
Program
Yapay Zeka Uygulamaları Geliştirme
21 sa
RAG hakkında temel nitelikte bir dizi mülakat sorusuyla başlayalım.
Bir RAG (retrieval-augmented generation) sisteminin iki ana bileşeni vardır: geri getirici (retriever) ve üretici (generator).
Geri getirici, veritabanları, belgeler veya web siteleri gibi harici kaynaklardan ilgili bilgileri arar ve toplar.
Üretici ise genellikle gelişmiş bir dil modelidir ve bu bilgileri kullanarak açık ve doğru metin üretir.
Geri getirici sistemin en güncel bilgilere erişmesini sağlarken, üretici bu bilgileri kendi bilgisiyle birleştirerek daha iyi yanıtlar üretir.
Birlikte çalıştıklarında, yalnızca üreticiye kıyasla daha doğru yanıtlar sunarlar.
Yalnızca bir LLM’in yerleşik bilgisine güvenirseniz, sistem eğitildiği verilerle sınırlı kalır; bu veriler güncel olmayabilir veya ayrıntı açısından yetersiz olabilir.
RAG sistemleri, harici kaynaklardan taze bilgi çekerek daha doğru ve zamanında yanıtlar üretme avantajı sağlar.
Bu yaklaşım ayrıca, modelin uydurma yaparak gerçek dışı bilgiler üretmesi anlamına gelen "halüsinasyonları" azaltır; çünkü yanıtlar gerçek verilere dayanır. RAG, güncel ve uzmanlaşmış bilginin gerektiği hukuk, tıp veya teknoloji gibi belirli alanlarda özellikle faydalıdır.
RAG, farklı alanlardaki çeşitli gerçek dünya AI uygulamalarında kullanılır:
Soru-cevap ve destek sistemleri: RAG, müşteri destek sohbet botlarını ve bilgi tabanı asistanlarını güncel dokümantasyon veya SSS’leri geri getirip kullanıcılara doğru yanıtlar üreterek güçlendirir. Bu sayede müşteri soruları en güncel bilgilerle çözülür (örneğin, geçerli politika bilgileri veya ürün detaylarının çekilmesi).
Konuşma ajanları: Pek çok sohbet botu ve sanal asistan, olgusal ve bağlama duyarlı yanıtlar sağlamak için RAG kullanır. İlgili gerçekleri anlık olarak getirerek, bir konuşma ajanı (ör. sağlık veya finans sohbet botu) güvenilir kaynaklara dayanan bilgilendirilmiş yanıtlar verebilir.
İçerik üretimi ve özetleme: RAG, olgusal doğrulukla içerik üretmeye veya özetlemeye yardımcı olur. Örneğin, haber makalelerinin veya araştırma makalelerinin bölümlerini geri getirip, kaynak veriye dayalı olarak hem tutarlı hem de doğrulanmış özetler veya raporlar üretebilir.
Alana özgü araştırma: Hukuk veya tıp gibi uzmanlık alanlarında, RAG sistemleri vaka hukuku, tıp dergileri vb. alan veritabanlarından bilgi çekerek karmaşık sorgulara yanıt verir. Böylece model çıktısı güvenilir ve güncel alan bilgisine dayanır; bu da profesyonel kullanım senaryoları için önemlidir.
RAG sistemleri, hem yapılandırılmış hem de yapılandırılmamış harici kaynaklardan bilgi toplayabilir:
Bu esneklik, RAG sistemlerinin vaka hukuku veritabanları, araştırma dergileri veya klinik çalışma verileri gibi kaynaklardan çekim yaparak hukuk ya da tıp gibi farklı alanlara uyarlanmasına olanak tanır.
Prompt mühendisliği, geri getirilen bilgileri kullanarak dil modellerinin yüksek kaliteli yanıtlar üretmesine yardımcı olur. Bir prompt’un nasıl tasarlandığı, çıktının uygunluğunu ve açıklığını etkileyebilir.
Bir RAG sisteminde geri getirici, üreticinin kullanması için harici kaynaklardan ilgili bilgileri toplar. Bilgi geri getirmenin farklı yolları vardır.
Bir yöntem seyrek geri getirmedir; anahtar kelimeleri eşleştirir (ör. TF-IDF veya BM25). Basittir ancak sözcüklerin ardındaki derin anlamı yakalamayabilir.
Bir diğer yaklaşım ise yoğun geri getirmedir; dokümanların ve sorguların anlamını kavramak için sinir gömülerini kullanır. BERT veya Dense Passage Retrieval (DPR) gibi yöntemler, dokümanları ortak bir uzayda vektörler olarak temsil ederek geri getirmeyi daha isabetli kılar.
Bu yöntemler arasındaki seçim, RAG sisteminin başarımını büyük ölçüde etkileyebilir.
Geri getirilen bilgiyi bir LLM’in üretimiyle birleştirmek bazı zorluklar içerir. Örneğin, geri getirilen verinin sorguyla yüksek derecede ilgili olması gerekir; ilgisiz veri modeli şaşırtabilir ve yanıt kalitesini düşürebilir.
Ayrıca, geri getirilen bilgi modelin dahili bilgisiyle çelişirse kafa karıştırıcı veya hatalı yanıtlar oluşabilir. Bu nedenle, kullanıcıyı karıştırmadan bu çelişkileri gidermek kritik önem taşır.
Son olarak, geri getirilen verinin üslup ve biçimi her zaman modelin alışık olduğu yazım veya formatla örtüşmeyebilir; bu da modelin bilgiyi akıcı biçimde entegre etmesini zorlaştırabilir.
Bir RAG sisteminde, vektör veritabanı, yoğun metin gömülerinin yönetilmesine ve depolanmasına yardımcı olur. Bu gömüler, BERT veya OpenAI gibi modeller tarafından oluşturulan ve sözcüklerin ile ifadelerin anlamını yakalayan sayısal temsillerdir.
Bir sorgu yapıldığında, onun gömüsü veritabanındaki kayıtlı gömülerle karşılaştırılarak benzer dokümanlar bulunur. Bu da doğru bilginin daha hızlı ve daha isabetli geri getirilmesini sağlar. Bu süreç, sistemin en ilgili bilgiyi hızla bulup çıkarmasına yardımcı olarak geri getirme hızını ve doğruluğunu artırır.
Bir RAG sistemini değerlendirmek için geri getirme ve üretim bileşenlerine birlikte bakmanız gerekir.
Soru-cevap gibi aşağı akış görevlerinde, F1 skoru, kesinlik ve duyarlılık metrikleri de genel RAG sistemini değerlendirmek için kullanılabilir.
Bir RAG sisteminde belirsiz veya eksik sorguları ele almak, kullanıcının girdisindeki netlik eksikliğine rağmen ilgili ve doğru bilgilerin geri getirilmesini sağlamak için stratejiler gerektirir.
Bir yaklaşım, sistemin bilinen kalıplara veya önceki etkileşimlere dayanarak belirsiz sorguyu daha kesin bir ifadeye dönüştürdüğü sorgu iyileştirme tekniklerini uygulamaktır. Bu, takip soruları sormayı veya kullanıcının amacını daraltmak için birden fazla seçenek sunmayı içerebilir.
Bir diğer yöntem, sorgunun birden çok olası yorumunu kapsayan çeşitli dokümanları geri getirmektir. Geniş bir sonuç yelpazesi getirerek, sorgu muğlak olsa bile bazı ilgili bilgilerin dahil edilmesi sağlanır.
Son olarak, eksik sorgulardan kullanıcı niyetini çıkarmak ve geri getirme sürecini rafine etmek için doğal dil anlama (NLU) modelleri kullanılabilir.
Artık birkaç temel soruyu ele aldığımıza göre, orta düzey RAG mülakat sorularına geçme zamanı.
Doğru geri getirici seçimi, üzerinde çalıştığınız veri türüne, sorguların doğasına ve sahip olduğunuz hesaplama gücüne bağlıdır.
Sözcüklerin ardındaki anlamın derinlemesine anlaşılmasını gerektiren karmaşık sorgular için BERT veya DPR gibi yoğun geri getirme yöntemleri daha iyidir. Bu yöntemler bağlamı yakalar ve müşteri desteği veya araştırma gibi temel anlamların önemli olduğu görevler için idealdir.
Görev daha basitse ve anahtar kelime eşleştirmeye dayanıyorsa ya da hesaplama kaynaklarınız sınırlıysa BM25 veya TF-IDF gibi seyrek geri getirme yöntemleri daha uygun olabilir. Bu yöntemler daha hızlıdır ve kurulumu kolaydır; ancak tam anahtar kelimeleri içermeyen dokümanları bulamayabilirler.
Yoğun ve seyrek yöntemler arasındaki temel ödünleşim, doğruluk ile hesaplama maliyeti arasındadır. Bazen, her iki yaklaşımı hibrit bir geri getirme sisteminde birleştirmek, doğruluğu hesaplama verimliliği ile dengelemeye yardımcı olabilir. Böylece ihtiyacınıza göre her iki yöntemin faydalarını elde edersiniz.
Hibrit arama, hem yoğun hem de seyrek geri getirme yöntemlerinin güçlü yönlerini birleştirir.
Örneğin, anahtar kelimelere dayalı olarak dokümanları hızlıca bulmak için BM25 gibi bir seyrek yöntemle başlayabilirsiniz. Ardından, BERT gibi bir yoğun yöntem bu dokümanları bağlamlarını ve anlamlarını anlayarak yeniden sıralar. Bu, büyük veri kümeleri ve karmaşık sorgular için harika olan, seyrek aramanın hızını yoğun yöntemlerin doğruluğuyla birleştirir.
Bir vektör veritabanı, yoğun gömüleri yönetmek için harikadır; ancak her zaman gerekli değildir. Alternatifler şunlardır:
Doğru seçim, veri ölçeği ve derin anlamsal anlama gereksinimi gibi spesifik ihtiyaçlarınıza bağlıdır.
Geri getirilen bilginin ilgili ve doğru olduğundan emin olmak için çeşitli yaklaşımlar kullanabilirsiniz:
Uzun dokümanlar veya büyük bilgi tabanlarıyla uğraşırken yararlı bazı teknikler şunlardır:
Bir RAG sisteminden doğruluk ve verimlilik açısından en iyi performansı almak için çeşitli stratejiler kullanabilirsiniz:
Çok turlu konuşmalarda (ör. bir sohbet botu diyaloğu), bir RAG sistemi daha sonraki soruları doğru cevaplayabilmek için önceki turlardan gelen ilgili bağlamı taşımak zorundadır. Bunu başarmak için, RAG her yeni sorguya konuşma geçmişini dahil edebilir:
Sorgu iyileştirme: Sistem, önceki değiş tokuşlardan gelen bilgileri kullanarak kullanıcının sorusunu otomatik olarak yeniden yazabilir veya zenginleştirebilir. Önceki turlardan ayrıntılar eklenerek, geri getirici daha bağlam açısından zengin bir sorgu alır ve devam eden tartışmayla ilgili dokümanları getirebilir.
Konuşma geçmişini dahil etme: Bir başka yaklaşım, modele önceki diyalog turlarının özetini veya listesini girdi bağlamının bir parçası olarak vermektir. Birçok RAG mimarisi, yeni soruyla birlikte bir dizi mesajın (kullanıcı ve asistan geçmişi) iletilmesine izin verir. Böylece geri getirici bilgi ararken yerleşik bağlamı hesaba katar ve üretici geçmişi kullanarak tutarlı bir konuşma sürdürebilir.
Bu yöntemlerle RAG sistemi “kim ne dedi” ve nelerin zaten çözümlendiğini takip eder. Bu da ayrıntıların unutulmasını veya kendini tekrar etmesini önler.
Şimdiye kadar temel ve orta düzey RAG mülakat sorularını ele aldık; şimdi de parçalara ayırma teknikleri veya bağlamsallaştırma gibi daha ileri kavramlara değineceğiz.
Geri getirme ve işleme için dokümanları parçalara ayırmanın birkaç yolu vardır:
Cümleler veya kısa paragraflar gibi daha küçük parçalar, önemli bağlamsal bilginin tek bir vektöre sıkıştırılırken seyrelmesini önlemeye yardımcı olur. Ancak bu, parçalar arası uzun menzilli bağımlılıkların kaybedilmesine yol açabilir; modellerin parçalara yayılan göndermeleri anlamasını zorlaştırır.
Daha büyük parçalar daha fazla bağlamı korur; bu da daha zengin bağlamsal bilgi sağlar; ancak daha az odaklı olabilir ve tüm bilgiyi tek bir vektöre kodlamaya çalışırken bilgi kaybı yaşanabilir.
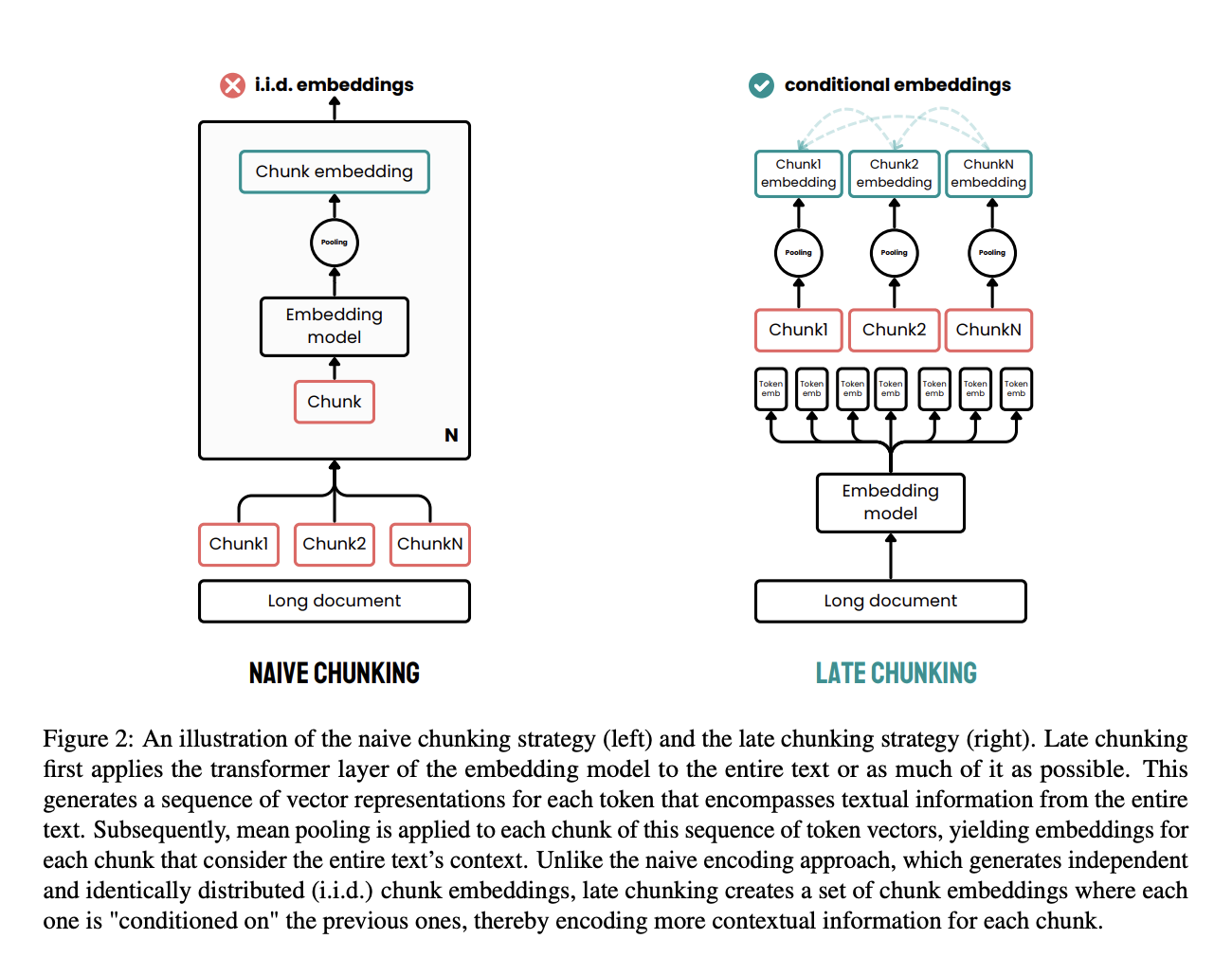
Geç parçalara ayırma, doküman işlemeyle ilgili geleneksel yöntemlerin sınırlamalarını gidermek üzere tasarlanmış etkili bir yaklaşımdır.
Geleneksel yöntemlerde, dokümanlar önce cümleler veya paragraflar gibi parçalara bölünür; ardından bir gömme modeli uygulanır. Bu parçalar, genellikle her parça için tek bir gömme oluşturmak amacıyla ortalama havuzlama kullanılarak ayrı ayrı vektörlere kodlanır. Bu yaklaşım, gömmeler birbirinden bağımsız üretildiği ve tüm doküman bağlamı dikkate alınmadığı için uzun mesafeli bağlamsal bağımlılıkların kaybına neden olabilir.
Geç parçalara ayırma farklı bir yol izler. Önce gömme modelinin dönüştürücü (transformer) katmanı tüm dokümana veya mümkün olduğunca büyük bir kısmına uygulanır ve her belirteç için bir dizi vektör temsili oluşturulur. Bu yöntem, bu belirteç düzeyi gömmelerde metnin tam bağlamını yakalar.
Ardından, bu belirteç vektörleri dizisinin parçalarına ortalama havuzlama uygulanır ve her parça için, tüm dokümanın bağlamından beslenen gömmeler üretilir. Geleneksel yöntemden farklı olarak, geç parçalara ayırma, parçaların birbirine koşullu olduğu gömmeler üretir; bu da daha fazla bağlamsal bilginin korunmasını ve uzun menzilli bağımlılıkların çözülmesini sağlar.
Parçalama işlemini sürecin daha geç bir aşamasına uygulayarak, her parçanın gömüsünün tüm dokümanın sağladığı zengin bağlamdan yararlanmasını sağlar; parçaların yalıtılmış kalmasını önler. Bu yaklaşım, bağlam kaybı sorununu giderir ve geri getirme ile üretim görevlerinde kullanılan gömmelerin kalitesini artırır.
Kaynak: Günther ve diğ., 2024
RAG’de bağlamsallaştırma, geri getirilen bilginin sorguyla ilgili olmasını sağlamaktır. Geri getirilen veriyi sorguyla hizalayarak sistem daha iyi ve daha ilgili yanıtlar üretir.
Bu, hatalı veya ilgisiz sonuç olasılığını azaltır ve çıktının kullanıcının ihtiyaçlarına uygun olmasını sağlar. Bir yaklaşım, Düzeltici RAG (CRAG)’de gösterildiği gibi, üretici modele göndermeden önce geri getirilen dokümanların ilgili olup olmadığını bir LLM ile kontrol etmektir.
Öncelikle, bilgi tabanını taraflı içeriği filtreleyecek şekilde oluşturmak ve bilgilerin mümkün olduğunca nesnel olmasını sağlamak esastır. Ayrıca, dengeli ve önyargısız kaynaklara öncelik verecek şekilde geri getirme sistemini yeniden eğitebilirsiniz.
Bir diğer önemli adım, potansiyel önyargıları kontrol etmek ve model çıktısının nesnel kalmasını sağlamak için özel bir aracıyı devreye almaktır.
Başlıca sorunlardan biri, indekslenmiş veriyi en son bilgilerle güncel tutmaktır; bu da güvenilir bir güncelleme mekanizması gerektirir. Bu nedenle, farklı bilgi sürümlerini yönetmek ve tutarlılığı sağlamak için sürüm kontrolü kritik hale gelir.
Ayrıca, modelin sık sık yeniden eğitime ihtiyaç duymadan, gerçek zamanlı olarak yeni bilgilere uyum sağlayabilmesi gerekir; bu da kaynak yoğun olabilir. Bu zorluklar, bilgi tabanı gelişirken sistemin doğru ve ilgili kalmasını sağlamak için sofistike çözümler gerektirir.
CAG (Cache-Augmented Generation), geri getirilen dokümanların LLM’e iletilmeden önce özetlendiği veya sıkıştırıldığı RAG’in bir evrimidir. Bu, ilgililiği artırır, token kullanımını azaltır ve modelin bağlam penceresine daha fazla bilgi sığdırmaya yardımcı olur.
Temel fark, CAG’de geri getirilen içeriğin üreticiye beslenmeden önce bir özetleyici veya bağlam rafinerisi gibi bir ara adımdan geçmesidir. Buna karşılık, geleneksel RAG ham dokümanları doğrudan prompt’a dahil eder.
CAG özellikle şu durumlarda kullanışlıdır:
Önceden sıkıştırılıp önbelleğe alınabilecek statik veri kümeleriyle (ör. ürün katalogları, akademik makaleler) çalışıyorsanız.
Token verimliliğinin kritik olduğu durumlarda (ör. maliyet duyarlı API’ler veya mobil/cihaz üstü çıkarım).
Geri getirilen dokümanlar uzun veya gürültülüyse ve damıtılmaya ihtiyaç duyuyorsa.
Öte yandan RAG tercih edilir, eğer:
Temel veriler dinamikse veya sık güncelleniyorsa (ör. gerçek zamanlı destek talepleri, canlı dokümantasyon).
Tüm bilgi tabanını yeniden işlemeye gerek kalmadan, sorgu anında en taze bilgiyi dahil etmek istiyorsanız.
Kısacası, bağlamı önceden optimize edebileceğiniz stabil alanlar için CAG, tazelik ve isteğe bağlı geri getirme gerektiren dinamik senaryolar için RAG kullanın.
Daha ayrıntılı bir karşılaştırma için RAG ve CAG hakkındaki bu makaleye göz atın.
Pek çok ileri RAG sistemi vardır.
Bunlardan biri Uyarlanabilir (Adaptive) RAG’dir; sistem, bilgi geri getirmenin yanı sıra sorguya göre yaklaşımını gerçek zamanlı olarak ayarlar. Uyarlanabilir RAG, hiç geri getirmeme, tek atış RAG veya yinelemeli RAG yapmaya karar verebilir. Bu dinamik davranış, RAG sistemini kullanıcının talebine karşı daha sağlam ve ilgili hale getirir.
Bir diğer ileri RAG sistemi Ajanik (Agentic) RAG’dir; bu sistem, bir kaynaktan bilgi çekilip çekilmeyeceğine karar veren geri getirme ajanlarını devreye sokar. Bu yeteneğin bir dil modeline verilmesi, gerekirse modelin kendi kendine ek bilgiye ihtiyaç duyup duymadığını belirlemesini sağlar ve süreci daha akıcı kılar.
Düzeltici RAG (CRAG) de giderek popülerleşiyor. Bu yaklaşımda sistem, geri getirdiği dokümanları gözden geçirip ilgililiğini kontrol eder. Yalnızca ilgili olarak sınıflandırılan dokümanlar üreticiye beslenir. Bu öz-düzeltme adımı, doğru ve ilgili bilginin kullanılmasını sağlamaya yardımcı olur. Daha fazlasını öğrenmek için LangGraph ile Düzeltici RAG (CRAG) Uygulaması başlıklı bu öğreticiyi okuyabilirsiniz.
Self-RAG bunu bir adım daha ileri götürerek yalnızca geri getirilen dokümanları değil, üretilen nihai yanıtları da değerlendirir; her ikisinin de kullanıcının sorgusuyla uyumlu olmasını sağlar. Bu da daha güvenilir ve tutarlı sonuçlara yol açar.
Etkili yaklaşımlardan biri, ilgili ve sıkça istenen bilgileri önceden getirip hazır tutmaktır. Ayrıca, indeksleme ve sorgu algoritmalarınızı iyileştirmek, verilerin ne kadar hızlı geri getirildiği ve işlendiği üzerinde büyük fark yaratabilir.
RAG güçlü olsa da çeşitli sınırlamalar ve zorluklar barındırır:
Geri getirilen veri kalitesine bağımlılık: Bir RAG sistemi, geri getirdiği bilgi kadar iyidir. Geri getirici ilgisiz veya hatalı dokümanlar çekerse, üreticinin yanıtı da olumsuz etkilenir. Çöp girerse çöp çıkar sorunundan kaçınmak için yüksek kaliteli, güvenilir veri kaynaklarını sağlamak (ve geri getiriciyi ince ayar yapmak) sürekli bir meydan okumadır.
Artan karmaşıklık ve gecikme: RAG, üretime ek olarak bir geri getirme adımı daha ekler; bu da sistemi tek başına bir LLM’e kıyasla daha karmaşık ve hesaplama açısından daha ağır hale getirir. Büyük bir bilgi tabanında arama yapmak gecikme ekleyebilir ve önemli hesaplama kaynakları gerektirebilir; bu nedenle RAG sistemleri doğruluk ile verimlilik arasında denge kurmak zorundadır.
Bilgi tabanının bakım gereksinimi: Statik LLM’lerin aksine, RAG düzenli güncelleme ve kürasyon gerektiren harici bir bilgi deposuna bağlıdır. Kuruluşlar sürekli olarak yeni verileri içeri almalı, eski bilgileri kaldırmalı ve indeksleri yönetmelidir. Güvenilir ve güncel veri kaynakları olmadan bir RAG sistemi hızla etkisizleşebilir veya güncel olmayan yanıtlar sağlayabilir.
Entegrasyon ve ayar zorluğu: Geri getirme ve üretimi birleştirmek, ayarlanıp izlenecek daha fazla bileşen (vektör veritabanı, geri getirici model ve LLM) anlamına gelir. Hataları gidermek daha zor olabilir; çünkü sorunlar geri getirme veya üretim tarafından kaynaklanabilir. Bu karmaşıklık, yalnızca bir LLM kullanmaya kıyasla geliştirme ve bakım çabasını artırabilir.
Ayrıca, bir alanın verileri büyük ölçüde statikse ve modelin eğitimiyle kapsanabiliyorsa, RAG yerine ince ayar yapılmış bir LLM de yeterli olabilir. Ancak, ince ayar RAG’in anlık olarak taze bilgiyi dahil etme kabiliyetinden yoksundur ve her bilgi güncellemesi için yeniden eğitmek daha maliyetli olabilir.
Şimdi, AI Mühendisi pozisyonları için mülakat yapanlara yönelik bazı özel soruları ele alalım.
Bu kurslarla AI öğrenin!
Program
Program
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
