
Curso
Introdução aos bancos de dados relacionais em SQL
4 h
192.8K
O gerenciamento de conjuntos de dados maciços não é apenas um desafio técnico - é um desafio estratégico. À medida que os dados crescem, aumentam também as demandas de armazenamento, desempenho e escalabilidade. É aí que entram em ação duas técnicas essenciais: sharding e particionamento.
Quando me deparei com esses conceitos pela primeira vez, eles pareciam semelhantes à primeira vista, mas uma análise mais profunda revelou algumas diferenças importantes que têm um impacto real sobre como os sistemas são projetados e dimensionados.
Neste artigo, mostrarei a você o que realmente significa sharding e particionamento, como eles diferem, quando usar cada um e os prós e contras a serem considerados ao criar aplicativos com uso intenso de dados.
>Para entender os fundamentos de como os dados são estruturados antes de serem particionados ou fragmentados, comece com uma base sólida emno design do banco de dados.
Sharding é o processo de dividir um banco de dados em partes menores e mais gerenciáveis, chamadas "shards". Cada fragmento contém um subconjunto dos dados gerais e funciona como um banco de dados independente.
Os fragmentos são distribuídos em vários servidores, permitindo que o sistema lide com grandes conjuntos de dados e altos volumes de tráfego. Essa abordagem equilibra a carga entre os servidores e permite otimizações personalizadas para shards específicos com base em seus dados.
O diagrama a seguir ilustra como o sharding funciona em um sistema de banco de dados distribuído. Observe como um balanceador de carga e um sistema de gerenciamento de banco de dados (DBMS) trabalham juntos para distribuir as solicitações de entrada de clientes em vários shards.
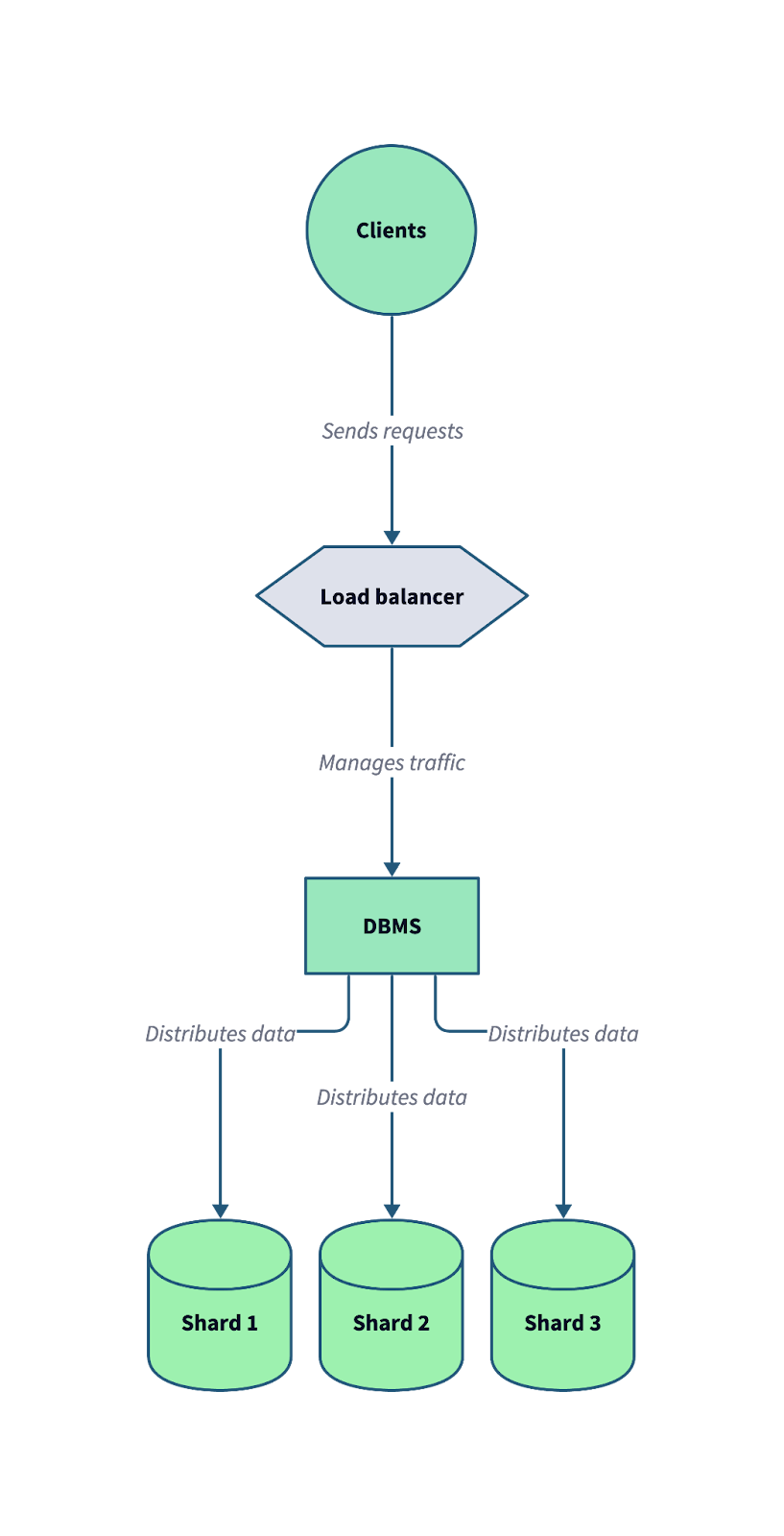
Uma arquitetura típica de banco de dados sharded, em que os dados são divididos em vários shards independentes para otimizar a escalabilidade e a tolerância a falhas. Imagem do autor.
Ao dividir os dados em fragmentos, o sistema pode distribuir as cargas de trabalho com mais eficiência e dimensionar horizontalmente para acomodar o crescimento do tráfego e do volume de dados.Esses são os benefícios do sharding:
>Você está curioso sobre o cenário mais amplo dos sistemas distribuídos? Saiba comoa w computação distribuídapermite arquiteturas dimensionáveis como sharding.
O particionamento é o processo de dividir uma tabela de banco de dados grande em segmentos menores e mais gerenciáveis, chamados de partições - tudo dentro do mesmo servidor e sistema de banco de dados. Cada partição contém um subconjunto de dados com base em uma regra especificada, como intervalos de datas, regiões geográficas ou IDs de clientes.
Ao contrário do sharding, o particionamento não distribui os dados entre várias máquinas. Em vez disso, ele ajuda a organizar os dados internamente para acelerar as consultas e simplificar a manutenção.Mas o particionamento não se trata apenas de organização - ele afeta diretamente o desempenho e a capacidade de gerenciamento dos dados. Aqui estão alguns de seus principais benefícios:
Para que você entenda melhor o particionamento em ação, vamos dar uma olhada em uma representação visual. Nesse exemplo, os dados são armazenados em um banco de dados central, mas segmentados em partições lógicas com base na localização do usuário ou no tipo de conteúdo:
Particionamento em um banco de dados central. Os dados são divididos em partições lógicas (por exemplo, por local ou tipo de conteúdo) para melhorar o desempenho e a capacidade de manutenção. Imagem do autor.
O particionamento pode ser implementado de várias maneiras, cada uma delas adaptada às necessidades específicas de organização de dados e otimização de consultas. Tipos diferentes de bancos de dados serão particionados de forma diferente para garantir um acesso simples e eficiente.Exemplo:
Os dados são divididos com base em um intervalo de valores, como datas. Por exemplo, as transações podem ser divididas por mês ou ano. Isso é particularmente útil para dados de séries temporais, em que as consultas geralmente se concentram em intervalos de datas específicos.
CREATE TABLE transactions (
id INT,
transaction_date DATE,
amount DECIMAL
)
PARTITION BY RANGE (transaction_date) (
PARTITION p_2024_q1 VALUES LESS THAN ('2024-04-01'),
PARTITION p_2024_q2 VALUES LESS THAN ('2024-07-01'),
PARTITION p_2024_q3 VALUES LESS THAN ('2024-10-01'),
PARTITION p_2024_q4 VALUES LESS THAN ('2025-01-01')
);Os dados são divididos com base na saída da função hash aplicada a uma chave de partição. Isso garante uma distribuição uniforme dos dados entre as partições, minimizando os pontos de acesso. Por exemplo, um ID de usuário pode ser submetido a hash para determinar a partição onde os dados de um usuário serão armazenados, distribuindo uniformemente a carga.
Exemplo:
CREATE TABLE user_activity (
user_id INT,
activity TEXT
)
PARTITION BY HASH(user_id) PARTITIONS 4;Os dados são divididos com base em uma lista predefinida de categorias. Por exemplo, os dados do cliente podem ser divididos por região geográfica ou tipo de produto. Essa abordagem beneficia conjuntos de dados com categorias claramente definidas, permitindo consultas direcionadas a segmentos específicos.
Exemplo:
CREATE TABLE customer_data (
customer_id INT,
region TEXT
)
PARTITION BY LIST (region) (
PARTITION us_customers VALUES IN ('US'),
PARTITION eu_customers VALUES IN ('EU'),
PARTITION apac_customers VALUES IN ('APAC')
);> Se você ainda não sabe como os dados são armazenados e consultados em sistemas estruturados, você pode começar com este curso de introdução aos bancos de dados relacionais em SQL é um ótimo lugar para você começar.
Compreender as diferenças entre sharding e particionamento é fundamental para selecionar a estratégia apropriada para gerenciar grandes conjuntos de dados. Embora ambas as técnicas tenham como objetivo otimizar o desempenho e o dimensionamento do banco de dados, elas operam em níveis diferentes e atendem a finalidades distintas, conforme descrito a seguir.
|
Categoria |
Fragmentação |
Particionamento |
|
Escopo |
Opera em vários bancos de dados ou servidores |
Ocorre em um único banco de dados |
|
Complexidade |
Maior complexidade: envolve arquitetura e coordenação distribuídas |
Menor complexidade: gerenciado em um único sistema de banco de dados |
|
Distribuição de dados |
Os dados são divididos e armazenados em diferentes nós/shards |
Os dados são divididos em partições lógicas dentro do mesmo sistema |
|
Escalabilidade |
Oferece suporte ao dimensionamento horizontal por meio da adição de servidores |
Otimiza o desempenho, mas não é inerentemente dimensionado entre servidores |
|
Gerenciamento |
Requer planejamento cuidadoso, ferramentas personalizadas e tratamento da consistência dos dados |
Mais fácil de manter com os recursos de banco de dados incorporados |
|
Desempenho da consulta |
Depende da chave de fragmentação correta e dos padrões de acesso aos dados |
As consultas podem ser otimizadas automaticamente por meio da poda de partição |
|
Casos de uso |
Melhor para aplicativos distribuídos e de grande escala (por exemplo, comércio eletrônico, mídia social) |
Ideal para cargas de trabalho analíticas e consultas de dados lógicos/baseados em tempo |
A escolha entre sharding e particionamento nem sempre é óbvia - depende da escala,da arquitetura edos objetivos do seu sistema. Ambas as estratégias abordam o desempenho e a capacidade de gerenciamento, mas de maneiras diferentes. Veja como você pode decidir qual deles se encaixa no seu cenário.
Use o sharding quando seu sistema estiver atingindo os limites do que um único banco de dados pode suportar:
Exemplo: Um site global de comércio eletrônico com milhões de usuários e transações pode fragmentar os dados por região do cliente ou ID do usuário para garantir acesso rápido e escalonável.
Use o particionamento quando seus dados estiverem crescendo, mas você ainda estiver operando em um único servidor ou banco de dados:
Exemplo: Uma empresa de serviços financeiros que armazena logs de transações pode particionar tabelas por mês para executar rapidamente relatórios de fim de mês e arquivar registros antigos com eficiência.
Nem todos os bancos de dados são compatíveis com sharding ou particionamento prontos para uso, e alguns exigem extensões de terceiros ou implementações personalizadas.
Veja a seguir como os sistemas de banco de dados populares lidam com sharding e particionamento e quais ferramentas você pode precisar para implementá-los de forma eficaz:
|
Sistema de banco de dados |
Suporte a fragmentação |
Suporte a particionamento |
Notas / Ferramentas |
|
PostgreSQL |
A fragmentação nativa não está incorporada (mas está disponível por meio de extensões) |
Suporte nativo por meio da sintaxe |
Use o Citus para PostgreSQL distribuído com sharding |
|
MySQL |
Suportado por ferramentas como Vitess ou Fabric |
Intervalo nativo, lista, particionamento de hash |
Particionamento nativo desde o MySQL 5.1; o sharding precisa de ferramentas de orquestração |
|
MongoDB |
Distribuição automática integrada |
Não há particionamento integrado; você consegue efeitos semelhantes com chaves de fragmento |
Ideal para cargas de trabalho NoSQL distribuídas |
|
Banco de dados Oracle |
Não há sharding nas versões básicas (a Enterprise Edition oferece suporte via Oracle Sharding) |
Recursos avançados de particionamento (intervalo, lista, hash, composto) |
O particionamento é robusto, mas o sharding precisa de uma licença Enterprise ou superior |
|
SQL Server |
Não há fragmentação nativa; requer implementação personalizada |
✅ Suportado por tabelas e índices particionados |
Use exibições particionadas ou bancos de dados federados para pseudo-armazenamento |
|
Amazon Redshift |
Usa chaves de distribuição para distribuir dados entre os nós |
Suporte nativo para particionamento colunar por meio de chaves de classificação e distribuição |
Escolha cuidadosamente o estilo de distribuição para juntas grandes |
|
Google BigQuery |
Tratada automaticamente nos bastidores |
✅ Suporta tabelas particionadas (por ingestão ou carimbo de data/hora personalizado) |
Excelente para análises - sem necessidade de fragmentação manual |
|
Cassandra |
Armazenamento integrado por meio de hashing consistente |
Não há particionamento em si, mas os dados são divididos por meio de chaves de partição |
Escala horizontal por design |
|
ClickHouse |
Fragmentação horizontal por meio de clusters |
Particionamento nativo por qualquer coluna |
Muito eficiente para cargas de trabalho OLAP |
|
CockroachDB |
Sharding automático e geodistribuído |
Particionamento baseado em intervalo para dados regionais |
Ideal para sistemas SQL distribuídos globalmente |
>Saiba como o BigQuery automatiza a fragmentação e o particionamento nos bastidores neste curso introdutório. Para se aprofundar na abordagem do Redshift em relação ao armazenamento distribuído e ao particionamento, explore este curso de Redshift para iniciantes.
Sharding e particionamento são técnicas poderosas para gerenciar grandes conjuntos de dados, cada uma com seus próprios pontos fortes e aplicações. A fragmentação é essencial para o dimensionamento de sistemas distribuídos, enquanto o particionamento otimiza o desempenho da consulta e simplifica o gerenciamento de dados. A compreensão desses conceitos ajudará os cientistas de dados iniciantes a projetar soluções de banco de dados eficientes e dimensionáveis.
Para obter mais informações, confiraos recursos adicionais sobre técnicas de dimensionamento de banco de dados e otimização de desempenho:
Aprenda mais sobre bancos de dados com estes cursos!
Curso
Curso
Curso
blog
Mike Shakhomirov
11 min
blog
Kurtis Pykes
11 min
blog
Zoumana Keita
12 min
blog
Tim Lu
12 min
Tutorial
DataCamp Team
Tutorial
Kurtis Pykes

