
Track
Developing AI Applications
21 hr
Let’s begin with a series of fundamental interview questions about RAG.
A RAG (retrieval-augmented generation) system has two main components: the retriever and the generator.
The retriever searches for and collects relevant information from external sources, like databases, documents, or websites.
The generator, usually an advanced language model, uses this information to create clear and accurate text.
The retriever makes sure the system gets the most up-to-date information, while the generator combines this with its own knowledge to produce better answers.
Together, they provide more accurate responses than the generator could on its own.
If you rely only on an LLM’s built-in knowledge, the system is limited to what it was trained on, which could be outdated or lacking detail.
RAG systems offer a big advantage by pulling in fresh information from external sources, resulting in more accurate and timely responses.
This approach also reduces "hallucinations"—errors where the model makes up facts—because the answers are based on real data. RAG is especially helpful for specific fields like law, medicine, or tech, where up-to-date, specialized knowledge is needed.
RAG is used in a variety of real-world AI applications across different domains:
Question-answering and support systems: RAG powers customer support chatbots and knowledge base assistants by retrieving up-to-date documentation or FAQs and generating accurate answers for users. This ensures customer queries are resolved with the latest information (for example, pulling current policy info or product details).
Conversational agents: Many chatbots and virtual assistants use RAG to provide factual, context-aware responses. By fetching relevant facts on the fly, a conversational agent (like a healthcare or finance chatbot) can give informed answers grounded in credible sources.
Content generation and summarization: RAG helps in generating or summarizing content with factual accuracy. For instance, it can retrieve parts of news articles or research papers and then produce summaries or reports that are both coherent and fact-checked against source data.
Domain-specific research: In specialized fields like law or medicine, RAG systems assist by pulling from domain-specific databases (case law, medical journals, etc.) to answer complex queries. This way, the model’s output is grounded in reliable, up-to-date domain knowledge, which is important for professional use cases.
RAG systems can gather information from both structured and unstructured external sources:
This flexibility allows RAG systems to be tailored to different fields, such as legal or medical use, by pulling from case law databases, research journals, or clinical trial data.
Prompt engineering helps language models provide high-quality responses using the retrieved information. How you design a prompt can affect the relevance and clarity of the output.
In a RAG system, the retriever gathers relevant information from external sources for the generator to use. There are different ways to retrieve information.
One method is sparse retrieval, which matches keywords (e.g., TF-IDF or BM25). This is simple but may not capture the deeper meaning behind the words.
Another approach is dense retrieval, which uses neural embeddings to understand the meaning of documents and queries. Methods like BERT or Dense Passage Retrieval (DPR) represent documents as vectors in a shared space, making retrieval more accurate.
The choice between these methods can greatly affect how well the RAG system works.
Combining retrieved information with an LLM’s generation presents some challenges. For instance, the retrieved data must be highly relevant to the query as irrelevant data can confuse the model and reduce the quality of the response.
Additionally, if the retrieved information conflicts with the model’s internal knowledge, it can create confusing or inaccurate answers. As such, resolving these conflicts without confusing the user is crucial.
Finally, the style and format of retrieved data might not always match the model's usual writing or formatting, making it hard for the model to integrate the information smoothly.
In a RAG system, a vector database helps manage and store dense embeddings of text. These embeddings are numerical representations that capture the meaning of words and phrases, created by models like BERT or OpenAI.
When a query is made, its embedding is compared to the stored ones in the database to find similar documents. This makes it faster and more accurate to retrieve the right information. This process helps the system quickly locate and pull up the most relevant information, improving both the speed and accuracy of retrieval.
To evaluate a RAG system, you need to look at both the retrieval and generation components.
For downstream tasks like question-answering, metrics like F1 score, precision, and recall can also be used to evaluate the overall RAG system.
Handling ambiguous or incomplete queries in a RAG system requires strategies to ensure that relevant and accurate information is retrieved despite the lack of clarity in the user’s input.
One approach is to implement query refinement techniques, where the system automatically suggests clarifications or reformulates the ambiguous query into a more precise one based on known patterns or previous interactions. This can involve asking follow-up questions or providing the user with multiple options to narrow down their intent.
Another method is to retrieve a diverse set of documents that cover multiple possible interpretations of the query. By retrieving a range of results, the system ensures that even if the query is vague, some relevant information is likely to be included.
Lastly, we can use natural language understanding (NLU) models to infer user intent from incomplete queries and refine the retrieval process.
Now that we’ve covered a few basic questions, it’s time to move on to intermediate RAG interview questions.
Choosing the right retriever depends on the type of data you're working with, the nature of the queries, and how much computing power you have.
For complex queries that need a deep understanding of the meaning behind words, dense retrieval methods like BERT or DPR are better. These methods capture context and are ideal for tasks like customer support or research, where understanding the underlying meanings matter.
If the task is simpler and revolves around keyword matching, or if you have limited computational resources, sparse retrieval methods such as BM25 or TF-IDF might be more suitable. These methods are quicker and easier to set up but might not find documents that don’t match exact keywords.
The main trade-off between dense and sparse retrieval methods is accuracy versus computational cost. Sometimes, combining both approaches in a hybrid retrieval system can help balance accuracy with computational efficiency. This way, you get the benefits of both dense and sparse methods depending on your needs.
Hybrid search combines the strengths of both dense and sparse retrieval methods.
For instance, you can start with a sparse method like BM25 to quickly find documents based on keywords. Then, a dense method like BERT re-ranks those documents by understanding their context and meaning. This gives you the speed of sparse search with the accuracy of dense methods, which is great for complex queries and large datasets.
A vector database is great for managing dense embeddings, but it’s not always necessary. Alternatives include:
The right choice depends on your specific needs, such as the scale of your data and whether you need deep semantic understanding.
To make sure the retrieved information is relevant and accurate, you can use several approaches:
When dealing with long documents or large knowledge bases, here are some useful techniques:
To get the best performance from a RAG system in terms of accuracy and efficiency, you can use several strategies:
In multi-turn conversations (e.g., a chatbot dialog), a RAG system needs to carry over relevant context from earlier turns to answer later questions correctly. To achieve this, RAG can incorporate the conversation history into each new query:
Query refinement: The system can automatically rewrite or augment the user’s question using information from previous exchanges. By adding details from prior turns, the retriever gets a more context-rich query, so it can fetch documents relevant to the ongoing discussion.
Including conversation history: Another approach is to provide the model with a summary or list of the previous dialogue turns as part of its input context. Many RAG architectures allow passing a sequence of messages (user and assistant history) along with the new question. This way, when the retriever searches for information, it considers the established context, and the generator can use the past context to maintain a coherent conversation.
By using these methods, the RAG system keeps track of “who said what” and what has already been resolved. This prevents it from forgetting details or repeating itself.
So far, we’ve covered basic and intermediate RAG interview questions, and now we will tackle more advanced concepts like chunking techniques or contextualization.
There are several ways to break down documents for retrieval and processing:
Smaller chunks, like sentences or short paragraphs, help avoid the dilution of important contextual information when compressed into a single vector. However, this can lead to losing long-range dependencies across chunks, making it difficult for models to understand references that span across chunks.
Larger chunks keep more context, which allows for richer contextual information but can be less focused and information might get lost when trying to encode all the information into a single vector.
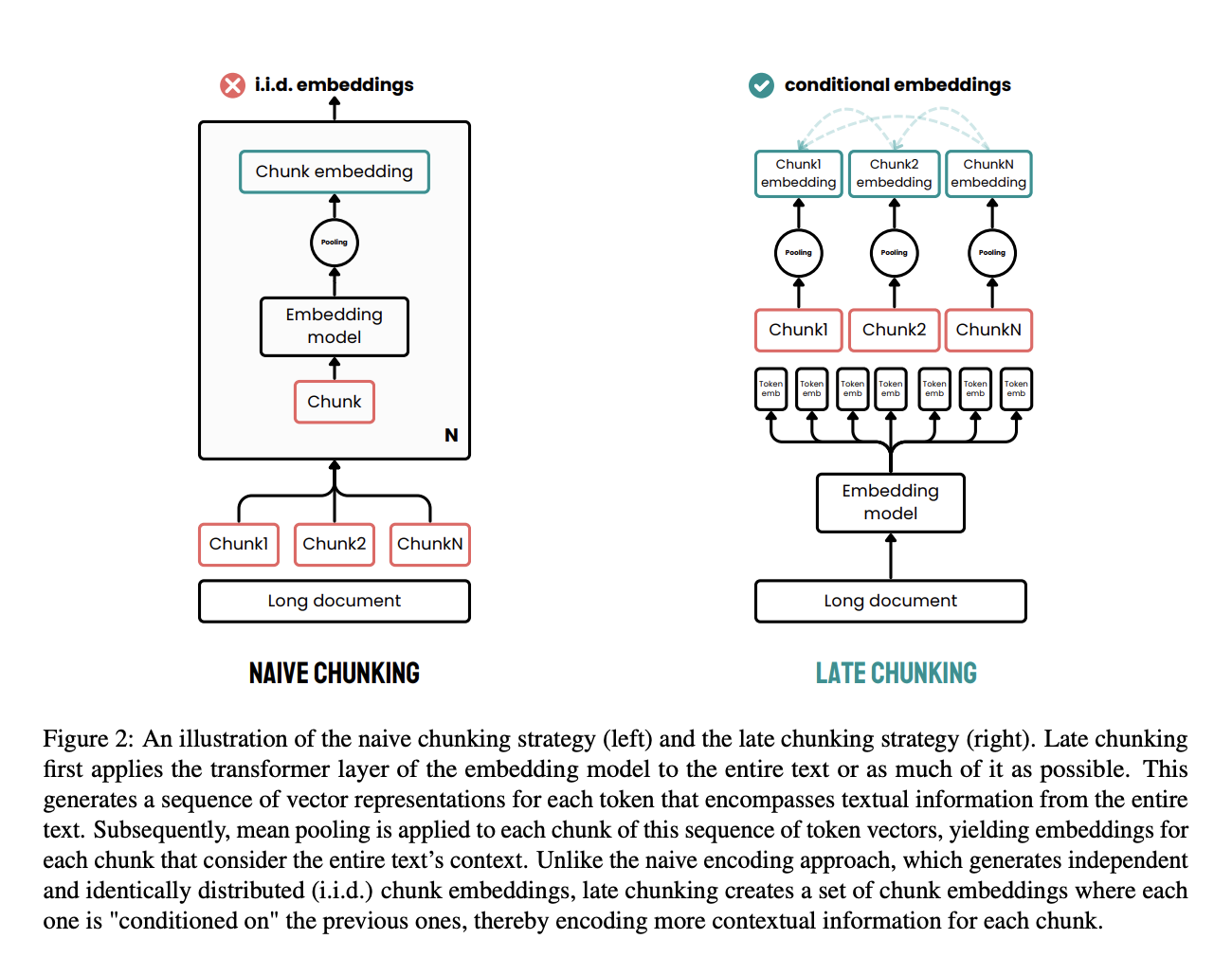
Late chunking is an effective approach designed to address the limitations of traditional chunking methods in document processing.
In traditional methods, documents are first split into chunks, such as sentences or paragraphs, before applying an embedding model. These chunks are then individually encoded into vectors, often using mean pooling to create a single embedding for each chunk. This approach can lead to a loss of long-distance contextual dependencies because the embeddings are generated independently, without considering the full document context.
Late chunking takes a different approach. It first applies the transformer layer of the embedding model to the entire document or as much of it as possible, creating a sequence of vector representations for each token. This method captures the full context of the text in these token-level embeddings.
Afterward, mean pooling is applied to the chunks of this sequence of token vectors, producing embeddings for each chunk that are informed by the entire document's context. Unlike the traditional method, late chunking generates chunk embeddings that are conditioned on each other, preserving more contextual information and resolving long-range dependencies.
By applying chunking later in the process, it ensures that each chunk's embedding benefits from the rich context provided by the entire document, rather than being isolated. This approach addresses the problem of lost context and improves the quality of the embeddings used for retrieval and generation tasks.
Source: Günther et al., 2024
Contextualization in RAG means making sure the information retrieved is relevant to the query. By aligning the retrieved data with the query, the system produces better, more relevant answers.
This reduces the chances of incorrect or irrelevant results and ensures the output fits the user's needs. One approach is to use an LLM to check if the retrieved documents are relevant before sending them to the generator model, as demonstrated by Corrective RAG (CRAG).
First, it's essential to build the knowledge base in a way that filters out biased content, making sure the information is as objective as possible. You can also retrain the retrieval system to prioritize balanced, unbiased sources.
Another important step could be to adopt an agent specifically to check for potential biases and ensure that the model’s output remains objective.
One major issue is keeping the indexed data up-to-date with the latest information, which requires a reliable updating mechanism. As such, version control becomes crucial to manage different iterations of information and ensure consistency.
Additionally, the model needs to be able to adapt to new information in real-time without having to retrain frequently, which can be resource-intensive. These challenges require sophisticated solutions to ensure that the system remains accurate and relevant as the knowledge base evolves.
CAG (Cache-Augmented Generation) is an evolution of RAG where retrieved documents are summarized or compressed before being passed to the LLM. This improves relevance, reduces token usage, and helps fit more information into the model’s context window.
The key difference is that in CAG, the retrieved content goes through an intermediate step, like a summarizer or context refiner, before being fed to the generator. In contrast, traditional RAG passes raw documents directly into the prompt.
CAG is especially useful when:
You’re working with static datasets (e.g., product catalogs, academic papers) that can be pre-compressed and cached.
Token efficiency is critical (e.g., cost-sensitive APIs or mobile/on-device inference).
The retrieved documents are long or noisy and need distillation.
RAG, on the other hand, is preferred when:
The underlying data is dynamic or frequently updated (e.g., real-time support tickets, live documentation).
You want to incorporate the freshest knowledge at query time, without reprocessing the entire knowledge base.
In short, use CAG for stable domains where you can optimize the context ahead of time, and RAG for dynamic scenarios where freshness and on-demand retrieval matter more.
Check out this article on RAG versus CAG for a more detailed comparison.
There are many advanced RAG systems.
One such system is the Adaptive RAG, where the system not only retrieves information but also adjusts its approach in real-time based on the query. The adaptive RAG can decide to perform no retrieval, single-shot RAG, or iterative RAG. This dynamic behavior makes the RAG system more robust and relevant to the user's request.
Another advanced RAG system is Agentic RAG, which introduces retrieval agents—tools that decide whether or not to pull information from a source. By giving a language model this capability, it can determine on its own if it needs extra information, making the process smoother.
Corrective RAG (CRAG) is also becoming popular. In this approach, the system reviews the documents it retrieves, checking for relevancy. Only documents that are classified as relevant would be fed to the generator. This self-correction step helps ensure accurate relevant information is used. To learn more, you can read this tutorial on Corrective RAG (CRAG) Implementation With LangGraph.
Self-RAG takes this a step further by evaluating not just the retrieved documents but also the final responses generated, making sure both are aligned with the user’s query. This leads to more reliable and consistent results.
One effective approach is pre-fetching relevant and commonly requested information so that it's ready to go when needed. Additionally, refining your indexing and query algorithms can make a big difference in how quickly data is retrieved and processed.
While RAG is powerful, it has several limitations and challenges:
Dependency on retrieved data quality: A RAG system is only as good as the information it retrieves. If the retriever pulls in irrelevant or incorrect documents, the generator’s answer will suffer. Ensuring high-quality, trusted data sources (and fine-tuning the retriever) is an ongoing challenge to avoid garbage-in, garbage-out issues.
Increased complexity and latency: RAG introduces an extra retrieval step on top of generation, which makes the whole system more complex and computationally heavy than a standalone LLM. Searching a large knowledge base can add latency and require significant compute resources, so RAG systems must balance accuracy with efficiency.
Need for maintenance of the knowledge base: Unlike static LLMs, RAG depends on an external knowledge repository that needs regular updating and curation. Organizations must continuously ingest new data, remove outdated info, and manage indices. Without reliable and up-to-date data sources, a RAG system can quickly become less effective or even provide outdated answers.
Integration and tuning difficulty: Combining retrieval and generation means more components to tune and monitor (the vector database, retriever model, and the LLM). Troubleshooting errors can be harder because issues might stem from the retrieval side or the generation side. This complexity can increase development and maintenance effort compared to using an LLM alone.
It’s also worth noting that if a domain’s data is largely static and fits in the model’s training, a fine-tuned LLM might be good enough in place of RAG. However, fine-tuning lacks RAG’s ability to incorporate fresh information on the fly and can be costlier to retrain for each knowledge update.
Now, let’s address a few specific questions targeted at those interviewing for AI Engineer positions.
Learn AI with these courses!
Track
Track
Course
blog
Vinod Chugani
15 min
blog
Hesam Sheikh Hassani
15 min
blog
Dimitri Didmanidze
15 min
blog
Stanislav Karzhev
15 min
blog
Abid Ali Awan
15 min
blog
Stanislav Karzhev
12 min


