
Programma
Sviluppare applicazioni AI
21 h
Iniziamo con una serie di domande fondamentali su RAG.
Un sistema RAG (retrieval-augmented generation) ha due componenti principali: il retriever e il generator.
Il retriever cerca e raccoglie informazioni rilevanti da fonti esterne, come database, documenti o siti web.
Il generator, di solito un modello linguistico avanzato, usa queste informazioni per creare testo chiaro e accurato.
Il retriever assicura che il sistema ottenga le informazioni più aggiornate, mentre il generator le combina con la propria conoscenza per produrre risposte migliori.
Insieme forniscono risposte più accurate di quelle che il solo generator potrebbe dare.
Se ti affidi solo alla conoscenza interna di un LLM, il sistema è limitato a ciò su cui è stato addestrato, che potrebbe essere obsoleto o poco dettagliato.
I sistemi RAG offrono un grande vantaggio attingendo a informazioni aggiornate da fonti esterne, producendo risposte più accurate e tempestive.
Questo approccio riduce anche le "allucinazioni"—errori in cui il modello inventa fatti—perché le risposte si basano su dati reali. RAG è particolarmente utile in settori specifici come il diritto, la medicina o la tecnologia, dove servono conoscenze specialistiche e aggiornate.
RAG è usato in numerose applicazioni AI reali in diversi ambiti:
Question answering e sistemi di supporto: RAG alimenta chatbot di assistenza clienti e assistenti per knowledge base recuperando documentazione aggiornata o FAQ e generando risposte accurate per gli utenti. Questo assicura che le richieste dei clienti vengano risolte con le informazioni più recenti (ad esempio, recuperando policy o dettagli di prodotto attuali).
Agenti conversazionali: Molti chatbot e assistenti virtuali usano RAG per fornire risposte fattuali e sensibili al contesto. Recuperando fatti rilevanti al volo, un agente conversazionale (come un chatbot per la sanità o la finanza) può dare risposte informate basate su fonti credibili.
Generazione e sintesi di contenuti: RAG aiuta a generare o riassumere contenuti con accuratezza fattuale. Per esempio, può recuperare parti di articoli di cronaca o paper di ricerca e produrre sintesi o report coerenti e verificati rispetto ai dati di partenza.
Ricerca specifica di dominio: In campi specializzati come diritto o medicina, i sistemi RAG aiutano attingendo a database di dominio (giurisprudenza, riviste mediche, ecc.) per rispondere a quesiti complessi. In questo modo, l'output del modello è ancorato a conoscenze affidabili e aggiornate, fondamentali per casi d'uso professionali.
I sistemi RAG possono raccogliere informazioni da fonti esterne sia strutturate che non strutturate:
Questa flessibilità consente di adattare i sistemi RAG a diversi settori, come quello legale o medico, attingendo a database di giurisprudenza, riviste di ricerca o dati di trial clinici.
Il prompt engineering aiuta i modelli linguistici a fornire risposte di alta qualità usando le informazioni recuperate. Come progetti il prompt può influire sulla pertinenza e sulla chiarezza dell'output.
In un sistema RAG, il retriever raccoglie informazioni rilevanti da fonti esterne che il generator utilizzerà. Esistono diversi modi per recuperare le informazioni.
Un metodo è il retrieval sparso, che abbina parole chiave (ad es., TF-IDF o BM25). È semplice ma può non cogliere il significato profondo delle parole.
Un altro approccio è il retrieval denso, che usa embedding neurali per comprendere il significato di documenti e query. Metodi come BERT o Dense Passage Retrieval (DPR) rappresentano i documenti come vettori in uno spazio condiviso, rendendo il retrieval più accurato.
La scelta tra questi metodi può influenzare molto le prestazioni del sistema RAG.
Combinare informazioni recuperate con la generazione di un LLM presenta alcune sfide. Per esempio, i dati recuperati devono essere altamente pertinenti alla query, perché dati non pertinenti possono confondere il modello e ridurre la qualità della risposta.
Inoltre, se le informazioni recuperate sono in conflitto con la conoscenza interna del modello, possono generare risposte confuse o imprecise. È quindi fondamentale risolvere questi conflitti senza confondere l'utente.
Infine, lo stile e il formato dei dati recuperati potrebbero non coincidere con la consueta scrittura o formattazione del modello, rendendo più difficile un'integrazione fluida delle informazioni.
In un sistema RAG, un database vettoriale aiuta a gestire e archiviare embedding densi di testo. Questi embedding sono rappresentazioni numeriche che catturano il significato di parole e frasi, create da modelli come BERT o OpenAI.
Quando si effettua una query, il suo embedding viene confrontato con quelli archiviati nel database per trovare documenti simili. Questo rende più rapido e accurato il recupero delle informazioni giuste. Questo processo aiuta il sistema a localizzare e recuperare rapidamente le informazioni più pertinenti, migliorando sia la velocità sia l'accuratezza del retrieval.
Per valutare un sistema RAG, devi considerare sia il componente di retrieval sia quello di generazione.
Per task downstream come il question answering, si possono usare anche metriche come F1 score, precisione e recall per valutare l'intero sistema RAG.
Gestire query ambigue o incomplete in un sistema RAG richiede strategie per assicurare che vengano recuperate informazioni pertinenti e accurate nonostante la scarsa chiarezza dell'input dell'utente.
Un approccio consiste nell'implementare tecniche di raffinamento della query, in cui il sistema suggerisce automaticamente chiarimenti o riformula la query ambigua in una più precisa basandosi su pattern noti o interazioni precedenti. Questo può includere domande di follow-up o la presentazione di più opzioni all'utente per restringere l'intento.
Un altro metodo è recuperare un set diversificato di documenti che coprano più possibili interpretazioni della query. Recuperando una gamma di risultati, il sistema si assicura che anche se la query è vaga, è probabile includere qualche informazione rilevante.
Infine, possiamo usare modelli di natural language understanding (NLU) per inferire l'intento dell'utente da query incomplete e affinare il processo di retrieval.
Ora che abbiamo coperto alcune domande base, passiamo a domande intermedie su RAG.
La scelta del retriever dipende dal tipo di dati con cui lavori, dalla natura delle query e dalle risorse computazionali disponibili.
Per query complesse che richiedono una profonda comprensione del significato dietro le parole, metodi di retrieval denso come BERT o DPR sono migliori. Questi metodi catturano il contesto e sono ideali per attività come il supporto clienti o la ricerca, dove conta comprendere i significati sottostanti.
Se il compito è più semplice e ruota attorno al matching di parole chiave, o se hai risorse limitate, metodi sparsi come BM25 o TF-IDF potrebbero essere più adatti. Sono più rapidi e facili da configurare, ma potrebbero non trovare documenti che non corrispondono alle parole chiave esatte.
Il compromesso principale tra retrieval denso e sparso è accuratezza contro costo computazionale. A volte, combinare entrambi gli approcci in un sistema ibrido può aiutare a bilanciare l'accuratezza con l'efficienza computazionale. Così ottieni i benefici di entrambi i metodi in base alle tue esigenze.
La ricerca ibrida combina i punti di forza dei metodi di retrieval denso e sparso.
Per esempio, puoi iniziare con un metodo sparso come BM25 per trovare rapidamente documenti in base alle parole chiave. Poi, un metodo denso come BERT ri-classifica quei documenti comprendendone il contesto e il significato. Ottieni così la velocità della ricerca sparsa e l'accuratezza dei metodi densi, ideale per query complesse e dataset di grandi dimensioni.
Un database vettoriale è ottimo per gestire embedding densi, ma non è sempre necessario. Le alternative includono:
La scelta giusta dipende dalle tue esigenze specifiche, come la scala dei dati e se serve comprensione semantica profonda.
Per assicurarti che le informazioni recuperate siano pertinenti e accurate, puoi adottare diversi approcci:
Quando si hanno a che fare con documenti lunghi o knowledge base ampie, ecco alcune tecniche utili:
Per ottenere il massimo in termini di accuratezza ed efficienza, puoi adottare diverse strategie:
Nelle conversazioni multi-turno (es. dialogo con un chatbot), un sistema RAG deve trasferire il contesto rilevante dai turni precedenti per rispondere correttamente alle domande successive. Per farlo, RAG può incorporare la cronologia della conversazione in ogni nuova query:
Raffinamento della query: Il sistema può riscrivere o arricchire automaticamente la domanda dell'utente usando le informazioni degli scambi precedenti. Aggiungendo dettagli dai turni passati, il retriever riceve una query più ricca di contesto, così può recuperare documenti pertinenti alla discussione in corso.
Inclusione della cronologia: Un altro approccio è fornire al modello un riepilogo o l'elenco dei turni precedenti come parte del contesto di input. Molte architetture RAG permettono di passare una sequenza di messaggi (storia utente e assistente) insieme alla nuova domanda. In questo modo, quando il retriever cerca informazioni, considera il contesto stabilito e il generator può mantenere una conversazione coerente.
Usando questi metodi, il sistema RAG tiene traccia di “chi ha detto cosa” e di ciò che è già stato risolto, evitando di dimenticare dettagli o ripetersi.
Finora abbiamo coperto domande base e intermedie su RAG, ora affrontiamo concetti più avanzati come le tecniche di chunking o la contestualizzazione.
Esistono vari modi per suddividere i documenti per retrieval ed elaborazione:
Chunk più piccoli, come frasi o brevi paragrafi, aiutano a evitare la diluizione di informazioni contestuali importanti quando compresse in un singolo vettore. Tuttavia, possono far perdere dipendenze a lungo raggio tra chunk, rendendo difficile comprendere riferimenti che si estendono su più chunk.
Chunk più grandi mantengono più contesto, consentendo informazioni più ricche, ma possono essere meno focalizzati e parte dell'informazione può perdersi cercando di codificare tutto in un unico vettore.
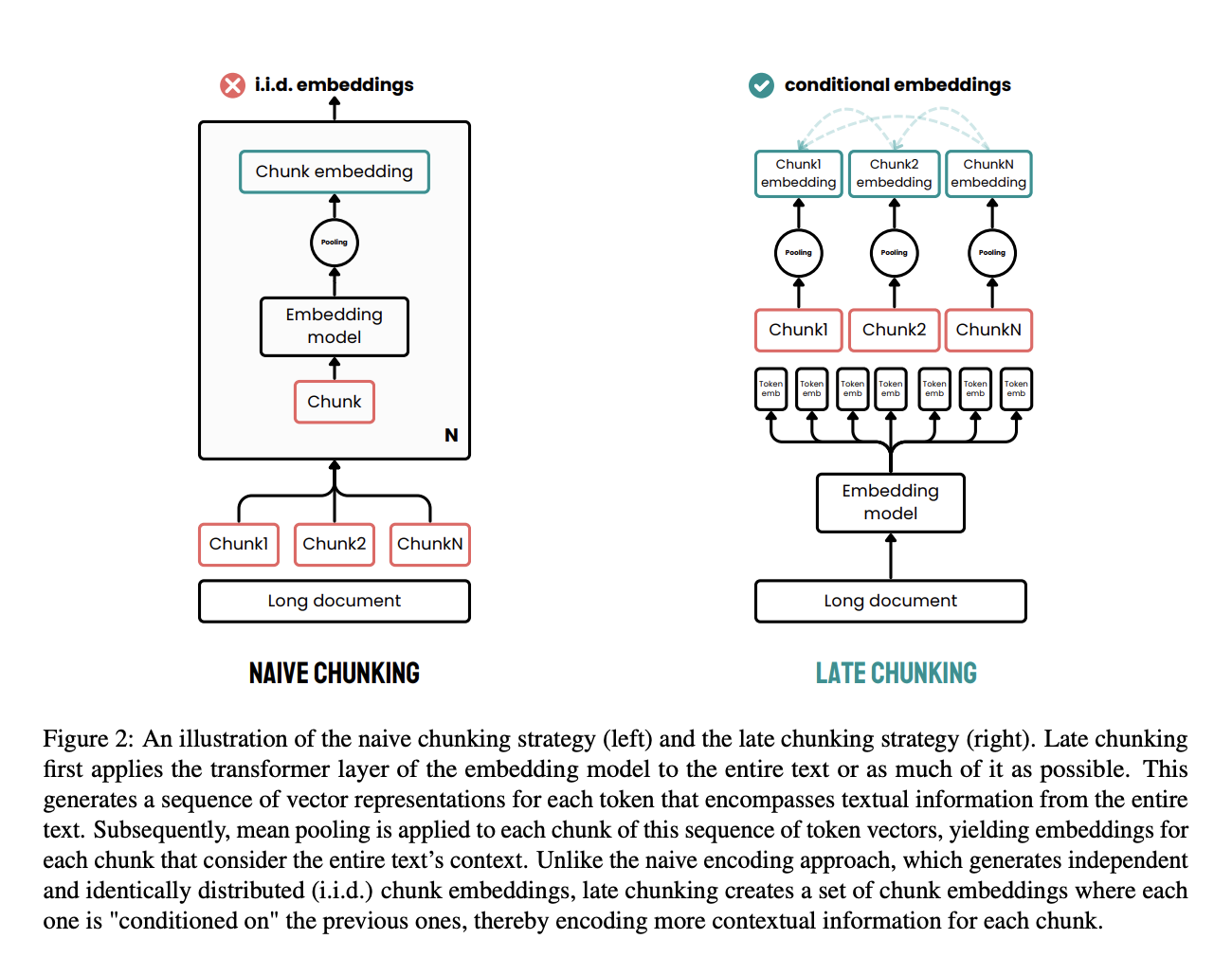
Il late chunking è un approccio efficace pensato per superare i limiti dei metodi tradizionali di chunking nel processamento dei documenti.
Nei metodi tradizionali, i documenti sono prima divisi in chunk, come frasi o paragrafi, prima di applicare un modello di embedding. Questi chunk sono poi codificati singolarmente in vettori, spesso usando il mean pooling per creare un singolo embedding per ogni chunk. Questo può portare a perdita di dipendenze contestuali a lungo raggio perché gli embedding sono generati in modo indipendente, senza considerare il contesto dell'intero documento.
Il late chunking adotta un approccio diverso. Applica prima il livello transformer del modello di embedding all'intero documento o a quanto più possibile, creando una sequenza di rappresentazioni vettoriali per ciascun token. Questo metodo cattura il contesto completo del testo in questi embedding a livello di token.
Successivamente, si applica il mean pooling ai chunk di questa sequenza di vettori di token, producendo embedding per ogni chunk informati dal contesto dell'intero documento. A differenza del metodo tradizionale, il late chunking genera embedding dei chunk condizionati gli uni agli altri, preservando più informazioni contestuali e risolvendo dipendenze a lungo raggio.
Applicando il chunking più avanti nel processo, si garantisce che l'embedding di ciascun chunk benefici del ricco contesto fornito dall'intero documento, invece di essere isolato. Questo approccio affronta il problema della perdita di contesto e migliora la qualità degli embedding usati per retrieval e generazione.
Fonte: Günther et al., 2024
La contestualizzazione in RAG significa garantire che le informazioni recuperate siano pertinenti alla query. Allineando i dati recuperati con la query, il sistema produce risposte migliori e più rilevanti.
Questo riduce le probabilità di risultati errati o irrilevanti e assicura che l'output risponda alle esigenze dell'utente. Un approccio consiste nell'usare un LLM per verificare se i documenti recuperati sono pertinenti prima di inviarli al modello generatore, come dimostra il Corrective RAG (CRAG).
Per prima cosa, è essenziale costruire la knowledge base filtrando contenuti faziosi, assicurando che le informazioni siano il più possibile oggettive. Puoi anche riaddestrare il sistema di retrieval per dare priorità a fonti equilibrate e non di parte.
Un altro passo importante può essere adottare un agente dedicato a controllare potenziali bias e garantire che l'output del modello resti obiettivo.
Un problema importante è mantenere i dati indicizzati aggiornati con le ultime informazioni, il che richiede un meccanismo di aggiornamento affidabile. Di conseguenza, il controllo di versione diventa cruciale per gestire diverse iterazioni di informazione e garantire coerenza.
Inoltre, il modello deve potersi adattare in tempo reale a nuove informazioni senza dover essere riaddestrato frequentemente, operazione che può essere onerosa. Queste sfide richiedono soluzioni sofisticate per mantenere il sistema accurato e pertinente man mano che la knowledge base evolve.
CAG (Cache-Augmented Generation) è un'evoluzione di RAG in cui i documenti recuperati vengono riassunti o compressi prima di essere passati all'LLM. Questo migliora la pertinenza, riduce l'uso di token e aiuta a inserire più informazioni nella finestra di contesto del modello.
La differenza chiave è che in CAG il contenuto recuperato passa attraverso uno step intermedio, come un riassuntore o un raffinatore di contesto, prima di essere fornito al generatore. Nel RAG tradizionale, invece, i documenti grezzi vengono passati direttamente nel prompt.
CAG è particolarmente utile quando:
Lavori con dataset statici (ad es., cataloghi prodotto, paper accademici) che possono essere precompressi e messi in cache.
L'efficienza in termini di token è critica (ad es., API sensibili ai costi o inferenza su mobile/on-device).
I documenti recuperati sono lunghi o rumorosi e necessitano di distillazione.
RAG, invece, è preferibile quando:
I dati sottostanti sono dinamici o frequentemente aggiornati (ad es., ticket di supporto in tempo reale, documentazione live).
Vuoi incorporare la conoscenza più fresca al momento della query, senza rielaborare l'intera knowledge base.
In breve, usa CAG per domini stabili in cui puoi ottimizzare il contesto in anticipo, e RAG per scenari dinamici in cui contano freschezza e retrieval on-demand.
Dai un'occhiata a questo articolo su RAG versus CAG per un confronto più dettagliato.
Esistono molti sistemi RAG avanzati.
Uno è l'Adaptive RAG, in cui il sistema non solo recupera informazioni ma adatta in tempo reale il proprio approccio in base alla query. L'Adaptive RAG può decidere di non fare retrieval, di eseguire RAG a singolo passaggio o RAG iterativo. Questo comportamento dinamico rende il sistema più robusto e pertinente alla richiesta dell'utente.
Un altro sistema avanzato è l'Agentic RAG, che introduce retrieval agent—strumenti che decidono se attingere o meno a una fonte. Dando questa capacità a un modello linguistico, può determinare autonomamente se ha bisogno di informazioni aggiuntive, rendendo il processo più fluido.
Corrective RAG (CRAG) sta diventando popolare. In questo approccio, il sistema rivede i documenti recuperati verificandone la pertinenza. Solo i documenti classificati come pertinenti vengono passati al generatore. Questo step di autocorrezione aiuta a garantire l'uso di informazioni accurate e rilevanti. Per saperne di più, leggi questo tutorial su Implementazione di Corrective RAG (CRAG) con LangGraph.
Self-RAG fa un passo oltre valutando non solo i documenti recuperati ma anche le risposte finali generate, assicurando che entrambe siano allineate alla query dell'utente. Questo porta a risultati più affidabili e coerenti.
Un approccio efficace è il prefetching di informazioni rilevanti e spesso richieste, così sono pronte quando servono. Inoltre, affinare l'indicizzazione e gli algoritmi di query può fare una grande differenza nella rapidità di recupero ed elaborazione dei dati.
Pur essendo potente, RAG presenta diversi limiti e sfide:
Dipendenza dalla qualità dei dati recuperati: Un sistema RAG è valido quanto le informazioni che recupera. Se il retriever porta documenti irrilevanti o errati, anche la risposta del generator ne risentirà. Garantire fonti dati di alta qualità e affidabili (e fare fine-tuning del retriever) è una sfida continua per evitare il classico garbage-in, garbage-out.
Aumentata complessità e latenza: RAG introduce uno step di retrieval oltre alla generazione, rendendo il sistema più complesso e oneroso computazionalmente di un LLM standalone. Cercare in una knowledge base ampia può aggiungere latenza e richiedere risorse, quindi i sistemi RAG devono bilanciare accuratezza ed efficienza.
Necessità di manutenzione della knowledge base: A differenza degli LLM statici, RAG dipende da un repository esterno che va aggiornato e curato regolarmente. Le organizzazioni devono ingestire continuamente nuovi dati, rimuovere informazioni obsolete e gestire gli indici. Senza fonti affidabili e aggiornate, un sistema RAG può rapidamente diventare meno efficace o fornire risposte datate.
Difficoltà di integrazione e tuning: Combinare retrieval e generazione significa più componenti da ottimizzare e monitorare (database vettoriale, modello di retrieval e LLM). La diagnosi degli errori è più difficile perché i problemi possono derivare dal lato retrieval o da quello di generazione. Questa complessità aumenta gli sforzi di sviluppo e manutenzione rispetto all'uso di un solo LLM.
Vale anche la pena notare che, se i dati di un dominio sono in gran parte statici e rientrano nell'addestramento del modello, un LLM fine-tunato potrebbe bastare al posto di RAG. Tuttavia, il fine-tuning non ha la capacità di RAG di incorporare informazioni fresche al volo e può risultare più costoso da riaddestrare a ogni aggiornamento della conoscenza.
Ora affrontiamo alcune domande specifiche per chi sostiene colloqui per posizioni di AI Engineer.
Impara l'AI con questi corsi!
Programma
Programma
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

