
Leerpad
AI-toepassingen ontwikkelen
21 Hr
Retrieval-augmented generation (RAG) combineert documentopvraging met natuurlijke taal generatie, waardoor antwoorden accurater en contextbewuster worden.
Hoewel basis-RAG effectief is, heeft het moeite met complexe vragen, hallucinaties en het behouden van context in gesprekken met meerdere beurten.
In deze blog verken ik geavanceerde technieken die deze uitdagingen aanpakken door de opvraag-nauwkeurigheid, de kwaliteit van de generatie en de algehele systeemprestaties te verbeteren.
Lees je dit ter voorbereiding op een sollicitatiegesprek? Bekijk dan zeker het artikel Top 30 RAG Interview Questions and Answers.
Hoewel basisimplementaties van RAG nuttig kunnen zijn, hebben ze beperkingen, vooral in veeleisendere contexten.
Een van de meest opvallende problemen is hallucinatie, waarbij het model inhoud genereert die feitelijk onjuist is of niet wordt ondersteund door de opgehaalde documenten. Dit kan de betrouwbaarheid van het systeem ondermijnen, vooral in vakgebieden die hoge nauwkeurigheid vereisen, zoals geneeskunde of recht.
Standaard RAG-modellen kunnen moeite hebben met domeinspecifieke vragen. Zonder het ophalen en genereren af te stemmen op de nuances van gespecialiseerde domeinen, loopt het systeem het risico irrelevante of onjuiste informatie op te halen.
Een andere uitdaging is het beheren van complexe, meerstapsvragen of gesprekken met meerdere beurten. Basis-RAG-systemen hebben vaak moeite om de context over interacties heen te behouden, wat leidt tot onsamenhangende of onvolledige antwoorden. Naarmate gebruikersvragen complexer worden, moeten RAG-systemen mee evolueren om deze toenemende complexiteit aan te kunnen.
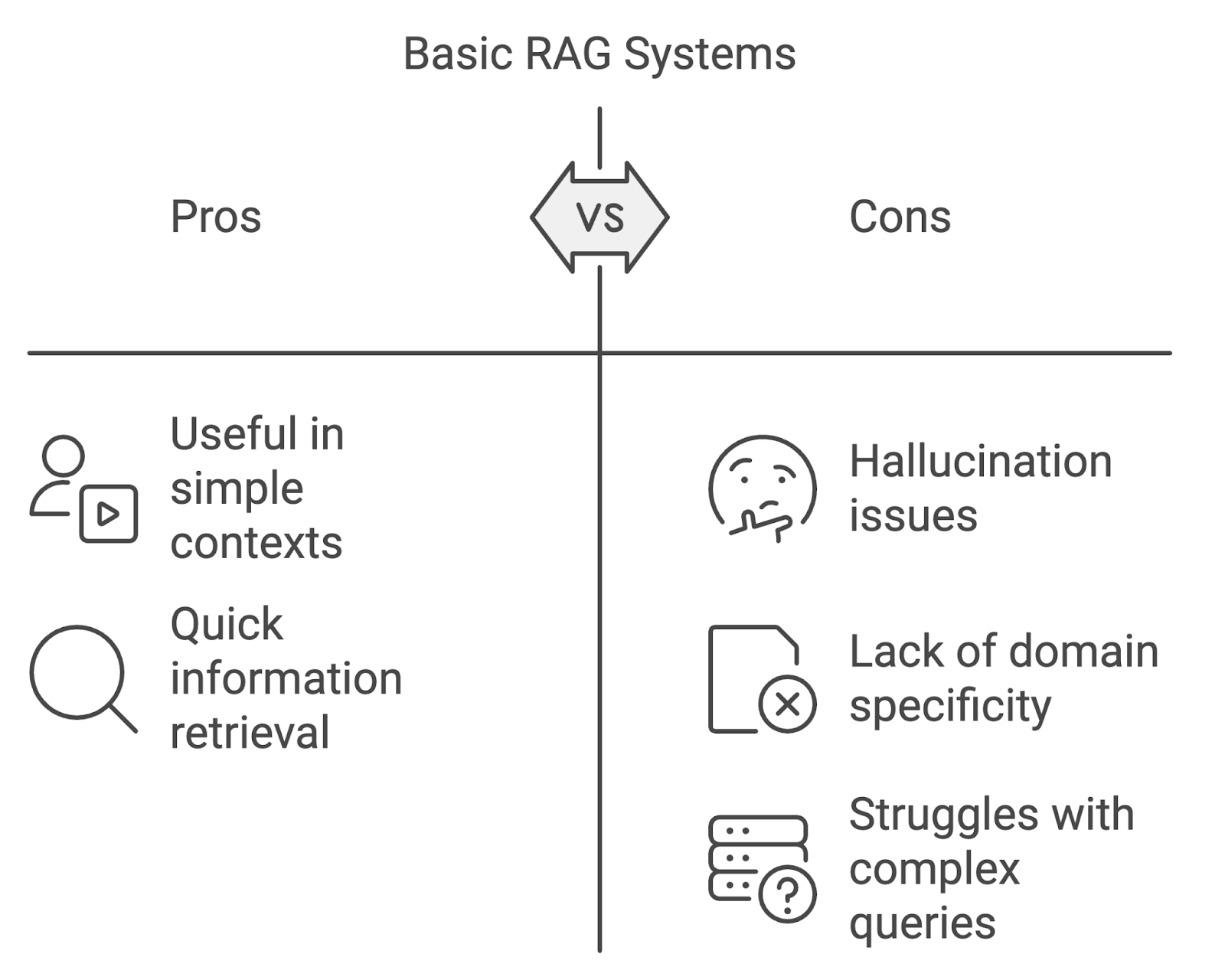
Diagram gegenereerd met napkin.ai
Geavanceerde ophaaltechnieken richten zich op het verbeteren van zowel de relevantie als de reikwijdte van opgehaalde documenten. Deze technieken, waaronder dense retrieval, hybride zoeken, reranking en query-expansie, pakken de beperkingen van op trefwoorden gebaseerde opvraging aan.
Dense retrieval en hybride zoeken zijn sleuteltechnieken om de nauwkeurigheid en relevantie van opvraging te verbeteren. Methoden zoals TF-IDF of BM25 hebben vaak moeite met semantisch begrip wanneer vragen anders geformuleerd zijn dan de documenten.
Dense retrieval, zoals DPR (Dense Passage Retrieval), gebruikt deep learning om vragen en documenten in dense vectorrepresentaties te mappen, zodat de betekenis van tekst wordt vastgelegd voorbij exacte trefwoorden.
Hybride zoeken combineert sparse en dense retrieval, en balanceert precisie en recall door trefwoordmatching te combineren met semantische gelijkenis, waardoor het effectief is voor complexere vragen.
Reranking is een andere geavanceerde techniek om de lijst met opgehaalde documenten te verfijnen voordat ze naar de generatiecomponent gaan. In een typisch RAG-systeem kan de initiële ophaalfase een grote set documenten opleveren met uiteenlopende relevantie.
De rol van reranking is om deze documenten te herordenen zodat de meest relevante prioriteit krijgen voor gebruik door het taalmodel. Reranking kan variëren van eenvoudige scores op basis van vraag-documentgelijkenis tot complexere machinelearningmodellen die de relevantie van elk document voorspellen.
Je kunt in deze tutorial leren hoe je reranking implementeert: reranking met RankGPT.
Query-expansie houdt in dat je de vraag van de gebruiker verrijkt met aanvullende termen die de kans vergroten dat relevante documenten worden opgehaald. Dat kan met:
Als de oorspronkelijke vraag bijvoorbeeld “artificial intelligence in healthcare” is, kan query-expansie gerelateerde termen toevoegen zoals “AI”, “machine learning” of “health tech”, zodat de ophaalvijver breder wordt.
In RAG-systemen is alleen documenten ophalen niet genoeg; het waarborgen van de relevantie en kwaliteit van deze documenten is cruciaal voor een beter eindresultaat. Geavanceerde technieken die de opgehaalde inhoud verfijnen en filteren zijn daarvoor essentieel.
Deze methoden verminderen ruis, verhogen de relevantie en richten het taalmodel tijdens de generatie op de belangrijkste informatie.
Geavanceerde filtertechnieken gebruiken metadata of op inhoud gebaseerde regels om irrelevante of lage kwaliteit documenten uit te sluiten, zodat alleen de meest relevante resultaten worden doorgegeven.
Contextdistillatie is het samenvatten of condenseren van opgehaalde documenten om het taalmodel te richten op de belangrijkste informatie. Dit is nuttig wanneer de opgehaalde documenten te veel irrelevante inhoud bevatten of wanneer de vraag complexe, meerstapsredenering omvat.
Door de context te distilleren, extraheert het systeem de kerninzichten en meest relevante passages uit de opgehaalde documenten, zodat het taalmodel met de duidelijkste en meest relevante informatie kan werken.
Zodra relevante documenten zijn opgehaald en verfijnd, is de volgende stap in een RAG-systeem het generatieproces. Het optimaliseren van hoe het taalmodel antwoorden genereert is essentieel voor nauwkeurigheid, samenhang en relevantie.
Prompt engineering verwijst naar het ontwerpen en structureren van de prompts die aan het taalmodel worden gevoed. De kwaliteit van de prompt heeft direct invloed op de kwaliteit van de gegenereerde output, omdat de prompt de eerste instructies of context biedt voor de taak.
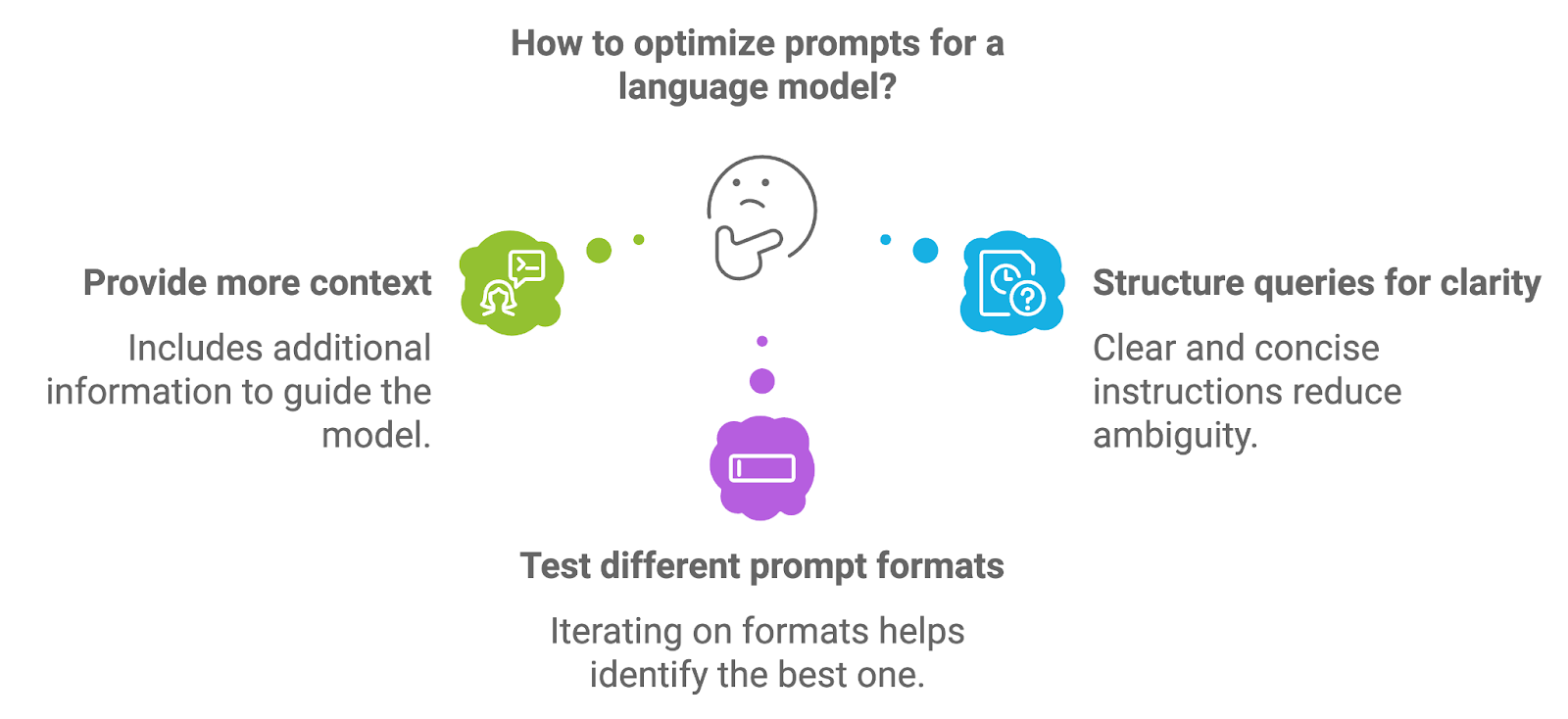
Diagram gegenereerd met napkin.ai
Om prompts te optimaliseren kunnen ontwikkelaars met een paar verschillende benaderingen experimenteren.
Door extra informatie toe te voegen, zoals expliciete instructies of kerntermen, kun je het model sturen naar nauwkeurigere en contextueel relevantere antwoorden. In een medisch RAG-systeem kan een prompt bijvoorbeeld expliciet vragen om een samenvatting van een diagnose op basis van opgehaalde documenten.
Goed gestructureerde prompts, met duidelijke en beknopte instructies, helpen ambiguïteit te verminderen en leiden tot meer gefocuste resultaten. De prompt formuleren als een directe vraag of verzoek levert vaak betere uitkomsten op.
Itereren op promptformaten, zoals vragen herformuleren, het specificiteitsniveau aanpassen of voorbeelden geven, kan helpen het formaat te vinden dat voor een specifieke usecase de beste resultaten geeft.
Lees meer in deze blog: Prompt Optimization Techniques.
Veel vragen, vooral in domeinen zoals onderzoek, recht of technische support, bestaan uit meerdere stappen of vereisen complexe redenering. Redeneren in meerdere stappen betekent dat een systeem een complexe vraag opdeelt in behapbare subtaken en deze sequentieel verwerkt om tot een volledig antwoord te komen.
We kunnen meerstapsredenering in een RAG-systeem op verschillende manieren implementeren:
Zoals kort genoemd is een van de grootste uitdagingen bij generatiemodellen, ook in RAG-systemen, hallucinatie. Verschillende technieken kunnen helpen om hallucinaties te beperken in RAG-systemen:
Naarmate RAG-systemen vaker in realistische taken worden ingezet, moeten ze complexe interacties met meerdere beurten en ambigue vragen aankunnen.
Een van de belangrijkste uitdagingen in conversationale RAG-systemen is het beheren van de informatiestroom over meerdere interacties. In alledaagse scenario’s, zoals klantenservice of lopende technische discussies, voeren gebruikers vaak gesprekken met meerdere beurten waarin de context over verschillende uitwisselingen moet worden behouden.
Het systeem relevante delen van het gesprek laten bijhouden en onthouden is cruciaal voor samenhangende en consistente antwoorden. Om meer-ronde gesprekken effectief te verwerken, kunnen RAG-systemen de volgende technieken gebruiken:
Gebruikersvragen zijn niet altijd eenduidig; vaak zijn ze vaag, dubbelzinnig of vereisen ze complexe redenering die de capaciteiten van een RAG-systeem op de proef stelt.
Een manier om ambiguïteit aan te pakken is het systeem aan te sporen om verduidelijking aan de gebruiker te vragen. Als de vraag bijvoorbeeld te vaag is, kan het systeem een vervolgvraag genereren om meer specificiteit te vragen. Dit interactieve proces helpt de intentie van de gebruiker te vernauwen voordat de ophaal- en generatiefasen beginnen.
Voor complexe vragen met meerdere aspecten of deelonderwerpen kan het systeem de vraag opsplitsen in kleinere, beter hanteerbare delen. Dit houdt in dat informatie in fasen wordt opgehaald, waarbij elke fase een specifiek aspect van de vraag aanpakt. De uiteindelijke output wordt dan gesynthetiseerd uit meerdere ophaal- en generatiestappen, zodat alle componenten van de vraag worden behandeld.
Om ambiguïteit te hanteren, kan het systeem contextuele aanwijzingen uit de vraag of gespreksgeschiedenis gebruiken. Door eerdere interacties of gerelateerde onderwerpen te analyseren, kan het RAG-systeem de intentie van de gebruiker nauwkeuriger afleiden, waardoor de kans op irrelevante of onjuiste antwoorden afneemt.
Voor bijzonder uitdagende vragen kunnen RAG-systemen geavanceerde ophaalmethoden toepassen, zoals multi-hop vraagbeantwoording, waarbij informatie uit meerdere documenten wordt opgehaald en er logische verbanden over worden gelegd om complexe vragen te beantwoorden.
Hoewel RAG-systemen krachtige oplossingen bieden voor informatie-opvraging en tekstgeneratie, brengen ze ook specifieke uitdagingen met zich mee die moeten worden aangepakt.
Bias in taalmodellen, ook die in RAG-systemen, is een bekend probleem dat de eerlijkheid en nauwkeurigheid van gegenereerde outputs negatief kan beïnvloeden. Bias kan het systeem binnendringen via zowel de ophaal- als de generatiefase, wat resulteert in scheve of discriminerende outputs die maatschappelijke, culturele of domeinspecifieke vooroordelen in de onderliggende datasets weerspiegelen.
Om bias in RAG-systemen te beperken, kunnen we verschillende strategieën toepassen:
Naarmate RAG-systemen complexer worden met de integratie van geavanceerde ophaal- en generatietechnieken, nemen de rekenkundige eisen ook toe. Deze uitdaging komt tot uiting in zaken als modelgrootte, verwerkingssnelheid en latency, die allemaal de efficiëntie en schaalbaarheid van het systeem kunnen beïnvloeden.
Om rekenkundige overhead te beheersen, kunnen ontwikkelaars de volgende optimalisaties toepassen:
RAG-systemen zijn sterk afhankelijk van de kwaliteit en reikwijdte van de data die ze ophalen en genereren. In domeinspecifieke toepassingen kunnen datalimieten een grote uitdaging zijn, vooral wanneer de beschikbare trainingsdata onvoldoende, verouderd of van lage kwaliteit is.
We kunnen datalimieten in RAG-systemen op verschillende manieren aanpakken.
Wanneer domeinspecifieke trainingsdata beperkt is, kunnen data-augmentatietechnieken helpen de dataset kunstmatig uit te breiden. Dit kan bestaan uit het genereren van synthetische data, het parafraseren van bestaande documenten of het gebruik van externe bronnen als aanvulling op de oorspronkelijke dataset. Data-augmentatie zorgt ervoor dat het model toegang heeft tot een breder scala aan voorbeelden, waardoor het beter kan omgaan met diverse vragen.
Het fijn afstemmen van voorgetrainde taalmodellen op kleine, domeinspecifieke datasets helpt RAG-systemen zich aan te passen aan gespecialiseerde usecases, zelfs met beperkte data. Domeinaanpassing laat het model branchespecifieke terminologie en nuances beter begrijpen, wat de kwaliteit van de gegenereerde antwoorden verbetert.
In gevallen waarin kwalitatief hoogwaardige trainingsdata schaars is, kan actief leren worden ingezet om de dataset iteratief te verbeteren. Door de meest informatieve datapunten te identificeren en annotatie-inspanningen daarop te richten, kunnen ontwikkelaars de dataset geleidelijk verbeteren zonder meteen enorme hoeveelheden gelabelde data nodig te hebben.
Het implementeren van geavanceerde technieken in RAG-systemen vereist een goed begrip van de beschikbare tools, frameworks en strategieën. Naarmate deze technieken complexer worden, maakt het benutten van gespecialiseerde libraries en frameworks het integreren van geavanceerde ophaal- en generatie-workflows eenvoudiger.
Er zijn veel frameworks en libraries verschenen die de implementatie van geavanceerde RAG-technieken ondersteunen, met modulaire en schaalbare oplossingen voor ontwikkelaars en onderzoekers. Deze tools verbeteren het bouwproces van RAG-systemen door componenten te bieden voor opvraging, ranking, filtering en generatie.
LangChain is een populair framework dat specifiek is ontworpen om met taalmodellen te werken en ze te integreren met externe databronnen. Het ondersteunt geavanceerde retrieval-augmented technieken, waaronder documentindexering, querying en het ketenen van verschillende verwerkingsstappen (opvraging, generatie en redenering).
LangChain biedt ook kant-en-klare integraties met vectordatabases en diverse retrievers, wat het een veelzijdige optie maakt voor het bouwen van aangepaste RAG-systemen.
Leer meer over LangChain en RAG in deze cursus: Build RAG Systems with LangChain
Haystack is een open-source framework dat gespecialiseerd is in het bouwen van RAG-systemen voor productie. Het biedt tools voor dense retrieval, documentranking en filtering, evenals natuurlijke taal generatie.
Haystack is bijzonder krachtig in toepassingen die domeinspecifieke zoekopdrachten, vraagbeantwoording of documentsamenvatting vereisen. Met ondersteuning voor diverse backends en integratie met populaire taalmodellen, vereenvoudigt Haystack de uitrol van RAG-systemen in praktijksituaties.
De OpenAI API stelt ontwikkelaars in staat krachtige taalmodellen, zoals GPT-4, in RAG-workflows te integreren. Hoewel niet specifiek voor retrieval-augmented taken, kunnen de modellen van OpenAI in combinatie met ophaalframeworks worden gebruikt om antwoorden te genereren op basis van opgehaalde informatie, wat geavanceerde generatiecapaciteiten mogelijk maakt.
Om geavanceerde technieken in een bestaand RAG-systeem te integreren, is het essentieel om een gestructureerde aanpak te volgen.
Begin met het kiezen van een framework of library die aansluit bij je usecase. Als je bijvoorbeeld een zeer schaalbaar systeem met dense retrieval-capaciteiten nodig hebt, zijn frameworks zoals LangChain of Haystack ideaal.
De eerste stap is het inrichten van de ophaalcomponent, wat inhoudt dat je je databron indexeert en de ophaalmethode configureert. Afhankelijk van je usecase kun je kiezen voor dense retrieval (met vector-embeddings) of hybride zoeken (combinatie van sparse en dense methoden). Zo kun je met LangChain of Haystack de ophaalpijplijn opzetten.
Zodra het ophaalsysteem werkt, is de volgende stap het verhogen van de relevantie via reranking en filtertechnieken. Dit kan met de ingebouwde reranking-modules in Haystack of door eigen reranking-modellen te ontwikkelen op basis van jouw vraagtypes.
Optimaliseer na het ophalen het generatieproces met prompt engineering, contextdistillatie en meerstapsredenering. Met LangChain kun je ophaal- en generatiestappen aan elkaar ketenen om meerstapsvragen te behandelen of prompt-templates gebruiken die het model conditioneren voor nauwkeurigere generatie.
Als hallucinatie een probleem is, focus dan op het gronden van de generatie in opgehaalde documenten, zodat het model output genereert op basis van de inhoud daarvan.
Regelmatig testen is cruciaal om de prestaties van het RAG-systeem te verfijnen. Gebruik evaluatiemetrics zoals nauwkeurigheid, relevantie en gebruikerstevredenheid om de effectiviteit te beoordelen van geavanceerde technieken zoals reranking en contextdistillatie. Voer A/B-tests uit om verschillende benaderingen te vergelijken en stel het systeem bij op basis van feedback.
Naarmate het systeem groeit, kan rekenkundige overhead een zorg worden. Pas hiervoor optimalisatietechnieken toe zoals modeldistillatie of kwantisatie, en zorg dat ophaalprocessen efficiënt zijn. Het gebruiken van GPU-versnelling of parallelisatie kan ook helpen de prestaties op schaal te behouden.
RAG-systemen moeten evolueren om zich aan te passen aan nieuwe vragen en data. Richt monitoringtools in om de systeemprestaties in realtime te volgen en werk het model en de opvraagindex continu bij om opkomende trends en vereisten aan te kunnen.
Het implementeren van geavanceerde technieken in een RAG-systeem is nog maar het begin. Door passende evaluatiemetrics en testmethoden zoals A/B-testen te gebruiken, kunnen we beoordelen hoe goed het systeem reageert op gebruikersvragen en hoe het in de tijd verbetert.
Nauwkeurigheid meet hoe vaak het systeem het juiste of relevante antwoord ophaalt en genereert. Voor vraagbeantwoordingssystemen kan dit inhouden dat je de gegenereerde antwoorden direct vergelijkt met grondwaarheid. Hogere nauwkeurigheid geeft aan dat het systeem vragen correct interpreteert en precieze resultaten levert.
Deze metric beoordeelt de relevantie van opgehaalde documenten en de kwaliteit van het gegenereerde antwoord op basis van hoe goed ze de vraag van de gebruiker beantwoorden. Metrics zoals Mean Reciprocal Rank (MRR) of Precision@K worden vaak gebruikt om relevantie te kwantificeren, door te beoordelen hoe hoog het meest relevante document in de ranking verschijnt.
Hoewel nauwkeurigheid en relevantie cruciaal zijn, telt realtime performance ook. Latency verwijst naar de reactietijd van het systeem—de snelheid waarmee het documenten ophaalt en antwoorden genereert. Lage latency is vooral belangrijk in toepassingen waar tijdigheid essentieel is, zoals klantenservice of live Q&A-systemen.
Dekking meet hoe goed het RAG-systeem met een breed scala aan vragen omgaat. In domeinspecifieke toepassingen is het essentieel dat het systeem het volledige spectrum aan mogelijke gebruikersvragen aankan om volledige ondersteuning te bieden.
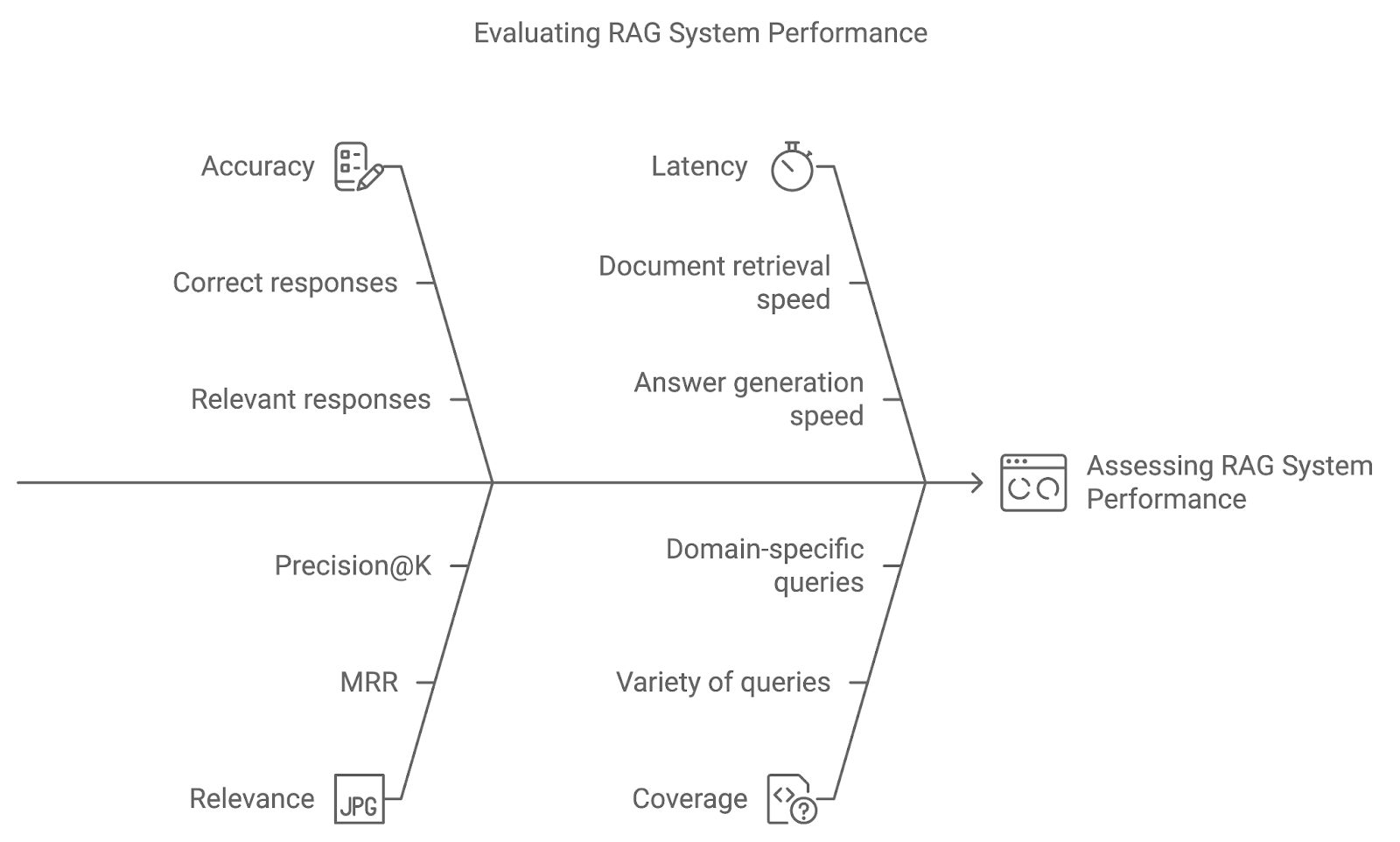
Diagram gegenereerd met napkin.ai
Geavanceerde RAG-technieken openen een breed scala aan mogelijkheden in verschillende sectoren en toepassingen.
Een van de meest impactvolle usecases van geavanceerde RAG-technieken is in complexe vraagbeantwoordingssystemen (QA). Deze systemen vereisen meer dan alleen eenvoudige documentopvraging—ze moeten context begrijpen, meerstapsvragen opdelen en uitgebreide antwoorden geven op basis van opgehaalde documenten.
In sectoren waar domeinspecifieke kennis belangrijk is, kunnen geavanceerde RAG-systemen worden gebouwd om zeer gespecialiseerde content op te halen en te genereren. Enkele opvallende toepassingen zijn:
Gepersonaliseerde aanbevelingssystemen zijn een andere belangrijke usecase voor geavanceerde RAG-technieken. Door gebruikersvoorkeuren, gedrag en externe databronnen te combineren, kunnen RAG-systemen gepersonaliseerde aanbevelingen genereren voor producten, diensten of content, waaronder:
De volgende generatie RAG-systemen zal meer diverse databronnen integreren, de redeneercapaciteiten verbeteren en huidige beperkingen zoals ambiguïteit en behandeling van complexe vragen aanpakken.
Een belangrijk ontwikkelgebied is de integratie van verschillende databronnen, voorbij het vertrouwen op enkele datasets. Toekomstige systemen zullen informatie combineren uit diverse bronnen zoals databases, API’s en realtime feeds, waardoor meer uitgebreide en multidimensionale antwoorden op complexe vragen mogelijk worden.
Het omgaan met ambigue of onvolledige vragen is een andere uitdaging die toekomstige RAG-systemen zullen aanpakken. Door probabilistische redenering te combineren met beter contextueel begrip, zullen deze systemen onzekerheid effectiever beheren.
Daarnaast zal meerstapsredenering een nog integralere rol spelen in hoe RAG-systemen complexe vragen verwerken: ze breken vragen op in kleinere componenten en synthetiseren de resultaten over meerdere documenten of stappen. Dit is vooral gunstig in velden zoals juridisch onderzoek, wetenschappelijke ontdekkingen en klantenondersteuning, waar vragen vaak vereisen dat uiteenlopende informatie wordt verbonden.
Naarmate personalisatie en contextbewustzijn blijven verbeteren, zullen toekomstige RAG-systemen hun antwoorden verder afstemmen op gebruikersgeschiedenis, voorkeuren en eerdere interacties. Realtime aanpassing aan nieuwe informatie zal leiden tot dynamischere en productievere gesprekken.
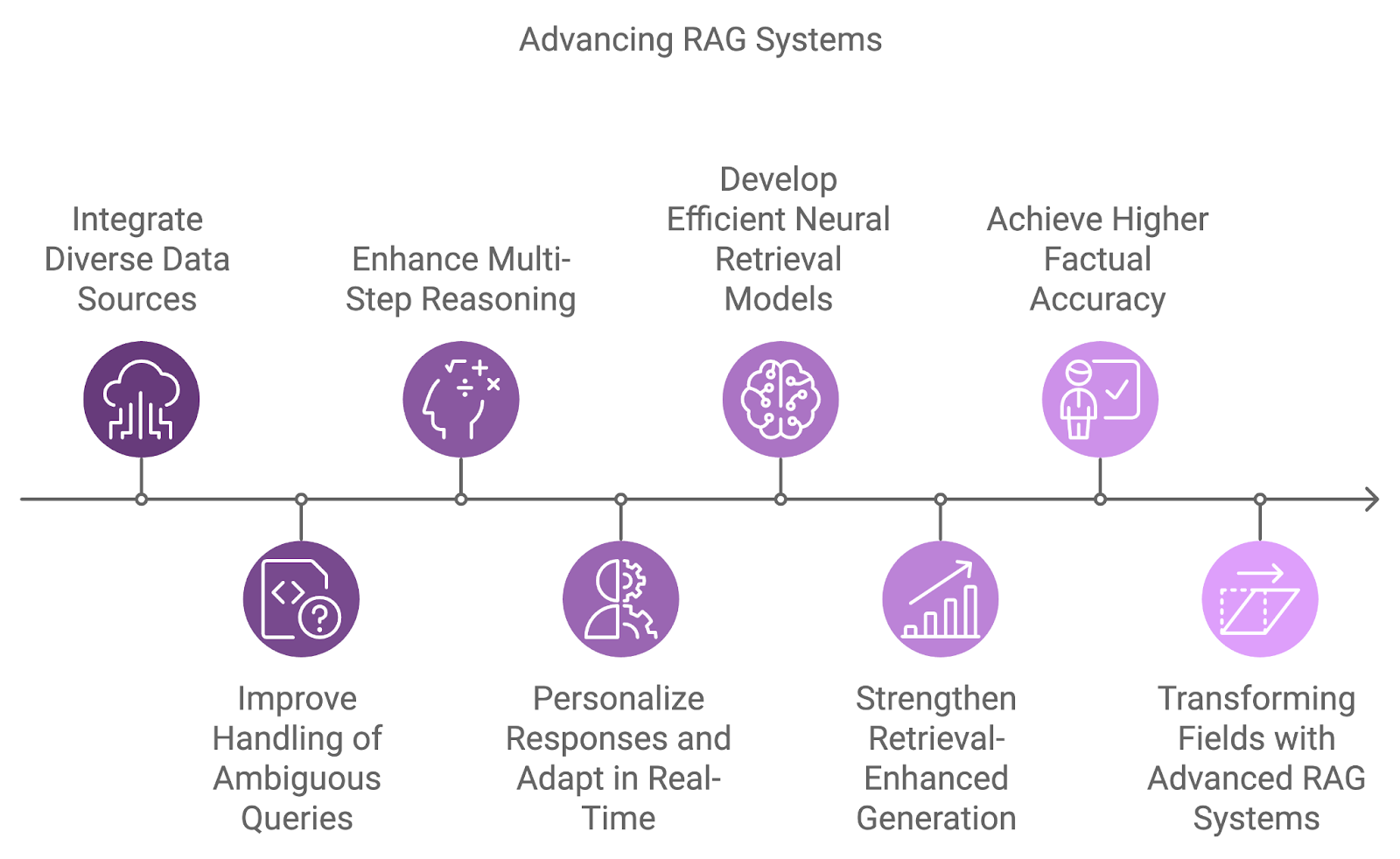
Diagram gegenereerd met napkin.ai
Huidige dense-retrievalmodellen zijn zeer effectief, maar er loopt onderzoek om nog efficiëntere en nauwkeurigere neurale retrievalmodellen te ontwikkelen. Deze modellen zijn erop gericht semantische gelijkenissen beter vast te leggen over een breder scala aan vraag-document-paren, terwijl de efficiëntie bij grootschalige opvragingstaken verbetert.
Artikelen zoals Karpukhin et al. (2020) introduceerden Dense Passage Retrieval (DPR) als kernmethode voor open-domein vraagbeantwoording, terwijl recentere studies zoals Izacard et al. (2022) zich richten op few-shot learning om RAG-systemen aan te passen voor domeinspecifieke taken.
Een ander opkomend onderzoeksgebied richt zich op het verbeteren van de connectie tussen opvraging en generatie via retrieval-enhanced generation-modellen. Deze modellen streven ernaar opgehaalde documenten naadloos te integreren in het generatieproces, zodat het taalmodel zijn output directer kan conditioneren op de opgehaalde inhoud.
Dit kan hallucinaties verminderen en de feitelijke nauwkeurigheid van gegenereerde antwoorden verbeteren, waardoor het systeem betrouwbaarder wordt. Opmerkelijke werken zijn onder meer Huang et al. (2023) met het RAVEN-model, dat in-context learning verbetert met retrieval-augmented encoder-decoder modellen.
De integratie van geavanceerde RAG-technieken zoals dense retrieval, reranking en meerstapsredenering zorgt ervoor dat RAG-systemen voldoen aan de eisen van realistische toepassingen, van zorg tot gepersonaliseerde aanbevelingen.
Vooruitkijkend wordt de evolutie van RAG-systemen gedreven door innovaties zoals cross-linguale capaciteiten, gepersonaliseerde generatie en het verwerken van meer diverse databronnen.
Wil je blijven leren en praktischer aan de slag met RAG-systemen? Dan raad ik deze tutorials aan:
Leer AI met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
