
programa
Desarrollo de aplicaciones de IA
21 h
Comencemos con una serie de preguntas fundamentales para la entrevista sobre RAG.
Un sistema RAG (generación aumentada por recuperación) tiene dos componentes principales: el recuperador y el generador.
El recuperador busca y recopila información relevante de fuentes externas, como bases de datos, documentos o sitios web.
El generador, normalmente un modelo lingüístico avanzado, utiliza esta información para crear un texto claro y preciso.
El recuperador se asegura de que el sistema obtenga la información más actualizada, mientras que el generador la combina con sus propios conocimientos para producir mejores respuestas.
Juntos, proporcionan respuestas más precisas que las que podría dar el generador por sí solo.
Si solo te basas en el conocimiento integrado de un LLM, el sistema se limita a aquello para lo que ha sido entrenado, lo que podría estar desactualizado o carecer de detalles.
Los sistemas RAG ofrecen una gran ventaja al recopilar información nueva de fuentes externas, lo que se traduce en respuestas más precisas y oportunas.
Este enfoque también reduce las «alucinaciones» (errores en los que el modelo inventa datos), ya que las respuestas se basan en datos reales. RAG es especialmente útil para campos específicos como el derecho, medicinao tecnología, donde se necesitan conocimientos especializados y actualizados.
RAG se utiliza en diversas aplicaciones de IA del mundo real en diferentes ámbitos:
Sistemas de respuesta a preguntas y asistencia: RAG potencia los chatbots de atención al cliente y los asistentes de bases de conocimiento mediante la recuperación de documentación actualizada o preguntas frecuentes y la generación de respuestas precisas para los usuarios. Esto garantiza que las consultas de los clientes se resuelvan con la información más reciente (por ejemplo, obteniendo información actualizada sobre pólizas o detalles de productos).
Agentes conversacionales: Muchos chatbots y asistentes virtuales utilizan RAG para proporcionar respuestas objetivas y contextuales. Al recopilar datos relevantes sobre la marcha, un agente conversacional (como un chatbot de atención médica o finanzas) puede dar respuestas fundamentadas basadas en fuentes fiables.
Generación y resumen de contenido: RAG ayuda a generar o resumir contenido con precisión factual. Por ejemplo, puede recuperar partes de artículos periodísticos o trabajos de investigación y luego elaborar resúmenes o informes que sean coherentes y cuyas fuentes hayan sido verificadas.
Investigación específica del dominio: En campos especializados como el derecho o la medicina, los sistemas RAG ayudan a responder consultas complejas recurriendo a bases de datos específicas del ámbito (jurisprudencia, revistas médicas, etc.). De esta manera, los resultados del modelo se basan en conocimientos fiables y actualizados sobre el ámbito, lo cual es importante para los casos de uso profesional.
Los sistemas RAG pueden recopilar información tanto de fuentes externas estructuradas como no estructuradas:
Esta flexibilidad permite adaptar los sistemas RAG a diferentes campos, como el jurídico o el médico, recurriendo a bases de datos de jurisprudencia, revistas de investigación o datos de ensayos clínicos.
La ingeniería de prompts ayuda a los modelos lingüísticos a proporcionar respuestas de alta calidad utilizando la información recuperada. La forma en que diseñes una indicación puede afectar a la relevancia y claridad del resultado.
En un sistema RAG, el recuperador recopila información relevante de fuentes externas para que la utilice el generador. Hay diferentes maneras de recuperar información.
Un método es la recuperación dispersa, que compara palabras clave (por ejemplo, TF-IDF o BM25). Esto es sencillo, pero puede que no capte el significado más profundo que hay detrás de las palabras.
Otro enfoque es la recuperación densa, que utiliza incrustaciones neuronales para comprender el significado de los documentos y las consultas. Métodos como BERT o Dense Passage Retrieval (DPR) representan los documentos como vectores en un espacio compartido, lo que hace que la recuperación sea más precisa.
La elección entre estos métodos puede afectar en gran medida al funcionamiento del sistema RAG.
Combinar la información recuperada con la generación de un LLM plantea algunos retos. Por ejemplo, los datos recuperados deben ser muy relevantes para la consulta, ya que los datos irrelevantes pueden confundir al modelo y reducir la calidad de la respuesta.
Además, si la información recuperada entra en conflicto con el conocimiento interno del modelo, puede generar respuestas confusas o inexactas. Por lo tanto, es fundamental resolver estos conflictos sin confundir al usuario.
Por último, es posible que el estilo y el formato de los datos recuperados no siempre coincidan con la escritura o el formato habituales del modelo, lo que dificulta que este integre la información sin problemas.
En un sistema RAG, una base de datos vectorial ayuda a gestionar y almacenar incrustaciones de texto. Estas incrustaciones son representaciones numéricas que capturan el significado de palabras y frases, creadas por modelos como BERT u OpenAI.
Cuando se realiza una consulta, tu incrustación se compara con las almacenadas en la base de datos para encontrar documentos similares. Esto hace que la recuperación de la información correcta sea más rápida y precisa. Este proceso ayuda al sistema a localizar y extraer rápidamente la información más relevante, mejorando tanto la velocidad como la precisión de la recuperación.
Para evaluar un sistema RAG, es necesario examinar tanto los componentes de recuperación como los de generación.
Para tareas posteriores, como responder preguntas, métricas como puntuación F1o la precisióny recall también pueden utilizarse para evaluar el sistema RAG en su conjunto.
El manejo de consultas ambiguas o incompletas en un sistema RAG requiere estrategias que garanticen la recuperación de información relevante y precisa a pesar de la falta de claridad en la entrada del usuario.
Un enfoque consiste en implementar técnicas de refinamiento de consultas, en las que el sistema sugiere automáticamente aclaraciones o reformula la consulta ambigua para que sea más precisa, basándose en patrones conocidos o interacciones anteriores. Esto puede implicar hacer preguntas de seguimiento u ofrecer al usuario varias opciones para concretar su intención.
Otro método consiste en recuperar un conjunto diverso de documentos que abarquen múltiples interpretaciones posibles de la consulta. Al recuperar una serie de resultados, el sistema garantiza que, incluso si la consulta es imprecisa, es probable que se incluya alguna información relevante.
Por último, podemos utilizar modelos de comprensión del lenguaje natural (NLU) para deducir la intención del usuario a partir de consultas incompletas y refinar el proceso de recuperación.
Ahora que hemos cubierto algunas preguntas básicas, es hora de pasar a las preguntas intermedias de la entrevista RAG.
La elección del recuperador adecuado depende del tipo de datos con los que trabajes, la naturaleza de las consultas y la potencia de cálculo de que dispongas.
Para consultas complejas que requieren una comprensión profunda del significado de las palabras, métodos de recuperación densos como BERT o DPR son mejores. Estos métodos capturan el contexto y son ideales para tareas como la atención al cliente o la investigación, en las que es importante comprender los significados subyacentes.
Si la tarea es más sencilla y gira en torno a la coincidencia de palabras clave, o si dispones de recursos computacionales limitados, los métodos de recuperación dispersa, como BM25 o TF-IDF, pueden ser más adecuados. Estos métodos son más rápidos y fáciles de configurar, pero es posible que no encuentren documentos que no coincidan exactamente con las palabras clave.
La principal contrapartida entre los métodos de recuperación densos y dispersos es la precisión frente al coste computacional. A veces, combinar ambos enfoques en un sistema de recuperación híbrido puede ayudar a equilibrar la precisión con la eficiencia computacional. De esta manera, obtienes las ventajas de los métodos densos y dispersos en función de tus necesidades.
La búsqueda híbrida combina las ventajas de los métodos de recuperación densa y dispersa.
Por ejemplo, puedes comenzar con un método disperso como BM25 para encontrar rápidamente documentos basados en palabras clave. Entonces, un método denso como BERT reclasifica esos documentos al comprender su contexto y significado. Esto te proporciona la velocidad de la búsqueda dispersa con la precisión de los métodos densos, lo que resulta ideal para consultas complejas y grandes conjuntos de datos.
Una base de datos vectorial es ideal para gestionar incrustaciones densas, pero no siempre es necesaria. Las alternativas incluyen:
La elección correcta depende de tus necesidades específicas, como el volumen de tus datos y si necesitas una comprensión semántica profunda.
Para asegurarte de que la información recuperada sea relevante y precisa, puedes utilizar varios métodos:
Cuando se trata de documentos largos o bases de conocimiento extensas, aquí tienes algunas técnicas útiles:
Para obtener el mejor rendimiento de un sistema RAG en términos de precisión y eficiencia, puedes utilizar varias estrategias:
En conversaciones con múltiples turnos (por ejemplo, un diálogo con un chatbot), un sistema RAG necesita trasladar el contexto relevante de los turnos anteriores para responder correctamente a las preguntas posteriores. Para lograrlo, RAG puede incorporar el historial de conversaciones en cada nueva consulta:
Refinamiento de la consulta: El sistema puede reescribir o ampliar automáticamente la pregunta del usuario utilizando información de intercambios anteriores. Al añadir detalles de turnos anteriores, el recuperador obtiene una consulta más rica en contexto, por lo que puede buscar documentos relevantes para la discusión en curso.
Incluyendo el historial de conversaciones: Otro enfoque consiste en proporcionar al modelo un resumen o una lista de los turnos de diálogo anteriores como parte de su contexto de entrada. Muchas arquitecturas RAG permiten pasar una secuencia de mensajes (historial del usuario y del asistente) junto con la nueva pregunta. De esta manera, cuando el recuperador busca información, tiene en cuenta el contexto establecido, y el generador puede utilizar el contexto anterior para mantener una conversación coherente.
Mediante el uso de estos métodos, el sistema RAG realiza un seguimiento de «quién dijo qué» y qué se ha resuelto ya. Esto evita que se olviden detalles o se repitan cosas.
Hasta ahora, hemos cubierto preguntas básicas e intermedias de entrevistas RAG, y ahora abordaremos conceptos más avanzados como las técnicas de fragmentación o la contextualización.
Hay varias formas de desglosar los documentos para su recuperación y procesamiento:
Los fragmentos más pequeños, como frases o párrafos cortos, ayudan a evitar la dilución de información contextual importante cuando se comprimen en un único vector. Sin embargo, esto puede llevar a la pérdida de dependencias de largo alcance entre fragmentos, lo que dificulta que los modelos comprendan las referencias que abarcan varios fragmentos.
Los fragmentos más grandes conservan más contexto, lo que permite obtener información contextual más rica, pero pueden ser menos específicos y la información puede perderse al intentar codificar toda la información en un único vector.
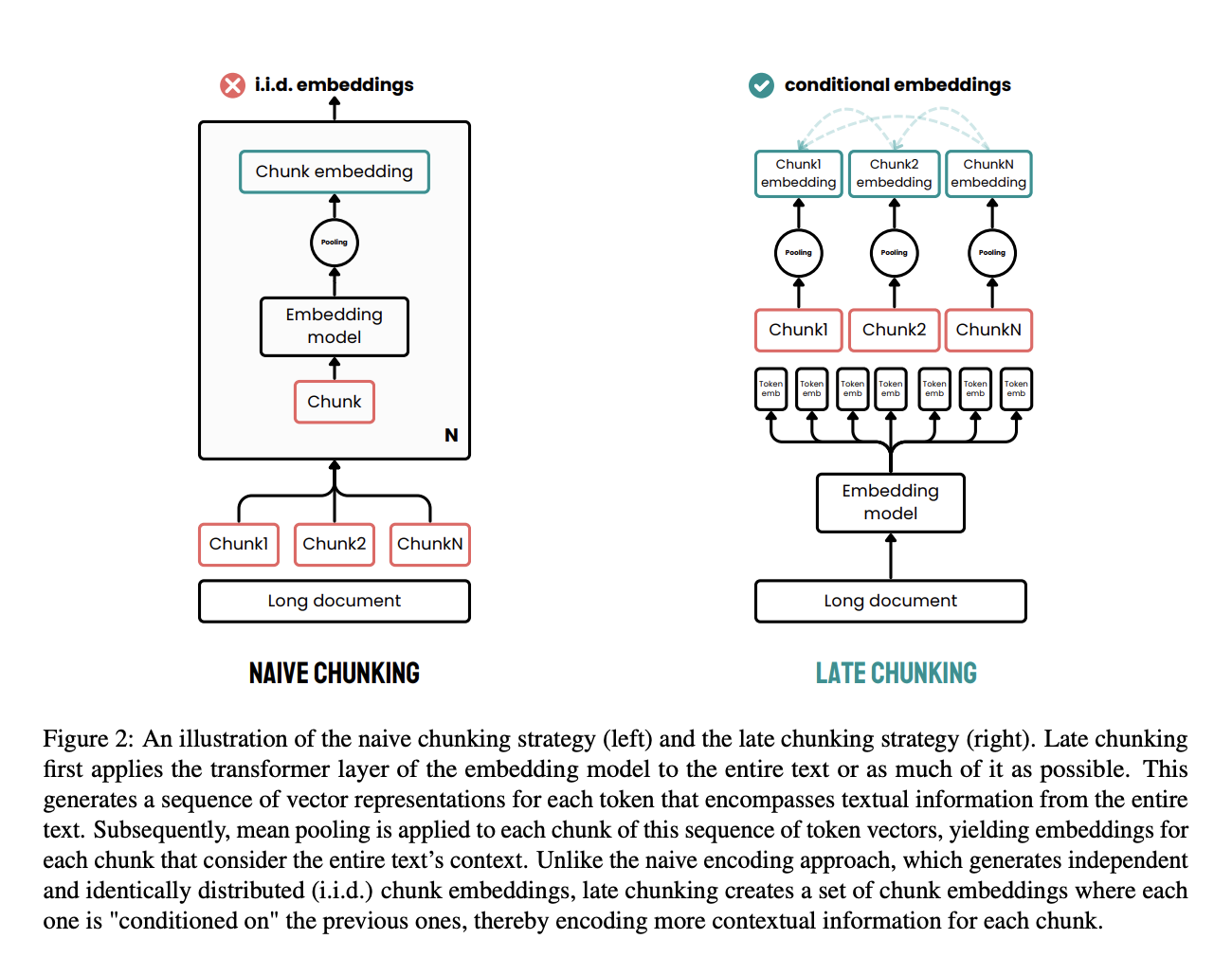
El chunking tardío es un enfoque eficaz diseñado para abordar las limitaciones de los métodos tradicionales de chunking en el procesamiento de documentos.
En los métodos tradicionales, los documentos se dividen primero en fragmentos, como oraciones o párrafos, antes de aplicar un modelo de incrustación. A continuación, estos fragmentos se codifican individualmente en vectores, a menudo utilizando el agrupamiento medio para crear una única incrustación para cada fragmento. Este enfoque puede provocar una pérdida de las dependencias contextuales a larga distancia, ya que las incrustaciones se generan de forma independiente, sin tener en cuenta el contexto completo del documento.
El chunking tardío adopta un enfoque diferente. Primero aplica la capa transformadora del modelo de incrustación a todo el documento o a la mayor parte posible del mismo, creando una secuencia de representaciones vectoriales para cada token. Este método captura el contexto completo del texto en estas incrustaciones a nivel de token.
A continuación, se aplica el agrupamiento medio a los fragmentos de esta secuencia de vectores de tokens, lo que produce incrustaciones para cada fragmento que se basan en el contexto de todo el documento. A diferencia del método tradicional, el chunking tardío genera incrustaciones de fragmentos que están condicionadas entre sí, lo que permite conservar más información contextual y resolver dependencias de largo alcance.
Al aplicar la fragmentación más adelante en el proceso, se garantiza que la incrustación de cada fragmento se beneficie del rico contexto que proporciona el documento completo, en lugar de quedar aislada. Este enfoque aborda el problema de la pérdida de contexto y mejora la calidad de las incrustaciones utilizadas para las tareas de recuperación y generación.
Fuente: Günther et al., 2024
La contextualización en RAG significa asegurarse de que la información recuperada sea relevante para la consulta. Al alinear los datos recuperados con la consulta, el sistema genera respuestas mejores y más relevantes.
Esto reduce las posibilidades de obtener resultados incorrectos o irrelevantes y garantiza que el resultado se ajuste a las necesidades del usuario. Un enfoque consiste en utilizar un LLM para comprobar si los documentos recuperados son relevantes antes de enviarlos al modelo generador, tal y como se demuestra en Corrective RAG (CRAG).
En primer lugar, es fundamental crear la base de conocimientos de manera que se filtre el contenido sesgado, asegurándote de que la información sea lo más objetiva posible. También puedes reeducar el sistema de recuperación para que dé prioridad a fuentes equilibradas e imparciales.
Otro paso importante podría ser contratar a un agente específicamente para que compruebe los posibles sesgos y garantice que los resultados del modelo sigan siendo objetivos.
Una cuestión importante es mantener los datos indexados actualizados con la información más reciente, lo que requiere un mecanismo de actualización fiable. Por lo tanto, el control de versiones se vuelve crucial para gestionar las diferentes iteraciones de la información y garantizar la coherencia.
Además, el modelo debe ser capaz de adaptarse a la nueva información en tiempo real sin tener que volver a entrenarse con frecuencia, lo que puede requerir muchos recursos. Estos retos requieren soluciones sofisticadas para garantizar que el sistema siga siendo preciso y relevante a medida que evoluciona la base de conocimientos.
CAG (Cache-Augmented Generation) es una evolución de RAG en la que los documentos recuperados se resumen o comprimen antes de pasar al LLM. Esto mejora la relevancia, reduce el uso de tokens y ayuda a incluir más información en la ventana de contexto del modelo.
La diferencia clave es que, en CAG, el contenido recuperado pasa por un paso intermedio, como un resumidor o un refinador de contexto, antes de ser enviado al generador. Por el contrario, el RAG tradicional pasa los documentos sin procesar directamente al prompt.
El CAG es especialmente útil cuando:
Trabajas con conjuntos de datos estáticos (por ejemplo, catálogos de productos, artículos académicos) que se pueden comprimir previamente y almacenar en caché.
La eficiencia de los tokens es fundamental (por ejemplo, API sensibles al coste o inferencia móvil/en el dispositivo).
Los documentos recuperados son largos o contienen ruido y necesitan ser destilados.
Por otro lado, RAG es preferible cuando:
Los datos subyacentes son dinámicos o se actualizan con frecuencia (por ejemplo, tickets de soporte en tiempo real, documentación en vivo).
Quieres incorporar los conocimientos más recientes en el momento de la consulta, sin volver a procesar toda la base de conocimientos.
En resumen, utiliza CAG para dominios estables en los que puedas optimizar el contexto con antelación, y RAG para escenarios dinámicos en los que la actualidad y la recuperación bajo demanda sean más importantes.
Echa un vistazo a este artículo sobre RAG frente a CAG para obtener una comparación más detallada.
Existen muchos sistemas RAG avanzados.
Uno de estos sistemas es el Adaptive RAG, en el que el sistema no solo recupera información, sino que también ajusta su enfoque en tiempo real en función de la consulta. El RAG adaptativo puede decidir no realizar ninguna recuperación, realizar un RAG único o realizar un RAG iterativo. Este comportamiento dinámico hace que el sistema RAG sea más robusto y relevante para la solicitud del usuario.
Otro sistema RAG avanzado es Agentic RAG, que introduce agentes de recuperación (), herramientas que deciden si extraer o no información de una fuente. Al dotar a un modelo lingüístico de esta capacidad, este puede determinar por sí mismo si necesita información adicional, lo que agiliza el proceso.
El RAG correctivo (CRAG) también está ganando popularidad. En este enfoque, el sistema revisa los documentos que recupera, comprobando su relevancia. Solo los documentos clasificados como relevantes se introducirían en el generador. Este paso de autocorrección ayuda a garantizar que se utilice información precisa y relevante. Para obtener más información, puedes leer este tutorial sobre Implementación de RAG correctivo (CRAG) con LangGraph.
El auto-RAG ( ) va un paso más allá al evaluar no solo los documentos recuperados, sino también las respuestas finales generadas, asegurándose de que ambos estén alineados con la consulta del usuario. Esto conduce a resultados más fiables y consistentes.
Un enfoque eficaz consiste en precargar la información relevante y más solicitada para que esté lista cuando se necesite. Además, perfeccionar los algoritmos de indexación y consulta puede marcar una gran diferencia en la rapidez con la que se recuperan y procesan los datos.
Aunque RAG es potente, tiene varias limitaciones y retos:
Dependencia de la calidad de los datos recuperados: Un sistema RAG es tan bueno como la información que recupera. Si el recuperador extrae documentos irrelevantes o incorrectos, la respuesta del generador se verá afectada. Garantizar fuentes de datos fiables y de alta calidad (y ajustar el recuperador) es un reto constante para evitar problemas de «basura entra, basura sale».
Mayor complejidad y latencia: RAG introduce un paso adicional de recuperación además de la generación, lo que hace que todo el sistema sea más complejo y computacionalmente más pesado que un LLM independiente. La búsqueda en una gran base de conocimientos puede añadir latencia y requerir importantes recursos informáticos, por lo que los sistemas RAG deben equilibrar la precisión con la eficiencia.
Necesidad de mantener la base de conocimientos: A diferencia de los LLM estáticos, el RAG depende de un repositorio de conocimientos externo que necesita actualizaciones y curación periódicas. Las organizaciones deben incorporar continuamente nuevos datos, eliminar la información obsoleta y gestionar los índices. Sin fuentes de datos fiables y actualizadas, un sistema RAG puede perder rápidamente su eficacia o incluso proporcionar respuestas obsoletas.
Dificultad de integración y ajuste: Combinar la recuperación y la generación implica más componentes que ajustar y supervisar (la base de datos vectorial, el modelo de recuperación y el LLM). La resolución de errores puede resultar más difícil, ya que los problemas pueden tener su origen tanto en la recuperación como en la generación. Esta complejidad puede aumentar el esfuerzo de desarrollo y mantenimiento en comparación con el uso exclusivo de un LLM.
También cabe señalar que, si los datos de un dominio son en gran medida estáticos y se ajustan al entrenamiento del modelo, un LLM ajustado podría ser suficiente en lugar de un RAG. Sin embargo, el ajuste fino carece de la capacidad de RAG para incorporar información nueva sobre la marcha y puede resultar más costoso volver a entrenar el modelo cada vez que se actualiza el conocimiento.
Ahora, abordemos algunas preguntas específicas dirigidas a quienes se presentan a entrevistas para puestos de ingeniero de IA.
¡Aprende IA con estos cursos!
programa
programa
Curso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Tim Lu
9 min
blog
Josep Ferrer
15 min
blog
Abid Ali Awan
15 min

