
Kurs
Künstliche Intelligenz verstehen
2 Std.
401.5K
Eine Vektordatenbank ist eine spezielle Art von Datenbank, die Infos in Form von mehrdimensionalen Vektoren speichert, die bestimmte Eigenschaften oder Qualitäten darstellen.
Die Anzahl der Dimensionen in jedem Vektor kann stark variieren, von nur wenigen bis zu mehreren Tausend, je nachdem, wie kompliziert und detailliert die Daten sind. Diese Daten, die Text, Bilder, Audio- und Videodateien umfassen können, werden mithilfe verschiedener Verfahren wie maschinellen Lernmodellen, Wort-Embeddings oder Merkmalsextraktionsverfahren in Vektoren umgewandelt.
Der Hauptvorteil einer Vektordatenbank ist, dass sie Daten schnell und genau nach ihrer Vektorähnlichkeit oder -nähe finden und abrufen kann. Das ermöglicht Suchen, die auf semantischer oder kontextueller Relevanz basieren, anstatt sich nur auf exakte Übereinstimmungen oder festgelegte Kriterien wie bei herkömmlichen Datenbanken zu verlassen.
Mit einer Vektordatenbank kannst du zum Beispiel:
Traditionelle Datenbanken speichern einfache Daten wie Wörter und Zahlen in Form einer Tabelle. Vektordatenbanken arbeiten aber mit komplizierten Daten, die man Vektoren nennt, und nutzen spezielle Suchmethoden.
Während normale Datenbanken nach exakten Datenübereinstimmungen suchen, suchen Vektordatenbanken mithilfe spezifischer Ähnlichkeitsmaße nach der besten Übereinstimmung.
Vektordatenbanken nutzen spezielle Suchtechniken, die als Approximate Nearest Neighbor (ANN)-Suche bekannt sind. Dazu gehören Methoden wie Hashing und graphbasierte Suchen.
Um wirklich zu kapieren, wie Vektordatenbanken funktionieren und wie sie sich von herkömmlichen relationalen Datenbanken wie SQL unterscheiden, müssen wir erst mal das Konzept der Einbettungen verstehen.
Unstrukturierte Daten wie Texte, Bilder und Audiodateien haben kein festes Format, was für herkömmliche Datenbanken echt schwierig ist. Um diese Daten in KI- und ML-Anwendungen zu nutzen, werden sie mit Hilfe von Einbettungen in numerische Darstellungen umgewandelt.
Einbetten ist so, als würde man jedem Element, egal ob Wort, Bild oder was auch immer, einen einzigartigen Code geben, der seine Bedeutung oder sein Wesen erfasst. Dieser Code hilft Computern, diese Elemente besser zu verstehen und zu vergleichen. Stell dir vor, du machst aus einem komplizierten Buch eine kurze Zusammenfassung, die trotzdem die wichtigsten Punkte enthält.
Dieser Einbettungsprozess wird normalerweise mit einem speziellen neuronalen Netzwerk gemacht, das genau dafür entwickelt wurde. Zum Beispiel verwandeln Wort-Embeddings Wörter in Vektoren, sodass Wörter mit ähnlicher Bedeutung im Vektorraum näher beieinander liegen.
Durch diese Umwandlung können Algorithmen Beziehungen und Ähnlichkeiten zwischen Elementen erkennen.
Im Grunde sind Einbettungen wie eine Brücke, die nicht-numerische Daten in eine Form umwandelt, mit der Machine-Learning-Modelle arbeiten können. So können sie Muster und Beziehungen in den Daten besser erkennen.
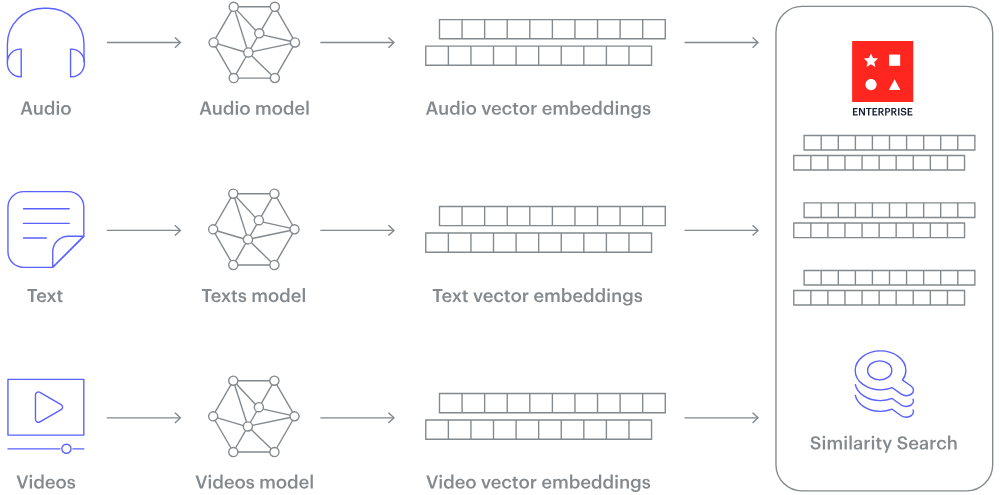
Wie funktioniert eine Vektordatenbank? (Bildquelle)
Vektordatenbanken machen sich mit ihren coolen Funktionen in vielen Branchen einen Namen, weil sie super effizient bei der „Ähnlichkeitssuche” sind. Hier geht's zu einem tieferen Einblick in ihre vielfältigen Anwendungen:
Im lebhaften Einzelhandel verändern Vektordatenbanken die Art und Weise, wie Leute einkaufen. Sie machen es möglich, fortschrittliche Empfehlungssysteme zu entwickeln, die personalisierte Einkaufserlebnisse bieten. Ein Online-Käufer kann zum Beispiel Produktvorschläge nicht nur aufgrund früherer Käufe bekommen, sondern auch durch die Analyse von Ähnlichkeiten bei Produktmerkmalen, Nutzerverhalten und Vorlieben.
Der Finanzsektor ist voll von komplizierten Mustern und Trends. Vektordatenbanken sind super darin, diese komplexen Daten zu analysieren, und helfen Finanzanalysten dabei, Muster zu erkennen, die für Investitionsstrategien wichtig sind. Indem sie kleine Ähnlichkeiten oder Unterschiede erkennen, können sie Marktbewegungen vorhersagen und fundiertere Investitionspläne erstellen.
Im Gesundheitswesen ist es super wichtig, alles individuell anzupassen. Durch die Analyse von Genomsequenzen ermöglichen Vektordatenbanken individuellere medizinische Behandlungen, sodass medizinische Lösungen besser auf die genetische Veranlagung jedes Einzelnen abgestimmt werden können.
In der digitalen Welt gibt's immer mehr Chatbots und virtuelle Assistenten. Diese KI-gesteuerten Systeme sind total darauf angewiesen, die menschliche Sprache zu verstehen. Durch die Umwandlung riesiger Textdaten in Vektoren können diese Systeme menschliche Anfragen genauer verstehen und darauf reagieren. Firmen wie Talkmap nutzen zum Beispiel Echtzeit-Verständnis natürlicher Sprache, was zu einer reibungsloseren Interaktion zwischen Kunden und Kundendienstmitarbeitern führt.
Von medizinischen Scans bis hin zu Überwachungsaufnahmen ist es echt wichtig, Bilder genau vergleichen und verstehen zu können. Vektordatenbanken machen das einfacher, indem sie sich auf die wichtigsten Merkmale von Bildern konzentrieren und Störungen und Verzerrungen rausfiltern. Zum Beispiel kann man im Verkehrsmanagement Bilder aus Videoaufnahmen schnell checken, um den Verkehrsfluss zu verbessern und die Sicherheit zu erhöhen.
Ausreißer zu erkennen ist genauso wichtig wie Gemeinsamkeiten zu erkennen. Besonders in Bereichen wie Finanzen und Sicherheit kann das Erkennen von Anomalien dazu beitragen, Betrug zu verhindern oder potenzielle Sicherheitsverletzungen zu vermeiden. Vektordatenbanken bieten in diesem Bereich mehr Möglichkeiten, wodurch der Erkennungsprozess schneller und genauer wird.
Vektordatenbanken sind echt nützliche Tools geworden, um sich in der riesigen Welt unstrukturierter Daten wie Bilder, Videos und Texte zurechtzufinden, ohne dass man sich dabei stark auf von Menschen erstellte Beschriftungen oder Tags verlassen muss. Wenn man ihre Fähigkeiten mit modernen Machine-Learning-Modellen kombiniert, können sie viele Branchen, vom E-Commerce bis zur Pharmaindustrie, total verändern. Hier sind ein paar der coolen Features, die Vektordatenbanken so besonders machen:
Eine robuste Vektordatenbank sorgt dafür, dass die Daten, wenn sie wachsen – bis zu Millionen oder sogar Milliarden von Elementen –, problemlos über mehrere Knoten skaliert werden können. Die besten Vektordatenbanken sind flexibel und lassen sich anpassen, sodass die Nutzer das System je nach Einfügungsrate, Abfragerate und der zugrunde liegenden Hardware optimieren können.
Die Unterstützung mehrerer Benutzer ist bei Datenbanken ganz normal. Es ist aber nicht so effizient, einfach für jeden Nutzer eine neue Vektordatabase zu erstellen. Vektordatenbanken legen Wert auf die Isolierung von Daten, sodass Änderungen an einer Datensammlung für die anderen unsichtbar bleiben, es sei denn, der Besitzer teilt sie absichtlich mit ihnen. Das unterstützt nicht nur die Mandantenfähigkeit, sondern sorgt auch für Datenschutz und Datensicherheit.
Eine echte und effektive Datenbank hat einen kompletten Satz an APIs und SDKs. Dadurch wird sichergestellt, dass das System mit verschiedenen Anwendungen interagieren und effektiv verwaltet werden kann. Führende Vektordatenbanken wie Pinecone bieten SDKs in verschiedenen Programmiersprachen wie Python, Node, Go und Java an, was Flexibilität bei der Entwicklung und Verwaltung garantiert.
Um die steile Lernkurve bei neuen Technologien zu flachen, sind benutzerfreundliche Oberflächen in Vektordatenbanken echt wichtig. Diese Schnittstellen bieten einen schnellen Überblick, einfache Navigation und Zugriff auf Funktionen, die sonst vielleicht nicht so leicht zu finden wären.
Die Liste ist nicht in einer bestimmten Reihenfolge – jeder zeigt viele der Eigenschaften, die oben beschrieben wurden.
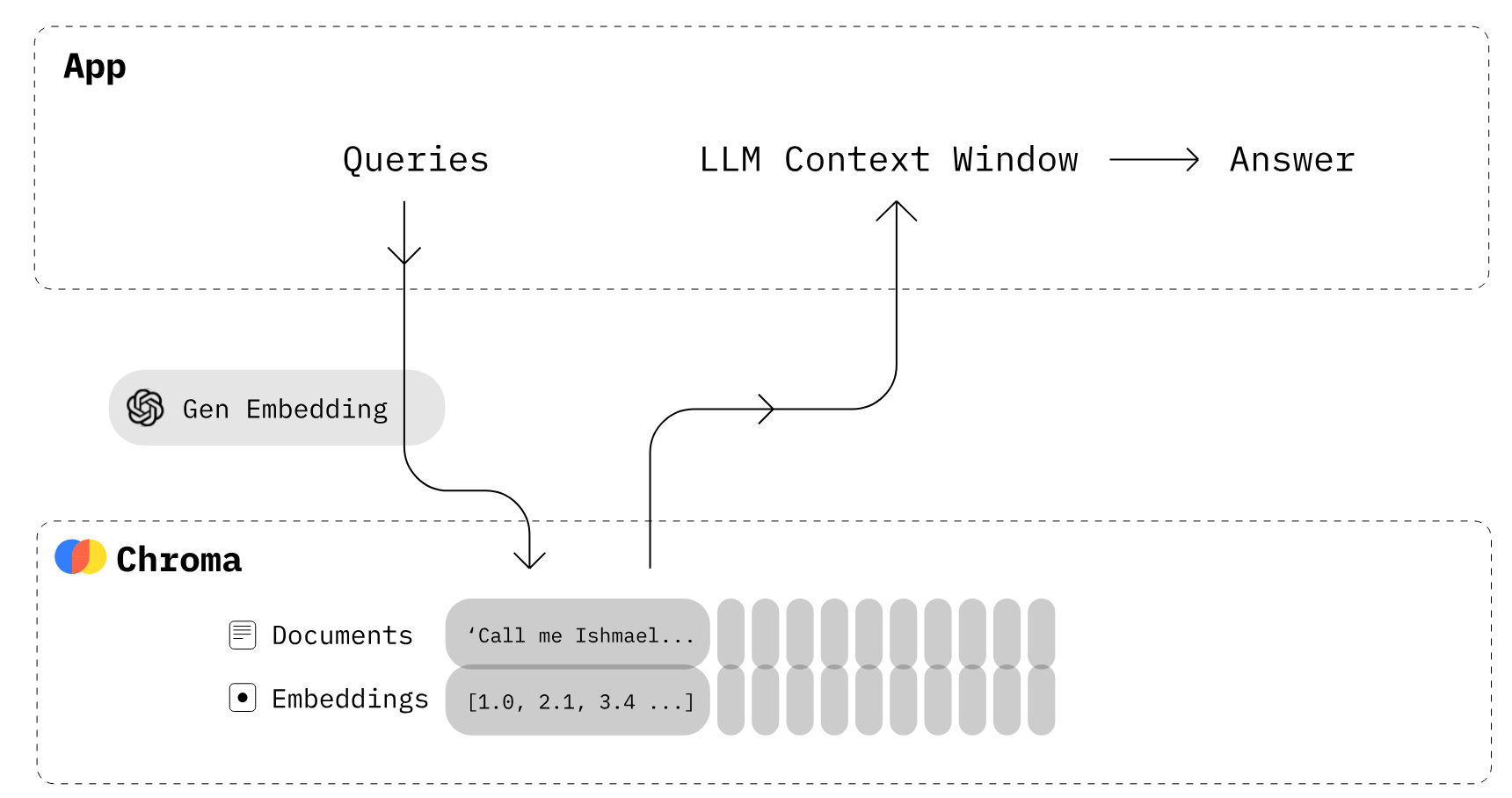
Entwickle LLM-Apps mit ChromaDB (Bildquelle)
Chroma ist eine Open-Source-Einbettungsdatenbank. Chroma macht es einfach, LLM-Apps zu entwickeln, indem es Wissen, Fakten und Fähigkeiten für LLMs einbaufähig macht. Wie wir in unserem Chroma DB-Tutorial zeigen, kannst du ganz einfach Textdokumente verwalten, Text in Einbettungen umwandeln und Ähnlichkeitssuchen durchführen.
ChromaDB bietet:

Pinecone-Vektordatenbank (Bildquelle)
Pinecone ist eine verwaltete Vektordatenbankplattform, die speziell entwickelt wurde, um die besonderen Herausforderungen im Zusammenhang mit hochdimensionalen Daten zu bewältigen. Mit den neuesten Indexierungs- und Suchfunktionen hilft Pinecone Dateningenieuren und Datenwissenschaftlern dabei, große Machine-Learning-Anwendungen zu entwickeln und einzusetzen, die hochdimensionale Daten effektiv verarbeiten und analysieren können.
Die wichtigsten Features von Pinecone sind:
Besonders cool ist, dass Pinecone die einzige Vektordatenbank war, die es auf die erste Fortune 2023 50 AI Innovator-Liste geschafft hat.
Wenn du mehr über Pinecone erfahren willst, schau dir das Tutorial „Vektordatenbanken mit Pinecone meistern“ an.
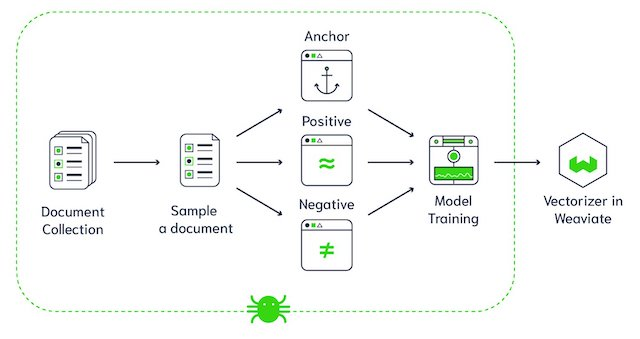
Weaviate-Vektordatenbankarchitektur (Bildquelle)
Weaviate ist eine Open-Source-Vektordatenbank. Damit kannst du Datenobjekte und Vektoreinbettungen aus deinen Lieblings-ML-Modellen speichern und nahtlos auf Milliarden von Datenobjekten skalieren. Ein paar der wichtigsten Features von Weaviate sind:

Faiss ist eine Open-Source-Bibliothek für die Vektorsuche, die von Facebook entwickelt wurde (Bildquelle)
Faiss ist eine Open-Source-Bibliothek für die schnelle Suche nach Ähnlichkeiten und das Clustering dichter Vektoren. Es hat Algorithmen drauf, die in Vektorsätzen unterschiedlicher Größe suchen können, sogar in solchen, die die RAM-Kapazität übersteigen könnten. Außerdem hat Faiss einen Zusatzcode für die Bewertung und Anpassung von Parametern.
Obwohl es hauptsächlich in C++ programmiert ist, unterstützt es Python/NumPy voll. Einige der wichtigsten Algorithmen können auch auf der GPU laufen. Die Hauptentwicklung von Faiss läuft bei der Fundamental AI Research-Gruppe bei Meta.
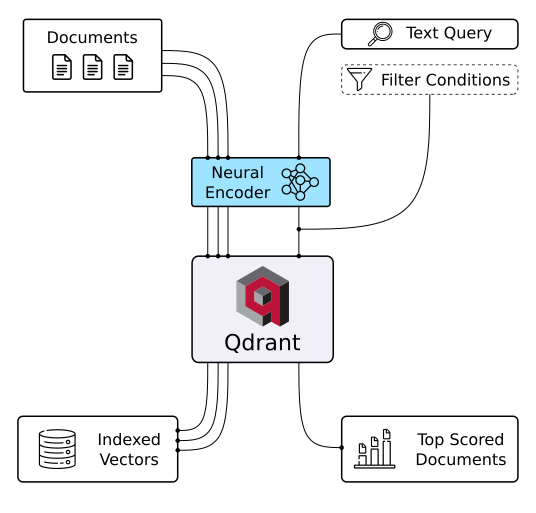
Qdrant-Vektordatenbank (Bildquelle)
Qdrant ist eine Vektordatenbank und ein Tool, um nach Ähnlichkeiten zwischen Vektoren zu suchen. Es läuft als API-Dienst und macht die Suche nach den ähnlichsten hochdimensionalen Vektoren möglich. Mit Qdrant kannst du Einbettungen oder neuronale Netzwerk-Encoder in umfassende Anwendungen für Aufgaben wie Abgleich, Suche, Empfehlungen und vieles mehr verwandeln. Hier sind ein paar wichtige Features von Qdrant:
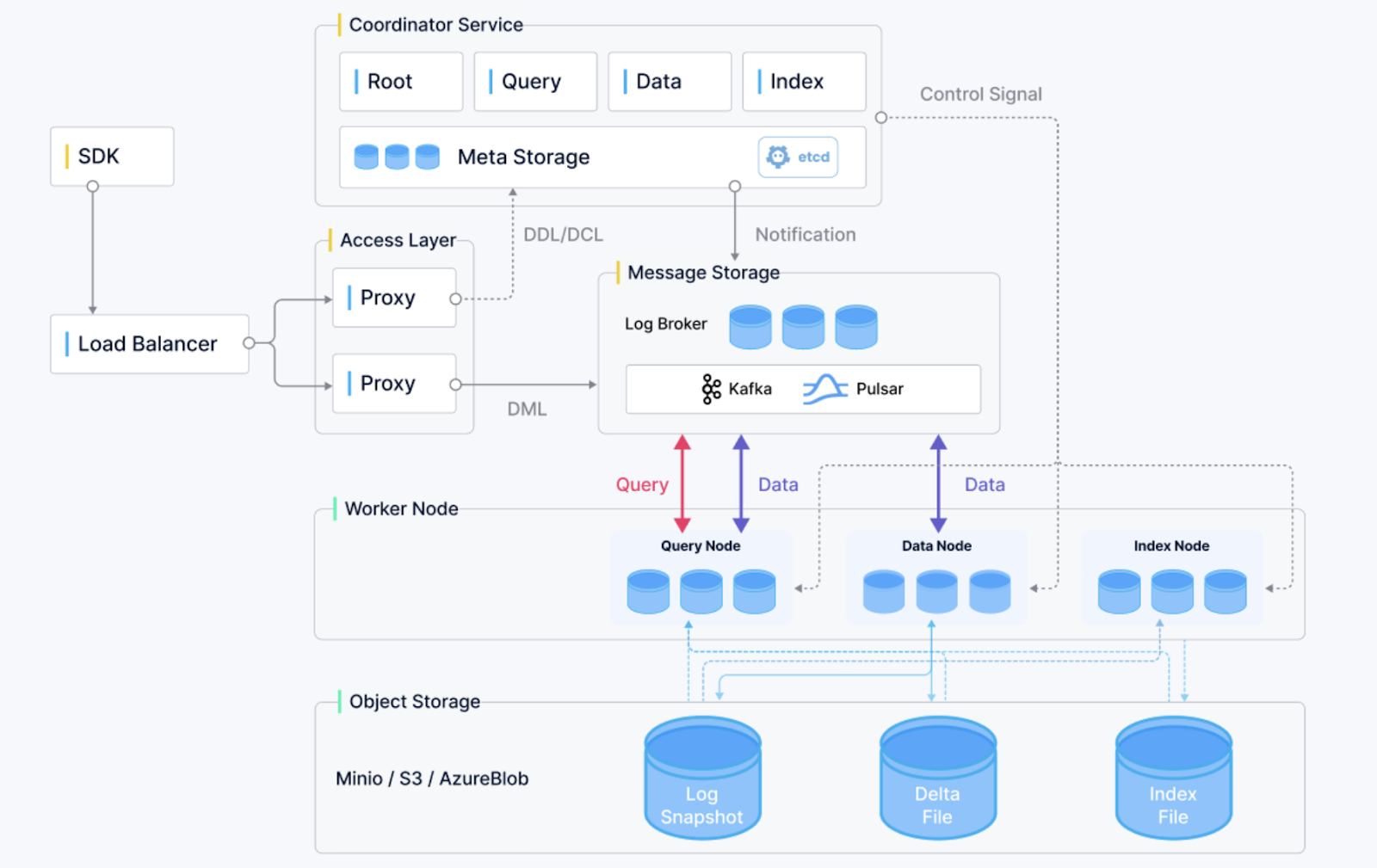
Milvus-Architektur im Überblick. (Bildquelle)
Milvus ist eine Open-Source-Vektordatenbank, die wegen ihrer Skalierbarkeit, Zuverlässigkeit und Leistung schnell an Beliebtheit gewonnen hat. Entwickelt für die Ähnlichkeitssuche und KI-gesteuerte Anwendungen, unterstützt es die Speicherung und Abfrage riesiger Einbettungsvektoren, die von tiefen neuronalen Netzen generiert werden. Milvus hat diese Funktionen:
Milvus ist super für Empfehlungssysteme, Videoanalysen und personalisierte Sucherlebnisse.
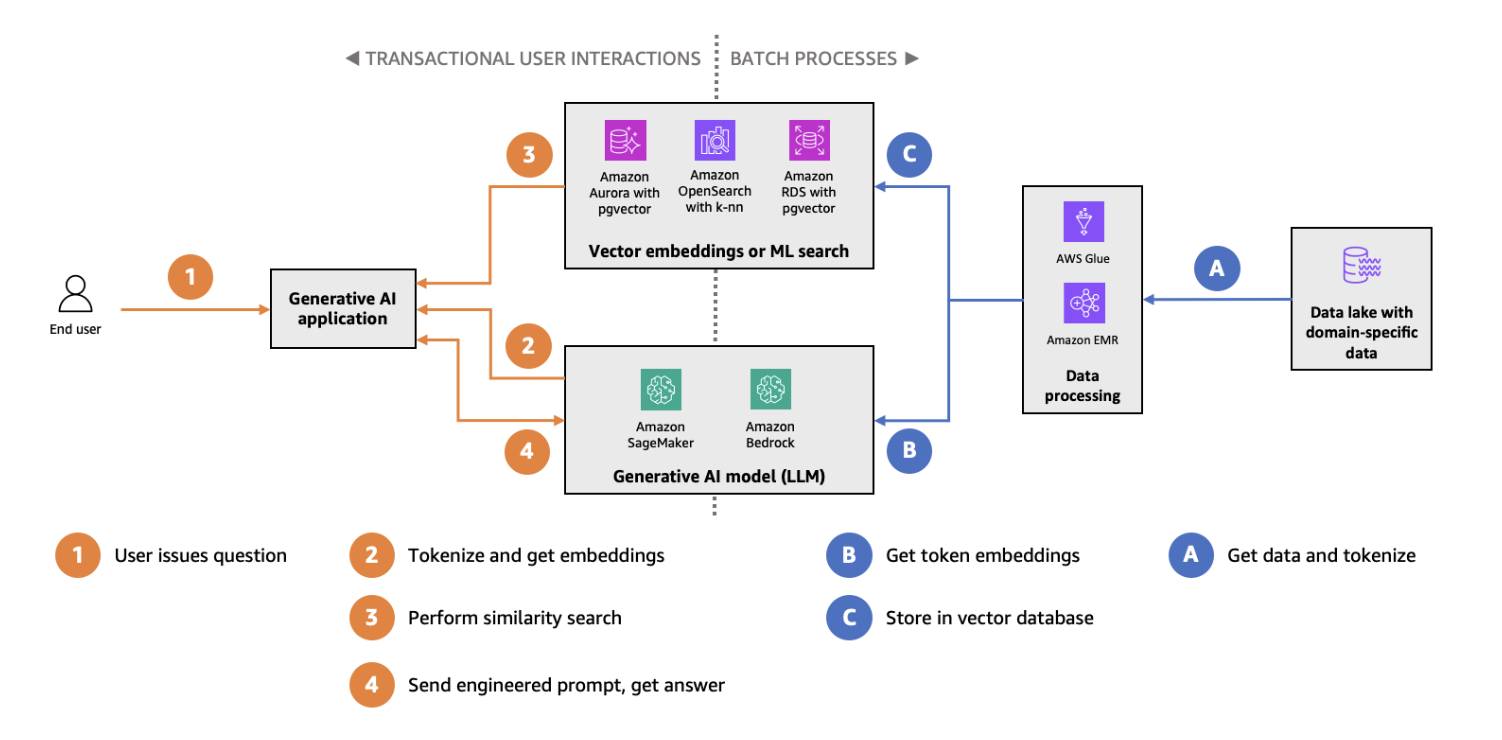
HNSW-Indizierung und -Suche mit pgvector auf Amazon Aurora – Architekturdiagramm. (Bildquelle)
pgvector ist eine Erweiterung für PostgreSQL, die Vektordaten-Typen und Funktionen für die Ähnlichkeitssuche in die weit verbreitete relationale Datenbank einführt. Durch die Integration der Vektorsuche in PostgreSQL bietet pgvector eine nahtlose Lösung für Teams, die schon traditionelle Datenbanken nutzen, aber Vektorsuchfunktionen hinzufügen wollen. Die wichtigsten Funktionen von pgvector sind:
pgvector passt super für kleinere Vektorsuchanwendungen oder Umgebungen, wo ein einziges Datenbanksystem sowohl für relationale als auch für vektorbasierte Aufgaben genutzt werden soll. Schau dir zuerst unser ausführliches Tutorial zu pgvector an.
Hier ist eine Tabelle, die die Funktionen der oben erwähnten Top-Vektordatenbanken zeigt:
| Feature | Chroma | Tannenzapfen | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Open Source | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Hauptanwendungsfall | Entwicklung von LLM-Apps | Verwaltete Vektordatenbank für ML | Skalierbare Vektorspeicherung und -suche | Schnelle Ähnlichkeitssuche und Clustering | Vektorähnlichkeitssuche | Hochleistungsfähige KI-Suche | Hinzufügen der Vektorsuche zu PostgreSQL |
| Integration | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, GPU-Ausführung | OpenAPI v3, Clients in verschiedenen Sprachen | TensorFlow, PyTorch, HuggingFace | Integriert in das PostgreSQL-Ökosystem |
| Skalierbarkeit | Skaliert von Python-Notebooks bis hin zu Clustern | Super skalierbar | Einfach auf Milliarden von Objekten skalierbar | Kann mit größeren Mengen als dem RAM umgehen | Cloud-nativ mit horizontaler Skalierung | Skaliert auf Milliarden von Vektoren | Kommt auf die PostgreSQL-Einrichtung an |
| Suchgeschwindigkeit | Schnelle Ähnlichkeitssuche | Suche mit geringer Latenz | Millisekunden für Millionen von Objekten | Schnell, unterstützt GPU | Benutzerdefinierter HNSW-Algorithmus für die schnelle Suche | Optimiert für Suche mit geringer Latenz | Ungefährer nächster Nachbar (ANN) |
| Datenschutz | Unterstützt mehrere Benutzer mit Datenisolierung | Komplett verwalteter Service | Legt Wert auf Sicherheit und Replikation | Hauptsächlich für Forschung und Entwicklung | Erweiterte Filterung von Vektor-Nutzlasten | Sichere Multi-Tenant-Architektur | Übernimmt die Sicherheit von PostgreSQL |
| Programmiersprache | Python, JavaScript | Python | Python, Java, Go, andere | C++, Python | Rost | C++, Python, Go | PostgreSQL-Erweiterung (SQL-basiert) |
Vektordatenbanken sind darauf spezialisiert, hochdimensionale Vektoren zu speichern, was schnelle und genaue Ähnlichkeitssuchen ermöglicht. Da KI-Modelle, vor allem im Bereich der natürlichen Sprachverarbeitung und des maschinellen Sehens, diese Vektoren erstellen und damit arbeiten, ist es super wichtig, effiziente Systeme zum Speichern und Abrufen zu haben. Hier kommen Vektordatenbanken ins Spiel, die eine super optimierte Umgebung für diese KI-gesteuerten Anwendungen bieten.
Ein super Beispiel für diese Verbindung zwischen KI und Vektordatenbanken sieht man bei der Entwicklung von großen Sprachmodellen (LLMs) wie GPT-3.
Diese Modelle sind dafür gemacht, menschenähnliche Texte zu verstehen und zu erzeugen, indem sie riesige Datenmengen verarbeiten und in hochdimensionale Vektoren umwandeln. Anwendungen wie „ “, die auf GPT und ähnlichen Modellen basieren, brauchen Vektordatenbanken, um diese Vektoren effizient zu verwalten und abzufragen. Der Grund dafür ist einfach die Menge und Komplexität der Daten, mit denen diese Modelle arbeiten. Wegen der vielen Parameter machen Modelle wie GPT-4 eine riesige Menge an vektorisierten Daten, was für normale Datenbanken echt schwierig sein kann, effizient zu verarbeiten. Das zeigt, wie wichtig spezielle Vektordatenbanken sind, die mit solchen hochdimensionalen Daten klarkommen.
Die sich ständig weiterentwickelnde Landschaft der künstlichen Intelligenz und des maschinellen Lernens zeigt, wie wichtig Vektordatenbanken in der heutigen datenzentrierten Welt sind. Diese Datenbanken, die super gut darin sind, mehrdimensionale Datenvektoren zu speichern, zu suchen und zu analysieren, sind echt wichtig für KI-gesteuerte Anwendungen, von Empfehlungssystemen bis hin zur Genomanalyse.
Wir haben in letzter Zeit eine beeindruckende Reihe von Vektordatenbanken gesehen, wie Chroma, Pinecone, Weaviate, Faiss und Qdrant, die alle ihre eigenen Funktionen und Innovationen haben. Da KI immer mehr auf dem Vormarsch ist, wird die Rolle von Vektordatenbanken bei der Gestaltung der Zukunft der Datenabfrage, -verarbeitung und -analyse sicher immer wichtiger werden und verspricht ausgefeiltere, effizientere und personalisierte Lösungen in verschiedenen Bereichen.
Lerne mit unserem Pinecone-Tutorial, wie man Vektordatenbanken richtig nutzt, oder melde dich für unseren Skill Track „Deep Learning in Python” an, um deine KI-Kenntnisse zu verbessern und über die neuesten Entwicklungen auf dem Laufenden zu bleiben.
Lerne mit diesen Kursen mehr über KI!
Kurs
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Matt Crabtree
14 Min.
Tutorial
Javier Canales Luna
Tutorial
Sejal Jaiswal
