
Kurs
Yapay Zekayı Anlamak
2 sa
409.4K
Vektör veritabanı, belirli özellikleri veya nitelikleri temsil eden çok boyutlu vektörler biçiminde bilgi saklayan özel bir veritabanı türüdür.
Her vektördeki boyut sayısı, verinin karmaşıklığına ve ayrıntı düzeyine bağlı olarak birkaçdan birkaç bine kadar değişebilir. Metin, görsel, ses ve video gibi bu veriler; makine öğrenimi modelleri, kelime gömme (word embeddings) yöntemleri veya özellik çıkarımı teknikleri gibi çeşitli süreçlerle vektörlere dönüştürülür.
Bir vektör veritabanının temel avantajı, verileri vektör yakınlığına veya benzerliğine göre hızlı ve isabetli biçimde bulup getirebilmesidir. Bu sayede, geleneksel veritabanlarında olduğu gibi yalnızca bire bir eşleşmelere veya sabit ölçütlere dayanmak yerine, anlamsal veya bağlamsal uygunluğa dayalı aramalar yapılabilir.
Örneğin, bir vektör veritabanıyla şunları yapabilirsiniz:
Geleneksel veritabanları, kelimeler ve sayılar gibi basit verileri tablo biçiminde saklar. Vektör veritabanları ise vektör adı verilen karmaşık verilerle çalışır ve arama için özgün yöntemler kullanır.
Klasik veritabanları tam eşleşen verileri ararken, vektör veritabanları belirli benzerlik ölçütlerini kullanarak en yakın eşleşmeyi bulur.
Vektör veritabanları, karma yaklaşımlar içeren yaklaşımlar olan Yaklaşık En Yakın Komşu (Approximate Nearest Neighbor, ANN) arama tekniklerini kullanır; buna hashing ve grafik tabanlı aramalar da dahildir.
Vektör veritabanlarının nasıl çalıştığını ve SQL gibi geleneksel ilişkisel veritabanlarından nasıl farklılaştığını gerçekten anlamak için önce gömme (embedding) kavramını kavramamız gerekir.
Metin, görsel ve ses gibi yapılandırılmamış verilerin önceden tanımlanmış bir biçimi yoktur; bu da geleneksel veritabanları için zorluk yaratır. Bu verilerden yapay zeka ve makine öğrenimi uygulamalarında yararlanmak için, gömmeler kullanılarak sayısal temsillere dönüştürülür.
Gömme, bir kelime, görsel ya da başka bir öğeye anlamını veya özünü yakalayan benzersiz bir kod vermeye benzer. Bu kod, bilgisayarların bu öğeleri daha verimli ve anlamlı biçimde anlamasına ve karşılaştırmasına yardımcı olur. Bunu, karmaşık bir kitabı ana fikirleri koruyan kısa bir özete dönüştürmek gibi düşünebilirsiniz.
Bu gömme süreci genellikle görev için tasarlanmış özel bir sinir ağı kullanılarak gerçekleştirilir. Örneğin, kelime gömmeleri, benzer anlama sahip kelimelerin vektör uzayında birbirine daha yakın olacağı şekilde kelimeleri vektörlere dönüştürür.
Bu dönüşüm, algoritmaların öğeler arasındaki ilişkileri ve benzerlikleri anlamasına olanak tanır.
Özünde gömmeler, sayısal olmayan veriyi makine öğrenimi modellerinin çalışabileceği bir biçime dönüştüren bir köprü görevi görür; böylece verideki örüntüleri ve ilişkileri daha etkili biçimde ayırt edebilirler.
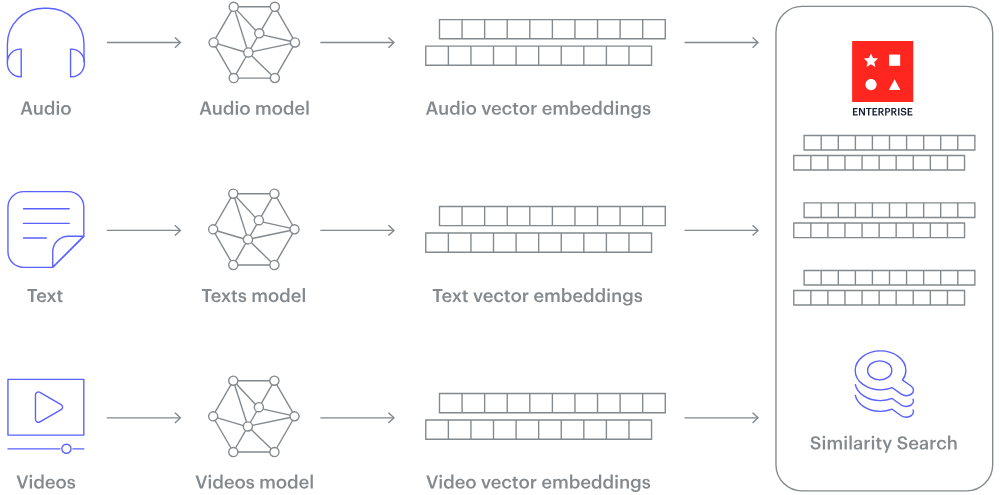
Bir vektör veritabanı nasıl çalışır? (Görsel kaynağı)
Vektör veritabanları, benzersiz yetenekleriyle, “benzerlik araması”nı verimli biçimde uygulayabildikleri için pek çok sektörde kendilerine yer açıyor. İşte çeşitli kullanım alanlarına daha yakından bir bakış:
Hareketli perakende sektöründe vektör veritabanları, tüketicilerin alışveriş biçimini dönüştürüyor. Kişiselleştirilmiş alışveriş deneyimleri sunan gelişmiş öneri sistemlerinin oluşturulmasını sağlıyorlar. Örneğin, bir çevrim içi alışverişçi, sadece geçmiş satın alımlara göre değil; ürün özelliklerindeki benzerlikler, kullanıcı davranışları ve tercihler analiz edilerek de ürün önerileri alabilir.
Finans sektörü karmaşık örüntüler ve trendlerle doludur. Vektör veritabanları bu yoğun veriyi analiz etmede üstünlük sağlar; finansal analistlerin yatırım stratejileri için kritik örüntüleri saptamasına yardımcı olur. İnce benzerlikleri veya sapmaları fark ederek piyasa hareketlerini öngörebilir ve daha bilinçli yatırım planları geliştirebilirler.
Sağlık alanında kişiselleştirme çok önemlidir. Genom dizilimlerini analiz ederek vektör veritabanları, tıbbi çözümlerin bireysel genetik yapıyla daha yakından örtüşmesini sağlayan daha kişiye özel tedavileri mümkün kılar.
Dijital dünyada chatbot’lar ve sanal asistanlar hızla yayılıyor. Bu AI tabanlı varlıklar, insan dilini anlamaya büyük ölçüde dayanır. Geniş metin verilerini vektörlere dönüştürerek bu sistemler, insan sorularını daha doğru anlayıp yanıtlayabilir. Örneğin Talkmap gibi şirketler, müşteri-temsilci etkileşimlerini daha akıcı hale getiren gerçek zamanlı doğal dil anlama kullanır.
Tıbbi taramalardan güvenlik görüntülerine kadar, görselleri doğru biçimde karşılaştırıp anlamak kritik önemdedir. Vektör veritabanları, görsellerin temel özelliklerine odaklanarak gürültü ve bozulmaları filtreleyip bu süreci kolaylaştırır. Örneğin, trafik yönetiminde video akışlarından alınan görüntüler hızlıca analiz edilerek trafik akışı optimize edilebilir ve kamu güvenliği artırılabilir.
Aykırı değerleri saptamak, benzerlikleri tanımak kadar önemlidir. Özellikle finans ve güvenlik gibi sektörlerde anomali tespiti, dolandırıcılığı önlemek veya potansiyel bir güvenlik ihlalini erkenden yakalamak anlamına gelebilir. Vektör veritabanları bu alanda gelişmiş yetenekler sunar; tespit sürecini daha hızlı ve hassas hale getirir.
Vektör veritabanları, görseller, videolar ve metinler gibi yapılandırılmamış veri dünyasında, insan tarafından üretilen etiketlere veya tag’lere aşırı bağımlı olmadan gezinmek için güçlü araçlar olarak öne çıktı. Yetenekleri, gelişmiş makine öğrenimi modelleriyle entegre edildiğinde; e-ticaretten ilaç sektörüne kadar birçok alanda devrim yaratma potansiyeli taşır. İşte vektör veritabanlarını oyunun kurallarını değiştiren teknoloji haline getiren öne çıkan özelliklerden bazıları:
Sağlam bir vektör veritabanı, veri büyüdükçe — milyonlara hatta milyarlara ulaştığında — birden çok düğüm (node) arasında zahmetsizce ölçeklenir. En iyi vektör veritabanları; ekleme hızı, sorgu hızı ve altyapı gibi değişkenlere göre sistemi ayarlamaya olanak tanıyan uyarlanabilirlik sunar.
Birden fazla kullanıcıyı barındırmak veritabanları için standart bir beklentidir. Ancak her kullanıcı için yeni bir vektör veritabanı oluşturmak verimli değildir. Vektör veritabanları, veri izolasyonunu önceler; böylece bir veri koleksiyonunda yapılan değişiklikler, sahibi özellikle paylaşmadıkça diğerleri tarafından görülmez. Bu, çoklu kiracılığı (multi-tenancy) desteklemenin yanı sıra verinin gizliliğini ve güvenliğini de sağlar.
Gerçek ve etkili bir veritabanı, eksiksiz bir API ve SDK seti sunar. Bu sayede sistem, çeşitli uygulamalarla etkileşime girebilir ve etkin biçimde yönetilebilir. Pinecone gibi önde gelen vektör veritabanları; Python, Node, Go ve Java gibi çeşitli programlama dillerinde SDK’lar sağlayarak geliştirme ve yönetimde esneklik sunar.
Yeni teknolojilerle ilişkili dik öğrenme eğrisini azaltmak için, vektör veritabanlarındaki kullanıcı dostu arayüzler kritik bir rol oynar. Bu arayüzler görsel bir genel bakış, kolay gezinme ve aksi takdirde gözden kaçabilecek özelliklere erişim sunar.
Liste belirli bir sıralama gözetmiyor — her biri yukarıdaki bölümde belirtilen niteliklerin çoğunu sergiliyor.
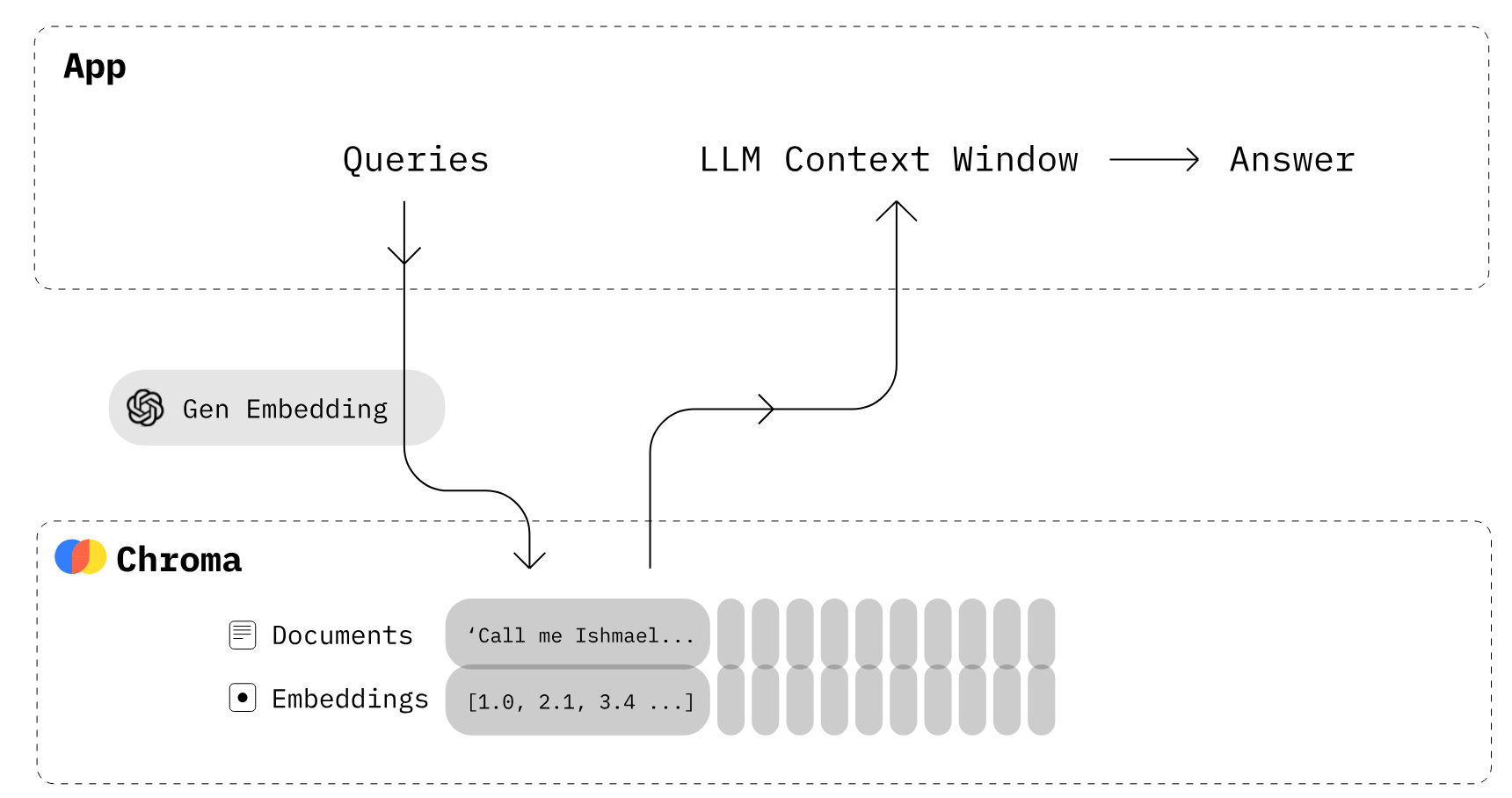
ChromaDB kullanarak LLM Uygulamaları oluşturma (Görsel kaynağı)
Chroma, açık kaynaklı bir embedding veritabanıdır. Chroma, LLM’ler için bilgi, gerçekler ve becerileri tak-çalıştır hale getirerek LLM uygulamalarını oluşturmayı kolaylaştırır. Chroma DB eğitiminde ele aldığımız gibi, metin belgelerini kolayca yönetebilir, metni gömmelere dönüştürebilir ve benzerlik aramaları yapabilirsiniz.
ChromaDB özellikleri:

Pinecone vektör veritabanı (Görsel kaynağı)
Pinecone, yüksek boyutlu verilerle ilişkili benzersiz zorlukların üstesinden gelmek için özel olarak tasarlanmış, yönetilen bir vektör veritabanı platformudur. Son teknoloji indeksleme ve arama yetenekleriyle donatılan Pinecone, veri mühendisleri ve veri bilimcilerinin, yüksek boyutlu verileri etkili biçimde işleyen ve analiz eden büyük ölçekli makine öğrenimi uygulamaları kurup devreye almalarını sağlar.
Pinecone’un başlıca özellikleri şunlardır:
Dikkat çekici biçimde, Pinecone, Fortune 2023 50 AI Innovator açılış listesine alınan tek vektör veritabanıydı.
Pinecone hakkında daha fazla bilgi için Pinecone ile Vektör Veritabanlarında Ustalaşma eğitimine göz atın.
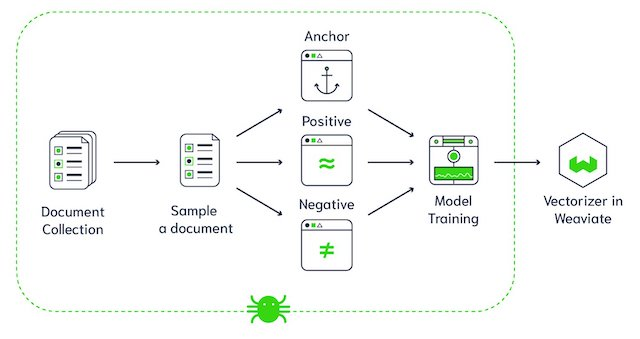
Weaviate vektör veritabanı mimarisi (Görsel kaynağı)
Weaviate, açık kaynaklı bir vektör veritabanıdır. Favori ML modellerinizden veri nesnelerini ve vektör gömmelerini saklamanıza ve milyarlarca veri nesnesine sorunsuzca ölçeklenmenize olanak tanır. Weaviate’in bazı temel özellikleri şunlardır:

Faiss, Facebook tarafından oluşturulan vektör araması için açık kaynaklı bir kütüphanedir (Görsel kaynağı)
Faiss, benzerliklerin hızlı aranması ve yoğun vektörlerin kümeleme işlemleri için açık kaynaklı bir kütüphanedir. RAM kapasitesini bile aşabilecek büyüklükteki vektör kümelerinde arama yapabilen algoritmalar barındırır. Ayrıca, değerlendirme ve parametre ayarı için yardımcı kodlar sunar.
Temel olarak C++ ile yazılmış olsa da Python/NumPy ile tam entegrasyon sağlar. Temel algoritmalarının bir kısmı GPU üzerinde çalıştırılabilir. Faiss’in ana geliştirmesi Meta’daki Fundamental AI Research grubu tarafından yürütülmektedir.
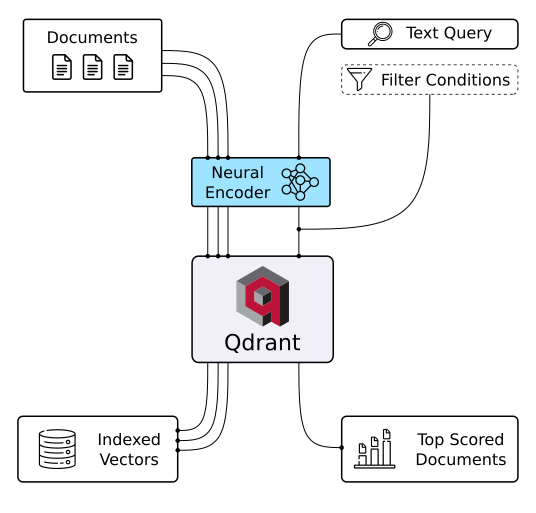
Qdrant vektör veritabanı (Görsel kaynağı)
Qdrant, bir vektör veritabanı ve vektör benzerlik aramaları için bir araçtır. Bir API hizmeti olarak çalışır ve en yakın yüksek boyutlu vektörleri aramayı mümkün kılar. Qdrant kullanarak gömmeleri veya sinir ağı kodlayıcılarını; eşleştirme, arama, öneri oluşturma ve çok daha fazlası gibi görevler için kapsamlı uygulamalara dönüştürebilirsiniz. Qdrant’ın bazı temel özellikleri şunlardır:
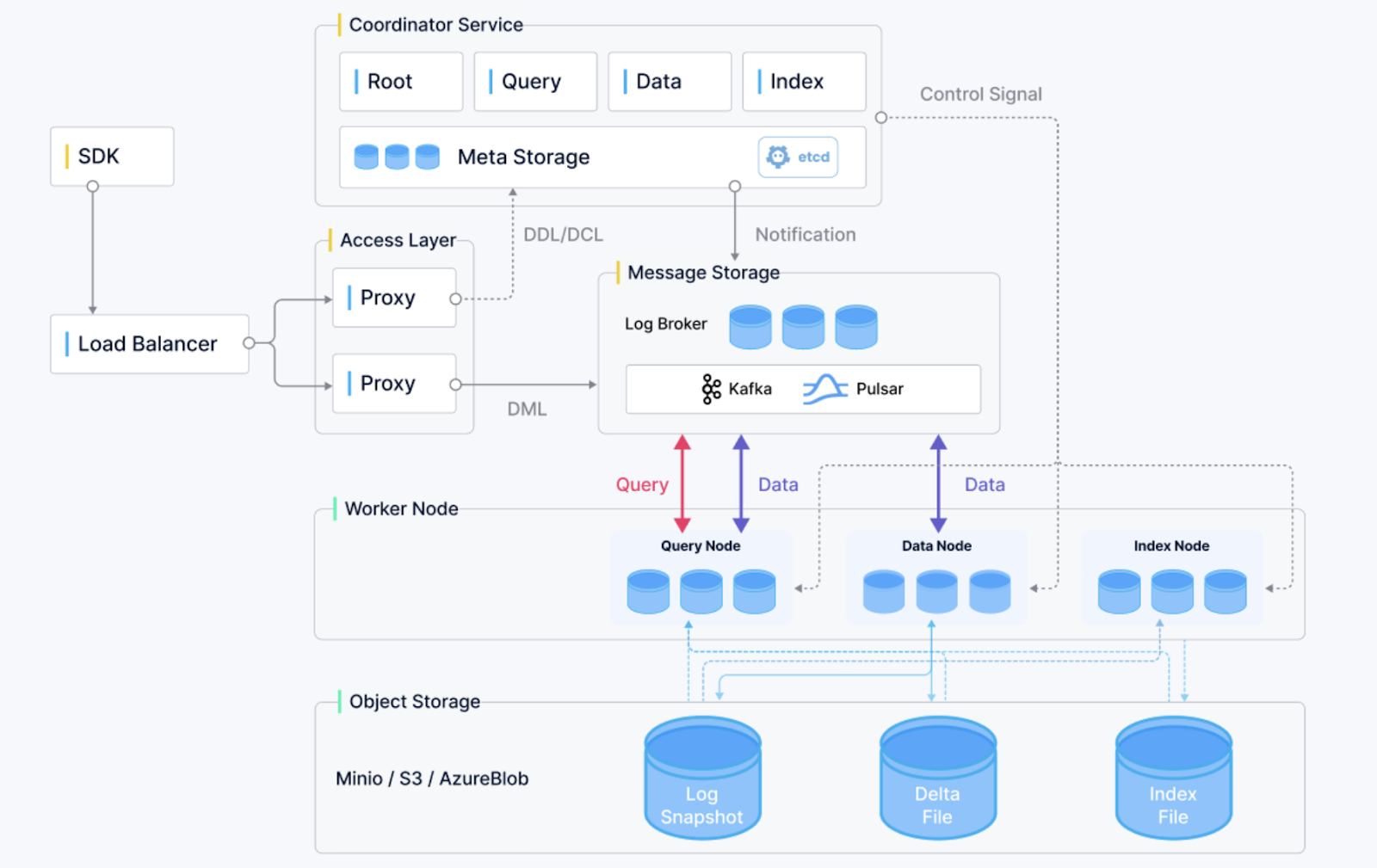
Milvus mimarisine genel bakış. (Görsel kaynağı)
Milvus, ölçeklenebilirliği, güvenilirliği ve performansı ile hızla ilgi kazanan açık kaynaklı bir vektör veritabanıdır. Benzerlik araması ve AI odaklı uygulamalar için tasarlanmıştır; derin sinir ağları tarafından üretilen muazzam gömme vektörlerini depolamayı ve sorgulamayı destekler. Milvus şu özellikleri sunar:
Milvus, öneri sistemleri, video analizi ve kişiselleştirilmiş arama deneyimleri için idealdir.
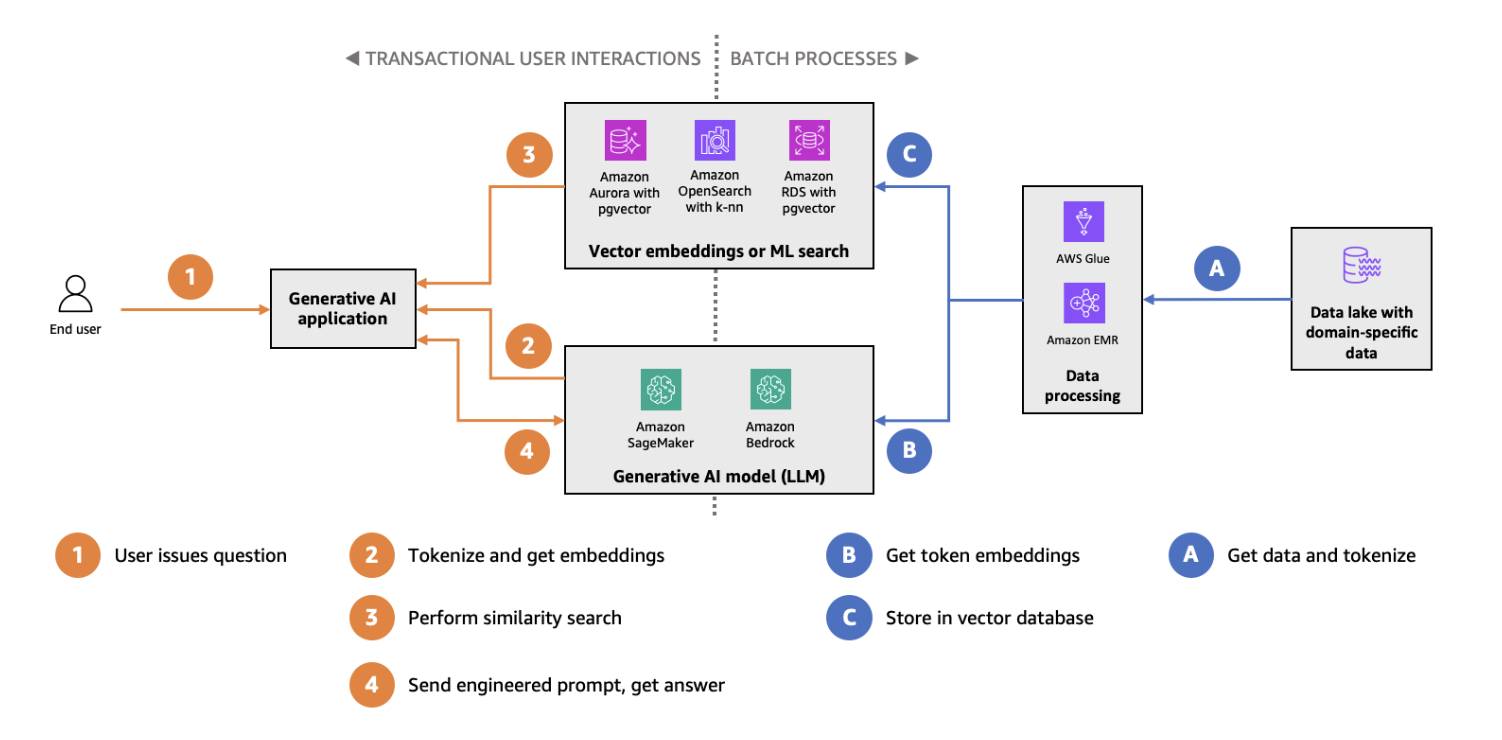
Amazon Aurora mimarisi diyagramında pgvector ile HNSW indeksleme ve arama. (Görsel kaynağı)
pgvector, yaygın olarak kullanılan ilişkisel veritabanı PostgreSQL’e vektör veri türleri ve benzerlik arama yetenekleri kazandıran bir eklentidir. Vektör aramayı PostgreSQL’e entegre ederek, geleneksel veritabanlarını zaten kullanan ancak vektör arama yetenekleri eklemek isteyen ekipler için sorunsuz bir çözüm sunar. pgvector’ün temel özellikleri şunlardır:
pgvector, özellikle daha küçük ölçekli vektör arama kullanım durumları veya hem ilişkisel hem vektör tabanlı iş yükleri için tek bir veritabanı sisteminin tercih edildiği ortamlar için uygundur. Başlamak için pgvector üzerine ayrıntılı eğitimimize göz atın.
Aşağıda, önce ele alınan en iyi vektör veritabanlarının özelliklerini öne çıkaran bir karşılaştırma tablosu yer almaktadır:
| Özellik | Chroma | Pinecone | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Açık kaynak | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Birincil Kullanım Durumu | LLM Uygulama Geliştirme | ML için Yönetilen Vektör Veritabanı | Ölçeklenebilir Vektör Depolama ve Arama | Yüksek Hızlı Benzerlik Araması ve Kümeleme | Vektör Benzerlik Araması | Yüksek Performanslı AI Arama | PostgreSQL’e Vektör Arama Ekleme |
| Entegrasyon | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, GPU Çalıştırma | OpenAPI v3, Çeşitli Dil İstemcileri | TensorFlow, PyTorch, HuggingFace | PostgreSQL ekosistemine yerleşik |
| Ölçeklenebilirlik | Python defterlerinden kümelere ölçeklenir | Yüksek ölçekte ölçeklenebilir | Milyarlarca nesneye sorunsuz ölçeklenme | RAM’den büyük kümeleri işleyebilir | Yatay ölçeklemeli bulut-yerel | Milyarlarca vektöre ölçeklenir | PostgreSQL kurulumuna bağlıdır |
| Arama Hızı | Hızlı benzerlik aramaları | Düşük gecikmeli arama | Milyonlarca nesne için milisaniyeler | Hızlı, GPU desteği var | Hızlı arama için özel HNSW algoritması | Düşük gecikmeli arama için optimize | Yaklaşık En Yakın Komşu (ANN) |
| Veri Gizliliği | Veri izolasyonuyla çoklu kullanıcı desteği | Tamamen yönetilen hizmet | Güvenlik ve replikasyona vurgu | Öncelikle araştırma ve geliştirme için | Vektör yüklerinde gelişmiş filtreleme | Güvenli çoklu kiracı mimarisi | PostgreSQL’in güvenliğini devralır |
| Programlama Dili | Python, JavaScript | Python | Python, Java, Go, diğerleri | C++, Python | Rust | C++, Python, Go | PostgreSQL eklentisi (SQL tabanlı) |
Vektör veritabanları, yüksek boyutlu vektörleri depolamada uzmanlaşmıştır; hızlı ve doğru benzerlik aramalarını mümkün kılar. Özellikle doğal dil işleme ve bilgisayarlı görü alanlarındaki AI modelleri bu vektörleri üretip onlarla çalıştıkça, verimli depolama ve getirme sistemlerine duyulan ihtiyaç hayati hale gelmiştir. Vektör veritabanları tam da bu noktada devreye girer; bu AI odaklı uygulamalar için son derece optimize edilmiş bir ortam sağlar.
AI ile vektör veritabanları arasındaki bu ilişkinin çarpıcı bir örneği, GPT-3 gibi Büyük Dil Modellerinin (LLM) ortaya çıkışında görülebilir.
Bu modeller, muazzam miktarda veriyi işleyip onları yüksek boyutlu vektörlere dönüştürerek insan benzeri metinleri anlamak ve üretmek üzere tasarlanmıştır. GPT ve benzeri modellere dayalı uygulamalar, bu vektörleri verimli biçimde yönetmek ve sorgulamak için vektör veritabanlarına büyük ölçüde dayanır. Bu bağımlılığın nedeni, bu modellerin işlediği verinin hacmi ve karmaşıklığıdır. Parametre sayısındaki ciddi artış düşünüldüğünde, GPT-4 gibi modeller muazzam miktarda vektörleştirilmiş veri üretir; bu da geleneksel veritabanlarının verimli şekilde işlemesi için zorlayıcı olabilir. Bu durum, böylesi yüksek boyutlu verileri işleyebilen özel vektör veritabanlarının önemini vurgular.
Sürekli evrilen yapay zeka ve makine öğrenimi dünyası, günümüzün veri merkezli ortamında vektör veritabanlarının vazgeçilmezliğinin altını çiziyor. Çok boyutlu veri vektörlerini depolama, arama ve analiz etme konusundaki benzersiz yetenekleriyle bu veritabanları; öneri sistemlerinden genomik analize kadar AI tabanlı uygulamaları güçlendirmede kilit rol oynuyor.
Son dönemde Chroma, Pinecone, Weaviate, Faiss ve Qdrant gibi etkileyici bir vektör veritabanı yelpazesi gördük; her biri farklı yetenekler ve yenilikler sunuyor. AI yükselişini sürdürdükçe, vektör veritabanlarının veri getirme, işleme ve analizinin geleceğini şekillendirmedeki rolü de kaçınılmaz olarak büyüyecek ve çeşitli sektörlerde daha sofistike, verimli ve kişiselleştirilmiş çözümler vaat edecek.
Vektör veritabanlarında ustalaşmayı Pinecone eğitimimizle öğrenin veya Python ile Derin Öğrenme beceri yoluna kaydolup AI becerilerinizi geliştirin ve en son gelişmelerden haberdar kalın.
Bu kurslarla AI hakkında daha fazlasını öğrenin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
