
Program
Pengembangan Aplikasi Kecerdasan Buatan
21 Hr
Mari mulai dengan serangkaian pertanyaan dasar tentang RAG.
Sistem RAG (retrieval-augmented generation) memiliki dua komponen utama: retriever dan generator.
Retriever mencari dan mengumpulkan informasi relevan dari sumber eksternal, seperti database, dokumen, atau situs web.
Generator, biasanya model bahasa tingkat lanjut, menggunakan informasi ini untuk membuat teks yang jelas dan akurat.
Retriever memastikan sistem memperoleh informasi yang paling mutakhir, sementara generator menggabungkannya dengan pengetahuan internalnya untuk menghasilkan jawaban yang lebih baik.
Bersama-sama, keduanya memberikan respons yang lebih akurat daripada generator saja.
Jika Anda hanya mengandalkan pengetahuan bawaan LLM, sistem terbatas pada data pelatihannya, yang bisa jadi sudah usang atau kurang detail.
Sistem RAG menawarkan keunggulan besar dengan menarik informasi segar dari sumber eksternal, menghasilkan respons yang lebih akurat dan tepat waktu.
Pendekatan ini juga mengurangi "halusinasi"—kesalahan ketika model mengada-ada fakta—karena jawaban didasarkan pada data nyata. RAG sangat membantu untuk bidang spesifik seperti hukum, kedokteran, atau teknologi, yang memerlukan pengetahuan khusus dan mutakhir.
RAG digunakan dalam berbagai aplikasi AI dunia nyata di berbagai domain:
Sistem tanya jawab dan dukungan: RAG menggerakkan chatbot dukungan pelanggan dan asisten basis pengetahuan dengan mengambil dokumentasi atau FAQ terbaru dan menghasilkan jawaban akurat untuk pengguna. Ini memastikan pertanyaan pelanggan diselesaikan dengan informasi terkini (misalnya, menarik info kebijakan atau detail produk saat ini).
Agen percakapan: Banyak chatbot dan asisten virtual menggunakan RAG untuk memberikan respons yang faktual dan kontekstual. Dengan mengambil fakta relevan secara dinamis, agen percakapan (seperti chatbot kesehatan atau keuangan) dapat memberikan jawaban yang terinformasi dan berpijak pada sumber tepercaya.
Generasi konten dan rangkuman: RAG membantu menghasilkan atau meringkas konten dengan akurasi faktual. Misalnya, sistem dapat mengambil bagian dari artikel berita atau makalah riset lalu menghasilkan ringkasan atau laporan yang koheren dan diperiksa faktanya terhadap data sumber.
Riset khusus domain: Dalam bidang khusus seperti hukum atau kedokteran, sistem RAG membantu dengan menarik dari database domain-spesifik (yurisprudensi, jurnal medis, dll.) untuk menjawab kueri kompleks. Dengan demikian, keluaran model berpijak pada pengetahuan domain yang andal dan mutakhir, yang penting untuk kasus penggunaan profesional.
Sistem RAG dapat mengumpulkan informasi dari sumber eksternal terstruktur dan tidak terstruktur:
Fleksibilitas ini memungkinkan sistem RAG disesuaikan untuk berbagai bidang, seperti penggunaan legal atau medis, dengan menarik dari basis data yurisprudensi, jurnal riset, atau data uji klinis.
Prompt engineering membantu model bahasa memberikan respons berkualitas tinggi menggunakan informasi yang diambil. Cara Anda merancang prompt dapat memengaruhi relevansi dan kejelasan keluaran.
Dalam sistem RAG, retriever mengumpulkan informasi relevan dari sumber eksternal agar dapat digunakan oleh generator. Ada berbagai cara untuk melakukan retrieval.
Salah satu metodenya adalah sparse retrieval, yang mencocokkan kata kunci (misalnya, TF-IDF atau BM25). Ini sederhana namun mungkin tidak menangkap makna mendalam di balik kata-kata.
Pendekatan lain adalah dense retrieval, yang menggunakan embedding neural untuk memahami makna dokumen dan kueri. Metode seperti BERT atau Dense Passage Retrieval (DPR) merepresentasikan dokumen sebagai vektor dalam ruang bersama, membuat retrieval lebih akurat.
Pilihan di antara metode-metode ini dapat sangat memengaruhi kinerja sistem RAG.
Menggabungkan informasi yang diambil dengan generasi LLM menghadirkan sejumlah tantangan. Misalnya, data yang diambil harus sangat relevan dengan kueri karena data yang tidak relevan dapat membingungkan model dan menurunkan kualitas respons.
Selain itu, jika informasi yang diambil bertentangan dengan pengetahuan internal model, hal ini dapat menghasilkan jawaban yang membingungkan atau tidak akurat. Karena itu, menyelesaikan konflik ini tanpa membingungkan pengguna sangatlah penting.
Terakhir, gaya dan format data yang diambil mungkin tidak selalu sesuai dengan gaya penulisan atau pemformatan model, sehingga menyulitkan model untuk mengintegrasikan informasi dengan mulus.
Dalam sistem RAG, sebuah database vektor membantu mengelola dan menyimpan embedding teks yang padat. Embedding ini adalah representasi numerik yang menangkap makna kata dan frasa, dibuat oleh model seperti BERT atau OpenAI.
Ketika sebuah kueri diajukan, embedding-nya dibandingkan dengan embedding yang tersimpan di database untuk menemukan dokumen yang serupa. Ini membuat pengambilan informasi yang tepat menjadi lebih cepat dan akurat. Proses ini membantu sistem dengan cepat menemukan dan menampilkan informasi paling relevan, meningkatkan kecepatan dan akurasi retrieval.
Untuk mengevaluasi sistem RAG, Anda perlu melihat baik komponen retrieval maupun generasi.
Untuk tugas hilir seperti tanya jawab, metrik seperti F1 score, precision, dan recall juga dapat digunakan untuk mengevaluasi keseluruhan sistem RAG.
Menangani kueri yang ambigu atau tidak lengkap dalam sistem RAG memerlukan strategi agar informasi yang diambil tetap relevan dan akurat meski masukan pengguna kurang jelas.
Salah satu pendekatan adalah menerapkan teknik penyempurnaan kueri, di mana sistem secara otomatis menyarankan klarifikasi atau memformulasi ulang kueri yang ambigu menjadi lebih presisi berdasarkan pola yang diketahui atau interaksi sebelumnya. Ini bisa melibatkan pertanyaan lanjutan atau memberikan beberapa opsi kepada pengguna untuk mempersempit maksudnya.
Metode lain adalah mengambil kumpulan dokumen yang beragam yang mencakup beberapa kemungkinan interpretasi kueri. Dengan mengambil berbagai hasil, sistem memastikan bahwa meskipun kueri samar, kemungkinan tetap ada informasi relevan yang disertakan.
Terakhir, kita dapat menggunakan model natural language understanding (NLU) untuk menyimpulkan maksud pengguna dari kueri yang tidak lengkap dan menyempurnakan proses retrieval.
Setelah membahas beberapa pertanyaan dasar, saatnya beralih ke pertanyaan wawancara RAG tingkat menengah.
Memilih retriever yang tepat bergantung pada jenis data yang Anda gunakan, sifat kueri, dan seberapa besar daya komputasi yang Anda miliki.
Untuk kueri kompleks yang memerlukan pemahaman mendalam terhadap makna di balik kata, metode dense retrieval seperti BERT atau DPR lebih baik. Metode ini menangkap konteks dan ideal untuk tugas seperti dukungan pelanggan atau riset, di mana pemahaman makna yang mendasari sangat penting.
Jika tugasnya lebih sederhana dan berkisar pada pencocokan kata kunci, atau jika sumber daya komputasi terbatas, metode sparse retrieval seperti BM25 atau TF-IDF mungkin lebih cocok. Metode ini lebih cepat dan mudah diatur, tetapi mungkin tidak menemukan dokumen yang tidak cocok secara kata kunci persis.
Pertukaran utama antara metode dense dan sparse adalah akurasi versus biaya komputasi. Terkadang, menggabungkan keduanya dalam sistem retrieval hibrida dapat membantu menyeimbangkan akurasi dengan efisiensi komputasi. Dengan cara ini, Anda mendapatkan manfaat dari metode dense dan sparse sesuai kebutuhan.
Pencarian hibrida menggabungkan kelebihan metode dense dan sparse retrieval.
Misalnya, Anda dapat mulai dengan metode sparse seperti BM25 untuk cepat menemukan dokumen berdasarkan kata kunci. Lalu, metode dense seperti BERT melakukan re-ranking terhadap dokumen tersebut dengan memahami konteks dan maknanya. Ini memberi Anda kecepatan pencarian sparse dengan akurasi metode dense—sangat cocok untuk kueri kompleks dan dataset besar.
Database vektor sangat baik untuk mengelola embedding padat, namun tidak selalu diperlukan. Alternatifnya meliputi:
Pilihan yang tepat bergantung pada kebutuhan spesifik Anda, seperti skala data dan apakah Anda memerlukan pemahaman semantik yang mendalam.
Untuk memastikan informasi yang diambil relevan dan akurat, Anda dapat menggunakan beberapa pendekatan:
Saat berhadapan dengan dokumen panjang atau basis pengetahuan besar, berikut beberapa teknik yang bermanfaat:
Untuk mendapatkan kinerja terbaik dari sistem RAG dalam hal akurasi dan efisiensi, Anda dapat menggunakan beberapa strategi:
Dalam percakapan multi-giliran (misalnya, dialog chatbot), sistem RAG perlu membawa konteks relevan dari giliran sebelumnya untuk menjawab pertanyaan berikutnya dengan benar. Untuk mencapai ini, RAG dapat memasukkan riwayat percakapan ke dalam setiap kueri baru:
Penyempurnaan kueri: Sistem dapat secara otomatis menulis ulang atau menambah pertanyaan pengguna menggunakan informasi dari pertukaran sebelumnya. Dengan menambahkan detail dari giliran terdahulu, retriever mendapatkan kueri yang lebih kaya konteks, sehingga dapat mengambil dokumen yang relevan dengan diskusi yang sedang berlangsung.
Menyertakan riwayat percakapan: Pendekatan lain adalah memberi model ringkasan atau daftar giliran dialog sebelumnya sebagai bagian dari konteks masukan. Banyak arsitektur RAG memungkinkan pengiriman urutan pesan (riwayat pengguna dan asisten) bersama dengan pertanyaan baru. Dengan cara ini, saat retriever mencari informasi, ia mempertimbangkan konteks yang telah dibangun, dan generator dapat menggunakan konteks masa lalu untuk menjaga percakapan tetap koheren.
Dengan menggunakan metode ini, sistem RAG melacak “siapa mengatakan apa” dan apa yang sudah terselesaikan. Ini mencegahnya melupakan detail atau mengulang-ulang.
Sejauh ini, kita telah membahas pertanyaan dasar dan menengah tentang RAG, dan sekarang kita akan membahas konsep yang lebih maju seperti teknik chunking atau kontekstualisasi.
Ada beberapa cara untuk memecah dokumen untuk retrieval dan pemrosesan:
Potongan yang lebih kecil, seperti kalimat atau paragraf pendek, membantu menghindari pengenceran informasi kontekstual penting saat dikompresi ke dalam satu vektor. Namun, ini dapat menyebabkan hilangnya dependensi jarak jauh antar potongan, sehingga menyulitkan model memahami referensi yang melintasi potongan.
Potongan yang lebih besar mempertahankan lebih banyak konteks, yang memungkinkan informasi kontekstual lebih kaya namun bisa menjadi kurang fokus dan informasi dapat hilang saat mencoba mengenkode semua informasi ke dalam satu vektor.
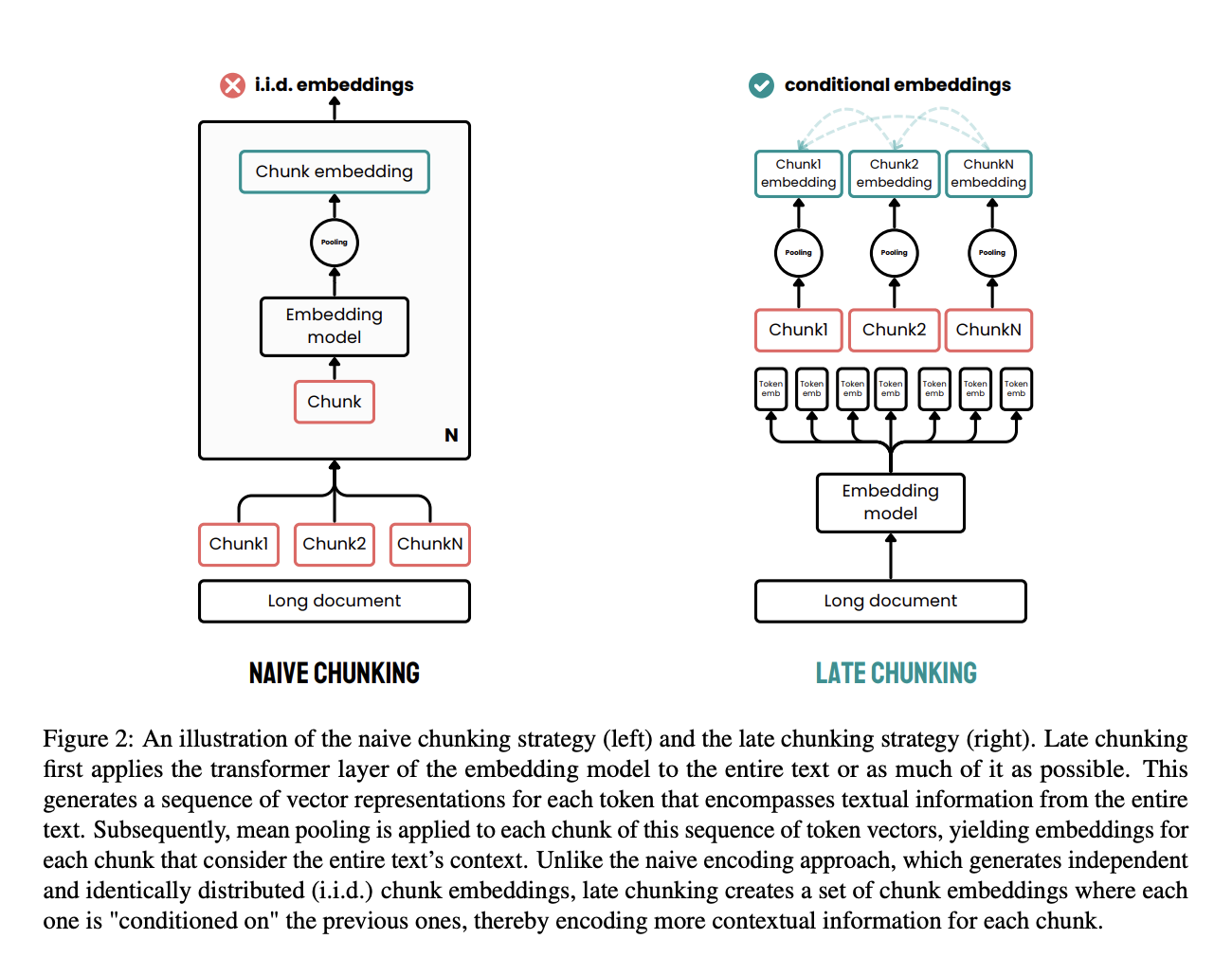
Late chunking adalah pendekatan efektif yang dirancang untuk mengatasi keterbatasan metode chunking tradisional dalam pemrosesan dokumen.
Dalam metode tradisional, dokumen terlebih dahulu dipecah menjadi potongan, seperti kalimat atau paragraf, sebelum menerapkan model embedding. Potongan-potongan ini kemudian dikodekan secara individual menjadi vektor, sering kali menggunakan mean pooling untuk membuat satu embedding untuk setiap potongan. Pendekatan ini dapat menyebabkan hilangnya dependensi kontekstual jarak jauh karena embedding dibuat secara independen tanpa mempertimbangkan konteks dokumen penuh.
Late chunking mengambil pendekatan berbeda. Lapisan transformer dari model embedding terlebih dahulu diterapkan pada seluruh dokumen atau sebanyak mungkin bagian, menciptakan urutan representasi vektor untuk setiap token. Metode ini menangkap konteks penuh teks dalam embedding tingkat token tersebut.
Setelah itu, mean pooling diterapkan pada potongan dari urutan vektor token ini, menghasilkan embedding untuk setiap potongan yang diinformasikan oleh konteks seluruh dokumen. Berbeda dengan metode tradisional, late chunking menghasilkan embedding potongan yang saling terkondisikan, sehingga lebih banyak informasi kontekstual terjaga dan dependensi jarak jauh terselesaikan.
Dengan menerapkan chunking di tahap akhir, setiap embedding potongan memperoleh manfaat dari konteks kaya yang disediakan oleh seluruh dokumen, bukan berdiri sendiri. Pendekatan ini mengatasi masalah hilangnya konteks dan meningkatkan kualitas embedding untuk tugas retrieval dan generasi.
Sumber: Günther et al., 2024
Kontekstualisasi dalam RAG berarti memastikan informasi yang diambil relevan dengan kueri. Dengan menyelaraskan data yang diambil dengan kueri, sistem menghasilkan jawaban yang lebih baik dan lebih relevan.
Ini mengurangi kemungkinan hasil yang salah atau tidak relevan dan memastikan keluaran sesuai kebutuhan pengguna. Salah satu pendekatannya adalah menggunakan LLM untuk memeriksa apakah dokumen yang diambil relevan sebelum mengirimkannya ke model generator, seperti ditunjukkan oleh Corrective RAG (CRAG).
Pertama, penting untuk membangun basis pengetahuan dengan cara menyaring konten bias, memastikan informasi seobjektif mungkin. Anda juga dapat melatih ulang sistem retrieval untuk memprioritaskan sumber yang seimbang dan tidak bias.
Langkah penting lainnya adalah mengadopsi sebuah agen khusus untuk memeriksa potensi bias dan memastikan keluaran model tetap objektif.
Salah satu isu utama adalah menjaga data yang diindeks tetap mutakhir dengan informasi terbaru, yang memerlukan mekanisme pembaruan andal. Karena itu, kontrol versi menjadi krusial untuk mengelola iterasi informasi yang berbeda dan memastikan konsistensi.
Selain itu, model perlu mampu beradaptasi dengan informasi baru secara real-time tanpa sering dilatih ulang, yang dapat menguras sumber daya. Tantangan-tantangan ini memerlukan solusi canggih untuk memastikan sistem tetap akurat dan relevan seiring evolusi basis pengetahuan.
CAG (Cache-Augmented Generation) adalah evolusi dari RAG di mana dokumen yang diambil dirangkum atau dikompresi sebelum diteruskan ke LLM. Ini meningkatkan relevansi, mengurangi penggunaan token, dan membantu memuat lebih banyak informasi ke dalam jendela konteks model.
Perbedaan utamanya adalah pada CAG, konten yang diambil melalui langkah perantara, seperti peringkas atau perapih konteks, sebelum diberikan ke generator. Sebaliknya, RAG tradisional meneruskan dokumen mentah langsung ke prompt.
CAG sangat berguna ketika:
Anda bekerja dengan dataset statis (misalnya, katalog produk, makalah akademik) yang dapat dipra-kompres dan di-cache.
Efisiensi token sangat kritis (misalnya, API sensitif biaya atau inferensi seluler/on-device).
Dokumen yang diambil panjang atau berisik dan perlu didistilasi.
Di sisi lain, RAG lebih disukai ketika:
Data yang mendasari bersifat dinamis atau sering diperbarui (misalnya, tiket dukungan real-time, dokumentasi live).
Anda ingin memasukkan pengetahuan terbaru saat waktu kueri, tanpa memproses ulang seluruh basis pengetahuan.
Singkatnya, gunakan CAG untuk domain yang stabil di mana Anda dapat mengoptimalkan konteks sebelumnya, dan RAG untuk skenario dinamis di mana kebaruan dan retrieval sesuai permintaan lebih penting.
Lihat artikel tentang RAG versus CAG untuk perbandingan yang lebih mendetail.
Ada banyak sistem RAG tingkat lanjut.
Salah satunya adalah Adaptive RAG, di mana sistem tidak hanya mengambil informasi tetapi juga menyesuaikan pendekatannya secara real-time berdasarkan kueri. Adaptive RAG dapat memutuskan untuk tidak melakukan retrieval, melakukan RAG satu kali, atau RAG iteratif. Perilaku dinamis ini membuat sistem RAG lebih tangguh dan relevan dengan permintaan pengguna.
Sistem RAG tingkat lanjut lainnya adalah Agentic RAG, yang memperkenalkan agen retrieval—alat yang memutuskan apakah perlu mengambil informasi dari suatu sumber. Dengan memberi kemampuan ini kepada model bahasa, ia dapat menentukan sendiri apakah memerlukan informasi tambahan, sehingga proses menjadi lebih lancar.
Corrective RAG (CRAG) juga semakin populer. Dalam pendekatan ini, sistem meninjau dokumen yang diambil, memeriksa relevansinya. Hanya dokumen yang diklasifikasikan relevan yang akan diteruskan ke generator. Langkah koreksi mandiri ini membantu memastikan informasi yang digunakan akurat dan relevan. Untuk mempelajari lebih lanjut, Anda dapat membaca tutorial ini tentang Implementasi Corrective RAG (CRAG) dengan LangGraph.
Self-RAG melangkah lebih jauh dengan mengevaluasi tidak hanya dokumen yang diambil tetapi juga respons akhir yang dihasilkan, memastikan keduanya selaras dengan kueri pengguna. Ini menghasilkan hasil yang lebih andal dan konsisten.
Salah satu pendekatan efektif adalah melakukan pre-fetching informasi yang relevan dan sering diminta agar siap digunakan saat diperlukan. Selain itu, menyempurnakan pengindeksan dan algoritma kueri Anda dapat sangat memengaruhi kecepatan pengambilan dan pemrosesan data.
Meskipun RAG kuat, ada beberapa keterbatasan dan tantangan:
Ketergantungan pada kualitas data yang diambil: Sistem RAG hanya sebaik informasi yang diambilnya. Jika retriever menarik dokumen yang tidak relevan atau salah, jawaban generator akan terdampak. Memastikan sumber data yang berkualitas dan tepercaya (serta fine-tuning retriever) adalah tantangan berkelanjutan untuk menghindari masalah garbage-in, garbage-out.
Peningkatan kompleksitas dan latensi: RAG menambahkan langkah retrieval di atas generasi, yang membuat keseluruhan sistem lebih kompleks dan berat secara komputasi dibanding LLM mandiri. Mencari di basis pengetahuan besar dapat menambah latensi dan memerlukan sumber daya komputasi signifikan, sehingga sistem RAG harus menyeimbangkan akurasi dengan efisiensi.
Kebutuhan pemeliharaan basis pengetahuan: Tidak seperti LLM statis, RAG bergantung pada repositori pengetahuan eksternal yang perlu diperbarui dan dikurasi secara rutin. Organisasi harus terus memasukkan data baru, menghapus info usang, dan mengelola indeks. Tanpa sumber data yang andal dan terkini, sistem RAG dapat cepat menjadi kurang efektif atau bahkan memberikan jawaban yang kedaluwarsa.
Kesulitan integrasi dan penyetelan: Menggabungkan retrieval dan generasi berarti ada lebih banyak komponen untuk disetel dan dipantau (database vektor, model retriever, dan LLM). Pemecahan masalah bisa lebih sulit karena isu mungkin berasal dari sisi retrieval atau generasi. Kompleksitas ini dapat meningkatkan upaya pengembangan dan pemeliharaan dibanding hanya menggunakan LLM.
Perlu dicatat juga bahwa jika data suatu domain sebagian besar statis dan sudah tercakup dalam pelatihan model, LLM yang di-fine-tune mungkin sudah cukup menggantikan RAG. Namun, fine-tuning tidak memiliki kemampuan RAG untuk memasukkan informasi segar secara langsung dan bisa lebih mahal untuk dilatih ulang setiap kali ada pembaruan pengetahuan.
Sekarang, mari bahas beberapa pertanyaan khusus yang ditujukan bagi mereka yang melamar posisi AI Engineer.
Pelajari AI dengan kursus-kursus ini!
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
