
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Retrieval-augmented generation (RAG) kombiniert das Abrufen von Dokumenten mit der Generierung natürlicher Sprache, um genauere und kontextbezogene Antworten zu erhalten.
Während das einfache RAG effektiv ist, hat es Probleme mit komplexen Abfragen, Halluzinationen und dem Beibehalten des Kontexts in Gesprächen mit mehreren Personen.
In diesem Blog gehe ich auf fortschrittliche Techniken ein, die diese Herausforderungen angehen, indem sie die Abrufgenauigkeit, die Generierungsqualität und die Gesamtleistung des Systems verbessern.
Wenn du dich auf ein Vorstellungsgespräch vorbereitest, solltest du dir die Top 30 RAG-Interview-Fragen und Antworten Artikel.
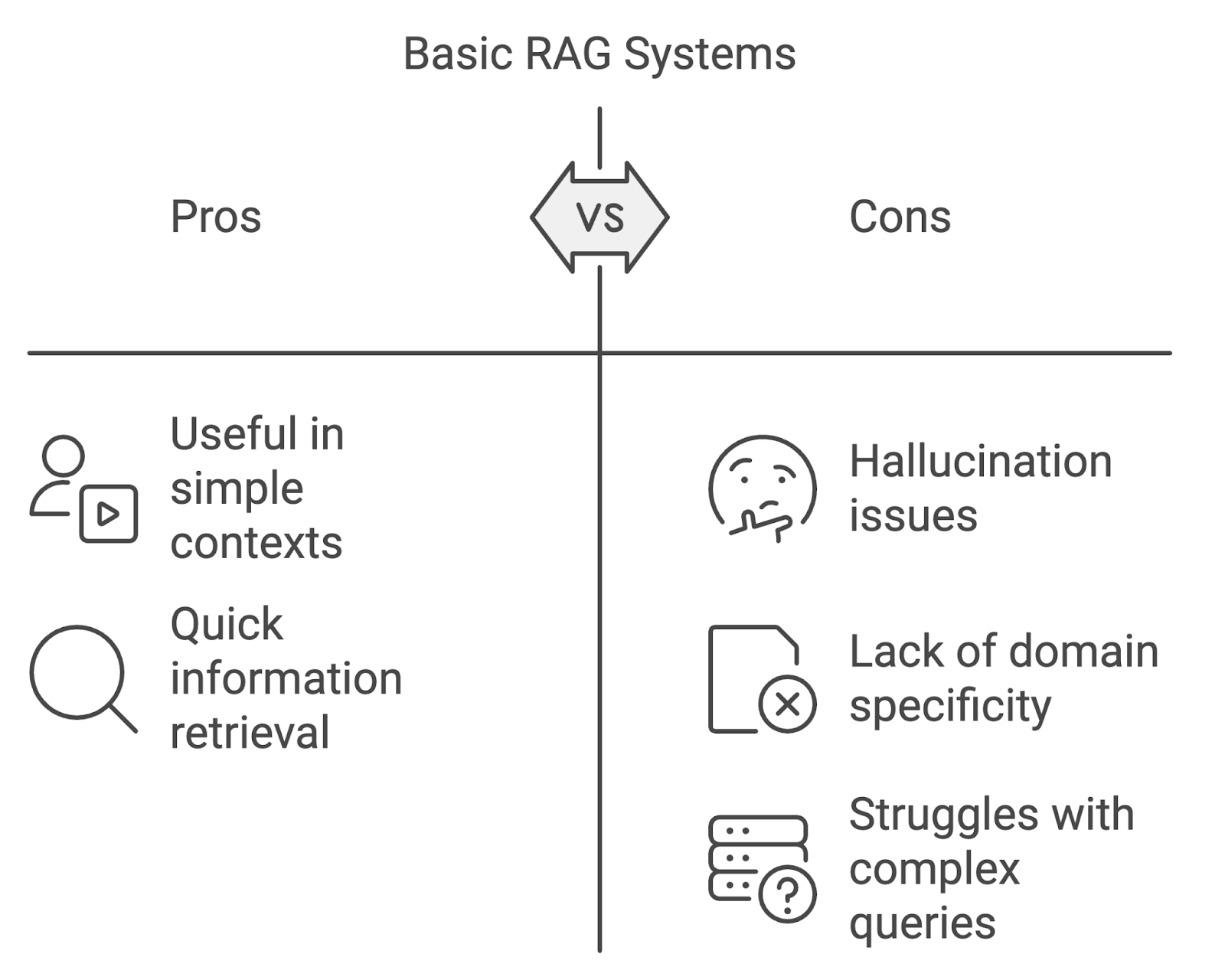
Einfache RAG-Implementierungen können zwar nützlich sein, haben aber auch ihre Grenzen, vor allem wenn sie in anspruchsvolleren Kontexten eingesetzt werden.
Eines der bekanntesten Probleme ist die Halluzination, bei der das Modell Inhalte generiert, die sachlich falsch sind oder durch die abgerufenen Dokumente nicht unterstützt werden. Dies kann die Zuverlässigkeit des Systems beeinträchtigen, insbesondere in Bereichen, die eine hohe Genauigkeit erfordern, wie z. B. Medizin oder Recht.
Standard-RAG-Modelle können bei domänenspezifischen Abfragen Schwierigkeiten haben. Wenn die Abfrage- und Generierungsprozesse nicht auf die Feinheiten spezialisierter Bereiche zugeschnitten sind, besteht die Gefahr, dass das System irrelevante oder ungenaue Informationen abruft.
Eine weitere Herausforderung ist die Verwaltung komplexer, mehrstufiger Abfragen oder Konversationen, die mehrere Schritte umfassen. Einfache RAG-Systeme haben oft Schwierigkeiten, den Kontext über Interaktionen hinweg zu erhalten, was zu unzusammenhängenden oder unvollständigen Antworten führt. Da die Nutzeranfragen immer komplexer werden, müssen sich die RAG-Systeme weiterentwickeln, um diese wachsende Komplexität zu bewältigen.
Mit napkin.ai erstelltes Diagramm
Fortschrittliche Suchtechniken konzentrieren sich darauf, sowohl die Relevanz als auch den Umfang der gefundenen Dokumente zu verbessern. Diese Techniken, zu denen die dichte Suche, die hybride Suche, das Reranking und die Anfrageerweiterung gehören, beheben die Grenzen der schlagwortbasierten Suche.
Dense Retrieval und hybride Suche sind Schlüsseltechniken zur Verbesserung der Abrufgenauigkeit und Relevanz. Methoden wie TF-IDF oder BM25 haben oft Probleme mit dem semantischen Verständnis, wenn die Suchanfragen anders formuliert sind als die Dokumente.
Dense Retrieval, wie DPR (Dense Passage Retrieval), nutzt Deep Learning um Abfragen und Dokumente in dichten Vektor Vektor-Repräsentationendie die Bedeutung des Textes über exakte Schlüsselwörter hinaus erfassen.
Die hybride Suche verbindet sparse und dense retrieval und sorgt für ein ausgewogenes Verhältnis von Präzision und Recall, indem sie schlagwortbasiertes Matching mit semantischer Ähnlichkeit kombiniert und so auch bei komplexeren Anfragen effektiv ist.
Reranking ist eine weitere fortschrittliche Technik, um die Liste der abgerufenen Dokumente zu verfeinern, bevor sie an die Generierungskomponente weitergegeben wird. In einem typischen RAG-System kann die anfängliche Abfragephase eine große Menge an Dokumenten mit unterschiedlicher Relevanz ergeben.
Die Aufgabe des Rerankings ist es, diese Dokumente neu zu ordnen, so dass die relevantesten Dokumente für das Sprachmodell priorisiert werden. Reranking kann von einer einfachen Bewertung auf der Grundlage der Ähnlichkeit von Suchanfragen und Dokumenten bis hin zu komplexeren maschinellen Lernmodellen reichen, die die Relevanz der einzelnen Dokumente vorhersagen.
Wie du Reranking implementieren kannst, erfährst du in diesem Tutorial über Reranking mit RankGPT.
Bei der Anfrageerweiterung wird die Anfrage des Nutzers mit zusätzlichen Begriffen angereichert, die die Wahrscheinlichkeit erhöhen, relevante Dokumente zu finden. Das kann erreicht werden durch:
Wenn die ursprüngliche Suchanfrage zum Beispiel "Künstliche Intelligenz im Gesundheitswesen" lautet, kann die Suchanfrage um verwandte Begriffe wie "KI", "maschinelles Lernen" oder "Gesundheitstechnologie" erweitert werden, um ein breiteres Suchnetz zu erhalten.
In RAG-Systemen reicht es nicht aus, einfach nur Dokumente abzurufen. Die Relevanz und Qualität dieser Dokumente ist der Schlüssel zur Verbesserung des Endergebnisses. Zu diesem Zweck sind fortschrittliche Techniken zur Verfeinerung und Filterung der abgerufenen Inhalte unerlässlich.
Diese Methoden reduzieren das Rauschen, erhöhen die Relevanz und fokussieren das Sprachmodell auf die wichtigsten Informationen während des Generierungsprozesses.
Fortgeschrittene Filtertechniken verwenden Metadaten oder inhaltsbasierte Regeln, um irrelevante oder minderwertige Dokumente auszuschließen und sicherzustellen, dass nur die relevantesten Ergebnisse weitergeleitet werden.
Bei der Kontextdestillation werden die abgerufenen Dokumente zusammengefasst oder verdichtet, um das Sprachmodell auf die wichtigsten Informationen zu konzentrieren. Dies ist nützlich, wenn die abgerufenen Dokumente zu viele irrelevante Inhalte enthalten oder wenn die Abfrage komplexe, mehrstufige Schlussfolgerungen beinhaltet.
Durch das Herausfiltern des Kontexts extrahiert das System die wichtigsten Erkenntnisse und relevantesten Passagen aus den abgerufenen Dokumenten und stellt so sicher, dass das Sprachmodell mit den klarsten und relevantesten Informationen arbeiten kann.
Sobald relevante Dokumente gefunden und verfeinert wurden, ist der nächste Schritt in einem RAG-System der Generierungsprozess. Die Optimierung der Art und Weise, wie das Sprachmodell Antworten generiert, ist entscheidend für Genauigkeit, Kohärenz und Relevanz.
Prompt-Engineering bezieht sich auf den Prozess der Gestaltung und Strukturierung der Prompts, die in das Sprachmodell eingespeist werden. Die Qualität des Prompts wirkt sich direkt auf die Qualität der vom Modell erzeugten Ausgabe aus, da der Prompt die ersten Anweisungen oder den Kontext für die Generierungsaufgabe liefert.
Mit napkin.ai erstelltes Diagramm
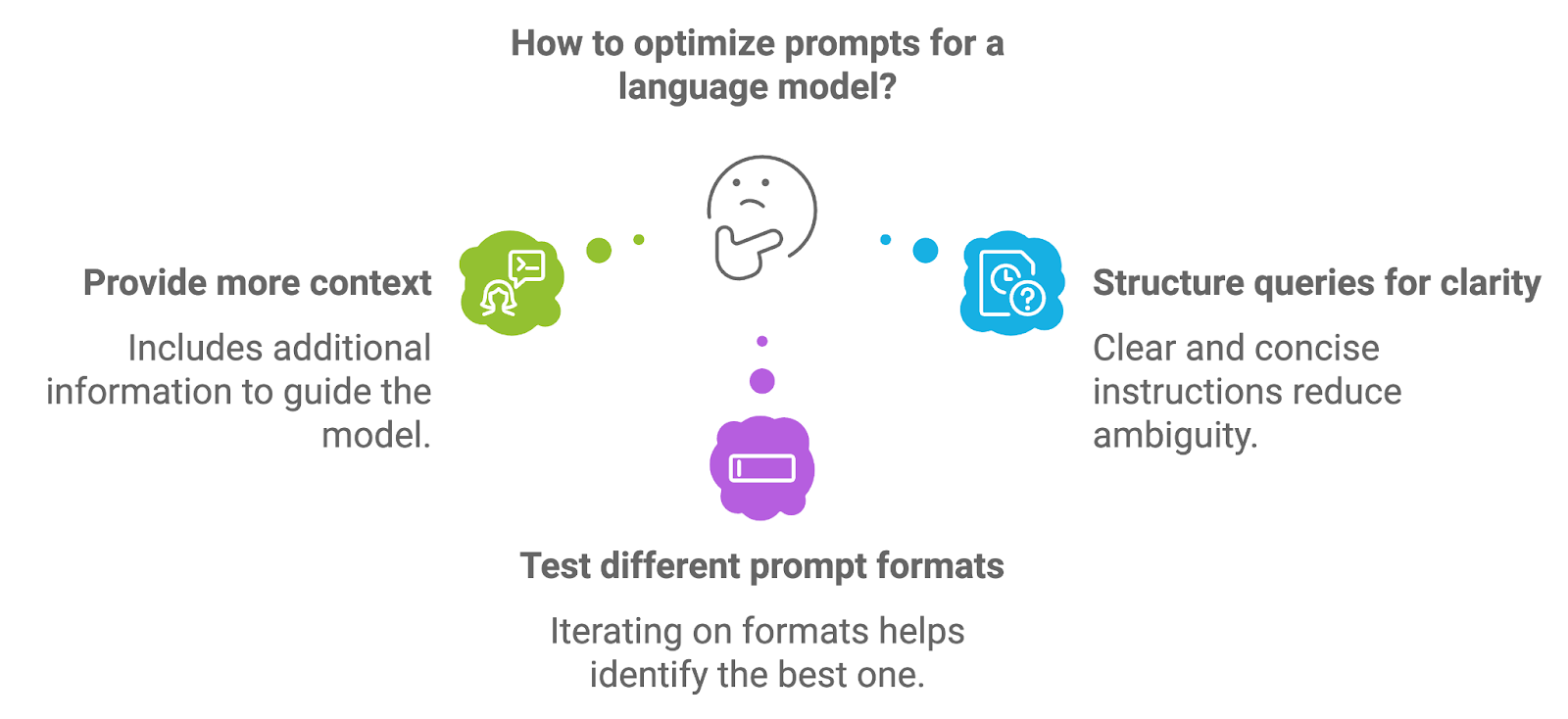
Um Prompts zu optimieren, können Entwickler mit verschiedenen Ansätzen experimentieren.
Zusätzliche Informationen, wie z. B. explizite Anweisungen oder Schlüsselbegriffe, können das Modell zu genaueren und kontextbezogenen Antworten führen. In einem medizinischen RAG-System könnte eine Eingabeaufforderung beispielsweise explizit verlangen, dass das Modell eine Diagnosezusammenfassung auf der Grundlage der abgerufenen Dokumente erstellt.
Gut strukturierte Aufforderungen mit klaren und präzisen Anweisungen tragen dazu bei, Unklarheiten zu beseitigen und führen zu gezielteren Generierungsergebnissen. Wenn du die Aufforderung als direkte Frage oder Bitte formulierst, kannst du oft bessere Ergebnisse erzielen.
Das Ausprobieren von Prompt-Formaten, wie z.B. das Umformulieren von Fragen, das Anpassen der Spezifität oder das Bereitstellen von Beispielen, kann helfen, das Format zu finden, das die besten Ergebnisse für einen bestimmten Anwendungsfall liefert.
Erfahre mehr in diesem Blog: Prompt-Optimierungstechniken.
Viele Abfragen, insbesondere in Bereichen wie Forschung, Recht oder technische Unterstützung, umfassen mehrere Schritte oder erfordern komplexe Überlegungen. Beim Multi-Step Reasoning zerlegt ein System eine komplexe Anfrage in überschaubare Teilaufgaben und bearbeitet sie nacheinander, um zu einer umfassenden Antwort zu gelangen.
Wir können das mehrstufige Reasoning in einem RAG-System auf verschiedene Arten umsetzen:
Wie bereits kurz erwähnt, ist eine der größten Herausforderungen bei Generierungsmodellen, einschließlich der in RAG-Systemen verwendeten, die Halluzination. Verschiedene Techniken können dazu beitragen, Halluzinationen in RAG-Systemen abzuschwächen:
Da RAG-Systeme zunehmend für reale Aufgaben eingesetzt werden, müssen sie in der Lage sein, komplexe Interaktionen und mehrdeutige Abfragen zu bewältigen.
Eine der größten Herausforderungen bei dialogorientierten RAG-Systemen ist die Steuerung des Informationsflusses über mehrere Interaktionen hinweg. In vielen alltäglichen Szenarien, wie z.B. beim Kundensupport oder in technischen Diskussionen, führen die Nutzer oft Gespräche mit mehreren Gesprächspartnern, bei denen der Kontext über mehrere Gespräche hinweg beibehalten werden muss.
Damit das System relevante Teile des Gesprächs verfolgen und sich merken kann, ist es wichtig, dass es kohärente und einheitliche Antworten gibt. Um Multi-Turn-Gespräche effektiv zu führen, können RAG-Systeme die folgenden Techniken anwenden:
Benutzeranfragen sind nicht immer einfach, oft sind sie vage, mehrdeutig oder beinhalten komplexe Überlegungen, die die Fähigkeiten eines RAG-Systems herausfordern.
Eine Möglichkeit, Unklarheiten zu beseitigen, besteht darin, das System aufzufordern, den/die Nutzer/in um eine Erklärung zu bitten. Wenn die Anfrage zum Beispiel zu vage ist, kann das System eine Folgefrage stellen, in der es um genauere Angaben geht. Dieser interaktive Prozess hilft dabei, die Absicht des Nutzers einzugrenzen, bevor mit der Abfrage- und Generierungsphase fortgefahren wird.
Bei komplexen Abfragen, die mehrere Aspekte oder Unterthemen umfassen, kann das System die Abfrage in kleinere, leichter zu handhabende Teile zerlegen. Dabei werden die Informationen in mehreren Schritten abgerufen, wobei jeder Schritt einen bestimmten Aspekt der Anfrage behandelt. Die endgültige Ausgabe wird dann aus mehreren Abfrage- und Generierungsschritten zusammengesetzt, um sicherzustellen, dass alle Komponenten der Anfrage berücksichtigt werden.
Um mit Mehrdeutigkeiten umzugehen, kann das System kontextbezogene Hinweise aus der Anfrage oder dem Gesprächsverlauf verwenden. Durch die Analyse früherer Interaktionen oder verwandter Themen kann das RAG-System genauer auf die Absicht des Nutzers schließen und so die Wahrscheinlichkeit irrelevanter oder falscher Antworten verringern.
Für besonders schwierige Abfragen können RAG-Systeme fortschrittliche Retrieval-Methoden implementieren, wie z.B. die Beantwortung von Multi-Hop-Fragen, bei denen das System Informationen aus mehreren Dokumenten abruft und logische Verbindungen zwischen ihnen herstellt, um komplexe Abfragen zu beantworten.
RAG-Systeme bieten zwar leistungsstarke Lösungen für die Informationssuche und die Texterstellung, aber sie bringen auch besondere Herausforderungen mit sich, die es zu bewältigen gilt.
Verzerrungen in Sprachmodellen, einschließlich derer, die in RAG-Systemen verwendet werden, ist ein bekanntes Problem, das sich negativ auf die Fairness und Genauigkeit der erzeugten Ergebnisse auswirken kann. Sowohl in der Abfrage- als auch in der Generierungsphase können Vorurteile in das System eindringen und zu verzerrten oder diskriminierenden Ergebnissen führen, die gesellschaftliche, kulturelle oder bereichsspezifische Vorurteile in den zugrunde liegenden Datensätzen widerspiegeln.
Um Verzerrungen in RAG-Systemen abzumildern, können wir verschiedene Strategien anwenden:
Da RAG-Systeme durch die Integration fortschrittlicher Retrieval- und Generierungstechniken immer komplexer werden, steigen die rechnerischen Anforderungen ebenfalls steigen. Diese Herausforderung manifestiert sich in Bereichen wie Modellgröße, Verarbeitungsgeschwindigkeit und Latenz, die alle die Effizienz und Skalierbarkeit des Systems beeinflussen können.
Um den Rechenaufwand zu reduzieren, können Entwickler die folgenden Optimierungen anwenden:
RAG-Systeme sind stark von der Qualität und dem Umfang der Daten abhängig, die sie abrufen und erzeugen. Bei domänenspezifischen Anwendungen können Datenbeschränkungen eine große Herausforderung darstellen, insbesondere wenn die verfügbaren Trainingsdaten unzureichend, veraltet oder von geringer Qualität sind.
Wir können den Datenbeschränkungen in RAG-Systemen mit einigen Ansätzen begegnen.
Wenn die domänenspezifischen Trainingsdaten begrenzt sind, können Techniken zur Datenerweiterung helfen, den Datensatz künstlich zu vergrößern. Dies kann die Erstellung synthetischer Daten, die Paraphrasierung vorhandener Dokumente oder die Nutzung externer Quellen zur Ergänzung des ursprünglichen Datensatzes beinhalten. Die Datenerweiterung stellt sicher, dass das Modell auf eine breitere Palette von Beispielen zugreifen kann, wodurch es besser in der Lage ist, verschiedene Abfragen zu bearbeiten.
Die Feinabstimmung von vortrainierten Sprachmodellen auf kleinen, domänenspezifischen Datensätzen kann RAG-Systemen dabei helfen, sich an spezielle Anwendungsfälle anzupassen, selbst bei begrenzten Daten. Durch die Anpassung an den jeweiligen Bereich kann das Modell die branchenspezifische Terminologie und Nuancen besser verstehen und die Qualität der generierten Antworten verbessern.
In Fällen, in denen nur wenige hochwertige Trainingsdaten zur Verfügung stehen, kann aktives Lernen eingesetzt werden, um den Datensatz iterativ zu verbessern. Indem man die informativsten Datenpunkte identifiziert und sich auf diese konzentriert, können die Entwickler den Datensatz schrittweise erweitern, ohne von Anfang an große Mengen an beschrifteten Daten zu benötigen.
Die Umsetzung fortschrittlicher Techniken in RAG-Systemen erfordert ein solides Verständnis der verfügbaren Tools, Frameworks und Strategien. Da diese Techniken immer komplexer werden, vereinfacht die Nutzung spezialisierter Bibliotheken und Frameworks die Integration anspruchsvoller Abruf- und Generierungsworkflows.
Viele Frameworks und Bibliotheken sind entstanden, um die Implementierung fortschrittlicher RAG-Techniken zu unterstützen. Sie bieten modulare und skalierbare Lösungen für Entwickler und Forscher. Diese Tools verbessern den Aufbau von RAG-Systemen, indem sie Komponenten für das Retrieval, das Ranking, die Filterung und die Generierung bereitstellen.
LangChain ist ein beliebtes Framework, das speziell für die Arbeit mit Sprachmodellen und deren Integration mit externen Datenquellen entwickelt wurde. Es unterstützt fortschrittliche Retrieval-Techniken, einschließlich der Indizierung von Dokumenten, der Abfrage und der Verkettung verschiedener Verarbeitungsschritte (Retrieval, Generierung und Reasoning).
LangChain bietet außerdem sofort einsatzbereite Integrationen mit Vektor-Datenbanken und verschiedenen Retrievern, was es zu einer vielseitigen Option für den Aufbau eigener RAG-Systeme macht.
In diesem Kurs erfährst du mehr über LangChain und RAG: RAG-Systeme mit LangChain aufbauen
Haystack ist ein Open-Source-Framework, das auf den Aufbau von RAG-Systemen für den Produktionseinsatz spezialisiert ist. Es bietet Werkzeuge für das dichte Retrieval, das Ranking und die Filterung von Dokumenten sowie die Generierung natürlicher Sprache.
Haystack ist besonders leistungsstark in Anwendungen, die eine domänenspezifische Suche, die Beantwortung von Fragen oder die Zusammenfassung von Dokumenten erfordern. Durch die Unterstützung einer Vielzahl von Backends und die Integration mit gängigen Sprachmodellen vereinfacht Haystack den Einsatz von RAG-Systemen in realen Szenarien.
Die OpenAI API ermöglicht es Entwicklern, leistungsstarke Sprachmodelle wie GPT-4 in RAG-Workflows zu integrieren. Die Modelle von OpenAI sind zwar nicht spezifisch für Retrieval-Aufgaben, können aber in Verbindung mit Retrieval-Frameworks verwendet werden, um Antworten auf der Grundlage der abgerufenen Informationen zu generieren, was erweiterte Generierungsfunktionen ermöglicht.
Um fortschrittliche Techniken in ein bestehendes RAG-System zu integrieren, ist es wichtig, einen strukturierten Ansatz zu verfolgen.
Beginne mit der Auswahl eines Frameworks oder einer Bibliothek, die zu deinem Anwendungsfall passt. Wenn du zum Beispiel ein hoch skalierbares System mit dichten Suchfunktionen brauchst, sind Frameworks wie LangChain oder Haystack ideal.
Der erste Schritt besteht darin, die Abrufkomponente einzurichten, d.h. deine Datenquelle zu indizieren und die Abrufmethode zu konfigurieren. Je nach Anwendungsfall kannst du dich für die dichte Suche (mit Vektoreinbettungen) oder die hybride Suche (mit einer Kombination aus spärlichen und dichten Methoden) entscheiden. Zum Beispiel können LangChain oder Haystack verwendet werden, um die Retrieval-Pipeline zu erstellen.
Sobald das Retrievalsystem einsatzbereit ist, besteht der nächste Schritt darin, die Relevanz durch Reranking und Filtertechniken zu verbessern. Dazu kannst du die eingebauten Reranking-Module in Haystack verwenden oder deine Reranking-Modelle auf der Grundlage deiner spezifischen Abfragetypen anpassen.
Nach dem Abruf optimierst du den Generierungsprozess, indem du Prompt Engineering, Context Distillation und Multi-Step Reasoning einsetzt. Mit LangChain kannst du Abfrage- und Generierungsschritte miteinander verketten, um mehrstufige Abfragen zu bearbeiten, oder Abfragevorlagen verwenden, die das Modell für eine genauere Generierung konditionieren.
Wenn Halluzinationen ein Problem sind, konzentriere dich darauf, die Generierung auf die abgerufenen Dokumente zu stützen und sicherzustellen, dass das Modell Ausgaben auf der Grundlage des Inhalts dieser Dokumente generiert.
Regelmäßige Tests sind wichtig, um die Leistung des RAG-Systems zu verbessern. Nutze Bewertungskriterien wie Genauigkeit, Relevanz und Nutzerzufriedenheit, um die Effektivität von fortgeschrittenen Techniken wie Reranking und Kontextdestillation zu bewerten. Führe A/B-Tests durch, um verschiedene Ansätze zu vergleichen und das System anhand des Feedbacks zu optimieren.
Wenn das System wächst, kann der Rechenaufwand zu einem Problem werden. Um dies zu bewältigen, solltest du Optimierungstechniken wie die Modelldestillation oder die Quantisierung anwenden und sicherstellen, dass die Abrufprozesse effizient sind. Der Einsatz von GPU-Beschleunigung oder Parallelisierung kann ebenfalls dazu beitragen, die Leistung bei der Skalierung zu erhalten.
Die RAG-Systeme müssen sich weiterentwickeln, um sich an neue Abfragen und Daten anzupassen. Richte Lernpfade ein, um die Leistung des Systems in Echtzeit zu verfolgen, und aktualisiere das Modell und den Abrufindex kontinuierlich, um neue Trends und Anforderungen zu berücksichtigen.
Die Implementierung fortschrittlicher Techniken in ein RAG-System ist nur der Anfang. Durch die Verwendung geeigneter Bewertungsmetriken und Testmethoden wie A/B-Tests können wir beurteilen, wie gut das System auf Nutzeranfragen reagiert und sich im Laufe der Zeit verbessert.
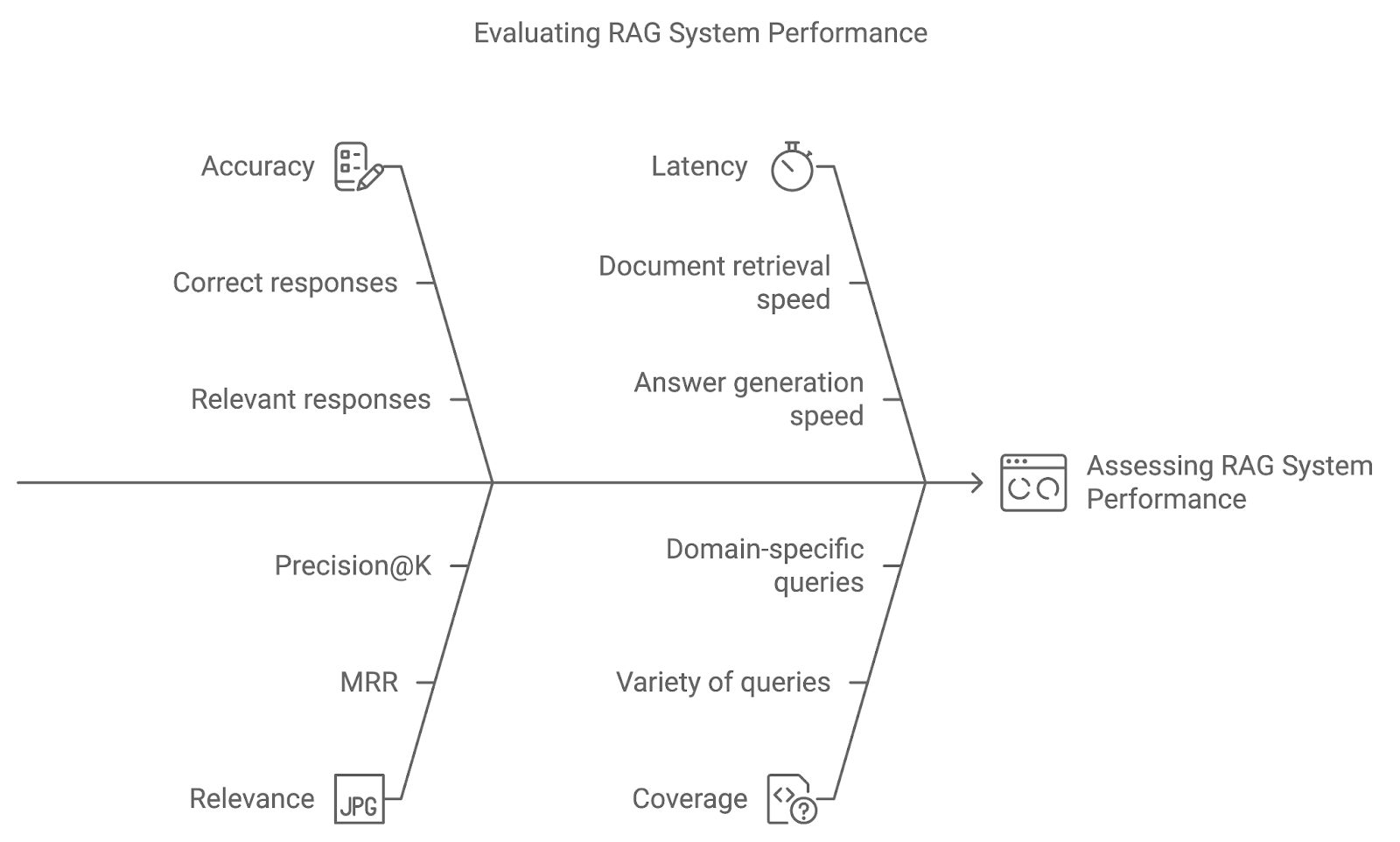
Die Genauigkeit misst, wie oft das System die richtige oder relevante Antwort abruft und erzeugt. Bei Frage-Antwort-Systemen könnte dies ein direkter Vergleich der generierten Antworten mit echten Daten sein. Eine höhere Genauigkeit zeigt, dass das System die Abfragen richtig interpretiert und präzise Ergebnisse liefert.
Diese Metrik bewertet die Relevanz der abgerufenen Dokumente und die Qualität der generierten Antwort, basierend darauf, wie gut sie die Anfrage des Nutzers beantworten. Metriken wie Mean Reciprocal Rank (MRR) oder Precision@K werden häufig verwendet, um die Relevanz zu quantifizieren und zu bewerten, wie weit oben in der Rangliste das relevanteste Dokument erscheint.
Genauigkeit und Relevanz sind zwar wichtig, aber auch die Leistung in Echtzeit ist wichtig. Die Latenzzeit bezieht sich auf die Reaktionszeit des Systems - die Geschwindigkeit, mit der das System Dokumente abruft und Antworten generiert. Niedrige Latenzzeiten sind besonders wichtig für Anwendungen, bei denen zeitnahe Antworten entscheidend sind, wie z.B. beim Kundensupport oder bei Live-Q&A-Systemen.
Der Abdeckungsgrad misst, wie gut das RAG-System eine Vielzahl von Abfragen bearbeitet. Bei domänenspezifischen Anwendungen ist es für eine umfassende Unterstützung entscheidend, dass das System alle möglichen Benutzeranfragen bearbeiten kann.
Mit napkin.ai erstelltes Diagramm
Fortgeschrittene RAG-Techniken eröffnen eine breite Palette von Möglichkeiten in verschiedenen Branchen und Anwendungen.
Einer der wichtigsten Anwendungsfälle für fortschrittliche RAG-Techniken sind komplexe Frage-Antwort-Systeme (QA). Diese Systeme brauchen mehr als nur eine einfache Dokumentensuche - sie müssen den Kontext verstehen, mehrstufige Abfragen aufschlüsseln und umfassende Antworten auf der Grundlage der gefundenen Dokumente geben.
In Branchen, in denen domänenspezifisches Wissen wichtig ist, können fortschrittliche RAG-Systeme entwickelt werden, um hochspezialisierte Inhalte abzurufen und zu generieren. Einige bemerkenswerte Anwendungen sind:
Personalisierte Empfehlungssysteme sind ein weiterer wichtiger Anwendungsfall für fortschrittliche RAG-Techniken. Durch die Kombination von Nutzerpräferenzen, Verhalten und externen Datenquellen können RAG-Systeme personalisierte Empfehlungen für Produkte, Dienstleistungen oder Inhalte generieren, einschließlich:
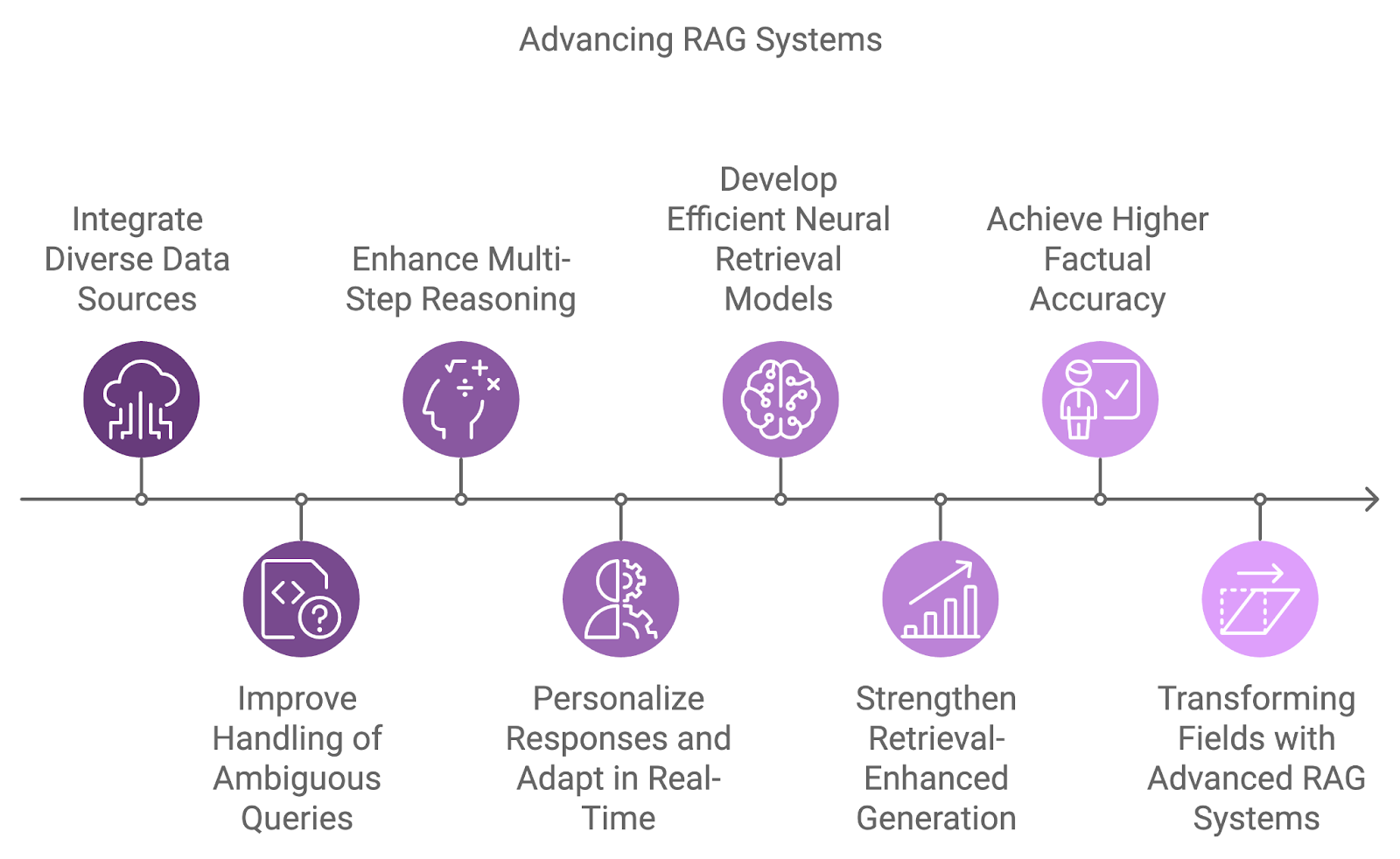
Die nächste Generation von RAG-Systemen wird vielfältigere Datenquellen integrieren, die Schlussfolgerungsmöglichkeiten verbessern und aktuelle Einschränkungen wie Mehrdeutigkeit und komplexe Abfrageverarbeitung beseitigen.
Ein wichtiger Entwicklungsbereich ist die Integration verschiedener Datenquellen, um sich nicht mehr nur auf einzelne Datensätze verlassen zu müssen. Künftige Systeme werden Informationen aus verschiedenen Quellen wie Datenbanken, APIs und Echtzeit-Feeds kombinieren und so umfassendere und mehrdimensionale Antworten auf komplexe Abfragen ermöglichen.
Der Umgang mit mehrdeutigen oder unvollständigen Abfragen ist eine weitere Herausforderung, der sich zukünftige RAG-Systeme stellen werden. Durch die Kombination von probabilistischem Denken mit einem besseren Verständnis des Kontextes können diese Systeme effektiver mit Unsicherheit umgehen.
Darüber hinaus wird das mehrstufige Reasoning ein wesentlicher Bestandteil der Art und Weise sein, wie RAG-Systeme komplexe Abfragen verarbeiten, indem sie sie in kleinere Komponenten zerlegen und die Ergebnisse über mehrere Dokumente oder Schritte zusammenfassen. Dies ist vor allem in Bereichen wie der Rechtsforschung, der wissenschaftlichen Forschung und dem Kundensupport von Vorteil, wo bei Anfragen oft verschiedene Informationen miteinander verbunden werden müssen.
Da die Personalisierung und das Kontextbewusstsein immer besser werden, werden zukünftige RAG-Systeme ihre Antworten auf der Grundlage der Benutzerhistorie, der Vorlieben und der vergangenen Interaktionen anpassen. Die Anpassung an neue Informationen in Echtzeit ermöglicht dynamischere und produktivere Gespräche.
Mit napkin.ai erstelltes Diagramm
Die derzeitigen dichten Abrufmodelle sind sehr effektiv, aber die Forschung arbeitet daran, noch effizientere und genauere neuronale Abrufmodelle zu entwickeln. Diese Modelle zielen darauf ab, semantische Ähnlichkeiten bei einer größeren Anzahl von Abfrage-Dokumenten-Paaren besser zu erfassen und gleichzeitig die Effizienz bei umfangreichen Retrievalaufgaben zu verbessern.
Papers like Karpukhin et al. (2020) führte Dense Passage Retrieval (DPR) als zentrale Methode für die Beantwortung von Fragen in offenen Bereichen ein, während neuere Studien wie Izacard et al. (2022) konzentrieren sich auf das Lernen in wenigen Schritten, um RAG-Systeme für domänenspezifische Aufgaben anzupassen.
Ein weiterer aufstrebender Forschungsbereich konzentriert sich auf die Verbesserung der Verbindung zwischen Retrieval und Generierung durch Retrieval-erweiterte Generierungsmodelle. Diese Modelle zielen darauf ab, die abgerufenen Dokumente nahtlos in den Generierungsprozess zu integrieren, so dass das Sprachmodell seine Ausgabe direkter von den abgerufenen Inhalten abhängig machen kann.
Dadurch können Halluzinationen reduziert und die sachliche Richtigkeit der generierten Antworten verbessert werden, wodurch das System zuverlässiger wird. Bemerkenswerte Arbeiten sind Huang et al. (2023) mit dem RAVEN-Modell, das das kontextinterne Lernen mit Retrieval-augmentierten Encoder-Decoder-Modellen verbessert.
Die Integration fortschrittlicher RAG-Techniken wie Dense Retrieval, Reranking und Multi-Step Reasoning stellt sicher, dass RAG-Systeme den Anforderungen realer Anwendungen gerecht werden, vom Gesundheitswesen bis hin zu personalisierten Empfehlungen.
In Zukunft wird die Entwicklung von RAG-Systemen durch Innovationen wie sprachübergreifende Funktionen, personalisierte Generierung und den Umgang mit vielfältigeren Datenquellen vorangetrieben werden.
Wenn du dich weiterbilden und mehr über die RAG-Systeme erfahren möchtest, empfehle ich dir diese Tutorials:
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Laiba Siddiqui
Tutorial
Allan Ouko

