
Corso
Comprendere l'intelligenza artificiale
2 h
409.4K
Un database vettoriale è un tipo specifico di database che salva le informazioni sotto forma di vettori multidimensionali che rappresentano determinate caratteristiche o qualità.
Il numero di dimensioni di ciascun vettore può variare ampiamente, da poche fino a diverse migliaia, in base alla complessità e al livello di dettaglio dei dati. Questi dati, che possono includere testo, immagini, audio e video, vengono trasformati in vettori tramite vari processi come modelli di machine learning, word embedding o tecniche di estrazione di caratteristiche.
Il principale vantaggio di un database vettoriale è la capacità di individuare e recuperare rapidamente e con precisione i dati in base alla loro prossimità o somiglianza vettoriale. Questo consente ricerche basate sulla rilevanza semantica o contestuale, invece di affidarsi esclusivamente a corrispondenze esatte o criteri fissi come nei database convenzionali.
Per esempio, con un database vettoriale puoi:
I database tradizionali archiviano dati semplici come parole e numeri in formato tabellare. I database vettoriali, invece, lavorano con dati complessi chiamati vettori e utilizzano metodi unici per la ricerca.
Mentre i database classici cercano corrispondenze esatte, i database vettoriali cercano la corrispondenza più vicina utilizzando specifiche misure di similarità.
I database vettoriali impiegano tecniche di ricerca speciali note come Approximate Nearest Neighbor (ANN), che includono metodi come hashing e ricerche basate su grafi.
Per capire davvero come funziona un database vettoriale e in cosa differisce dai database relazionali tradizionali come SQL, dobbiamo prima comprendere il concetto di embedding.
I dati non strutturati, come testo, immagini e audio, non hanno un formato predefinito e pongono sfide per i database tradizionali. Per sfruttare questi dati nelle applicazioni di intelligenza artificiale e machine learning, vengono trasformati in rappresentazioni numeriche usando gli embedding.
L'embedding è come assegnare a ogni elemento, che sia una parola, un'immagine o altro, un codice unico che ne cattura il significato o l'essenza. Questo codice aiuta i computer a comprendere e confrontare questi elementi in modo più efficiente e significativo. Pensalo come trasformare un libro complicato in un breve riassunto che ne mantiene i punti principali.
Questo processo di embedding viene in genere realizzato usando una particolare tipologia di rete neurale progettata per il compito. Per esempio, i word embedding convertono le parole in vettori in modo tale che le parole con significati simili risultino più vicine nello spazio vettoriale.
Questa trasformazione consente agli algoritmi di comprendere relazioni e somiglianze tra gli elementi.
In sostanza, gli embedding fungono da ponte, convertendo i dati non numerici in una forma con cui i modelli di machine learning possono lavorare, permettendo loro di individuare pattern e relazioni nei dati in modo più efficace.
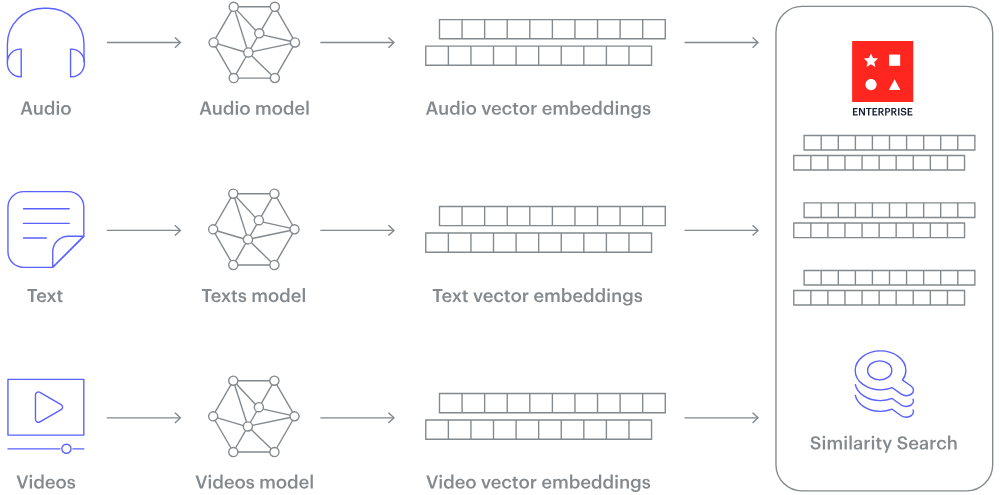
Come funziona un database vettoriale? (Fonte immagine)
I database vettoriali, grazie alle loro capacità uniche, stanno trovando spazio in numerosi settori per l'efficienza nell'implementare la "similarity search". Ecco un approfondimento delle loro applicazioni:
Nel vivace settore retail, i database vettoriali stanno ridefinendo il modo in cui i consumatori fanno acquisti. Consentono di creare sistemi di raccomandazione avanzati, curando esperienze di shopping personalizzate. Per esempio, a un acquirente online possono essere suggeriti prodotti non solo in base agli acquisti passati, ma anche analizzando le somiglianze negli attributi dei prodotti, nel comportamento dell'utente e nelle preferenze.
Il settore finanziario pullula di pattern e trend complessi. I database vettoriali eccellono nell'analisi di questi dati densi, aiutando gli analisti finanziari a rilevare pattern cruciali per le strategie di investimento. Riconoscendo somiglianze o deviazioni sottili, possono prevedere i movimenti del mercato ed elaborare piani di investimento più informati.
Nel campo della sanità, la personalizzazione è fondamentale. Analizzando le sequenze genomiche, i database vettoriali consentono trattamenti medici più su misura, assicurando che le soluzioni siano più allineate al profilo genetico individuale.
Il mondo digitale sta assistendo a un boom di chatbot e assistenti virtuali. Queste entità guidate dall'IA si basano fortemente sulla comprensione del linguaggio umano. Convertendo vasti testi in vettori, questi sistemi possono comprendere e rispondere alle domande con maggiore precisione. Per esempio, aziende come Talkmap utilizzano la comprensione del linguaggio naturale in tempo reale, consentendo interazioni più fluide tra clienti e operatori.
Dalle scansioni mediche ai filmati di sorveglianza, la capacità di confrontare e comprendere accuratamente le immagini è cruciale. I database vettoriali semplificano questo processo concentrandosi sulle caratteristiche essenziali delle immagini, filtrando rumori e distorsioni. Per esempio, nella gestione del traffico, le immagini dai flussi video possono essere analizzate rapidamente per ottimizzare i flussi e migliorare la sicurezza pubblica.
Individuare i valori anomali è tanto essenziale quanto riconoscere le somiglianze. In particolare in settori come finanza e sicurezza, rilevare anomalie può significare prevenire frodi o anticipare possibili violazioni. I database vettoriali offrono capacità avanzate in questo ambito, rendendo il processo di rilevamento più rapido e preciso.
I database vettoriali sono emersi come strumenti potenti per orientarsi nell'immenso territorio dei dati non strutturati, come immagini, video e testi, senza fare forte affidamento su etichette o tag generati dall'uomo. Le loro capacità, quando integrate con modelli di machine learning avanzati, hanno il potenziale di rivoluzionare numerosi settori, dall'e-commerce alla farmaceutica. Ecco alcune caratteristiche distintive che rendono i database vettoriali un punto di svolta:
Un database vettoriale solido assicura che, man mano che i dati crescono - arrivando a milioni o persino miliardi di elementi - possa scalare senza sforzo su più nodi. I migliori database vettoriali offrono adattabilità, consentendo agli utenti di configurare il sistema in base alle variazioni nel tasso di inserimento, nel tasso di query e nell'hardware sottostante.
Accogliere più utenti è un'aspettativa standard per i database. Tuttavia, creare un nuovo database vettoriale per ogni utente non è efficiente. I database vettoriali danno priorità all'isolamento dei dati, garantendo che qualsiasi modifica apportata a una raccolta rimanga invisibile agli altri, a meno che il proprietario non la condivida intenzionalmente. Questo non solo supporta la multi-tenancy, ma assicura anche la privacy e la sicurezza dei dati.
Un database autentico ed efficace offre un set completo di API e SDK. Ciò garantisce che il sistema possa interagire con applicazioni diverse e possa essere gestito in modo efficace. I principali database vettoriali, come Pinecone, forniscono SDK in vari linguaggi di programmazione come Python, Node, Go e Java, assicurando flessibilità nello sviluppo e nella gestione.
Riducendo la ripida curva di apprendimento associata alle nuove tecnologie, le interfacce intuitive nei database vettoriali svolgono un ruolo fondamentale. Offrono una panoramica visiva, una navigazione semplice e l'accesso a funzionalità che altrimenti potrebbero rimanere nascoste.
L'elenco non segue un ordine particolare: ognuno mostra molte delle qualità descritte nella sezione precedente.
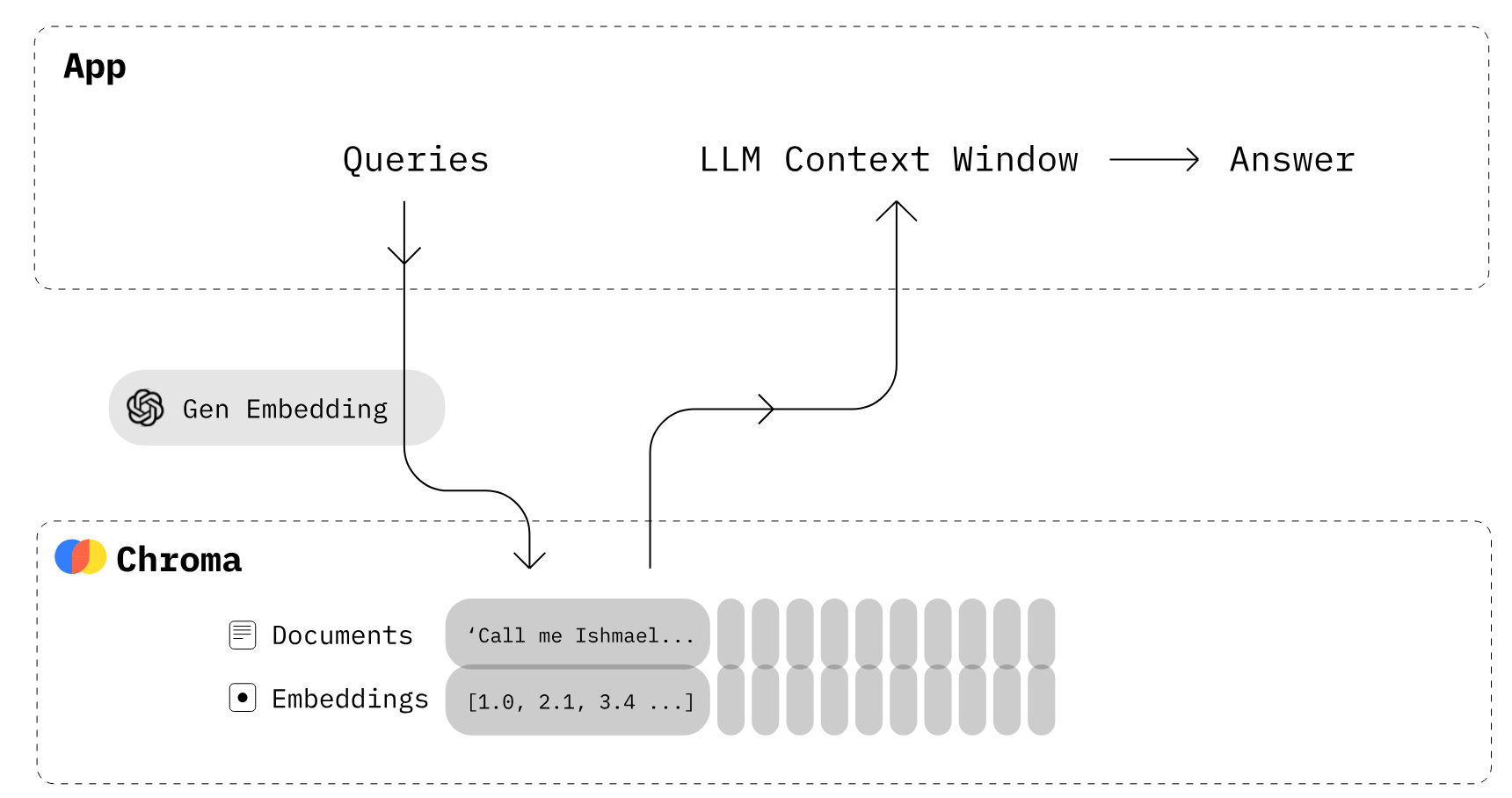
Creare app LLM con ChromaDB (Fonte immagine)
Chroma è un database di embedding open source. Chroma rende semplice creare app LLM rendendo conoscenze, fatti e competenze inseribili nei LLM. Come esploriamo nel nostro tutorial su Chroma DB, puoi gestire facilmente documenti di testo, convertire testo in embedding ed eseguire ricerche per similarità.
Funzionalità di ChromaDB:

Database vettoriale Pinecone (Fonte immagine)
Pinecone è una piattaforma di database vettoriale gestita, progettata appositamente per affrontare le sfide uniche dei dati ad alta dimensionalità. Dotato di funzionalità all'avanguardia per indicizzazione e ricerca, Pinecone consente a data engineer e data scientist di costruire e implementare applicazioni di machine learning su larga scala che elaborano e analizzano efficacemente dati ad alta dimensionalità.
Le caratteristiche principali di Pinecone includono:
Vale la pena notare che Pinecone è stato l'unico database vettoriale incluso nella lista inaugurale Fortune 2023 50 AI Innovator.
Per saperne di più su Pinecone, dai un'occhiata al tutorial Mastering Vector Databases with Pinecone.
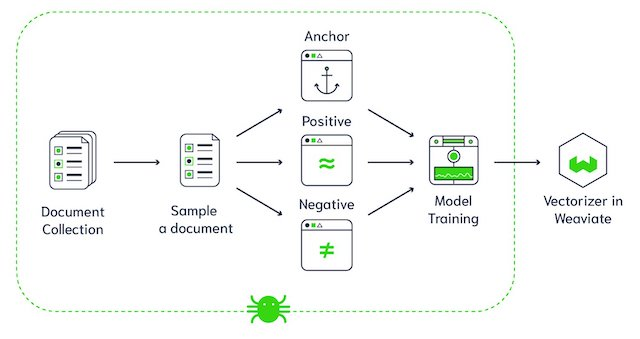
Architettura del database vettoriale Weaviate (Fonte immagine)
Weaviate è un database vettoriale open source. Ti permette di archiviare oggetti dati ed embedding vettoriali dai tuoi modelli di ML preferiti e di scalare senza soluzione di continuità fino a miliardi di oggetti. Alcune caratteristiche chiave di Weaviate sono:

Faiss è una libreria open source per la ricerca vettoriale creata da Facebook (Fonte immagine)
Faiss è una libreria open source per la ricerca rapida delle somiglianze e il clustering di vettori densi. Contiene algoritmi in grado di cercare all'interno di insiemi vettoriali di dimensioni variabili, persino quelli che potrebbero superare la capacità della RAM. Inoltre, Faiss offre codice ausiliario per la valutazione e la regolazione dei parametri.
Sebbene sia principalmente scritta in C++, supporta pienamente l'integrazione con Python/NumPy. Alcuni dei suoi algoritmi principali sono disponibili anche per l'esecuzione su GPU. Lo sviluppo principale di Faiss è curato dal gruppo Fundamental AI Research di Meta.
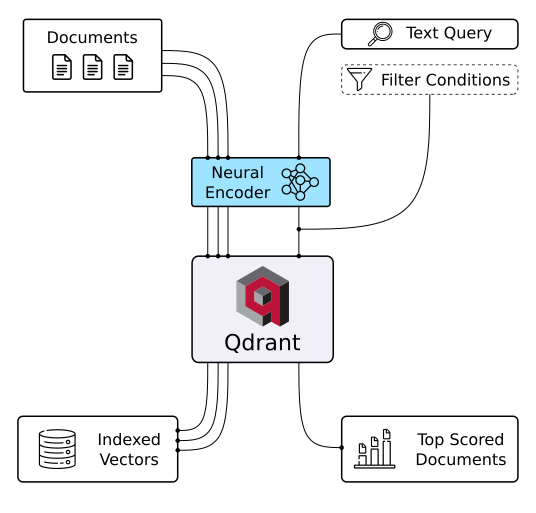
Database vettoriale Qdrant (Fonte immagine)
Qdrant è un database vettoriale e uno strumento per eseguire ricerche di similarità tra vettori. Funziona come servizio API, consentendo ricerche dei vettori ad alta dimensionalità più vicini. Con Qdrant, puoi trasformare embedding o encoder di reti neurali in applicazioni complete per attività come matching, ricerca, raccomandazioni e molto altro. Ecco alcune funzionalità chiave di Qdrant:
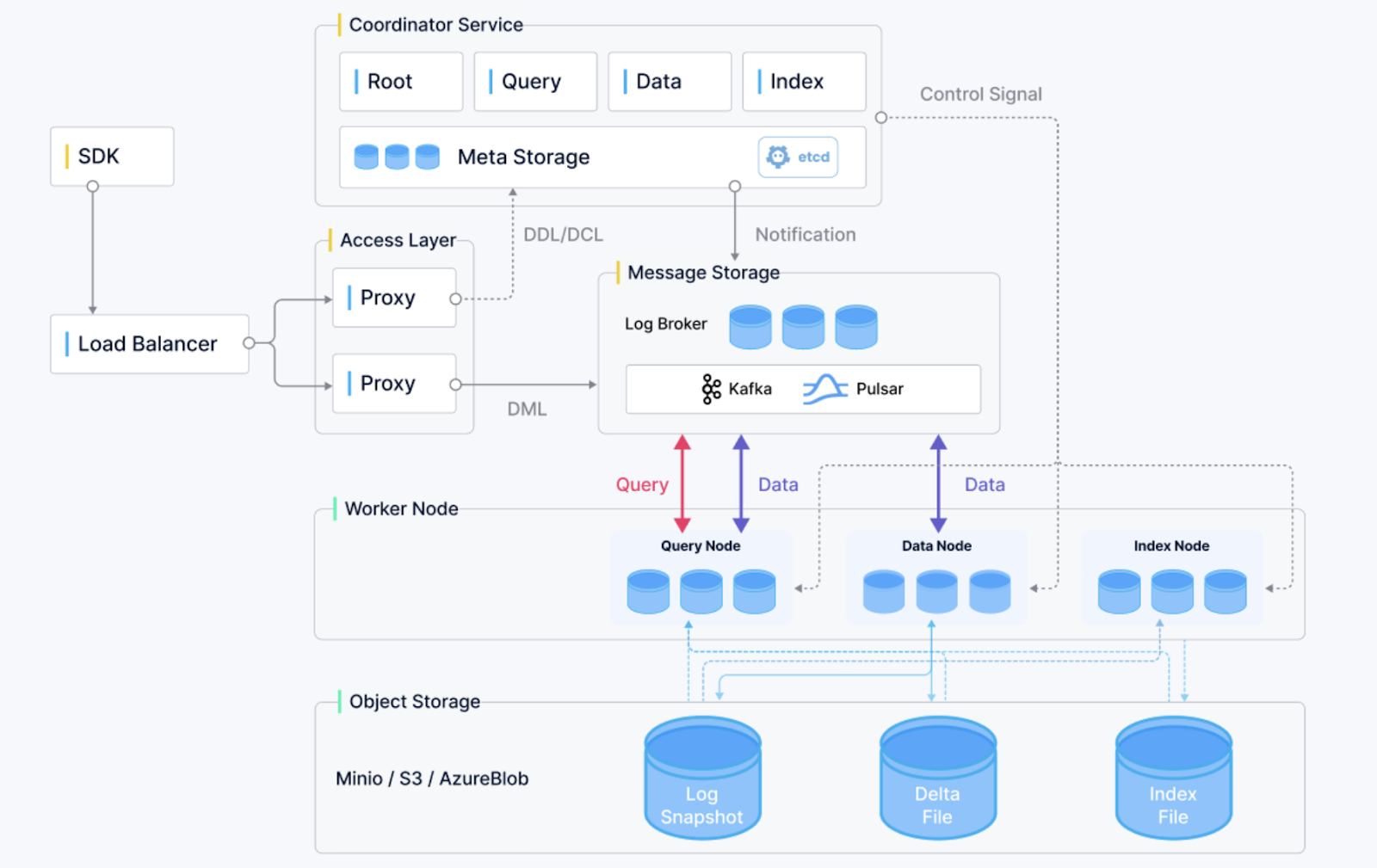
Panoramica dell'architettura di Milvus. (Fonte immagine)
Milvus è un database vettoriale open source che ha rapidamente guadagnato terreno per scalabilità, affidabilità e prestazioni. Progettato per la ricerca per similarità e applicazioni guidate dall'IA, supporta l'archiviazione e l'interrogazione di enormi vettori di embedding generati da reti neurali profonde. Milvus offre le seguenti funzionalità:
Milvus è ideale per applicazioni in sistemi di raccomandazione, analisi video ed esperienze di ricerca personalizzate.
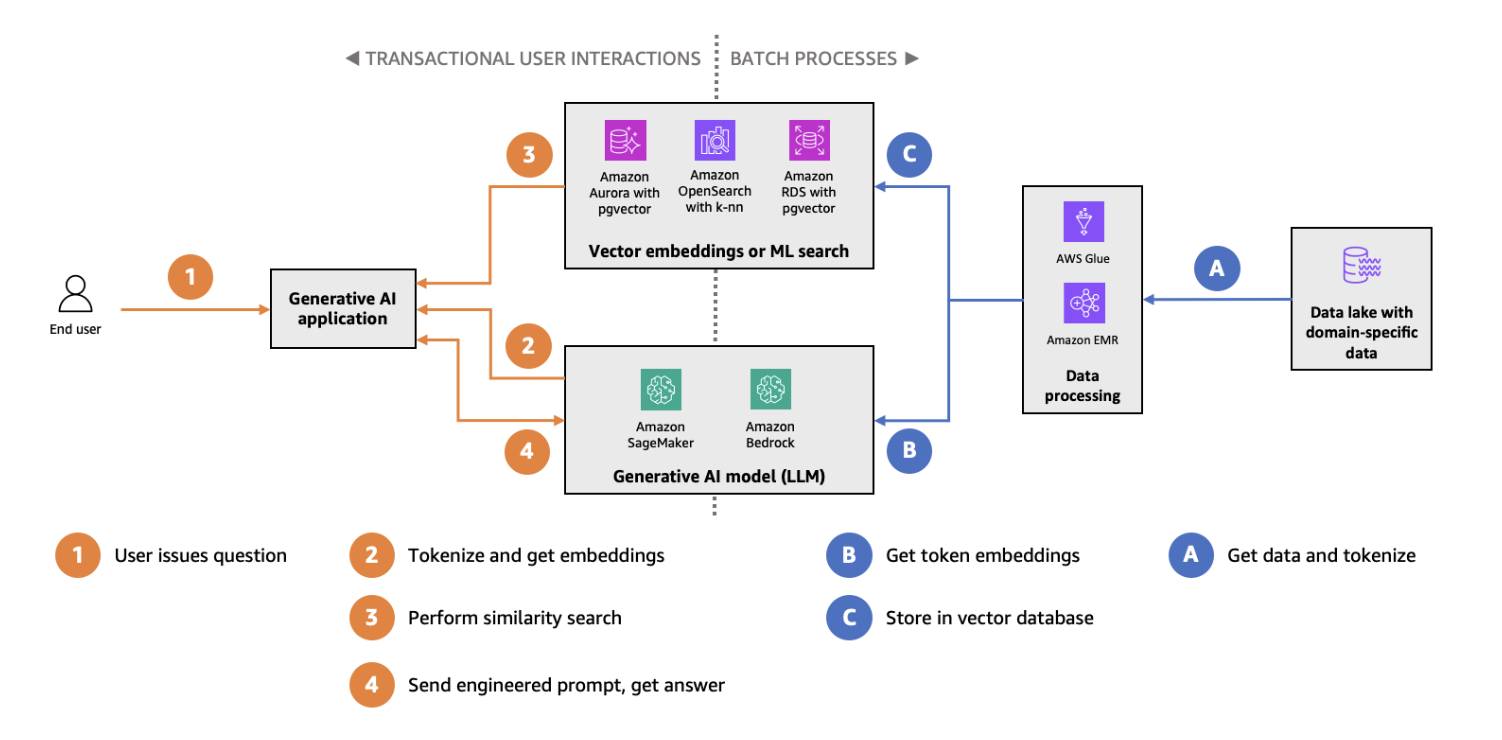
Indicizzazione e ricerca HNSW con pgvector su Amazon Aurora, diagramma dell'architettura. (Fonte immagine)
pgvector è un'estensione per PostgreSQL che introduce tipi di dati vettoriali e funzionalità di ricerca per similarità nel diffuso database relazionale. Integrando la ricerca vettoriale in PostgreSQL, pgvector offre una soluzione senza soluzione di continuità per i team che già utilizzano database tradizionali ma desiderano aggiungere capacità di ricerca vettoriale. Le caratteristiche principali di pgvector includono:
pgvector è particolarmente adatto a casi d'uso di ricerca vettoriale su scala ridotta o in ambienti in cui si preferisce un unico sistema di database per carichi di lavoro sia relazionali sia basati su vettori. Per iniziare, dai un'occhiata al nostro tutorial dettagliato su pgvector.
Di seguito una tabella di confronto che evidenzia le caratteristiche dei principali database vettoriali citati in precedenza:
| Feature | Chroma | Pinecone | Weaviate | Faiss | Qdrant | Milvus | PGVector |
|---|---|---|---|---|---|---|---|
| Open-source | ✅ | ❎ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Primary Use Case | Sviluppo di app LLM | Database vettoriale gestito per ML | Archiviazione e ricerca vettoriale scalabile | Ricerca per similarità ad alta velocità e clustering | Ricerca di similarità tra vettori | Ricerca IA ad alte prestazioni | Aggiungere la ricerca vettoriale a PostgreSQL |
| Integration | LangChain, LlamaIndex | LangChain | OpenAI, Cohere, HuggingFace | Python/NumPy, esecuzione su GPU | OpenAPI v3, vari client linguistici | TensorFlow, PyTorch, HuggingFace | Integrato nell'ecosistema PostgreSQL |
| Scalability | Scala dai notebook Python ai cluster | Altamente scalabile | Scalabilità senza soluzione di continuità fino a miliardi di oggetti | In grado di gestire insiemi più grandi della RAM | Cloud-native con scalabilità orizzontale | Scala a miliardi di vettori | Dipende dalla configurazione di PostgreSQL |
| Search Speed | Ricerche per similarità rapide | Ricerca a bassa latenza | Millisecondi per milioni di oggetti | Veloce, supporta GPU | Algoritmo HNSW personalizzato per ricerche rapide | Ottimizzato per ricerche a bassa latenza | Approximate Nearest Neighbor (ANN) |
| Data Privacy | Supporta multi-utente con isolamento dei dati | Servizio completamente gestito | Pone l'accento su sicurezza e replica | Principalmente per ricerca e sviluppo | Filtri avanzati sui payload dei vettori | Architettura sicura multi-tenant | Eredita la sicurezza di PostgreSQL |
| Programming Language | Python, JavaScript | Python | Python, Java, Go, altri | C++, Python | Rust | C++, Python, Go | Estensione PostgreSQL (basata su SQL) |
I database vettoriali sono specializzati nell'archiviazione di vettori ad alta dimensionalità, consentendo ricerche per similarità rapide e accurate. Poiché i modelli di IA, in particolare nell'ambito dell'elaborazione del linguaggio naturale e della visione artificiale, generano e lavorano con questi vettori, la necessità di sistemi di archiviazione e recupero efficienti è diventata fondamentale. È qui che entrano in gioco i database vettoriali, offrendo un ambiente altamente ottimizzato per queste applicazioni guidate dall'IA.
Un esempio lampante di questo rapporto tra IA e database vettoriali si osserva con l'emergere dei Large Language Model (LLM) come GPT-3.
Questi modelli sono progettati per comprendere e generare testo simile a quello umano elaborando enormi quantità di dati, trasformandoli in vettori ad alta dimensionalità. Le applicazioni costruite su GPT e modelli simili dipendono fortemente dai database vettoriali per gestire e interrogare questi vettori in modo efficiente. Il motivo di questa dipendenza risiede nell'enorme volume e nella complessità dei dati gestiti da questi modelli. Dato il sostanziale aumento dei parametri, modelli come GPT-4 generano una quantità enorme di dati vettorializzati, che possono essere impegnativi da elaborare in modo efficiente per i database convenzionali. Ciò sottolinea l'importanza di database vettoriali specializzati in grado di gestire dati così ad alta dimensionalità.
Il panorama in continua evoluzione dell'intelligenza artificiale e del machine learning evidenzia l'indispensabilità dei database vettoriali nel mondo odierno centrato sui dati. Questi database, con la loro capacità unica di archiviare, cercare e analizzare vettori di dati multidimensionali, si stanno dimostrando fondamentali nel dare impulso alle applicazioni guidate dall'IA, dai sistemi di raccomandazione all'analisi genomica.
Abbiamo visto di recente un'impressionante gamma di database vettoriali, come Chroma, Pinecone, Weaviate, Faiss e Qdrant, ciascuno con capacità e innovazioni proprie. Con il continuo avanzare dell'IA, il ruolo dei database vettoriali nel plasmare il futuro del recupero, dell'elaborazione e dell'analisi dei dati crescerà senza dubbio, promettendo soluzioni più sofisticate, efficienti e personalizzate in vari settori.
Impara a padroneggiare i database vettoriali con il nostro tutorial su Pinecone, oppure iscriviti al nostro percorso di competenze Deep Learning in Python per migliorare le tue abilità in IA e restare aggiornato sugli ultimi sviluppi.
Approfondisci l'IA con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

