
Track
Developing AI Applications
21 hr
Retrieval-augmented generation (RAG) combines document retrieval with natural language generation, creating more accurate and contextually aware responses.
While basic RAG is effective, it struggles with complex queries, hallucinations, and maintaining context in multi-turn conversations.
In this blog, I’ll explore advanced techniques that address these challenges by improving retrieval accuracy, generation quality, and overall system performance.
If you're reading this in preparation for an interview, be sure to check out the Top 30 RAG Interview Questions and Answers article.
While basic RAG implementations can be useful, they do have their limitations, especially when applied in more demanding contexts.
One of the most prominent issues is hallucination, where the model generates content that is factually incorrect or unsupported by the retrieved documents. This can undermine the system’s reliability, especially in fields requiring high accuracy, such as medicine or law.
Standard RAG models may struggle when dealing with domain-specific queries. Without tailoring retrieval and generation processes to the nuances of specialized domains, the system risks retrieving irrelevant or inaccurate information.
Another challenge is managing complex, multi-step queries or multi-turn conversations. Basic RAG systems often struggle to maintain context across interactions, leading to disjointed or incomplete answers. As user queries grow more complex, RAG systems need to evolve to handle this growing complexity.
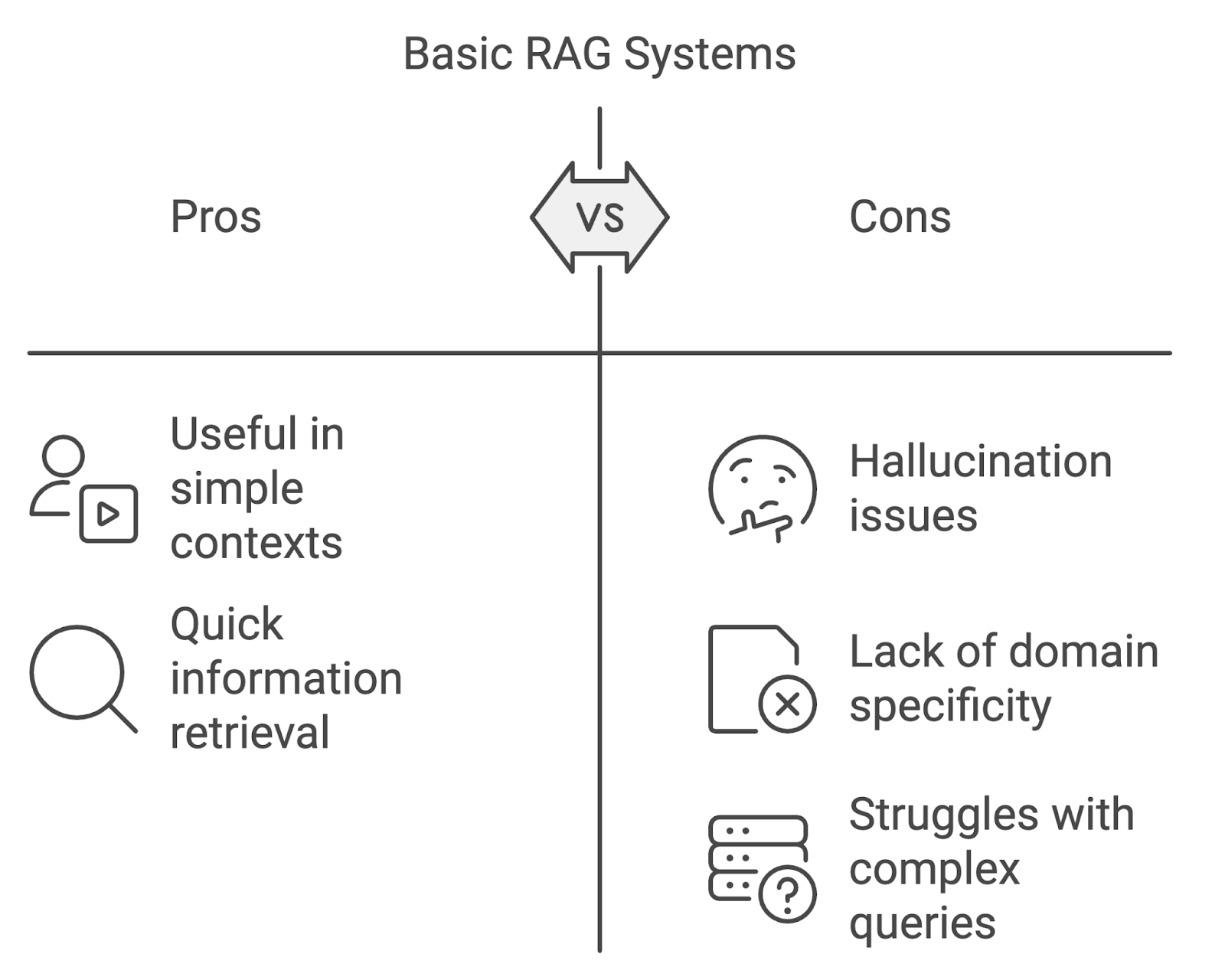
Diagram generated with napkin.ai
Advanced retrieval techniques focus on enhancing both the relevance and scope of retrieved documents. These techniques, which include dense retrieval, hybrid search, reranking, and query expansion, address the limitations of keyword-based retrieval.
Dense retrieval and hybrid search are key techniques for improving retrieval accuracy and relevance. Methods like TF-IDF or BM25 often struggle with semantic understanding when queries are phrased differently from the documents.
Dense retrieval, such as DPR (Dense Passage Retrieval), uses deep learning to map queries and documents into dense vector representations, capturing the meaning of text beyond exact keywords.
Hybrid search blends sparse and dense retrieval, balancing precision and recall by combining keyword-based matching with semantic similarity, making it effective for more complex queries.
Reranking is another advanced technique used to refine the list of retrieved documents before they are passed to the generation component. In a typical RAG system, the initial retrieval phase might produce a large set of documents that vary in relevance.
The role of reranking is to reorder these documents so that the most relevant ones are prioritized for use by the language model. Reranking can be achieved from a simple scoring based on query-document similarity to more complex machine learning models trained to predict the relevance of each document.
You can learn how to implement reranking in this tutorial on reranking with RankGPT.
Query expansion involves enriching the user’s query with additional terms that increase the chances of retrieving relevant documents. It can be achieved through:
For example, if the original query is “artificial intelligence in healthcare,” query expansion might include related terms like “AI,” “machine learning,” or “health tech,” ensuring a wider retrieval net.
In RAG systems, simply retrieving documents is not enough, ensuring the relevance and quality of these documents is key to improving the final output. To this end, advanced techniques that refine and filter the retrieved content are vital.
These methods work to reduce noise, boost relevance, and focus the language model on the most important information during the generation process.
Advanced filtering techniques use metadata or content-based rules to exclude irrelevant or low-quality documents, ensuring that only the most relevant results are passed on.
Context distillation is the process of summarizing or condensing retrieved documents to focus the language model on the most important pieces of information. This is useful when the retrieved documents contain too much irrelevant content or when the query involves complex, multi-step reasoning.
By distilling the context, the system extracts the key insights and most relevant passages from the retrieved documents, ensuring that the language model has the clearest and most pertinent information to work with.
Once relevant documents have been retrieved and refined, the next step in a RAG system is the generation process. Optimizing how the language model generates responses is essential to establishing accuracy, coherence, and relevance.
Prompt engineering refers to the process of designing and structuring the prompts that are fed into the language model. The quality of the prompt directly impacts the quality of the model’s generated output, as the prompt provides the initial instructions or context for the generation task.
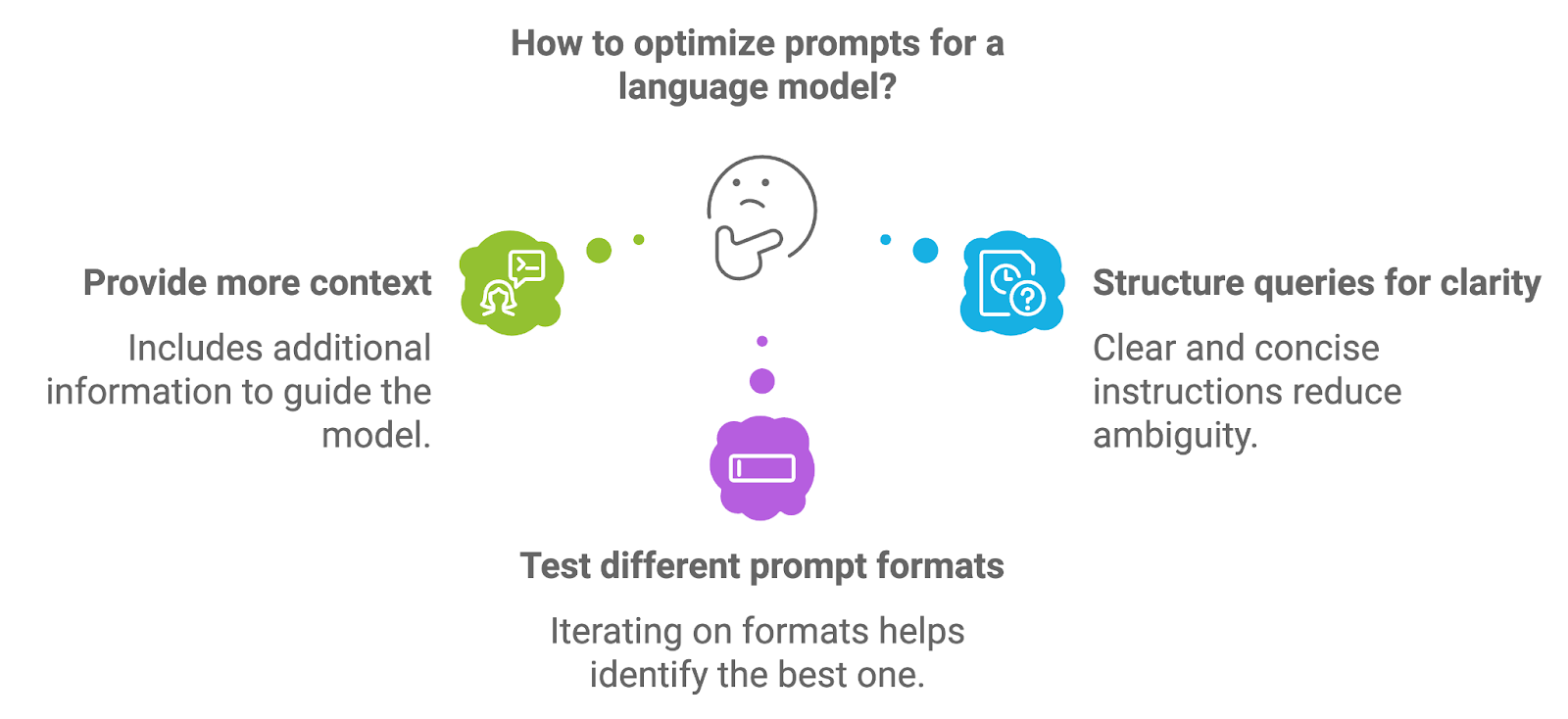
Diagram generated with napkin.ai
To optimize prompts, developers can experiment with a few different approaches.
Including additional information, such as explicit instructions or key terms, can guide the model toward more accurate and contextually relevant responses. For example, in a medical RAG system, a prompt might explicitly request that the model provide a diagnosis summary based on retrieved documents.
Well-structured prompts, with clear and concise instructions, help reduce ambiguity and lead to more focused generation results. Phrasing the prompt as a direct question or request can often yield better outcomes.
Iterating on prompt formats such as rephrasing questions, adjusting the level of specificity, or providing examples can help identify the format that delivers the best results for a specific use case.
Learn more in this blog: Prompt Optimization Techniques.
Many queries particularly in areas like research, law, or technical support, involve multiple steps or require complex reasoning. Multi-step reasoning is the process by which a system breaks down a complex query into manageable sub-tasks and processes them sequentially to arrive at a comprehensive answer.
We can implement multi-step reasoning within a RAG system in numerous ways:
As briefly mentioned, one of the main challenges in generation models, including those used in RAG systems, is hallucination. Several techniques can help mitigate hallucinations in RAG systems:
As RAG systems are increasingly applied to real-world tasks, they must be able to handle complex, multi-turn interactions and ambiguous queries.
One of the primary challenges in conversational RAG systems is managing the flow of information across multiple interactions. In many everyday scenarios, such as customer support or ongoing technical discussions users often engage in multi-turn conversations where the context must be maintained across several exchanges.
Having the system track and remember relevant parts of the conversation is key to providing coherent and consistent responses. To handle multi-turn conversations effectively, RAG systems can use the following techniques:
User queries are not always straightforward, many times, they can be vague, ambiguous, or involve complex reasoning that challenges a RAG system’s capabilities.
One way to address ambiguity is to prompt the system to seek clarification from the user. For instance, if the query is too vague, the system can generate a follow-up question asking for more specifics. This interactive process helps narrow down the user’s intent before proceeding with the retrieval and generation phases.
For complex queries that involve multiple aspects or subtopics, the system can break down the query into smaller, more manageable parts. This involves retrieving information in stages, where each stage tackles a specific aspect of the query. The final output is then synthesized from multiple retrieval and generation steps, ensuring that all components of the query are addressed.
To handle ambiguity, the system can use contextual clues from the query or conversation history. By analyzing previous interactions or related topics, the RAG system can infer the user’s intent more accurately, reducing the likelihood of generating irrelevant or incorrect responses.
For particularly challenging queries, RAG systems can implement advanced retrieval methods, such as multi-hop question answering, where the system retrieves information from multiple documents and makes logical connections across them to answer complex queries.
While RAG systems offer powerful solutions for information retrieval and text generation, they also introduce specific challenges that need to be addressed.
Bias in language models, including those used in RAG systems, is a well-known issue that can negatively impact the fairness and accuracy of generated outputs. Bias can enter the system through both the retrieval and generation phases, resulting in skewed or discriminatory outputs that reflect societal, cultural, or domain-specific biases present in the underlying datasets.
To mitigate bias in RAG systems, we can apply several strategies:
As RAG systems become more complex with the integration of advanced retrieval and generation techniques, the computational demands also increase. This challenge manifests in areas such as model size, processing speed, and latency, all of which can affect the system’s efficiency and scalability.
To manage computational overheads, developers can employ the following optimizations:
RAG systems are heavily dependent on the quality and scope of the data they retrieve and generate. In domain-specific applications, data limitations can be a major challenge, particularly when the available training data is insufficient, outdated, or of low quality.
We can address data limitations in RAG systems with a few approaches.
When domain-specific training data is limited, data augmentation techniques can help artificially expand the dataset. This can include generating synthetic data, paraphrasing existing documents, or using external sources to complement the original dataset. Data augmentation ensures that the model has access to a broader range of examples, improving its ability to handle diverse queries.
Fine-tuning pre-trained language models on small, domain-specific datasets can help RAG systems adapt to specialized use cases, even with limited data. Domain adaptation allows the model to better understand industry-specific terminology and nuances, improving the quality of generated responses.
In cases where high-quality training data is scarce, active learning can be employed to improve the dataset iteratively. By identifying the most informative data points and focusing annotation efforts on those, developers can gradually enhance the dataset without requiring massive amounts of labeled data from the outset.
Implementing advanced techniques in RAG systems requires a solid understanding of the tools, frameworks, and strategies available. As these techniques become more complex, leveraging specialized libraries and frameworks simplifies integrating sophisticated retrieval and generation workflows.
Many frameworks and libraries have emerged to support the implementation of advanced RAG techniques, offering modular and scalable solutions for developers and researchers. These tools improve the process of building RAG systems by providing components for retrieval, ranking, filtering, and generation.
LangChain is a popular framework designed specifically for working with language models and integrating them with external data sources. It supports advanced retrieval-augmented techniques, including document indexing, querying, and chaining different processing steps (retrieval, generation, and reasoning).
LangChain also offers out-of-the-box integrations with vector databases and various retrievers, making it a versatile option for building custom RAG systems.
Learn more about LangChain and RAG in this course: Build RAG Systems with LangChain
Haystack is an open-source framework that specializes in building RAG systems for production use. It provides tools for dense retrieval, document ranking, and filtering, as well as natural language generation.
Haystack is particularly powerful in applications that require domain-specific search, question answering, or document summarization. With support for a variety of backends and integration with popular language models, Haystack simplifies the deployment of RAG systems in real-world scenarios.
The OpenAI API allows developers to integrate powerful language models, such as GPT-4, into RAG workflows. While not specific to retrieval-augmented tasks, OpenAI’s models can be used in conjunction with retrieval frameworks to generate responses based on retrieved information, enabling advanced generation capabilities.
To integrate advanced techniques into an existing RAG system, it’s essential to follow a structured approach.
Start by selecting a framework or library that aligns with your use case. For example, if you need a highly scalable system with dense retrieval capabilities, frameworks like LangChain or Haystack are ideal.
The first step is to set up the retrieval component, which involves indexing your data source and configuring the retrieval method. Depending on your use case, you might choose dense retrieval (using vector embeddings) or hybrid search (combining sparse and dense methods). For instance, LangChain or Haystack can be used to create the retrieval pipeline.
Once the retrieval system is operational, the next step is to enhance relevance through reranking and filtering techniques. This can be done using the built-in reranking modules in Haystack or by customizing your reranking models based on your specific query types.
After retrieval, optimize the generation process by leveraging prompt engineering, context distillation, and multi-step reasoning. With LangChain, you can chain together retrieval and generation steps to handle multi-step queries or use prompt templates that condition the model for more accurate generation.
If hallucination is an issue, focus on grounding the generation in retrieved documents, ensuring the model generates output based on the content of those documents.
Regular testing is crucial for refining the performance of the RAG system. Use evaluation metrics like accuracy, relevance, and user satisfaction to assess the effectiveness of advanced techniques such as reranking and context distillation. Run A/B tests to compare different approaches and fine-tune the system based on feedback.
As the system grows, computational overheads may become a concern. To manage this, employ optimization techniques like model distillation or quantization, and ensure that retrieval processes are efficient. Utilizing GPU acceleration or parallelization can also help maintain performance at scale.
RAG systems need to evolve to adapt to new queries and data. Set up monitoring tools to track the system’s performance in real-time, and continuously update the model and retrieval index to handle emerging trends and requirements.
Implementing advanced techniques in a RAG system is only the beginning. By using appropriate evaluation metrics and testing methods like A/B testing, we can assess how well the system responds to user queries and refines over time.
Accuracy measures how often the system retrieves and generates the correct or relevant response. For question-answering systems, this could involve a direct comparison of the generated answers with ground-truth data. Increased accuracy indicates that the system is accurately interpreting queries and delivering precise results.
This metric evaluates the relevance of retrieved documents and the quality of the generated response based on how well they answer the user’s query. Metrics like Mean Reciprocal Rank (MRR) or Precision@K are commonly used to quantify relevance, assessing how high in the ranking the most relevant document appears.
While accuracy and relevance are critical, real-time performance also matters. Latency refers to the system’s response time—the speed at which the system retrieves documents and generates answers. Low latency is particularly important in applications where timely responses are vital, such as customer support or live Q&A systems.
Coverage measures how well the RAG system handles a wide variety of queries. In domain-specific applications, ensuring that the system can handle the full scope of potential user queries is key to providing comprehensive support.
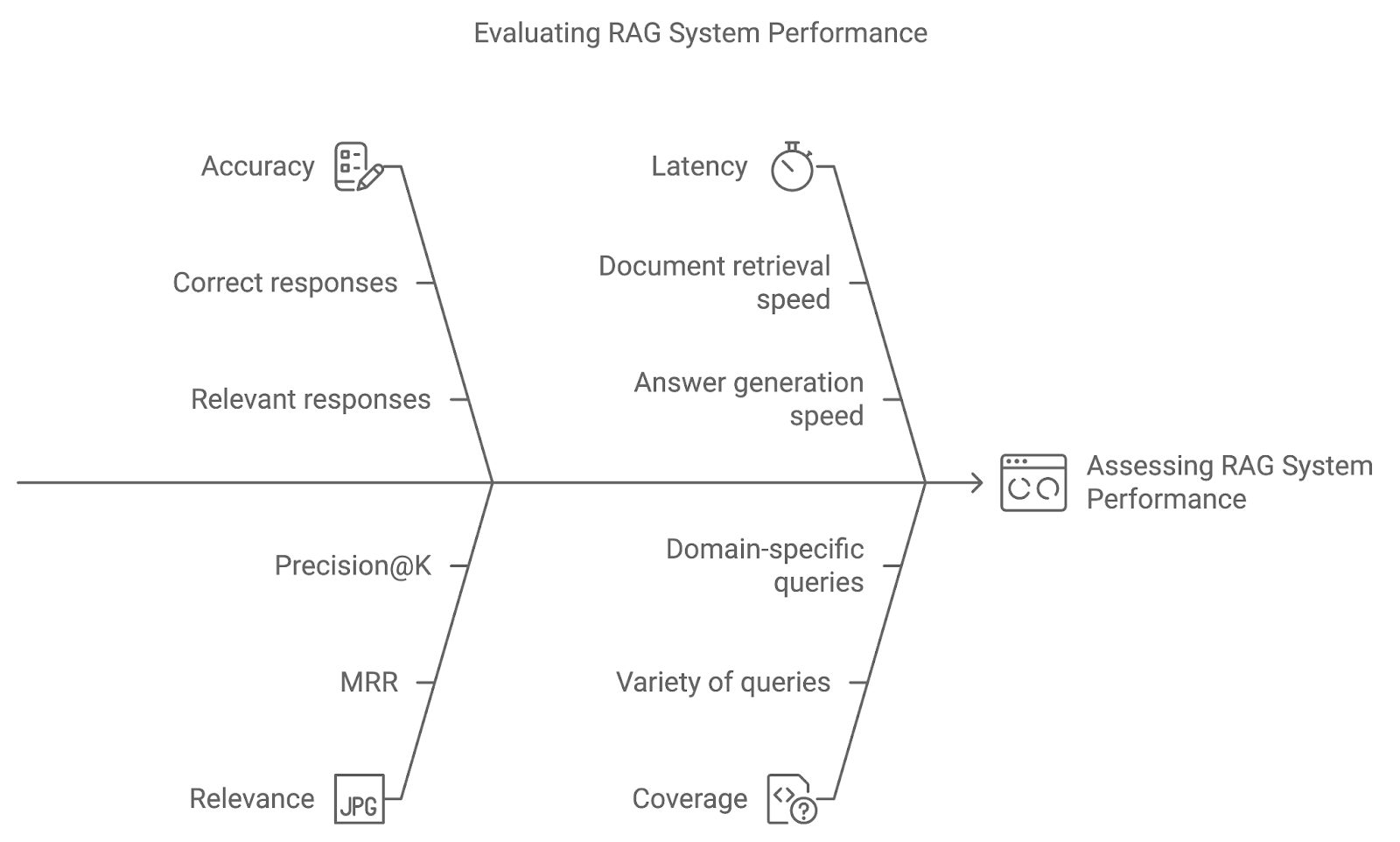
Diagram generated with napkin.ai
Advanced RAG techniques open up a wide range of possibilities across different industries and applications.
One of the most impactful use cases of advanced RAG techniques is in complex question-answering (QA) systems. These systems require more than just simple document retrieval—they must understand the context, break down multi-step queries, and provide comprehensive answers based on retrieved documents.
In industries where domain-specific knowledge is important, advanced RAG systems can be built to retrieve and generate highly specialized content. Some noteworthy applications include:
Personalized recommendation systems are another key use case for advanced RAG techniques. By combining user preferences, behavior, and external data sources, RAG systems can generate personalized recommendations for products, services, or content, including:
The next generation of RAG systems will integrate more diverse data sources, improving reasoning capabilities, and addressing current limitations like ambiguity and complex query handling.
A key development area is the integration of various data sources, moving beyond the reliance on single datasets. Future systems will combine information from diverse sources such as databases, APIs, and real-time feeds, enabling more comprehensive and multidimensional answers to complex queries.
Handling ambiguous or incomplete queries is another challenge that future RAG systems will address. By combining probabilistic reasoning with better contextual understanding, these systems will manage uncertainty more effectively.
Additionally, multi-step reasoning will become more integral to how RAG systems process complex queries, breaking them down into smaller components and synthesizing the results across multiple documents or steps. This will be especially beneficial in fields like legal research, scientific discovery, and customer support, where queries often require connecting diverse pieces of information.
As personalization and context awareness continue to improve, future RAG systems will tailor their responses based on user history, preferences, and past interactions. Real-time adaptation to new information will allow for more dynamic and productive conversations.
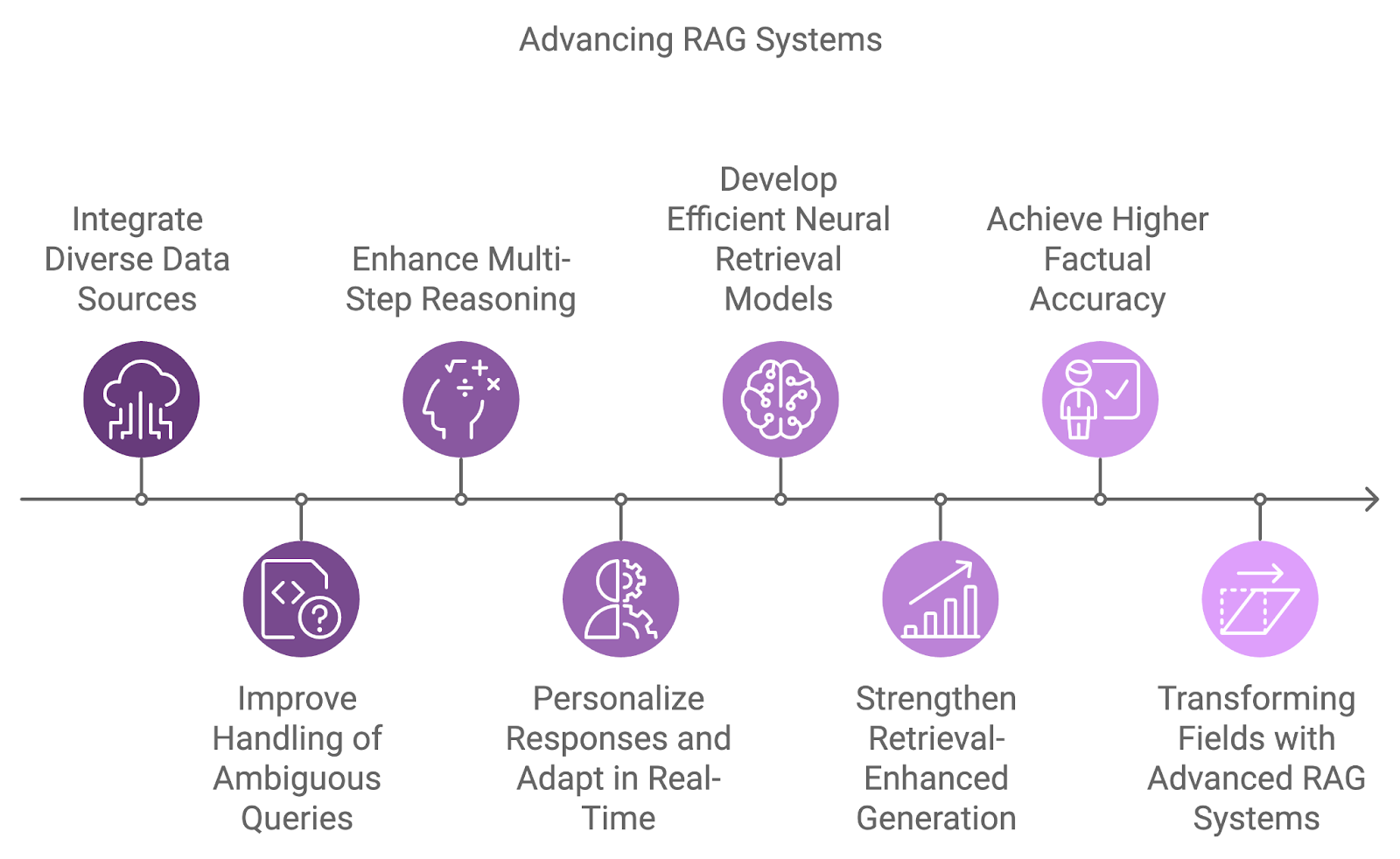
Diagram generated with napkin.ai
Current dense retrieval models are highly effective, but research is ongoing to develop even more efficient and accurate neural retrieval models. These models aim to better capture semantic similarities across a wider range of query-document pairs while improving efficiency in large-scale retrieval tasks.
Papers like Karpukhin et al. (2020) introduced Dense Passage Retrieval (DPR) as a core method for open-domain question answering, while more recent studies like Izacard et al. (2022) focus on few-shot learning to adapt RAG systems for domain-specific tasks.
Another emerging research area focuses on improving the connection between retrieval and generation through retrieval-enhanced generation models. These models aim to seamlessly integrate retrieved documents into the generation process, allowing the language model to condition its output more directly on the retrieved content.
This can reduce hallucinations and improve the factual accuracy of generated responses, making the system more reliable. Notable works include Huang et al. (2023) with the RAVEN model, which improves in-context learning using retrieval-augmented encoder-decoder models.
The integration of advanced RAG techniques like dense retrieval, reranking, and multi-step reasoning ensures that RAG systems can meet the demands of real-world applications, from healthcare to personalized recommendations.
Looking forward, the evolution of RAG systems will be driven by innovations like cross-lingual capabilities, personalized generation, and handling more diverse data sources.
If you want to keep learning and get more hands-on with RAG systems, I recommend these tutorials:
Learn AI with these courses!
Track
Course
Course
blog
Natassha Selvaraj
10 min
blog
Oluseye Jeremiah
10 min
Tutorial
Iván Palomares Carrascosa
Tutorial
Eugenia Anello
Tutorial
Ryan Ong
Tutorial
Ryan Ong
