
Cursus
Artificial Intelligence begrijpen
2 Hr
409.4K
Een vectordatabase is een specifiek type database die informatie opslaat in de vorm van multidimensionale vectors die bepaalde kenmerken of eigenschappen vertegenwoordigen.
Het aantal dimensies in elke vector kan sterk variëren, van slechts een paar tot enkele duizenden, afhankelijk van de complexiteit en detailgraad van de data. Deze data, zoals tekst, afbeeldingen, audio en video, wordt omgezet in vectors via processen zoals machinelearningmodellen, woord-embeddings of feature-extractietechnieken.
Het belangrijkste voordeel van een vectordatabase is het vermogen om snel en nauwkeurig data te lokaliseren en op te halen op basis van hun vectornabijheid of -gelijkenis. Hierdoor kun je zoeken op semantische of contextuele relevantie in plaats van uitsluitend te vertrouwen op exacte overeenkomsten of vaste criteria zoals bij conventionele databases.
Met een vectordatabase kun je bijvoorbeeld:
Traditionele databases slaan eenvoudige data zoals woorden en getallen op in tabelvorm. Vectordatabases werken echter met complexe data, genaamd vectors, en gebruiken unieke zoekmethoden.
Waar reguliere databases zoeken naar exacte datamatches, zoeken vectordatabases naar de dichtstbijzijnde match met specifieke gelijkenismaatstaven.
Vectordatabases gebruiken speciale zoektechnieken die Approximate Nearest Neighbor (ANN) search worden genoemd, waaronder methoden zoals hashing en grafgebaseerde zoekopdrachten.
Om echt te begrijpen hoe vectordatabases werken en hoe ze verschillen van traditionele relationele databases zoals SQL, moeten we eerst het concept van embeddings begrijpen.
Ongestructureerde data, zoals tekst, afbeeldingen en audio, heeft geen vooraf gedefinieerd formaat en vormt een uitdaging voor traditionele databases. Om deze data te benutten in kunstmatige intelligentie en machinelearningtoepassingen, wordt ze omgezet in numerieke representaties met behulp van embeddings.
Een embedding is alsof je elk item, of het nu een woord, afbeelding of iets anders is, een unieke code geeft die de betekenis of essentie vastlegt. Deze code helpt computers deze items efficiënter en zinvoller te begrijpen en te vergelijken. Zie het als het samenvatten van een ingewikkeld boek tot een korte samenvatting die toch de kern bewaart.
Dit embeddingproces wordt meestal uitgevoerd met een speciaal type neuraal netwerk dat hiervoor is ontworpen. Zo zetten woord-embeddings woorden om in vectors op zo'n manier dat woorden met vergelijkbare betekenis dichter bij elkaar liggen in de vectorruimte.
Deze transformatie stelt algoritmen in staat relaties en overeenkomsten tussen items te begrijpen.
Kortom, embeddings fungeren als een brug: ze zetten niet-numerieke data om in een vorm waar machinelearningmodellen mee kunnen werken, zodat die patronen en relaties in de data effectiever kunnen herkennen.
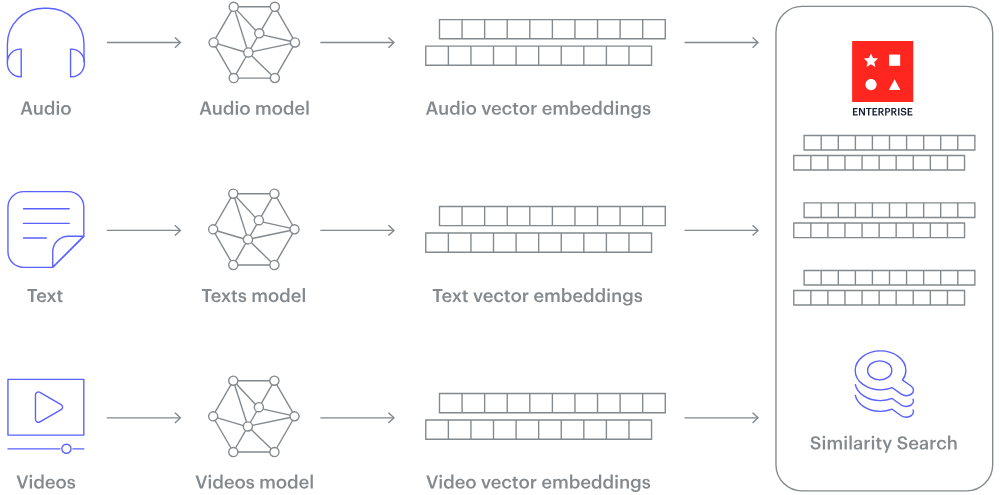
Hoe werkt een vectordatabase? (Beeldbron)
Vectordatabases, met hun unieke mogelijkheden, veroveren een plek in talloze sectoren dankzij hun efficiëntie bij het implementeren van "similarity search". Hier volgt een nadere blik op hun diverse toepassingen:
In de bruisende retailsector veranderen vectordatabases de manier waarop consumenten winkelen. Ze maken geavanceerde aanbevelingssystemen mogelijk die gepersonaliseerde winkelervaringen samenstellen. Zo kan een online shopper niet alleen suggesties krijgen op basis van eerdere aankopen, maar ook via analyse van overeenkomsten in productkenmerken, gebruikersgedrag en voorkeuren.
De financiële sector zit vol met complexe patronen en trends. Vectordatabases blinken uit in het analyseren van deze dichte data en helpen financieel analisten patronen te detecteren die cruciaal zijn voor beleggingsstrategieën. Door subtiele overeenkomsten of afwijkingen te herkennen, kunnen ze marktbewegingen voorspellen en beter onderbouwde plannen opstellen.
In de gezondheidszorg is personalisatie essentieel. Door genomische sequenties te analyseren, maken vectordatabases meer op maat gemaakte behandelingen mogelijk, zodat medische oplossingen beter aansluiten op iemands genetische profiel.
De digitale wereld ziet een toename van chatbots en virtuele assistenten. Deze AI-systemen zijn sterk afhankelijk van het begrijpen van mensentaal. Door grote hoeveelheden tekstdata om te zetten in vectors kunnen deze systemen menselijkerwijs vragen begrijpen en beantwoorden. Bedrijven zoals Talkmap gebruiken bijvoorbeeld realtime natural language understanding, wat soepelere interacties tussen klant en agent mogelijk maakt.
Van medische scans tot bewakingsbeelden: de mogelijkheid om afbeeldingen accuraat te vergelijken en te begrijpen is cruciaal. Vectordatabases stroomlijnen dit door te focussen op de essentiële kenmerken van afbeeldingen en ruis en vervorming te filteren. In verkeersmanagement kunnen beelden uit videostreams bijvoorbeeld snel worden geanalyseerd om de doorstroming te optimaliseren en de openbare veiligheid te vergroten.
Het opsporen van uitschieters is net zo belangrijk als het herkennen van overeenkomsten. Vooral in sectoren als financiën en beveiliging kan het detecteren van anomalieën fraude voorkomen of een potentiële inbraak voor zijn. Vectordatabases bieden verbeterde mogelijkheden op dit gebied, waardoor detectie sneller en nauwkeuriger verloopt.
Vectordatabases zijn uitgegroeid tot krachtige tools om te navigeren door het enorme terrein van ongestructureerde data, zoals afbeeldingen, video’s en teksten, zonder zwaar te leunen op door mensen gegenereerde labels of tags. Hun mogelijkheden, in combinatie met geavanceerde machinelearningmodellen, kunnen talloze sectoren revolutioneren, van e-commerce tot farmacie. Dit zijn enkele opvallende kenmerken die vectordatabases tot een gamechanger maken:
Een robuuste vectordatabase zorgt ervoor dat, naarmate data groeit — tot miljoenen of zelfs miljarden elementen — deze moeiteloos over meerdere nodes kan schalen. De beste vectordatabases bieden flexibiliteit, zodat je het systeem kunt afstemmen op variaties in invoersnelheid, queryrate en onderliggende hardware.
Het ondersteunen van meerdere gebruikers is een standaardverwachting voor databases. Maar voor elke gebruiker een nieuwe vectordatabase aanmaken is niet efficiënt. Vectordatabases geven prioriteit aan data-isolatie, zodat wijzigingen in één datacollectie onzichtbaar blijven voor de rest, tenzij de eigenaar ze bewust deelt. Dit ondersteunt niet alleen multi-tenantgebruik, maar waarborgt ook privacy en beveiliging.
Een echte, effectieve database biedt een volledige set API’s en SDK’s. Zo kan het systeem met diverse applicaties communiceren en effectief worden beheerd. Leidinggevende vectordatabases, zoals Pinecone, bieden SDK’s in verschillende programmeertalen zoals Python, Node, Go en Java, wat flexibiliteit geeft in ontwikkeling en beheer.
Om de steile leercurve van nieuwe technologie te verlagen, zijn gebruiksvriendelijke interfaces in vectordatabases cruciaal. Ze bieden een visueel overzicht, eenvoudige navigatie en toegang tot functies die anders verborgen zouden blijven.
De lijst is niet geordend — elk van deze opties laat veel van de kwaliteiten zien die hierboven zijn beschreven.
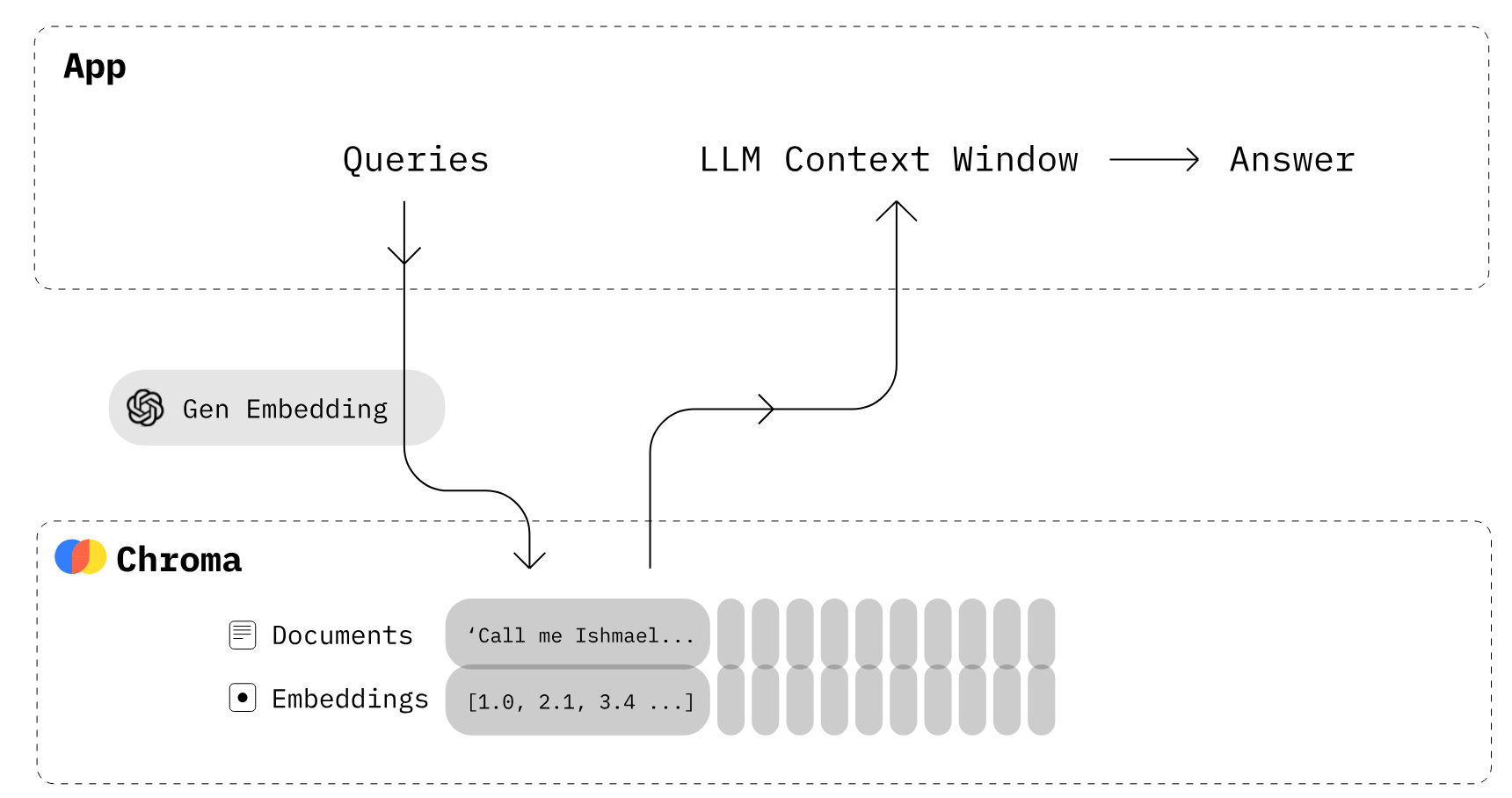
LLM-apps bouwen met ChromaDB (Beeldbron)
Chroma is een open-source embeddingdatabase. Chroma maakt het makkelijk om LLM-apps te bouwen door kennis, feiten en vaardigheden plug-and-play te maken voor LLM’s. Zoals we laten zien in onze Chroma DB-tutorial, kun je eenvoudig tekstdocumenten beheren, tekst omzetten naar embeddings en similarity searches uitvoeren.
ChromaDB-functies:

Pinecone-vectordatabase (Beeldbron)
Pinecone is een beheerd vectordatabaseplatform dat is gebouwd om de unieke uitdagingen van hoog-dimensionale data aan te pakken. Met geavanceerde indexerings- en zoekmogelijkheden stelt Pinecone data engineers en data scientists in staat grootschalige machinelearningtoepassingen te bouwen en te implementeren die hoog-dimensionale data effectief verwerken en analyseren.
Belangrijke kenmerken van Pinecone:
Opvallend is dat Pinecone de enige vectordatabase was die werd opgenomen in de eerste Fortune 2023 50 AI Innovator-lijst.
Wil je meer weten over Pinecone? Bekijk de Mastering Vector Databases with Pinecone-tutorial.
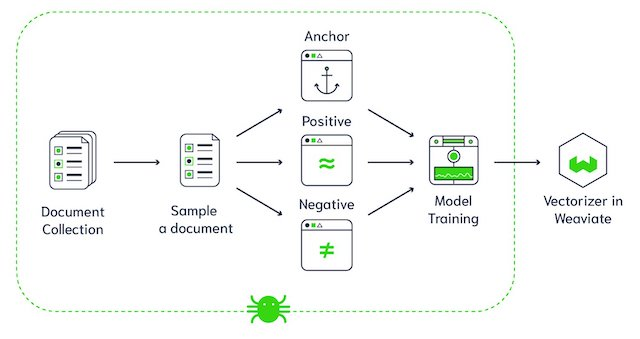
Weaviate-vectordatabasearchitectuur (Beeldbron)
Weaviate is een open-source vectordatabase. Je kunt er dataobjecten en vector-embeddings uit je favoriete ML-modellen in opslaan en naadloos opschalen naar miljarden dataobjecten. Enkele kernfuncties van Weaviate:

Faiss is een open-sourcebibliotheek voor vectorzoekopdrachten, ontwikkeld door Facebook (Beeldbron)
Faiss is een open-sourcebibliotheek voor het snel zoeken naar overeenkomsten en het clusteren van dichte vectors. Het bevat algoritmen die kunnen zoeken binnen vectorsets van uiteenlopende grootte, zelfs die welke het RAM-geheugen overschrijden. Daarnaast biedt Faiss ondersteunende code voor evaluatie en parameterafstemming.
Hoewel het primair in C++ is geschreven, is er volledige ondersteuning voor Python/NumPy-integratie. Sommige ker nalgoritmen zijn ook beschikbaar voor GPU-uitvoering. De primaire ontwikkeling van Faiss wordt gedaan door de Fundamental AI Research-groep bij Meta.
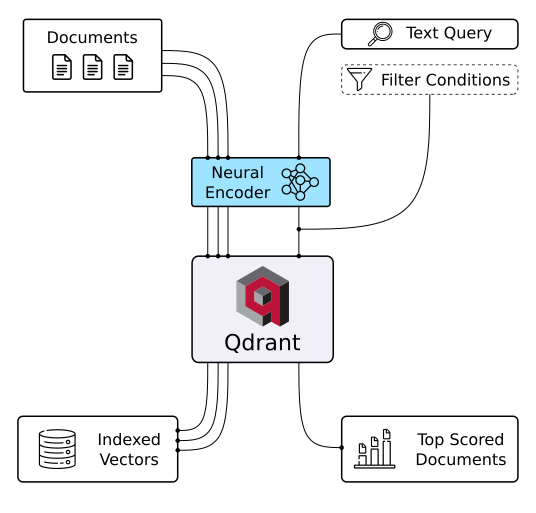
Qdrant-vectordatabase (Beeldbron)
Qdrant is een vectordatabase en een tool voor het uitvoeren van vector-similarity searches. Het draait als een API-service die het zoeken naar de dichtstbijzijnde hoog-dimensionale vectors mogelijk maakt. Met Qdrant kun je embeddings of neurale netwerk-encoders omzetten in complete toepassingen voor taken als matching, zoeken, aanbevelingen doen en veel meer. Enkele belangrijke kenmerken van Qdrant:
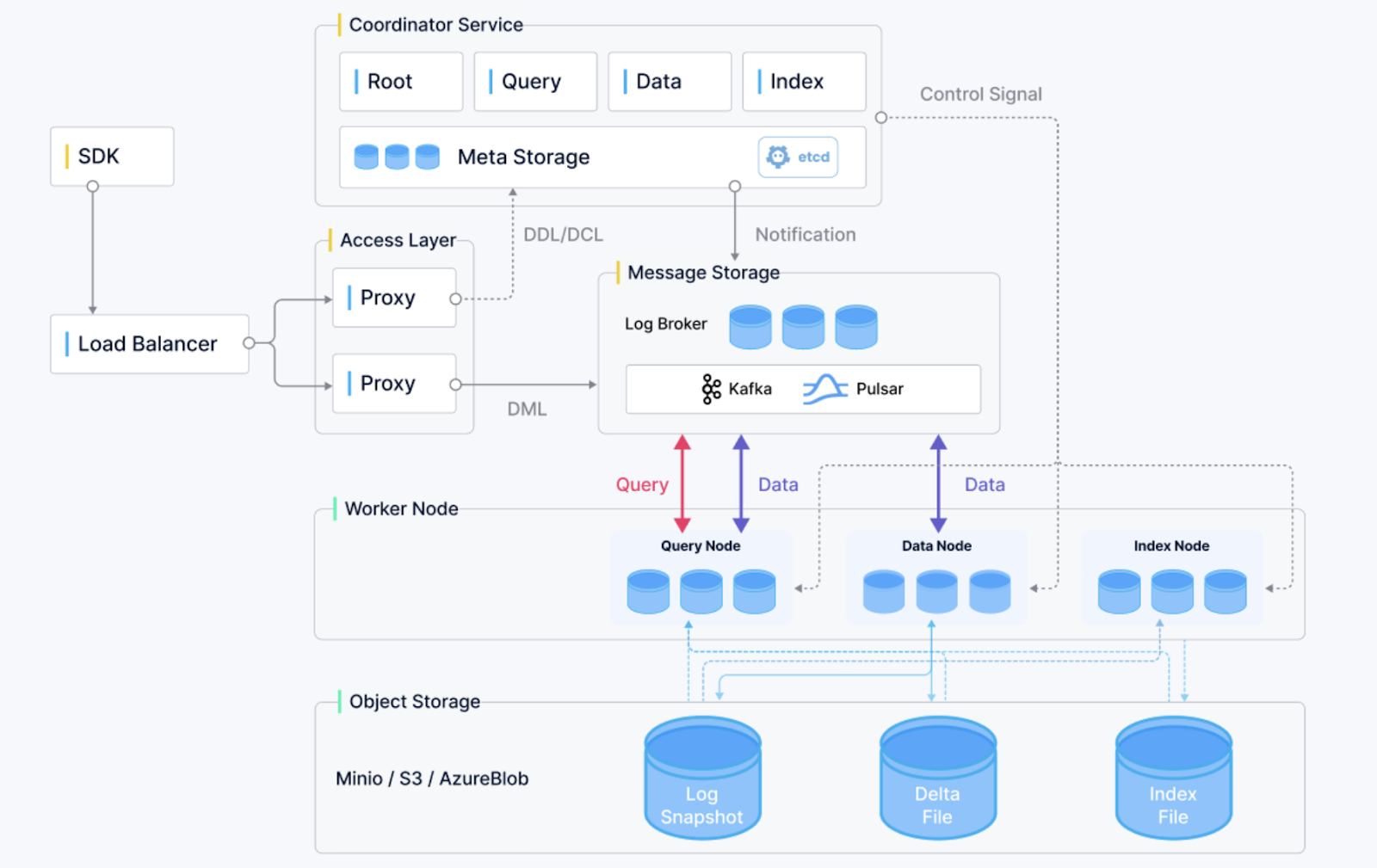
Overzicht van de Milvus-architectuur. (Beeldbron)
Milvus is een open-source vectordatabase die snel aan populariteit wint vanwege zijn schaalbaarheid, betrouwbaarheid en prestaties. Ontworpen voor similarity search en AI-gedreven toepassingen, ondersteunt het het opslaan en bevragen van enorme embeddingvectors die door diepe neurale netwerken worden gegenereerd. Milvus biedt de volgende functies:
Milvus is ideaal voor toepassingen in aanbevelingssystemen, videoanalyse en gepersonaliseerde zoekervaringen.
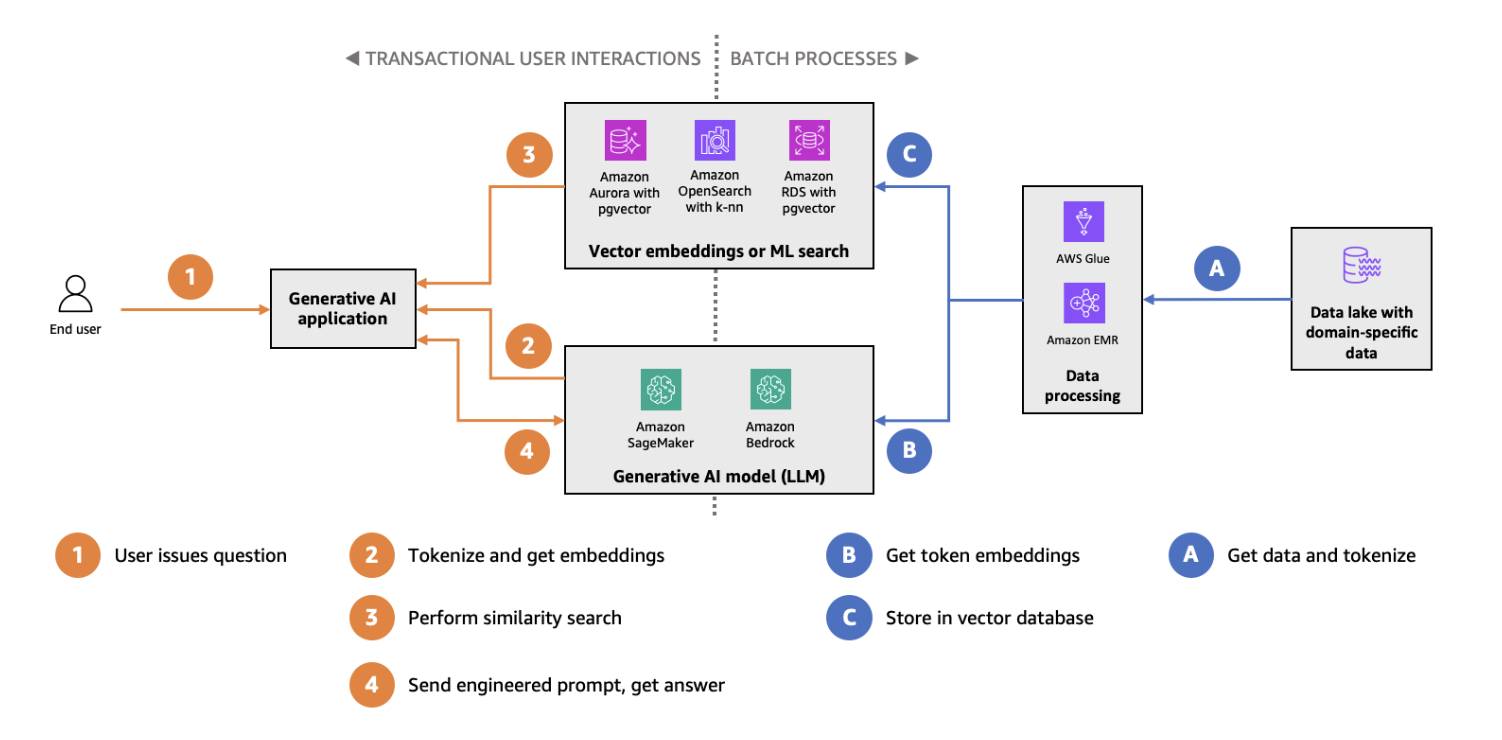
HNSW-indexering en -zoeken met pgvector op Amazon Aurora architectuuroverzicht. (Beeldbron)
pgvector is een extensie voor PostgreSQL die vectordatatypes en similarity search-mogelijkheden toevoegt aan de veelgebruikte relationele database. Door vector search te integreren in PostgreSQL biedt pgvector een naadloze oplossing voor teams die al traditionele databases gebruiken maar vectorzoekfunctionaliteit willen toevoegen. Belangrijke kenmerken van pgvector:
pgvector is bijzonder geschikt voor kleinschaligere vectorzoekcases of omgevingen waar één databasesysteem de voorkeur heeft voor zowel relationele als vectorgebaseerde workloads. Ga van start met onze uitgebreide pgvector-tutorial.
Hieronder staat een vergelijkingstabel met de kenmerken van de eerder besproken top-vectordatabases:
| Kenmerk | Chroma | Pinecone | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Open-source | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Primaire usecase | LLM-appontwikkeling | Beheerde vectordatabase voor ML | Schaalbare vectoropslag en -zoekopdrachten | Hogesnelheids-similarity search en clustering | Vector-similarity search | High-performance AI-zoekopdrachten | Vector search toevoegen aan PostgreSQL |
| Integratie | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, GPU-uitvoering | OpenAPI v3, clients voor diverse talen | TensorFlow, PyTorch, HuggingFace | Ingebed in het PostgreSQL-ecosysteem |
| Schaalbaarheid | Schaalt van Python-notebooks naar clusters | Zeer schaalbaar | Naadloos schalen naar miljarden objecten | Kan sets groter dan RAM aan | Cloud-native met horizontale schaalbaarheid | Schaalt naar miljarden vectors | Afhankelijk van PostgreSQL-setup |
| Zoeksnelheid | Snelle similarity searches | Zoeken met lage latentie | Milliseconden voor miljoenen objecten | Snel, ondersteunt GPU | Aangepast HNSW-algoritme voor snelle zoekopdrachten | Geoptimaliseerd voor zoeken met lage latentie | Approximate Nearest Neighbor (ANN) |
| Dataprivacy | Ondersteunt multi-user met data-isolatie | Volledig beheerde service | Legt nadruk op beveiliging en replicatie | Voornamelijk voor onderzoek en ontwikkeling | Geavanceerd filteren op vector-payloads | Veilige, multi-tenantarchitectuur | Erft de beveiliging van PostgreSQL |
| Programmeertaal | Python, JavaScript | Python | Python, Java, Go, andere | C++, Python | Rust | C++, Python, Go | PostgreSQL-extensie (SQL-gebaseerd) |
Vectordatabases zijn gespecialiseerd in het opslaan van hoog-dimensionale vectors en maken snelle en nauwkeurige similarity searches mogelijk. Aangezien AI-modellen, vooral op het gebied van natural language processing en computervisie, deze vectors genereren en ermee werken, is de behoefte aan efficiënte opslag- en ophaalsystemen essentieel geworden. Dit is waar vectordatabases uitkomst bieden: ze vormen een sterk geoptimaliseerde omgeving voor dit soort AI-gedreven toepassingen.
Een goed voorbeeld van deze relatie tussen AI en vectordatabases is de opkomst van Large Language Models (LLM’s) zoals GPT-3.
Deze modellen zijn ontworpen om mensachtige tekst te begrijpen en te genereren door enorme hoeveelheden data te verwerken en om te zetten in hoog-dimensionale vectors. Toepassingen die op GPT en vergelijkbare modellen zijn gebouwd, leunen zwaar op vectordatabases om deze vectors efficiënt te beheren en te bevragen. De reden hiervoor ligt in het enorme volume en de complexiteit van de data die deze modellen verwerken. Door de sterke toename in parameters genereren modellen zoals GPT-4 een enorme hoeveelheid gevectoriseerde data, wat voor conventionele databases lastig efficiënt te verwerken is. Dit onderstreept het belang van gespecialiseerde vectordatabases die dergelijke hoog-dimensionale data aankunnen.
Het voortdurend veranderende landschap van kunstmatige intelligentie en machine learning benadrukt hoe onmisbaar vectordatabases zijn in onze datagedreven wereld. Deze databases, met hun unieke vermogen om multidimensionale datavectors op te slaan, te doorzoeken en te analyseren, blijken cruciaal voor AI-gedreven toepassingen, van aanbevelingssystemen tot genomische analyse.
We hebben recent een indrukwekkende reeks vectordatabases gezien, zoals Chroma, Pinecone, Weaviate, Faiss en Qdrant, die elk eigen mogelijkheden en innovaties bieden. Naarmate AI blijft groeien, zal de rol van vectordatabases bij het vormgeven van de toekomst van data-opslag, -verwerking en -analyse ongetwijfeld toenemen, met de belofte van meer geavanceerde, efficiënte en gepersonaliseerde oplossingen in diverse sectoren.
Leer vectordatabases onder de knie te krijgen met onze Pinecone-tutorial, of schrijf je in voor onze skilltrack Deep Learning in Python om je AI-skills te verbeteren en bij te blijven met de nieuwste ontwikkelingen.
Leer meer over AI met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
