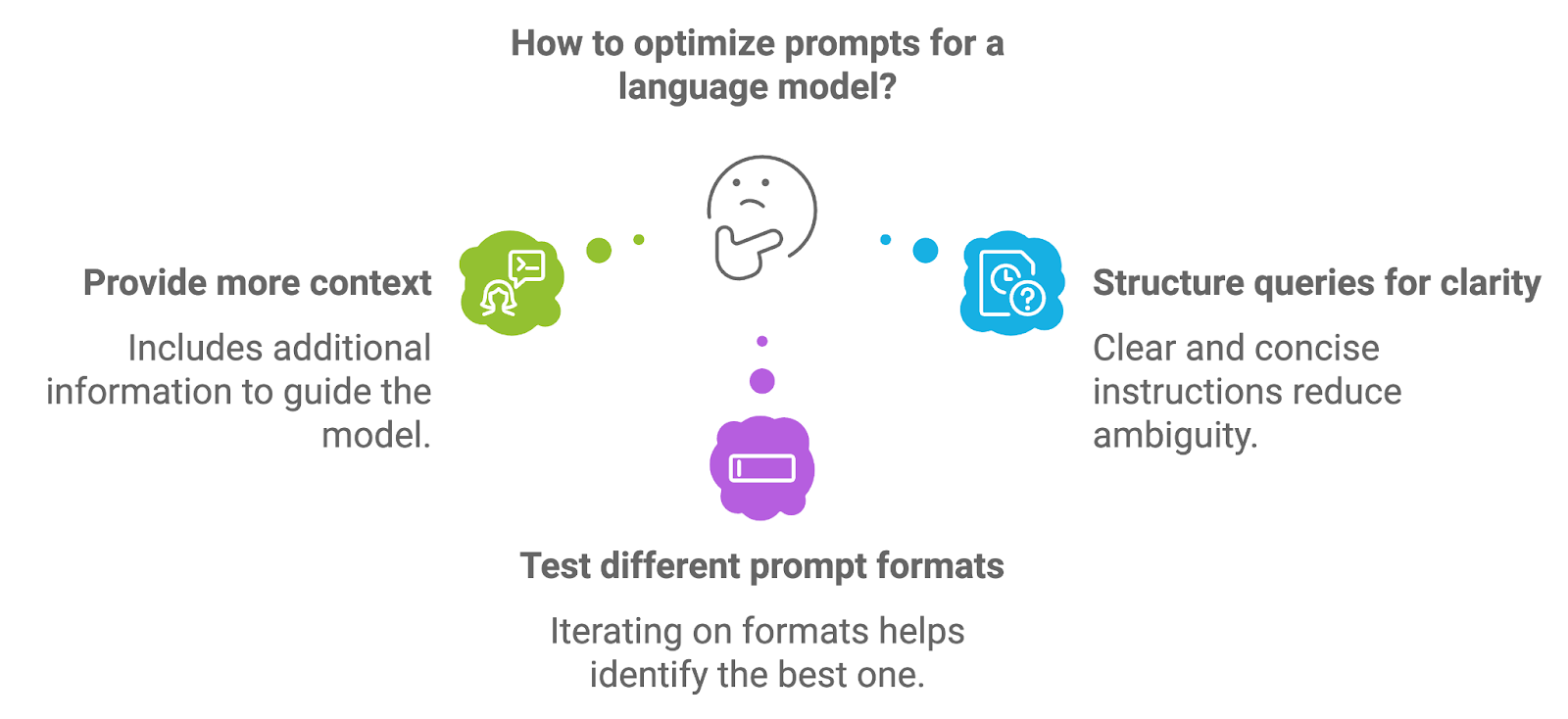
Diagram dibuat dengan napkin.ai
Untuk mengoptimalkan prompt, pengembang dapat bereksperimen dengan beberapa pendekatan.
Menyertakan informasi tambahan, seperti instruksi eksplisit atau istilah kunci, dapat memandu model menuju respons yang lebih akurat dan relevan secara kontekstual. Misalnya, dalam sistem RAG medis, prompt dapat secara eksplisit meminta model memberikan ringkasan diagnosis berdasarkan dokumen yang diambil.
Prompt yang tersusun baik, dengan instruksi yang jelas dan ringkas, membantu mengurangi ambiguitas dan menghasilkan generasi yang lebih terfokus. Merumuskan prompt sebagai pertanyaan atau permintaan langsung sering memberikan hasil lebih baik.
Mengiterasi format prompt seperti memparafrasekan pertanyaan, menyesuaikan tingkat spesifisitas, atau memberikan contoh dapat membantu menemukan format yang memberikan hasil terbaik untuk kasus penggunaan tertentu.
Pelajari lebih lanjut di blog ini: Teknik Optimasi Prompt.
Banyak kueri, khususnya di bidang riset, hukum, atau dukungan teknis, melibatkan beberapa langkah atau memerlukan penalaran kompleks. Penalaran multi-langkah adalah proses ketika sistem memecah kueri kompleks menjadi sub-tugas yang dapat dikelola dan memprosesnya secara berurutan untuk menghasilkan jawaban komprehensif.
Kita dapat mengimplementasikan penalaran multi-langkah dalam sistem RAG melalui berbagai cara:
Seperti disebutkan sekilas, salah satu tantangan utama pada model generatif, termasuk yang digunakan dalam sistem RAG, adalah halusinasi. Beberapa teknik dapat membantu menguranginya dalam sistem RAG:
Seiring sistem RAG makin banyak diterapkan pada tugas dunia nyata, sistem harus mampu menangani interaksi kompleks, multi-giliran, dan kueri ambigu.
Salah satu tantangan utama dalam sistem RAG percakapan adalah mengelola aliran informasi di banyak interaksi. Dalam banyak skenario sehari-hari, seperti dukungan pelanggan atau diskusi teknis berkelanjutan, pengguna sering terlibat dalam percakapan multi-giliran di mana konteks harus dipertahankan di beberapa pertukaran.
Kemampuan sistem untuk melacak dan mengingat bagian percakapan yang relevan sangat penting untuk memberikan respons yang koheren dan konsisten. Untuk menangani percakapan multi-giliran secara efektif, sistem RAG dapat menggunakan teknik berikut:
Kueri pengguna tidak selalu lugas; sering kali bersifat samar, ambigu, atau melibatkan penalaran kompleks yang menantang kapabilitas sistem RAG.
Salah satu cara mengatasi ambiguitas adalah mendorong sistem untuk meminta klarifikasi dari pengguna. Misalnya, jika kueri terlalu samar, sistem dapat menghasilkan pertanyaan lanjutan yang meminta detail lebih spesifik. Proses interaktif ini membantu mempersempit maksud pengguna sebelum melanjutkan ke fase pengambilan dan generasi.
Untuk kueri kompleks yang melibatkan banyak aspek atau subtopik, sistem dapat memecah kueri menjadi bagian yang lebih kecil dan mudah dikelola. Ini melibatkan pengambilan informasi bertahap, di mana setiap tahap menangani aspek spesifik kueri. Keluaran akhir kemudian disintesis dari beberapa langkah pengambilan dan generasi, memastikan semua komponen kueri terjawab.
Untuk menangani ambiguitas, sistem dapat menggunakan petunjuk kontekstual dari kueri atau riwayat percakapan. Dengan menganalisis interaksi sebelumnya atau topik terkait, sistem RAG dapat menyimpulkan maksud pengguna dengan lebih akurat, mengurangi kemungkinan menghasilkan respons yang tidak relevan atau salah.
Untuk kueri yang sangat menantang, sistem RAG dapat menerapkan metode pengambilan lanjutan, seperti multi-hop question answering, di mana sistem mengambil informasi dari beberapa dokumen dan membuat koneksi logis di antaranya untuk menjawab kueri kompleks.
Meskipun sistem RAG menawarkan solusi kuat untuk pengambilan informasi dan generasi teks, ada pula tantangan spesifik yang perlu ditangani.
Bias pada model bahasa, termasuk yang digunakan dalam sistem RAG, adalah isu yang dikenal luas dan dapat berdampak negatif terhadap keadilan dan akurasi keluaran yang dihasilkan. Bias dapat masuk melalui fase pengambilan maupun generasi, menghasilkan keluaran yang menyimpang atau diskriminatif yang merefleksikan bias sosial, budaya, atau spesifik domain pada dataset dasar.
Untuk mengurangi bias dalam sistem RAG, beberapa strategi dapat diterapkan:
Seiring sistem RAG menjadi lebih kompleks dengan integrasi teknik pengambilan dan generasi lanjutan, tuntutan komputasi juga meningkat. Tantangan ini muncul pada ukuran model, kecepatan pemrosesan, dan latensi, yang semuanya dapat memengaruhi efisiensi dan skalabilitas sistem.
Untuk mengelola beban komputasi, pengembang dapat menerapkan optimasi berikut:
Sistem RAG sangat bergantung pada kualitas dan cakupan data yang diambil dan dihasilkan. Dalam aplikasi spesifik domain, keterbatasan data bisa menjadi tantangan besar, terutama ketika data pelatihan yang tersedia tidak memadai, usang, atau berkualitas rendah.
Kita dapat mengatasi keterbatasan data dalam sistem RAG dengan beberapa pendekatan.
Saat data pelatihan spesifik domain terbatas, teknik augmentasi data dapat membantu memperluas dataset secara artifisial. Ini bisa mencakup menghasilkan data sintetis, memparafrasekan dokumen yang ada, atau menggunakan sumber eksternal untuk melengkapi dataset asli. Augmentasi data memastikan model memiliki akses ke ragam contoh yang lebih luas, meningkatkan kemampuannya menangani kueri beragam.
Melakukan fine-tuning model bahasa pra-latih pada dataset kecil spesifik domain dapat membantu sistem RAG beradaptasi ke kasus penggunaan khusus, bahkan dengan data terbatas. Adaptasi domain memungkinkan model lebih memahami terminologi dan nuansa industri, sehingga meningkatkan kualitas respons yang dihasilkan.
Jika data pelatihan berkualitas tinggi langka, active learning dapat digunakan untuk meningkatkan dataset secara iteratif. Dengan mengidentifikasi titik data yang paling informatif dan memfokuskan upaya anotasi pada titik-titik tersebut, pengembang dapat secara bertahap meningkatkan dataset tanpa memerlukan data berlabel dalam jumlah besar sejak awal.
Mengimplementasikan teknik lanjutan dalam sistem RAG memerlukan pemahaman yang kuat tentang alat, kerangka kerja, dan strategi yang tersedia. Seiring teknik-teknik ini menjadi lebih kompleks, memanfaatkan pustaka dan kerangka kerja khusus menyederhanakan integrasi alur kerja pengambilan dan generasi yang canggih.
Banyak kerangka kerja dan pustaka telah hadir untuk mendukung implementasi teknik RAG lanjutan, menawarkan solusi modular dan skalabel bagi pengembang dan peneliti. Alat-alat ini meningkatkan proses pembangunan sistem RAG dengan menyediakan komponen untuk pengambilan, pemeringkatan, penyaringan, dan generasi.
LangChain adalah kerangka kerja populer yang dirancang khusus untuk bekerja dengan model bahasa dan mengintegrasikannya dengan sumber data eksternal. Kerangka ini mendukung teknik retrieval-augmented lanjutan, termasuk pengindeksan dokumen, kueri, dan perangkaian berbagai langkah pemrosesan (pengambilan, generasi, dan penalaran).
LangChain juga menawarkan integrasi siap pakai dengan basis data vektor dan berbagai retriever, menjadikannya opsi serbaguna untuk membangun sistem RAG kustom.
Pelajari lebih lanjut tentang LangChain dan RAG di kursus ini: Membangun Sistem RAG dengan LangChain
Haystack adalah kerangka kerja open-source yang mengkhususkan diri pada pembangunan sistem RAG untuk penggunaan produksi. Ia menyediakan alat untuk dense retrieval, pemeringkatan dokumen, dan penyaringan, serta generasi bahasa alami.
Haystack sangat kuat untuk aplikasi yang memerlukan pencarian spesifik domain, tanya jawab, atau ringkasan dokumen. Dengan dukungan beragam backend dan integrasi dengan model bahasa populer, Haystack menyederhanakan penerapan sistem RAG di skenario dunia nyata.
OpenAI API memungkinkan pengembang mengintegrasikan model bahasa yang kuat, seperti GPT-4, ke dalam alur kerja RAG. Meskipun tidak spesifik untuk tugas retrieval-augmented, model OpenAI dapat digunakan bersama kerangka kerja pengambilan untuk menghasilkan respons berbasis informasi yang diambil, memungkinkan kapabilitas generasi tingkat lanjut.
Untuk mengintegrasikan teknik lanjutan ke dalam sistem RAG yang ada, penting mengikuti pendekatan terstruktur.
Mulailah dengan memilih kerangka kerja atau pustaka yang selaras dengan kasus penggunaan Anda. Misalnya, jika Anda memerlukan sistem yang sangat skalabel dengan kapabilitas dense retrieval, kerangka kerja seperti LangChain atau Haystack sangat ideal.
Langkah pertama adalah menyiapkan komponen pengambilan, yang melibatkan pengindeksan sumber data dan mengonfigurasi metode pengambilan. Bergantung pada kasus penggunaan, Anda mungkin memilih dense retrieval (menggunakan embedding vektor) atau pencarian hibrida (menggabungkan metode jarang dan padat). Misalnya, LangChain atau Haystack dapat digunakan untuk membuat pipeline pengambilan.
Setelah sistem pengambilan berjalan, langkah berikutnya adalah meningkatkan relevansi melalui teknik reranking dan penyaringan. Ini dapat dilakukan menggunakan modul reranking bawaan di Haystack atau dengan menyesuaikan model reranking Anda berdasarkan jenis kueri spesifik.
Setelah pengambilan, optimalkan proses generasi dengan memanfaatkan prompt engineering, distilasi konteks, dan penalaran multi-langkah. Dengan LangChain, Anda dapat merangkai langkah pengambilan dan generasi untuk menangani kueri multi-langkah atau menggunakan templat prompt yang mengondisikan model agar menghasilkan generasi yang lebih akurat.
Jika halusinasi menjadi masalah, fokuskan pada grounding generasi pada dokumen yang diambil, memastikan model menghasilkan keluaran berdasarkan konten dokumen tersebut.
Pengujian rutin sangat penting untuk menyempurnakan performa sistem RAG. Gunakan metrik evaluasi seperti akurasi, relevansi, dan kepuasan pengguna untuk menilai efektivitas teknik lanjutan seperti reranking dan distilasi konteks. Jalankan uji A/B untuk membandingkan pendekatan berbeda dan menyetel sistem berdasarkan umpan balik.
Seiring sistem berkembang, beban komputasi dapat menjadi perhatian. Untuk mengelolanya, terapkan teknik optimasi seperti distilasi atau kuantisasi model, dan pastikan proses pengambilan efisien. Memanfaatkan akselerasi GPU atau paralelisasi juga dapat membantu menjaga performa pada skala besar.
Sistem RAG perlu berevolusi untuk beradaptasi dengan kueri dan data baru. Siapkan alat pemantauan untuk melacak performa sistem secara real-time, dan terus perbarui model serta indeks pengambilan untuk menghadapi tren dan kebutuhan yang muncul.
Mengimplementasikan teknik lanjutan dalam sistem RAG hanyalah awal. Dengan menggunakan metrik evaluasi dan metode pengujian yang tepat seperti uji A/B, kita dapat menilai seberapa baik sistem merespons kueri pengguna dan membaik seiring waktu.
Akurasi mengukur seberapa sering sistem mengambil dan menghasilkan respons yang benar atau relevan. Untuk sistem tanya jawab, ini dapat melibatkan perbandingan langsung antara jawaban yang dihasilkan dengan data kebenaran dasar. Peningkatan akurasi menunjukkan sistem menafsirkan kueri dengan tepat dan memberikan hasil yang presisi.
Metrik ini mengevaluasi relevansi dokumen yang diambil dan kualitas respons yang dihasilkan berdasarkan seberapa baik keduanya menjawab kueri pengguna. Metrik seperti Mean Reciprocal Rank (MRR) atau Precision@K umum digunakan untuk mengukur relevansi, menilai seberapa tinggi dokumen paling relevan muncul dalam peringkat.
Walau akurasi dan relevansi krusial, performa waktu nyata juga penting. Latensi merujuk pada waktu respons sistem—kecepatan sistem mengambil dokumen dan menghasilkan jawaban. Latensi rendah sangat penting pada aplikasi yang membutuhkan respons tepat waktu, seperti dukungan pelanggan atau sistem tanya jawab langsung.
Cakupan mengukur seberapa baik sistem RAG menangani berbagai jenis kueri. Dalam aplikasi spesifik domain, memastikan sistem mampu menangani seluruh cakupan potensi kueri pengguna adalah kunci untuk memberikan dukungan komprehensif.
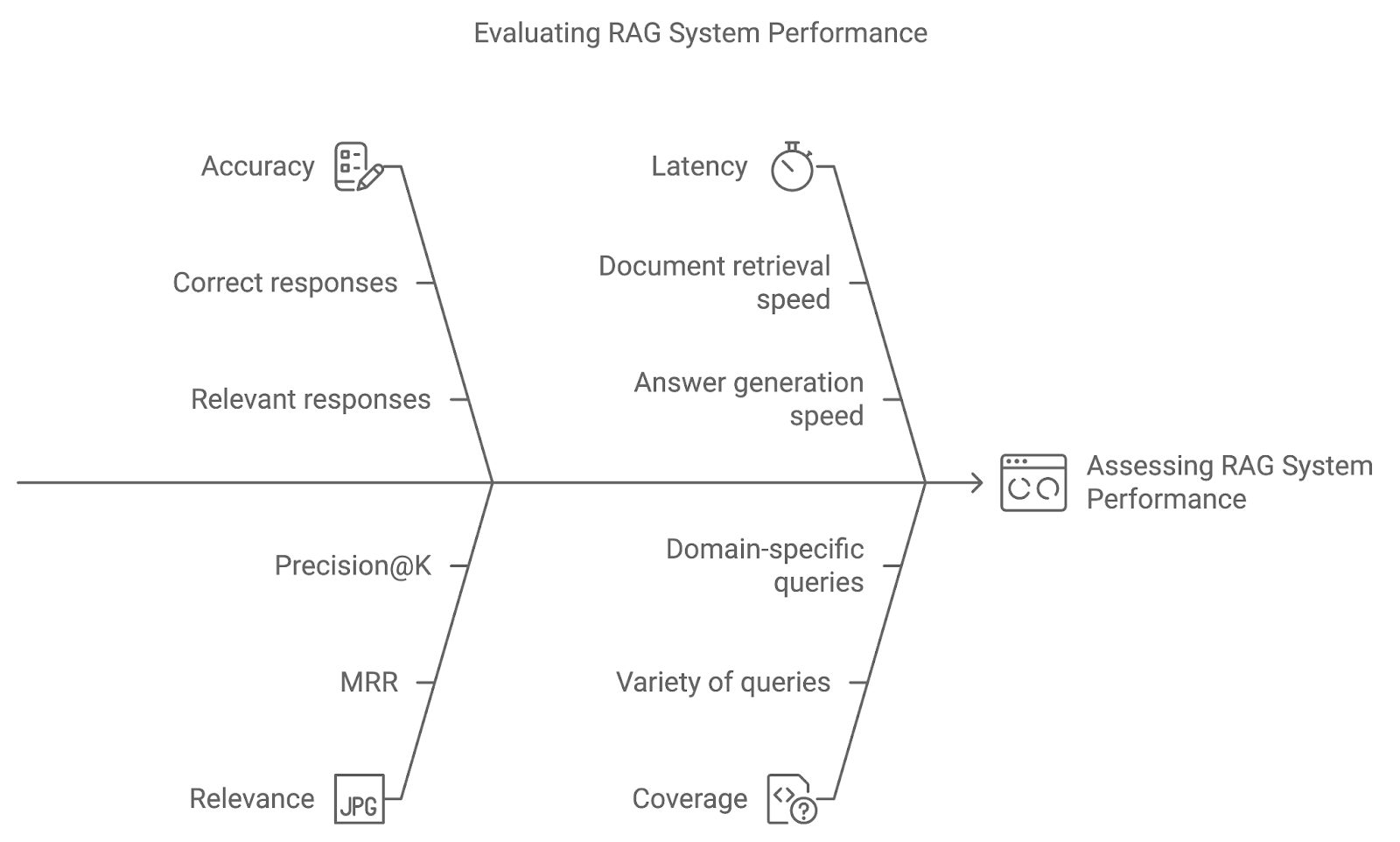
Diagram dibuat dengan napkin.ai
Teknik RAG lanjutan membuka berbagai kemungkinan di beragam industri dan aplikasi.
Salah satu kasus penggunaan paling berdampak dari teknik RAG lanjutan adalah pada sistem tanya jawab (QA) yang kompleks. Sistem ini memerlukan lebih dari sekadar pengambilan dokumen sederhana—mereka harus memahami konteks, memecah kueri multi-langkah, dan memberikan jawaban komprehensif berdasarkan dokumen yang diambil.
Dalam industri yang membutuhkan pengetahuan spesifik domain, sistem RAG lanjutan dapat dibangun untuk mengambil dan menghasilkan konten yang sangat khusus. Beberapa aplikasi penting meliputi:
Sistem rekomendasi personal juga merupakan kasus penggunaan kunci untuk teknik RAG lanjutan. Dengan menggabungkan preferensi pengguna, perilaku, dan sumber data eksternal, sistem RAG dapat menghasilkan rekomendasi personal untuk produk, layanan, atau konten, termasuk:
Generasi berikutnya dari sistem RAG akan mengintegrasikan lebih banyak sumber data yang beragam, meningkatkan kemampuan penalaran, dan mengatasi keterbatasan saat ini seperti ambiguitas dan penanganan kueri kompleks.
Salah satu area pengembangan kunci adalah integrasi berbagai sumber data, melampaui ketergantungan pada satu dataset. Sistem masa depan akan menggabungkan informasi dari beragam sumber seperti basis data, API, dan umpan waktu nyata, memungkinkan jawaban yang lebih komprehensif dan multidimensi untuk kueri kompleks.
Menangani kueri ambigu atau tidak lengkap adalah tantangan lain yang akan diatasi sistem RAG mendatang. Dengan memadukan penalaran probabilistik dan pemahaman konteks yang lebih baik, sistem ini akan mengelola ketidakpastian secara lebih efektif.
Selain itu, penalaran multi-langkah akan menjadi lebih integral dalam cara sistem RAG memproses kueri kompleks, memecahnya menjadi komponen yang lebih kecil dan mensintesis hasilnya lintas banyak dokumen atau langkah. Ini akan sangat bermanfaat di bidang seperti riset hukum, penemuan ilmiah, dan dukungan pelanggan, di mana kueri sering memerlukan penghubungan berbagai potongan informasi.
Seiring personalisasi dan kesadaran konteks terus meningkat, sistem RAG masa depan akan menyesuaikan respons berdasarkan riwayat, preferensi, dan interaksi pengguna sebelumnya. Adaptasi waktu nyata terhadap informasi baru akan memungkinkan percakapan yang lebih dinamis dan produktif.
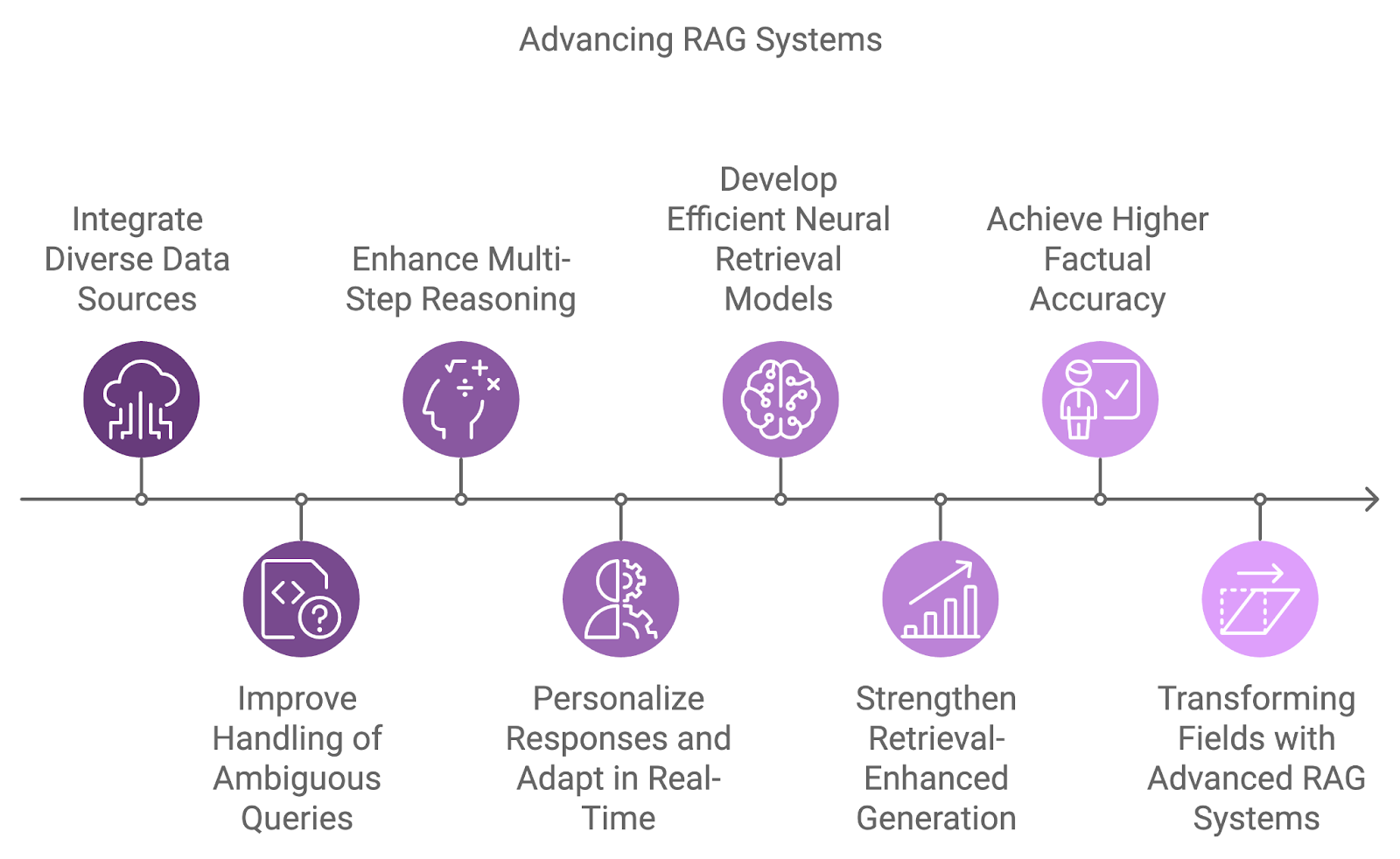
Diagram dibuat dengan napkin.ai
Model dense retrieval saat ini sangat efektif, namun riset terus dilakukan untuk mengembangkan model retrieval neural yang lebih efisien dan akurat. Model-model ini bertujuan menangkap kemiripan semantik dengan lebih baik di berbagai pasangan kueri-dokumen sekaligus meningkatkan efisiensi dalam tugas pengambilan berskala besar.
Makalah seperti Karpukhin et al. (2020) memperkenalkan Dense Passage Retrieval (DPR) sebagai metode inti untuk tanya jawab domain terbuka, sementara studi yang lebih baru seperti Izacard et al. (2022) berfokus pada pembelajaran few-shot untuk menyesuaikan sistem RAG pada tugas spesifik domain.
Bidang riset lain yang muncul berfokus pada peningkatan koneksi antara pengambilan dan generasi melalui model generasi berpenunjang retrieval. Model-model ini bertujuan mengintegrasikan dokumen yang diambil secara mulus ke dalam proses generasi, memungkinkan model bahasa mengondisikan keluarannya lebih langsung pada konten yang diambil.
Ini dapat mengurangi halusinasi dan meningkatkan akurasi faktual respons yang dihasilkan, sehingga sistem lebih andal. Karya penting termasuk Huang et al. (2023) dengan model RAVEN, yang meningkatkan pembelajaran dalam konteks menggunakan model encoder-decoder berpenunjang retrieval.
Integrasi teknik RAG lanjutan seperti dense retrieval, reranking, dan penalaran multi-langkah memastikan sistem RAG mampu memenuhi tuntutan aplikasi dunia nyata, dari layanan kesehatan hingga rekomendasi yang dipersonalisasi.
Ke depan, evolusi sistem RAG akan didorong oleh inovasi seperti kapabilitas lintas bahasa, generasi yang dipersonalisasi, dan penanganan sumber data yang lebih beragam.
Jika Anda ingin terus belajar dan praktik langsung dengan sistem RAG, saya merekomendasikan tutorial berikut:
Belajar AI dengan kursus-kursus ini!
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
