
Lernpfad
Entwicklung von KI-Anwendungen
21 Std.
Fangen wir mit ein paar grundlegenden Interviewfragen zu RAG an.
Ein RAG-System (Retrieval-Augmented Generation) hat zwei Hauptkomponenten: den Retriever und den Generator.
Der Retriever sucht und sammelt relevante Infos aus externen Quellen, wie zum Beispiel Datenbanken, Dokumenten oder Websites.
Der Generator, meistens ein fortschrittliches Sprachmodell, nutzt diese Infos, um einen klaren und genauen Text zu erstellen.
Der Retriever sorgt dafür, dass das System die aktuellsten Infos bekommt, während der Generator diese mit seinem eigenen Wissen kombiniert, um bessere Antworten zu liefern.
Zusammen liefern sie genauere Antworten, als der Generator alleine könnte.
Wenn du dich nur auf das eingebaute Wissen eines LLM verlässt, ist das System auf das beschränkt, worauf es trainiert wurde, was veraltet sein oder Details vermissen lassen könnte.
RAG-Systeme haben den großen Vorteil, dass sie neue Infos von externen Quellen holen, was zu genaueren und schnelleren Antworten führt.
Dieser Ansatz reduziert auch „Halluzinationen“ – Fehler, bei denen das Modell Fakten erfindet –, weil die Antworten auf echten Daten basieren. RAG ist besonders nützlich für bestimmte Bereiche wie Recht, Medizinoder Technik, wo man immer auf dem neuesten Stand sein muss.
RAG wird in vielen echten KI-Anwendungen in verschiedenen Bereichen eingesetzt:
Frage-Antwort- und Supportsysteme: RAG macht Chatbots für den Kundensupport und Assistenten für Wissensdatenbanken möglich, indem es aktuelle Infos oder FAQs abruft und genaue Antworten für die Nutzer zusammenstellt. So stellen wir sicher, dass Kundenfragen mit den aktuellsten Infos beantwortet werden (z. B. durch Abrufen der aktuellen Versicherungsdaten oder Produktdetails).
Dialogagenten: Viele Chatbots und virtuelle Assistenten nutzen RAG, um sachliche, kontextbezogene Antworten zu geben. Durch das Abrufen relevanter Fakten in Echtzeit kann ein Gesprächsagent (wie ein Chatbot im Gesundheits- oder Finanzbereich) fundierte Antworten geben, die auf glaubwürdigen Quellen basieren.
Erstellung und Zusammenfassung von Inhalten: RAG hilft dabei, Inhalte mit korrekten Fakten zu erstellen oder zusammenzufassen. Zum Beispiel kann es Teile von Nachrichtenartikeln oder Forschungsarbeiten abrufen und dann Zusammenfassungen oder Berichte erstellen, die sowohl zusammenhängend sind als auch anhand der Quelldaten auf ihre Richtigkeit überprüft wurden.
Forschung in bestimmten Bereichen: In Fachgebieten wie Jura oder Medizin helfen RAG-Systeme, indem sie aus speziellen Datenbanken (Rechtsprechung, medizinische Fachzeitschriften usw.) ziehen, um komplizierte Fragen zu beantworten. So basiert das Ergebnis des Modells auf zuverlässigem, aktuellem Fachwissen, was für professionelle Anwendungen echt wichtig ist.
RAG-Systeme können Infos aus strukturierten und unstrukturierten externen Quellen sammeln:
Dank dieser Flexibilität können RAG-Systeme auf verschiedene Bereiche wie den rechtlichen oder medizinischen Einsatz zugeschnitten werden, indem sie auf Datenbanken mit Präzedenzfällen, Forschungszeitschriften oder Daten aus klinischen Studien zugreifen.
Prompt Engineering hilft Sprachmodellen dabei, mit den gefundenen Infos echt gute Antworten zu geben. Wie du eine Eingabeaufforderung gestaltest, kann die Relevanz und Klarheit der Ausgabe beeinflussen.
In einem RAG-System sammelt der Retriever relevante Infos aus externen Quellen, die der Generator dann nutzen kann. Es gibt verschiedene Möglichkeiten, Infos zu finden.
Eine Methode ist das Sparse Retrieval, das Schlüsselwörter abgleicht (z. B. TF-IDF oder BM25). Das ist zwar einfach, gibt aber vielleicht nicht die tiefere Bedeutung der Worte wieder.
Ein anderer Ansatz ist das Dense Retrieval, das neuronale Einbettungen nutzt, um die Bedeutung von Dokumenten und Suchanfragen zu verstehen. Methoden wie BERT oder Dense Passage Retrieval (DPR) zeigen Dokumente als Vektoren in einem gemeinsamen Raum, was das Auffinden genauer macht.
Die Wahl zwischen diesen Methoden kann echt einen großen Einfluss darauf haben, wie gut das RAG-System funktioniert.
Die Kombination von gefundenen Infos mit der Generierung durch ein LLM bringt ein paar Herausforderungen mit sich. Zum Beispiel müssen die gefundenen Daten echt relevant für die Anfrage sein, weil irrelevante Daten das Modell verwirren und die Qualität der Antwort beeinträchtigen können.
Außerdem kann es zu verwirrenden oder falschen Antworten kommen, wenn die gefundenen Infos nicht mit dem, was das Modell schon weiß, übereinstimmen. Deshalb ist es echt wichtig, diese Konflikte zu lösen, ohne die Nutzer zu verwirren.
Schließlich können Stil und Format der abgerufenen Daten nicht immer mit der üblichen Schreibweise oder Formatierung des Modells übereinstimmen, was es für das Modell schwierig macht, die Informationen reibungslos zu integrieren.
In einem RAG-System ist eine Vektordatenbank dabei, dichte Einbettungen von Text. Diese Einbettungen sind numerische Darstellungen, die die Bedeutung von Wörtern und Phrasen erfassen und von Modellen wie BERT oder OpenAI erstellt werden.
Wenn eine Anfrage kommt, wird ihre Einbettung mit den in der Datenbank gespeicherten verglichen, um ähnliche Dokumente zu finden. Dadurch kann man die richtigen Infos schneller und genauer finden. Dieser Prozess hilft dem System, die relevantesten Infos schnell zu finden und abzurufen, was sowohl die Geschwindigkeit als auch die Genauigkeit der Suche verbessert.
Um ein RAG-System zu bewerten, musst du sowohl die Abruf- als auch die Generierungskomponenten anschauen.
Für nachgelagerte Aufgaben wie das Beantworten von Fragen sind Metriken wie F1-Score, Präzisionund Recall können auch zur Bewertung des gesamten RAG-Systems verwendet werden.
Um mit unklaren oder unvollständigen Suchanfragen in einem RAG-System klarzukommen, braucht man Strategien, die sicherstellen, dass trotz der unklaren Eingabe des Nutzers relevante und genaue Infos gefunden werden.
Ein Ansatz ist, Techniken zur Verfeinerung von Suchanfragen zu nutzen, bei denen das System automatisch Klarstellungen vorschlägt oder die unklare Anfrage anhand bekannter Muster oder früherer Interaktionen präziser formuliert. Das kann bedeuten, dass man Folgefragen stellt oder dem Nutzer mehrere Optionen anbietet, um seine Absicht genauer zu bestimmen.
Eine andere Möglichkeit ist, verschiedene Dokumente zu finden, die mehrere mögliche Interpretationen der Suchanfrage abdecken. Durch das Abrufen einer Reihe von Ergebnissen stellt das System sicher, dass selbst bei einer vagen Suchanfrage wahrscheinlich einige relevante Informationen enthalten sind.
Schließlich können wir Modelle zum Verständnis natürlicher Sprache (NLU) Modelle, um die Absicht des Benutzers aus unvollständigen Suchanfragen zu ermitteln und den Suchvorgang zu verfeinern.
Nachdem wir jetzt ein paar grundlegende Fragen geklärt haben, ist es Zeit, zu den mittleren RAG-Interviewfragen überzugehen.
Die Wahl des richtigen Retrievers hängt davon ab, mit welcher Art von Daten du arbeitest, wie die Abfragen aussehen und wie viel Rechenleistung du hast.
Für komplizierte Suchanfragen, die ein tiefes Verständnis der Bedeutung hinter den Wörtern erfordern, sind Methoden wie BERT oder DPR besser geeignet. Diese Methoden erfassen den Kontext und sind super für Aufgaben wie Kundensupport oder Forschung, wo es wichtig ist, die zugrunde liegenden Bedeutungen zu verstehen.
Wenn die Aufgabe einfacher ist und sich um die Übereinstimmung von Schlüsselwörtern dreht oder wenn du nur begrenzte Rechenressourcen hast, könnten spärliche Suchmethoden wie BM25 oder TF-IDF besser passen. Diese Methoden sind schneller und einfacher einzurichten, finden aber möglicherweise keine Dokumente, die nicht genau den Suchbegriffen entsprechen.
Der Hauptkompromiss zwischen dichten und spärlichen Suchmethoden ist die Genauigkeit gegenüber den Rechenkosten. Manchmal kann es helfen, beide Ansätze in einem hybriden Abrufsystem zu kombinieren, um Genauigkeit und Rechenleistung unter einen Hut zu bringen. Recheneffizienzauszugleichen. So kannst du je nach Bedarf die Vorteile sowohl der dichten als auch der spärlichen Methode nutzen.
Die hybride Suche bringt die Vorteile von dichten und spärlichen Suchmethoden zusammen.
Du kannst zum Beispiel mit einer spärlichen Methode wie BM25 anfangen, um Dokumente anhand von Stichwörtern schnell zu finden. Dann wird eine komplexe Methode wie BERT die Dokumente neu sortiert diese Dokumente neu, indem sie den Kontext und die Bedeutung versteht. Damit kriegst du die Geschwindigkeit einer spärlichen Suche mit der Genauigkeit dichter Methoden, was super für komplexe Abfragen und große Datensätze ist.
Eine Vektordatenbank ist super, um dichte Einbettungen zu verwalten, aber sie ist nicht immer nötig. Alternativen sind:
Die richtige Wahl hängt von deinen spezifischen Anforderungen ab, wie zum Beispiel dem Umfang deiner Daten und ob du ein tiefes semantisches Verständnis brauchst.
Um sicherzugehen, dass die gefundenen Infos relevant und richtig sind, kannst du verschiedene Methoden anwenden:
Hier sind ein paar nützliche Tipps für den Umgang mit langen Dokumenten oder großen Wissensdatenbanken:
Um die beste Leistung eines RAG-Systems in Sachen Genauigkeit und Effizienz zu kriegen, kannst du verschiedene Strategien anwenden:
Bei Gesprächen mit mehreren Runden (z. B. einem Chatbot-Dialog) muss ein RAG-System den relevanten Kontext aus früheren Runden übernehmen, um spätere Fragen richtig beantworten zu können. Um das zu schaffen, kann RAG den Gesprächsverlauf in jede neue Anfrage einbauen:
Verfeinerung der Suchanfrage: Das System kann die Frage des Benutzers automatisch umschreiben oder ergänzen, indem es Infos aus früheren Unterhaltungen nutzt. Durch das Hinzufügen von Details aus früheren Runden bekommt der Retriever eine kontextreichere Anfrage, sodass er Dokumente finden kann, die für die aktuelle Diskussion relevant sind.
Einschließlich Gesprächsverlauf: Ein anderer Ansatz ist, dem Modell eine Zusammenfassung oder Liste der vorherigen Dialogrunden als Teil seines Eingabekontexts zu geben. Viele RAG-Architekturen können eine Reihe von Nachrichten (Benutzer- und Assistentengeschichte) zusammen mit der neuen Frage weiterleiten. So berücksichtigt der Retriever bei der Suche nach Infos den festgelegten Kontext, und der Generator kann den bisherigen Kontext nutzen, um ein zusammenhängendes Gespräch zu führen.
Mit diesen Methoden behält das RAG-System den Überblick darüber, wer was gesagt hat und was schon geklärt ist. So wird verhindert, dass es Details vergisst oder sich wiederholt.
Bis jetzt haben wir grundlegende und mittelschwere RAG-Interviewfragen behandelt, und jetzt werden wir uns mit fortgeschritteneren Konzepten wie Chunking-Techniken oder Kontextualisierung beschäftigen.
Es gibt verschiedene Möglichkeiten, Dokumente für die Suche und Verarbeitung zu zerlegen:
Kleinere Teile, wie Sätze oder kurze Absätze, helfen dabei, dass wichtige Infos im Kontext nicht verloren gehen, wenn sie zu einem einzigen Vektor zusammengefasst werden. Das kann aber dazu führen, dass man langfristige Abhängigkeiten zwischen den Blöcken verliert, was es für Modelle schwierig macht, Referenzen zu verstehen, die sich über mehrere Blöcke erstrecken.
Größere Teile behalten mehr Kontext, was reichhaltigere Kontextinfos ermöglicht, aber weniger fokussiert sein kann und Infos verloren gehen können, wenn man versucht, alle Infos in einen einzigen Vektor zu packen.
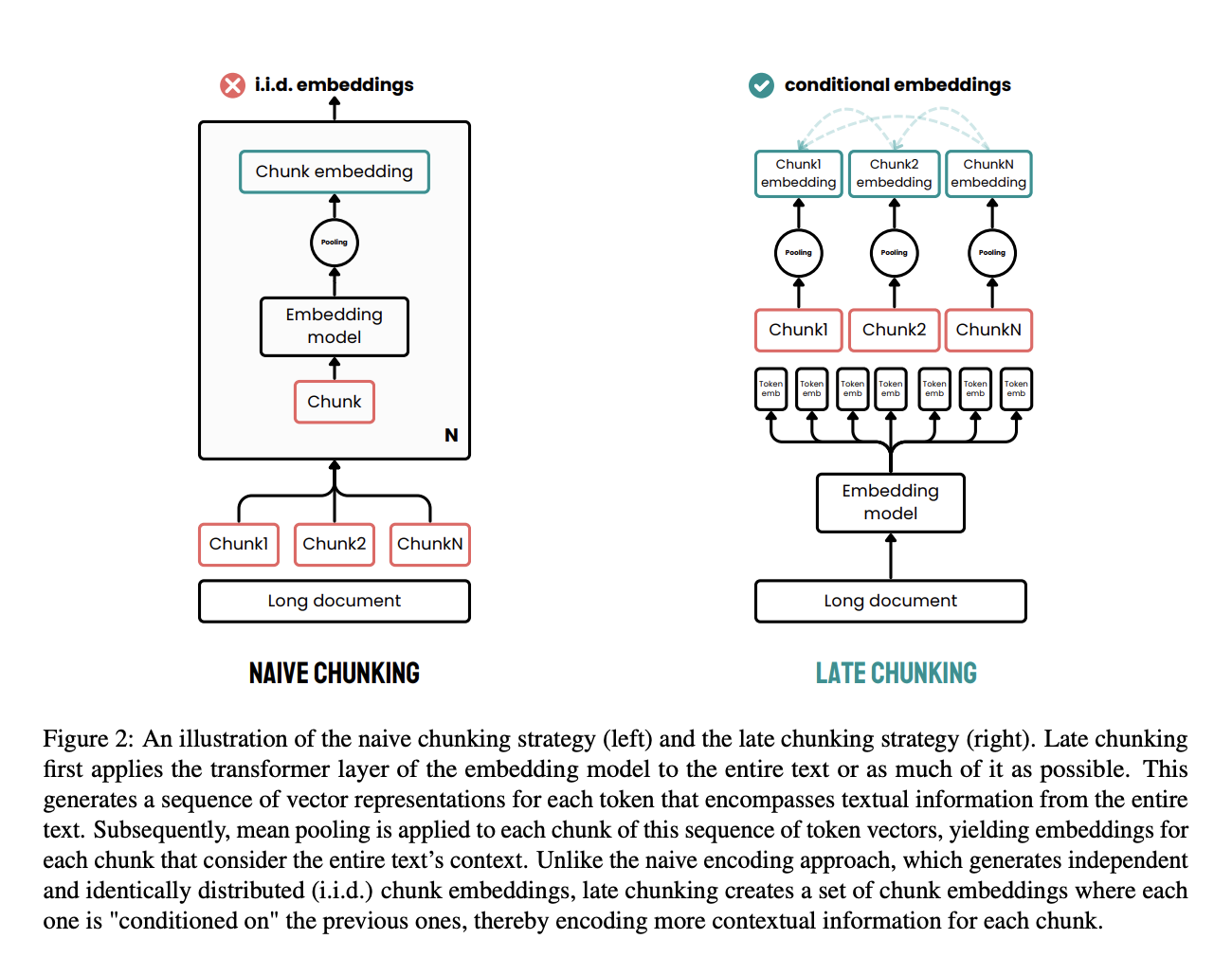
Spätes Chunking ist ein cooler Ansatz, der entwickelt wurde, um die Einschränkungen traditioneller Chunking-Methoden bei der Dokumentverarbeitung zu umgehen.
Bei den klassischen Methoden werden Dokumente erst in Teile wie Sätze oder Absätze aufgeteilt, bevor man ein Einbettungsmodell anwendet. Diese Teile werden dann einzeln in Vektoren umgewandelt, oft mit Hilfe von Mean Pooling, um für jedes Teil eine einzige Einbettung zu erstellen. Dieser Ansatz kann dazu führen, dass kontextuelle Abhängigkeiten über große Entfernungen verloren gehen, weil die Einbettungen unabhängig voneinander generiert werden, ohne den gesamten Dokumentkontext zu berücksichtigen.
Late Chunking geht anders ran. Zuerst wird die Transformatorschicht des Einbettungsmodells auf das ganze Dokument oder so viel wie möglich davon angewendet, wodurch eine Folge von Vektordarstellungen für jedes Token erstellt wird. Diese Methode fängt den ganzen Kontext des Textes in diesen Einbettungen auf Token-Ebene ein.
Danach wird ein Mittelwertpooling auf die Teile dieser Folge von Token-Vektoren angewendet, wodurch für jeden Teil Einbettungen erzeugt werden, die durch den Kontext des gesamten Dokuments beeinflusst werden. Anders als bei der herkömmlichen Methode erzeugt Late Chunking Chunk-Einbettungen, die voneinander abhängig sind, wodurch mehr Kontextinformationen erhalten bleiben und weitreichende Abhängigkeiten aufgelöst werden.
Wenn man das Chunking später im Prozess macht, stellt man sicher, dass jedes Chunk von dem ganzen Kontext des Dokuments profitiert und nicht isoliert ist. Dieser Ansatz löst das Problem des verlorenen Kontexts und verbessert die Qualität der Einbettungen, die für Such- und Generierungsaufgaben verwendet werden.
Quelle: Günther et al., 2024
Bei der Kontextualisierung in RAG geht's darum, sicherzustellen, dass die gefundenen Infos für die Anfrage relevant sind. Indem die abgerufenen Daten mit der Abfrage abgeglichen werden, liefert das System bessere und relevantere Antworten.
Das verringert die Wahrscheinlichkeit von falschen oder irrelevanten Ergebnissen und stellt sicher, dass die Ausgabe den Bedürfnissen des Benutzers entspricht. Ein Ansatz besteht darin, mit einem LLM zu checken, ob die gefundenen Dokumente relevant sind, bevor sie an das Generator-Modell geschickt werden, wie bei Corrective RAG (CRAG).
Zuerst muss man die Wissensdatenbank so aufbauen, dass voreingenommene Inhalte rausgefiltert werden, damit die Infos so objektiv wie möglich sind. Du kannst das Suchsystem auch so umprogrammieren, dass es ausgewogene, unvoreingenommene Quellen bevorzugt.
Ein weiterer wichtiger Schritt könnte sein, einen Agenten einzusetzen, der speziell nach möglichen Verzerrungen sucht und sicherstellt, dass die Ergebnisse des Modells objektiv bleiben.
Ein großes Problem ist, die indizierten Daten mit den neuesten Infos auf dem Laufenden zu halten, was einen zuverlässigen Aktualisierungsmechanismus braucht. Deshalb ist die Versionskontrolle echt wichtig, um verschiedene Versionen von Infos zu verwalten und dafür zu sorgen, dass alles einheitlich bleibt.
Außerdem muss das Modell in Echtzeit auf neue Infos reagieren können, ohne dass man es ständig neu trainieren muss, was echt ressourcenintensiv sein kann. Diese Herausforderungen brauchen ausgeklügelte Lösungen, damit das System auch bei Weiterentwicklungen der Wissensdatenbank genau und relevant bleibt.
CAG (Cache-Augmented Generation) ist eine Weiterentwicklung von RAG, bei der die gefundenen Dokumente zusammengefasst oder komprimiert werden, bevor sie an das LLM weitergeleitet werden. Das macht die Sachen relevanter, braucht weniger Token und sorgt dafür, dass mehr Infos ins Kontextfenster des Modells passen.
Der Hauptunterschied ist, dass bei CAG der gefundene Inhalt erst mal einen Zwischenschritt macht, wie zum Beispiel einen Summarizer oder einen Context Refiner, bevor er an den Generator weitergeleitet wird. Im Gegensatz dazu gibt traditionelles RAG die Rohdokumente direkt in die Eingabeaufforderung weiter.
CAG ist besonders nützlich, wenn:
Du arbeitest mit statischen Datensätzen (z. B. Produktkatalogen, wissenschaftlichen Arbeiten), die vorab komprimiert und zwischengespeichert werden können.
Die Effizienz der Token ist echt wichtig (z. B. bei kostensensiblen APIs oder mobilen/geräteinternen Inferenzprozessen).
Die gefundenen Dokumente sind lang oder unübersichtlich und müssen gekürzt werden.
RAG ist dagegen besser, wenn:
Die zugrunde liegenden Daten sind dynamisch oder werden oft aktualisiert (z. B. Support-Tickets in Echtzeit, Live-Dokumentation).
Du willst die aktuellsten Infos bei der Abfrage nutzen, ohne die ganze Wissensdatenbank neu zu verarbeiten.
Kurz gesagt: Nutze CAG für stabile Bereiche, wo du den Kontext im Voraus optimieren kannst, und RAG für dynamische Szenarien, wo Aktualität und Abrufbarkeit auf Abruf wichtiger sind.
Schau dir diesen Artikel über RAG versus CAG an, um einen genaueren Vergleich zu kriegen.
Es gibt viele moderne RAG-Systeme.
Ein solches System ist das Adaptive RAG-, bei dem das System nicht nur Infos abruft, sondern auch seine Vorgehensweise in Echtzeit basierend auf der Anfrage anpasst. Das adaptive RAG kann entscheiden, ob es gar nichts abruft, einen einmaligen RAG oder einen iterativen RAG macht. Dieses dynamische Verhalten macht das RAG-System robuster und relevanter für die Anfrage des Benutzers.
Ein weiteres fortschrittliches RAG-System ist Agentic RAG, das Retrieval Agents einführt – also Tools, die entscheiden, ob Infos aus einer Quelle geholt werden sollen oder nicht. Wenn man einem Sprachmodell diese Fähigkeit gibt, kann es selbst entscheiden, ob es zusätzliche Infos braucht, was den Prozess reibungsloser macht.
Korrektive RAG (CRAG) wird auch immer beliebter. Bei diesem Ansatz schaut das System die gefundenen Dokumente an und prüft, ob sie relevant sind. Nur Dokumente, die als relevant eingestuft werden, werden in den Generator eingespeist. Dieser Schritt zur Selbstkorrektur hilft dabei, dass genaue und relevante Infos verwendet werden. Mehr Infos findest du in diesem Tutorial zum Thema Implementierung von Corrective RAG (CRAG) mit LangGraph.
Self-RAG geht noch einen Schritt weiter, indem es nicht nur die gefundenen Dokumente, sondern auch die generierten Antworten checkt und sicherstellt, dass beides mit der Anfrage des Nutzers übereinstimmt. Das sorgt für zuverlässigere und einheitlichere Ergebnisse.
Ein guter Trick ist, wichtige und oft nachgefragte Infos schon vorher zu laden, damit sie bereitstehen, wenn man sie braucht. Außerdem kann es echt einen Unterschied machen, wie schnell Daten abgerufen und verarbeitet werden, wenn du deine Indizierungs- und Abfragealgorithmen optimierst.
RAG ist zwar leistungsstark, hat aber ein paar Einschränkungen und Herausforderungen:
Abhängigkeit von der Qualität der abgerufenen Daten: Ein RAG-System ist nur so gut wie die Infos, die es findet. Wenn der Retriever irrelevante oder falsche Dokumente findet, wird die Antwort des Generators darunter leiden. Die Sicherstellung hochwertiger, vertrauenswürdiger Datenquellen (und die Feinabstimmung des Retrievers) ist eine ständige Herausforderung, um Probleme mit fehlerhaften Eingaben und fehlerhaften Ausgaben zu vermeiden.
Mehr Komplexität und Verzögerung: RAG fügt nach der Generierung noch einen zusätzlichen Abrufschritt ein, was das ganze System komplexer und rechenintensiver macht als ein eigenständiges LLM. Das Durchsuchen einer großen Wissensdatenbank kann zu Verzögerungen führen und viel Rechenleistung brauchen, deshalb müssen RAG-Systeme Genauigkeit und Effizienz gut ausbalancieren.
Notwendigkeit der Pflege der Wissensdatenbank: Anders als statische LLMs braucht RAG ein externes Wissensrepository, das regelmäßig aktualisiert und gepflegt werden muss. Unternehmen müssen ständig neue Daten einlesen, alte Infos löschen und Indizes verwalten. Ohne zuverlässige und aktuelle Datenquellen kann ein RAG-System schnell an Effektivität verlieren oder sogar veraltete Antworten liefern.
Schwierigkeiten bei der Integration und Abstimmung: Die Kombination von Abruf und Generierung bedeutet, dass mehr Komponenten abgestimmt und überwacht werden müssen (die Vektordatenbank, das Abrufmodell und das LLM). Fehler zu beheben kann schwieriger sein, weil die Probleme sowohl beim Abrufen als auch beim Erstellen auftreten können. Diese Komplexität kann den Entwicklungs- und Wartungsaufwand im Vergleich zur alleinigen Verwendung eines LLM erhöhen.
Es ist auch zu beachten, dass, wenn die Daten einer Domain weitgehend statisch sind und zum Training des Modells passen, ein fein abgestimmtes LLM anstelle von RAG ausreichend sein könnte. Allerdings fehlt bei der Feinabstimmung die Fähigkeit von RAG, neue Infos spontan einzubauen, und es kann teurer sein, das System bei jeder Wissensaktualisierung neu zu trainieren.
Jetzt wollen wir uns ein paar Fragen anschauen, die speziell für Leute gedacht sind, die sich für Stellen als KI-Ingenieur bewerben.
Lerne KI mit diesen Kursen!
Lernpfad
Lernpfad
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nisha Arya Ahmed
15 Min.
Blog
Blog
Matt Crabtree
14 Min.