
Kursus
Pengantar Basis Data Relasional dalam SQL
4 Hr
194.7K
Mengelola himpunan data yang masif bukan hanya tantangan teknis—tetapi juga strategis. Seiring pertumbuhan data, tuntutan terhadap penyimpanan, performa, dan skalabilitas juga meningkat. Di sinilah dua teknik penting berperan: sharding dan partitioning.
Saat pertama kali menemukan konsep ini, sekilas keduanya tampak mirip—namun setelah ditelusuri lebih dalam, ada perbedaan penting yang berdampak nyata pada bagaimana sistem dirancang dan diskalakan.
Dalam artikel ini, saya akan menjelaskan apa sebenarnya yang dimaksud dengan sharding dan partitioning, bagaimana perbedaannya, kapan menggunakan masing-masing, serta kelebihan dan kekurangannya saat membangun aplikasi yang intensif data.
>Untuk memahami fondasi bagaimana data disusun sebelum dipartisi atau di-shard, mulailah dengan dasar yang kuat dalam desain basis data.
Sharding adalah proses membagi sebuah basis data menjadi bagian-bagian yang lebih kecil dan lebih mudah dikelola yang disebut "shard." Setiap shard berisi subset dari keseluruhan data dan berfungsi sebagai basis data independen.
Shard didistribusikan ke beberapa server, memungkinkan sistem menangani himpunan data besar dan volume trafik tinggi. Pendekatan ini menyeimbangkan beban di antara server dan memungkinkan optimalisasi yang disesuaikan untuk shard tertentu berdasarkan datanya.
Diagram berikut mengilustrasikan cara kerja sharding dalam sistem basis data terdistribusi. Perhatikan bagaimana load balancer dan sistem manajemen basis data (DBMS) bekerja sama untuk mendistribusikan permintaan klien yang masuk ke berbagai shard.
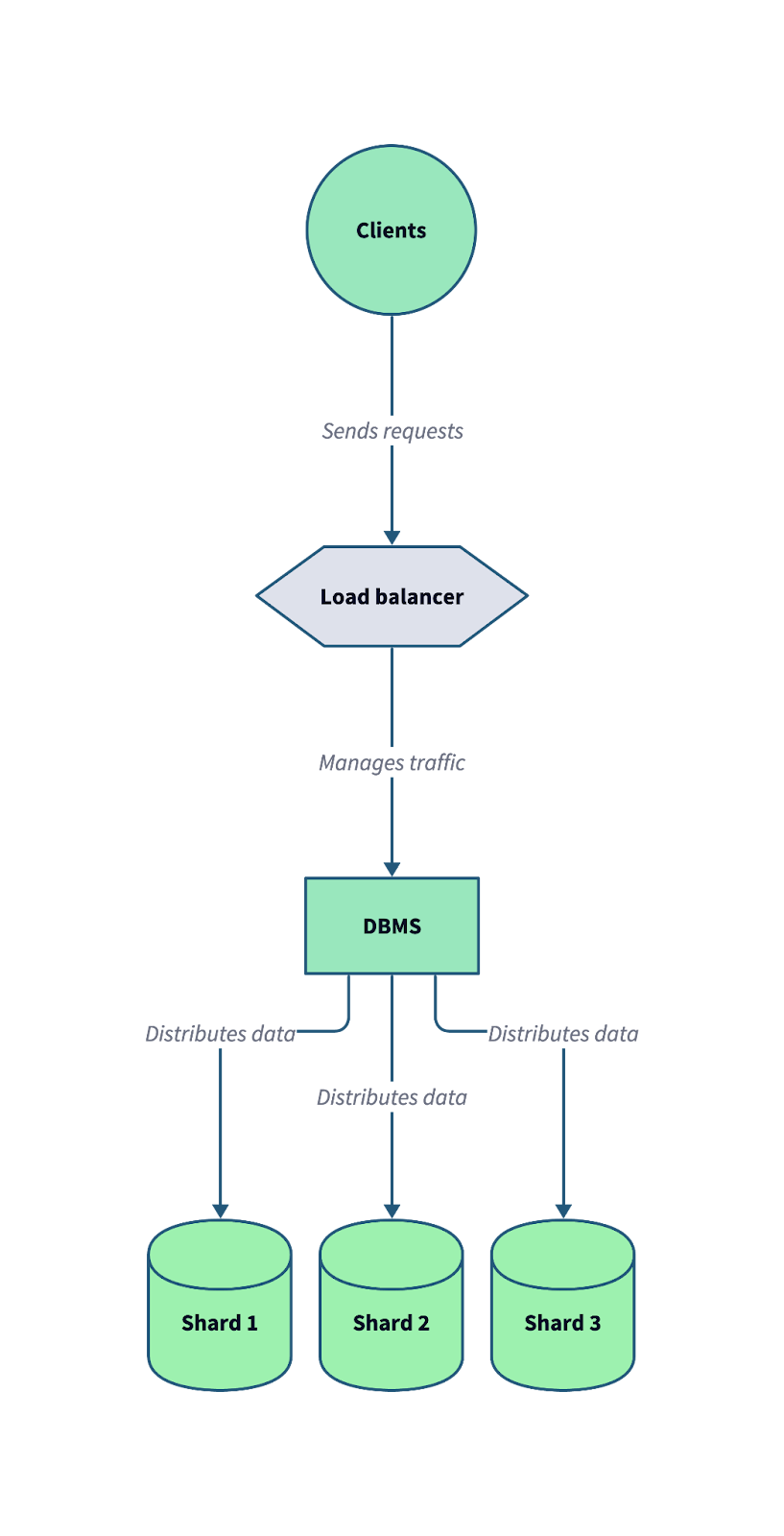
Arsitektur basis data yang di-shard pada umumnya, di mana data dipecah ke beberapa shard independen untuk mengoptimalkan skalabilitas dan toleransi kesalahan. Gambar oleh Penulis.
Dengan membagi data ke dalam shard, sistem dapat mendistribusikan beban kerja lebih efisien dan melakukan penskalaan horizontal untuk mengakomodasi pertumbuhan trafik dan volume data.Inilah manfaat sharding:
>Ingin tahu lebih jauh tentang lanskap sistem terdistribusi? Pelajari bagaimana komputasi terdistribusi memungkinkan arsitektur yang skalabel seperti sharding.
Partitioning adalah proses membagi sebuah tabel basis data yang besar menjadi segmen-segmen yang lebih kecil dan mudah dikelola yang disebut partisi—semuanya tetap berada dalam server dan sistem basis data yang sama. Setiap partisi menampung subset data berdasarkan aturan tertentu, seperti rentang tanggal, wilayah geografis, atau ID pelanggan.
Berbeda dengan sharding, partitioning tidak menyebarkan data ke banyak mesin. Alih-alih, ini membantu mengorganisasi data secara internal untuk mempercepat kueri dan menyederhanakan pemeliharaan.Namun partitioning bukan sekadar urusan organisasi—ini berdampak langsung pada performa dan keterkelolaan data. Berikut beberapa manfaat utamanya:
Untuk lebih memahami partitioning secara praktis, mari lihat representasi visual. Pada contoh ini, data disimpan dalam satu basis data terpusat tetapi dipisahkan ke partisi logis berdasarkan lokasi pengguna atau jenis konten:
Partitioning dalam basis data terpusat. Data dipecah ke partisi logis (misalnya, berdasarkan lokasi atau jenis konten) untuk kinerja dan kemudahan pemeliharaan yang lebih baik. Gambar oleh Penulis.
Partitioning dapat diimplementasikan dengan berbagai cara, masing-masing disesuaikan dengan kebutuhan organisasi data dan optimisasi kueri tertentu. Jenis basis data yang berbeda akan dipartisi dengan cara berbeda untuk memastikan akses yang sederhana dan efisien.Contoh:
Data dibagi berdasarkan rentang nilai, seperti tanggal. Misalnya, transaksi dapat dipartisi berdasarkan bulan atau tahun. Ini sangat berguna untuk data deret waktu, di mana kueri sering berfokus pada rentang tanggal tertentu.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Data dibagi berdasarkan keluaran fungsi hash yang diterapkan pada kunci partisi. Ini memastikan distribusi data yang merata di seluruh partisi, meminimalkan hotspot. Misalnya, ID pengguna dapat di-hash untuk menentukan partisi tempat data pengguna akan disimpan, sehingga beban tersebar merata.
Contoh:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Data dibagi berdasarkan daftar kategori yang telah ditentukan. Misalnya, data pelanggan dapat dipartisi berdasarkan wilayah geografis atau jenis produk. Pendekatan ini bermanfaat untuk himpunan data dengan kategori yang jelas, memungkinkan kueri terarah untuk segmen tertentu.
Contoh:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Jika Anda baru mengenal cara data disimpan dan diquery dalam sistem terstruktur, kursus pengantar basis data relasional di SQL ini adalah tempat yang tepat untuk memulai.
Memahami perbedaan antara sharding dan partitioning sangat penting untuk memilih strategi yang tepat dalam mengelola himpunan data besar. Meskipun keduanya bertujuan mengoptimalkan performa dan skalabilitas basis data, keduanya beroperasi pada level yang berbeda dan melayani tujuan yang berbeda, seperti diuraikan di bawah ini.
|
Kategori |
Sharding |
Partitioning |
|
Cakupan |
Beroperasi di berbagai basis data atau server |
Terjadi dalam satu basis data |
|
Kompleksitas |
Kompleksitas lebih tinggi: melibatkan arsitektur dan koordinasi terdistribusi |
Kompleksitas lebih rendah: dikelola dalam satu sistem basis data |
|
Distribusi data |
Data dipecah dan disimpan pada node/shard yang berbeda |
Data dipecah menjadi partisi logis dalam sistem yang sama |
|
Skalabilitas |
Mendukung penskalaan horizontal dengan menambah server |
Mengoptimalkan performa tetapi tidak secara bawaan melakukan penskalaan lintas server |
|
Manajemen |
Memerlukan perencanaan matang, tooling kustom, dan penanganan konsistensi data |
Lebih mudah dipelihara dengan fitur bawaan basis data |
|
Performa kueri |
Bergantung pada kunci sharding yang tepat dan pola akses data |
Kueri dapat dioptimalkan secara otomatis melalui pemangkasan partisi (partition pruning) |
|
Use case |
Terbaik untuk aplikasi besar dan terdistribusi (misalnya, e-niaga, media sosial) |
Ideal untuk beban kerja analitik dan kueri data berbasis waktu/logis |
Memilih antara sharding dan partitioning tidak selalu jelas—ini bergantung pada skala, arsitektur, dan tujuan sistem Anda. Keduanya mengatasi performa dan keterkelolaan, tetapi dengan cara yang berbeda. Berikut cara menentukan mana yang sesuai dengan skenario Anda.
Gunakan sharding saat sistem Anda mencapai batas kemampuan yang dapat ditangani satu basis data:
Contoh: Situs e-niaga global dengan jutaan pengguna dan transaksi dapat melakukan sharding data berdasarkan wilayah pelanggan atau ID pengguna untuk memastikan akses yang cepat dan skalabel.
Gunakan partitioning saat data Anda berkembang besar, namun Anda masih beroperasi dalam satu server atau basis data:
Contoh: Perusahaan layanan keuangan yang menyimpan log transaksi dapat mempartisi tabel berdasarkan bulan untuk menjalankan laporan akhir bulan dengan cepat dan mengarsipkan catatan lama secara efisien.
Tidak semua basis data mendukung sharding atau partitioning secara bawaan—dan beberapa memerlukan ekstensi pihak ketiga atau implementasi kustom.
Berikut gambaran singkat bagaimana sistem basis data populer menangani sharding dan partitioning serta perangkat apa yang mungkin Anda butuhkan untuk mengimplementasikannya secara efektif:
|
Sistem Basis Data |
Dukungan Sharding |
Dukungan Partitioning |
Catatan / Perangkat |
|
PostgreSQL |
❌ Sharding native tidak bawaan (namun tersedia melalui ekstensi) |
✅ Dukungan native melalui sintaks |
Gunakan Citus untuk PostgreSQL terdistribusi dengan sharding |
|
MySQL |
✅ Didukung melalui perangkat seperti Vitess atau Fabric |
✅ Partitioning native range, list, hash |
Partitioning native sejak MySQL 5.1; sharding memerlukan perangkat orkestrasi |
|
MongoDB |
✅ Sharding otomatis bawaan |
❌ Tidak ada partitioning bawaan; mencapai efek serupa dengan shard key |
Ideal untuk beban kerja NoSQL terdistribusi |
|
Oracle Database |
❌ Tidak ada sharding di versi dasar (Enterprise Edition mendukung melalui Oracle Sharding) |
✅ Fitur partitioning canggih (range, list, hash, komposit) |
Partitioning kuat, tetapi sharding memerlukan lisensi Enterprise atau lebih tinggi |
|
SQL Server |
❌ Tidak ada sharding native; memerlukan implementasi kustom |
✅ Didukung melalui tabel dan indeks terpartisi |
Gunakan Partitioned Views atau Federated Databases untuk pseudo-sharding |
|
Amazon Redshift |
✅ Menggunakan kunci distribusi untuk menyebarkan data ke node |
✅ Dukungan native untuk partitioning kolumnar melalui sort dan distribution key |
Pilih gaya distribusi dengan cermat untuk join berskala besar |
|
Google BigQuery |
✅ Ditangani secara otomatis di balik layar |
✅ Mendukung tabel terpartisi (berdasarkan ingestion atau stempel waktu kustom) |
Sangat baik untuk analitik—tidak perlu sharding manual |
|
Cassandra |
✅ Sharding bawaan melalui consistent hashing |
❌ Tidak ada partitioning per se, tetapi data dibagi melalui partition key |
Diskalakan secara horizontal sejak desain awal |
|
ClickHouse |
✅ Sharding horizontal melalui klaster |
✅ Partitioning native berdasarkan kolom apa pun |
Sangat bertenaga untuk beban kerja OLAP |
|
CockroachDB |
✅ Sharding otomatis, geo-terdistribusi |
✅ Partitioning berbasis rentang untuk data regional |
Ideal untuk sistem SQL yang terdistribusi secara global |
>Pelajari bagaimana BigQuery mengotomatiskan sharding dan partitioning di balik layar dalam kursus pengantar ini. Untuk menyelami lebih dalam pendekatan Redshift terhadap penyimpanan terdistribusi dan partitioning, jelajahi kursus Redshift untuk pemula ini.
Sharding dan partitioning adalah teknik yang kuat untuk mengelola himpunan data besar, masing-masing dengan kekuatan dan penerapannya sendiri. Sharding penting untuk menskalakan sistem terdistribusi sementara partitioning mengoptimalkan performa kueri dan menyederhanakan manajemen data. Memahami konsep-konsep ini akan membantu ilmuwan data pemula merancang solusi basis data yang efisien dan skalabel.
Untuk informasi lebih lanjut, simak sumber tambahan tentang teknik penskalaan basis data dan optimisasi performa:
Pelajari lebih lanjut tentang basis data melalui kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
