
Kursus
Memahami Kecerdasan Buatan
2 Hr
409.4K
Basis data vektor adalah jenis basis data khusus yang menyimpan informasi dalam bentuk vektor multi-dimensi yang merepresentasikan karakteristik atau kualitas tertentu.
Jumlah dimensi dalam setiap vektor dapat sangat bervariasi, dari hanya beberapa hingga beberapa ribu, bergantung pada kerumitan dan detail data. Data ini, yang bisa berupa teks, gambar, audio, dan video, diubah menjadi vektor menggunakan berbagai proses seperti model pembelajaran mesin, word embeddings, atau teknik ekstraksi fitur.
Manfaat utama basis data vektor adalah kemampuannya untuk dengan cepat dan akurat menemukan serta mengambil data berdasarkan kedekatan atau kemiripan vektor. Ini memungkinkan pencarian yang berakar pada relevansi semantik atau kontekstual alih-alih hanya mengandalkan kecocokan persis atau kriteria tetap seperti pada basis data konvensional.
Sebagai contoh, dengan basis data vektor, Anda dapat:
Basis data tradisional menyimpan data sederhana seperti kata dan angka dalam format tabel. Basis data vektor, sebaliknya, bekerja dengan data kompleks yang disebut vektor dan menggunakan metode pencarian yang unik.
Sementara basis data biasa mencari kecocokan data yang tepat, basis data vektor mencari kecocokan terdekat menggunakan ukuran kesamaan tertentu.
Basis data vektor menggunakan teknik pencarian khusus yang dikenal sebagai Approximate Nearest Neighbor (ANN), yang mencakup metode seperti hashing dan pencarian berbasis graf.
Untuk benar-benar memahami cara kerja basis data vektor dan bagaimana perbedaannya dari basis data relasional tradisional seperti SQL, kita harus terlebih dahulu memahami konsep embedding.
Data tidak terstruktur, seperti teks, gambar, dan audio, tidak memiliki format yang telah ditentukan, sehingga menjadi tantangan bagi basis data tradisional. Untuk memanfaatkan data ini dalam aplikasi kecerdasan buatan dan pembelajaran mesin, data tersebut diubah menjadi representasi numerik menggunakan embedding.
Embedding ibarat memberikan setiap item, baik itu kata, gambar, atau yang lainnya, sebuah kode unik yang menangkap makna atau esensinya. Kode ini membantu komputer memahami dan membandingkan item-item tersebut dengan cara yang lebih efisien dan bermakna. Anggap saja seperti mengubah buku yang rumit menjadi ringkasan singkat yang tetap menangkap pokok-pokok pentingnya.
Proses embedding ini biasanya dilakukan menggunakan jenis jaringan saraf khusus yang dirancang untuk tugas tersebut. Misalnya, word embeddings mengubah kata-kata menjadi vektor sedemikian rupa sehingga kata-kata dengan makna serupa berada lebih dekat dalam ruang vektor.
Transformasi ini memungkinkan algoritme memahami hubungan dan kemiripan antar item.
Intinya, embedding berfungsi sebagai jembatan, mengubah data non-numerik menjadi bentuk yang dapat digunakan model pembelajaran mesin, sehingga memungkinkan mereka mengenali pola dan hubungan dalam data secara lebih efektif.
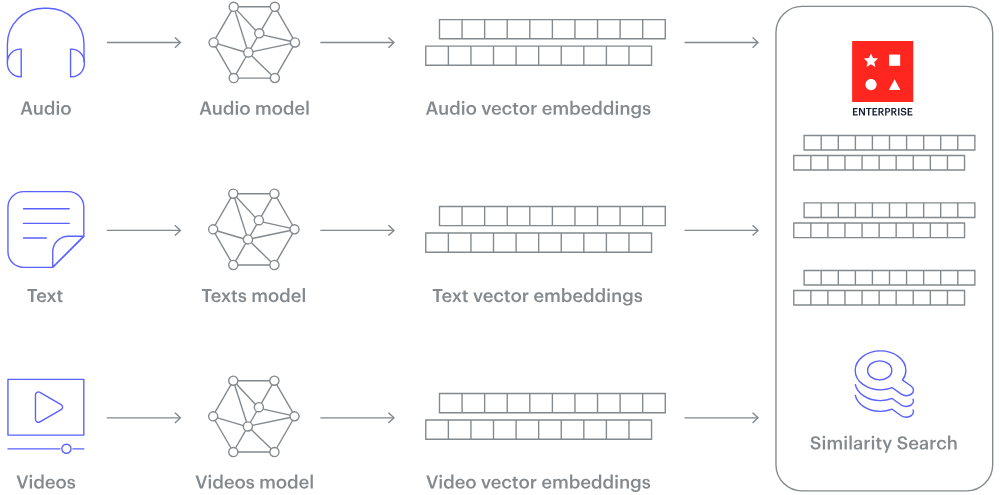
Bagaimana cara kerja basis data vektor? (Sumber gambar)
Basis data vektor, dengan kemampuannya yang unik, membangun peran di berbagai industri karena efisiensinya dalam menerapkan "pencarian kemiripan". Berikut ulasan lebih dalam tentang beragam penerapannya:
Di sektor ritel yang dinamis, basis data vektor mengubah cara konsumen berbelanja. Mereka memungkinkan pembuatan sistem rekomendasi canggih, yang menyajikan pengalaman belanja personal. Misalnya, seorang pembelanja online dapat menerima saran produk bukan hanya berdasarkan pembelian sebelumnya, tetapi juga dengan menganalisis kemiripan atribut produk, perilaku pengguna, dan preferensi.
Sektor keuangan dipenuhi pola dan tren yang rumit. Basis data vektor unggul dalam menganalisis data padat ini, membantu analis keuangan mendeteksi pola yang krusial bagi strategi investasi. Dengan mengenali kemiripan halus atau penyimpangan, mereka dapat memprediksi pergerakan pasar dan menyusun rencana investasi yang lebih terinformasi.
Dalam bidang kesehatan, personalisasi adalah yang utama. Dengan menganalisis urutan genom, basis data vektor memungkinkan pengobatan yang lebih terarah, memastikan solusi medis selaras lebih dekat dengan susunan genetik individu.
Dunia digital menyaksikan lonjakan chatbot dan asisten virtual. Entitas bertenaga AI ini sangat bergantung pada pemahaman bahasa manusia. Dengan mengubah data teks yang sangat besar menjadi vektor, sistem ini dapat lebih akurat memahami dan merespons pertanyaan manusia. Sebagai contoh, perusahaan seperti Talkmap memanfaatkan pemahaman bahasa alami secara real-time, sehingga interaksi pelanggan-agen menjadi lebih lancar.
Dari pemindaian medis hingga rekaman pengawasan, kemampuan membandingkan dan memahami gambar secara akurat sangatlah penting. Basis data vektor menyederhanakannya dengan berfokus pada fitur-fitur penting dari gambar, menyaring noise dan distorsi. Misalnya, dalam manajemen lalu lintas, gambar dari tayangan video dapat dianalisis dengan cepat untuk mengoptimalkan arus lalu lintas dan meningkatkan keamanan publik.
Mendeteksi outlier sama pentingnya dengan mengenali kemiripan. Terutama di sektor seperti keuangan dan keamanan, mendeteksi anomali bisa berarti mencegah penipuan atau mengantisipasi potensi pelanggaran keamanan. Basis data vektor menawarkan kemampuan yang lebih baik di ranah ini, membuat proses deteksi lebih cepat dan lebih presisi.
Basis data vektor telah muncul sebagai alat yang kuat untuk menavigasi hamparan data tidak terstruktur, seperti gambar, video, dan teks, tanpa terlalu bergantung pada label atau tag buatan manusia. Kemampuannya, saat terintegrasi dengan model pembelajaran mesin tingkat lanjut, berpotensi merevolusi banyak sektor, dari e-niaga hingga farmasi. Berikut beberapa fitur menonjol yang menjadikan basis data vektor sebagai pengubah permainan:
Basis data vektor yang tangguh memastikan bahwa seiring pertumbuhan data — mencapai jutaan bahkan miliaran elemen — sistem dapat ditingkatkan dengan mudah di berbagai node. Basis data vektor terbaik menawarkan adaptabilitas, memungkinkan pengguna menyetel sistem berdasarkan variasi tingkat penyisipan, tingkat kueri, dan perangkat keras yang mendasari.
Mengakomodasi banyak pengguna adalah ekspektasi standar untuk basis data. Namun, sekadar membuat basis data vektor baru untuk setiap pengguna tidaklah efisien. Basis data vektor memprioritaskan isolasi data, memastikan perubahan yang dibuat pada satu koleksi data tidak terlihat oleh yang lain kecuali sengaja dibagikan oleh pemiliknya. Ini tidak hanya mendukung multi-penyewa, tetapi juga memastikan privasi dan keamanan data.
Basis data yang andal dan efektif menawarkan satu set API dan SDK yang lengkap. Ini memastikan sistem dapat berinteraksi dengan berbagai aplikasi dan dapat dikelola secara efektif. Basis data vektor terkemuka, seperti Pinecone, menyediakan SDK dalam berbagai bahasa pemrograman seperti Python, Node, Go, dan Java, memastikan fleksibilitas dalam pengembangan dan pengelolaan.
Untuk mengurangi kurva pembelajaran yang terjal terkait teknologi baru, antarmuka yang ramah pengguna pada basis data vektor memainkan peran penting. Antarmuka ini menawarkan tampilan visual, navigasi yang mudah, dan akses ke fitur-fitur yang mungkin sebaliknya tersembunyi.
Daftar ini tidak berurutan — masing-masing menampilkan banyak kualitas yang diuraikan pada bagian di atas.
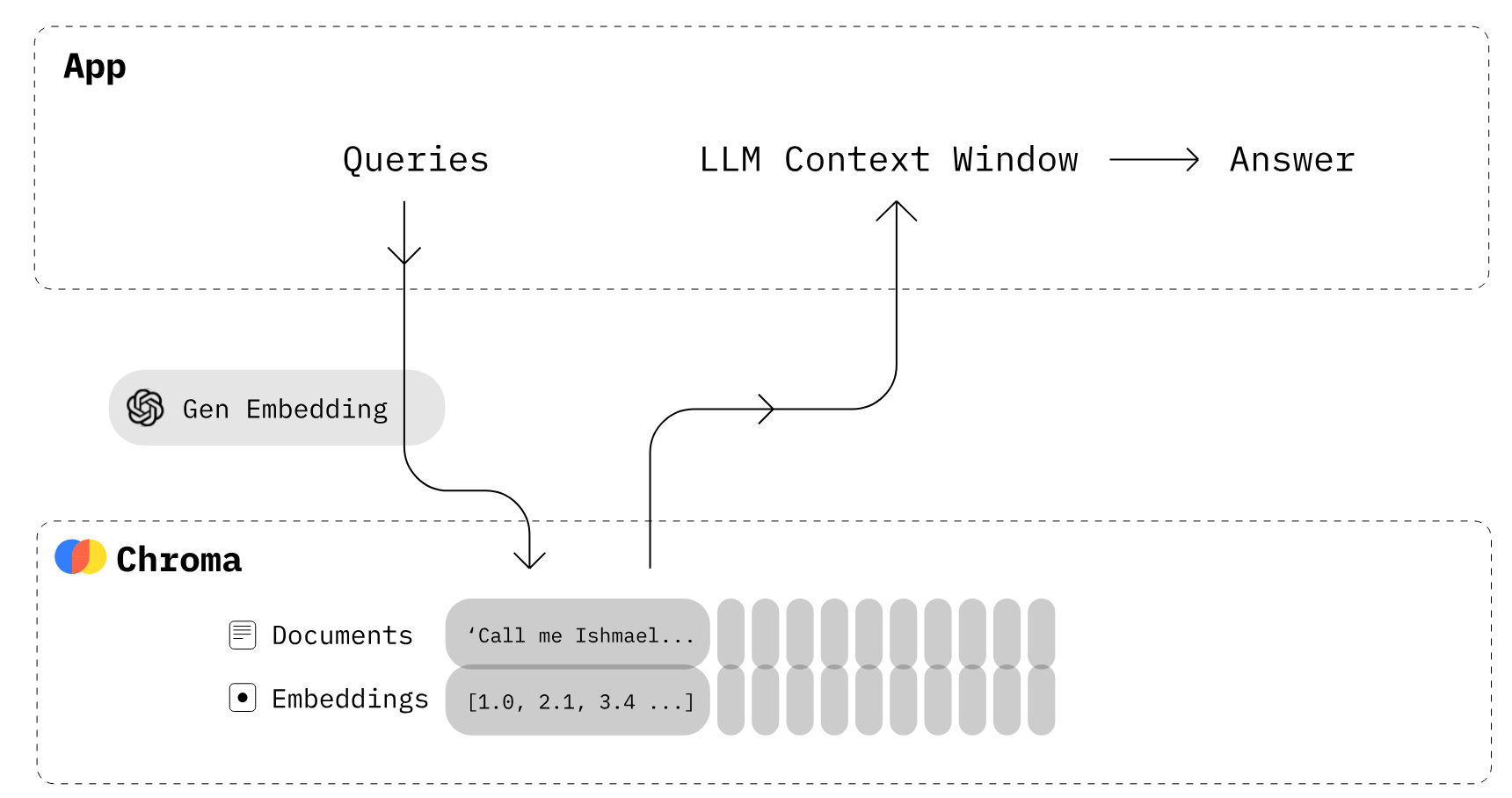
Membangun Aplikasi LLM menggunakan ChromaDB (Sumber gambar)
Chroma adalah basis data embedding open-source. Chroma memudahkan pembuatan aplikasi LLM dengan membuat pengetahuan, fakta, dan keterampilan dapat dipasang ke LLM. Seperti yang kami bahas dalam tutorial Chroma DB, Anda dapat dengan mudah mengelola dokumen teks, mengonversi teks menjadi embedding, dan melakukan pencarian kemiripan.
Fitur ChromaDB:

Basis data vektor Pinecone (Sumber gambar)
Pinecone adalah platform basis data vektor terkelola yang dibangun khusus untuk mengatasi tantangan unik terkait data berdimensi tinggi. Dilengkapi kemampuan pengindeksan dan pencarian mutakhir, Pinecone memberdayakan engineer data dan data scientist untuk membangun dan menerapkan aplikasi pembelajaran mesin skala besar yang secara efektif memproses dan menganalisis data berdimensi tinggi.
Fitur utama Pinecone meliputi:
Perlu dicatat, Pinecone adalah satu-satunya basis data vektor yang masuk dalam daftar perdana Fortune 2023 50 AI Innovator.
Untuk mempelajari lebih lanjut tentang Pinecone, lihat tutorial Menguasai Basis Data Vektor dengan Pinecone.
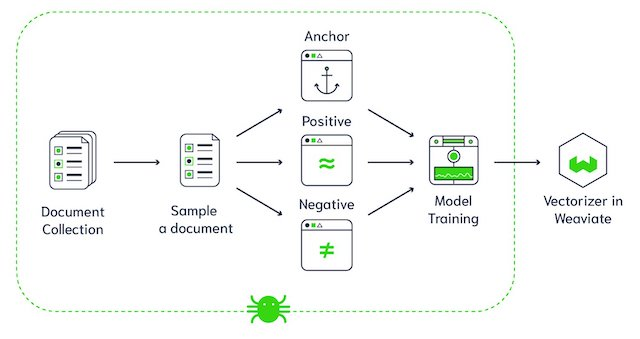
Arsitektur basis data vektor Weaviate (Sumber gambar)
Weaviate adalah basis data vektor open-source. Ini memungkinkan Anda menyimpan objek data dan embedding vektor dari model ML favorit Anda dan menskalakan secara mulus hingga miliaran objek data. Beberapa fitur kunci Weaviate adalah:

Faiss adalah pustaka open-source untuk pencarian vektor yang dibuat oleh Facebook (Sumber gambar)
Faiss adalah pustaka open-source untuk pencarian kemiripan yang cepat dan pengelompokan vektor padat. Ia memiliki algoritme yang mampu mencari dalam himpunan vektor dengan berbagai ukuran, bahkan yang mungkin melampaui kapasitas RAM. Selain itu, Faiss menawarkan kode pendukung untuk penilaian dan penyetelan parameter.
Meskipun terutama ditulis dalam C++, ia sepenuhnya mendukung integrasi Python/NumPy. Beberapa algoritme kuncinya juga tersedia untuk eksekusi GPU. Pengembangan utama Faiss dilakukan oleh kelompok Fundamental AI Research di Meta.
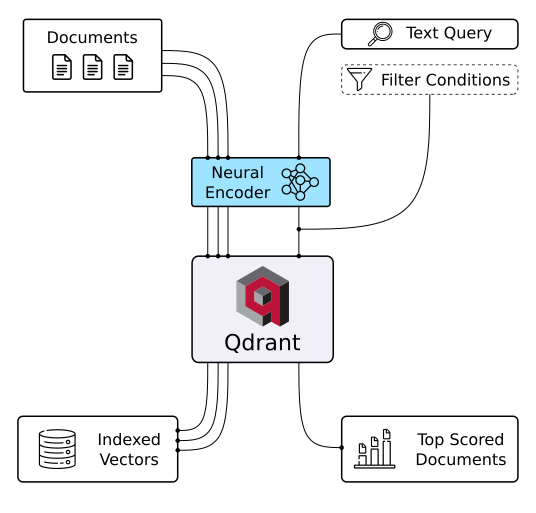
Basis data vektor Qdrant (Sumber gambar)
Qdrant adalah basis data vektor dan alat untuk melakukan pencarian kemiripan vektor. Ia beroperasi sebagai layanan API, yang memungkinkan pencarian vektor berdimensi tinggi terdekat. Dengan Qdrant, Anda dapat mengubah embedding atau encoder jaringan saraf menjadi aplikasi menyeluruh untuk tugas seperti pencocokan, pencarian, rekomendasi, dan banyak lagi. Berikut beberapa fitur kunci Qdrant:
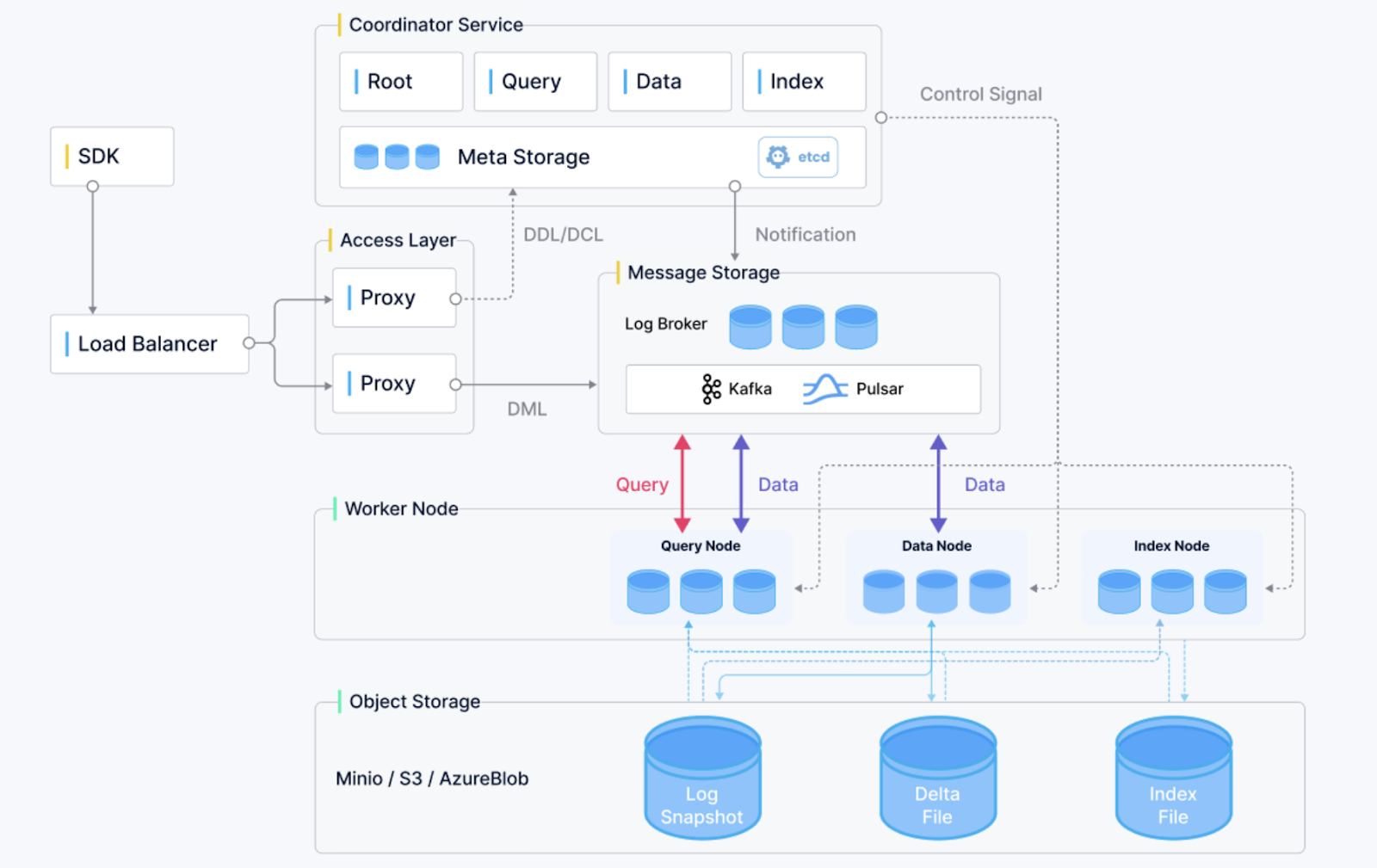
Gambaran arsitektur Milvus. (Sumber gambar)
Milvus adalah basis data vektor open-source yang dengan cepat mendapatkan perhatian karena skalabilitas, keandalan, dan kinerjanya. Dirancang untuk pencarian kemiripan dan aplikasi berbasis AI, ia mendukung penyimpanan dan kueri embedding vektor masif yang dihasilkan oleh jaringan saraf dalam. Milvus menawarkan fitur berikut:
Milvus ideal untuk aplikasi dalam sistem rekomendasi, analisis video, dan pengalaman pencarian yang dipersonalisasi.
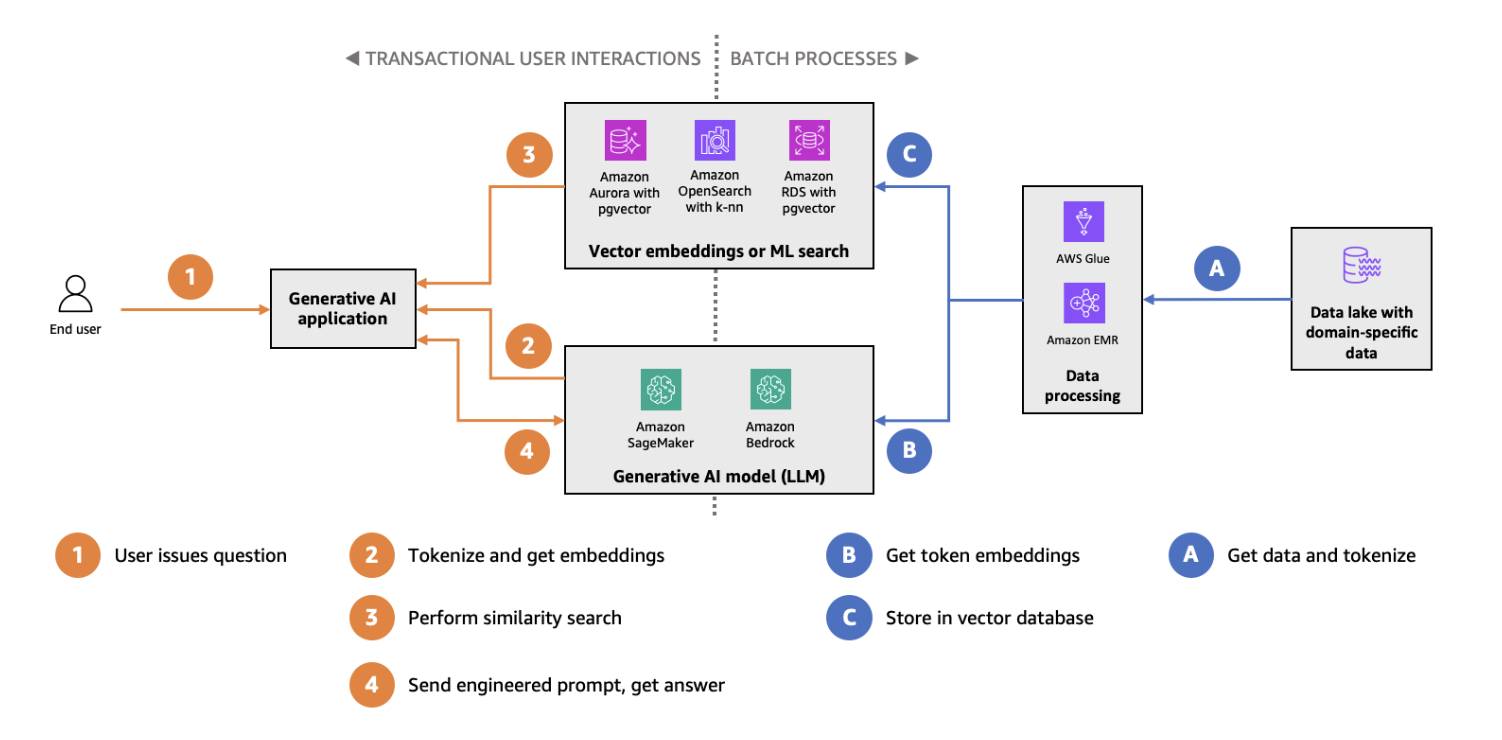
Pengindeksan dan pencarian HNSW dengan pgvector pada diagram arsitektur Amazon Aurora. (Sumber gambar)
pgvector adalah ekstensi untuk PostgreSQL yang menghadirkan tipe data vektor dan kemampuan pencarian kemiripan ke basis data relasional yang banyak digunakan tersebut. Dengan mengintegrasikan pencarian vektor ke dalam PostgreSQL, pgvector menawarkan solusi tanpa hambatan bagi tim yang sudah menggunakan basis data tradisional namun ingin menambahkan kemampuan pencarian vektor. Fitur utama pgvector meliputi:
pgvector sangat cocok untuk kasus penggunaan pencarian vektor skala lebih kecil atau lingkungan yang lebih memilih satu sistem basis data untuk beban kerja relasional dan berbasis vektor. Untuk memulai, lihat tutorial pgvector kami yang terperinci.
Di bawah ini adalah tabel perbandingan yang menyoroti fitur-fitur basis data vektor teratas yang telah dibahas sebelumnya:
| Fitur | Chroma | Pinecone | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Sumber terbuka | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Kasus Penggunaan Utama | Pengembangan Aplikasi LLM | Basis Data Vektor Terkelola untuk ML | Penyimpanan dan Pencarian Vektor yang Skalabel | Pencarian Kemiripan dan Klastering Berkecepatan Tinggi | Pencarian Kemiripan Vektor | Pencarian AI Berkinerja Tinggi | Menambahkan Pencarian Vektor ke PostgreSQL |
| Integrasi | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, Eksekusi GPU | OpenAPI v3, Berbagai Klien Bahasa | TensorFlow, PyTorch, HuggingFace | Terintegrasi dalam ekosistem PostgreSQL |
| Skalabilitas | Menskalakan dari notebook Python ke kluster | Sangat skalabel | Skalabilitas mulus hingga miliaran objek | Mampu menangani himpunan yang lebih besar dari RAM | Cloud-native dengan penskalaan horizontal | Menskalakan hingga miliaran vektor | Bergantung pada penyiapan PostgreSQL |
| Kecepatan Pencarian | Pencarian kemiripan yang cepat | Pencarian berlatensi rendah | Beberapa milidetik untuk jutaan objek | Cepat, mendukung GPU | Algoritme HNSW khusus untuk pencarian cepat | Dioptimalkan untuk pencarian berlatensi rendah | Approximate Nearest Neighbor (ANN) |
| Privasi Data | Mendukung multi-pengguna dengan isolasi data | Layanan sepenuhnya terkelola | Menekankan keamanan dan replikasi | Utamanya untuk riset dan pengembangan | Pemfilteran lanjutan pada payload vektor | Arsitektur multi-penyewa yang aman | Mewarisi keamanan PostgreSQL |
| Bahasa Pemrograman | Python, JavaScript | Python | Python, Java, Go, lainnya | C++, Python | Rust | C++, Python, Go | Ekstensi PostgreSQL (berbasis SQL) |
Basis data vektor mengkhususkan diri dalam menyimpan vektor berdimensi tinggi, memungkinkan pencarian kemiripan yang cepat dan akurat. Seiring model AI, khususnya di bidang pemrosesan bahasa alami dan visi komputer, menghasilkan dan bekerja dengan vektor-vektor ini, kebutuhan akan sistem penyimpanan dan pengambilan yang efisien menjadi sangat penting. Di sinilah basis data vektor berperan, menyediakan lingkungan yang sangat dioptimalkan untuk aplikasi berbasis AI ini.
Contoh utama hubungan antara AI dan basis data vektor terlihat pada kemunculan Model Bahasa Besar (LLM) seperti GPT-3.
Model-model ini dirancang untuk memahami dan menghasilkan teks yang mirip manusia dengan memproses sejumlah besar data, mengubahnya menjadi vektor berdimensi tinggi. Aplikasi yang dibangun di atas GPT dan model serupa sangat bergantung pada basis data vektor untuk mengelola dan mengkueri vektor-vektor ini secara efisien. Alasan ketergantungan ini terletak pada besarnya volume dan kompleksitas data yang ditangani model-model tersebut. Mengingat peningkatan parameter yang substansial, model seperti GPT-4 menghasilkan sejumlah besar data tervektorisasi, yang dapat menjadi tantangan bagi basis data konvensional untuk diproses secara efisien. Hal ini menegaskan pentingnya basis data vektor khusus yang mampu menangani data berdimensi tinggi seperti itu.
Lanskap kecerdasan buatan dan pembelajaran mesin yang terus berkembang menegaskan betapa tak tergantikannya basis data vektor di dunia yang berpusat pada data saat ini. Basis data ini, dengan kemampuannya yang unik untuk menyimpan, mencari, dan menganalisis vektor data multi-dimensi, terbukti penting dalam mendukung aplikasi berbasis AI, dari sistem rekomendasi hingga analisis genomik.
Belakangan ini kita melihat beragam basis data vektor yang mengesankan, seperti Chroma, Pinecone, Weaviate, Faiss, dan Qdrant, masing-masing menawarkan kemampuan dan inovasi yang berbeda. Seiring AI terus berkembang, peran basis data vektor dalam membentuk masa depan pengambilan, pemrosesan, dan analisis data pasti akan semakin besar, menjanjikan solusi yang lebih canggih, efisien, dan personal di berbagai sektor.
Pelajari cara menguasai basis data vektor dengan tutorial Pinecone kami, atau daftar ke jalur keterampilan Deep Learning in Python untuk meningkatkan keterampilan AI Anda dan tetap mengikuti perkembangan terbaru.
Pelajari lebih lanjut tentang AI dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
