
Cours
Comprendre l'intelligence artificielle
2 h
401.7K
Une base de données vectorielle est un type spécifique de base de données qui stocke les informations sous forme de vecteurs multidimensionnels représentant certaines caractéristiques ou qualités.
Le nombre de dimensions dans chaque vecteur peut varier considérablement, de quelques-unes à plusieurs milliers, en fonction de la complexité et du niveau de détail des données. Ces données, qui peuvent inclure du texte, des images, des fichiers audio et vidéo, sont transformées en vecteurs à l'aide de divers processus tels que des modèles d'apprentissage automatique, des plongements lexicaux ou des techniques d'extraction de caractéristiques.
Le principal avantage d'une base de données vectorielle réside dans sa capacité à localiser et à récupérer rapidement et précisément des données en fonction de leur proximité ou de leur ressemblance vectorielle. Cela permet d'effectuer des recherches fondées sur la pertinence sémantique ou contextuelle plutôt que de se baser uniquement sur des correspondances exactes ou des critères prédéfinis, comme c'est le cas avec les bases de données conventionnelles.
Par exemple, avec une base de données vectorielle, vous pouvez :
Les bases de données traditionnelles stockent des données simples telles que des mots et des chiffres sous forme de tableaux. Les bases de données vectorielles, cependant, fonctionnent avec des données complexes appelées vecteurs et utilisent des méthodes de recherche uniques.
Alors que les bases de données classiques recherchent des correspondances exactes, les bases de données vectorielles recherchent la correspondance la plus proche à l'aide de mesures de similarité spécifiques.
Les bases de données vectorielles utilisent des techniques de recherche spéciales appelées « recherche par approximations du plus proche voisin » (ANN), qui comprennent des méthodes telles que le hachage et les recherches basées sur des graphes.
Pour bien appréhender le fonctionnement des bases de données vectorielles et leur différence par rapport aux bases de données relationnelles traditionnelles telles que SQL, il est nécessaire de comprendre le concept d'intégration.
Les données non structurées, telles que le texte, les images et l'audio, ne disposent pas d'un format prédéfini, ce qui pose des défis aux bases de données traditionnelles. Afin d'exploiter ces données dans des applications d'intelligence artificielle et d'apprentissage automatique, elles sont converties en représentations numériques à l'aide d'intégrations.
L'intégration consiste à attribuer à chaque élément, qu'il s'agisse d'un mot, d'une image ou de tout autre élément, un code unique qui en capture la signification ou l'essence. Ce code aide les ordinateurs à comprendre et à comparer ces éléments de manière plus efficace et pertinente. Considérez cela comme la transformation d'un ouvrage complexe en un résumé concis qui en conserve les points essentiels.
Ce processus d'intégration est généralement réalisé à l'aide d'un type particulier de réseau neuronal conçu pour cette tâche. Par exemple, les plongements de mots convertissent les mots en vecteurs de telle sorte que les mots ayant des significations similaires soient plus proches dans l'espace vectoriel.
Cette transformation permet aux algorithmes de comprendre les relations et les similitudes entre les éléments.
Essentiellement, les intégrations servent de passerelle, convertissant les données non numériques en un format exploitable par les modèles d'apprentissage automatique, ce qui leur permet de discerner plus efficacement les modèles et les relations dans les données.
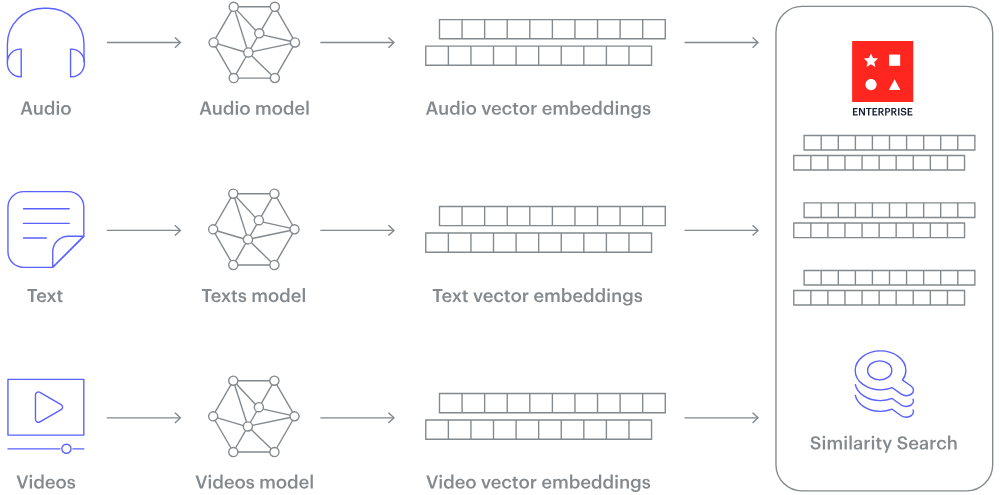
Comment fonctionne une base de données vectorielle ? (Source de l'image)
Les bases de données vectorielles, grâce à leurs capacités uniques, se taillent une place dans de nombreux secteurs en raison de leur efficacité dans la mise en œuvre de la « recherche par similarité ». Voici un aperçu plus détaillé de leurs diverses applications :
Dans le secteur dynamique de la vente au détail, les bases de données vectorielles transforment la manière dont les consommateurs effectuent leurs achats. Ils permettent la création de systèmes de recommandation avancés, offrant des expériences d'achat personnalisées. Par exemple, un client en ligne peut recevoir des suggestions de produits non seulement en fonction de ses achats antérieurs, mais également en analysant les similitudes entre les caractéristiques des produits, le comportement des utilisateurs et leurs préférences.
Le secteur financier est caractérisé par des modèles et des tendances complexes. Les bases de données vectorielles excellent dans l'analyse de ces données denses, aidant les analystes financiers à détecter les tendances cruciales pour les stratégies d'investissement. En identifiant les similitudes ou les écarts subtils, ils peuvent prévoir les mouvements du marché et élaborer des plans d'investissement plus éclairés.
Dans le domaine des soins de santé, la personnalisation est essentielle. En analysant les séquences génomiques, les bases de données vectorielles permettent des traitements médicaux plus personnalisés, garantissant ainsi que les solutions médicales correspondent mieux à la constitution génétique de chaque individu.
Le monde numérique connaît actuellement une forte augmentation des chatbots et des assistants virtuels. Ces entités basées sur l'intelligence artificielle dépendent fortement de la compréhension du langage humain. En convertissant de grandes quantités de données textuelles en vecteurs, ces systèmes peuvent mieux comprendre et répondre aux requêtes humaines. Par exemple, des entreprises telles que Talkmap utilisent la compréhension du langage naturel en temps réel, ce qui permet des interactions plus fluides entre les clients et les agents.
Des examens médicaux aux images de vidéosurveillance, la capacité à comparer et à comprendre avec précision les images est essentielle. Les bases de données vectorielles simplifient ce processus en se concentrant sur les caractéristiques essentielles des images, en filtrant le bruit et les distorsions. Par exemple, dans le domaine de la gestion du trafic, les images provenant de flux vidéo peuvent être rapidement analysées afin d'optimiser la fluidité du trafic et d'améliorer la sécurité publique.
Identifier les valeurs aberrantes est aussi important que reconnaître les similitudes. Dans des secteurs tels que la finance et la sécurité, la détection d'anomalies peut permettre de prévenir la fraude ou d'anticiper une éventuelle faille de sécurité. Les bases de données vectorielles offrent des capacités améliorées dans ce domaine, rendant le processus de détection plus rapide et plus précis.
Les bases de données vectorielles se sont imposées comme des outils puissants pour explorer le vaste domaine des données non structurées, telles que les images, les vidéos et les textes, sans dépendre fortement des étiquettes ou balises générées par l'homme. Leurs capacités, lorsqu'elles sont intégrées à des modèles avancés d'apprentissage automatique, ont le potentiel de révolutionner de nombreux secteurs, du commerce électronique à l'industrie pharmaceutique. Voici quelques-unes des fonctionnalités remarquables qui font des bases de données vectorielles un outil révolutionnaire :
Une base de données vectorielle robuste garantit que, à mesure que les données augmentent (pour atteindre des millions, voire des milliards d'éléments), elles peuvent facilement être réparties sur plusieurs nœuds. Les meilleures bases de données vectorielles offrent une grande adaptabilité, permettant aux utilisateurs d'ajuster le système en fonction des variations du taux d'insertion, du taux de requêtes et du matériel sous-jacent.
La prise en charge de plusieurs utilisateurs est une exigence standard pour les bases de données. Cependant, la simple création d'une nouvelle base de données vectorielle pour chaque utilisateur n'est pas efficace. Les bases de données vectorielles privilégient l'isolation des données, garantissant que toute modification apportée à un ensemble de données reste invisible pour les autres, à moins que le propriétaire ne la partage intentionnellement. Cela permet non seulement de prendre en charge la multi-location, mais aussi de garantir la confidentialité et la sécurité des données.
Une base de données authentique et efficace fournit un ensemble complet d'API et de SDK. Cela garantit que le système peut interagir avec diverses applications et être géré efficacement. Les principales bases de données vectorielles, telles que Pinecone, fournissent des SDK dans divers langages de programmation tels que Python, Node, Go et Java, garantissant ainsi une grande flexibilité dans le développement et la gestion.
En réduisant la courbe d'apprentissage abrupte associée aux nouvelles technologies, les interfaces conviviales des bases de données vectorielles jouent un rôle essentiel. Ces interfaces offrent une vue d'ensemble visuelle, une navigation aisée et un accès à des fonctionnalités qui, sans cela, pourraient rester cachées.
La liste n'est pas classée dans un ordre particulier - chaque élément présente plusieurs des qualités décrites dans la section ci-dessus.
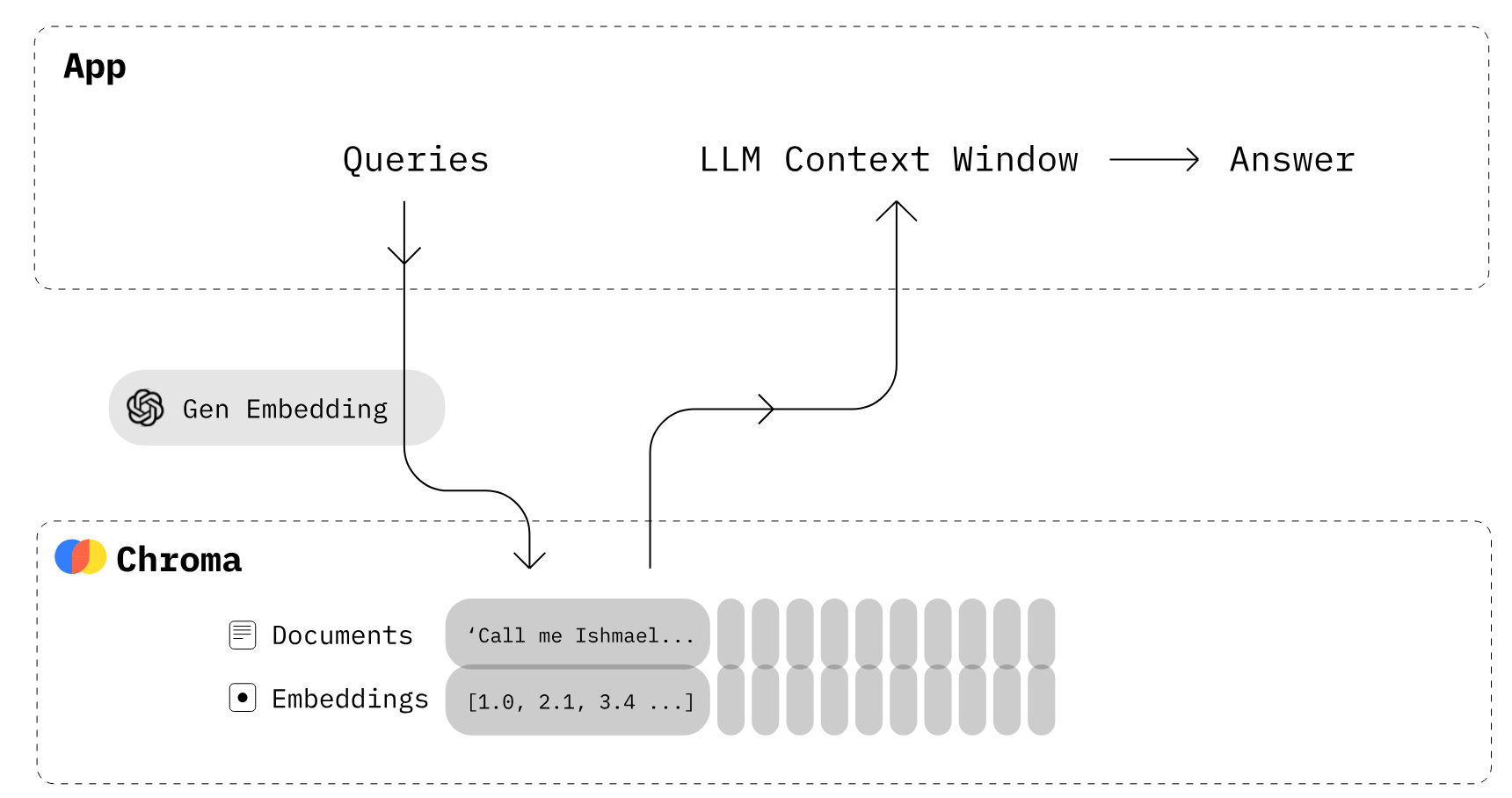
Développement d'applications LLM à l'aide de ChromaDB (Source de l'image)
Chroma est une base de données d'intégration open source. Chroma facilite la création d'applications LLM en rendant les connaissances, les faits et les compétences intégrables aux LLM. Comme nous l'expliquons dans notre tutoriel Chroma DB, vous pouvez facilement gérer des documents texte, convertir du texte en embeddings et effectuer des recherches par similarité.
Caractéristiques de ChromaDB :

Base de données vectorielle Pinecone (Source de l'image)
Pinecone est une plateforme de base de données vectorielle gérée, spécialement conçue pour relever les défis uniques associés aux données à haute dimension. Doté de capacités d'indexation et de recherche de pointe, Pinecone permet aux ingénieurs et aux scientifiques spécialisés dans les données de créer et de mettre en œuvre des applications d'apprentissage automatique à grande échelle qui traitent et analysent efficacement des données à haute dimension.
Les principales fonctionnalités de Pinecone sont les suivantes :
Il est à noter que Pinecone était la seule base de données vectorielle à figurer dans la première liste Fortune 2023 des 50 innovateurs en intelligence artificielle.
Pour en savoir plus sur Pinecone, veuillez consulter le tutoriel « Maîtriser les bases de données vectorielles avec Pinecone ».
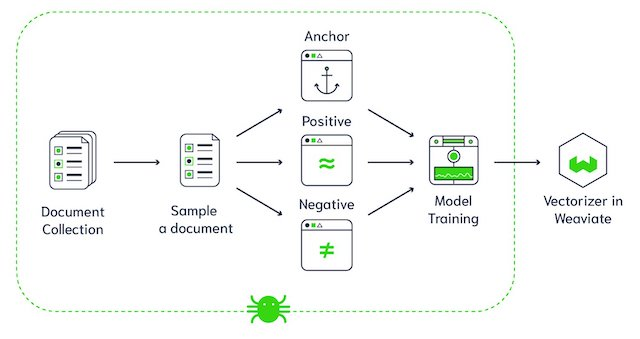
Architecture de la base de données vectorielle Weaviate (Source de l'image)
Weaviate est une base de données vectorielle open source. Il vous permet de stocker des objets de données et des intégrations vectorielles provenant de vos modèles ML préférés et d'évoluer de manière transparente vers des milliards d'objets de données. Voici quelques-unes des principales fonctionnalités de Weaviate :

Faiss est une bibliothèque open source pour la recherche vectorielle développée par Facebook (Source de l'image)
Faiss est une bibliothèque open source permettant la recherche rapide de similitudes et le regroupement de vecteurs denses. Il contient des algorithmes capables d'effectuer des recherches dans des ensembles de vecteurs de tailles variables, même ceux qui pourraient dépasser la capacité de la mémoire vive. De plus, Faiss propose un code auxiliaire pour l'évaluation et l'ajustement des paramètres.
Bien qu'il soit principalement codé en C++, il prend entièrement en charge l'intégration Python/NumPy. Certains de ses algorithmes clés sont également disponibles pour une exécution sur GPU. Le développement initial de Faiss est assuré par le groupe Fundamental AI Research de Meta.
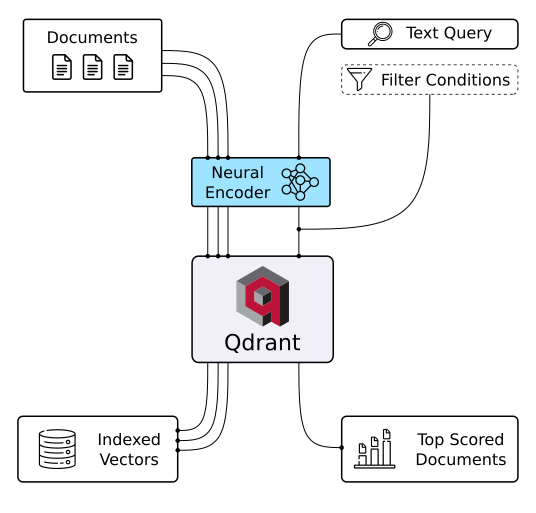
Base de données vectorielle Qdrant (Source de l'image)
Qdrant est une base de données vectorielle et un outil permettant d'effectuer des recherches de similarité vectorielle. Il fonctionne comme un service API, permettant de rechercher les vecteurs de haute dimension les plus proches. Grâce à Qdrant, vous pouvez transformer des intégrations ou des encodeurs de réseaux neuronaux en applications complètes pour des tâches telles que la mise en correspondance, la recherche, la formulation de recommandations et bien plus encore. Voici quelques fonctionnalités clés de Qdrant :
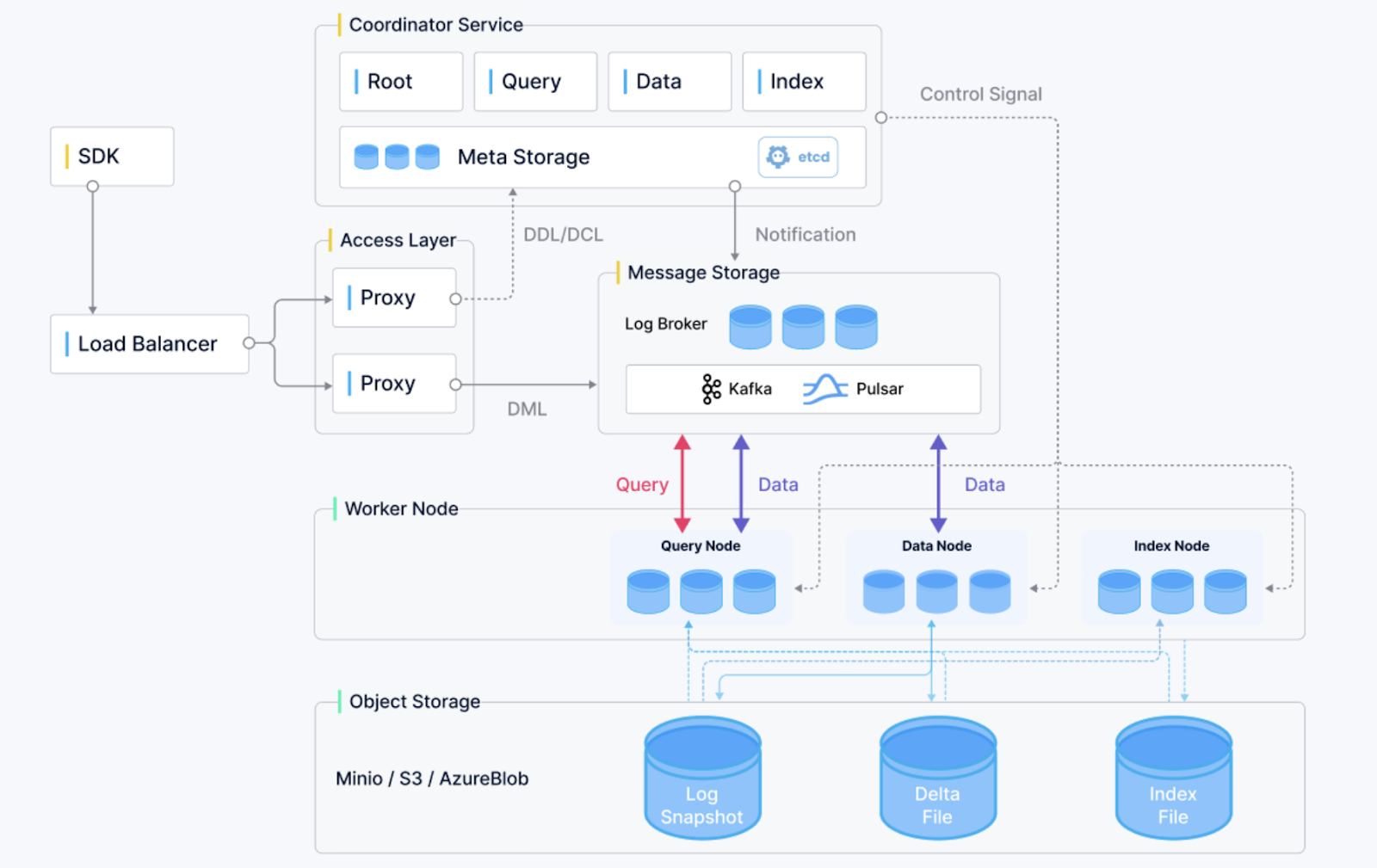
Présentation de l'architecture Milvus. (Source de l'image)
Milvus est une base de données vectorielles open source qui a rapidement gagné en popularité grâce à son évolutivité, sa fiabilité et ses performances. Conçu pour la recherche par similarité et les applications basées sur l'intelligence artificielle, il prend en charge le stockage et l'interrogation de vecteurs d'intégration massifs générés par des réseaux neuronaux profonds. Milvus propose les fonctionnalités suivantes :
Milvus est particulièrement adapté aux applications dans les systèmes de recommandation, l'analyse vidéo et les expériences de recherche personnalisées.
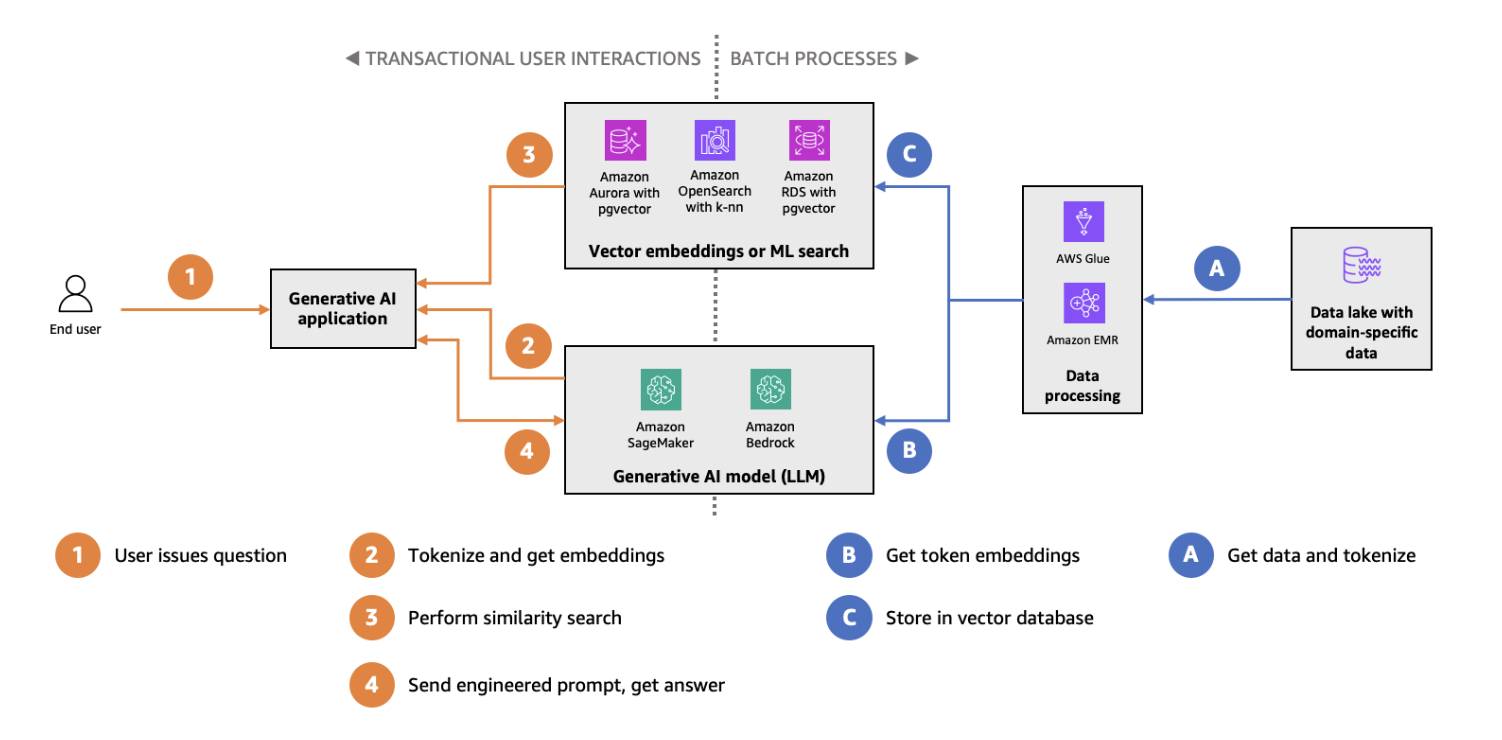
Indexation et recherche HNSW avec pgvector sur le schéma d'architecture Amazon Aurora. (Source de l'image)
pgvector est une extension pour PostgreSQL qui introduit des types de données vectorielles et des capacités de recherche par similarité dans la base de données relationnelle largement utilisée. En intégrant la recherche vectorielle dans PostgreSQL, pgvector offre une solution transparente aux équipes qui utilisent déjà des bases de données traditionnelles mais souhaitent ajouter des fonctionnalités de recherche vectorielle. Les principales fonctionnalités de pgvector sont les suivantes :
pgvector est particulièrement adapté aux cas d'utilisation de recherche vectorielle à petite échelle ou aux environnements où un système de base de données unique est préférable pour les charges de travail relationnelles et vectorielles. Pour commencer, veuillez consulternotre tutoriel détaillé sur pgvector.
Vous trouverez ci-dessous un tableau comparatif mettant en évidence les caractéristiques des principales bases de données vectorielles évoquées précédemment :
| Caractéristique | Chroma | Pomme de pin | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Open source | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Cas d'utilisation principal | Développement d'applications LLM | Base de données vectorielle gérée pour l'apprentissage automatique | Stockage et recherche vectoriels évolutifs | Recherche de similitudes et regroupement à grande vitesse | Recherche par similarité vectorielle | Recherche IA haute performance | Ajout de la recherche vectorielle à PostgreSQL |
| Intégration | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, exécution sur GPU | OpenAPI v3, clients en plusieurs langues | TensorFlow, PyTorch, HuggingFace | Intégré à l'écosystème PostgreSQL |
| Évolutivité | Évolutif, des notebooks Python aux clusters | Très évolutif | Évolutivité transparente jusqu'à des milliards d'objets | Capable de gérer des ensembles plus grands que la mémoire vive | Natif du cloud avec évolutivité horizontale | Échelle à des milliards de vecteurs | Dépend de la configuration de PostgreSQL |
| Vitesse de recherche | Recherches rapides par similarité | Recherche à faible latence | Millisecondes pour des millions d'objets | Rapide, prend en charge le GPU | Algorithme HNSW personnalisé pour une recherche rapide | Optimisé pour une recherche à faible latence | Voisin approximatif le plus proche (ANN) |
| Confidentialité des données | Prend en charge plusieurs utilisateurs avec isolation des données | Service entièrement géré | Met l'accent sur la sécurité et la réplication | Principalement pour la recherche et le développement | Filtrage avancé des charges utiles vectorielles | Architecture multi-locataires sécurisée | Hérite de la sécurité de PostgreSQL |
| Langage de programmation | Python, JavaScript | Python | Python, Java, Go, autres | C++, Python | Rouille | C++, Python, Go | Extension PostgreSQL (basée sur SQL) |
Les bases de données vectorielles sont spécialisées dans le stockage de vecteurs à haute dimension, ce qui permet des recherches de similarité rapides et précises. Étant donné que les modèles d'IA, en particulier ceux utilisés dans le domaine du traitement du langage naturel et de la vision par ordinateur, génèrent et exploitent ces vecteurs, il est devenu essentiel de disposer de systèmes de stockage et de récupération efficaces. C'est là que les bases de données vectorielles entrent en jeu, en fournissant un environnement hautement optimisé pour ces applications basées sur l'intelligence artificielle.
Un exemple significatif de cette relation entre l'IA et les bases de données vectorielles est l'émergence de grands modèles linguistiques (LLM) tels que GPT-3.
Ces modèles sont conçus pour comprendre et générer des textes semblables à ceux rédigés par des humains en traitant de grandes quantités de données, qu'ils transforment en vecteurs à haute dimension. Les applications telles que, basées sur le GPT et des modèles similaires, s'appuient fortement sur des bases de données vectorielles pour gérer et interroger efficacement ces vecteurs. La raison de cette dépendance réside dans le volume considérable et la complexité des données traitées par ces modèles. Compte tenu de l'augmentation considérable du nombre de paramètres, les modèles tels que GPT-4 génèrent une quantité considérable de données vectorisées, ce qui peut poser des difficultés pour les bases de données conventionnelles qui souhaitent les traiter efficacement. Cela souligne l'importance des bases de données vectorielles spécialisées capables de traiter des données aussi multidimensionnelles.
Le paysage en constante évolution de l'intelligence artificielle et de l'apprentissage automatique souligne le caractère indispensable des bases de données vectorielles dans le monde actuel centré sur les données. Ces bases de données, grâce à leur capacité unique à stocker, rechercher et analyser des vecteurs de données multidimensionnels, s'avèrent essentielles pour alimenter les applications basées sur l'IA, des systèmes de recommandation à l'analyse génomique.
Nous avons récemment observé une gamme impressionnante de bases de données vectorielles, telles que Chroma, Pinecone, Weaviate, Faiss et Qdrant, chacune offrant des capacités et des innovations distinctes. À mesure que l'IA poursuit son ascension, le rôle des bases de données vectorielles dans l'avenir de la récupération, du traitement et de l'analyse des données va sans aucun doute prendre de l'importance, promettant des solutions plus sophistiquées, plus efficaces et plus personnalisées dans divers secteurs.
Apprenez à maîtriser les bases de données vectorielles grâce à notre tutoriel Pinecone, ou inscrivez-vous à notre cursus de compétences Deep Learning in Python pour améliorer vos compétences en IA et rester informé des dernières avancées.
Veuillez approfondir vos connaissances en matière d'IA grâce à ces cours.
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Kurtis Pykes
9 min
blog
Lynn Heidmann
Tutoriel
Tutoriel
Sejal Jaiswal

