
Cursus
Développer des applications d'IA
21 h
Commençons par une série de questions fondamentales concernant le RAG.
Un système RAG (génération augmentée par la recherche) comporte deux composants principaux : le récupérateur et le générateur.
Le récupérateur recherche et collecte des informations pertinentes à partir de sources externes, telles que des bases de données. bases de données, des documents ou des sites web.
Le générateur, généralement un modèle linguistique avancé, utilise ces informations pour créer un texte clair et précis.
Le récupérateur s'assure que le système obtient les informations les plus récentes, tandis que le générateur les combine avec ses propres connaissances pour produire de meilleures réponses.
Ensemble, ils fournissent des réponses plus précises que celles que le générateur pourrait fournir seul.
Si vous vous fiez uniquement aux connaissances intégrées d'un LLM, le système est limité à ce sur quoi il a été formé, ce qui peut être obsolète ou manquer de détails.
Les systèmes RAG offrent un avantage considérable en recueillant des informations récentes provenant de sources externes, ce qui permet d'obtenir des réponses plus précises et plus rapides.
Cette approche réduit également les « hallucinations » — erreurs dans lesquelles le modèle invente des faits — car les réponses sont basées sur des données réelles. Le RAG est particulièrement utile dans des domaines spécifiques tels que le droit, la médecine, etc. médecineou la technologie, où des connaissances spécialisées et actualisées sont nécessaires.
Le RAG est utilisé dans diverses applications concrètes de l'IA dans différents domaines :
Systèmes de réponse aux questions et d'assistance : RAG alimente les chatbots d'assistance à la clientèle et les assistants de base de connaissances en récupérant de la documentation ou des FAQ à jour et en générant des réponses précises pour les utilisateurs. Cela garantit que les demandes des clients sont traitées à l'aide des informations les plus récentes (par exemple, en récupérant les informations actuelles sur les polices ou les détails des produits).
Agents conversationnels : De nombreux chatbots et assistants virtuels utilisent le RAG pour fournir des réponses factuelles et adaptées au contexte. En récupérant des informations pertinentes à la volée, un agent conversationnel (tel qu'un chatbot dédié à la santé ou à la finance) peut fournir des réponses éclairées s'appuyant sur des sources fiables.
Génération et résumé de contenu : RAG facilite la génération ou la synthèse de contenu avec une grande précision factuelle. Par exemple, il peut extraire des parties d'articles d'actualité ou de documents de recherche, puis produire des résumés ou des rapports cohérents et vérifiés par rapport aux données sources.
Recherche spécifique à un domaine : Dans des domaines spécialisés tels que le droit ou la médecine, les systèmes RAG apportent leur aide en puisant dans des bases de données spécifiques (jurisprudence, revues médicales, etc.) afin de répondre à des requêtes complexes. De cette manière, les résultats du modèle s'appuient sur des connaissances fiables et actualisées dans le domaine, ce qui est essentiel pour les cas d'utilisation professionnels.
Les systèmes RAG peuvent collecter des informations provenant de sources externes structurées et non structurées :
Cette flexibilité permet d'adapter les systèmes RAG à différents domaines, tels que l'utilisation juridique ou médicale, en puisant dans des bases de données jurisprudentielles, des revues de recherche ou des données d'essais cliniques.
L'ingénierie des invites aide les modèles linguistiques à fournir des réponses de haute qualité à partir des informations récupérées. La manière dont vous concevez une invite peut influencer la pertinence et la clarté du résultat.
Dans un système RAG, le récupérateur rassemble des informations pertinentes provenant de sources externes afin que le générateur puisse les utiliser. Il existe différentes méthodes pour récupérer des informations.
Une méthode est la recherche clairsemée, qui correspond à des mots-clés (par exemple, TF-IDF ou BM25). C'est simple, mais cela ne rend peut-être pas compte de la signification profonde des mots.
Une autre approche est la recherche dense, qui utilise des intégrations neuronales pour comprendre la signification des documents et des requêtes. Des méthodes telles que BERT ou Dense Passage Retrieval (DPR) représentent les documents sous forme de vecteurs dans un espace partagé, ce qui rend la recherche plus précise.
Le choix entre ces méthodes peut considérablement influencer l'efficacité du système RAG.
La combinaison des informations récupérées avec la génération d'un LLM présente certains défis. Par exemple, les données récupérées doivent être hautement pertinentes par rapport à la requête, car des données non pertinentes peuvent perturber le modèle et réduire la qualité de la réponse.
De plus, si les informations récupérées entrent en conflit avec les connaissances internes du modèle, cela peut générer des réponses confuses ou inexactes. Il est donc essentiel de résoudre ces conflits sans semer la confusion chez l'utilisateur.
Enfin, le style et le format des données récupérées peuvent ne pas toujours correspondre à la manière habituelle dont le modèle rédige ou formate, ce qui peut compliquer l'intégration harmonieuse de ces informations par le modèle.
Dans un système RAG, une base de données vectorielle facilite la gestion et le stockage d'des intégrations de texte. Ces intégrations sont des représentations numériques qui capturent la signification des mots et des expressions, créées par des modèles tels que BERT ou OpenAI.
Lorsqu'une requête est effectuée, son intégration est comparée à celles stockées dans la base de données afin de trouver des documents similaires. Cela permet de récupérer les informations pertinentes plus rapidement et avec plus de précision. Ce processus permet au système de localiser et d'extraire rapidement les informations les plus pertinentes, améliorant ainsi la rapidité et la précision de la recherche.
Pour évaluer un système RAG, il est nécessaire d'examiner à la fois les composants de récupération et de génération.
Pour les tâches en aval telles que les questions-réponses, des mesures telles que score F1et la précisionet le rappel peuvent également être utilisés pour évaluer le système RAG dans son ensemble.
Le traitement des requêtes ambiguës ou incomplètes dans un système RAG nécessite des stratégies visant à garantir la récupération d'informations pertinentes et précises malgré le manque de clarté de la saisie de l'utilisateur.
Une approche consiste à mettre en œuvre des techniques de raffinement des requêtes, dans lesquelles le système suggère automatiquement des clarifications ou reformule la requête ambiguë en une requête plus précise, sur la base de modèles connus ou d'interactions précédentes. Cela peut impliquer de poser des questions complémentaires ou de proposer à l'utilisateur plusieurs options afin de préciser son intention.
Une autre méthode consiste à récupérer un ensemble varié de documents couvrant plusieurs interprétations possibles de la requête. En récupérant une série de résultats, le système garantit que, même si la requête est vague, certaines informations pertinentes sont susceptibles d'être incluses.
Enfin, nous pouvons utiliser la des modèles de compréhension du langage naturel (NLU) pour déduire l'intention de l'utilisateur à partir de requêtes incomplètes et affiner le processus de recherche.
Maintenant que nous avons abordé quelques questions fondamentales, il est temps de passer aux questions d'entretien RAG de niveau intermédiaire.
Le choix du récupérateur approprié dépend du type de données que vous traitez, de la nature des requêtes et de la puissance de calcul dont vous disposez.
Pour les requêtes complexes qui nécessitent une compréhension approfondie du sens des mots, des méthodes de recherche dense telles que BERT ou DPR sont plus appropriées. Ces méthodes permettent de saisir le contexte et sont idéales pour des tâches telles que le service client ou la recherche, où il est essentiel de comprendre les significations sous-jacentes.
Si la tâche est plus simple et concerne principalement la correspondance de mots-clés, ou si vos ressources informatiques sont limitées, les méthodes de recherche clairsemée telles que BM25 ou TF-IDF pourraient être plus appropriées. Ces méthodes sont plus rapides et plus faciles à mettre en place, mais elles peuvent ne pas permettre de trouver les documents qui ne correspondent pas exactement aux mots-clés.
Le principal compromis entre les méthodes de recherche dense et clairsemée réside dans la précision par rapport au coût de calcul. Parfois, la combinaison des deux approches dans un système de recherche hybride peut contribuer à équilibrer la précision et l'efficacité de calcul. efficacité informatique. De cette manière, vous bénéficiez des avantages des méthodes denses et clairsemées en fonction de vos besoins.
La recherche hybride combine les avantages des méthodes de recherche dense et clairsemée.
Par exemple, vous pouvez commencer par une méthode clairsemée telle que BM25 pour trouver rapidement des documents en fonction de mots-clés. Ensuite, une méthode dense telle que BERT reclasse ces documents en comprenant leur contexte et leur signification. Cela vous offre la rapidité d'une recherche clairsemée avec la précision des méthodes denses, ce qui est idéal pour les requêtes complexes et les grands ensembles de données.
Une base de données vectorielle est très utile pour gérer des intégrations denses, mais elle n'est pas toujours nécessaire. Les alternatives comprennent :
Le choix approprié dépend de vos besoins spécifiques, tels que le volume de vos données et la nécessité ou non d'une compréhension sémantique approfondie.
Afin de garantir la pertinence et l'exactitude des informations récupérées, plusieurs approches sont possibles :
Lorsque vous traitez des documents volumineux ou des bases de connaissances étendues, voici quelques techniques utiles :
Pour obtenir les meilleures performances d'un système RAG en termes de précision et d'efficacité, plusieurs stratégies peuvent être utilisées :
Dans les conversations à plusieurs tours (par exemple, un dialogue avec un chatbot), un système RAG doit conserver le contexte pertinent des tours précédents afin de répondre correctement aux questions suivantes. Pour ce faire, RAG peut intégrer l'historique des conversations dans chaque nouvelle requête :
Affiner la requête : Le système peut automatiquement reformuler ou compléter la question de l'utilisateur à l'aide des informations issues des échanges précédents. En ajoutant des détails provenant des tours précédents, le système de recherche obtient une requête plus riche en contexte, ce qui lui permet de récupérer des documents pertinents pour la discussion en cours.
Y compris l'historique des conversations : Une autre approche consiste à fournir au modèle un résumé ou une liste des tours de dialogue précédents dans le cadre de son contexte d'entrée. De nombreuses architectures RAG permettent de transmettre une séquence de messages (historique de l'utilisateur et de l'assistant) avec la nouvelle question. De cette manière, lorsque le récupérateur recherche des informations, il tient compte du contexte établi, et le générateur peut utiliser le contexte passé pour maintenir une conversation cohérente.
En utilisant ces méthodes, le système RAG garde une trace de « qui a dit quoi » et de ce qui a déjà été résolu. Cela lui évite d'oublier des détails ou de se répéter.
Jusqu'à présent, nous avons abordé les questions d'entretien RAG de niveau débutant et intermédiaire. Nous allons maintenant aborder des concepts plus avancés tels que les techniques de segmentation ou la contextualisation.
Il existe plusieurs méthodes pour décomposer les documents en vue de leur récupération et de leur traitement :
Les segments plus courts, tels que les phrases ou les paragraphes courts, permettent d'éviter la dilution d'informations contextuelles importantes lorsqu'ils sont compressés en un seul vecteur. Cependant, cela peut entraîner la perte de dépendances à long terme entre les segments, ce qui complique la compréhension par les modèles des références qui s'étendent sur plusieurs segments.
Les segments plus longs conservent davantage de contexte, ce qui permet d'obtenir des informations contextuelles plus riches, mais peuvent être moins ciblés et certaines informations peuvent être perdues lorsque l'on tente de coder toutes les informations dans un seul vecteur.
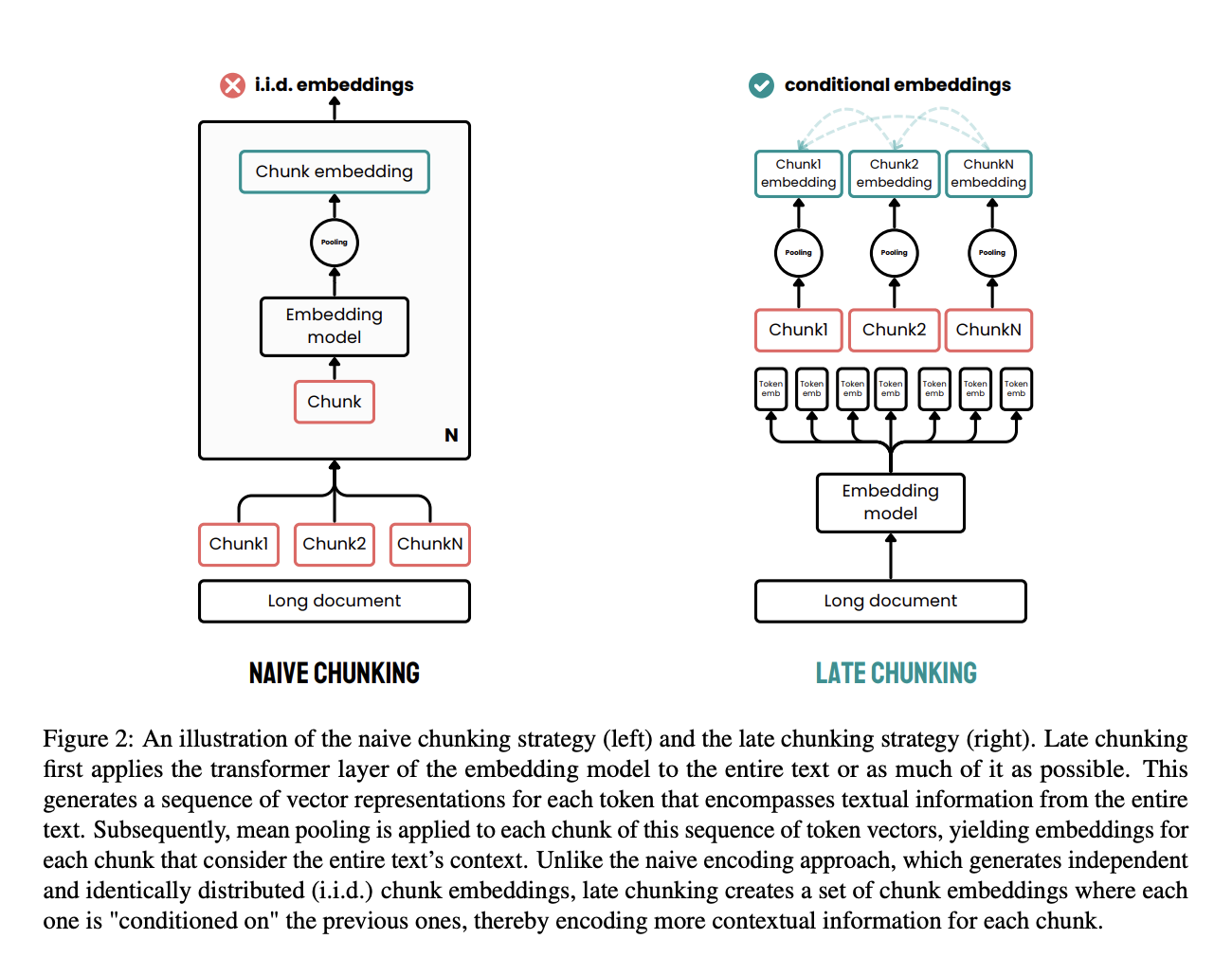
Le chunking tardif est une approche efficace conçue pour pallier les limites des méthodes traditionnelles de chunking dans le traitement des documents.
Dans les méthodes traditionnelles, les documents sont d'abord divisés en segments, tels que des phrases ou des paragraphes, avant d'appliquer un modèle d'intégration. Ces segments sont ensuite codés individuellement en vecteurs, souvent à l'aide d'un regroupement moyen afin de créer un seul encodage pour chaque segment. Cette approche peut entraîner une perte des dépendances contextuelles à longue distance, car les intégrations sont générées indépendamment, sans tenir compte du contexte complet du document.
Le chunking tardif adopte une approche différente. Il applique d'abord la couche de transformation du modèle d'intégration à l'ensemble du document ou à la plus grande partie possible de celui-ci, créant ainsi une séquence de représentations vectorielles pour chaque token. Cette méthode permet de saisir le contexte complet du texte dans ces intégrations au niveau des tokens.
Ensuite, un regroupement moyen est appliqué aux segments de cette séquence de vecteurs de tokens, produisant des intégrations pour chaque segment qui sont informées par le contexte global du document. Contrairement à la méthode traditionnelle, le chunking tardif génère des intégrations de chunks qui sont conditionnées les unes par les autres, préservant ainsi davantage d'informations contextuelles et résolvant les dépendances à long terme.
En appliquant le découpage en morceaux plus tard dans le processus, on s'assure que l'intégration de chaque morceau bénéficie du contexte riche fourni par l'ensemble du document, plutôt que d'être isolée. Cette approche résout le problème de la perte de contexte et améliore la qualité des intégrations utilisées pour les tâches de recherche et de génération.
Source : Günther et al., 2024
Dans le cadre du RAG, la contextualisation consiste à s'assurer que les informations récupérées sont pertinentes par rapport à la requête. En alignant les données récupérées avec la requête, le système génère des réponses plus pertinentes et de meilleure qualité.
Cela réduit les risques d'obtenir des résultats incorrects ou non pertinents et garantit que le résultat correspond aux besoins de l'utilisateur. Une approche consiste à utiliser un LLM pour vérifier si les documents récupérés sont pertinents avant de les envoyer au modèle générateur, comme le démontre le Corrective RAG (CRAG).
Tout d'abord, il est essentiel de constituer la base de connaissances de manière à filtrer les contenus biaisés, en veillant à ce que les informations soient aussi objectives que possible. Vous pouvez également rééduquer le système de recherche afin qu'il privilégie les sources équilibrées et impartiales.
Une autre mesure importante pourrait être d'adopter un agent spécifiquement chargé de vérifier les biais potentiels et de s'assurer que les résultats du modèle restent objectifs.
L'un des principaux enjeux consiste à maintenir les données indexées à jour avec les informations les plus récentes, ce qui nécessite un mécanisme de mise à jour fiable. À ce titre, le contrôle de version devient essentiel pour gérer les différentes itérations d'informations et garantir la cohérence.
De plus, le modèle doit être capable de s'adapter en temps réel aux nouvelles informations sans nécessiter de réentraînement fréquent, ce qui peut être coûteux en ressources. Ces défis nécessitent des solutions sophistiquées afin de garantir que le système reste précis et pertinent à mesure que la base de connaissances évolue.
Le CAG (Cache-Augmented Generation) est une évolution du RAG dans laquelle les documents récupérés sont résumés ou compressés avant d'être transmis au LLM. Cela améliore la pertinence, réduit l'utilisation des jetons et permet d'intégrer davantage d'informations dans la fenêtre contextuelle du modèle.
La principale différence réside dans le fait que, dans le CAG, le contenu récupéré passe par une étape intermédiaire, telle qu'un résumeur ou un affineur de contexte, avant d'être transmis au générateur. En revanche, le RAG traditionnel transmet directement les documents bruts dans l'invite.
Le CAG est particulièrement utile lorsque :
Vous travaillez avec des ensembles de données statiques (par exemple, des catalogues de produits, des articles universitaires) qui peuvent être précompressés et mis en cache.
L'efficacité des jetons est essentielle (par exemple, API sensibles au coût ou inférence mobile/sur appareil).
Les documents récupérés sont volumineux ou contiennent des informations superflues et nécessitent une synthèse.
RAG, d'autre part, est préférable lorsque :
Les données sous-jacentes sont dynamiques ou fréquemment mises à jour (par exemple, tickets d'assistance en temps réel, documentation en direct).
Vous souhaitez intégrer les connaissances les plus récentes au moment de la requête, sans retraiter l'ensemble de la base de connaissances.
En résumé, veuillez utiliser CAG pour les domaines stables où vous pouvez optimiser le contexte à l'avance, et RAG pour les scénarios dynamiques où la fraîcheur et la récupération à la demande sont plus importantes.
Veuillez consulter cet article sur RAG versus CAG pour une comparaison plus détaillée.
Il existe de nombreux systèmes RAG avancés.
L'un de ces systèmes est l'Adaptive RAG (), qui non seulement récupère des informations, mais adapte également son approche en temps réel en fonction de la requête. Le RAG adaptatif peut choisir de ne pas effectuer de recherche, d'effectuer un RAG unique ou un RAG itératif. Ce comportement dynamique rend le système RAG plus robuste et plus pertinent par rapport à la demande de l'utilisateur.
Un autre système RAG avancé est Agentic RAG, qui introduit des agents de recherche (), des outils qui déterminent s'il convient ou non d'extraire des informations d'une source. En dotant un modèle linguistique de cette capacité, il peut déterminer de manière autonome s'il a besoin d'informations supplémentaires, ce qui fluidifie le processus.
L', également appelée RAG corrective (CRAG), gagne également en popularité. Dans cette approche, le système examine les documents qu'il récupère afin d'en vérifier la pertinence. Seuls les documents jugés pertinents seront transmis au générateur. Cette étape d'autocorrection contribue à garantir l'utilisation d'informations pertinentes et précises. Pour en savoir plus, veuillez consulter ce tutoriel sur la mise en œuvre du Mise en œuvre du RAG correctif (CRAG) avec LangGraph.
L'auto-évaluation ( ) va encore plus loin en évaluant non seulement les documents récupérés, mais également les réponses finales générées, afin de s'assurer que les deux correspondent à la requête de l'utilisateur. Cela permet d'obtenir des résultats plus fiables et plus cohérents.
Une approche efficace consiste à précharger les informations pertinentes et fréquemment demandées afin qu'elles soient disponibles dès que nécessaire. De plus, l'optimisation de vos algorithmes d'indexation et de requête peut considérablement améliorer la rapidité de récupération et de traitement des données.
Bien que le RAG soit puissant, il présente plusieurs limites et défis :
Dépendance à l'égard de la qualité des données récupérées : La qualité d'un système RAG dépend de la qualité des informations qu'il récupère. Si le récupérateur extrait des documents non pertinents ou incorrects, la réponse du générateur en sera affectée. Garantir des sources de données fiables et de haute qualité (et affiner le moteur de recherche) constitue un défi permanent pour éviter les problèmes liés à la qualité des données d'entrée et de sortie.
Complexité et latence accrues : RAG introduit une étape de récupération supplémentaire en plus de la génération, ce qui rend l'ensemble du système plus complexe et plus lourd en termes de calcul qu'un LLM autonome. La recherche dans une base de connaissances volumineuse peut entraîner une latence et nécessiter d'importantes ressources informatiques. Les systèmes RAG doivent donc trouver un équilibre entre précision et efficacité.
Nécessité de maintenir la base de connaissances : Contrairement aux LLM statiques, le RAG dépend d'un référentiel de connaissances externe qui nécessite des mises à jour et une curation régulières. Les organisations doivent continuellement intégrer de nouvelles données, supprimer les informations obsolètes et gérer les index. Sans sources de données fiables et actualisées, un système RAG peut rapidement perdre en efficacité, voire fournir des réponses obsolètes.
Difficultés d'intégration et de réglage : La combinaison de la récupération et de la génération implique davantage de composants à régler et à surveiller (la base de données vectorielle, le modèle de récupération et le LLM). Le dépannage des erreurs peut s'avérer plus complexe, car les problèmes peuvent provenir du côté de la récupération ou de la génération. Cette complexité peut augmenter les efforts de développement et de maintenance par rapport à l'utilisation d'un LLM seul.
Il convient également de noter que si les données d'un domaine sont largement statiques et correspondent à la formation du modèle, un LLM finement ajusté pourrait être suffisant à la place du RAG. Cependant, le réglage fin ne dispose pas de la capacité du RAG à intégrer de nouvelles informations à la volée et peut s'avérer plus coûteux à réentraîner à chaque mise à jour des connaissances.
À présent, abordons quelques questions spécifiques destinées aux candidats postulant à des postes d'ingénieur en intelligence artificielle.
Apprenez l'IA grâce à ces cours.
Cursus
Cursus
Cours
blog
Nisha Arya Ahmed
15 min
blog
Lynn Heidmann
blog
blog
Kurtis Pykes
9 min
Tutoriel

