
Programa
Desenvolvimento de aplicativos de IA
21 h
Vamos começar com uma série de perguntas fundamentais sobre o RAG.
Um sistema RAG (geração aumentada por recuperação) tem dois componentes principais: o recuperador e o gerador.
O recuperador procura e coleta informações relevantes de fontes externas, como bancos de dados. bancos de dados, documentos ou sites.
O gerador, geralmente um modelo de linguagem avançado, usa essas informações para criar um texto claro e preciso.
O recuperador garante que o sistema receba as informações mais atualizadas, enquanto o gerador combina isso com seu próprio conhecimento para produzir respostas melhores.
Juntos, eles dão respostas mais precisas do que o gerador conseguiria sozinho.
Se você confiar só no conhecimento que vem no LLM, o sistema vai ficar limitado ao que foi treinado, o que pode estar desatualizado ou sem detalhes.
Os sistemas RAG oferecem uma grande vantagem ao obter informações atualizadas de fontes externas, resultando em respostas mais precisas e oportunas.
Essa abordagem também reduz as “alucinações” — erros em que o modelo inventa fatos — porque as respostas são baseadas em dados reais. O RAG é especialmente útil para áreas específicas como direito, medicinaou tecnologia, onde é necessário ter conhecimento atualizado e especializado.
O RAG é usado em várias aplicações de IA do mundo real em diferentes áreas:
Sistemas de perguntas e respostas e de suporte: O RAG ajuda os chatbots de suporte ao cliente e os assistentes da base de conhecimento a pegar documentação atualizada ou perguntas frequentes e gerar respostas precisas para os usuários. Isso garante que as dúvidas dos clientes sejam resolvidas com as informações mais recentes (por exemplo, pegando informações atuais sobre políticas ou detalhes de produtos).
Agentes conversacionais: Muitos chatbots e assistentes virtuais usam RAG para dar respostas factuais e que entendem o contexto. Ao buscar informações relevantes na hora, um agente conversacional (como um chatbot de saúde ou finanças) pode dar respostas bem informadas, baseadas em fontes confiáveis.
Criação e resumo de conteúdo: O RAG ajuda a criar ou resumir conteúdo com precisão factual. Por exemplo, ele pode pegar partes de notícias ou artigos de pesquisa e criar resumos ou relatórios que são coerentes e verificados com base nos dados originais.
Pesquisa específica do domínio: Em áreas especializadas, como direito ou medicina, os sistemas RAG ajudam a responder perguntas complexas usando bancos de dados específicos do domínio (jurisprudência, revistas médicas, etc.). Assim, o resultado do modelo é baseado em conhecimento confiável e atualizado sobre o assunto, o que é importante para casos de uso profissional.
Os sistemas RAG podem coletar informações de fontes externas estruturadas e não estruturadas:
Essa flexibilidade permite que os sistemas RAG sejam adaptados a diferentes áreas, como uso jurídico ou médico, usando bancos de dados de jurisprudência, revistas científicas ou dados de ensaios clínicos.
A engenharia de prompts ajuda os modelos de linguagem a fornecer respostas de alta qualidade usando as informações recuperadas. A forma como você cria um prompt pode afetar a relevância e a clareza do resultado.
Num sistema RAG, o recuperador junta informações relevantes de fontes externas para o gerador usar. Tem várias maneiras de pegar informações.
Um método é a recuperação esparsa, que combina palavras-chave (por exemplo, TF-IDF ou BM25). Isso é simples, mas pode não captar o significado mais profundo por trás das palavras.
Outra abordagem é a recuperação densa, que usa embeddings neurais para entender o significado de documentos e consultas. Métodos como BERT ou Dense Passage Retrieval (DPR) mostram documentos como vetores num espaço compartilhado, tornando a recuperação mais precisa.
A escolha entre esses métodos pode afetar bastante o funcionamento do sistema RAG.
Combinar as informações recuperadas com a geração de um LLM traz alguns desafios. Por exemplo, os dados recuperados precisam ser bem relevantes para a consulta, porque dados irrelevantes podem confundir o modelo e diminuir a qualidade da resposta.
Além disso, se as informações recuperadas entrarem em conflito com o conhecimento interno do modelo, isso pode gerar respostas confusas ou imprecisas. Por isso, resolver esses conflitos sem confundir o usuário é super importante.
Por fim, o estilo e o formato dos dados recuperados podem nem sempre combinar com a escrita ou formatação normal do modelo, dificultando a integração suave das informações pelo modelo.
Em um sistema RAG, um banco de dados vetorial ajuda a gerenciar e armazenar de texto. Essas incorporações são representações numéricas que capturam o significado de palavras e frases, criadas por modelos como BERT ou OpenAI.
Quando alguém faz uma consulta, a incorporação dela é comparada com as que estão guardadas no banco de dados pra achar documentos parecidos. Isso torna mais rápido e preciso recuperar as informações certas. Esse processo ajuda o sistema a localizar e acessar rapidamente as informações mais relevantes, melhorando tanto a velocidade quanto a precisão da recuperação.
Para avaliar um sistema RAG, você precisa analisar os componentes de recuperação e geração.
Para tarefas a jusante, como responder perguntas, métricas como pontuação F1e precisãoe recall também podem ser usados para avaliar o sistema RAG como um todo.
Lidar com consultas ambíguas ou incompletas em um sistema RAG precisa de estratégias para garantir que informações relevantes e precisas sejam recuperadas, mesmo que a entrada do usuário não seja muito clara.
Uma abordagem é implementar técnicas de refinamento de consulta, em que o sistema automaticamente sugere esclarecimentos ou reformula a consulta ambígua em uma mais precisa, com base em padrões conhecidos ou interações anteriores. Isso pode envolver fazer perguntas complementares ou dar várias opções para o usuário, pra ajudar a entender melhor o que ele quer.
Outro jeito é pegar um conjunto variado de documentos que abranjam várias interpretações possíveis da consulta. Ao buscar vários resultados, o sistema garante que, mesmo que a consulta seja meio vaga, algumas informações relevantes provavelmente vão aparecer.
Por fim, podemos usar modelos de compreensão de linguagem natural (NLU) para entender o que o usuário quer mesmo quando a consulta está incompleta e melhorar o processo de busca.
Agora que já falamos sobre algumas perguntas básicas, é hora de passar para as perguntas intermediárias da entrevista RAG.
Escolher o recuperador certo depende do tipo de dados com que você está trabalhando, da natureza das consultas e da capacidade de computação que você tem.
Para consultas complexas que exigem uma compreensão profunda do significado por trás das palavras, métodos de recuperação densos como BERT ou DPR são melhores. Esses métodos capturam o contexto e são ideais para tarefas como suporte ao cliente ou pesquisa, onde entender os significados subjacentes é importante.
Se a tarefa for mais simples e girar em torno da correspondência de palavras-chave, ou se você tiver recursos computacionais limitados, métodos de recuperação esparsos, como BM25 ou TF-IDF, podem ser mais adequados. Esses métodos são mais rápidos e fáceis de configurar, mas podem não encontrar documentos que não correspondam exatamente às palavras-chave.
A principal diferença entre os métodos de recuperação densa e esparsa é a precisão versus o custo computacional. Às vezes, juntar as duas abordagens num sistema híbrido de recuperação pode ajudar a equilibrar a precisão com a eficiência computacional. eficiência computacional. Assim, você aproveita os benefícios dos métodos densos e esparsos, dependendo do que precisar.
A pesquisa híbrida junta o que há de melhor nos métodos de recuperação densa e esparsa.
Por exemplo, você pode começar com um método esparso como o BM25 para encontrar rapidamente documentos com base em palavras-chave. Então, um método denso como o BERT reclassifica esses documentos, entendendo seu contexto e significado. Isso te dá a velocidade da pesquisa esparsa com a precisão dos métodos densos, o que é ótimo para consultas complexas e grandes conjuntos de dados.
Um banco de dados vetorial é ótimo para gerenciar embeddings densos, mas nem sempre é necessário. As alternativas incluem:
A escolha certa depende das suas necessidades específicas, como o tamanho dos seus dados e se você precisa de um entendimento semântico profundo.
Para garantir que as informações recuperadas sejam relevantes e precisas, você pode usar várias abordagens:
Quando você estiver lidando com documentos longos ou grandes bases de conhecimento, aqui vão algumas dicas úteis:
Para obter o melhor desempenho de um sistema RAG em termos de precisão e eficiência, você pode usar várias estratégias:
Em conversas com várias rodadas (por exemplo, um diálogo com um chatbot), um sistema RAG precisa levar em conta o contexto relevante das rodadas anteriores para responder corretamente às perguntas posteriores. Para conseguir isso, o RAG pode incluir o histórico de conversas em cada nova consulta:
Refinamento da consulta: O sistema pode reescrever ou aumentar automaticamente a pergunta do usuário usando informações de conversas anteriores. Ao adicionar detalhes de turnos anteriores, o recuperador obtém uma consulta mais rica em contexto, para que possa buscar documentos relevantes para a discussão em andamento.
Incluindo o histórico de conversas: Outra abordagem é dar ao modelo um resumo ou uma lista das conversas anteriores como parte do contexto de entrada. Muitas arquiteturas RAG permitem passar uma sequência de mensagens (histórico do usuário e do assistente) junto com a nova pergunta. Assim, quando o recuperador procura informações, ele leva em conta o contexto estabelecido, e o gerador pode usar o contexto anterior para manter uma conversa coerente.
Usando esses métodos, o sistema RAG fica de olho em “quem disse o quê” e o que já foi resolvido. Isso evita que ele esqueça detalhes ou se repita.
Até agora, falamos sobre perguntas básicas e intermediárias de entrevistas RAG, e agora vamos abordar conceitos mais avançados, como técnicas de chunking ou contextualização.
Tem várias maneiras de dividir documentos para recuperação e processamento:
Pedaços menores, tipo frases ou parágrafos curtos, ajudam a evitar que informações contextuais importantes se percam quando comprimidas em um único vetor. Mas isso pode fazer com que a gente perca dependências de longo alcance entre blocos, dificultando para os modelos entenderem referências que se estendem por vários blocos.
Pedaços maiores mantêm mais contexto, o que permite informações contextuais mais ricas, mas podem ser menos focados e as informações podem se perder ao tentar codificar todas as informações em um único vetor.
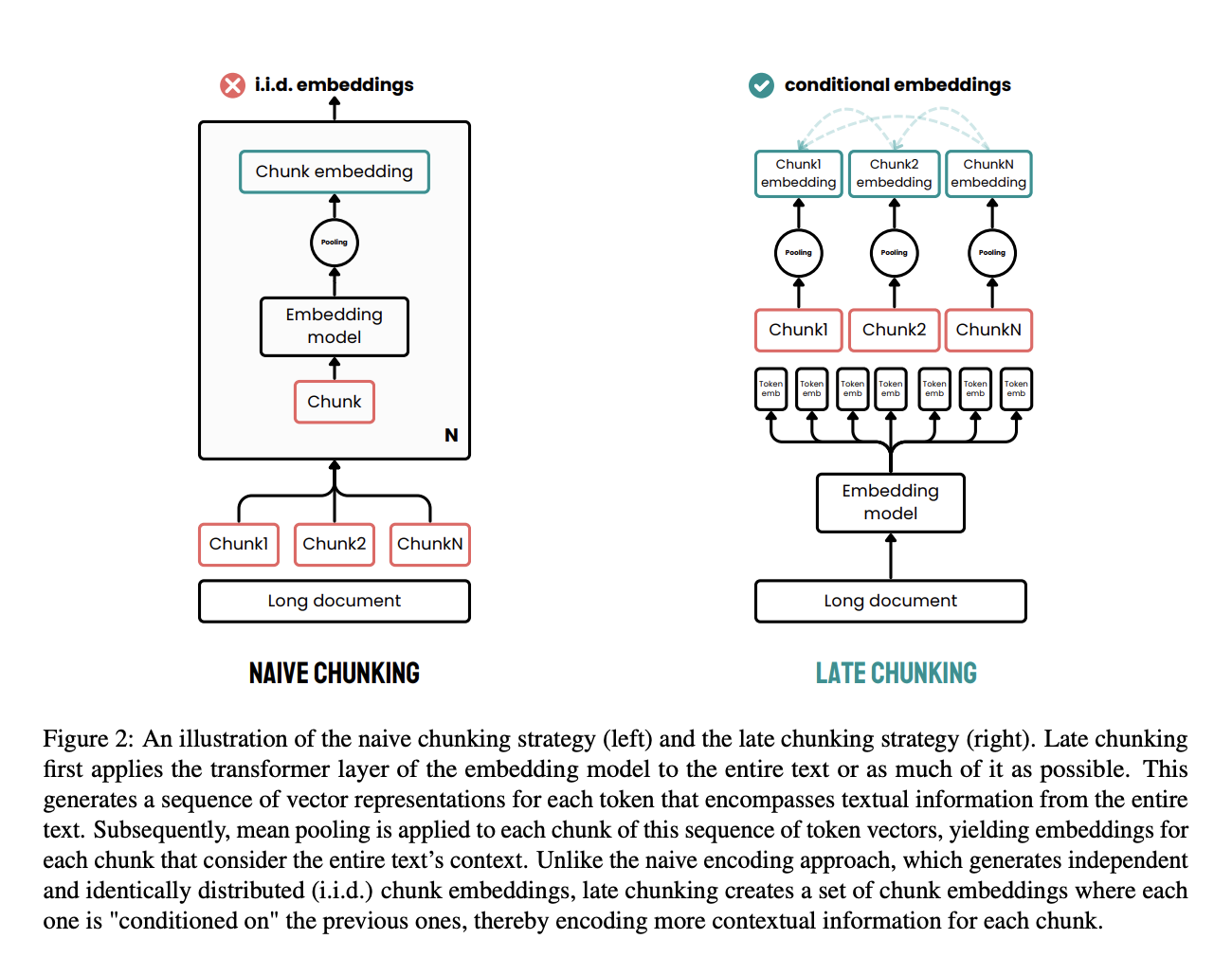
O chunking tardio é uma abordagem eficaz criada para resolver as limitações dos métodos tradicionais de chunking no processamento de documentos.
Nos métodos tradicionais, os documentos são primeiro divididos em partes, como frases ou parágrafos, antes de aplicar um modelo de incorporação. Esses pedaços são então codificados individualmente em vetores, muitas vezes usando agrupamento médio para criar uma única incorporação para cada pedaço. Essa abordagem pode levar à perda de dependências contextuais de longo alcance, porque as incorporações são geradas de forma independente, sem levar em conta todo o contexto do documento.
O chunking tardio usa uma abordagem diferente. Primeiro, aplica a camada transformadora do modelo de incorporação a todo o documento ou ao máximo possível dele, criando uma sequência de representações vetoriais para cada token. Esse método capta todo o contexto do texto nessas incorporações em nível de token.
Depois, a média é aplicada aos pedaços dessa sequência de vetores de tokens, produzindo incorporações para cada pedaço que são informadas pelo contexto de todo o documento. Diferente do método tradicional, o chunking tardio gera embeddings de chunks que dependem uns dos outros, mantendo mais informações contextuais e resolvendo dependências de longo alcance.
Ao aplicar o chunking mais tarde no processo, isso garante que a incorporação de cada chunk aproveite o contexto rico fornecido por todo o documento, em vez de ficar isolada. Essa abordagem resolve o problema da perda de contexto e melhora a qualidade das incorporações usadas para tarefas de recuperação e geração.
Fonte: Günther et al., 2024
Contextualização em RAG significa garantir que as informações recuperadas sejam relevantes para a consulta. Ao alinhar os dados recuperados com a consulta, o sistema gera respostas melhores e mais relevantes.
Isso diminui as chances de resultados errados ou sem sentido e garante que o resultado final seja do jeito que o usuário quer. Uma abordagem é usar um LLM para verificar se os documentos recuperados são relevantes antes de enviá-los para o modelo gerador, como demonstrado pelo Corrective RAG (CRAG).
Primeiro, é essencial construir a base de conhecimento de forma a filtrar conteúdos tendenciosos, garantindo que as informações sejam o mais objetivas possível. Você também pode treinar de novo o sistema de busca pra priorizar fontes equilibradas e imparciais.
Outra coisa importante seria contratar alguém só para ficar de olho em possíveis vieses e garantir que o resultado do modelo continue sendo objetivo.
Uma questão importante é manter os dados indexados atualizados com as informações mais recentes, o que exige um mecanismo de atualização confiável. Por isso, o controle de versão é super importante pra gerenciar as diferentes versões das informações e garantir que tudo fique consistente.
Além disso, o modelo precisa ser capaz de se adaptar a novas informações em tempo real, sem precisar ser treinado de novo com frequência, o que pode consumir muitos recursos. Esses desafios exigem soluções sofisticadas para garantir que o sistema continue preciso e relevante à medida que a base de conhecimento evolui.
CAG (Cache-Augmented Generation) é uma evolução do RAG, onde os documentos recuperados são resumidos ou compactados antes de serem passados para o LLM. Isso melhora a relevância, reduz o uso de tokens e ajuda a encaixar mais informações na janela de contexto do modelo.
A principal diferença é que, no CAG, o conteúdo recuperado passa por uma etapa intermediária, como um resumidor ou refinador de contexto, antes de ser enviado para o gerador. Já o RAG tradicional passa os documentos brutos direto para o prompt.
O CAG é especialmente útil quando:
Você está trabalhando com conjuntos de dados estáticos (por exemplo, catálogos de produtos, artigos acadêmicos) que podem ser pré-compactados e armazenados em cache.
A eficiência do token é super importante (por exemplo, APIs sensíveis ao custo ou inferência móvel/no dispositivo).
Os documentos recuperados são longos ou confusos e precisam ser resumidos.
Já o RAG é melhor quando:
Os dados de base são dinâmicos ou atualizados com frequência (por exemplo, tickets de suporte em tempo real, documentação ao vivo).
Você quer usar o conhecimento mais recente na hora da consulta, sem precisar refazer toda a base de conhecimento.
Resumindo, use CAG para domínios estáveis, onde você pode otimizar o contexto com antecedência, e RAG para cenários dinâmicos, onde a atualização e a recuperação sob demanda são mais importantes.
Dá uma olhada nesse artigo sobre RAG versus CAG pra ver uma comparação mais detalhada.
Tem vários sistemas RAG avançados.
Um desses sistemas é o Adaptive RAG (), onde o sistema não só pega as informações, mas também ajusta sua abordagem em tempo real com base na consulta. O RAG adaptativo pode decidir não fazer nenhuma recuperação, fazer uma única recuperação RAG ou fazer uma recuperação RAG iterativa. Esse jeito dinâmico de agir deixa o sistema RAG mais robusto e relevante para o que o usuário quer.
Outro sistema RAG avançado é o Agentic RAG, que traz os agentes de recuperação () — ferramentas que decidem se vão ou não pegar informações de uma fonte. Ao dar essa capacidade a um modelo de linguagem, ele pode decidir sozinho se precisa de mais informações, tornando o processo mais tranquilo.
O RAG corretivo (CRAG) também está ficando popular. Nessa abordagem, o sistema analisa os documentos que recupera, verificando sua relevância. Só os documentos que forem considerados relevantes vão ser enviados para o gerador. Essa etapa de autocorreção ajuda a garantir que informações precisas e relevantes sejam usadas. Para saber mais, dá uma olhada neste tutorial sobre Implementação do RAG corretivo (CRAG) com o LangGraph.
O Self-RAG vai além, avaliando não só os documentos encontrados, mas também as respostas finais geradas, garantindo que ambos estejam alinhados com a consulta do usuário. Isso leva a resultados mais confiáveis e consistentes.
Uma abordagem eficaz é pré-buscar informações relevantes e comumente solicitadas para que estejam prontas quando precisar. Além disso, refinar seus algoritmos de indexação e consulta pode fazer uma grande diferença na rapidez com que os dados são recuperados e processados.
Embora o RAG seja poderoso, ele tem várias limitações e desafios:
Dependência da qualidade dos dados recuperados: Um sistema RAG é tão bom quanto as informações que ele consegue. Se o recuperador puxar documentos irrelevantes ou incorretos, a resposta do gerador vai ser prejudicada. Garantir fontes de dados confiáveis e de alta qualidade (e ajustar o recuperador) é um desafio constante para evitar problemas de “lixo entra, lixo sai”.
Maior complexidade e latência: O RAG adiciona uma etapa extra de recuperação além da geração, o que torna todo o sistema mais complexo e pesado em termos computacionais do que um LLM independente. Pesquisar em uma base de conhecimento grande pode aumentar a latência e exigir muitos recursos de computação, então os sistemas RAG precisam equilibrar precisão e eficiência.
Precisa manter a base de conhecimento atualizada: Diferente dos LLMs estáticos, o RAG depende de um repositório de conhecimento externo que precisa ser atualizado e cuidado com frequência. As organizações precisam sempre pegar novos dados, tirar as informações que já não servem mais e cuidar dos índices. Sem fontes de dados confiáveis e atualizadas, um sistema RAG pode rapidamente se tornar menos eficaz ou até mesmo fornecer respostas desatualizadas.
Dificuldade de integração e ajuste: Juntar recuperação e geração significa mais coisas para ajustar e monitorar (o banco de dados vetorial, o modelo de recuperação e o LLM). Resolver erros pode ser mais complicado porque os problemas podem vir tanto do lado da recuperação quanto do lado da geração. Essa complexidade pode aumentar o esforço de desenvolvimento e manutenção em comparação com o uso exclusivo de um LLM.
Também vale a pena notar que, se os dados de um domínio forem bem estáticos e se encaixarem no treinamento do modelo, um LLM bem ajustado pode ser bom o suficiente no lugar do RAG. Mas, o ajuste fino não tem a capacidade do RAG de pegar novas informações na hora e pode ser mais caro treinar de novo a cada atualização de conhecimento.
Agora, vamos abordar algumas questões específicas destinadas àqueles que estão se candidatando a vagas de engenheiro de IA.
Aprenda IA com esses cursos!
Programa
Programa
Curso
blog
Hesam Sheikh Hassani
15 min
blog
Abid Ali Awan
15 min
blog
Austin Chia
15 min
blog
Matt Crabtree
8 min
blog
Elena Kosourova
15 min
blog
Javier Canales Luna
15 min


