
Cursus
Introductie tot relationele databases in SQL
4 Hr
194.7K
Het beheren van gigantische datasets is niet alleen een technische uitdaging—het is ook een strategische. Naarmate data groeit, nemen ook de eisen aan opslag, performance en schaalbaarheid toe. Daar komen twee essentiële technieken om de hoek kijken: sharding en partitioning.
Toen ik deze concepten voor het eerst tegenkwam, leken ze op het eerste gezicht op elkaar—maar bij nader inzien bleken er belangrijke verschillen te zijn die echt impact hebben op hoe systemen worden ontworpen en opgeschaald.
In dit artikel leg ik uit wat sharding en partitioning precies betekenen, hoe ze van elkaar verschillen, wanneer je welke inzet, en de voor- en nadelen om mee te nemen bij het bouwen van data-intensieve applicaties.
>Om de basis te begrijpen van hoe data is gestructureerd voordat deze wordt gepartitioneerd of geshard, begin je met een stevige basis in databaseontwerp.
Sharding is het opsplitsen van een database in kleinere, beter beheersbare delen, zogenaamde "shards". Elke shard bevat een subset van de totale data en functioneert als een zelfstandige database.
De shards worden over meerdere servers verspreid, waardoor het systeem grote datasets en hoge verkeersvolumes aankan. Deze aanpak verdeelt de belasting over servers en maakt gerichte optimalisaties per shard mogelijk, afhankelijk van de data daarin.
Het onderstaande diagram laat zien hoe sharding werkt in een gedistribueerd databasesysteem. Let op hoe een load balancer en een databasebeheersysteem (DBMS) samenwerken om inkomende clientverzoeken over meerdere shards te verdelen.
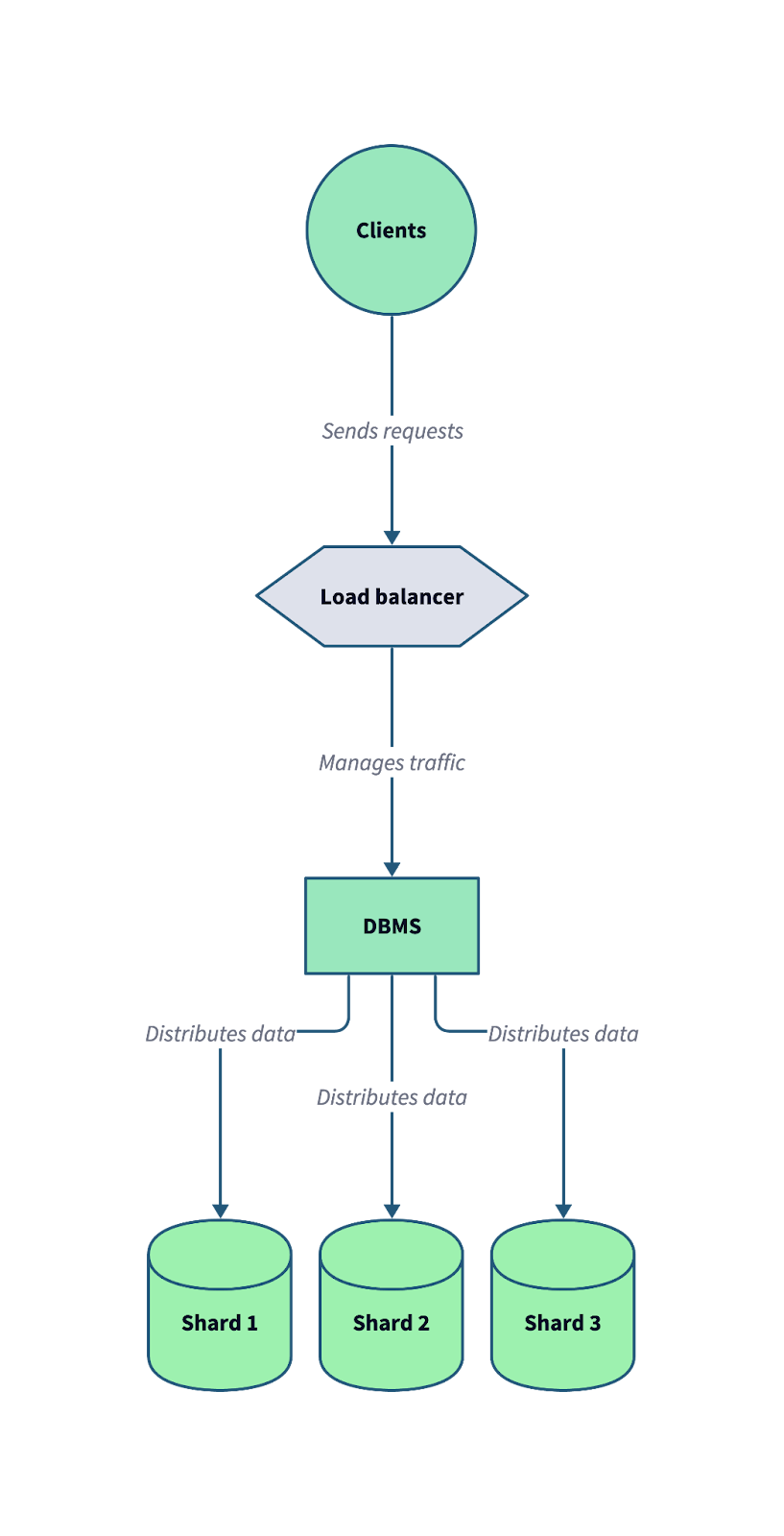
Een typische geshardde databasearchitectuur, waarbij data over meerdere onafhankelijke shards wordt verdeeld om schaalbaarheid en fouttolerantie te optimaliseren. Afbeelding door de auteur.
Door data in shards op te splitsen kan het systeem workloads efficiënter verdelen en horizontaal schalen om groei in verkeer en datavolume op te vangen.Dit zijn de voordelen van sharding:
>Nieuwsgierig naar het bredere landschap van gedistribueerde systemen? Leer hoe distributed computing schaalbare architecturen zoals sharding mogelijk maakt.
Partitioning is het opsplitsen van een grote databasetabel in kleinere, beter beheersbare segmenten, zogenaamde partitions—allemaal binnen dezelfde server en hetzelfde databasesysteem. Elke partition bevat een subset van de data op basis van een bepaalde regel, zoals datumbereiken, geografische regio’s of klant-ID’s.
In tegenstelling tot sharding spreidt partitioning data niet over meerdere machines. In plaats daarvan helpt het om data intern te organiseren om queries te versnellen en onderhoud te vereenvoudigen.Maar partitioning draait niet alleen om organisatie—het heeft directe invloed op performance en beheerbaarheid van data. Dit zijn enkele belangrijke voordelen:
Om partitioning in de praktijk beter te begrijpen, bekijken we een visuele weergave. In dit voorbeeld wordt data opgeslagen in één centrale database maar logisch opgedeeld in partitions op basis van gebruikerslocatie of contenttype:
Partitioning binnen een centrale database. Data wordt opgesplitst in logische partitions (bijv. op locatie of contenttype) voor betere performance en onderhoudbaarheid. Afbeelding door de auteur.
Partitioning kan op verschillende manieren worden geïmplementeerd, elk afgestemd op specifieke behoeften voor data-organisatie en query-optimalisatie. Verschillende soorten databases worden op verschillende manieren gepartitioneerd om eenvoudige en efficiënte toegang te waarborgen.Voorbeeld:
Data wordt verdeeld op basis van een bereik aan waarden, zoals datums. Zo kunnen transacties per maand of jaar worden gepartitioneerd. Dit is vooral nuttig voor time-series data, waarbij queries vaak op specifieke datumbereiken focussen.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Data wordt verdeeld op basis van de output van een hashfunctie die wordt toegepast op een partition key. Dit zorgt voor een gelijkmatige verdeling van data over partitions en minimaliseert hotspots. Een gebruikers-ID kan bijvoorbeeld worden gehasht om te bepalen in welke partition de data van een gebruiker wordt opgeslagen, waardoor de load gelijkmatig wordt verspreid.
Voorbeeld:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Data wordt verdeeld op basis van een vooraf gedefinieerde lijst met categorieën. Zo kan klantdata worden gepartitioneerd per geografische regio of producttype. Deze aanpak is gunstig voor datasets met duidelijk afgebakende categorieën en maakt gerichte queries op specifieke segmenten mogelijk.
Voorbeeld:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Als je nieuw bent met hoe data wordt opgeslagen en bevraagd in gestructureerde systemen, is deze cursus Introductie tot relationele databases in SQL een uitstekend startpunt.
Het begrijpen van de verschillen tussen sharding en partitioning is cruciaal om de juiste strategie te kiezen voor het beheren van grote datasets. Hoewel beide technieken gericht zijn op het optimaliseren van databaseperformance en schaalbaarheid, werken ze op verschillende niveaus en dienen ze andere doelen, zoals hieronder uiteengezet.
|
Categorie |
Sharding |
Partitioning |
|
Reikwijdte |
Werkt over meerdere databases of servers |
Vindt plaats binnen één database |
|
Complexiteit |
Hogere complexiteit: omvat gedistribueerde architectuur en coördinatie |
Lagere complexiteit: beheerd binnen één databasesysteem |
|
Datadistributie |
Data wordt opgesplitst en opgeslagen over verschillende nodes/shards |
Data wordt opgesplitst in logische partitions binnen hetzelfde systeem |
|
Schaalbaarheid |
Ondersteunt horizontaal schalen door servers toe te voegen |
Optimaliseert performance maar schaalt niet inherent over servers |
|
Beheer |
Vereist zorgvuldige planning, custom tooling en omgaan met dataconsistentie |
Makkelijker te onderhouden met ingebouwde databasefeatures |
|
Queryperformance |
Hangt af van de juiste shardingsleutel en data-toegangspatronen |
Queries kunnen automatisch worden geoptimaliseerd via partition pruning |
|
Use cases |
Het beste voor grootschalige, gedistribueerde apps (bijv. e-commerce, social media) |
Ideaal voor analytische workloads en tijdsgebonden/logische dataqueries |
Kiezen tussen sharding en partitioning is niet altijd eenvoudig—het hangt af van de schaal, architectuur en doelen van je systeem. Beide strategieën pakken performance en beheersbaarheid aan, maar op verschillende manieren. Zo bepaal je welke past bij jouw scenario.
Gebruik sharding wanneer je systeem de grenzen bereikt van wat één database aankan:
Voorbeeld: Een wereldwijd e-commerceplatform met miljoenen gebruikers en transacties kan data sharden op klantregio of gebruikers-ID om snelle, schaalbare toegang te garanderen.
Gebruik partitioning wanneer je data flink groeit, maar je nog steeds binnen één server of database opereert:
Voorbeeld: Een financiële dienstverlener die transactie-logs opslaat, kan tabellen per maand partitioneren om snel maandrapportages te draaien en oudere records efficiënt te archiveren.
Niet alle databases ondersteunen sharding of partitioning out of the box—en sommige vereisen third-party extensies of custom implementaties.
Hier is een kort overzicht van hoe populaire databasesystemen omgaan met sharding en partitioning en welke tools je mogelijk nodig hebt om ze effectief te implementeren:
|
Databasesysteem |
Sharding-ondersteuning |
Partitioning-ondersteuning |
Notities / Tools |
|
PostgreSQL |
❌ Native sharding is niet ingebouwd (wel via extensies) |
✅ Native ondersteuning via |
Gebruik Citus voor gedistribueerde PostgreSQL met sharding |
|
MySQL |
✅ Ondersteund via tools zoals Vitess of Fabric |
✅ Native range-, list-, hash-partitioning |
Native partitioning sinds MySQL 5.1; sharding vereist orchestratietools |
|
MongoDB |
✅ Ingebouwde automatische sharding |
❌ Geen ingebouwde partitioning; bereikt vergelijkbare effecten met shard keys |
Ideaal voor gedistribueerde NoSQL-workloads |
|
Oracle Database |
❌ Geen sharding in basisversies (Enterprise Edition ondersteunt het via Oracle Sharding) |
✅ Geavanceerde partitioning-features (range, list, hash, composiet) |
Partitioning is robuust, maar sharding vereist Enterprise- of hogere licentie |
|
SQL Server |
❌ Geen native sharding; vereist custom implementatie |
✅ Ondersteund via gepartitioneerde tabellen en indexen |
Gebruik Partitioned Views of Federated Databases voor pseudo-sharding |
|
Amazon Redshift |
✅ Gebruikt distributiesleutels om data over nodes te verdelen |
✅ Native ondersteuning voor kolomgebaseerde partitioning via sort- en distributiesleutels |
Kies de distributiestijl zorgvuldig voor grote joins |
|
Google BigQuery |
✅ Wordt automatisch achter de schermen afgehandeld |
✅ Ondersteunt gepartitioneerde tabellen (op basis van ingestie of aangepaste timestamp) |
Geweldig voor analytics—geen handmatige sharding nodig |
|
Cassandra |
✅ Ingebouwde sharding via consistente hashing |
❌ Geen partitioning an sich, maar data wordt verdeeld via partition keys |
Schaalt horizontaal by design |
|
ClickHouse |
✅ Horizontale sharding via clusters |
✅ Native partitioning op elke kolom |
Zeer performant voor OLAP-workloads |
|
CockroachDB |
✅ Automatische, geo-gedistribueerde sharding |
✅ Range-gebaseerde partitioning voor regionale data |
Ideaal voor wereldwijd gedistribueerde SQL-systemen |
>Ontdek hoe BigQuery sharding en partitioning achter de schermen automatiseert in deze introductiecursus. Wil je dieper duiken in Redshifts aanpak van gedistribueerde opslag en partitioning, bekijk dan deze toegankelijke Redshift-cursus.
Sharding en partitioning zijn krachtige technieken om grote datasets te beheren, elk met eigen sterke punten en toepassingen. Sharding is essentieel om gedistribueerde systemen op te schalen, terwijl partitioning queryperformance optimaliseert en databeheer vereenvoudigt. Het begrijpen van deze concepten helpt beginnende data scientists om efficiënte, schaalbare databasesoplossingen te ontwerpen.
Voor meer informatie, bekijk aanvullende bronnen over technieken voor databaseschaling en performance-optimalisatie:
Leer meer over databases met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
