
Corso
Introduzione ai database relazionali in SQL
4 h
194.7K
Gestire dataset enormi non è solo una sfida tecnica: è anche strategica. Con la crescita dei dati aumentano anche le esigenze di storage, prestazioni e scalabilità. È qui che entrano in gioco due tecniche fondamentali: sharding e partitioning.
Quando ho incontrato per la prima volta questi concetti, a colpo d’occhio sembravano simili—ma approfondendo ho scoperto differenze importanti che influiscono davvero su come i sistemi vengono progettati e scalati.
In questo articolo ti spiegherò cosa significano davvero sharding e partitioning, in cosa differiscono, quando usare l’uno o l’altro e i pro e i contro da considerare quando costruisci applicazioni data-intensive.
>Per capire le basi di come i dati sono strutturati prima che vengano partizionati o shardati, parti da fondamenta solide con il database design.
Lo sharding è il processo di suddivisione di un database in parti più piccole e gestibili chiamate "shard". Ogni shard contiene un sottoinsieme dei dati complessivi e funziona come un database indipendente.
Gli shard sono distribuiti su più server, consentendo al sistema di gestire dataset di grandi dimensioni e alti volumi di traffico. Questo approccio bilancia il carico tra i server e permette ottimizzazioni mirate per shard specifici in base ai loro dati.
Il seguente diagramma illustra come funziona lo sharding in un sistema di database distribuito. Nota come un load balancer e un sistema di gestione del database (DBMS) lavorino insieme per distribuire le richieste dei client in arrivo su più shard.
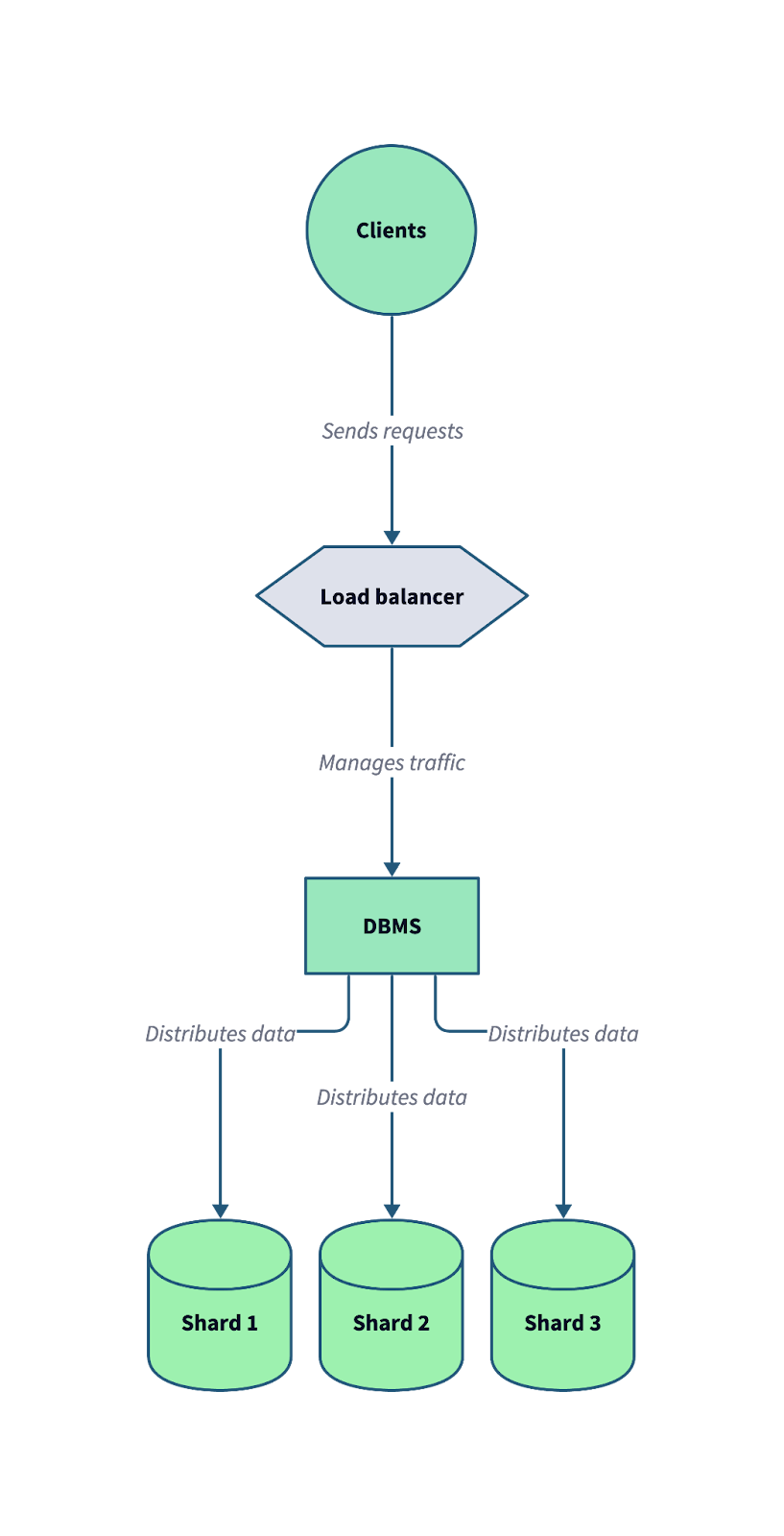
Un’architettura tipica di database shardato, in cui i dati sono suddivisi tra più shard indipendenti per ottimizzare scalabilità e tolleranza ai guasti. Immagine dell’autore.
Suddividendo i dati in shard, il sistema può distribuire i carichi di lavoro in modo più efficiente e scalare orizzontalmente per gestire la crescita del traffico e del volume dei dati.Questi sono i vantaggi dello sharding:
>Ti incuriosisce il panorama più ampio dei sistemi distribuiti? Scopri come il distributed computing abilita architetture scalabili come lo sharding.
Il partitioning è il processo di suddivisione di una grande tabella di database in segmenti più piccoli e gestibili chiamati partition—all’interno dello stesso server e sistema di database. Ogni partition contiene un sottoinsieme dei dati in base a una regola specifica, come intervalli di date, aree geografiche o ID cliente.
A differenza dello sharding, il partitioning non distribuisce i dati su più macchine. Aiuta invece a organizzare i dati internamente per velocizzare le query e semplificare la manutenzione.Ma il partitioning non riguarda solo l’organizzazione: ha un impatto diretto su prestazioni e gestibilità dei dati. Ecco alcuni dei suoi vantaggi principali:
Per capire meglio il partitioning in pratica, guardiamo una rappresentazione visiva. In questo esempio, i dati sono archiviati in un database centrale ma segmentati in partition logiche in base alla posizione dell’utente o al tipo di contenuto:
Partitioning all’interno di un database centrale. I dati sono suddivisi in partition logiche (ad esempio per posizione o tipo di contenuto) per migliorare prestazioni e manutenibilità. Immagine dell’autore.
Il partitioning può essere implementato in vari modi, ciascuno adatto a specifiche esigenze di organizzazione dei dati e ottimizzazione delle query. Tipi diversi di database saranno partizionati in modo diverso per garantire un accesso semplice ed efficiente.Esempio:
I dati sono suddivisi in base a un intervallo di valori, come le date. Ad esempio, le transazioni possono essere partizionate per mese o anno. È particolarmente utile per i dati time-series, dove le query si concentrano spesso su intervalli di date specifici.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);I dati sono suddivisi in base all’output di una funzione di hash applicata a una chiave di partition. Questo garantisce una distribuzione uniforme dei dati tra le partition, riducendo i punti caldi. Per esempio, un ID utente può essere sottoposto a hash per determinare la partition in cui verranno memorizzati i suoi dati, distribuendo uniformemente il carico.
Esempio:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;I dati sono suddivisi in base a un elenco predefinito di categorie. Ad esempio, i dati dei clienti possono essere partizionati per area geografica o tipo di prodotto. Questo approccio è utile per dataset con categorie ben definite, permettendo query mirate su segmenti specifici.
Esempio:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Se sei alle prime armi con l’archiviazione e l’interrogazione dei dati nei sistemi strutturati, questo corso di introduzione ai database relazionali in SQL è un ottimo punto di partenza.
Capire le differenze tra sharding e partitioning è fondamentale per scegliere la strategia giusta per gestire grandi dataset. Sebbene entrambe le tecniche puntino a ottimizzare prestazioni e scalabilità del database, operano a livelli diversi e servono scopi distinti, come descritto di seguito.
|
Categoria |
Sharding |
Partitioning |
|
Portata |
Opera su più database o server |
Avviene all’interno di un singolo database |
|
Complessità |
Maggiore complessità: comporta architettura distribuita e coordinamento |
Minore complessità: gestito all’interno di un unico sistema di database |
|
Distribuzione dei dati |
I dati sono suddivisi e archiviati su nodi/shard diversi |
I dati sono suddivisi in partition logiche all’interno dello stesso sistema |
|
Scalabilità |
Supporta la scalabilità orizzontale aggiungendo server |
Ottimizza le prestazioni ma non scala intrinsecamente su più server |
|
Gestione |
Richiede pianificazione accurata, strumenti personalizzati e gestione della consistenza dei dati |
Più facile da mantenere con funzionalità integrate del database |
|
Prestazioni delle query |
Dipendono dalla corretta scelta della sharding key e dai pattern di accesso ai dati |
Le query possono essere ottimizzate automaticamente tramite partition pruning |
|
Casi d’uso |
Ideale per app distribuite su larga scala (ad es., e-commerce, social media) |
Ideale per carichi analitici e query su dati basati su tempo/logica |
Scegliere tra sharding e partitioning non è sempre ovvio—dipende da scala, architettura e obiettivi del tuo sistema. Entrambe le strategie affrontano prestazioni e gestibilità, ma in modi diversi. Ecco come decidere quale si adatta al tuo scenario.
Usa lo sharding quando il tuo sistema sta raggiungendo i limiti di ciò che un singolo database può gestire:
Esempio: un sito e-commerce globale con milioni di utenti e transazioni potrebbe shardare i dati per area clienti o ID utente per garantire accesso rapido e scalabile.
Usa il partitioning quando i tuoi dati stanno crescendo, ma operi ancora all’interno di un singolo server o database:
Esempio: un’azienda di servizi finanziari che archivia log di transazioni potrebbe partizionare le tabelle per mese per eseguire rapidamente i report di fine mese e archiviare in modo efficiente i record più vecchi.
Non tutti i database supportano sharding o partitioning nativamente—alcuni richiedono estensioni di terze parti o implementazioni personalizzate.
Ecco una panoramica veloce di come i sistemi di database più diffusi gestiscono sharding e partitioning e quali strumenti potresti dover usare per implementarli in modo efficace:
|
Sistema di database |
Supporto Sharding |
Supporto Partitioning |
Note / Strumenti |
|
PostgreSQL |
❌ Lo sharding nativo non è integrato (ma disponibile tramite estensioni) |
✅ Supporto nativo tramite sintassi |
Usa Citus per PostgreSQL distribuito con sharding |
|
MySQL |
✅ Supportato tramite strumenti come Vitess o Fabric |
✅ Partitioning nativo per range, list, hash |
Partitioning nativo da MySQL 5.1; lo sharding richiede strumenti di orchestrazione |
|
MongoDB |
✅ Sharding automatico integrato |
❌ Nessun partitioning integrato; ottiene effetti simili con shard key |
Ideale per carichi NoSQL distribuiti |
|
Oracle Database |
❌ Niente sharding nelle versioni base (Enterprise Edition lo supporta tramite Oracle Sharding) |
✅ Funzionalità avanzate di partitioning (range, list, hash, composite) |
Il partitioning è robusto, ma lo sharding richiede licenza Enterprise o superiore |
|
SQL Server |
❌ Nessuno sharding nativo; richiede implementazione personalizzata |
✅ Supportato tramite tabelle e indici partizionati |
Usa Partitioned Views o Federated Databases per pseudo-sharding |
|
Amazon Redshift |
✅ Usa chiavi di distribuzione per distribuire i dati tra i nodi |
✅ Supporto nativo per partitioning colonnare tramite chiavi di ordinamento e distribuzione |
Scegli con cura lo stile di distribuzione per join di grandi dimensioni |
|
Google BigQuery |
✅ Gestito automaticamente dietro le quinte |
✅ Supporta tabelle partizionate (per ingestione o timestamp personalizzato) |
Ottimo per l’analitica—niente sharding manuale necessario |
|
Cassandra |
✅ Sharding integrato tramite hashing consistente |
❌ Nessun partitioning in quanto tale, ma i dati sono suddivisi tramite chiavi di partition |
Scala orizzontalmente per progettazione |
|
ClickHouse |
✅ Sharding orizzontale tramite cluster |
✅ Partitioning nativo per qualsiasi colonna |
Molto performante per workload OLAP |
|
CockroachDB |
✅ Sharding automatico, geo-distribuito |
✅ Partitioning basato su range per dati regionali |
Ideale per sistemi SQL distribuiti a livello globale |
>Scopri come BigQuery automatizza sharding e partitioning dietro le quinte in questo corso introduttivo. Per approfondire l’approccio di Redshift all’archiviazione distribuita e al partitioning, esplora questo corso Redshift per principianti.
Sharding e partitioning sono tecniche potenti per gestire grandi dataset, ciascuna con i propri punti di forza e applicazioni. Lo sharding è essenziale per scalare sistemi distribuiti, mentre il partitioning ottimizza le prestazioni delle query e semplifica la gestione dei dati. Comprendere questi concetti aiuterà i data scientist alle prime armi a progettare soluzioni di database efficienti e scalabili.
Per maggiori informazioni, dai un’occhiata ad altre risorse sulle tecniche di scaling dei database e sull’ottimizzazione delle prestazioni:
Approfondisci i database con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

