
Course
Introduction to Relational Databases in SQL
4 hr
192.8K
Managing massive datasets isn’t just a technical challenge—it’s a strategic one. As data grows, so do the demands on storage, performance, and scalability. That’s where two essential techniques come into play: sharding and partitioning.
When I first encountered these concepts, they seemed similar at a glance—but digging deeper revealed some important differences that have a real impact on how systems are designed and scaled.
In this article, I’ll walk you through what sharding and partitioning really mean, how they differ, when to use each, and the pros and cons to consider when building data-intensive applications.
>To understand the foundations of how data is structured before it's partitioned or sharded, start with a solid grounding in database design.
Sharding is the process of dividing a database into smaller, more manageable pieces called "shards." Each shard contains a subset of the overall data and functions as an independent database.
The shards are distributed across multiple servers, enabling the system to handle large datasets and high volumes of traffic. This approach balances the load among servers and allows for tailored optimizations for specific shards based on their data.
The following diagram illustrates how sharding works in a distributed database system. Notice how a load balancer and a database management system (DBMS) work together to distribute incoming client requests across multiple shards.
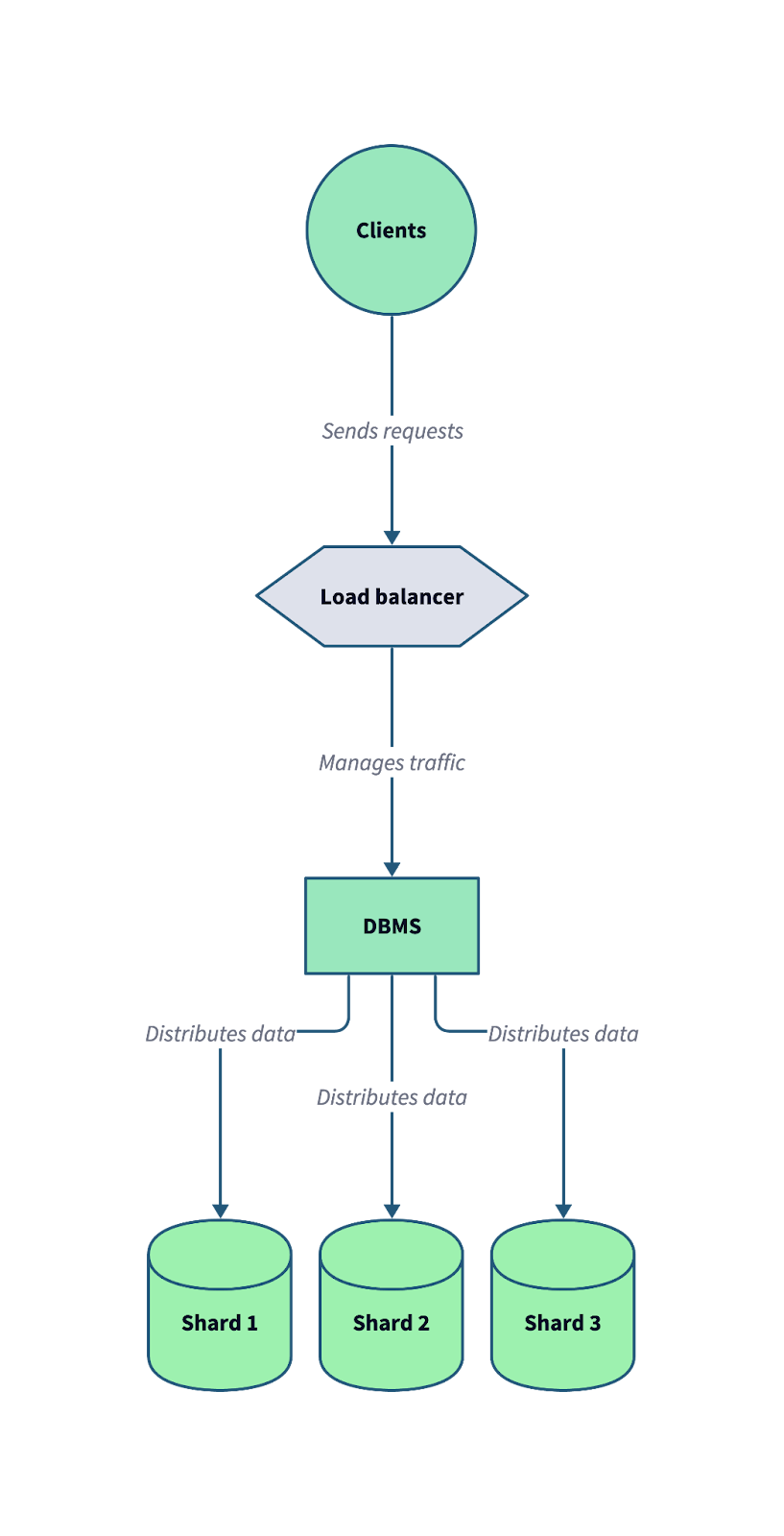
A typical sharded database architecture, where data is split across multiple independent shards to optimize scalability and fault tolerance. Image by Author.
By splitting data into shards, the system can distribute workloads more efficiently and scale horizontally to accommodate traffic and data volume growth.These are the benefits of sharding:
>Curious about the broader landscape of distributed systems? Learn how distributed computing enables scalable architectures like sharding.
Partitioning is the process of dividing a large database table into smaller, more manageable segments called partitions—all within the same server and database system. Each partition holds a subset of the data based on a specified rule, such as date ranges, geographic regions, or customer IDs.
Unlike sharding, partitioning doesn’t spread data across multiple machines. Instead, it helps organize data internally to speed up queries and simplify maintenance.But partitioning isn’t just about organization—it directly impacts performance and data manageability. Here are some of its key benefits:
To better understand partitioning in action, let’s look at a visual representation. In this example, data is stored in one central database but segmented into logical partitions based on user location or content type:
Partitioning within a central database. Data is split into logical partitions (e.g., by location or content type) for better performance and maintainability. Image by Author.
Partitioning can be implemented in various ways, each tailored to specific data organization and query optimization needs. Different types of databases will be partitioned differently to ensure simple and efficient access.Example:
Data is divided based on a range of values, such as dates. For example, transactions can be partitioned by month or year. This is particularly useful for time-series data, where queries often focus on specific date ranges.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Data is divided based on the hash function output applied to a partition key. This ensures an even distribution of data across partitions, minimizing hotspots. For instance, a user ID could be hashed to determine the partition where a user’s data will be stored, evenly spreading the load.
Example:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Data is divided based on a predefined list of categories. For instance, customer data might be partitioned by geographic region or product type. This approach benefits datasets with clearly defined categories, allowing targeted queries for specific segments.
Example:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> If you're new to how data is stored and queried in structured systems, this introduction to relational databases in SQL course is a great place to begin.
Understanding the differences between sharding and partitioning is crucial for selecting the appropriate strategy to manage large datasets. While both techniques aim to optimize database performance and scalability, they operate at different levels and serve distinct purposes, as outlined below.
|
Category |
Sharding |
Partitioning |
|
Scope |
Operates across multiple databases or servers |
Happens within a single database |
|
Complexity |
Higher complexity: involves distributed architecture and coordination |
Lower complexity: managed within one database system |
|
Data distribution |
Data is split and stored across different nodes/shards |
Data is split into logical partitions within the same system |
|
Scalability |
Supports horizontal scaling by adding servers |
Optimizes performance but doesn’t inherently scale across servers |
|
Management |
Requires careful planning, custom tooling, and data consistency handling |
Easier to maintain with built-in database features |
|
Query performance |
Depends on correct sharding key and data access patterns |
Queries can be optimized automatically through partition pruning |
|
Use cases |
Best for large-scale, distributed apps (e.g., e-commerce, social media) |
Ideal for analytical workloads and time-based/logical data queries |
Choosing between sharding and partitioning isn’t always obvious—it depends on the scale, architecture, and goals of your system. Both strategies address performance and manageability, but in different ways. Here’s how to decide which one fits your scenario.
Use sharding when your system is hitting the limits of what a single database can handle:
Example: A global e-commerce site with millions of users and transactions might shard data by customer region or user ID to ensure fast, scalable access.
Use partitioning when your data is growing large, but you're still operating within a single server or database:
Example: A financial services company storing transaction logs could partition tables by month to quickly run month-end reports and archive older records efficiently.
Not all databases support sharding or partitioning out of the box—and some require third-party extensions or custom implementations.
Here's a quick look at how popular database systems handle sharding and partitioning and what tools you might need to implement them effectively:
|
Database System |
Sharding Support |
Partitioning Support |
Notes / Tools |
|
PostgreSQL |
❌ Native sharding is not built-in (but available via extensions) |
✅ Native support via |
Use Citus for distributed PostgreSQL with sharding |
|
MySQL |
✅ Supported via tools like Vitess or Fabric |
✅ Native range, list, hash partitioning |
Native partitioning since MySQL 5.1; sharding needs orchestration tools |
|
MongoDB |
✅ Built-in automatic sharding |
❌ No built-in partitioning; achieves similar effects with shard keys |
Ideal for distributed NoSQL workloads |
|
Oracle Database |
❌ No sharding in basic versions (Enterprise Edition supports it via Oracle Sharding) |
✅ Advanced partitioning features (range, list, hash, composite) |
Partitioning is robust, but sharding needs Enterprise or higher license |
|
SQL Server |
❌ No native sharding; requires custom implementation |
✅ Supported via partitioned tables and indexes |
Use Partitioned Views or Federated Databases for pseudo-sharding |
|
Amazon Redshift |
✅ Uses distribution keys to distribute data across nodes |
✅ Native support for columnar partitioning via sort and distribution keys |
Choose distribution style carefully for large joins |
|
Google BigQuery |
✅ Handled automatically behind the scenes |
✅ Supports partitioned tables (by ingestion or custom timestamp) |
Great for analytics—no manual sharding needed |
|
Cassandra |
✅ Built-in sharding via consistent hashing |
❌ No partitioning per se, but data is divided via partition keys |
Scales horizontally by design |
|
ClickHouse |
✅ Horizontal sharding via clusters |
✅ Native partitioning by any column |
Very performant for OLAP workloads |
|
CockroachDB |
✅ Automatic, geo-distributed sharding |
✅ Range-based partitioning for regional data |
Ideal for globally distributed SQL systems |
>Learn how BigQuery automates sharding and partitioning behind the scenes in this introductory course. To dive deeper into Redshift’s approach to distributed storage and partitioning, explore this beginner-friendly Redshift course.
Sharding and partitioning are powerful techniques for managing large datasets, each with its own strengths and applications. Sharding is essential for scaling distributed systems while partitioning optimizes query performance and simplifies data management. Understanding these concepts will help beginner data scientists design efficient, scalable database solutions.
For more information, check out additional resources on database scaling techniques and performance optimization:
Learn more about databases with these courses!
Course
Course
Course
blog
Marie Fayard
7 min
blog
Srujana Maddula
12 min
blog
Allan Ouko
6 min
blog
Marie Fayard
8 min
blog
Mark Pedigo
13 min
Tutorial
Kurtis Pykes