
Cours
Introduction aux bases de données relationnelles en SQL
4 h
192.8K
La gestion d'énormes ensembles de données n'est pas seulement un défi technique, c'est aussi un défi stratégique. La croissance des données s'accompagne d'une augmentation des exigences en matière de stockage, de performances et d'évolutivité. C 'est là que deux techniques essentielles entrent en jeu : sharding et partitioning.
Lorsque j'ai rencontré ces concepts pour la première fois, ils m'ont semblé similaires à première vue, mais en creusant un peu, j'ai découvert des différences importantes qui ont un impact réel sur la façon dont les systèmes sont conçus et mis à l'échelle.
Dans cet article, je vous expliquerai ce que signifie réellement le sharding et le partitionnement, en quoi ils diffèrent, quand les utiliser et quels sont les avantages et les inconvénients à prendre en compte lors de la création d'applications à forte intensité de données.
>Pour comprendre les fondements de la structure des données avant qu'elles ne soient partitionnées ou partagées, commencez par acquérir de solides bases en matière de conception de bases de données.n conception de base de données.
Le sharding est le processus de division d'une base de données en éléments plus petits et plus faciles à gérer, appelés "shards". Chaque tesson contient un sous-ensemble de l'ensemble des données et fonctionne comme une base de données indépendante.
Les ensembles sont répartis sur plusieurs serveurs, ce qui permet au système de gérer des ensembles de données volumineux et des volumes de trafic importants. Cette approche permet d'équilibrer la charge entre les serveurs et d'effectuer des optimisations sur mesure pour des ensembles de données spécifiques en fonction de leurs données.
Le diagramme suivant illustre le fonctionnement du sharding dans un système de base de données distribué. Remarquez comment un équilibreur de charge et un système de gestion de base de données (SGBD) travaillent ensemble pour répartir les demandes des clients entrants sur plusieurs ensembles.
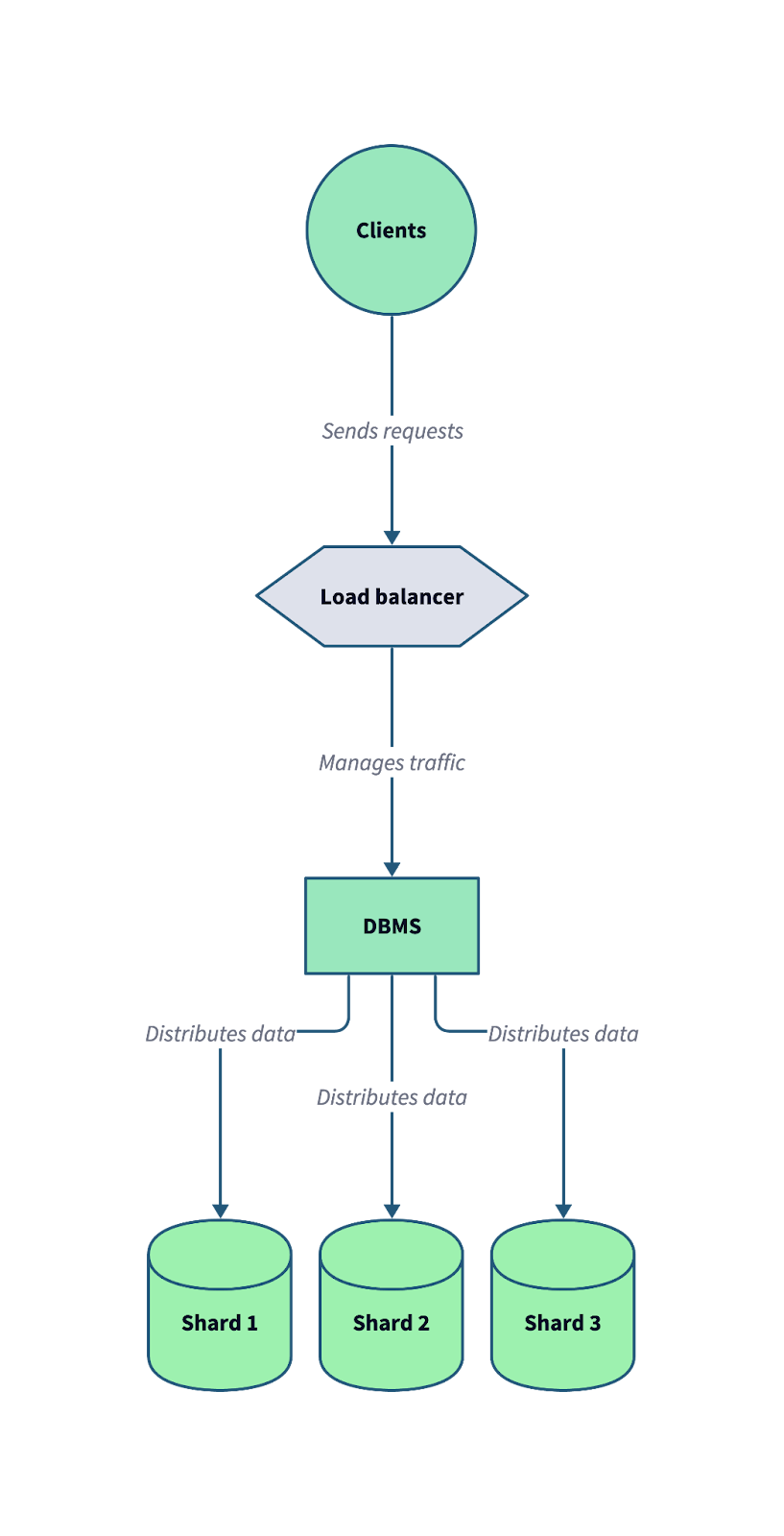
Architecture typique d'une base de données en grappes, où les données sont réparties sur plusieurs grappes indépendantes afin d'optimiser l'évolutivité et la tolérance aux pannes. Image par l'auteur.
En répartissant les données en plusieurs parties, le système peut distribuer les charges de travail plus efficacement et s'adapter horizontalement à la croissance du trafic et du volume de données.Tels sont les avantages du partage des données :
>Curieux de connaître le paysage plus large des systèmes distribués ? Apprenez comment w l' informatique distribuéepermet des architectures évolutives comme le sharding.
Le partitionnement consiste à diviser un tableau de base de données volumineux en segments plus petits et plus faciles à gérer, appelés partitions, le tout au sein du même serveur et du même système de base de données. Chaque partition contient un sous-ensemble de données basé sur une règle spécifique, comme des plages de dates, des régions géographiques ou des identifiants de clients.
Contrairement au partage, le partitionnement ne répartit pas les données sur plusieurs machines. Au contraire, il permet d'organiser les données en interne pour accélérer les requêtes et simplifier la maintenance.Mais le partitionnement n'est pas qu'une question d'organisation : il a un impact direct sur les performances et la facilité de gestion des données. Voici quelques-uns de ses principaux avantages :
Pour mieux comprendre le partitionnement en action, examinons une représentation visuelle. Dans cet exemple, les données sont stockées dans une base de données centrale mais segmentées en partitions logiques en fonction de la localisation de l'utilisateur ou du type de contenu :
Partitionnement au sein d'une base de données centrale. Les données sont divisées en partitions logiques (par exemple, par emplacement ou par type de contenu) afin d'améliorer les performances et la maintenabilité. Image par l'auteur.
Le partitionnement peut être mis en œuvre de différentes manières, chacune adaptée à des besoins spécifiques d'organisation des données et d'optimisation des requêtes. Les différents types de bases de données seront partitionnés différemment pour garantir un accès simple et efficace.Exemple :
Les données sont divisées en fonction d'une plage de valeurs, telles que des dates. Par exemple, les transactions peuvent être réparties par mois ou par année. Ceci est particulièrement utile pour les données de séries temporelles, où les requêtes se concentrent souvent sur des plages de dates spécifiques.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Les données sont divisées en fonction de la sortie de la fonction de hachage appliquée à une clé de partition. Cela garantit une répartition uniforme des données entre les partitions, minimisant ainsi les points chauds. Par exemple, l'identifiant d'un utilisateur peut être haché pour déterminer la partition où les données de l'utilisateur seront stockées, ce qui permet de répartir uniformément la charge.
Exemple :
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Les données sont divisées en fonction d'une liste prédéfinie de catégories. Par exemple, les données relatives aux clients peuvent être réparties par région géographique ou par type de produit. Cette approche profite aux ensembles de données dont les catégories sont clairement définies, ce qui permet d'effectuer des requêtes ciblées pour des segments spécifiques.
Exemple :
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Si vous ne savez pas comment les données sont stockées et interrogées dans des systèmes structurés, ce cours d'introduction aux bases de données relationnelles en SQL vous permettra de vous familiariser avec les bases de données relationnelles, ce cours d'introduction aux bases de données relationnelles en SQL est un excellent point de départ.
Il est essentiel de comprendre les différences entre le sharding et le partitionnement pour choisir la stratégie appropriée de gestion des grands ensembles de données. Si ces deux techniques visent à optimiser les performances et l'évolutivité des bases de données, elles opèrent à des niveaux différents et répondent à des objectifs distincts, comme indiqué ci-dessous.
|
Catégorie |
La mise en commun |
Cloisonnement |
|
Champ d'application |
Fonctionne sur plusieurs bases de données ou serveurs |
Se produit au sein d'une seule base de données |
|
Complexité |
Plus grande complexité : implique une architecture et une coordination distribuées |
Moins de complexité : gestion au sein d'un seul système de base de données |
|
Distribution des données |
Les données sont réparties et stockées sur différents nœuds/shards. |
Les données sont divisées en partitions logiques au sein d'un même système. |
|
Évolutivité |
Prise en charge de la mise à l'échelle horizontale par l'ajout de serveurs |
Optimise les performances, mais ne s'étend pas intrinsèquement à tous les serveurs. |
|
Gestion |
Nécessite une planification minutieuse, des outils personnalisés et un traitement cohérent des données. |
Plus facile à maintenir grâce aux fonctions de base de données intégrées |
|
Performances des requêtes |
Dépend de la bonne clé de répartition et des schémas d'accès aux données. |
Les requêtes peuvent être optimisées automatiquement par l'élagage des partitions. |
|
Cas d'utilisation |
Idéal pour les applications distribuées à grande échelle (commerce électronique, médias sociaux, etc.) |
Idéal pour les charges de travail analytiques et les requêtes de données temporelles/logiques |
Le choix entre le sharding et le partitionnement n'est pas toujours évident - il dépend de la taille, de l'architecture et des objectifs de votre système. Les deux stratégies portent sur les performances et la facilité de gestion, mais de manière différente. Voici comment choisir celui qui correspond le mieux à votre situation.
Utilisez le sharding lorsque votre système atteint les limites de ce qu'une seule base de données peut gérer :
Exemple : Un site de commerce électronique mondial comptant des millions d'utilisateurs et de transactions peut diviser les données par région de clientèle ou par identifiant d'utilisateur afin de garantir un accès rapide et évolutif.
Utilisez le partitionnement lorsque vos données deviennent volumineuses, mais que vous travaillez toujours sur un seul serveur ou une seule base de données :
Exemple : Une société de services financiers stockant des journaux de transactions pourrait partitionner les tableaux par mois afin d'exécuter rapidement les rapports de fin de mois et d'archiver efficacement les anciens enregistrements.
Toutes les bases de données ne prennent pas en charge le sharding ou le partitionnement dès le départ, et certaines nécessitent des extensions tierces ou des implémentations personnalisées.
Voici un bref aperçu de la manière dont les systèmes de base de données les plus répandus gèrent le sharding et le partitionnement, ainsi que des outils dont vous pourriez avoir besoin pour les mettre en œuvre efficacement :
|
Système de base de données |
Soutien au partage des responsabilités (Sharding) |
Support pour le partitionnement |
Notes / Outils |
|
PostgreSQL |
❌ Le sharding natif n'est pas intégré (mais disponible via des extensions) |
✅ Prise en charge native via la syntaxe |
Utilisez Citus pour PostgreSQL distribué avec sharding |
|
MySQL |
✅ Soutenu par des outils tels que Vitess ou Fabric |
✅ Partitionnement natif des plages, des listes et des hachages |
Partitionnement natif depuis MySQL 5.1 ; le sharding nécessite des outils d'orchestration |
|
MongoDB |
✅ Partage automatique intégré |
❌ Pas de partitionnement intégré ; permet d'obtenir des effets similaires avec des clés de répartition. |
Idéal pour les charges de travail NoSQL distribuées |
|
Base de données Oracle |
❌ Pas de sharding dans les versions de base (Enterprise Edition le supporte via Oracle Sharding) |
Fonctionnalités avancées de partitionnement (plage, liste, hachage, composite) |
Le partitionnement est robuste, mais le sharding nécessite une licence Enterprise ou supérieure. |
|
Serveur SQL |
❌ Pas de sharding natif ; nécessite une implémentation personnalisée |
✅ Prise en charge via des tableaux et des index partitionnés |
Utilisez les vues partitionnées ou les bases de données fédérées pour le pseudo-sharding. |
|
Amazon Redshift |
✅ Utilise des clés de distribution pour répartir les données entre les nœuds |
✅ Prise en charge native du partitionnement en colonnes via des clés de tri et de distribution |
Choisissez soigneusement le style de distribution pour les joints importants |
|
Google BigQuery |
✅ Traitement automatique dans les coulisses |
✅ Prise en charge des tableaux partitionnés (par ingestion ou par horodatage personnalisé). |
Idéal pour les analyses - pas besoin de sharding manuel |
|
Cassandra |
✅ Sharding intégré par hachage cohérent |
❌ Pas de partitionnement à proprement parler, mais les données sont divisées via des clés de partitionnement |
L'échelle est horizontale de par sa conception |
|
ClickHouse |
✅ Partage horizontal via des clusters |
✅ Partitionnement natif par n'importe quelle colonne |
Très performant pour les charges de travail OLAP |
|
CockroachDB |
✅ Sharding automatique et géo-distribué |
✅ Partitionnement basé sur l'étendue pour les données régionales |
Idéal pour les systèmes SQL distribués à l'échelle mondiale |
>Apprenez comment BigQuery automatise le sharding et le partitionnement dans les coulisses dans ce cours d'introduction. Pour approfondir l'approche de Redshift en matière de stockage distribué et de partitionnement, explorez ce cours sur Redshift adapté aux débutants.
Le sharding et le partitionnement sont des techniques puissantes de gestion de grands ensembles de données, chacune ayant ses propres atouts et applications. Le sharding est essentiel pour la mise à l'échelle des systèmes distribués, tandis que le partitionnement optimise les performances des requêtes et simplifie la gestion des données. La compréhension de ces concepts aidera les scientifiques débutants à concevoir des solutions de base de données efficaces et évolutives.
Pour plus d'informations, consultezdes ressources supplémentaires sur les techniques de mise à l'échelle des bases de données et l'optimisation des performances :
Apprenez-en plus sur les bases de données grâce à ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Tutoriel
Samuel Shaibu
Tutoriel
Allan Ouko
Tutoriel
Sejal Jaiswal

