
Cursus
Développer des applications d'IA
21 h
La génération augmentée par la recherche (RAG) associe la recherche de documents à la génération de langage naturel, ce qui permet d'obtenir des réponses plus précises et mieux adaptées au contexte.
Bien que le RAG de base soit efficace, il a du mal à répondre aux requêtes complexes, aux hallucinations et à maintenir le contexte dans les conversations à plusieurs tours.
Dans ce blog, j'explorerai les techniques avancées qui permettent de relever ces défis en améliorant la précision de la recherche, la qualité de la génération et les performances globales du système.
Si vous lisez ceci en vue d'un entretien, n'oubliez pas de consulter les Les 30 meilleures questions et réponses pour un entretien avec un RAG article.
Si les applications de base des RAG peuvent être utiles, elles ont leurs limites, en particulier lorsqu'elles sont appliquées dans des contextes plus exigeants.
L'un des problèmes les plus importants est l'hallucination, lorsque le modèle génère un contenu factuellement incorrect ou non étayé par les documents récupérés. Cela peut nuire à la fiabilité du système, en particulier dans les domaines exigeant une grande précision, tels que la médecine ou le droit.
Les modèles RAG standard peuvent se heurter à des difficultés lorsqu'ils traitent des requêtes spécifiques à un domaine. Si les processus de recherche et de génération ne sont pas adaptés aux nuances des domaines spécialisés, le système risque de récupérer des informations non pertinentes ou inexactes.
Un autre défi consiste à gérer des requêtes complexes en plusieurs étapes ou des conversations à plusieurs tours. Les systèmes RAG de base ont souvent du mal à maintenir le contexte à travers les interactions, ce qui conduit à des réponses décousues ou incomplètes. Au fur et à mesure que les requêtes des utilisateurs deviennent plus complexes, les systèmes RAG doivent évoluer pour gérer cette complexité croissante.
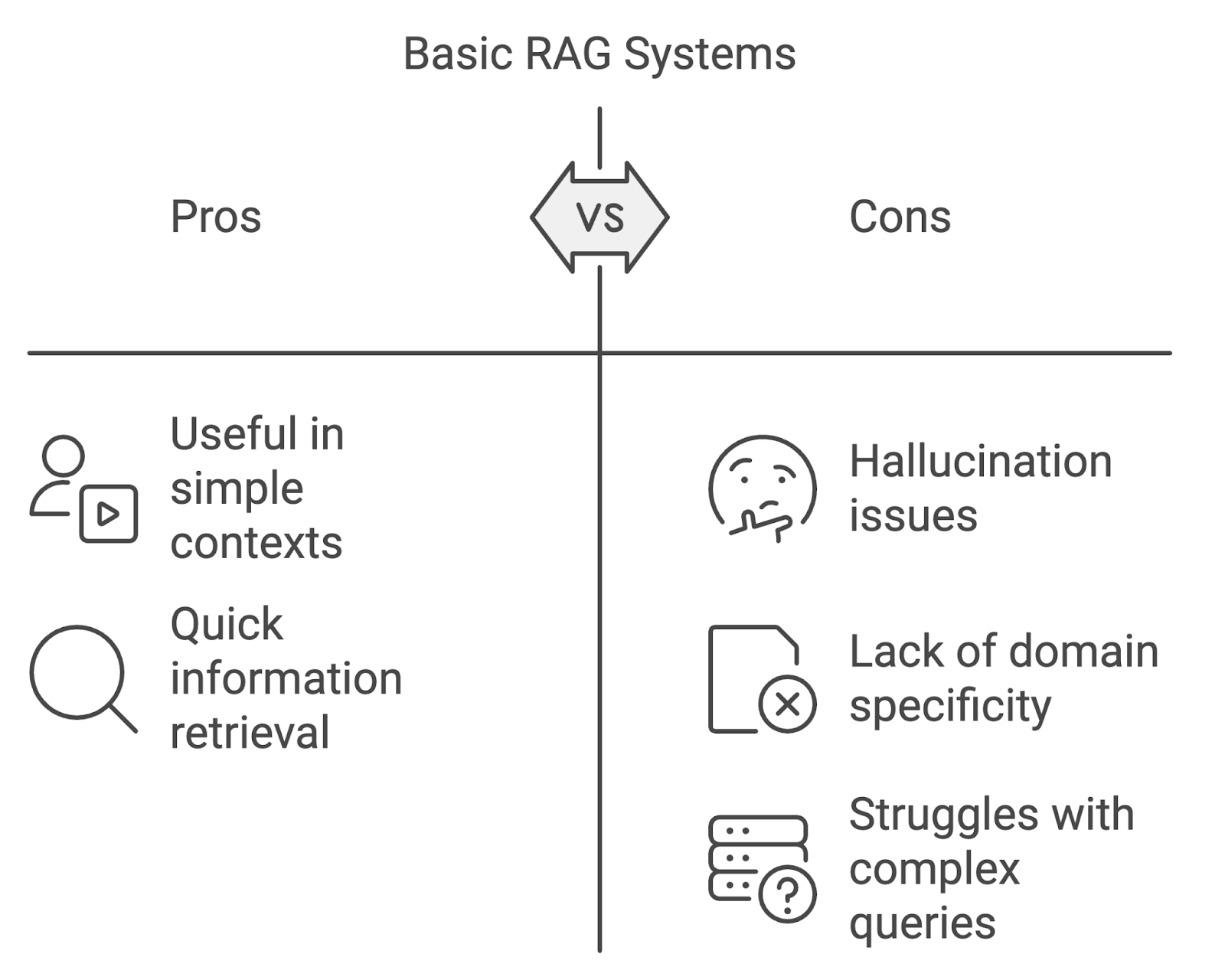
Diagramme généré avec napkin.ai
Les techniques de recherche avancées visent à améliorer à la fois la pertinence et la portée des documents retrouvés. Ces techniques, qui comprennent la recherche dense, la recherche hybride, le reclassement et l'expansion des requêtes, répondent aux limites de la recherche par mot-clé.
La recherche dense et la recherche hybride sont des techniques clés pour améliorer la précision et la pertinence de la recherche. Les méthodes telles que TF-IDF ou BM25 ont souvent du mal à comprendre la sémantique lorsque les requêtes sont formulées différemment des documents.
La récupération dense, telle que DPR (Dense Passage Retrieval), utilise l'apprentissage profond (deep learning). l'apprentissage profond pour cartographier les requêtes et les documents en représentations vectorielles représentations vectoriellesL'apprentissage profond permet de capturer le sens du texte au-delà des mots-clés exacts.
La recherche hybride combine la recherche dense et la recherche éparse, équilibrant la précision et le rappel en combinant la correspondance par mot-clé avec la similarité sémantique, ce qui la rend efficace pour les requêtes plus complexes.
Le reclassement est une autre technique avancée utilisée pour affiner la liste des documents récupérés avant qu'ils ne soient transmis au composant de génération. Dans un système RAG typique, la phase initiale de recherche peut produire un grand nombre de documents dont la pertinence varie.
Le rôle du reranking est de réorganiser ces documents de manière à ce que les plus pertinents soient utilisés en priorité par le modèle linguistique. Le reclassement peut aller d'une simple notation basée sur la similarité requête-document à des modèles d'apprentissage automatique plus complexes formés pour prédire la pertinence de chaque document.
Vous pouvez apprendre comment mettre en œuvre le reranking dans ce tutoriel sur le reclassement avec RankGPT.
L'expansion de la requête consiste à enrichir la requête de l'utilisateur avec des termes supplémentaires qui augmentent les chances de trouver des documents pertinents. Il peut être atteint grâce à :
Par exemple, si la requête initiale est "intelligence artificielle dans les soins de santé", l'extension de la requête peut inclure des termes connexes tels que "IA", "apprentissage automatique" ou "technologie de la santé", ce qui permet d'élargir le champ de recherche.
Dans les systèmes RAG, il ne suffit pas d'extraire des documents, il faut aussi s'assurer de la pertinence et de la qualité de ces documents pour améliorer le résultat final. À cette fin, les techniques avancées qui affinent et filtrent le contenu récupéré sont essentielles.
Ces méthodes permettent de réduire le bruit, d'augmenter la pertinence et de concentrer le modèle linguistique sur les informations les plus importantes au cours du processus de génération.
Des techniques de filtrage avancées utilisent des métadonnées ou des règles basées sur le contenu pour exclure les documents non pertinents ou de faible qualité, garantissant ainsi que seuls les résultats les plus pertinents sont transmis.
La distillation du contexte consiste à résumer ou à condenser les documents récupérés afin de concentrer le modèle linguistique sur les éléments d'information les plus importants. Ceci est utile lorsque les documents extraits contiennent trop de contenu non pertinent ou lorsque la requête implique un raisonnement complexe en plusieurs étapes.
En distillant le contexte, le système extrait les idées clés et les passages les plus pertinents des documents récupérés, garantissant ainsi que le modèle linguistique dispose des informations les plus claires et les plus pertinentes pour travailler.
Une fois que les documents pertinents ont été récupérés et affinés, l'étape suivante d'un système RAG est le processus de génération. L'optimisation de la manière dont le modèle linguistique génère les réponses est essentielle pour garantir la précision, la cohérence et la pertinence.
L'ingénierie des messages-guides désigne le processus de conception et de structuration des messages-guides qui sont introduits dans le modèle linguistique. La qualité de l'invite a un impact direct sur la qualité des résultats générés par le modèle, car l'invite fournit les instructions initiales ou le contexte de la tâche de génération.
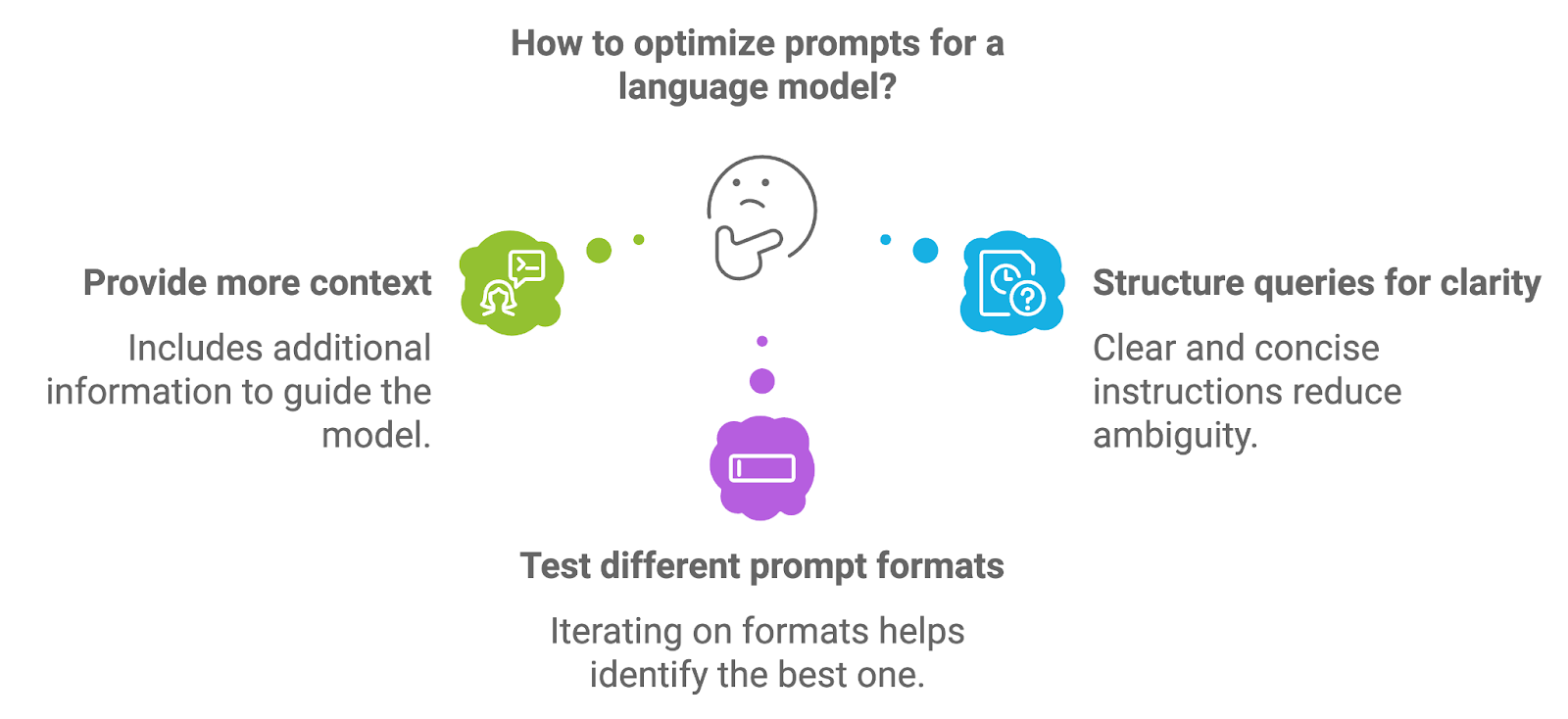
Diagramme généré avec napkin.ai
Pour optimiser les messages-guides, les développeurs peuvent expérimenter différentes approches.
L'ajout d'informations supplémentaires, telles que des instructions explicites ou des termes clés, peut guider le modèle vers des réponses plus précises et plus adaptées au contexte. Par exemple, dans un système RAG médical, une invite peut explicitement demander au modèle de fournir un résumé du diagnostic sur la base des documents récupérés.
Des invites bien structurées, avec des instructions claires et concises, permettent de réduire l'ambiguïté et d'obtenir des résultats de génération plus ciblés. La formulation de l'invite sous forme de question directe ou de demande permet souvent d'obtenir de meilleurs résultats.
La reformulation des questions, l'ajustement du niveau de spécificité ou la fourniture d'exemples peuvent aider à identifier le format qui donne les meilleurs résultats pour un cas d'utilisation spécifique.
Pour en savoir plus, consultez ce blog : Techniques d'optimisation de l'invite.
De nombreuses requêtes, en particulier dans des domaines tels que la recherche, le droit ou l'assistance technique, comportent plusieurs étapes ou nécessitent un raisonnement complexe. Le raisonnement en plusieurs étapes est le processus par lequel un système décompose une requête complexe en sous-tâches gérables et les traite de manière séquentielle pour parvenir à une réponse complète.
Nous pouvons mettre en œuvre le raisonnement à plusieurs étapes dans un système RAG de plusieurs façons :
Comme nous l'avons brièvement mentionné, l'un des principaux défis des modèles de génération, y compris ceux utilisés dans les systèmes RAG, est l'hallucination. Plusieurs techniques permettent d'atténuer les hallucinations dans les systèmes RAG :
Les systèmes RAG étant de plus en plus appliqués à des tâches réelles, ils doivent être capables de gérer des interactions complexes, à tours multiples, et des requêtes ambiguës.
L'un des principaux défis des systèmes de RAG conversationnels est la gestion du flux d'informations à travers des interactions multiples. Dans de nombreux scénarios quotidiens, tels que l'assistance à la clientèle ou les discussions techniques permanentes, les utilisateurs s'engagent souvent dans des conversations à plusieurs tours où le contexte doit être maintenu au cours de plusieurs échanges.
Pour fournir des réponses cohérentes et homogènes, il est essentiel que le système suive et mémorise les parties pertinentes de la conversation. Pour gérer efficacement les conversations à plusieurs tours, les systèmes RAG peuvent utiliser les techniques suivantes :
Les requêtes des utilisateurs ne sont pas toujours simples, elles sont souvent vagues, ambiguës ou impliquent un raisonnement complexe qui remet en cause les capacités d'un système RAG.
L'un des moyens de lever l'ambiguïté est d'inviter le système à demander des éclaircissements à l'utilisateur. Par exemple, si la requête est trop vague, le système peut générer une question de suivi demandant plus de précisions. Ce processus interactif permet de préciser l'intention de l'utilisateur avant de passer aux phases de recherche et de génération.
Pour les requêtes complexes qui impliquent plusieurs aspects ou sous-thèmes, le système peut décomposer la requête en parties plus petites et plus faciles à gérer. Il s'agit de rechercher des informations par étapes, chacune d'entre elles traitant d'un aspect spécifique de la requête. Le résultat final est ensuite synthétisé à partir de plusieurs étapes de recherche et de génération, en veillant à ce que tous les éléments de la requête soient pris en compte.
Pour gérer l'ambiguïté, le système peut utiliser des indices contextuels provenant de la requête ou de l'historique de la conversation. En analysant les interactions précédentes ou les sujets connexes, le système RAG peut déduire plus précisément l'intention de l'utilisateur, ce qui réduit la probabilité de générer des réponses non pertinentes ou incorrectes.
Pour les requêtes particulièrement difficiles, les systèmes RAG peuvent mettre en œuvre des méthodes de recherche avancées, telles que la réponse à des questions multi-sauts, où le système récupère des informations à partir de plusieurs documents et établit des connexions logiques entre eux pour répondre à des requêtes complexes.
Si les systèmes RAG offrent des solutions puissantes pour la recherche d'informations et la génération de textes, ils posent également des problèmes spécifiques qu'il convient de résoudre.
Les biais dans les modèles linguistiques, y compris ceux utilisés dans les systèmes RAG, est un problème bien connu qui peut avoir un impact négatif sur l'équité et la précision des résultats générés. Les biais peuvent s'introduire dans le système à la fois lors des phases d'extraction et de génération, ce qui se traduit par des résultats biaisés ou discriminatoires qui reflètent les préjugés sociétaux, culturels ou spécifiques à un domaine présents dans les ensembles de données sous-jacents.
Pour atténuer les biais dans les systèmes RAG, nous pouvons appliquer plusieurs stratégies :
Au fur et à mesure que les systèmes RAG deviennent plus complexes grâce à l'intégration de techniques avancées de recherche et de génération, les exigences en matière de calcul deviennent de plus en plus importantes. exigences en matière de calcul augmentent également. Ce défi se manifeste dans des domaines tels que la taille du modèle, la vitesse de traitement et la latence, qui peuvent tous affecter l'efficacité et l'évolutivité du système.
Pour gérer les frais généraux de calcul, les développeurs peuvent utiliser les optimisations suivantes :
Les systèmes RAG dépendent fortement de la qualité et de la portée des données qu'ils récupèrent et génèrent. Dans les applications spécifiques à un domaine, les limites des données peuvent constituer un défi majeur, en particulier lorsque les données d'apprentissage disponibles sont insuffisantes, obsolètes ou de mauvaise qualité.
Quelques approches permettent de remédier aux limitations des données dans les systèmes RAG.
Lorsque les données de formation spécifiques à un domaine sont limitées, les techniques d'augmentation des données peuvent contribuer à élargir artificiellement l'ensemble de données. Il peut s'agir de générer des données synthétiques, de paraphraser des documents existants ou d'utiliser des sources externes pour compléter l'ensemble de données original. L'augmentation des données permet au modèle d'avoir accès à un plus grand nombre d'exemples, ce qui améliore sa capacité à traiter diverses requêtes.
La mise au point de modèles linguistiques pré-entraînés sur de petits ensembles de données spécifiques à un domaine peut aider les systèmes RAG à s'adapter à des cas d'utilisation spécialisés, même avec des données limitées. L'adaptation au domaine permet au modèle de mieux comprendre la terminologie et les nuances propres à l'industrie, ce qui améliore la qualité des réponses générées.
Dans les cas où les données de formation de haute qualité sont rares, l'apprentissage actif peut être utilisé pour améliorer l'ensemble de données de manière itérative. En identifiant les points de données les plus informatifs et en concentrant les efforts d'annotation sur ceux-ci, les développeurs peuvent progressivement améliorer l'ensemble de données sans avoir besoin de quantités massives de données étiquetées dès le départ.
La mise en œuvre de techniques avancées dans les systèmes RAG nécessite une solide compréhension des outils, des cadres et des stratégies disponibles. Ces techniques devenant de plus en plus complexes, l'utilisation de bibliothèques et de cadres spécialisés simplifie l'intégration de flux de travail sophistiqués de recherche et de génération.
De nombreux cadres et bibliothèques ont vu le jour pour soutenir la mise en œuvre de techniques RAG avancées, offrant des solutions modulaires et évolutives aux développeurs et aux chercheurs. Ces outils améliorent le processus de construction des systèmes RAG en fournissant des composants pour la recherche, le classement, le filtrage et la génération.
LangChain est un cadre populaire conçu spécifiquement pour travailler avec des modèles de langage et les intégrer à des sources de données externes. Il prend en charge des techniques avancées d'amélioration de la recherche, notamment l'indexation de documents, l'interrogation et l'enchaînement de différentes étapes de traitement (recherche, génération et raisonnement).
LangChain offre également des intégrations prêtes à l'emploi avec les bases de données vectorielles et divers extracteurs, ce qui en fait une option polyvalente pour la création de systèmes RAG personnalisés.
Apprenez-en plus sur LangChain et RAG dans ce cours : Construire des systèmes RAG avec LangChain
Haystack est un framework open-source spécialisé dans la construction de systèmes RAG destinés à une utilisation en production. Il fournit des outils pour la recherche dense, le classement et le filtrage des documents, ainsi que pour la génération de langage naturel.
Haystack est particulièrement puissant dans les applications qui nécessitent une recherche spécifique à un domaine, une réponse à des questions ou un résumé de documents. Grâce à la prise en charge d'une variété de backends et à l'intégration des modèles linguistiques les plus courants, Haystack simplifie le déploiement des systèmes RAG dans des scénarios réels.
L'API OpenAI API permet aux développeurs d'intégrer de puissants modèles linguistiques, tels que GPT-4, dans les flux de travail RAG. Bien qu'ils ne soient pas spécifiques aux tâches augmentées par la recherche, les modèles d'OpenAI peuvent être utilisés en conjonction avec des cadres de recherche pour générer des réponses basées sur les informations recherchées, permettant ainsi des capacités de génération avancées.
Pour intégrer des techniques avancées dans un système RAG existant, il est essentiel de suivre une approche structurée.
Commencez par sélectionner un cadre ou une bibliothèque qui correspond à votre cas d'utilisation. Par exemple, si vous avez besoin d'un système hautement évolutif avec des capacités de recherche denses, des frameworks comme LangChain ou Haystack sont idéaux.
La première étape consiste à configurer le composant d'extraction, ce qui implique l'indexation de votre source de données et la configuration de la méthode d'extraction. En fonction de votre cas d'utilisation, vous pouvez choisir la recherche dense (en utilisant des vecteurs intégrés) ou la recherche hybride (en combinant des méthodes denses et éparses). Par exemple, LangChain ou Haystack peuvent être utilisés pour créer le pipeline de recherche.
Une fois que le système de recherche est opérationnel, l'étape suivante consiste à améliorer la pertinence grâce à des techniques de reclassement et de filtrage. Cela peut être fait en utilisant les modules de reclassement intégrés dans Haystack ou en personnalisant vos modèles de reclassement en fonction de vos types de requêtes spécifiques.
Après la recherche, optimisez le processus de génération en tirant parti de l'ingénierie de l'invite, de la distillation du contexte et du raisonnement en plusieurs étapes. Avec LangChain, vous pouvez enchaîner les étapes de recherche et de génération pour traiter des requêtes en plusieurs étapes ou utiliser des modèles d'invite qui conditionnent le modèle pour une génération plus précise.
Si l'hallucination est un problème, concentrez-vous sur l'ancrage de la génération dans les documents récupérés, en veillant à ce que le modèle génère des résultats basés sur le contenu de ces documents.
Des tests réguliers sont essentiels pour affiner les performances du système RAG. Utilisez des mesures d'évaluation telles que la précision, la pertinence et la satisfaction de l'utilisateur pour évaluer l'efficacité des techniques avancées telles que le reranking et la distillation de contexte. Effectuez des tests A/B pour comparer différentes approches et affinez le système en fonction du retour d'information.
Au fur et à mesure que le système se développe, les frais généraux de calcul peuvent devenir un problème. Pour y remédier, utilisez des techniques d'optimisation telles que la distillation de modèles ou la quantification, et veillez à ce que les processus de recherche soient efficaces. L'utilisation de l'accélération GPU ou de la parallélisation peut également contribuer à maintenir les performances à l'échelle.
Les systèmes RAG doivent évoluer pour s'adapter aux nouvelles requêtes et données. Mettez en place des outils de contrôle pour suivre les performances du système en temps réel, et mettez continuellement à jour le modèle et l'index de recherche pour gérer les nouvelles tendances et les nouveaux besoins.
La mise en œuvre de techniques avancées dans un système RAG n'est qu'un début. En utilisant des mesures d'évaluation et des méthodes de test telles que les tests A/B, nous pouvons évaluer dans quelle mesure le système répond aux demandes des utilisateurs et s'affine au fil du temps.
La précision mesure la fréquence à laquelle le système retrouve et génère la réponse correcte ou pertinente. Pour les systèmes de réponse aux questions, cela pourrait impliquer une comparaison directe des réponses générées avec des données de référence. Une précision accrue indique que le système interprète correctement les requêtes et fournit des résultats précis.
Cette mesure évalue la pertinence des documents récupérés et la qualité de la réponse générée en fonction de la manière dont ils répondent à la requête de l'utilisateur. Des mesures telles que le rang réciproque moyen (MRR) ou la précision@K sont couramment utilisées pour quantifier la pertinence, en évaluant la place qu'occupe le document le plus pertinent dans le classement.
Si la précision et la pertinence sont essentielles, la performance en temps réel est également importante. La latence fait référence au temps de réponse du système, c'est-à-dire à la vitesse à laquelle le système récupère les documents et génère des réponses. Une faible latence est particulièrement importante dans les applications où des réponses rapides sont vitales, telles que l'assistance à la clientèle ou les systèmes de questions-réponses en direct.
La couverture mesure la capacité du système RAG à traiter une grande variété de requêtes. Dans les applications spécifiques à un domaine, il est essentiel de s'assurer que le système peut traiter l'ensemble des requêtes potentielles de l'utilisateur pour fournir une assistance complète.
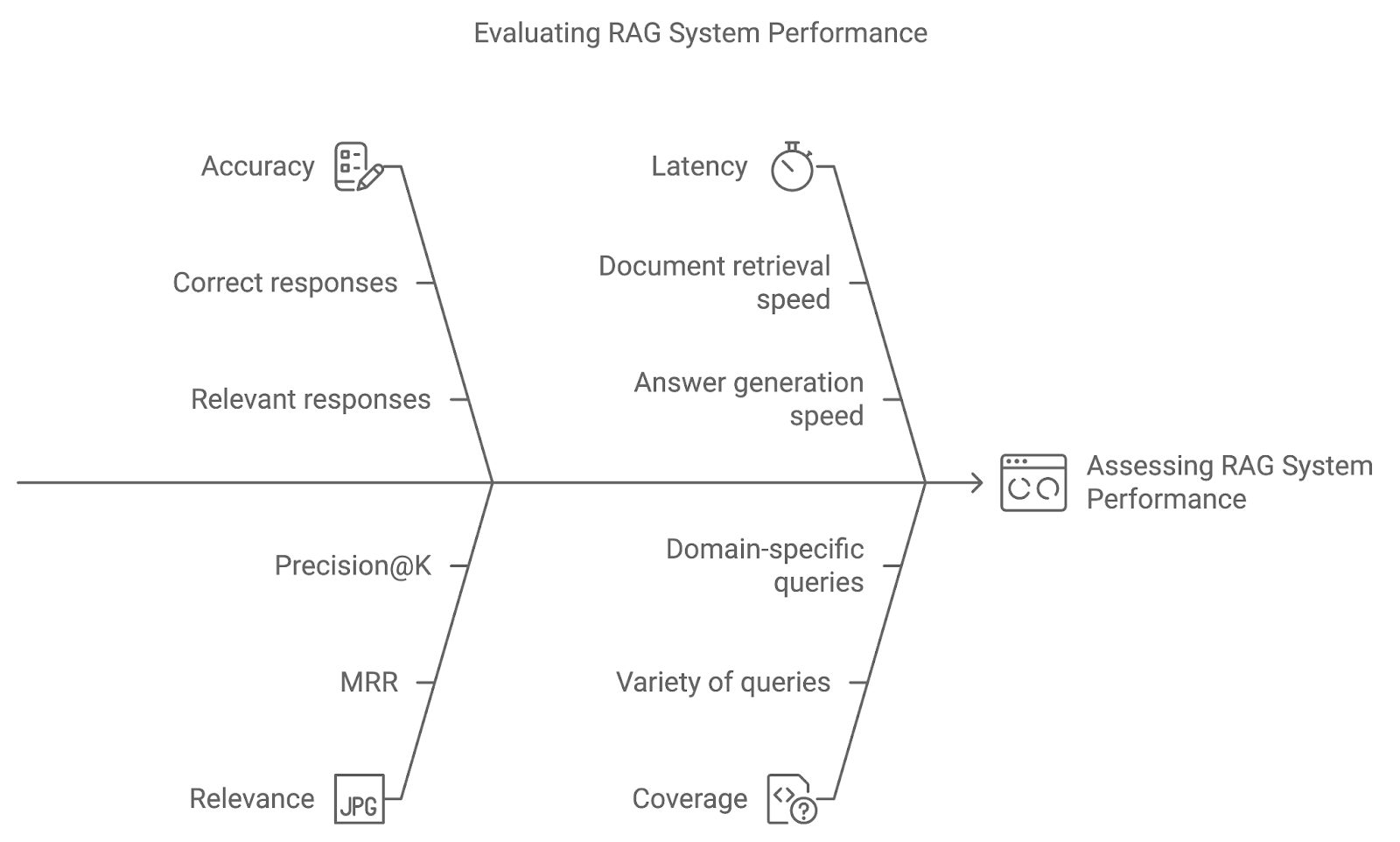
Diagramme généré avec napkin.ai
Les techniques avancées de RAG ouvrent un large éventail de possibilités dans différents secteurs et applications.
L'un des cas d'utilisation les plus importants des techniques avancées de RAG est celui des systèmes complexes de réponse aux questions (QA). Ces systèmes exigent plus qu'une simple recherche de documents : ils doivent comprendre le contexte, décomposer les requêtes en plusieurs étapes et fournir des réponses complètes sur la base des documents récupérés.
Dans les secteurs où les connaissances spécifiques à un domaine sont importantes, des systèmes RAG avancés peuvent être construits pour récupérer et générer un contenu hautement spécialisé. Parmi les applications notables, on peut citer
Les systèmes de recommandation personnalisés constituent un autre cas d'utilisation clé pour les techniques avancées de RAG. En combinant les préférences de l'utilisateur, son comportement et des sources de données externes, les systèmes RAG peuvent générer des recommandations personnalisées pour des produits, des services ou des contenus, notamment :
La prochaine génération de systèmes RAG intégrera des sources de données plus diverses, améliorera les capacités de raisonnement et s'attaquera aux limites actuelles telles que l'ambiguïté et le traitement de requêtes complexes.
L'intégration de diverses sources de données est un domaine de développement clé, qui permet d'aller au-delà de la dépendance à l'égard d'ensembles de données uniques. Les futurs systèmes combineront des informations provenant de diverses sources telles que des bases de données, des API et des flux en temps réel, ce qui permettra d'apporter des réponses plus complètes et multidimensionnelles à des requêtes complexes.
Le traitement des requêtes ambiguës ou incomplètes est un autre défi que les futurs systèmes RAG devront relever. En combinant le raisonnement probabiliste avec une meilleure compréhension du contexte, ces systèmes gèreront l'incertitude plus efficacement.
En outre, le raisonnement en plusieurs étapes fera de plus en plus partie intégrante de la manière dont les systèmes RAG traitent les requêtes complexes, en les décomposant en éléments plus petits et en synthétisant les résultats à travers plusieurs documents ou étapes. Cela sera particulièrement utile dans des domaines tels que la recherche juridique, la découverte scientifique et l'assistance à la clientèle, où les requêtes nécessitent souvent de relier différents éléments d'information.
Au fur et à mesure que la personnalisation et la prise en compte du contexte s'améliorent, les futurs systèmes RAG adapteront leurs réponses en fonction de l'historique de l'utilisateur, de ses préférences et de ses interactions passées. L'adaptation en temps réel aux nouvelles informations permettra des conversations plus dynamiques et plus productives.
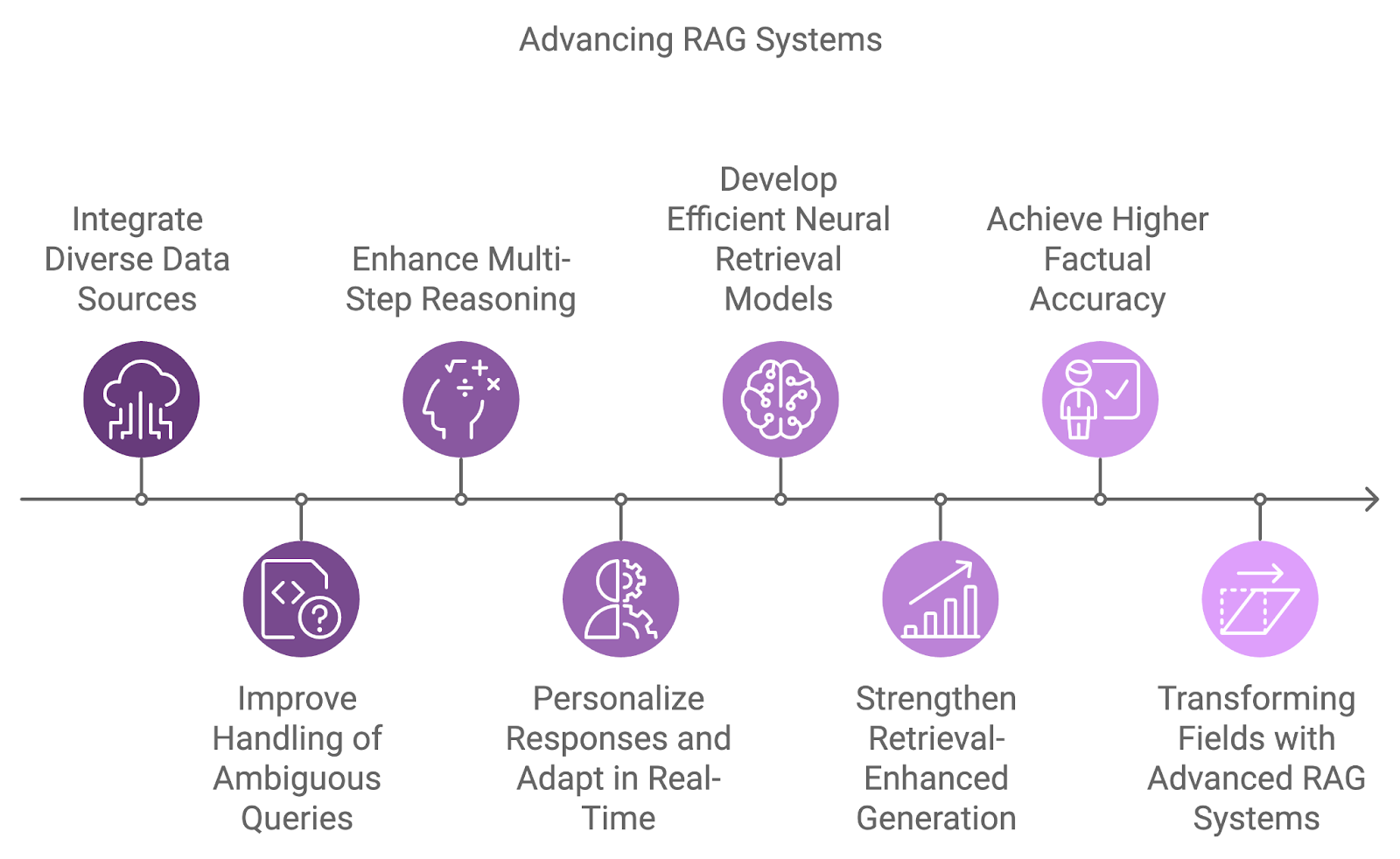
Diagramme généré avec napkin.ai
Les modèles actuels de récupération dense sont très efficaces, mais des recherches sont en cours pour développer des modèles de récupération neuronale encore plus efficaces et plus précis. Ces modèles visent à mieux saisir les similitudes sémantiques dans un plus large éventail de paires requête-document tout en améliorant l'efficacité des tâches de recherche à grande échelle.
Des articles comme Karpukhin et al. (2020) a présenté Dense Passage Retrieval (DPR) comme une méthode de base pour la réponse à des questions dans un domaine ouvert, tandis que des études plus récentes comme Izacard et al. (2022) se concentre sur l'apprentissage en quelques coups pour adapter les systèmes RAG à des tâches spécifiques à un domaine.
Un autre domaine de recherche émergent se concentre sur l'amélioration de la connexion entre la recherche et la génération par le biais de modèles de génération améliorés par la recherche. Ces modèles visent à intégrer de manière transparente les documents récupérés dans le processus de génération, ce qui permet au modèle linguistique de conditionner ses résultats plus directement sur le contenu récupéré.
Cela permet de réduire les hallucinations et d'améliorer l'exactitude factuelle des réponses générées, ce qui rend le système plus fiable. Parmi les travaux notables, citons Huang et al. (2023) avec le modèle RAVEN, qui améliore l'apprentissage en contexte à l'aide de modèles codeur-décodeur augmentés par la recherche.
L'intégration de techniques avancées de RAG, telles que la recherche dense, le reclassement et le raisonnement en plusieurs étapes, garantit que les systèmes de RAG peuvent répondre aux exigences des applications du monde réel, des soins de santé aux recommandations personnalisées.
À l'avenir, l'évolution des systèmes de RAG sera guidée par des innovations telles que les capacités multilingues, la génération personnalisée et le traitement de sources de données plus diverses.
Si vous souhaitez continuer à apprendre et à vous familiariser avec les systèmes RAG, je vous recommande ces tutoriels :
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
blog
blog
Kurtis Pykes
15 min
Tutoriel

