
Programma
Sviluppare applicazioni AI
21 h
La retrieval-augmented generation (RAG) combina il recupero di documenti con la generazione in linguaggio naturale, creando risposte più accurate e consapevoli del contesto.
Anche se la RAG di base è efficace, fatica con query complesse, allucinazioni e nel mantenere il contesto in conversazioni multi-turno.
In questo blog esplorerò tecniche avanzate che affrontano queste sfide migliorando l'accuratezza del recupero, la qualità della generazione e le prestazioni complessive del sistema.
Se stai leggendo questo articolo in preparazione a un colloquio, dai un'occhiata anche all'articolo Top 30 domande e risposte su RAG per colloqui.
Sebbene le implementazioni RAG di base possano essere utili, presentano dei limiti, soprattutto in contesti più esigenti.
Uno dei problemi più evidenti sono le allucinazioni, in cui il modello genera contenuti fattualmente errati o non supportati dai documenti recuperati. Questo può minare l'affidabilità del sistema, specialmente in ambiti che richiedono alta accuratezza, come la medicina o il diritto.
I modelli RAG standard possono avere difficoltà con le query specifiche di un dominio. Senza adattare i processi di recupero e generazione alle sfumature dei domini specializzati, il sistema rischia di recuperare informazioni irrilevanti o inaccurate.
Un'altra sfida è la gestione di query complesse, multi-step o di conversazioni multi-turno. I sistemi RAG di base spesso faticano a mantenere il contesto tra le interazioni, portando a risposte sconnesse o incomplete. Man mano che le query degli utenti diventano più complesse, i sistemi RAG devono evolversi per gestire questa crescente complessità.
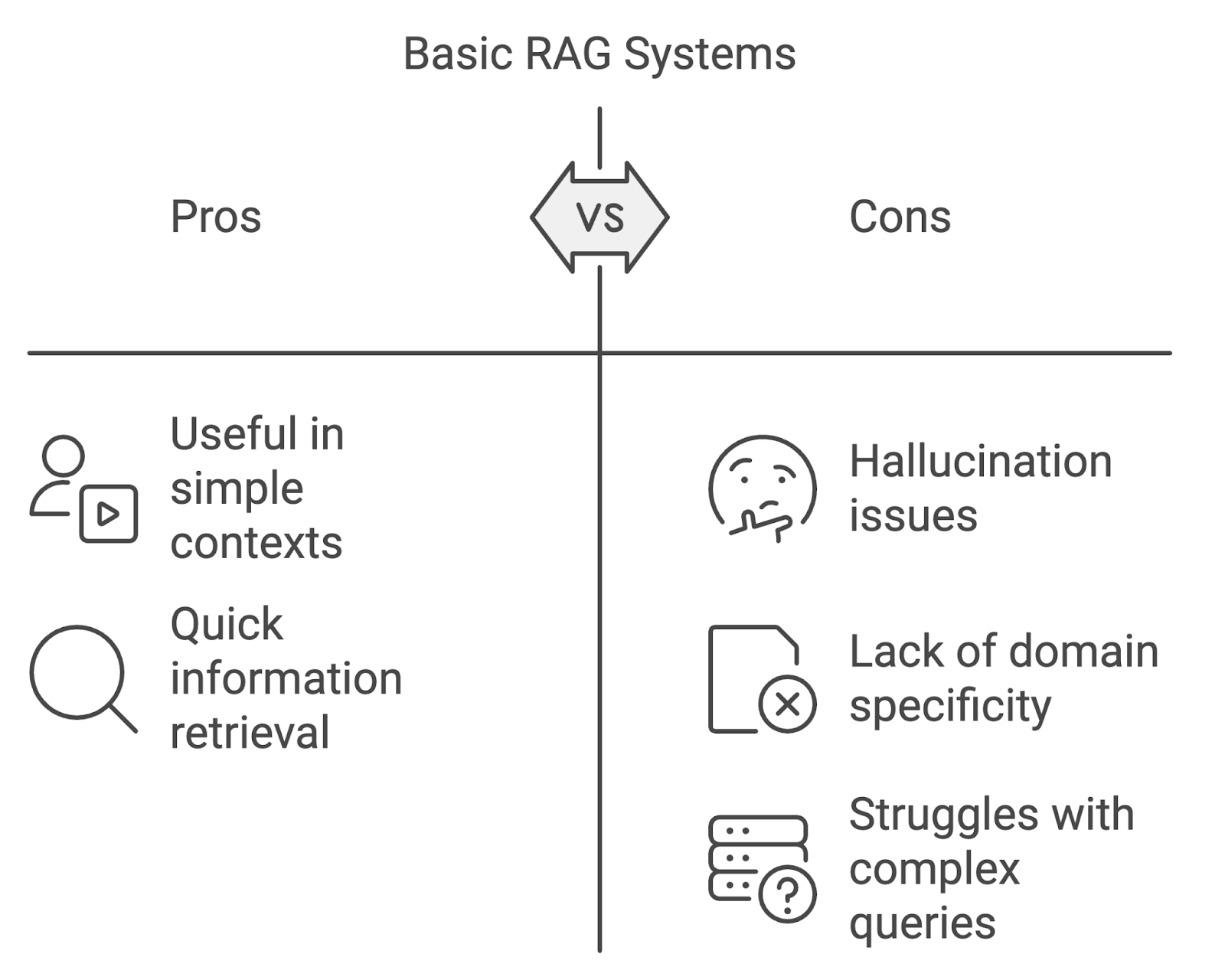
Diagramma generato con napkin.ai
Le tecniche di recupero avanzate mirano a migliorare sia la pertinenza sia l'ampiezza dei documenti recuperati. Queste tecniche, tra cui dense retrieval, ricerca ibrida, reranking ed espansione della query, affrontano i limiti del recupero basato su keyword.
Dense retrieval e ricerca ibrida sono tecniche chiave per migliorare accuratezza e pertinenza del recupero. Metodi come TF-IDF o BM25 spesso faticano con la comprensione semantica quando le query sono formulate in modo diverso rispetto ai documenti.
Il dense retrieval, come DPR (Dense Passage Retrieval), utilizza il deep learning per mappare query e documenti in rappresentazioni vettoriali dense, catturando il significato del testo oltre le keyword esatte.
La ricerca ibrida combina recupero sparso e denso, bilanciando precisione e recall unendo il matching basato su keyword con la similarità semantica, risultando efficace per query più complesse.
Il reranking è un'altra tecnica avanzata usata per rifinire l'elenco dei documenti recuperati prima che vengano passati al componente di generazione. In un tipico sistema RAG, la fase iniziale di recupero può produrre un ampio set di documenti con pertinenza variabile.
Il ruolo del reranking è riordinare questi documenti in modo che i più pertinenti siano prioritizzati per l'uso da parte del modello linguistico. Il reranking può andare da un semplice punteggio basato sulla similarità query-documento a modelli di machine learning più complessi addestrati a prevedere la pertinenza di ciascun documento.
Puoi imparare come implementare il reranking in questo tutorial sul reranking con RankGPT.
L'espansione della query consiste nell'arricchire la query dell'utente con termini aggiuntivi che aumentano le probabilità di recuperare documenti pertinenti. Può essere ottenuta tramite:
Per esempio, se la query originale è "intelligenza artificiale in sanità", l'espansione potrebbe includere termini correlati come "AI", "machine learning" o "health tech", garantendo una rete di recupero più ampia.
Nei sistemi RAG non basta semplicemente recuperare documenti: garantire la pertinenza e la qualità di tali documenti è fondamentale per migliorare l'output finale. A tal fine, sono vitali tecniche avanzate che raffinano e filtrano i contenuti recuperati.
Questi metodi riducono il rumore, aumentano la pertinenza e concentrano il modello linguistico sulle informazioni più importanti durante il processo di generazione.
Le tecniche di filtraggio avanzate utilizzano metadati o regole basate sui contenuti per escludere documenti irrilevanti o di bassa qualità, assicurando che vengano passati solo i risultati più pertinenti.
La distillazione del contesto è il processo di sintesi o condensazione dei documenti recuperati per concentrare il modello linguistico sulle informazioni più importanti. È utile quando i documenti recuperati contengono troppo contenuto irrilevante o quando la query richiede ragionamenti complessi e multi-step.
Distillando il contesto, il sistema estrae gli insight chiave e i passaggi più pertinenti dai documenti recuperati, assicurando che il modello linguistico disponga delle informazioni più chiare e rilevanti con cui lavorare.
Una volta che i documenti pertinenti sono stati recuperati e raffinati, il passaggio successivo in un sistema RAG è la generazione. Ottimizzare il modo in cui il modello linguistico genera risposte è essenziale per garantire accuratezza, coerenza e pertinenza.
Il prompt engineering si riferisce al processo di progettazione e strutturazione dei prompt forniti al modello linguistico. La qualità del prompt influisce direttamente sulla qualità dell'output generato dal modello, poiché il prompt fornisce le istruzioni o il contesto iniziale per il compito di generazione.
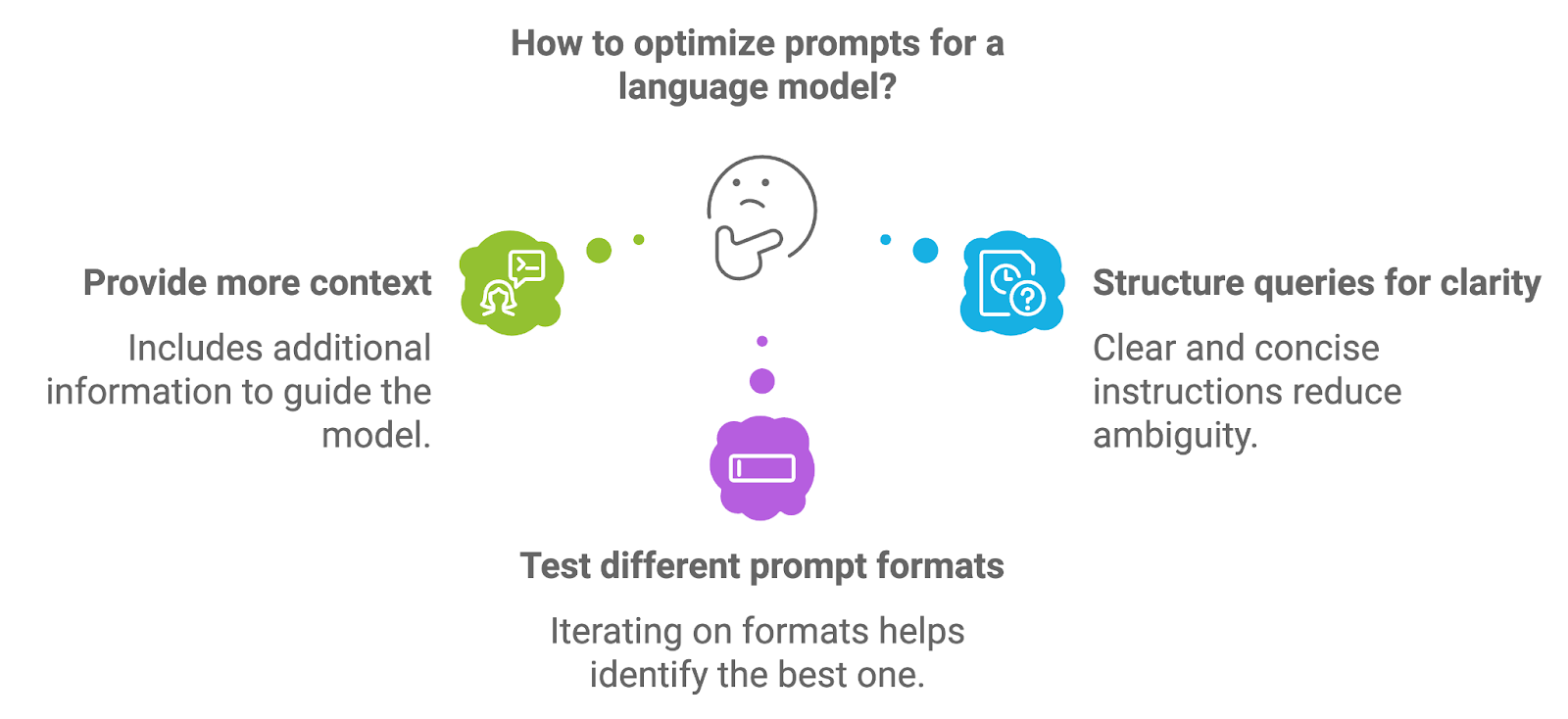
Diagramma generato con napkin.ai
Per ottimizzare i prompt, gli sviluppatori possono sperimentare diversi approcci.
Includere informazioni aggiuntive, come istruzioni esplicite o termini chiave, può guidare il modello verso risposte più accurate e contestualmente pertinenti. Per esempio, in un sistema RAG medico, un prompt potrebbe richiedere esplicitamente al modello di fornire un riepilogo diagnostico basato sui documenti recuperati.
Prompt ben strutturati, con istruzioni chiare e concise, aiutano a ridurre l'ambiguità e portano a risultati di generazione più mirati. Formulare il prompt come una domanda o richiesta diretta spesso produce risultati migliori.
Iterare sui formati di prompt, ad esempio riformulando le domande, regolando il livello di specificità o fornendo esempi, può aiutare a identificare il formato che offre i risultati migliori per uno specifico caso d'uso.
Scopri di più in questo blog: Tecniche di ottimizzazione dei prompt.
Molte query, in particolare in ambiti come ricerca, diritto o supporto tecnico, coinvolgono più passaggi o richiedono un ragionamento complesso. Il ragionamento multi-step è il processo con cui un sistema scompone una query complessa in sotto-attività gestibili e le elabora in sequenza per arrivare a una risposta completa.
Possiamo implementare il ragionamento multi-step all'interno di un sistema RAG in vari modi:
Come accennato, una delle principali sfide nei modelli di generazione, inclusi quelli usati nei sistemi RAG, sono le allucinazioni. Diverse tecniche possono aiutare a mitigare le allucinazioni nei sistemi RAG:
Poiché i sistemi RAG sono sempre più applicati a compiti reali, devono essere in grado di gestire interazioni complesse, multi-turno e query ambigue.
Una delle principali sfide nei sistemi RAG conversazionali è gestire il flusso di informazioni attraverso più interazioni. In molti scenari quotidiani, come l'assistenza clienti o discussioni tecniche continuative, gli utenti spesso intraprendono conversazioni multi-turno in cui il contesto deve essere mantenuto per diversi scambi.
Far sì che il sistema tracci e ricordi le parti rilevanti della conversazione è fondamentale per fornire risposte coerenti e consistenti. Per gestire efficacemente conversazioni multi-turno, i sistemi RAG possono usare le seguenti tecniche:
Le query degli utenti non sono sempre lineari: spesso possono essere vaghe, ambigue o coinvolgere ragionamenti complessi che mettono alla prova le capacità di un sistema RAG.
Un modo per affrontare l'ambiguità è far sì che il sistema richieda chiarimenti all'utente. Per esempio, se la query è troppo vaga, il sistema può generare una domanda di follow-up chiedendo maggiori dettagli. Questo processo interattivo aiuta a restringere l'intento dell'utente prima di procedere con le fasi di recupero e generazione.
Per query complesse che coinvolgono più aspetti o sottoargomenti, il sistema può scomporre la query in parti più piccole e gestibili. Ciò comporta il recupero delle informazioni in fasi, in cui ogni fase affronta uno specifico aspetto della query. L'output finale viene poi sintetizzato da più passaggi di recupero e generazione, assicurando che tutte le componenti della query siano affrontate.
Per gestire l'ambiguità, il sistema può usare indizi contestuali dalla query o dalla cronologia della conversazione. Analizzando interazioni precedenti o argomenti correlati, il sistema RAG può inferire l'intento dell'utente con maggiore precisione, riducendo la probabilità di generare risposte irrilevanti o errate.
Per query particolarmente impegnative, i sistemi RAG possono implementare metodi di recupero avanzati, come il question answering multi-hop, in cui il sistema recupera informazioni da più documenti e crea connessioni logiche tra di essi per rispondere a query complesse.
Sebbene i sistemi RAG offrano soluzioni potenti per il recupero di informazioni e la generazione di testo, introducono anche sfide specifiche da affrontare.
Il bias nei modelli linguistici, inclusi quelli usati nei sistemi RAG, è un problema noto che può influire negativamente sulla correttezza e l'accuratezza degli output generati. Il bias può entrare nel sistema sia nella fase di recupero sia in quella di generazione, risultando in output distorti o discriminatori che riflettono bias sociali, culturali o specifici di dominio presenti nei dataset sottostanti.
Per mitigare il bias nei sistemi RAG, possiamo applicare diverse strategie:
Man mano che i sistemi RAG diventano più complessi con l'integrazione di tecniche avanzate di recupero e generazione, aumentano anche le richieste computazionali. Questa sfida si manifesta in aree come dimensione del modello, velocità di elaborazione e latenza, che possono influire su efficienza e scalabilità del sistema.
Per gestire gli overhead computazionali, gli sviluppatori possono adottare le seguenti ottimizzazioni:
I sistemi RAG dipendono fortemente dalla qualità e dall'ampiezza dei dati che recuperano e generano. In applicazioni specifiche di dominio, le limitazioni dei dati possono essere una sfida notevole, in particolare quando i dati di addestramento disponibili sono insufficienti, obsoleti o di bassa qualità.
Possiamo affrontare le limitazioni dei dati nei sistemi RAG con alcuni approcci.
Quando i dati di addestramento specifici di dominio sono limitati, le tecniche di data augmentation possono aiutare ad ampliare artificialmente il dataset. Questo può includere la generazione di dati sintetici, la parafrasi di documenti esistenti o l'uso di fonti esterne per integrare il dataset originale. La data augmentation garantisce al modello l'accesso a una gamma più ampia di esempi, migliorando la capacità di gestire query diverse.
Eseguire il fine-tuning di modelli linguistici pre-addestrati su piccoli dataset specifici di dominio può aiutare i sistemi RAG ad adattarsi a casi d'uso specializzati, anche con dati limitati. L'adattamento al dominio consente al modello di comprendere meglio la terminologia e le sfumature del settore, migliorando la qualità delle risposte generate.
Nei casi in cui i dati di addestramento di alta qualità scarseggiano, si può impiegare l'active learning per migliorare il dataset in modo iterativo. Identificando i punti dati più informativi e concentrando su quelli gli sforzi di annotazione, gli sviluppatori possono potenziare gradualmente il dataset senza richiedere fin da subito grandi quantità di dati etichettati.
Implementare tecniche avanzate nei sistemi RAG richiede una solida comprensione di strumenti, framework e strategie disponibili. Man mano che queste tecniche diventano più complesse, l'uso di librerie e framework specializzati semplifica l'integrazione di workflow sofisticati di recupero e generazione.
Sono emersi molti framework e librerie per supportare l'implementazione di tecniche RAG avanzate, offrendo soluzioni modulari e scalabili per sviluppatori e ricercatori. Questi strumenti migliorano il processo di costruzione di sistemi RAG fornendo componenti per recupero, ranking, filtraggio e generazione.
LangChain è un framework popolare progettato specificamente per lavorare con modelli linguistici e integrarli con fonti di dati esterne. Supporta tecniche avanzate di retrieval-augmented, tra cui indicizzazione dei documenti, interrogazione e concatenazione di diversi passaggi di elaborazione (recupero, generazione e ragionamento).
LangChain offre anche integrazioni pronte all'uso con database vettoriali e vari retriever, rendendolo un'opzione versatile per costruire sistemi RAG personalizzati.
Scopri di più su LangChain e RAG in questo corso: Crea sistemi RAG con LangChain
Haystack è un framework open source specializzato nella costruzione di sistemi RAG per l'uso in produzione. Fornisce strumenti per dense retrieval, ranking e filtraggio dei documenti, oltre alla generazione in linguaggio naturale.
Haystack è particolarmente potente in applicazioni che richiedono ricerca specifica di dominio, question answering o sintesi di documenti. Con il supporto per vari backend e l'integrazione con modelli linguistici popolari, Haystack semplifica il deployment di sistemi RAG in scenari reali.
La OpenAI API consente agli sviluppatori di integrare potenti modelli linguistici, come GPT-4, nei workflow RAG. Pur non essendo specifica per i compiti di retrieval-augmented, i modelli OpenAI possono essere usati insieme ai framework di recupero per generare risposte basate sulle informazioni recuperate, abilitando capacità di generazione avanzate.
Per integrare tecniche avanzate in un sistema RAG esistente, è essenziale seguire un approccio strutturato.
Inizia selezionando un framework o una libreria in linea con il tuo caso d'uso. Per esempio, se ti serve un sistema altamente scalabile con capacità di dense retrieval, framework come LangChain o Haystack sono ideali.
Il primo passo è configurare il componente di recupero, che comporta l'indicizzazione della tua fonte dati e la configurazione del metodo di recupero. A seconda del caso d'uso, potresti scegliere il dense retrieval (usando embedding vettoriali) o la ricerca ibrida (combinando metodi sparsi e densi). Per esempio, LangChain o Haystack possono essere usati per creare la pipeline di recupero.
Una volta che il sistema di recupero è operativo, il passo successivo è migliorare la pertinenza tramite tecniche di reranking e filtraggio. Questo può essere fatto usando i moduli di reranking integrati in Haystack o personalizzando i tuoi modelli di reranking in base ai tipi di query specifici.
Dopo il recupero, ottimizza il processo di generazione sfruttando prompt engineering, distillazione del contesto e ragionamento multi-step. Con LangChain, puoi concatenare passaggi di recupero e generazione per gestire query multi-step o usare template di prompt che condizionino il modello per una generazione più accurata.
Se le allucinazioni sono un problema, concentrati sull'ancorare la generazione ai documenti recuperati, assicurando che il modello generi output basati sul contenuto di tali documenti.
Il test regolare è cruciale per perfezionare le prestazioni del sistema RAG. Usa metriche di valutazione come accuratezza, pertinenza e soddisfazione dell'utente per valutare l'efficacia di tecniche avanzate come reranking e distillazione del contesto. Esegui A/B test per confrontare approcci diversi e ottimizza il sistema in base ai feedback.
Con la crescita del sistema, gli overhead computazionali possono diventare un problema. Per gestirli, adotta tecniche di ottimizzazione come distillazione o quantizzazione del modello e assicurati che i processi di recupero siano efficienti. L'uso di accelerazione GPU o parallelizzazione può anche aiutare a mantenere le prestazioni su larga scala.
I sistemi RAG devono evolvere per adattarsi a nuove query e dati. Configura strumenti di monitoraggio per tracciare in tempo reale le prestazioni del sistema e aggiorna continuamente il modello e l'indice di recupero per gestire tendenze ed esigenze emergenti.
Implementare tecniche avanzate in un sistema RAG è solo l'inizio. Usando adeguate metriche di valutazione e metodi di test come l'A/B testing, possiamo valutare quanto bene il sistema risponde alle query degli utenti e si affina nel tempo.
L'accuratezza misura la frequenza con cui il sistema recupera e genera la risposta corretta o pertinente. Per i sistemi di question answering, ciò può comportare un confronto diretto delle risposte generate con dati di verità a terra. Un'accuratezza maggiore indica che il sistema interpreta correttamente le query e fornisce risultati precisi.
Questa metrica valuta la pertinenza dei documenti recuperati e la qualità della risposta generata in base a quanto bene rispondono alla query dell'utente. Metriche come Mean Reciprocal Rank (MRR) o Precision@K sono comunemente usate per quantificare la pertinenza, valutando quanto in alto in classifica appare il documento più rilevante.
Sebbene accuratezza e pertinenza siano cruciali, contano anche le prestazioni in tempo reale. La latenza si riferisce al tempo di risposta del sistema, cioè la velocità con cui recupera documenti e genera risposte. Una bassa latenza è particolarmente importante nelle applicazioni in cui le risposte tempestive sono vitali, come l'assistenza clienti o i sistemi di Q&A live.
La copertura misura quanto bene il sistema RAG gestisce un'ampia varietà di query. In applicazioni specifiche di dominio, garantire che il sistema possa affrontare l'intero spettro di potenziali query degli utenti è fondamentale per fornire un supporto completo.
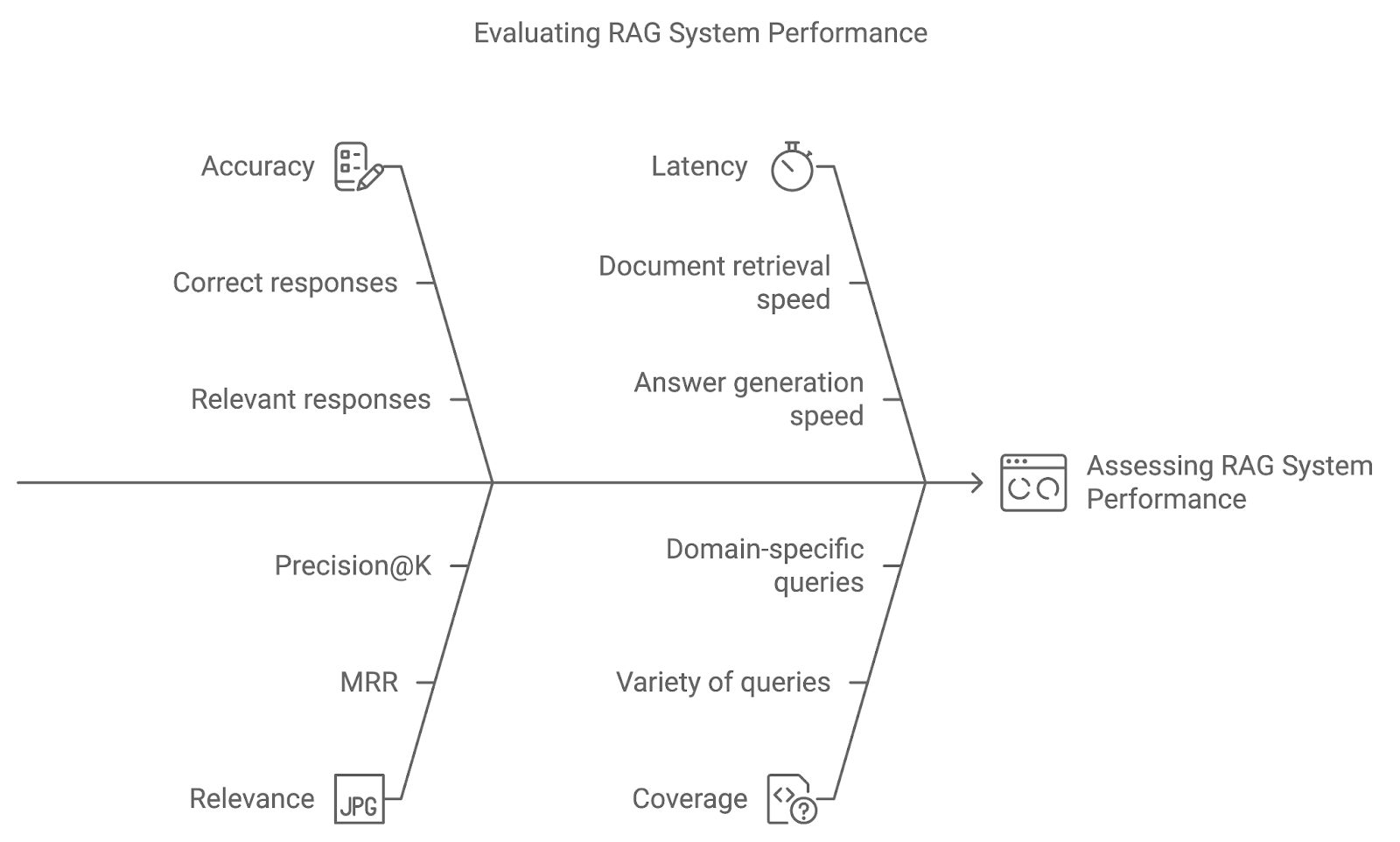
Diagramma generato con napkin.ai
Le tecniche RAG avanzate aprono un'ampia gamma di possibilità in diversi settori e applicazioni.
Uno dei casi d'uso più incisivi delle tecniche RAG avanzate è nei sistemi di question answering (QA) complessi. Questi sistemi richiedono più del semplice recupero di documenti: devono comprendere il contesto, scomporre query multi-step e fornire risposte complete basate sui documenti recuperati.
Nei settori in cui la conoscenza specifica di dominio è importante, si possono costruire sistemi RAG avanzati per recuperare e generare contenuti altamente specializzati. Alcune applicazioni degne di nota includono:
I sistemi di raccomandazione personalizzati sono un altro caso d'uso chiave per le tecniche RAG avanzate. Combinando preferenze utente, comportamenti e fonti di dati esterne, i sistemi RAG possono generare raccomandazioni personalizzate per prodotti, servizi o contenuti, tra cui:
La prossima generazione di sistemi RAG integrerà fonti di dati più diverse, migliorerà le capacità di ragionamento e affronterà le attuali limitazioni come l'ambiguità e la gestione di query complesse.
Un'area chiave di sviluppo è l'integrazione di varie fonti di dati, andando oltre l'affidamento su dataset singoli. I sistemi futuri combineranno informazioni da fonti diverse come database, API e feed in tempo reale, consentendo risposte più complete e multidimensionali a query complesse.
Gestire query ambigue o incomplete è un'altra sfida che i futuri sistemi RAG affronteranno. Combinando ragionamento probabilistico con una migliore comprensione contestuale, questi sistemi gestiranno l'incertezza in modo più efficace.
Inoltre, il ragionamento multi-step diventerà più centrale nel modo in cui i sistemi RAG elaborano le query complesse, scomponendole in componenti più piccole e sintetizzando i risultati tra più documenti o passaggi. Ciò sarà particolarmente utile in ambiti come ricerca legale, scoperta scientifica e supporto clienti, dove le query richiedono spesso il collegamento di informazioni eterogenee.
Con il continuo miglioramento della personalizzazione e della consapevolezza del contesto, i futuri sistemi RAG adatteranno le risposte in base alla cronologia, alle preferenze e alle interazioni passate dell'utente. L'adattamento in tempo reale a nuove informazioni consentirà conversazioni più dinamiche e produttive.
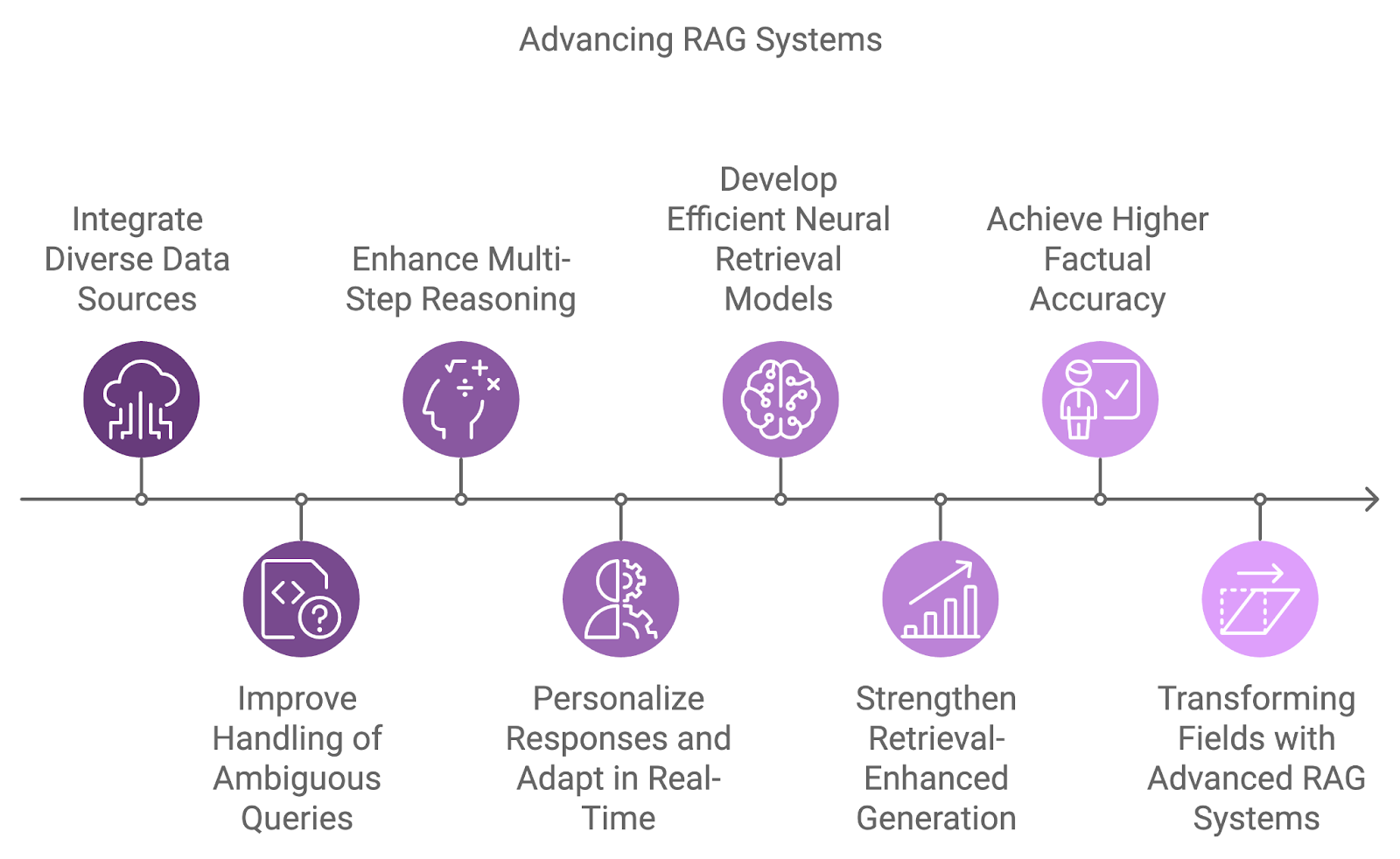
Diagramma generato con napkin.ai
Gli attuali modelli di dense retrieval sono altamente efficaci, ma la ricerca è in corso per sviluppare modelli neurali di recupero ancora più efficienti e accurati. Questi modelli puntano a catturare meglio le somiglianze semantiche su una gamma più ampia di coppie query-documento, migliorando l'efficienza nei compiti di recupero su larga scala.
Lavori come Karpukhin et al. (2020) hanno introdotto il Dense Passage Retrieval (DPR) come metodo cardine per il question answering open-domain, mentre studi più recenti come Izacard et al. (2022) si concentrano sul few-shot learning per adattare i sistemi RAG a compiti specifici di dominio.
Un'altra area di ricerca emergente si concentra sul miglioramento del collegamento tra recupero e generazione tramite modelli di generazione potenziata dal recupero. Questi modelli mirano a integrare senza soluzione di continuità i documenti recuperati nel processo di generazione, consentendo al modello linguistico di condizionare il proprio output più direttamente sui contenuti recuperati.
Ciò può ridurre le allucinazioni e migliorare l'accuratezza fattuale delle risposte generate, rendendo il sistema più affidabile. Tra i lavori degni di nota c'è Huang et al. (2023) con il modello RAVEN, che migliora l'in-context learning usando modelli encoder-decoder potenziati dal recupero.
L'integrazione di tecniche RAG avanzate come dense retrieval, reranking e ragionamento multi-step garantisce che i sistemi RAG possano soddisfare le esigenze delle applicazioni reali, dalla sanità alle raccomandazioni personalizzate.
Guardando avanti, l'evoluzione dei sistemi RAG sarà guidata da innovazioni come capacità cross-lingua, generazione personalizzata e gestione di fonti di dati più diversificate.
Se vuoi continuare a imparare e fare pratica con i sistemi RAG, ti consiglio questi tutorial:
Impara l'AI con questi corsi!
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

