
Curso
Entendendo a inteligência artificial
2 h
401.5K
Um banco de dados vetorial é um tipo específico de banco de dados que guarda informações na forma de vetores multidimensionais que representam certas características ou qualidades.
O número de dimensões em cada vetor pode variar bastante, de apenas algumas a vários milhares, dependendo da complexidade e dos detalhes dos dados. Esses dados, que podem incluir texto, imagens, áudio e vídeo, são transformados em vetores usando vários processos, como modelos de machine learning, incorporação de palavras ou técnicas de extração de recursos.
A principal vantagem de um banco de dados vetorial é a capacidade de localizar e recuperar dados de forma rápida e precisa, de acordo com a proximidade ou semelhança vetorial deles. Isso permite pesquisas baseadas na relevância semântica ou contextual, em vez de depender só de correspondências exatas ou critérios definidos, como acontece com os bancos de dados convencionais.
Por exemplo, com um banco de dados vetorial, você pode:
Os bancos de dados tradicionais armazenam dados simples, como palavras e números, em formato de tabela. Os bancos de dados vetoriais, no entanto, trabalham com dados complexos chamados vetores e usam métodos exclusivos para pesquisa.
Enquanto os bancos de dados comuns procuram correspondências exatas de dados, os bancos de dados vetoriais procuram a correspondência mais próxima usando medidas específicas de similaridade.
Os bancos de dados vetoriais usam técnicas especiais de pesquisa conhecidas como pesquisa Approximate Nearest Neighbor (ANN), que incluem métodos como hash e pesquisas baseadas em gráficos.
Para entender de verdade como funcionam os bancos de dados vetoriais e como eles são diferentes dos bancos de dados relacionais tradicionais, como o SQL, primeiro precisamos entender o conceito de embeddings.
Dados não estruturados, como texto, imagens e áudio, não têm um formato pré-definido, o que é um desafio para os bancos de dados tradicionais. Para usar esses dados em aplicações de inteligência artificial e machine learning, eles são transformados em representações numéricas usando embeddings.
Incorporar é como dar a cada item, seja uma palavra, imagem ou outra coisa, um código único que capta seu significado ou essência. Esse código ajuda os computadores a entender e comparar esses itens de uma maneira mais eficiente e significativa. Pense nisso como transformar um livro complicado em um resumo curto que ainda capta os pontos principais.
Esse processo de incorporação geralmente é feito usando um tipo especial de rede neural projetada para essa tarefa. Por exemplo, as incorporações de palavras transformam palavras em vetores de tal forma que palavras com significados parecidos ficam mais próximas no espaço vetorial.
Essa transformação permite que os algoritmos entendam as relações e semelhanças entre os itens.
Basicamente, os embeddings são tipo uma ponte, transformando dados não numéricos em um formato que os modelos de machine learning conseguem usar, permitindo que eles identifiquem padrões e relações nos dados de forma mais eficaz.
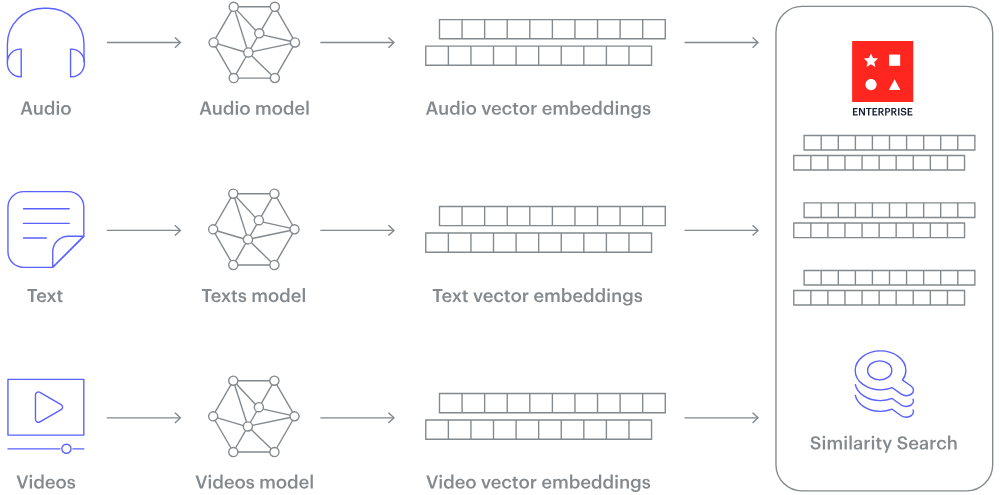
Como funciona um banco de dados vetorial? (Fonte da imagem)
Os bancos de dados vetoriais, com suas capacidades únicas, estão conquistando nichos em vários setores devido à sua eficiência na implementação da “busca por similaridade”. Aqui está uma análise mais aprofundada de suas diversas aplicações:
No movimentado setor de varejo, os bancos de dados vetoriais estão mudando a forma como os consumidores fazem compras. Eles permitem a criação de sistemas avançados de recomendação, criando experiências de compra personalizadas. Por exemplo, um comprador online pode receber sugestões de produtos não só com base em compras anteriores, mas também analisando as semelhanças nos atributos dos produtos, no comportamento do usuário e nas preferências.
O setor financeiro está cheio de padrões e tendências complicados. Os bancos de dados vetoriais são ótimos pra analisar esses dados densos, ajudando os analistas financeiros a detectar padrões importantes pra estratégias de investimento. Ao perceber semelhanças ou diferenças sutis, eles podem prever os movimentos do mercado e criar planos de investimento mais bem informados.
No mundo da saúde, a personalização é super importante. Ao analisar sequências genômicas, os bancos de dados de vetores permitem tratamentos médicos mais personalizados, garantindo que as soluções médicas se alinhem mais estreitamente com a composição genética individual.
O mundo digital está vendo um aumento nos chatbots e assistentes virtuais. Essas entidades baseadas em IA dependem muito da compreensão da linguagem humana. Ao transformar um monte de dados de texto em vetores, esses sistemas conseguem entender melhor e responder com mais precisão às perguntas das pessoas. Por exemplo, empresas como a Talkmap usam a compreensão de linguagem natural em tempo real, facilitando a interação entre o cliente e o agente.
De exames médicos a imagens de vigilância, a capacidade de comparar e entender imagens com precisão é super importante. Os bancos de dados vetoriais simplificam isso, focando nas características essenciais das imagens, filtrando ruídos e distorções. Por exemplo, na gestão do trânsito, as imagens das transmissões de vídeo podem ser analisadas rapidamente para otimizar o fluxo do trânsito e aumentar a segurança pública.
Identificar valores atípicos é tão importante quanto reconhecer semelhanças. Principalmente em áreas como finanças e segurança, perceber algo estranho pode ajudar a evitar fraudes ou impedir uma possível falha de segurança. Os bancos de dados vetoriais oferecem recursos aprimorados nesse campo, tornando o processo de detecção mais rápido e preciso.
Os bancos de dados vetoriais surgiram como ferramentas poderosas para navegar pelo vasto terreno dos dados não estruturados, como imagens, vídeos e textos, sem depender muito de rótulos ou tags criados por humanos. Suas capacidades, quando integradas a modelos avançados de machine learning, têm o potencial de revolucionar vários setores, do comércio eletrônico aos produtos farmacêuticos. Aqui estão algumas das características que fazem os bancos de dados vetoriais serem tão importantes:
Um banco de dados vetorial robusto garante que, à medida que os dados crescem — chegando a milhões ou até bilhões de elementos —, ele possa ser facilmente escalonado em vários nós. Os melhores bancos de dados vetoriais são flexíveis, permitindo que os usuários ajustem o sistema com base nas variações na taxa de inserção, taxa de consulta e hardware subjacente.
Acomodar vários usuários é uma expectativa padrão para bancos de dados. Mas, só criar um novo banco de dados vetorial para cada usuário não é eficiente. Os bancos de dados vetoriais priorizam o isolamento dos dados, garantindo que quaisquer alterações feitas em uma coleção de dados permaneçam invisíveis para o resto, a menos que sejam compartilhadas intencionalmente pelo proprietário. Isso não só dá suporte à multilocação, mas também garante a privacidade e a segurança dos dados.
Um banco de dados de verdade e que funciona bem tem um conjunto completo de APIs e SDKs. Isso garante que o sistema possa interagir com diversos aplicativos e ser gerenciado de forma eficaz. Os principais bancos de dados vetoriais, como o Pinecone, oferecem SDKs em várias linguagens de programação, como Python, Node, Go e Java, garantindo flexibilidade no desenvolvimento e gerenciamento.
Reduzindo a curva de aprendizado íngreme associada às novas tecnologias, as interfaces fáceis de usar em bancos de dados vetoriais têm um papel super importante. Essas interfaces oferecem uma visão geral, navegação fácil e acesso a recursos que, de outra forma, poderiam ficar escondidos.
A lista não está em nenhuma ordem específica - cada um deles tem muitas das qualidades que falamos na seção acima.
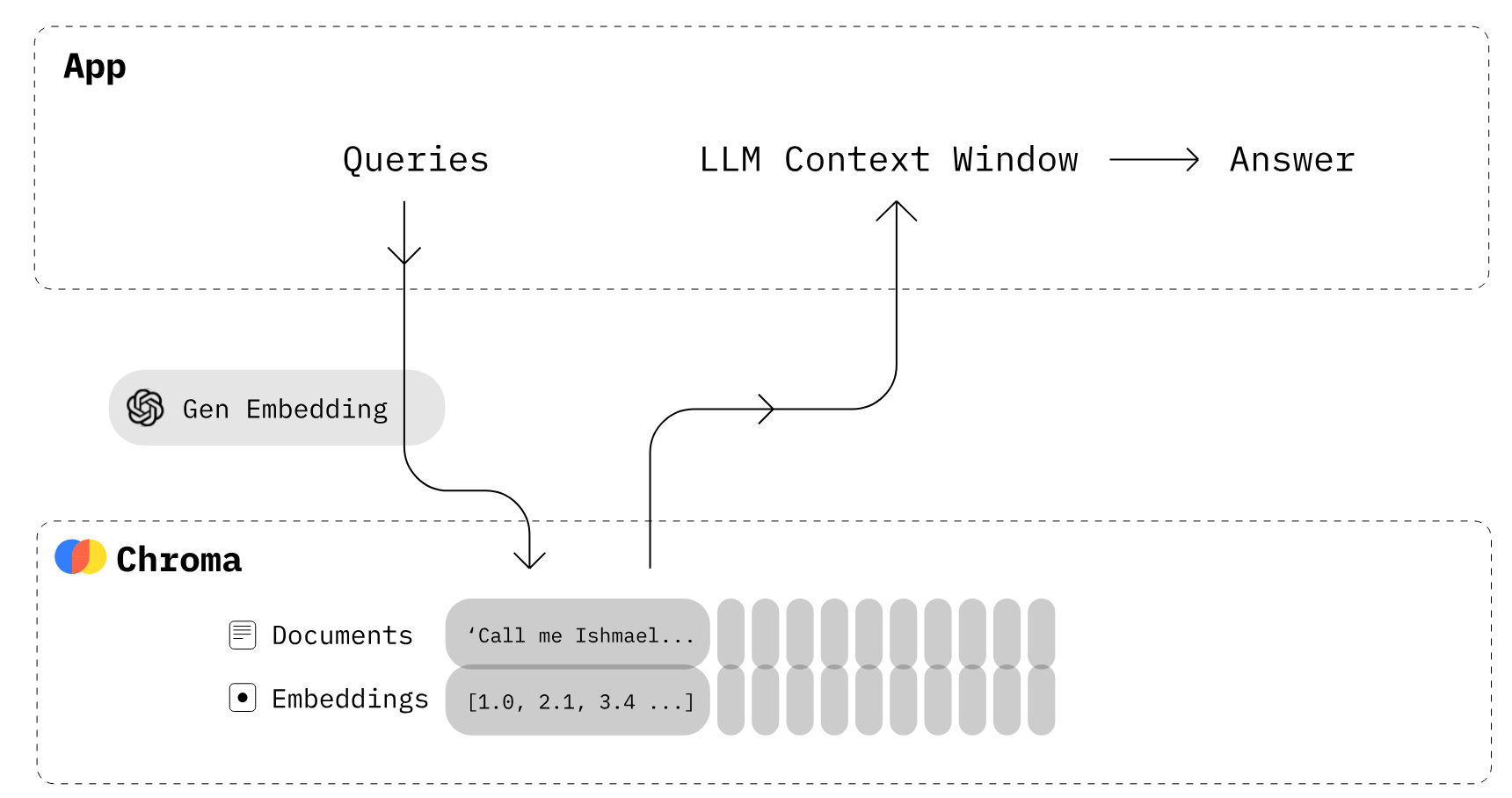
Criando aplicativos LLM usando o ChromaDB (Fonte da imagem)
Chroma é um banco de dados de incorporação de código aberto. O Chroma facilita a criação de aplicativos LLM, tornando conhecimentos, fatos e habilidades conectáveis para LLMs. Como a gente vê no nosso tutorial do Chroma DB, dá pra gerenciar documentos de texto, converter texto em embeddings e fazer buscas por similaridade com facilidade.
Recursos do ChromaDB:

Banco de dados vetorial Pinecone (Fonte da imagem)
O Pinecone é uma plataforma de banco de dados vetorial gerenciada que foi criada especialmente para lidar com os desafios únicos associados a dados de alta dimensão. Com recursos de indexação e pesquisa super avançados, o Pinecone ajuda engenheiros e cientistas de dados a criar e implementar aplicativos de machine learning em grande escala que processam e analisam dados de alta dimensão de um jeito eficiente.
As principais características do Pinecone são:
Vale dizer que a Pinecone foi a única base de dados vetorial que entrou na primeira lista dos 50 inovadores em IA da Fortune 2023.
Pra saber mais sobre o Pinecone, dá uma olhada no tutorial Dominando bancos de dados vetoriais com o Pinecone.
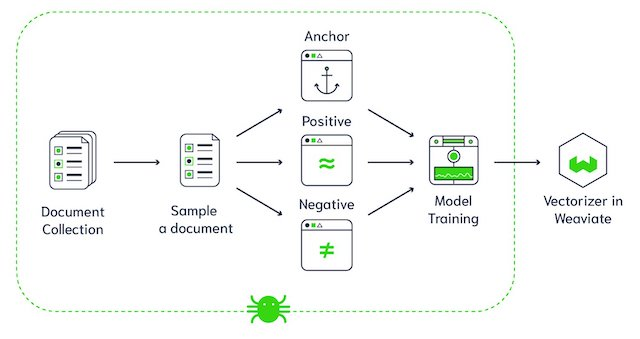
Arquitetura do banco de dados vetorial Weaviate (Fonte da imagem)
O Weaviate é um banco de dados vetorial de código aberto. Ele permite que você armazene objetos de dados e incorporações vetoriais dos seus modelos de ML favoritos e escale perfeitamente para bilhões de objetos de dados. Algumas das principais características do Weaviate são:

Faiss é uma biblioteca de código aberto para pesquisa vetorial criada pelo Facebook (Fonte da imagem)
Faiss é uma biblioteca de código aberto para a busca rápida de semelhanças e o agrupamento de vetores densos. Ele tem algoritmos que conseguem fazer buscas em conjuntos de vetores de tamanhos diferentes, mesmo aqueles que podem passar da capacidade da RAM. Além disso, o Faiss oferece um código auxiliar para avaliar e ajustar os parâmetros.
Embora seja codificado principalmente em C++, ele oferece suporte total à integração com Python/NumPy. Alguns dos seus principais algoritmos também estão disponíveis para execução em GPU. O desenvolvimento principal do Faiss é feito pelo grupo de Pesquisa Fundamental em IA da Meta.
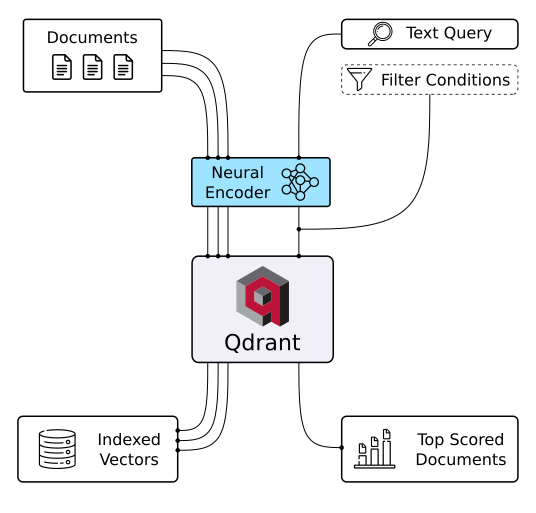
Banco de dados vetorial Qdrant (Fonte da imagem)
O Qdrant é um banco de dados vetorial e uma ferramenta para fazer buscas de similaridade vetorial. Funciona como um serviço API, permitindo pesquisas pelos vetores de alta dimensão mais próximos. Com o Qdrant, você pode transformar embeddings ou codificadores de redes neurais em aplicativos completos para tarefas como correspondência, pesquisa, recomendações e muito mais. Aqui estão algumas das principais funcionalidades do Qdrant:
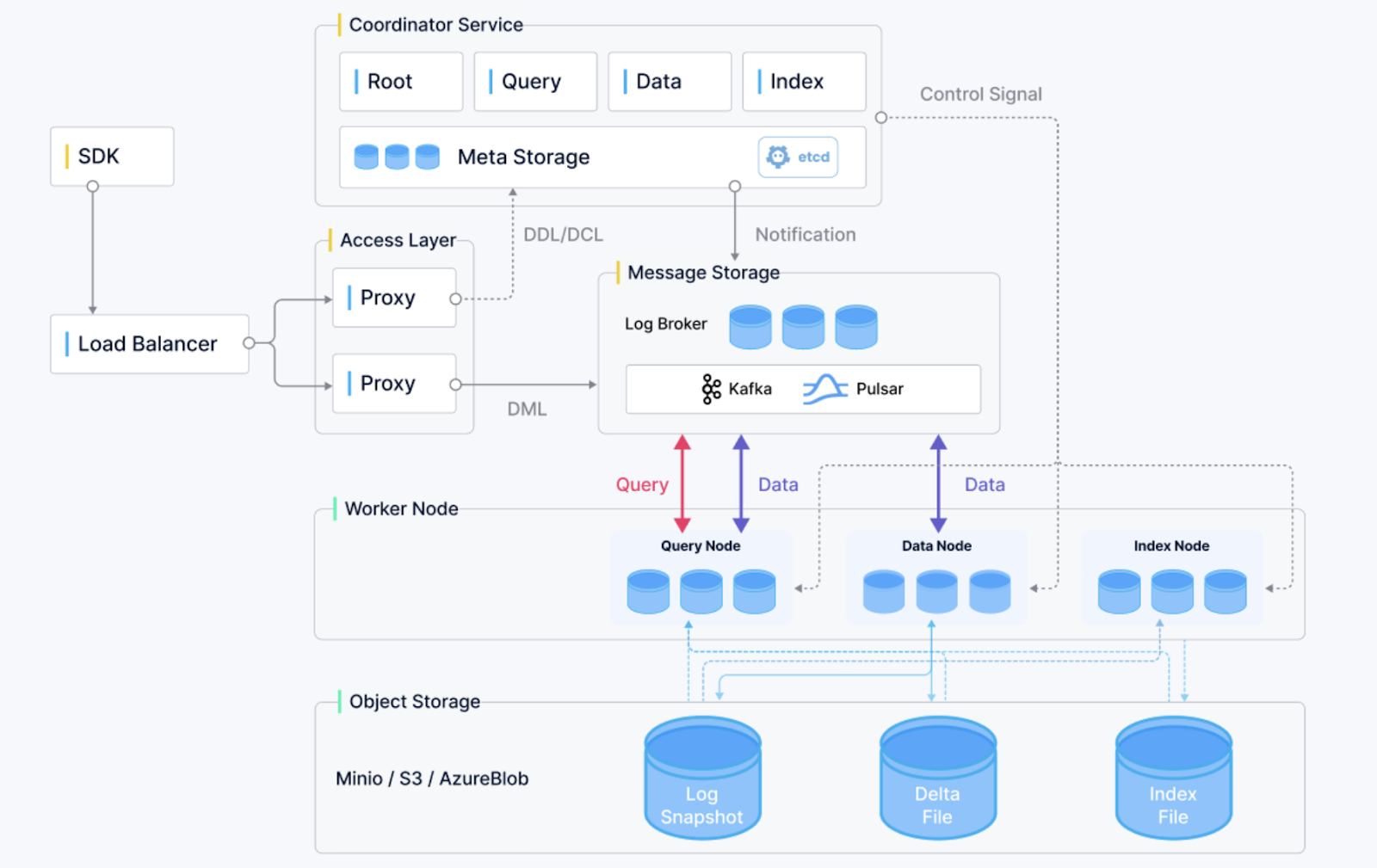
Visão geral da arquitetura do Milvus. (Fonte da imagem)
O Milvus é um banco de dados vetorial de código aberto que ficou famoso rapidinho por ser escalável, confiável e eficiente. Feito pra busca por semelhanças e aplicativos com inteligência artificial, ele dá suporte ao armazenamento e consulta de vetores de incorporação enormes gerados por redes neurais profundas. O Milvus tem as seguintes funcionalidades:
O Milvus é perfeito pra usar em sistemas de recomendação, análise de vídeo e experiências de pesquisa personalizadas.
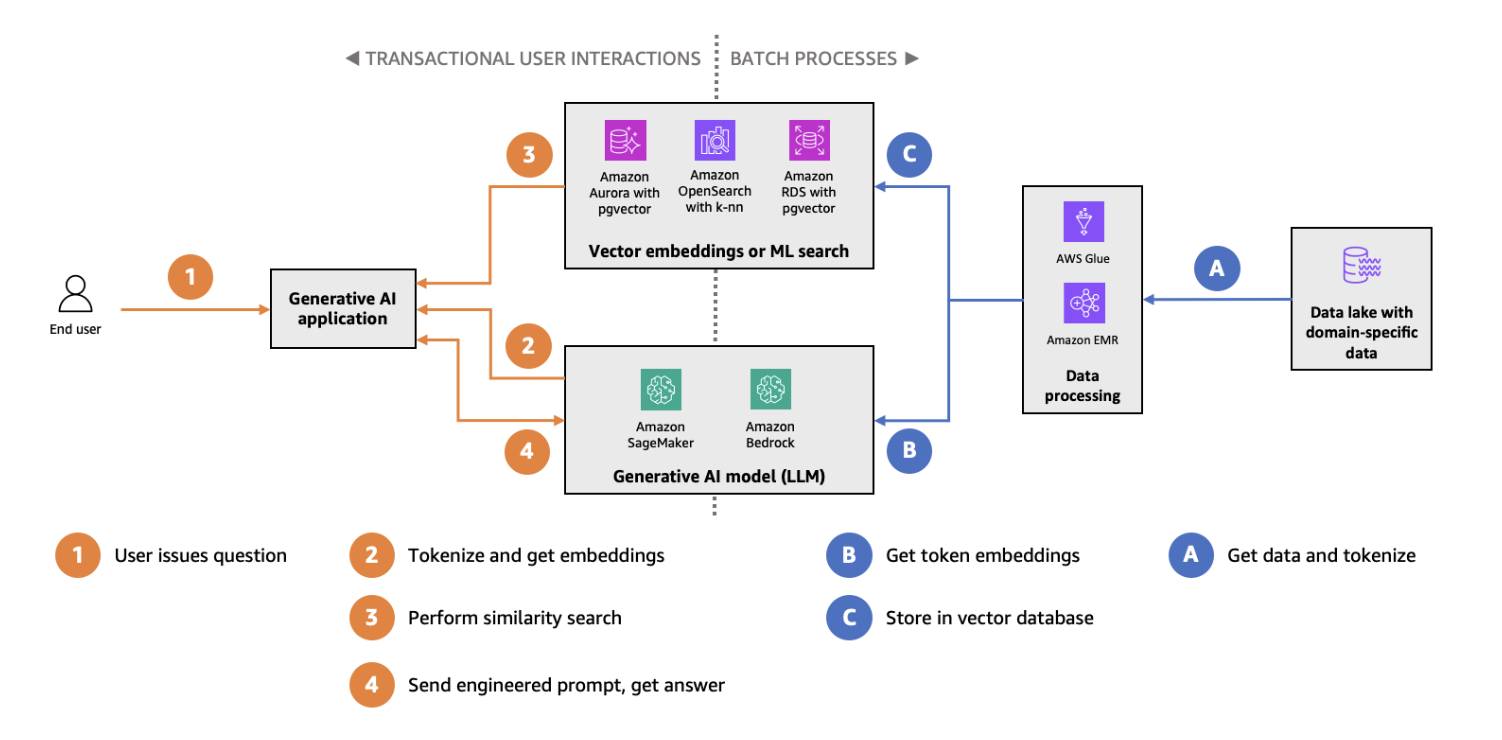
Indexação e pesquisa HNSW com pgvector no diagrama da arquitetura Amazon Aurora. (Fonte da imagem)
O pgvector é uma extensão para o PostgreSQL que traz tipos de dados vetoriais e recursos de pesquisa por similaridade para o banco de dados relacional que todo mundo usa. Ao integrar a pesquisa vetorial ao PostgreSQL, o pgvector oferece uma solução perfeita para equipes que já usam bancos de dados tradicionais, mas querem adicionar recursos de pesquisa vetorial. As principais características do pgvector são:
O pgvector é especialmente bom para casos de uso de pesquisa vetorial em menor escala ou ambientes onde um único sistema de banco de dados é preferível tanto para cargas de trabalho relacionais quanto vetoriais. Para começar, dá uma olhadano nosso tutorial detalhado sobre pgvector.
Abaixo está uma tabela comparativa destacando os recursos dos principais bancos de dados vetoriais discutidos anteriormente:
| Recurso | Chroma | Pinhão | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Código aberto | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Caso de uso principal | Desenvolvimento de aplicativos LLM | Banco de dados vetorial gerenciado para ML | Armazenamento e pesquisa de vetores escaláveis | Pesquisa de similaridade e agrupamento em alta velocidade | Pesquisa por similaridade vetorial | Pesquisa com IA de alto desempenho | Adicionando a Pesquisa Vetorial ao PostgreSQL |
| Integração | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, execução em GPU | OpenAPI v3, Clientes em vários idiomas | TensorFlow, PyTorch, HuggingFace | Integrado ao ecossistema PostgreSQL |
| Escalabilidade | Escalabilidade desde notebooks Python até clusters | Altamente escalável | Escalabilidade perfeita para bilhões de objetos | Capaz de lidar com conjuntos maiores que a RAM | Nativo da nuvem com escalabilidade horizontal | Escalável para bilhões de vetores | Depende da configuração do PostgreSQL |
| Velocidade de pesquisa | Pesquisas rápidas por semelhança | Pesquisa de baixa latência | Milissegundos para milhões de objetos | Rápido, suporta GPU | Algoritmo HNSW personalizado para pesquisa rápida | Otimizado para pesquisa de baixa latência | Vizinho mais próximo aproximado (ANN) |
| Privacidade dos dados | Suporta múltiplos usuários com isolamento de dados | Serviço totalmente gerenciado | Dá ênfase à segurança e à replicação | Principalmente para pesquisa e desenvolvimento | Filtragem avançada em cargas vetoriais | Arquitetura segura para vários usuários | Herdou a segurança do PostgreSQL |
| Linguagem de programação | Python, JavaScript | Python | Python, Java, Go, outros | C++, Python | Ferrugem | C++, Python, Go | Extensão PostgreSQL (baseada em SQL) |
Os bancos de dados vetoriais são especializados em guardar vetores de alta dimensão, o que permite fazer buscas rápidas e precisas por semelhanças. Como os modelos de IA, especialmente aqueles no campo do processamento de linguagem natural e visão computacional, geram e trabalham com esses vetores, a necessidade de sistemas eficientes de armazenamento e recuperação se tornou superimportante. É aí que entram os bancos de dados vetoriais, oferecendo um ambiente super otimizado para esses aplicativos movidos a IA.
Um excelente exemplo dessa relação entre IA e bancos de dados vetoriais é observado no surgimento de grandes modelos de linguagem (LLMs), como o GPT-3.
Esses modelos são feitos pra entender e criar textos parecidos com os humanos, processando um monte de dados e transformando-os em vetores de alta dimensão. Aplicativos como o, que usam GPT e modelos parecidos, dependem muito de bancos de dados vetoriais pra gerenciar e consultar esses vetores de forma eficiente. A razão para essa dependência está no grande volume e na complexidade dos dados que esses modelos lidam. Com o aumento significativo dos parâmetros, modelos como o GPT-4 geram uma quantidade enorme de dados vetorizados, o que pode ser complicado para os bancos de dados convencionais processarem de forma eficiente. Isso mostra como é importante ter bancos de dados vetoriais especializados que possam lidar com esses dados de alta dimensão.
O cenário em constante evolução da inteligência artificial e do machine learning mostra como os bancos de dados vetoriais são essenciais no mundo atual, que gira em torno dos dados. Esses bancos de dados, com sua capacidade única de armazenar, pesquisar e analisar vetores de dados multidimensionais, estão se mostrando fundamentais para impulsionar aplicativos baseados em IA, desde sistemas de recomendação até análises genômicas.
Recentemente, vimos uma variedade impressionante de bancos de dados vetoriais, como Chroma, Pinecone, Weaviate, Faiss e Qdrant, cada um oferecendo recursos e inovações diferentes. À medida que a IA continua a crescer, o papel dos bancos de dados vetoriais na definição do futuro da recuperação, processamento e análise de dados vai, sem dúvida, aumentar, prometendo soluções mais sofisticadas, eficientes e personalizadas em vários setores.
Aprenda a dominar bancos de dados vetoriais com nosso tutorial Pinecone ou inscreva-se em nosso programa Deep Learning em Python para melhorar suas habilidades em IA e ficar por dentro das últimas novidades.
Aprenda mais sobre IA com esses cursos!
Curso
Curso
Curso
blog
Javier Canales Luna
9 min
blog
Abid Ali Awan
9 min
blog
Kurtis Pykes
11 min
blog
Yuliya Melnik
15 min
blog
Javier Canales Luna
13 min
blog
Austin Chia


