
Leerpad
AI-toepassingen ontwikkelen
21 Hr
Laten we beginnen met een reeks fundamentele sollicitatievragen over RAG.
Een RAG-systeem (retrieval-augmented generation) heeft twee hoofdcomponenten: de retriever en de generator.
De retriever zoekt en verzamelt relevante informatie uit externe bronnen, zoals databases, documenten of websites.
De generator, meestal een geavanceerd taalmodel, gebruikt deze informatie om heldere en nauwkeurige tekst te maken.
De retriever zorgt dat het systeem de meest actuele informatie krijgt, terwijl de generator dit combineert met eigen kennis om betere antwoorden te produceren.
Samen leveren ze nauwkeurigere reacties dan de generator alleen zou kunnen.
Als je alleen vertrouwt op de ingebouwde kennis van een LLM, is het systeem beperkt tot waar het op getraind is, wat verouderd kan zijn of detail kan missen.
RAG-systemen bieden een groot voordeel door actuele informatie uit externe bronnen op te halen, wat leidt tot accuratere en tijdigere antwoorden.
Deze aanpak vermindert ook "hallucinaties"—fouten waarbij het model feiten verzint—omdat de antwoorden op echte data zijn gebaseerd. RAG is vooral nuttig voor specifieke domeinen zoals recht, geneeskunde of tech, waar actuele, gespecialiseerde kennis nodig is.
RAG wordt gebruikt in allerlei AI-toepassingen in de praktijk, in verschillende domeinen:
Vraag-en-antwoord- en supportsystemen: RAG drijft klantenservice-chatbots en knowledgebase-assistenten door actuele documentatie of FAQ’s op te halen en nauwkeurige antwoorden voor gebruikers te genereren. Zo worden vragen van klanten beantwoord met de nieuwste informatie (bijvoorbeeld actuele beleidsinfo of productdetails).
Conversatie-agents: Veel chatbots en virtuele assistenten gebruiken RAG om feitelijke, contextbewuste antwoorden te geven. Door ter plekke relevante feiten op te halen kan een conversational agent (zoals een zorg- of finance-chatbot) onderbouwde antwoorden geven op basis van geloofwaardige bronnen.
Contentgeneratie en samenvatten: RAG helpt bij het genereren of samenvatten van content met feitelijke juistheid. Het kan bijvoorbeeld delen van nieuwsartikelen of researchpapers ophalen en vervolgens samenvattingen of rapporten produceren die zowel coherent zijn als geverifieerd tegen brondata.
Domeinspecifiek onderzoek: In gespecialiseerde velden zoals recht of geneeskunde helpen RAG-systemen door te putten uit domeinspecifieke databases (jurisprudentie, medische tijdschriften, enz.) om complexe vragen te beantwoorden. Zo is de output van het model verankerd in betrouwbare, actuele domeinkennis, wat belangrijk is voor professionele use-cases.
RAG-systemen kunnen informatie verzamelen uit zowel gestructureerde als ongestructureerde externe bronnen:
Deze flexibiliteit maakt het mogelijk RAG-systemen af te stemmen op verschillende vakgebieden, zoals juridisch of medisch gebruik, door te putten uit jurisprudentiedatabases, researchjournals of data van klinische trials.
Prompt engineering helpt taalmodellen om met de opgehaalde informatie antwoorden van hoge kwaliteit te geven. Hoe je een prompt ontwerpt, kan de relevantie en helderheid van de output beïnvloeden.
In een RAG-systeem verzamelt de retriever relevante informatie uit externe bronnen die de generator kan gebruiken. Er zijn verschillende manieren om informatie op te halen.
Eén methode is sparse retrieval, die zoekt op trefwoorden (bijv. TF-IDF of BM25). Dit is eenvoudig, maar vangt mogelijk niet de diepere betekenis achter de woorden.
Een andere benadering is dense retrieval, waarbij neurale embeddings worden gebruikt om de betekenis van documenten en queries te begrijpen. Methoden zoals BERT of Dense Passage Retrieval (DPR) representeren documenten als vectoren in een gedeelde ruimte, wat de retrieval nauwkeuriger maakt.
De keuze tussen deze methoden kan de prestaties van het RAG-systeem sterk beïnvloeden.
Het combineren van opgehaalde informatie met de generatie van een LLM brengt uitdagingen met zich mee. Zo moet de opgehaalde data zeer relevant zijn voor de query, omdat irrelevante data het model kan verwarren en de kwaliteit van het antwoord kan verminderen.
Bovendien kan het, als de opgehaalde informatie botst met de interne kennis van het model, tot verwarrende of onnauwkeurige antwoorden leiden. Het is daarom cruciaal om deze conflicten op te lossen zonder de gebruiker te verwarren.
Ten slotte sluit de stijl en het formaat van opgehaalde data niet altijd aan bij de gebruikelijke schrijfstijl of opmaak van het model, waardoor integratie stroever kan verlopen.
In een RAG-systeem helpt een vector database om dichte embeddings van tekst te beheren en op te slaan. Deze embeddings zijn numerieke representaties die de betekenis van woorden en zinnen vastleggen, gemaakt door modellen zoals BERT of OpenAI.
Wanneer een query wordt uitgevoerd, wordt de embedding daarvan vergeleken met de opgeslagen embeddings in de database om vergelijkbare documenten te vinden. Dit maakt het sneller en nauwkeuriger om de juiste informatie op te halen. Dit proces helpt het systeem om snel de meest relevante informatie te vinden en op te halen, wat zowel de snelheid als de nauwkeurigheid van retrieval verbetert.
Om een RAG-systeem te evalueren, moet je zowel de retrieval- als de generatiecomponent bekijken.
Voor downstream-taken zoals vraag-en-antwoord kunnen metrieken zoals F1-score, precision en recall ook worden gebruikt om het totale RAG-systeem te evalueren.
Omgaan met onduidelijke of onvolledige queries in een RAG-systeem vereist strategieën om ervoor te zorgen dat, ondanks de onduidelijkheid in de invoer van de gebruiker, relevante en nauwkeurige informatie wordt opgehaald.
Een aanpak is het implementeren van queryverfijningstechnieken, waarbij het systeem automatisch verduidelijkingen suggereert of de onduidelijke query op basis van bekende patronen of eerdere interacties herformuleert tot een preciezere. Dit kan inhouden dat vervolgvragen worden gesteld of dat de gebruiker meerdere opties krijgt om zijn intentie te verfijnen.
Een andere methode is om een diverse set documenten op te halen die meerdere mogelijke interpretaties van de query dekken. Door een spreiding aan resultaten op te halen, is de kans groter dat er, zelfs bij een vage query, relevante informatie tussen zit.
Tot slot kunnen we natural language understanding (NLU)-modellen gebruiken om de intentie van de gebruiker te achterhalen uit onvolledige queries en zo het retrievalproces te verfijnen.
Nu we een paar basisvragen hebben behandeld, is het tijd voor intermediaire RAG-sollicitatievragen.
De juiste retriever kiezen hangt af van het type data waarmee je werkt, de aard van de queries en hoeveel rekenkracht je hebt.
Voor complexe queries die een diep begrip van de betekenis achter woorden vereisen, zijn dense retrieval-methoden zoals BERT of DPR beter. Deze methoden vatten context en zijn ideaal voor taken zoals klantenondersteuning of onderzoek, waar begrip van onderliggende betekenissen telt.
Als de taak simpeler is en draait om trefwoordmatching, of als je beperkte middelen hebt, zijn sparse retrieval-methoden zoals BM25 of TF-IDF geschikter. Deze zijn sneller en eenvoudiger op te zetten, maar vinden mogelijk geen documenten die niet exact op trefwoorden matchen.
De belangrijkste trade-off tussen dense en sparse retrieval is nauwkeurigheid versus rekenkosten. Soms kan het combineren van beide in een hybride retrievalsysteem helpen om nauwkeurigheid te balanceren met reken-efficiëntie. Zo profiteer je van beide methoden, afhankelijk van je behoeften.
Hybride zoeken combineert de sterke punten van zowel dense als sparse retrievalmethoden.
Je kunt bijvoorbeeld beginnen met een sparse methode zoals BM25 om snel documenten op trefwoorden te vinden. Vervolgens herordent een dense methode zoals BERT die documenten op basis van context en betekenis. Dit geeft je de snelheid van sparse search met de nauwkeurigheid van dense methoden, ideaal voor complexe queries en grote datasets.
Een vector database is geweldig voor het beheren van dichte embeddings, maar is niet altijd noodzakelijk. Alternatieven zijn:
De juiste keuze hangt af van je specifieke behoeften, zoals de schaal van je data en of je diepe semantische begrip nodig hebt.
Om te zorgen dat de opgehaalde informatie relevant en accuraat is, kun je verschillende aanpakken gebruiken:
Bij lange documenten of grote knowledgebases zijn dit nuttige technieken:
Om een RAG-systeem optimaal te laten presteren qua nauwkeurigheid en efficiëntie kun je verschillende strategieën gebruiken:
In meerstapsgesprekken (bijv. een chatbotdialoog) moet een RAG-systeem relevante context uit eerdere beurten meenemen om latere vragen correct te beantwoorden. Om dit te bereiken kan RAG de gespreksgeschiedenis in elke nieuwe query opnemen:
Queryverfijning: Het systeem kan de vraag van de gebruiker automatisch herschrijven of aanvullen met informatie uit eerdere uitwisselingen. Door details uit eerdere beurten toe te voegen, krijgt de retriever een contextrijkere query en kan hij documenten ophalen die relevant zijn voor het lopende gesprek.
Gespreksgeschiedenis opnemen: Een andere aanpak is om het model een samenvatting of lijst met eerdere dialoogbeurten als inputcontext te geven. Veel RAG-architecturen laten toe om een reeks berichten (gebruikers- en assistentgeschiedenis) mee te geven naast de nieuwe vraag. Zo houdt de retriever bij het zoeken rekening met de gevestigde context, en kan de generator de eerdere context gebruiken om het gesprek coherent te houden.
Met deze methoden houdt het RAG-systeem bij “wie wat zei” en wat al is afgehandeld. Zo voorkomt het dat details worden vergeten of dat het zichzelf herhaalt.
Tot nu toe hebben we basis- en intermediaire RAG-vragen behandeld; nu pakken we geavanceerdere concepten aan zoals chunkingtechnieken of contextualisering.
Er zijn meerdere manieren om documenten op te delen voor retrieval en verwerking:
Kleinere chunks, zoals zinnen of korte alinea’s, voorkomen dat belangrijke context verdund raakt wanneer deze in één vector wordt gecomprimeerd. Dit kan echter leiden tot verlies van langetermijnafhankelijkheden tussen chunks, waardoor modellen verwijzingen over chunks heen minder goed begrijpen.
Grotere chunks behouden meer context, waardoor rijkere contextinformatie mogelijk is, maar ze kunnen minder gefocust zijn en er kan informatie verloren gaan bij het encoden in één vector.
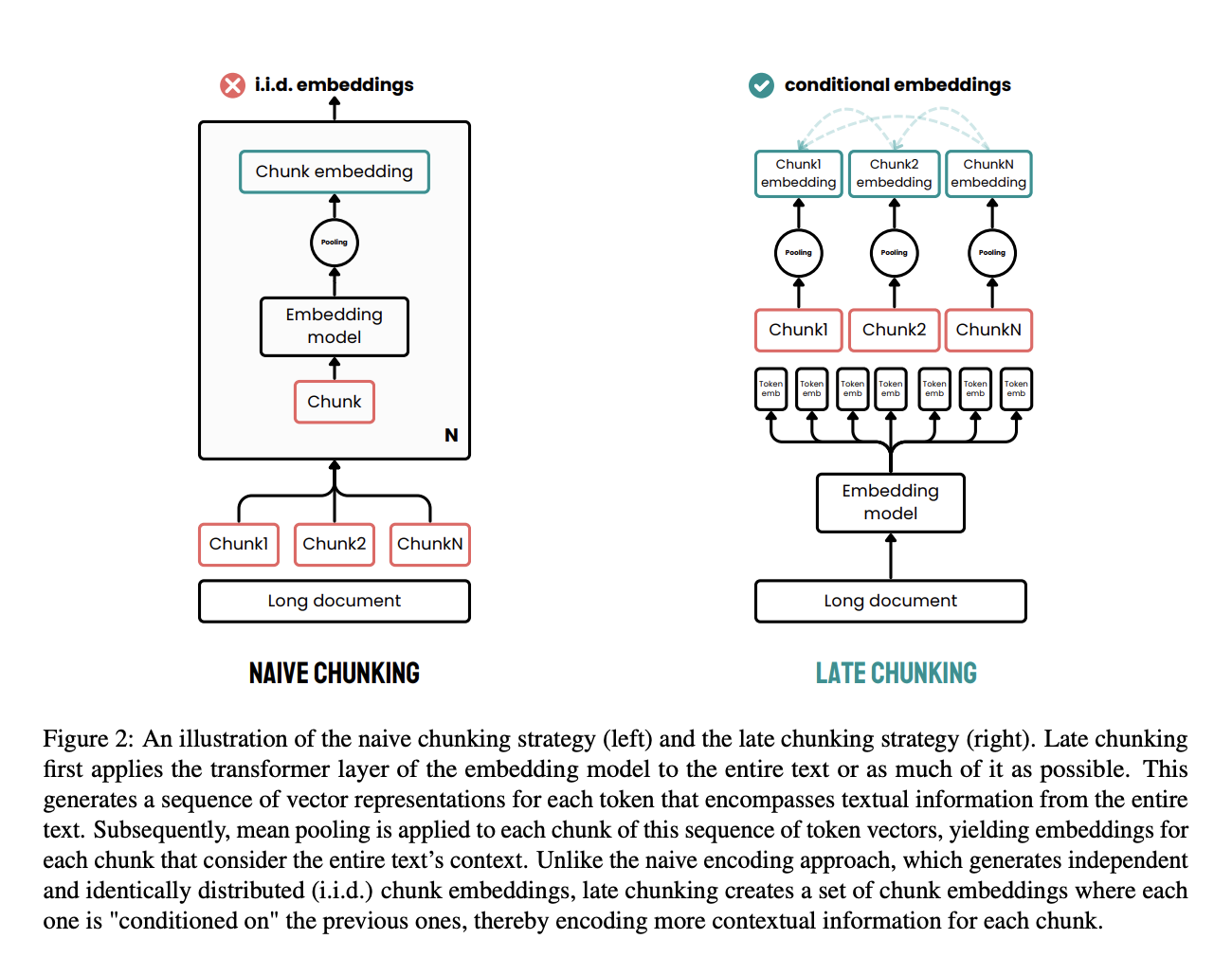
Late chunking is een effectieve aanpak die is ontworpen om de beperkingen van traditionele chunkmethoden bij documentverwerking aan te pakken.
Bij traditionele methoden worden documenten eerst in chunks gesplitst, zoals zinnen of alinea’s, voordat een embeddingmodel wordt toegepast. Deze chunks worden vervolgens afzonderlijk gecodeerd in vectoren, vaak met mean pooling om één embedding per chunk te maken. Deze aanpak kan leiden tot verlies van langetermijncontextuele afhankelijkheden, omdat de embeddings onafhankelijk van elkaar worden gegenereerd, zonder rekening te houden met de volledige documentcontext.
Late chunking pakt het anders aan. Het past eerst de transformerlaag van het embeddingmodel toe op het hele document, of zoveel mogelijk daarvan, en creëert zo een reeks vectorrepresentaties voor elk token. Deze methode vangt de volledige context van de tekst in deze token-level embeddings.
Daarna wordt mean pooling toegepast op de chunks van deze reeks tokenvectoren, waardoor embeddings voor elke chunk ontstaan die zijn geïnformeerd door de context van het hele document. In tegenstelling tot de traditionele methode genereert late chunking chunk-embeddings die op elkaar zijn geconditioneerd, waardoor meer context behouden blijft en langetermijnafhankelijkheden worden opgelost.
Door het chunken later in het proces toe te passen, profiteert de embedding van elke chunk van de rijke context van het volledige document, in plaats van geïsoleerd te zijn. Deze aanpak pakt het probleem van contextverlies aan en verbetert de kwaliteit van de embeddings voor retrieval- en generatietaken.
Bron: Günther et al., 2024
Contextualisering in RAG betekent ervoor zorgen dat de opgehaalde informatie relevant is voor de query. Door de opgehaalde data af te stemmen op de query, levert het systeem betere, relevantere antwoorden.
Dit verkleint de kans op onjuiste of irrelevante resultaten en zorgt dat de output beter aansluit op de behoefte van de gebruiker. Een aanpak is om een LLM te gebruiken om te checken of de opgehaalde documenten relevant zijn voordat ze naar het generatormodel gaan, zoals gedemonstreerd door Corrective RAG (CRAG).
Allereerst is het essentieel om de knowledgebase zo op te bouwen dat bevooroordeelde content wordt gefilterd, zodat de informatie zo objectief mogelijk is. Je kunt ook het retrievalsysteem hertrainen om evenwichtige, onbevooroordeelde bronnen te prioriteren.
Een andere belangrijke stap is een agent inzetten die specifiek controleert op mogelijke biases en waarborgt dat de output van het model objectief blijft.
Een groot probleem is het up-to-date houden van de geïndexeerde data met de nieuwste informatie, wat een betrouwbare update-structuur vereist. Versiebeheer wordt daarom cruciaal om verschillende iteraties van informatie te managen en consistentie te waarborgen.
Daarnaast moet het model zich in realtime kunnen aanpassen aan nieuwe informatie zonder vaak te hoeven hertrainen, wat veel middelen kan kosten. Deze uitdagingen vragen om geavanceerde oplossingen om het systeem accuraat en relevant te houden terwijl de knowledgebase evolueert.
CAG (Cache-Augmented Generation) is een evolutie van RAG waarbij opgehaalde documenten worden samengevat of gecomprimeerd voordat ze naar de LLM gaan. Dit verbetert de relevantie, vermindert het aantal tokens en helpt om meer informatie in het contextvenster van het model te passen.
Het belangrijkste verschil is dat bij CAG de opgehaalde content een tussenstap doorloopt, zoals een samenvatter of contextverfijner, voordat deze naar de generator gaat. Bij traditionele RAG worden ruwe documenten direct in de prompt gevoerd.
CAG is vooral nuttig wanneer:
Je met statische datasets werkt (bijv. productcatalogi, academische papers) die vooraf kunnen worden gecomprimeerd en gecachet.
Token-efficiëntie cruciaal is (bijv. kostengevoelige API’s of mobile/on-device inference).
De opgehaalde documenten lang of ruiserig zijn en distillatie nodig hebben.
RAG heeft daarentegen de voorkeur wanneer:
De onderliggende data dynamisch is of vaak wordt bijgewerkt (bijv. realtime supporttickets, live documentatie).
Je de meest recente kennis bij querytijd wilt betrekken, zonder de hele knowledgebase opnieuw te verwerken.
Kortom, gebruik CAG voor stabiele domeinen waar je de context vooraf kunt optimaliseren, en RAG voor dynamische scenario’s waar actualiteit en on-demand retrieval zwaarder wegen.
Bekijk dit artikel over RAG versus CAG voor een meer gedetailleerde vergelijking.
Er zijn veel geavanceerde RAG-systemen.
Een daarvan is Adaptive RAG, waarbij het systeem niet alleen informatie ophaalt, maar ook zijn aanpak realtime aanpast op basis van de query. Adaptive RAG kan besluiten geen retrieval te doen, single-shot RAG of iteratieve RAG. Dit dynamische gedrag maakt het systeem robuuster en relevanter voor het verzoek van de gebruiker.
Een ander geavanceerd systeem is Agentic RAG, dat retrieval agents introduceert—tools die beslissen of er wel of niet informatie uit een bron moet worden opgehaald. Door een taalmodel deze mogelijkheid te geven kan het zelf bepalen of extra informatie nodig is, waardoor het proces soepeler verloopt.
Corrective RAG (CRAG) wordt ook populair. Hierbij beoordeelt het systeem de opgehaalde documenten op relevantie. Alleen documenten die als relevant zijn geclassificeerd gaan naar de generator. Deze zelfcorrectiestap helpt ervoor te zorgen dat accurate, relevante informatie wordt gebruikt. Lees voor meer info deze tutorial over Corrective RAG (CRAG) implementeren met LangGraph.
Self-RAG gaat nog een stap verder door niet alleen de opgehaalde documenten, maar ook de uiteindelijke gegenereerde antwoorden te evalueren, zodat beide zijn afgestemd op de vraag van de gebruiker. Dit leidt tot betrouwbaardere en consistenter resultaten.
Een effectieve aanpak is het vooraf ophalen van relevante en veelgevraagde informatie, zodat die direct beschikbaar is. Daarnaast kan het verfijnen van je indexering en query-algoritmen een groot verschil maken in hoe snel data wordt opgehaald en verwerkt.
Hoewel RAG krachtig is, kent het verschillende beperkingen en uitdagingen:
Afhankelijkheid van de kwaliteit van opgehaalde data: Een RAG-systeem is zo goed als de informatie die het ophaalt. Als de retriever irrelevante of onjuiste documenten binnenhaalt, lijdt het antwoord van de generator daaronder. Zorgen voor hoogwaardige, betrouwbare databronnen (en het finetunen van de retriever) is een voortdurende uitdaging om garbage-in, garbage-out te voorkomen.
Toegenomen complexiteit en latentie: RAG voegt een extra retrievalstap toe bovenop generatie, wat het geheel complexer en rekenzwaarder maakt dan een standalone LLM. Zoeken in een grote knowledgebase kan latentie toevoegen en veel rekenbronnen vereisen, dus RAG-systemen moeten nauwkeurigheid balanceren met efficiëntie.
Onderhoud van de knowledgebase: In tegenstelling tot statische LLM’s is RAG afhankelijk van een externe kennisrepository die regelmatig moet worden bijgewerkt en gecureerd. Organisaties moeten continu nieuwe data opnemen, verouderde info verwijderen en indices beheren. Zonder betrouwbare en actuele bronnen kan een RAG-systeem snel minder effectief worden of zelfs verouderde antwoorden geven.
Moeilijkheid van integratie en tuning: Retrieval en generatie combineren betekent meer componenten om af te stemmen en te monitoren (de vectordatabase, het retrievermodel en de LLM). Fouten opsporen kan lastiger zijn omdat problemen aan de retrieval- of juist aan de generatiek kant kunnen liggen. Deze complexiteit kan de ontwikkel- en onderhoudsinspanning verhogen vergeleken met alleen een LLM gebruiken.
Het is ook het vermelden waard dat als de data in een domein grotendeels statisch is en binnen de training van het model past, een gefinetunede LLM voldoende kan zijn in plaats van RAG. Fine-tunen mist echter het vermogen van RAG om on-the-fly nieuwe informatie te integreren en kan duurder zijn om te hertrainen bij elke kennisupdate.
Laten we nu enkele specifieke vragen behandelen die gericht zijn op kandidaten voor AI-engineerposities.
Leer AI met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
