
Kurs
Einführung in relationale Datenbanken in SQL
4 Std.
193.2K
Die Verwaltung großer Datenmengen ist nicht nur eine technische, sondern auch eine strategische Herausforderung. Mit dem Wachstum der Daten steigen auch die Anforderungen an Speicherung, Leistung und Skalierbarkeit. Hier kommen zwei wichtige Techniken ins Spiel: sharding und partitioning.
Als ich zum ersten Mal mit diesen Konzepten in Berührung kam, schienen sie auf den ersten Blick ähnlich zu sein - aber wenn man genauer hinsieht, entdeckt man einige wichtige Unterschiede, die einen echten Einfluss darauf haben, wie Systeme entworfen und skaliert werden.
In diesem Artikel erkläre ich dir, was Sharding und Partitioning wirklich bedeuten, wie sie sich unterscheiden, wann sie eingesetzt werden sollten und welche Vor- und Nachteile du bei der Entwicklung datenintensiver Anwendungen beachten solltest.
>Um zu verstehen, wie die Daten strukturiert sind, bevor sie partitioniert oder gesplittet werden, solltest du eine solide Grundlage inn Datenbankdesign.
Beim Sharding wird eine Datenbank in kleinere, besser handhabbare Teile aufgeteilt, die sogenannten "Shards". Jeder Shard enthält eine Teilmenge der Gesamtdaten und funktioniert wie eine unabhängige Datenbank.
Die Shards sind auf mehrere Server verteilt, so dass das System große Datensätze und ein hohes Datenaufkommen bewältigen kann. Dieser Ansatz gleicht die Last zwischen den Servern aus und ermöglicht maßgeschneiderte Optimierungen für bestimmte Shards auf der Grundlage ihrer Daten.
Das folgende Diagramm zeigt, wie Sharding in einem verteilten Datenbanksystem funktioniert. Beachte, wie ein Load Balancer und ein Datenbankmanagementsystem (DBMS) zusammenarbeiten, um eingehende Client-Anfragen auf mehrere Shards zu verteilen.
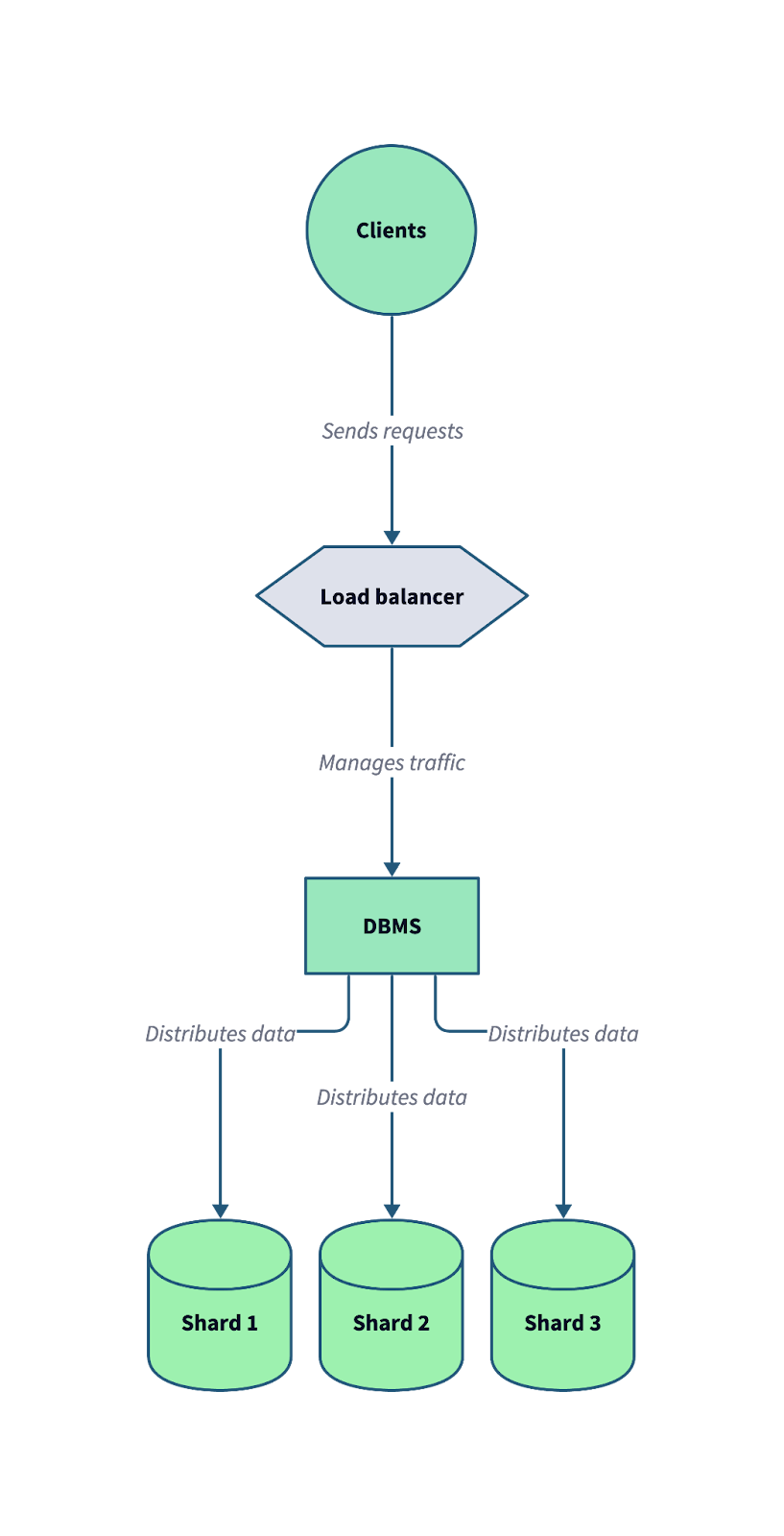
Eine typische Sharded-Datenbankarchitektur, bei der die Daten auf mehrere unabhängige Shards aufgeteilt werden, um Skalierbarkeit und Fehlertoleranz zu optimieren. Bild vom Autor.
Durch die Aufteilung der Daten in Shards kann das System die Arbeitslasten effizienter verteilen und horizontal skalieren, um den Datenverkehr und das Datenvolumen zu bewältigen.Das sind die Vorteile von Sharding:
>Bist du neugierig, wie es mit verteilten Systemen weitergeht? Lerne, wie w verteiltes Rechnenskalierbare Architekturen wie Sharding ermöglicht.
Bei der Partitionierung wird eine große Tabelle in kleinere, überschaubare Segmente, die sogenannten Partitionen, aufgeteilt - und zwar innerhalb desselben Servers und Datenbanksystems. Jede Partition enthält eine Teilmenge der Daten, die auf einer bestimmten Regel basiert, z. B. Datumsbereiche, geografische Regionen oder Kunden-IDs.
Anders als beim Sharding werden die Daten bei der Partitionierung nicht auf mehrere Maschinen verteilt. Stattdessen hilft es, die Daten intern zu organisieren, um Abfragen zu beschleunigen und die Wartung zu vereinfachen.Bei der Partitionierung geht es aber nicht nur um die Organisation - sie wirkt sich direkt auf die Leistung und die Datenverwaltung aus. Hier sind einige der wichtigsten Vorteile:
Um die Partitionierung in der Praxis besser zu verstehen, schauen wir uns eine visuelle Darstellung an. In diesem Beispiel werden die Daten in einer zentralen Datenbank gespeichert, aber in logische Partitionen aufgeteilt, die auf dem Standort des Nutzers oder dem Inhaltstyp basieren:
Partitionierung innerhalb einer zentralen Datenbank. Die Daten werden in logische Partitionen aufgeteilt (z. B. nach Ort oder Inhaltstyp), um die Leistung und Wartbarkeit zu verbessern. Bild vom Autor.
Die Partitionierung kann auf verschiedene Arten implementiert werden, die jeweils auf die spezifischen Bedürfnisse der Datenorganisation und der Abfrageoptimierung zugeschnitten sind. Verschiedene Arten von Datenbanken werden unterschiedlich partitioniert, um einen einfachen und effizienten Zugriff zu gewährleisten.Beispiel:
Daten werden auf der Grundlage eines Wertebereichs, z. B. eines Datums, unterteilt. Die Transaktionen können zum Beispiel nach Monat oder Jahr unterteilt werden. Dies ist besonders nützlich für Zeitreihendaten, bei denen sich die Abfragen oft auf bestimmte Datumsbereiche konzentrieren.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Die Daten werden auf der Grundlage der Hash-Funktion aufgeteilt, die auf einen Partitionsschlüssel angewendet wird. Das sorgt für eine gleichmäßige Verteilung der Daten auf die Partitionen und minimiert Hotspots. Zum Beispiel könnte eine Benutzer-ID gehasht werden, um die Partition zu bestimmen, in der die Daten eines Benutzers gespeichert werden, um die Last gleichmäßig zu verteilen.
Beispiel:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Die Daten werden auf der Grundlage einer vordefinierten Liste von Kategorien unterteilt. Die Kundendaten können zum Beispiel nach geografischer Region oder Produktart aufgeteilt werden. Dieser Ansatz kommt Datensätzen mit klar definierten Kategorien zugute und ermöglicht gezielte Abfragen für bestimmte Segmente.
Beispiel:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Wenn du nicht weißt, wie Daten in strukturierten Systemen gespeichert und abgefragt werden, dieser Kurs Einführung in relationale Datenbanken in SQL ist ein guter Anfang.
Das Verständnis der Unterschiede zwischen Sharding und Partitionierung ist entscheidend für die Wahl der richtigen Strategie zur Verwaltung großer Datenmengen. Obwohl beide Techniken darauf abzielen, die Leistung und Skalierbarkeit von Datenbanken zu optimieren, arbeiten sie auf verschiedenen Ebenen und dienen unterschiedlichen Zwecken, wie im Folgenden beschrieben.
|
Kategorie |
Sharding |
Aufteilung |
|
Umfang |
Funktioniert über mehrere Datenbanken oder Server hinweg |
Geschieht innerhalb einer einzigen Datenbank |
|
Komplexität |
Höhere Komplexität: erfordert verteilte Architektur und Koordination |
Geringere Komplexität: Verwaltung innerhalb eines Datenbanksystems |
|
Datenverteilung |
Daten werden über verschiedene Knoten/Shards verteilt und gespeichert |
Daten werden in logische Partitionen innerhalb desselben Systems aufgeteilt |
|
Skalierbarkeit |
Unterstützt horizontale Skalierung durch Hinzufügen von Servern |
Optimiert die Leistung, skaliert aber nicht von Natur aus über mehrere Server |
|
Management |
Erfordert eine sorgfältige Planung, benutzerdefinierte Werkzeuge und die Handhabung der Datenkonsistenz |
Einfachere Wartung durch integrierte Datenbankfunktionen |
|
Abfrageleistung |
Abhängig von den richtigen Sharding-Schlüsseln und Datenzugriffsmustern |
Abfragen können automatisch durch Partition Pruning optimiert werden |
|
Anwendungsfälle |
Am besten geeignet für große, verteilte Anwendungen (z. B. E-Commerce, soziale Medien) |
Ideal für analytische Workloads und zeitbasierte/logische Datenabfragen |
Die Entscheidung zwischen Sharding und Partitionierung ist nicht immer eindeutig - sie hängt von der Größe, der Architektur und den Zielen deines Systems ab. Beide Strategien zielen auf Leistung und Verwaltbarkeit ab, aber auf unterschiedliche Weise. Hier erfährst du, wie du entscheidest, welche Variante zu deinem Szenario passt.
Verwende Sharding, wenn dein System an die Grenzen dessen stößt, was eine einzelne Datenbank bewältigen kann:
Beispiel: Eine globale E-Commerce-Website mit Millionen von Nutzern und Transaktionen könnte die Daten nach Kundenregion oder Nutzer-ID splitten, um einen schnellen, skalierbaren Zugriff zu gewährleisten.
Verwende die Partitionierung, wenn deine Daten immer größer werden, du aber immer noch mit einem einzigen Server oder einer einzigen Datenbank arbeitest:
Beispiel: Ein Finanzdienstleistungsunternehmen, das Transaktionsprotokolle speichert, könnte Tabellen nach Monaten partitionieren, um schnell Monatsendberichte zu erstellen und ältere Datensätze effizient zu archivieren.
Nicht alle Datenbanken unterstützen Sharding oder Partitioning von Haus aus - einige erfordern Erweiterungen von Drittanbietern oder eigene Implementierungen.
Hier ist ein kurzer Blick darauf, wie gängige Datenbanksysteme mit Sharding und Partitionierung umgehen und welche Tools du brauchst, um sie effektiv zu implementieren :
|
Datenbank-System |
Sharding-Unterstützung |
Unterstützung der Partitionierung |
Anmerkungen / Tools |
|
PostgreSQL |
❌ Natives Sharding ist nicht eingebaut (aber über Erweiterungen verfügbar) |
✅ Native Unterstützung über |
Citus für verteilten PostgreSQL mit Sharding verwenden |
|
MySQL |
✅ Unterstützt durch Tools wie Vitess oder Fabric |
✅ Native Bereichs-, Listen- und Hash-Partitionierung |
Native Partitionierung seit MySQL 5.1; Sharding benötigt Orchestrierungswerkzeuge |
|
MongoDB |
✅ Eingebautes automatisches Sharding |
❌ Keine eingebaute Partitionierung; erreicht ähnliche Effekte mit Splitterschlüsseln |
Ideal für verteilte NoSQL-Workloads |
|
Oracle Datenbank |
❌ Kein Sharding in den Basisversionen (Enterprise Edition unterstützt es über Oracle Sharding) |
✅ Erweiterte Partitionierungsfunktionen (Bereich, Liste, Hash, Composite) |
Partitionierung ist robust, aber Sharding erfordert eine Enterprise- oder höhere Lizenz |
|
SQL Server |
❌ Kein natives Sharding; erfordert eigene Implementierung |
✅ Unterstützt durch partitionierte Tabellen und Indizes |
Partitionierte Ansichten oder föderierte Datenbanken für Pseudo-Sharding verwenden |
|
Amazon Redshift |
✅ Verwendet Verteilungsschlüssel, um die Daten auf die Knoten zu verteilen |
✅ Native Unterstützung für spaltenbezogene Partitionierung über Sortier- und Verteilungsschlüssel |
Wähle den Verteilungsstil für große Fugen sorgfältig aus |
|
Google BigQuery |
✅ Wird automatisch hinter den Kulissen erledigt |
✅ Unterstützt partitionierte Tabellen (nach Ingestion oder benutzerdefiniertem Zeitstempel) |
Ideal für Analysen - kein manuelles Sharding erforderlich |
|
Cassandra |
✅ Eingebautes Sharding über konsistentes Hashing |
❌ Keine Partitionierung per se, aber Daten werden über Partitionsschlüssel aufgeteilt |
Horizontale Skalierung durch Design |
|
ClickHouse |
✅ Horizontales Sharding über Cluster |
✅ Native Partitionierung nach einer beliebigen Spalte |
Sehr leistungsfähig für OLAP-Workloads |
|
CockroachDB |
✅ Automatisches, geo-distributives Sharding |
✅ Bereichsbezogene Partitionierung für regionale Daten |
Ideal für global verteilte SQL-Systeme |
>In diesem Einführungskurs lernst du, wie BigQuery das Sharding und Partitioning hinter den Kulissen automatisiert . Wenn du tiefer in den Redshift-Ansatz für verteilten Speicher und Partitionierung eintauchen möchtest, solltest du diesen einsteigerfreundlichen Redshift-Kurs besuchen.
Sharding und Partitionierung sind leistungsstarke Techniken für die Verwaltung großer Datenmengen, die jeweils ihre eigenen Stärken und Anwendungen haben. Sharding ist wichtig für die Skalierung verteilter Systeme, während Partitionierung die Abfrageleistung optimiert und die Datenverwaltung vereinfacht. Wenn du diese Konzepte verstehst, kannst du als angehender Datenwissenschaftler effiziente, skalierbare Datenbanklösungen entwickeln.
Weitere Informationen findest du inweiteren Ressourcen zu Skalierungstechniken für Datenbanken und Leistungsoptimierung:
Lerne mehr über Datenbanken mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Allan Ouko
Tutorial
Sejal Jaiswal
Tutorial
Moez Ali

