
Program
Veri Mühendisi Python'da
40 sa
Teknik bir mülakatta mülakatçılar genellikle kolaydan başlar; Airflow çerçevesinin temellerine ve çekirdek kavramlarına odaklanıp daha karmaşık ve teknik sorulara doğru ilerlerler.
Bu soruları yanıtlarken yalnızca teknik ayrıntılardan bahsetmekle kalmayıp, bunun veri mühendisliği ve/veya kurumsal veri iş akışına nasıl bağlanabileceğini de belirtmeye özen gösterin.
Yanıt: Apache Airflow, veri uygulayıcılarının Python yardımıyla veri ardışık düzenlerini programlı olarak tanımlamasına olanak tanıyan açık kaynaklı bir veri orkestrasyon aracıdır. Airflow en yaygın olarak veri mühendisliği ekiplerince veri ekosistemlerini entegre etmek ve verileri çıkarmak, dönüştürmek ve yüklemek için kullanılır.
Daha fazlasını anlat: Airflow, Apache yazılım lisansı kapsamında geliştirilir (bu nedenle başında “Apache” ibaresi yer alır).
Bir veri orkestrasyon aracı, birden fazla kaynak ve hizmetin tek bir ardışık düzende entegre edilmesine yönelik işlevsellik sağlar.
Airflow’u bir veri orkestrasyon aracı olarak öne çıkaran şey, veri ardışık düzenlerini tanımlamak için Python kullanmasıdır; bu da diğer veri orkestrasyon araçlarının sunamadığı bir genişletilebilirlik ve kontrol düzeyi sağlar. Airflow, herhangi bir ekibin veri yığınını entegre etmek için çok sayıda yerleşik ve sağlayıcı destekli araca sahiptir; ayrıca kendi araçlarınızı tasarlama olanağı da sunar.
Airflow ile başlamayla ilgili daha fazla bilgi için şu DataCamp öğreticisine göz atın: Apache Airflow’a Başlangıç. Airflow ile veri orkestrasyonunun dünyasına daha da derinlemesine dalmak isterseniz, bu Airflow’a Giriş kursu başlamak için en iyi yerdir.
Yanıt: DAG, yani directed-acyclic graph (yönlendirilmiş çevrimsiz grafik), görevlerin ve bu görevler arasındaki ilişkilerin bir koleksiyonudur. Bir DAG’in net bir başlangıcı ve bitişi vardır ve bu görevler arasında herhangi bir “döngü” bulunmaz. Airflow kullanırken “DAG” terimi yaygın olarak kullanılır ve genellikle bir veri ardışık düzeni olarak düşünülebilir.
Daha fazlasını anlat: Bu biraz çetrefilli bir sorudur. Bir mülakatçı bu soruyu sorduğunda, hem DAG’in resmi, “matematiksel” tanımına hem de Airflow’da nasıl kullanıldığına değinmek önemlidir. DAG’leri düşünürken görsellere bakmak faydalı olur. Aşağıdaki ilk görsel aslında bir DAG’dir. Net bir başlangıcı ve bitişi vardır ve görevler arasında döngü yoktur.

Aşağıda gösterilen ikinci süreç ise BİR DAG DEĞİLDİR. Net bir başlangıç görevi olmasına rağmen, extract ve validate görevleri arasında bir döngü vardır; bu da load görevinin ne zaman tetikleneceğini belirsiz kılar.
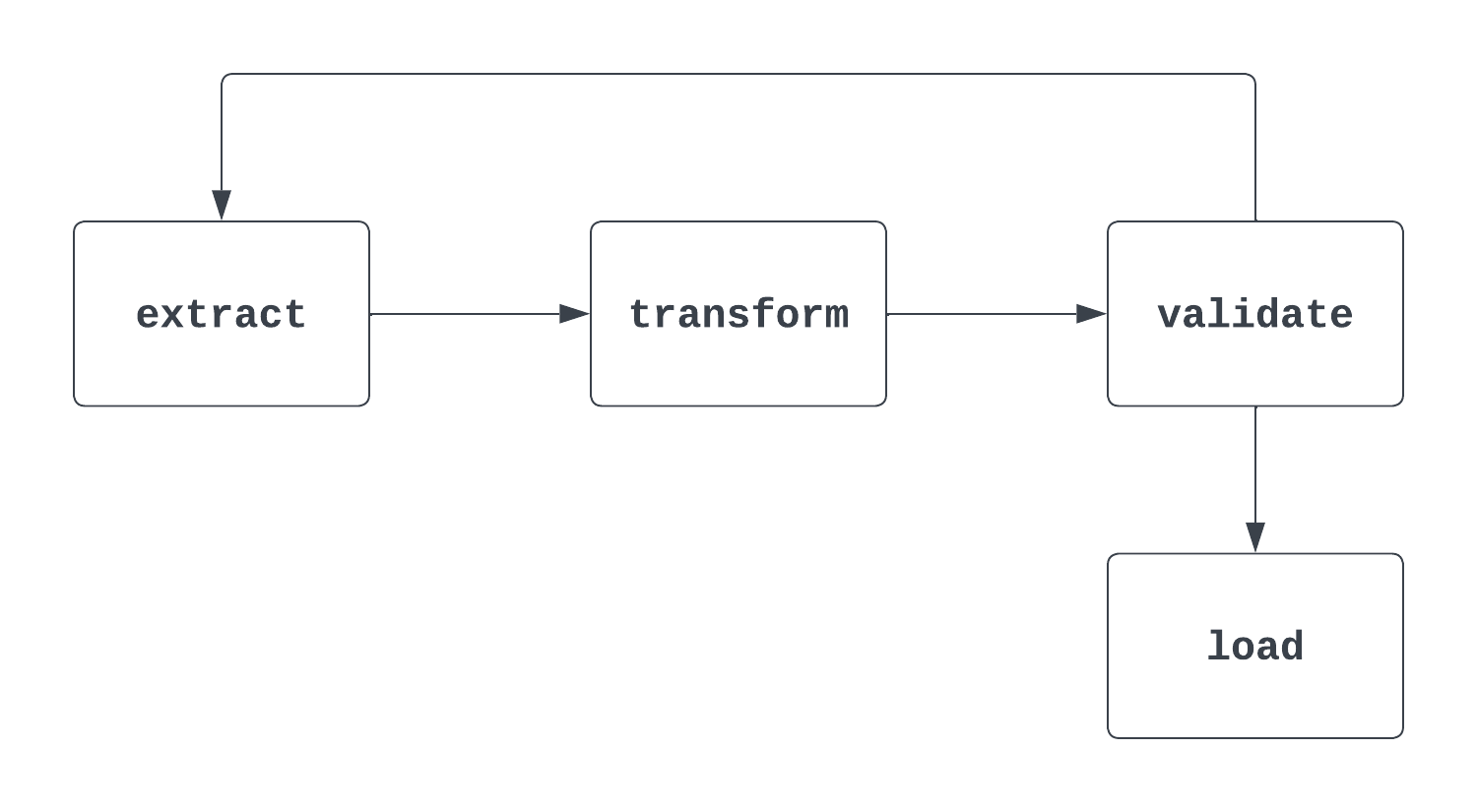
Yanıt: Bir DAG’i tanımlamak için bir ID, başlangıç tarihi ve zamanlama aralığı sağlanmalıdır.
Daha fazlasını anlat: ID, DAG’i benzersiz şekilde tanımlar ve genellikle "sample_da." gibi kısa bir dizedir. Başlangıç tarihi, bir DAG’in ilk kez tetikleneceği aralığın tarih ve saatidir.
Bu bir zaman damgasıdır; yani yıl, ay, gün, saat ve dakika tam olarak belirtilir. Zamanlama aralığı, DAG’in ne sıklıkla çalıştırılacağını gösterir. Bu, her hafta, her gün, her saat veya daha özel bir sıklık olabilir.
Buradaki örnekte, DAG "sample_dag" adlı bir dag_id kullanılarak tanımlanmıştır. datetime kütüphanesindeki datetime fonksiyonu, başlangıç tarihini 1 Ocak 2024 saat 09:00 olarak ayarlamak için kullanılır. Bu DAG, @daily zamanlanmış aralıkla belirtildiği üzere günlük (saat 09:00’da) çalışacaktır. Daha özel zamanlama aralıkları cron ifadeleri veya datetime kütüphanesindeki timedelta fonksiyonu kullanılarak ayarlanabilir.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Yanıt: Airflow görevleri, Airflow çerçevesindeki en küçük yürütme birimidir. Bir görev genellikle bir veri ardışık düzenindeki (DAG) tek bir işlemi kapsar. Görevler DAG’lerin yapı taşlarıdır ve bir DAG içindeki görevler, hangi sırada yürütüleceklerini belirleyen ilişkilere sahiptir. Görevlere üç örnek:
Bir ETL ardışık düzeninde ilişkiler şöyle olur:
Daha fazlasını anlat: Görevler çok genel de olabilir, oldukça özel de. Airflow bu görevleri tanımlamak için iki yol sunar: geleneksel operatörler ve TaskFlow API’si (buna birazdan değineceğiz).
Açık kaynağın faydalarından biri, yalnızca bireysel katkıcılardan değil, AWS, Databricks, Snowflake gibi oyunculardan da oluşan geniş topluluğun katkısıdır.
Muhtemelen tanımlamak istediğiniz görev için bir Airflow operatörü zaten oluşturulmuştur. Eğer yoksa, kendi operatörünüzü oluşturmak da kolaydır. Airflow operatörlerine birkaç örnek: SFTPToS3Operator, S3ToSnowflakeOperator ve DatabricksRunNowOperator.
Yanıt: Airflow mimarisinin dört çekirdek bileşeni vardır: zamanlayıcı (scheduler), yürütücü (executor), meta veri veritabanı ve web sunucusu (webserver).
Daha fazlasını anlat: Zamanlayıcı, her dakika DAG dizinini kontrol eder ve tetiklenebilecek görevleri belirlemek için DAG’leri ve görevleri izler. Yürütücü, görevlerin çalıştırıldığı yerdir. Görevler yerel (zamanlayıcı içinde) veya uzak (zamanlayıcının dışında) olarak yürütülebilir.
Yürütücü, her bir görevin gerektirdiği hesaplama “işinin” yapıldığı yerdir. Meta veri veritabanı, çalıştırdığınız Airflow projesine ilişkin DAG’ler ve görevler hakkında tüm bilgileri içerir. Buna geçmiş yürütme ayrıntıları, bağlantılar, değişkenler ve daha birçok bilgi dahildir.
Web sunucusu, DAG’leri geliştirirken, onlarla etkileşime geçerken ve bakım yaparken Airflow UI’nin görüntülenmesini ve kullanılmasını sağlar.
Bu, Airflow’un temel mimari bileşenlerine hızlı bir genel bakıştır.
Artık Airflow çerçevesinin ve mimarisinin temellerini bildiğinizi ortaya koydunuz. Şimdi sırada DAG yazım bilgilerinizi test etmek var.
PythonOperator nedir? Bu operatörü kullanmak için gerekenler nelerdir? PythonOperator’ı ne zaman kullanmak isteyeceğinize bir örnek verin.Yanıt: PythonOperator, bir Python fonksiyonunun Airflow görevi olarak yürütülmesine olanak tanıyan bir işleve karşılık gelir. Bu operatörü kullanmak için, bir Python fonksiyonu python_callable parametresine geçirilmelidir. PythonOperator’ın kullanılmak isteyebileceğiniz bir örnek, veriyi çıkarmak için bir API’ye istek atılmasıdır.
Daha fazlasını anlat: PythonOperator, Airflow’un sunduğu en güçlü operatörlerden biridir. Yalnızca özel kodun bir DAG içinde yürütülmesine izin vermekle kalmaz, sonuçlar XCom’lara yazılarak aşağı akıştaki görevler tarafından da kullanılabilir.
op_kwargs parametresine bir sözlük geçirilerek, anahtar sözcük argümanları Python çağrılabilirine iletilebilir; bu da çalışma zamanında daha fazla özelleştirme sağlar. op_kwargs’a ek olarak, PythonOperator’ın işlevselliğini genişletmeye yardımcı olan çok sayıda ek parametre vardır.
Aşağıda PythonOperator’ın örnek bir çağrısı yer alır. Genellikle, python_callable’a geçirilen Python fonksiyonu, DAG tanımını içeren dosyanın dışında tanımlanır. Ancak burada açıklayıcılık için dahil edilmiştir.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Yanıt: Bunu yapmanın bir hayli yolu vardır. En yaygın olanlardan biri, >> bit kaydırma operatörünü kullanmaktır. Bir diğeri, bir görevi bir diğerinin aşağı akışına yerleştirmek için .set_downstream() metodunu kullanmaktır. chain fonksiyonu da görevler arasında ardışık bağımlılıklar ayarlamak için kullanışlı bir araçtır. İşte bunun üç örneği:
# task_1, task_2, task_3 yukarıda oluşturuldu
# Bit kaydırma operatörlerini kullanma
task_1 >> task_2 >> task_3
# .set_downstream() kullanma
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# chain kullanma
chain(task_1, task_2, task_3)
Daha fazlasını anlat: Bağımlılıkları ayarlamak basit olabilir; ancak bazıları oldukça karmaşık hale de gelebilir! Ardışık yürütme için, bunu daha okunur kılmak adına bit kaydırma operatörlerini kullanmak yaygındır. TaskFlow API’si kullanıldığında, görevler arasındaki bağımlılıkları ayarlamak biraz farklı görünebilir.
İki bağımlı görev varsa, yukarıda bahsedilen teknikler yerine bir fonksiyon çağrısını başka bir fonksiyona argüman olarak geçirerek bu belirtilebilir. Airflow görev bağımlılıkları hakkında daha fazla bilgiyi ayrı bir yazıda bulabilirsiniz.
Yanıt: Task group’lar, bir DAG içinde görevleri birlikte düzenlemek için kullanılır. Bu, Airflow UI’de benzer görevleri bir arada göstermek için işleri kolaylaştırır. Aynı DAG içinde farklı ekiplere ait verileri çıkarırken, dönüştürürken ve yüklerken task group kullanmak faydalı olabilir.
Task group’lar, birden çok ML modelini eğitmek veya tek bir DAG içinde birden çok (ancak benzer) kaynak sistemle etkileşime geçmek gibi durumlarda da yaygın olarak kullanılır.
Airflow’da task group’lar kullanıldığında, ortaya çıkan grafik görünümü şu şekilde olabilir:
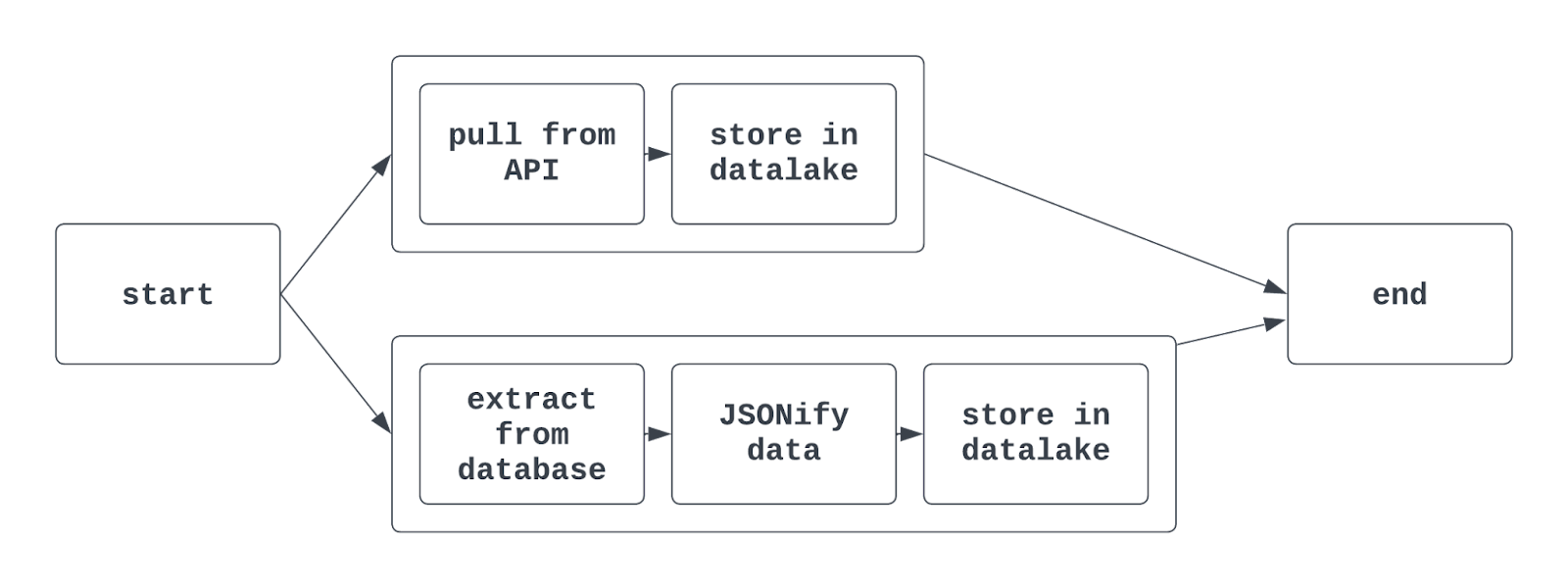
Daha fazlasını anlat: Geleneksel Airflow söz dizimini kullanırken, task group oluşturmak için TaskGroup fonksiyonu kullanılır. Task group’lar açıkça veya dinamik olarak üretilebilir; ancak benzersiz kimliklere (DAG’lerde olduğu gibi) sahip olmalıdır.
Bununla birlikte, aynı DAG içindeki farklı task group’larda aynı task_id’ye sahip görevler bulunabilir. Bu durumda görev, task group kimliği ile görev kimliğinin birleşimiyle benzersiz şekilde tanımlanır. TaskFlow API’sinden yararlanırken, bir task group oluşturmak için @task_group dekoratörü de kullanılabilir.
Yanıt: Dinamik olarak DAG üretmek, tek bir “kod parçası” kullanarak birden çok DAG oluşturmanın kullanışlı bir tekniğidir. Birden fazla konumdan veri çekmek, DAG’leri dinamik olarak oluşturmanın oldukça faydalı olduğu bir örnektir. Aynı mantığı kullanarak üç havalimanından veri çıkarmanız gerekiyorsa, DAG’leri dinamik üretmek bu süreci kolaylaştırır.
Bunu yapmanın bir dizi yolu vardır. En kolaylarından biri, üzerinde döngü kurulabilecek bir meta veri listesi kullanmaktır. Ardından, döngü içinde bir DAG örneği oluşturulabilir. Her DAG’in benzersiz bir DAG kimliğine sahip olması gerektiğini unutmamak önemlidir. Bunu yapmaya yönelik kod kabaca şöyle görünebilir:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# DAG tanımının geri kalanı
...
Bu kod, atl_daily_etl, lax_daily_etl ve jfk_daily_etl DAG kimliklerine sahip üç DAG üretir. Aşağı akışta, görevler aynı havalimanı kodu kullanılarak parametreleştirilerek her DAG’in beklendiği gibi çalışması sağlanabilir.
Daha fazlasını anlat: DAG’leri dinamik olarak üretmek, kurumsal ortamlarda yaygın olarak kullanılan bir tekniktir. Tek bir DAG içinde programatik olarak task group oluşturmak ile DAG’leri dinamik üretmek arasında karar verirken, işlemler arasındaki ilişkilere odaklanmak önemlidir.
Yukarıdaki örneğimizde, tek bir havalimanı bir istisna fırlatılmasına neden oluyorsa, task group kullanımı tüm DAG’in başarısız olmasına yol açar. Oysa DAG’ler dinamik olarak üretilirse, bu tek hata noktası diğer iki DAG’in başarısız olmasına neden olmaz.
Bir Python yinelenebilirinde döngü kurmak, DAG’leri dinamik üretmenin tek yolu değildir; bir create_dag fonksiyonu tanımlamak, değişkenler/bağlantılar kullanarak DAG’leri üretmek veya bir JSON yapılandırma dosyasından yararlanmak da aynı hedefe ulaşmak için yaygın seçeneklerdir. Gusty ve dag-factory gibi üçüncü taraf araçlar, DAG’leri dinamik üretmek için ek yapılandırma tabanlı yaklaşımlar sunar.
Airflow’un ve DAG geliştirmesinin temellerini anlamak ve anlatmak, genellikle başlangıç seviyesindeki bir veri pozisyonu için beklentileri karşılamaya yeterlidir. Ancak Airflow’u ustalıkla kullanmak, yalnızca DAG yazıp çalıştırmaktan fazlasını gerektirir.
Aşağıdaki sorular ve yanıtlar, genellikle kıdemli rollerde gereken, Airflow’un daha karmaşık işlevselliğine dair daha derin bir anlayışı mülakatçıya göstermenize yardımcı olacaktır.
data_interval_start ve data_interval_end, verildiğinde, bir DAG ne zaman yürütülür?Yanıt: Adlarının da ima ettiği gibi, data_interval_start ve data_interval_end, DAG çalıştırmasının zamansal sınırlarıdır. Bir DAG geriye dönük dolduruluyorsa (backfill) ve DAG’in yürütüldüğü zaman data_interval_end’den büyükse, DAG hemen sıraya alınarak çalıştırılır.
Ancak “normal” yürütmede, bir DAG, yürütüldüğü zaman **data_interval_end** değerinden büyük olmadıkça çalışmaz.
Daha fazlasını anlat: Bu, özellikle DAG çalıştırmalarının nasıl etiketlendiği düşünüldüğünde zor bir kavramdır. Bunu düşünmenin iyi bir yolu şöyle: Bir API’den 17 Mart 2024 tarihine ait tüm verileri çekmek istiyorsunuz.
Zamanlama aralığı günlükse, bu çalıştırma için data_interval_start 2024-03-17 00:00:00 UTC, data_interval_end ise 2024-03-18 00:00:00 UTC’dir. DAG’i 2024-03-17 00:00:00 UTC’de çalıştırmak mantıklı olmaz; çünkü 17 Mart’a ait verilerin hiçbiri mevcut olmayacaktır. Bunun yerine, DAG 2024-03-18 00:00:00 UTC olan data_interval_end’de yürütülür.
Yanıt: catchup parametresi bir DAG örneklendiğinde tanımlanır. catchup True veya False değeri alır; belirtilmezse varsayılanı True’dur. True ise, başlangıç tarihi ile DAG durumunun ilk kez etkin olarak değiştirildiği zaman arasındaki tüm DAG çalıştırmaları yürütülür.
Diyelim ki bir DAG’in başlangıç tarihi 1 Ocak 2024 olarak ayarlandı, zamanlama aralığı günlük ve catchup=True. Bu DAG ilk kez etkinleştirildiğinde geçerli tarih 15 Nisan 2024 ise, 1 Ocak 2024 data_interval_start’ına sahip DAG çalıştırması yürütülecek, ardından 2 Ocak 2024’ün DAG çalıştırması (ve bu şekilde devam edecektir).
Bu, DAG “yetişene” kadar sürecek ve sonra normal davranışına dönecektir. Buna “backfilling” denir. Backfill işlemi oldukça hızlı gerçekleşebilir. DAG çalıştırmanız sadece birkaç dakika sürüyorsa, birkaç aylık geçmiş DAG çalıştırması sadece birkaç saat içinde yürütülebilir.
False ise, geçmiş DAG çalıştırmaları yürütülmez ve ilk çalıştırma, DAG durumunun çalıştırmaya ayarlandığı aralığın sonunda başlar.
Daha fazlasını anlat: Önemli kod değişiklikleri veya manuel çaba olmadan DAG çalıştırmalarını geriye dönük doldurabilmek, Airflow’un en güçlü özelliklerinden biridir. Diyelim ki son bir yıla ait tüm işlemleri bir API’den çekmeye yönelik bir entegrasyon üzerinde çalışıyorsunuz.
DAG’inizi oluşturduktan sonra, tek yapmanız gereken istenen başlangıç tarihini ayarlamak ve catchup=True yapmak; böylece bu geçmiş verileri toplamak kolaylaşır.
DAG’inizi ilk kez etkinleştirirken geriye dönük doldurmak istemiyorsanız endişelenmeyin! Backfill’leri sistematik olarak tetiklemenin başka yolları da vardır. Bu, Airflow API ve Airflow (ve Astro CLI) ile yapılabilir.
Yanıt: XCom’lar (cross-communications), görevler arasında mesajların saklanıp okunmasına olanak tanıyan Airflow’un daha nüanslı bir özelliğidir.
XCom’lar anahtar-değer çiftleri halinde saklanır ve çeşitli yollarla okunup yazılabilir. PythonOperator kullanılırken, çağrılabilir içinde .xcom_push() ve .xcom_pull() metotları XCom’lara veri “göndermek” ve “çekmek” için kullanılabilir. XCom’lar küçük miktarda veriyi (ör. dosya adları veya bir boolean bayrağı) saklamak için kullanılır.
Daha fazlasını anlat: .xcom_push() ve .xcom_pull() kullanmanın yanı sıra, XCom’lara veri yazmanın ve okumamanın başka yolları da vardır. PythonOperator kullanılırken, do_xcom_push parametresine True verilmesi, çağrılabilirin döndürdüğü değerin XCom’lara yazılmasını sağlar.
Bu yalnızca PythonOperator ile sınırlı değildir; bir değer döndüren herhangi bir operatör, do_xcom_push parametresi yardımıyla bu değeri XCom’lara yazabilir. Arka planda, TaskFlow API de görevler arasında veri paylaşmak için XCom’ları kullanır (buna birazdan bakacağız).
XCom’lar hakkında daha fazla bilgi için, Airflow efsanesi Marc Lamberti’nin bu harika bloguna göz atın.
Yanıt: TaskFlow API, DAG yazmayı daha sezgisel ve “Pythonic” bir şekilde sunar. Geleneksel operatörleri kullanmak yerine, Python fonksiyonları @task dekoratörüyle süslenir ve görevler arasındaki bağımlılıkları açıkça tanımlamaya gerek kalmadan çıkarımlayabilir.
TaskFlow API kullanılarak yazılmış bir görev şu şekilde görünebilir:
import random
...
@task
def get_temperature():
# Bir sıcaklık çek, değeri döndür
temperature = random.randint(0, 100)
return temperature
…
TaskFlow API ile görevler arasında veri paylaşmak kolaydır. XCom’ları doğrudan kullanmak yerine, bir görevin (fonksiyonun) döndürdüğü değer başka bir göreve argüman olarak doğrudan geçirilebilir. Bu süreç boyunca, XCom’lar hâlâ arka planda kullanılır; yani TaskFlow API kullanırken bile görevler arasında büyük miktarda veri paylaşılamaz.
Daha fazlasını anlat: TaskFlow API, DAG yazımını kolaylaştırmaya yönelik Airflow hamlesinin bir parçasıdır; çerçevenin veri bilimciler ve analistlerden oluşan daha geniş bir kitleye hitap etmesine yardımcı olur. TaskFlow API, bulut veri ekosistemini entegre etmek isteyen Veri Mühendisliği ekiplerinin tüm ihtiyaçlarını karşılamasa da, temel ETL görevleri için özellikle kullanışlı (ve sezgiseldir).
TaskFlow API ve geleneksel operatörler aynı DAG içinde birlikte kullanılabilir; böylece geleneksel operatörlerin entegrasyon kabiliyeti, TaskFlow API’nin kullanım kolaylığıyla bir araya gelir. TaskFlow API hakkında daha fazla bilgi için belgelere göz atın.
Yanıt: İdempotentlik, bir sürecin/işlemin birden çok kez gerçekleştirilmesine rağmen başlangıçtaki sonucu değiştirmeyen bir özelliğidir. Daha basitçe ifade edersek, bir DAG’i bir kez çalıştırmanızla on kez çalıştırmanız aynı sonuçları vermelidir.
Bu durumun geçerli olmadığı yaygın iş akışlarından biri, verilerin yapılandırılmış (SQL) veritabanlarına eklenmesidir. Veriler birincil anahtar zorlaması olmadan eklenirse ve bir DAG birden çok kez çalıştırılırsa, bu DAG sonuç tablosunda yinelenen kayıtlara neden olur. Sil-ekle (delete-insert) veya “upsert” gibi kalıpları kullanmak, veri ardışık düzenlerinde idempotentliği uygulamaya yardımcı olur.
Daha fazlasını anlat: Bu konu tam olarak Airflow’a özgü değildir; ancak veri ardışık düzenleri tasarlanıp inşa edilirken akılda tutulması hayati önem taşır. Neyse ki Airflow, idempotentliği uygulamayı kolaylaştırmak için çeşitli araçlar sunar. Ancak bununla ilgili mantığın büyük kısmı, veri ardışık düzenini uygulamak üzere Airflow’dan yararlanan uygulayıcı tarafından tasarlanmalı, geliştirilip test edilmelidir.
Daha teknik rollerde, bir mülakatçı kendi ekiplerinde çalıştırdıklarına benzer şekilde, üretim düzeyinde bir Airflow dağıtımını yönetme ve izlemeye yönelik sorulara yönelebilir. Bu sorular biraz daha zordur ve mülakat öncesinde biraz daha hazırlık gerektirir.
Yanıt: Bir DAG yazıldıktan sonra test etmenin birkaç yolu vardır. En yaygın olanı, başarılı şekilde çalıştığını doğrulamak için DAG’i yürütmektir. Bu, yerel bir Airflow ortamı ayağa kaldırılarak ve Airflow UI kullanılarak DAG’in tetiklenmesiyle yapılabilir.
DAG tetiklendikten sonra, performansını doğrulamak için izlenebilir (hem DAG’in hem de bireysel görevlerin başarı/başarısızlığı ile çalışması için harcanan zaman ve kaynaklar).
DAG’i yürütme yoluyla manuel olarak test etmenin yanı sıra, DAG’ler birim testiyle de sınanabilir. Airflow, CLI aracılığıyla testleri çalıştırmak için araçlar sunar veya standart bir test koşucu kullanılabilir. Bu birim testleri, DAG yapılandırması ve yürütmesine karşı yazılabileceği gibi, çağrılabilirler ve eklentiler gibi bir Airflow projesinin diğer bileşenlerine karşı da yazılabilir.
Daha fazlasını anlat: Airflow DAG’lerini test etmek, bir Veri Mühendisinin yapacağı en önemli işlerden biridir. Bir DAG test edilmediyse, üretim iş akışlarını desteklemeye hazır değildir.
Veri ardışık düzenlerini test etmek özellikle zordur; diğer geliştirme senaryolarında tipik olarak görülmeyen uç ve köşe durumlar bulunur. Daha teknik bir mülakatta (özellikle Lider/Kıdemli Mühendis için), bir DAG’i uçtan uca test etmenin önemini, birim testleri yazmakla eşzamanlı yürütmeyi ve her birinin sonuçlarını belgeleme gerekliliğini mutlaka vurgulayın.
Yanıt: Kimse DAG başarısızlıklarını sevmez; ancak bunları ustalıkla ele almak sizi bir Veri Mühendisi olarak öne çıkarabilir. Neyse ki Airflow, DAG başarısızlıklarını yakalamak, uyarı vermek ve gidermek için çok sayıda araç sunar. Öncelikle, bir DAG’in başarısızlığı Airflow UI’de yakalanır. DAG’in durumu “failed” olarak değişir ve ızgara görünümünde bu çalıştırma için kırmızı bir kare/dikdörtgen görünür. Ardından, bu görevin günlükleri UI’de manuel olarak incelenebilir.
Genellikle bu günlükler, başarısızlığa neden olan istisnayı sağlar ve bir Veri Mühendisinin daha fazla triyaj yapması için bilgi sunar.
Sorun belirlendikten sonra, DAG’in altta yatan kodu/yapılandırması güncellenebilir ve DAG yeniden çalıştırılabilir. Bu, DAG’in durumunu temizleyip “active” olarak ayarlayarak yapılabilir.
Bir DAG düzenli olarak başarısız oluyor ancak yeniden denendiğinde çalışıyorsa, Airflow’un retries ve retry_delay işlevselliğini kullanmak faydalı olabilir. Bu iki parametre, bir görevin başarısız olması durumunda belirli bir süre bekledikten sonra belirlenmiş sayıda yeniden denenmesini sağlar. Bu, iniş zamanı gecikebilen bir SFTP sitesinden dosya çekmeye çalışmak gibi senaryolarda yararlı olabilir.
Daha fazlasını anlat: Bir DAG’in başarısız olması için belirli bir görevin başarısız olması gerekir. Tüm DAG yerine bu görevi triyaj etmek önemlidir. UI’ye yerleşik işlevselliğe ek olarak, DAG performansını izlemek ve yönetmek için sayısız başka araç vardır.
Geri çağırmalar (callback) Veri Mühendislerine DAG başarı ve başarısızlıklarını ele alırken neredeyse sınırsız özelleştirme sunar. Geri çağırmalarla, bir DAG başarılı olduğunda veya başarısız olduğunda, bir operatörün on_success_callback ve on_failure_callback parametreleri kullanılarak, DAG yazarının seçtiği bir fonksiyon yürütülebilir. Bu fonksiyon, PagerDuty gibi bir araca mesaj gönderebilir veya sonucu daha sonra uyarı üretmek üzere bir veritabanına yazabilir. Bu, görünürlüğü artırır ve bir başarısızlık gerçekleştiğinde triyaj sürecini hızlandırır.
Yanıt: Airflow’un en kullanışlı araçlarından biri “connections”dır (bağlantılar). Bağlantılar, bir DAG yazarının bağlantı bilgilerini (ör. ana bilgisayar, kullanıcı adı, parola vb.) bu değerleri koda gömmek zorunda kalmadan saklamasına ve bunlara erişmesine olanak tanır.
Bağlantıları saklamanın birkaç yolu vardır; en yaygın olanı Airflow’un UI’ını kullanmaktır. Bir bağlantı oluşturulduktan sonra, koddaki bir “hook” aracılığıyla doğrudan erişilebilir. Ancak, bir kaynak sistemle etkileşim gerektiren geleneksel operatörlerin çoğunda, bir dize alan ve istenen kaynağa bağlantı oluşturan bir conn_id (veya çok benzer isimli) alan bulunur.
Airflow bağlantıları, hassas bilgileri güvende tutmaya yardımcı olur ve bu bilgilerin saklanmasını ve alınmasını son derece kolaylaştırır.
Daha fazlasını anlat: Airflow UI’nin yanı sıra, CLI da bağlantıları saklamak ve almak için kullanılabilir. Kurumsal ortamlarda, bağlantı bilgilerini yönetmek için özel bir “secrets backend” kullanmak daha yaygındır. Airflow, bağlantıları yönetmek için bir dizi desteklenen gizli yönetim arka ucu sunar. AWS kullanan bir şirket, Secrets Manager’ı Airflow ile kolayca entegre ederek bağlantı ve hassas bilgileri saklayıp alabilir. Gerekirse, bağlantılar bir projenin ortam değişkenlerinde de tanımlanabilir.
Yanıt: Üretim düzeyinde çalışacak bir Airflow ortamını dağıtmak zor olabilir. Azure ve AWS gibi bulut araçları, bir Airflow dağıtımını dağıtmak ve yönetmek için yönetilen hizmetler sağlar. Ancak bu araçlar bir bulut hesabı gerektirir ve maliyetli olabilir.
Yaygın bir alternatif, üretim bir Airflow ortamını dağıtmak ve çalıştırmak için Kubernetes kullanmaktır. Bu, alttaki kaynaklar üzerinde tam kontrol sağlar; fakat bu altyapıyı yönetme sorumluluğunu da beraberinde getirir.
Bulut yerlisi ve yerleşik Kubernetes dağıtımlarının ötesine baktığımızda, Astronomer bu alanda Airflow’un en popüler yönetilen servis sağlayıcısıdır.
Airflow geliştirimi ve dağıtımını olabildiğince sorunsuz hale getirmek için “Astro” PaaS tekliflerinin yanı sıra çok sayıda açık kaynak araç (CLI, SDK, kapsamlı dokümantasyon) sağlarlar. Astro ile kaynak tahsisi, platform erişim kontrolü ve yerinde Airflow yükseltmeleri yerel olarak desteklenir; böylece odak yeniden ardışık düzen geliştirmeye döner.
Senaryo tabanlı sorular aşırı teknik olmasa da, bir Airflow mülakatındaki en önemli sorulardan bazılarıdır. Ayrıntılı ve iyi düşünülmüş yanıtlar, yalnızca Airflow konusunda değil, aynı zamanda veri mimarisi ve tasarım ilkeleri konusunda da derin bir yetkinlik sergiler.
Yanıt: Bu keyifli bir soru! Bu tür bir soruda olasılıklar çok geniştir. En önemli şey şu: Süreci anlatırken, eski veri ardışık düzenindeki aşina olduğunuz araçları ve süreçleri seçtiğinizden emin olun. Bu, uzmanlığınızı gösterir ve yanıtınızı daha isabetli hale getirir.
Ayrıca proje yönetimi ve liderlik becerilerinizi sergilemek için mükemmel bir fırsattır. Projeyi nasıl yapılandıracağınızı, paydaşlar ve diğer mühendislerle nasıl etkileşime geçeceğinizi ve süreçleri nasıl belgelendirip iletişim kuracağınızı anlatın. Bu, değer sunmaya odaklandığınızı ve ekibinizin işini kolaylaştırmayı hedeflediğinizi gösterir.
Bir şirketin yığında belirli bir araç varsa (örneğin, Google BigQuery), bu süreci Postgres gibi bir şeyden BigQuery’ye taşıyacak şekilde nasıl yeniden düzenleyebileceğinizden bahsetmek mantıklı olabilir. Bu, yalnızca Airflow’a değil, aynı zamanda bir şirketin altyapısının diğer bileşenlerine de farkındalık ve bilgi sahibi olduğunuzu gösterir.
Yanıt: Bu DAG’i tasarlamak için önce veriyi çıkarmak üzere API’ye istek atmanız gerekir. Bu, PythonOperator ve özel olarak yazılmış bir çağrılabilir ile yapılabilir. Bu çağrılabilir içinde, veriyi AWS S3 gibi bir bulut depolama konumuna kalıcı hale getirmek de isteyeceksiniz.
Bu veri kalıcı hale getirildikten sonra, S3’ten bir Snowflake veri ambarına veri yüklemek için S3ToSnowflakeOperator gibi önceden oluşturulmuş bir operatörden yararlanabilirsiniz. Son olarak, DbtCloudRunJobOperator kullanarak bu veriyi dönüştürmek için bir DBT işi çalıştırılabilir.
Bu DAG’i istenen aralıkta çalışacak şekilde zamanlamalı ve görünürlük sağlayarak hataları zarafetle ele alacak biçimde yapılandırmalısınız. Aşağıdaki diyagrama göz atın!
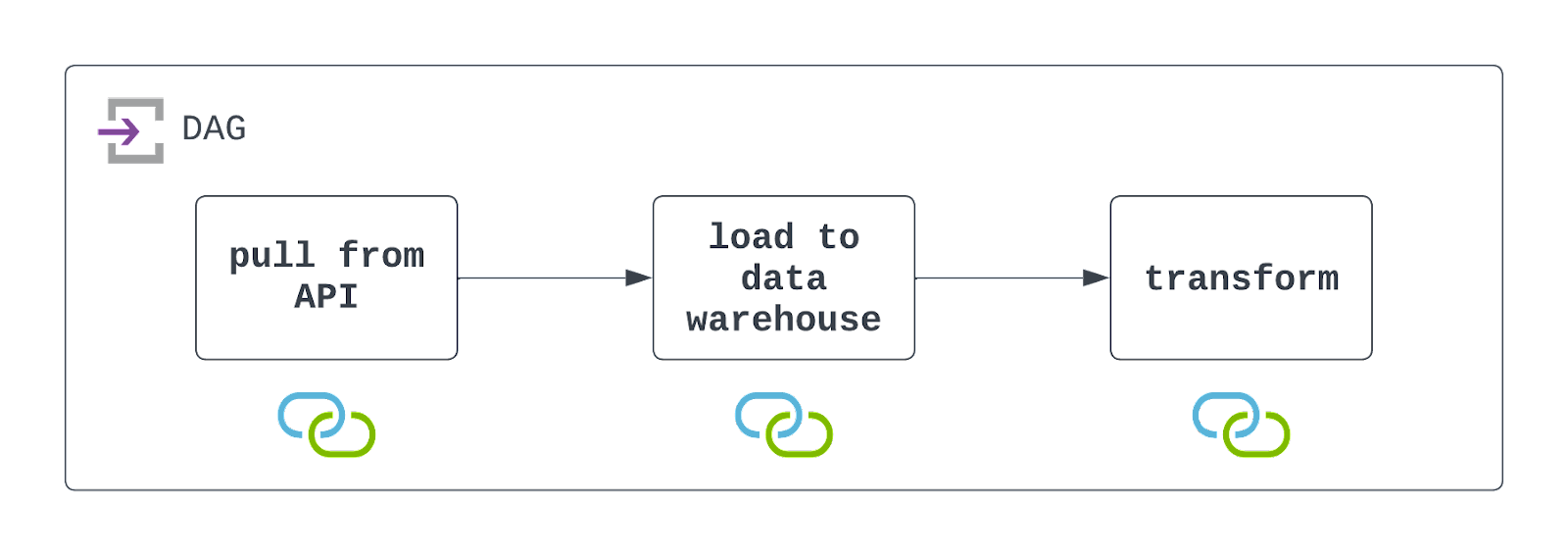
Airflow’un hem bir bulut depolama dosya sistemiyle hem de bir veri ambarıyla etkileşime girdiğini unutmamak önemlidir. Bu DAG’in başarıyla yürütülebilmesi için bu kaynakların mevcut olması ve bağlantıların tanımlanıp kullanılması gerekir. Bunlar, yukarıdaki mimari diyagramda her görevin altındaki simgelerle gösterilmiştir.
Daha fazlasını anlat: Bunlar, ayrıntılı teknik detaylardan ziyade daha çok üst düzey DAG tasarımı ve uygulamasına odaklanan en yaygın Airflow mülakat sorularındandır. Bu sorularda şu noktaları akılda tutmak önemlidir:
DbtCloudRunJobOperator kullanmak istiyorsanız bu araçtan bahsedin, ancak (sorulmadıkça) daha fazla açıklama yapma gereği duymayın.Yanıt: Airflow’un genişletilebilirliği ve veri topluluğunda artan popülaritesi, onu yalnızca Veri Mühendisleri için değil, daha fazlası için de başvurulan bir araç haline getirdi. Veri Bilimciler ve Makine Öğrenimi Mühendisleri, modellerini eğitmek (ve yeniden eğitmek) ve tam bir MLOps setini yürütmek için Airflow’u kullanıyor. Yapay Zekâ Mühendisleri de OpenAI, OpenSearch ve Pinecone gibi araçlara yönelik yeni entegrasyonlarla üretken yapay zekâ modellerini yönetmek ve ölçeklendirmek için Airflow’u kullanmaya başladı.
Daha fazlasını anlat: Geleneksel veri mühendisliği ardışık düzenlerinin dışında bu kadar gelişmek, Airflow’un ilk yaratıcılarının öngördüğü bir şey olmayabilirdi. Ancak Python’dan ve açık kaynak felsefelerinden yararlanarak Airflow, hızla evrilen veri/AI alanının ihtiyaçlarını karşılayacak şekilde büyüdü. Programatik görevlerin zamanlanıp yürütülmesi gerektiğinde, Airflow iş için en iyi araç olabilir!
Harika iş çıkardınız! Zorlu bir süreçten geçtiniz. Yukarıdaki sorular zorludur; ancak Airflow odaklı teknik mülakatlarda sorulanların büyük kısmını kapsar.
Yukarıdaki soruları gözden geçirmenin yanı sıra, bir Airflow mülakatına hazırlanmanın en iyi yollarından biri, Airflow kullanarak kendi veri ardışık düzenlerinizi oluşturmaktır.
İlginizi çeken bir veri kümesi bulun ve ETL (veya ELT) ardışık düzeninizi sıfırdan oluşturmaya başlayın. TaskFlow API’sini ve geleneksel operatörleri kullanmayı pratiğe dökün. Hassas bilgileri Airflow bağlantılarını kullanarak saklayın. Başarısızlıkları raporlamayı geri çağırmalarla deneyin ve DAG’inizi birim testleri ve uçtan uca testlerle sınayın. En önemlisi, yaptığınız işi belgeleyip paylaşın.
Bu tür bir proje, yalnızca Airflow yetkinliğini değil, aynı zamanda öğrenme ve gelişme arzunuzu da gösterir. Hâlâ bazı temel ilkelerle ilgili bir ön hazırlığa ihtiyacınız varsa, Python ile Airflow’a Giriş kursumuza, Airflow ve Prefect karşılaştırmamıza ve Apache Airflow’a Başlangıç öğreticimize göz atabilirsiniz.
Bol şans ve keyifli kodlamalar!
Veri Mühendisliği Yolculuğunuza Bugün Devam Edin!
Program
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
