
Kurs
SQL ile İlişkisel Veritabanlarına Giriş
4 sa
194.7K
Devasa veri kümelerini yönetmek sadece teknik bir zorluk değil—aynı zamanda stratejik bir mesele. Veri büyüdükçe, depolama, performans ve ölçeklenebilirlik talepleri de artar. Tam bu noktada iki temel teknik devreye girer: sharding ve bölümlendirme (partitioning).
Bu kavramlarla ilk karşılaştığımda, ilk bakışta benzer göründüler—ancak derine indikçe, sistemlerin nasıl tasarlandığını ve ölçeklendirildiğini gerçekten etkileyen önemli farklar olduğunu gördüm.
Bu yazıda, sharding ve bölümlendirmenin gerçekte ne anlama geldiğini, nasıl farklılaştıklarını, hangisini ne zaman kullanmanız gerektiğini ve veri yoğun uygulamalar oluştururken göz önünde bulundurmanız gereken artı ve eksileri anlatacağım.
>Veriler bölümlendirilmeden veya shard edilmeden önce nasıl yapılandırıldığının temellerini anlamak için, sağlam bir veritabanı tasarımı altyapısıyla başlayın.
Sharding, bir veritabanının "shard" adı verilen daha küçük ve yönetilebilir parçalara bölünmesi sürecidir. Her shard, tüm verinin bir alt kümesini içerir ve bağımsız bir veritabanı gibi çalışır.
Shard'lar birden fazla sunucuya dağıtılır; bu sayede sistem büyük veri kümelerini ve yüksek trafik hacimlerini karşılayabilir. Bu yaklaşım, yükü sunucular arasında dengeler ve shard'ların içerdiği veriye göre özelleştirilmiş optimizasyonlara imkan tanır.
Aşağıdaki diyagram, dağıtık bir veritabanı sisteminde sharding'in nasıl çalıştığını göstermektedir. Bir yük dengeleyici ile veritabanı yönetim sisteminin (DBMS) bir arada çalışarak gelen istemci isteklerini birden fazla shard'a nasıl dağıttığına dikkat edin.
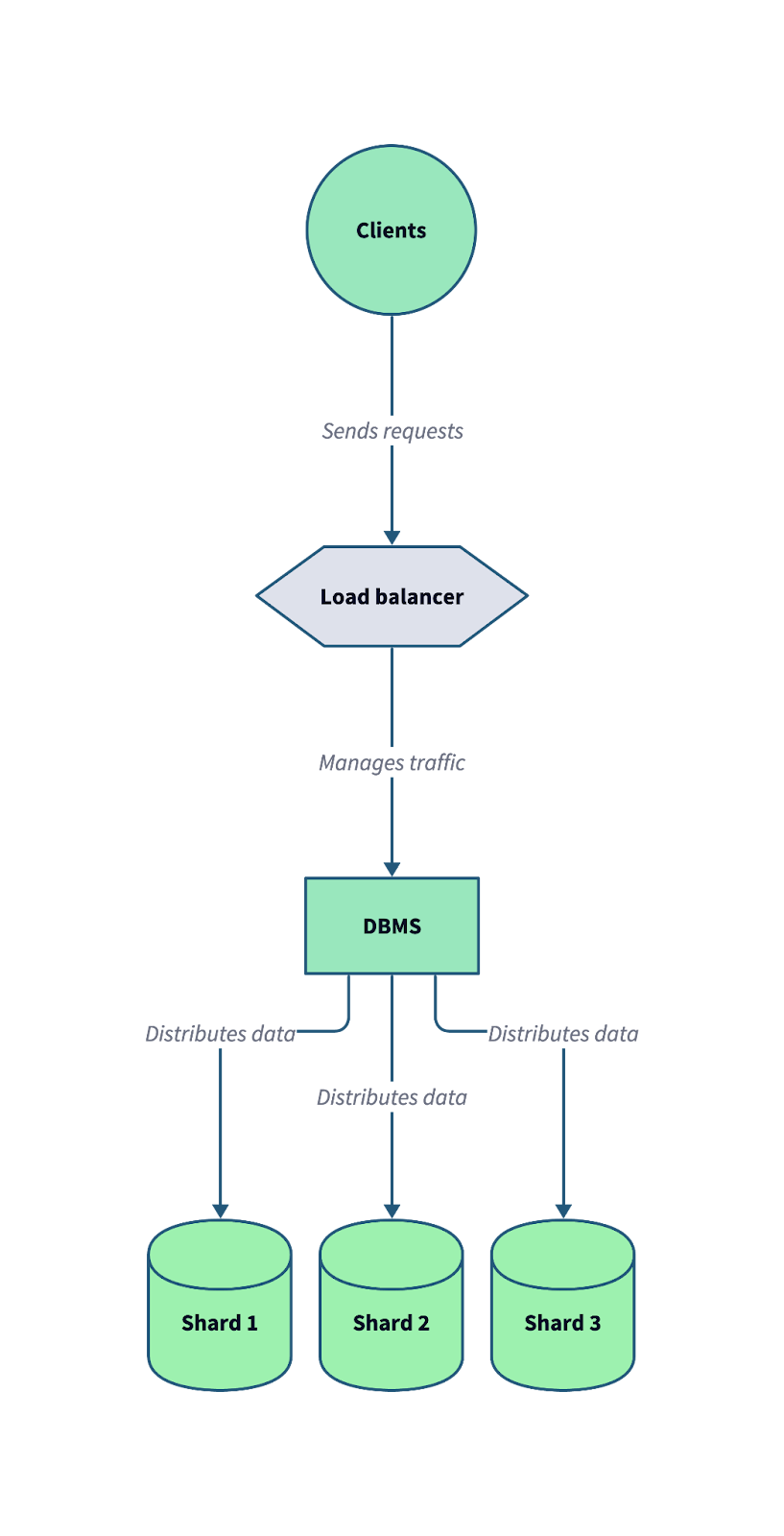
Verinin ölçeklenebilirlik ve hata toleransını iyileştirmek için birden çok bağımsız shard'a bölündüğü tipik bir sharding mimarisi. Görsel: Yazar.
Veriyi shard'lara bölerek, sistem iş yüklerini daha verimli dağıtabilir ve trafik ile veri hacmindeki büyümeyi karşılamak için yatay olarak ölçeklenebilir.Sharding'in avantajları şunlardır:
>Dağıtık sistemlerin genel dünyasını merak ediyor musunuz? Dağıtık bilişim gibi ölçeklenebilir mimarileri nasıl mümkün kıldığını öğrenin.
Bölümlendirme, büyük bir veritabanı tablosunun aynı sunucu ve veritabanı sistemi içinde daha küçük ve yönetilebilir parçalar olan bölümlere ayrılması sürecidir. Her bölüm, tarih aralıkları, coğrafi bölgeler veya müşteri kimlikleri gibi belirli bir kurala göre verinin bir alt kümesini tutar.
Sharding'den farklı olarak, bölümlendirme veriyi birden fazla makineye yaymaz. Bunun yerine, veriyi dahili olarak düzenleyerek sorguları hızlandırır ve bakımı basitleştirir.Ancak bölümlendirme yalnızca düzenlemeden ibaret değildir—performansı ve veri yönetilebilirliğini doğrudan etkiler. İşte başlıca faydaları:
Bölümlendirmenin uygulamada nasıl çalıştığını daha iyi anlamak için görsel bir temsile bakalım. Bu örnekte, veriler tek bir merkezi veritabanında saklanır ancak kullanıcı konumu veya içerik türüne göre mantıksal bölümlere ayrılır:
Merkezi bir veritabanı içinde bölümlendirme. Daha iyi performans ve bakım için veriler mantıksal bölümlere (ör. konuma veya içerik türüne göre) ayrılır. Görsel: Yazar.
Bölümlendirme, veri organizasyonu ve sorgu optimizasyonuna yönelik gereksinimlere göre farklı şekillerde uygulanabilir. Farklı türde veritabanları, basit ve verimli erişimi sağlamak için farklı biçimlerde bölümlendirilir.Örnek:
Veri, tarihler gibi bir değer aralığına göre bölünür. Örneğin, işlemler ay veya yıla göre bölümlendirilebilir. Bu yöntem, sorguların genellikle belirli tarih aralıklarına odaklandığı zaman serisi verilerinde özellikle kullanışlıdır.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Veri, bir bölüm anahtarına uygulanan hash fonksiyonunun çıktısına göre bölünür. Bu, verinin bölümler arasında eşit dağıtılmasını sağlayarak sıcak noktaları en aza indirir. Örneğin, bir kullanıcı kimliği hash'lenerek kullanıcının verisinin hangi bölümde saklanacağı belirlenebilir; bu da yükü eşit yayar.
Örnek:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Veri, önceden tanımlanmış kategori listelerine göre bölünür. Örneğin, müşteri verileri coğrafi bölgeye veya ürün türüne göre bölümlendirilebilir. Bu yaklaşım, açıkça tanımlanmış kategorilere sahip veri kümeleri için faydalıdır ve belirli segmentlere yönelik hedefli sorgulara imkan tanır.
Örnek:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Yapısal sistemlerde verilerin nasıl depolandığı ve sorgulandığına yeniyseniz, şu SQL ile ilişkisel veritabanlarına giriş kursu başlamak için harika bir yerdir.
Sharding ile bölümlendirme arasındaki farkları anlamak, büyük veri kümelerini yönetmek için uygun stratejiyi seçmek açısından kritik önem taşır. Her iki teknik de veritabanı performansını ve ölçeklenebilirliği optimize etmeyi amaçlar; ancak farklı düzeylerde çalışır ve farklı amaçlara hizmet eder. Aşağıda özetlendiği gibi.
|
Kategori |
Sharding |
Bölümlendirme |
|
Kapsam |
Birden fazla veritabanı veya sunucu arasında çalışır |
Tek bir veritabanı içinde gerçekleşir |
|
Karmaşıklık |
Daha yüksek karmaşıklık: dağıtık mimari ve koordinasyon içerir |
Daha düşük karmaşıklık: tek bir veritabanı sistemi içinde yönetilir |
|
Veri dağıtımı |
Veri farklı düğümlere/shard'lara bölünüp depolanır |
Veri aynı sistem içinde mantıksal bölümlere ayrılır |
|
Ölçeklenebilirlik |
Sunucu ekleyerek yatay ölçeklemeyi destekler |
Performansı optimize eder ancak doğası gereği sunucular arasında ölçeklenmez |
|
Yönetim |
Dikkatli planlama, özel araçlar ve veri tutarlılığı yönetimi gerektirir |
Yerleşik veritabanı özellikleriyle bakımı daha kolaydır |
|
Sorgu performansı |
Doğru sharding anahtarına ve veri erişim desenlerine bağlıdır |
Sorgular, bölüm budama ile otomatik olarak optimize edilebilir |
|
Kullanım alanları |
Büyük ölçekli, dağıtık uygulamalar için en iyisi (ör. e-ticaret, sosyal medya) |
Analitik iş yükleri ve zamana/mantığa dayalı veri sorguları için ideal |
Sharding ile bölümlendirme arasında seçim yapmak her zaman açık değildir—bu seçim, sisteminizin ölçeğine, mimarisine ve hedeflerine bağlıdır. Her iki strateji de performans ve yönetilebilirliği ele alır, ancak farklı şekillerde. İşte senaryonuza hangisinin uyduğuna karar vermenin yolu.
Sisteminiz tek bir veritabanının kaldırabileceği sınırları zorladığında sharding kullanın:
Örnek: Milyonlarca kullanıcı ve işleme sahip küresel bir e-ticaret sitesi, hızlı ve ölçeklenebilir erişim için verileri müşteri bölgesine veya kullanıcı kimliğine göre shard edebilir.
Veriniz büyüyor ancak hâlâ tek bir sunucu veya veritabanı içinde çalışıyorsanız bölümlendirme kullanın:
Örnek: İşlem günlükleri tutan bir finansal hizmetler şirketi, ay sonu raporlarını hızlıca çalıştırmak ve eski kayıtları verimli şekilde arşivlemek için tabloları aya göre bölümlendirebilir.
Tüm veritabanları sharding veya bölümlendirmeyi kutudan çıkar çıkmaz desteklemez—bazıları için üçüncü parti eklentiler veya özel uygulamalar gerekir.
İşte popüler veritabanı sistemlerinin sharding ve bölümlendirmeyi nasıl ele aldığına ve etkili bir şekilde uygulamak için hangi araçlara ihtiyaç duyabileceğinize hızlı bir bakış:
|
Veritabanı Sistemi |
Sharding Desteği |
Bölümlendirme Desteği |
Notlar / Araçlar |
|
PostgreSQL |
❌ Yerleşik yerel sharding yok (ancak eklentilerle mümkün) |
✅ |
Citus kullanarak sharding'li dağıtık PostgreSQL |
|
MySQL |
✅ Vitess veya Fabric gibi araçlarla desteklenir |
✅ Yerel aralık, liste, hash bölümlendirme |
MySQL 5.1'den beri yerel bölümlendirme; sharding için orkestrasyon araçları gerekir |
|
MongoDB |
✅ Yerleşik otomatik sharding |
❌ Yerleşik bölümlendirme yok; shard anahtarlarıyla benzer etki sağlanır |
Dağıtık NoSQL iş yükleri için idealdir |
|
Oracle Database |
❌ Temel sürümlerde sharding yok (Enterprise Edition, Oracle Sharding ile destekler) |
✅ Gelişmiş bölümlendirme özellikleri (aralık, liste, hash, bileşik) |
Bölümlendirme güçlüdür; ancak sharding için Enterprise veya üzeri lisans gerekir |
|
SQL Server |
❌ Yerel sharding yok; özel uygulama gerekir |
✅ Bölümlü tablolar ve indeksler ile desteklenir |
Sözde sharding için Bölümlendirilmiş Görünümler veya Birleşik Veritabanları kullanın |
|
Amazon Redshift |
✅ Veriyi düğümler arasında dağıtmak için dağıtım anahtarları kullanır |
✅ Sıralama ve dağıtım anahtarlarıyla sütunsal bölümlendirmeye yerel destek |
Büyük birleştirmeler için dağıtım stilini dikkatle seçin |
|
Google BigQuery |
✅ Arka planda otomatik olarak ele alınır |
✅ Bölümlü tabloları destekler (alım ya da özel zaman damgasına göre) |
Analitik için harikadır—manuel sharding gerekmez |
|
Cassandra |
✅ Tutarlı hash'leme ile yerleşik sharding |
❌ Doğrudan bölümlendirme yok, ancak veri bölüm anahtarlarıyla ayrılır |
Tasarım gereği yatay olarak ölçeklenir |
|
ClickHouse |
✅ Kümeler aracılığıyla yatay sharding |
✅ Herhangi bir sütuna göre yerel bölümlendirme |
OLAP iş yükleri için çok yüksek performanslı |
|
CockroachDB |
✅ Otomatik, coğrafi olarak dağıtık sharding |
✅ Bölgesel veri için aralık tabanlı bölümlendirme |
Küresel olarak dağıtık SQL sistemleri için ideal |
>BigQuery'nin sharding ve bölümlendirmeyi arka planda nasıl otomatikleştirdiğini bu giriş niteliğindeki kursta öğrenin. Redshift'in dağıtık depolama ve bölümlendirmeye yaklaşımını daha derinlemesine incelemek için şu başlangıç seviyesi Redshift kursuna göz atın.
Sharding ve bölümlendirme, büyük veri kümelerini yönetmek için güçlü tekniklerdir; her birinin kendi güçlü yanları ve kullanım alanları vardır. Sharding, dağıtık sistemleri ölçeklendirmek için kritik öneme sahipken; bölümlendirme sorgu performansını optimize eder ve veri yönetimini basitleştirir. Bu kavramları anlamak, yeni başlayan veri bilimcilerinin verimli ve ölçeklenebilir veritabanı çözümleri tasarlamasına yardımcı olacaktır.
Daha fazla bilgi için, veritabanı ölçekleme teknikleri ve performans optimizasyonu üzerine ek kaynaklara göz atın:
Bu kurslarla veritabanları hakkında daha fazlasını öğrenin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
