
Curso
Introducción a las bases de datos relacionales en SQL
4 h
192.8K
Gestionar conjuntos de datos masivos no es sólo un reto técnico, sino estratégico. A medida que crecen los datos, también lo hacen las demandas de almacenamiento, rendimiento y escalabilidad. Ahí es donde entran en juego dos técnicas esenciales: sharding y partitioning.
Cuando me encontré por primera vez con estos conceptos, me parecieron similares a primera vista, pero al profundizar en ellos descubrí algunas diferencias importantes que tienen un impacto real en cómo se diseñan y escalan los sistemas.
En este artículo, te explicaré qué significan realmente la fragmentación y la partición, en qué se diferencian, cuándo utilizar cada una, y los pros y los contras que hay que tener en cuenta al crear aplicaciones con gran cantidad de datos.
>Para entender los fundamentos de cómo se estructuran los datos antes de particionarlos o fragmentarlos, empieza con una base sólida en el diseño de bases de datos.en el diseño de bases de datos.
Sharding es el proceso de dividir una base de datos en piezas más pequeñas y manejables llamadas "shards". Cada fragmento contiene un subconjunto de los datos globales y funciona como una base de datos independiente.
Los fragmentos están distribuidos en varios servidores, lo que permite al sistema manejar grandes conjuntos de datos y grandes volúmenes de tráfico. Este enfoque equilibra la carga entre servidores y permite optimizaciones a medida para shards específicos en función de sus datos.
El siguiente diagrama ilustra cómo funciona la fragmentación en un sistema de base de datos distribuido. Observa cómo un equilibrador de carga y un sistema de gestión de bases de datos (SGBD) trabajan juntos para distribuir las peticiones entrantes de los clientes entre varios fragmentos.
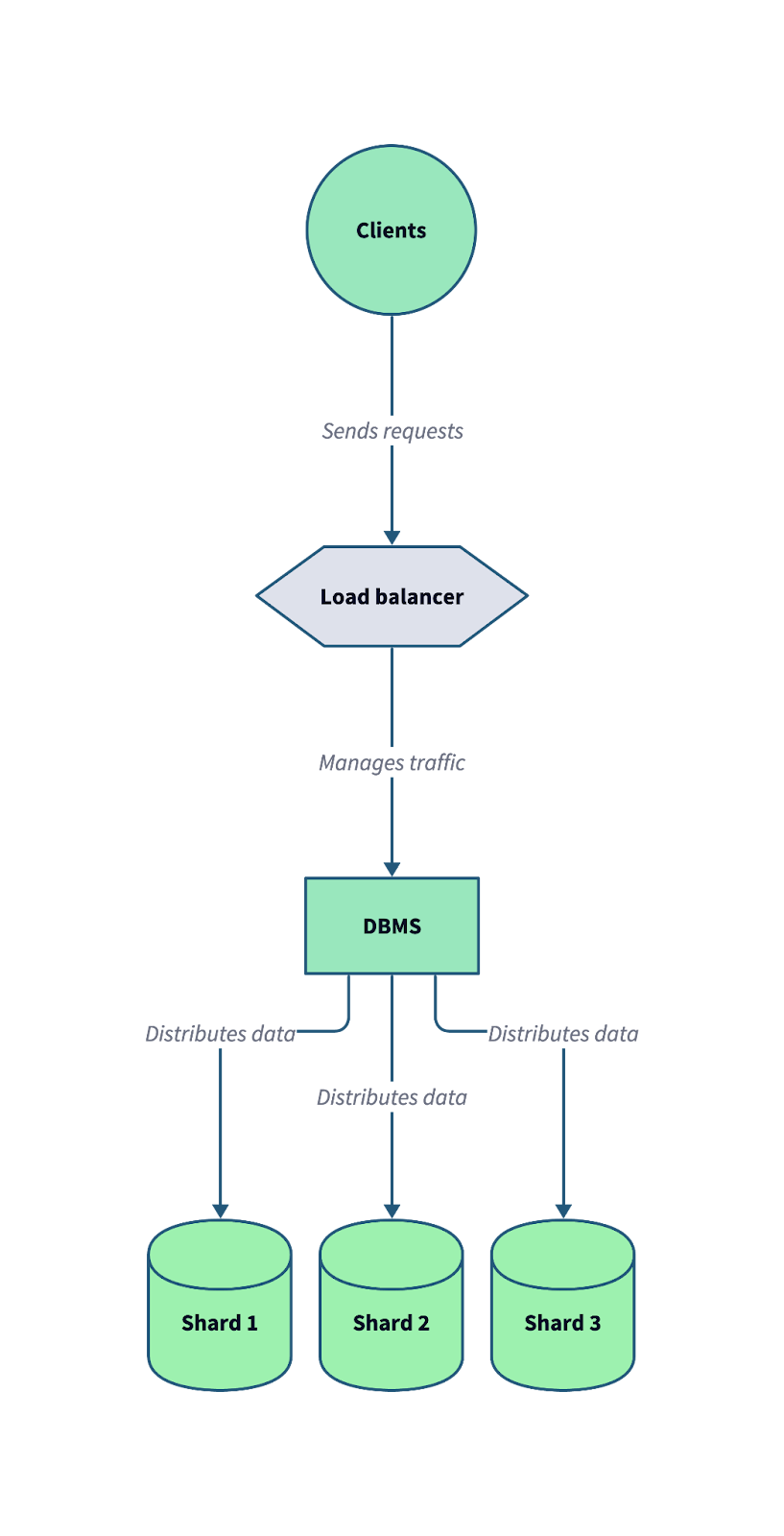
Una arquitectura típica de base de datos fragmentada, en la que los datos se dividen en varios fragmentos independientes para optimizar la escalabilidad y la tolerancia a fallos. Imagen del autor.
Al dividir los datos en fragmentos, el sistema puede distribuir las cargas de trabajo de forma más eficiente y escalar horizontalmente para adaptarse al crecimiento del tráfico y del volumen de datos.Estas son las ventajas de la fragmentación:
>¿Tienes curiosidad por conocer el panorama más amplio de los sistemas distribuidos? Aprende cómo la informática distribuida depermite arquitecturas escalables como la fragmentación.
Particionar es el proceso de dividir una tabla de base de datos grande en segmentos más pequeños y manejables, llamados particiones, todo ello dentro del mismo servidor y sistema de base de datos. Cada partición contiene un subconjunto de los datos basado en una regla especificada, como intervalos de fechas, regiones geográficas o ID de cliente.
A diferencia de la fragmentación, la partición no distribuye los datos entre varias máquinas. En cambio, ayuda a organizar los datos internamente para acelerar las consultas y simplificar el mantenimiento.Pero la partición no es sólo organización: afecta directamente al rendimiento y a la capacidad de gestión de los datos. He aquí algunas de sus principales ventajas:
Para comprender mejor la partición en acción, veamos una representación visual. En este ejemplo, los datos se almacenan en una base de datos central, pero segmentada en particiones lógicas basadas en la ubicación del usuario o en el tipo de contenido:
Partición dentro de una base de datos central. Los datos se dividen en particiones lógicas (por ejemplo, por ubicación o tipo de contenido) para mejorar el rendimiento y la capacidad de mantenimiento. Imagen del autor.
La partición puede implementarse de varias formas, cada una adaptada a las necesidades específicas de organización de datos y optimización de consultas. Los distintos tipos de bases de datos se particionarán de forma diferente para garantizar un acceso sencillo y eficaz.Ejemplo:
Los datos se dividen en función de un rango de valores, como las fechas. Por ejemplo, las transacciones pueden dividirse por meses o años. Esto es especialmente útil para los datos de series temporales, en los que las consultas suelen centrarse en intervalos de fechas concretos.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Los datos se dividen en función de la salida de la función hash aplicada a una clave de partición. Esto garantiza una distribución uniforme de los datos entre las particiones, minimizando los puntos calientes. Por ejemplo, se podría hacer un hash de un ID de usuario para determinar la partición donde se almacenarán los datos de un usuario, repartiendo uniformemente la carga.
Ejemplo:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Los datos se dividen según una lista predefinida de categorías. Por ejemplo, los datos de los clientes pueden dividirse por región geográfica o tipo de producto. Este enfoque beneficia a los conjuntos de datos con categorías claramente definidas, permitiendo consultas dirigidas a segmentos específicos.
Ejemplo:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Si no conoces cómo se almacenan y consultan los datos en sistemas estructurados, este curso de introducción a las bases de datos relacionales en SQL es un buen punto de partida.
Comprender las diferencias entre fragmentación y partición es crucial para seleccionar la estrategia adecuada para gestionar grandes conjuntos de datos. Aunque ambas técnicas pretenden optimizar el rendimiento y la escalabilidad de la base de datos, operan a niveles distintos y sirven a propósitos diferentes, como se expone a continuación.
|
Categoría |
Fragmentación |
Partición |
|
Alcance |
Funciona en varias bases de datos o servidores |
Ocurre dentro de una única base de datos |
|
Complejidad |
Mayor complejidad: implica arquitectura distribuida y coordinación |
Menor complejidad: se gestiona dentro de un sistema de base de datos |
|
Distribución de datos |
Los datos se dividen y almacenan en diferentes nodos/shards |
Los datos se dividen en particiones lógicas dentro del mismo sistema |
|
Escalabilidad |
Admite el escalado horizontal añadiendo servidores |
Optimiza el rendimiento, pero no escala intrínsecamente entre servidores |
|
Gestión |
Requiere una planificación cuidadosa, herramientas personalizadas y gestión de la coherencia de los datos |
Más fácil de mantener gracias a las funciones de base de datos integradas |
|
Rendimiento de la consulta |
Depende de la clave de fragmentación correcta y de los patrones de acceso a los datos |
Las consultas pueden optimizarse automáticamente mediante la poda de particiones |
|
Casos prácticos |
Lo mejor para aplicaciones distribuidas a gran escala (por ejemplo, comercio electrónico, redes sociales) |
Ideal para cargas de trabajo analíticas y consultas de datos temporales/lógicas |
Elegir entre fragmentación y partición no siempre es obvio: depende de la escala, la arquitectura y los objetivos de tu sistema. Ambas estrategias abordan el rendimiento y la manejabilidad, pero de formas distintas. He aquí cómo decidir cuál se adapta a tu situación.
Utiliza la fragmentación cuando tu sistema esté alcanzando los límites de lo que puede manejar una sola base de datos:
Ejemplo: Un sitio de comercio electrónico global con millones de usuarios y transacciones podría fragmentar los datos por región del cliente o ID de usuario para garantizar un acceso rápido y escalable.
Utiliza la partición cuando tus datos aumenten de tamaño, pero sigas operando dentro de un único servidor o base de datos:
Ejemplo: Una empresa de servicios financieros que almacene registros de transacciones podría particionar las tablas por meses para ejecutar rápidamente informes de fin de mes y archivar registros antiguos de forma eficiente.
No todas las bases de datos admiten la fragmentación o la partición de forma inmediata, y algunas requieren extensiones de terceros o implementaciones personalizadas.
He aquí un rápido vistazo a la forma en que los sistemas de bases de datos más populares gestionan la fragmentación y el particionamiento, y a las herramientas que puedes necesitar para aplicarlos eficazmente:
|
Sistema de base de datos |
Soporte para sharding |
Soporte de particionado |
Notas / Herramientas |
|
PostgreSQL |
❌ La fragmentación nativa no está integrada (pero está disponible a través de extensiones) |
✅ Soporte nativo mediante la sintaxis |
Utilizar Citus para PostgreSQL distribuido con sharding |
|
MySQL |
✅ Apoyado mediante herramientas como Vitess o Fabric |
✅ Partición nativa de rango, lista y hash |
Particionamiento nativo desde MySQL 5.1; el sharding necesita herramientas de orquestación |
|
MongoDB |
✅ Fragmentación automática incorporada |
❌ No hay partición incorporada; se consiguen efectos similares con claves de fragmentación |
Ideal para cargas de trabajo NoSQL distribuidas |
|
Base de datos Oracle |
❌ No hay fragmentación en las versiones básicas (la Edición Enterprise la admite mediante Oracle Sharding) |
✅ Funciones avanzadas de partición (rango, lista, hash, compuesto) |
La partición es robusta, pero la fragmentación necesita licencia Enterprise o superior |
|
Servidor SQL |
❌ No hay fragmentación nativa; requiere una implementación personalizada |
✅ Compatible con tablas e índices particionados |
Utiliza Vistas Particionadas o Bases de Datos Federadas para la pseudodistribución |
|
Amazon Redshift |
✅ Utiliza claves de distribución para distribuir los datos entre los nodos |
✅ Soporte nativo para la partición en columnas mediante claves de ordenación y distribución |
Elige bien el estilo de distribución para las uniones grandes |
|
Google BigQuery |
✅ Se gestiona automáticamente entre bastidores |
✅ Admite tablas particionadas (por ingestión o marca de tiempo personalizada) |
Ideal para análisis: no se necesita fragmentación manual |
|
Cassandra |
✅ Fragmentación integrada mediante hashing coherente |
❌ No hay partición propiamente dicha, pero los datos se dividen mediante claves de partición |
Escala horizontalmente por diseño |
|
ClickHouse |
✅ Fragmentación horizontal mediante clusters |
✅ Partición nativa por cualquier columna |
Muy eficaz para cargas de trabajo OLAP |
|
CockroachDB |
✅ Fragmentación automática y geodistribuida |
✅ Partición basada en rangos para datos regionales |
Ideal para sistemas SQL distribuidos globalmente |
>Aprende cómo BigQuery automatiza el sharding y el particionamiento entre bastidores en este curso introductorio. Para profundizar en el enfoque de Redshift sobre el almacenamiento distribuido y la partición, explora este curso de Redshift para principiantes.
La fragmentación y la partición son técnicas potentes para gestionar grandes conjuntos de datos, cada una con sus propios puntos fuertes y aplicaciones. La fragmentación es esencial para escalar los sistemas distribuidos, mientras que la partición optimiza el rendimiento de las consultas y simplifica la gestión de los datos. Comprender estos conceptos ayudará a los científicos de datos principiantes a diseñar soluciones de bases de datos eficientes y escalables.
Para más información, consultarecursos adicionales sobre técnicas de escalado de bases de datos y optimización del rendimiento:
Aprende más sobre bases de datos con estos cursos
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Tim Lu
12 min
blog
Kurtis Pykes
11 min
blog
Mona Khalil
5 min
Tutorial
Oluseye Jeremiah
Tutorial
Anneleen Rummens