
programa
Ingeniero de datos en Python
40 h
En una entrevista técnica, los entrevistadores suelen empezar por lo fácil, centrándose en los aspectos básicos del marco y los conceptos fundamentales de Airflow, antes de pasar a preguntas más complejas y técnicas.
Cuando respondas a estas preguntas, asegúrate no sólo de discutir los detalles técnicos, sino también de mencionar cómo esto podría vincularse a un flujo de trabajo de ingeniería de datos y/o de datos empresariales.
Contesta: Apache Airflow es una herramienta de orquestación de datos de código abierto que permite a los profesionales de los datos definir canalizaciones de datos mediante programación con la ayuda de Python. Los equipos de ingeniería de datos suelen utilizar Airflow para integrar su ecosistema de datos y extraer, transformar y cargar datos.
Cuéntame más: Airflow se mantiene bajo la licencia de software Apache (de ahí el prefijo "Apache").
Una herramienta de orquestación de datos proporciona funcionalidades que permiten integrar múltiples fuentes y servicios en una única canalización.
Lo que diferencia a Airflow como herramienta de orquestación de datos es su uso de Python para definir canalizaciones de datos, lo que proporciona un nivel de extensibilidad y control que otras herramientas de orquestación de datos no ofrecen. Airflow cuenta con una serie de herramientas integradas y compatibles con los proveedores para integrar la pila de datos de cualquier equipo, así como con la posibilidad de diseñar la tuya propia.
Para más información sobre cómo empezar a utilizar Airflow, consulta este tutorial de DataCamp: Primeros pasos con Apache Airflow. Si quieres sumergirte aún más en el mundo de la orquestación de datos con Airflow, este curso de Introducción a Airflow es el mejor lugar para empezar.
Contesta: Un DAG, o grafo acíclico dirigido, es una colección de tareas y relaciones entre esas tareas. Un DAG tiene un inicio y un final claros y no tiene "ciclos" entre estas tareas. Cuando se utiliza Airflow, se suele emplear el término "DAG", y normalmente se puede considerar como una canalización de datos.
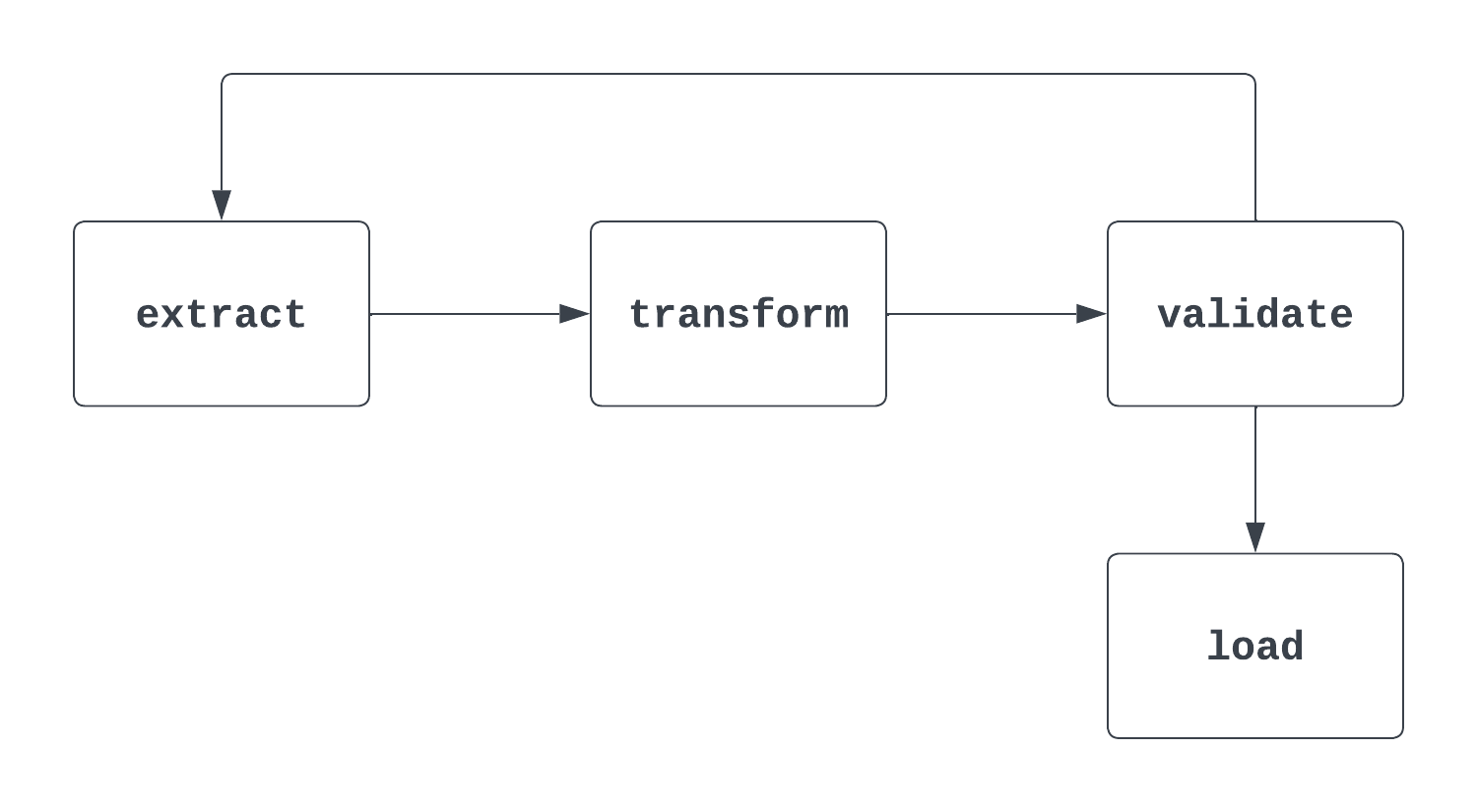
Cuéntame más: Esta es una pregunta delicada. Cuando un entrevistador hace esta pregunta, es importante abordar tanto la definición "matemática" formal de un DAG como su uso en Airflow. Al pensar en los DAG, ayuda echar un vistazo a una imagen. La primera imagen de abajo es, de hecho, un DAG. Tiene un comienzo y un final claros y no hay ciclos entre tareas.

El segundo proceso que se muestra a continuación NO es un DAG. Aunque hay una tarea de inicio clara, hay un ciclo entre las tareas de extracción y validación, lo que hace que no esté claro cuándo puede activarse la tarea de carga.
Contesta: Para definir un DAG, hay que proporcionar un ID, una fecha de inicio y un intervalo de programación.
Cuéntame más: El ID identifica de forma única al DAG y suele ser una cadena corta, como "sample_da." La fecha de inicio es la fecha y hora del primer intervalo en el que se activará un DAG.
Se trata de una marca de tiempo, lo que significa que se especifica un año, un mes, un día, una hora y un minuto exactos. El intervalo de programación es la frecuencia con la que debe ejecutarse el DAG. Puede ser cada semana, cada día, cada hora o algo más personalizado.
En este ejemplo, el DAG se ha definido utilizando un dag_id de "sample_dag". La función datetime de la biblioteca datetime se utiliza para establecer una fecha_de_inicio el 1 de enero de 2024, a las 9:00 AM. Este DAG se ejecutará diariamente (a las 9:00 AM), según lo designado por el intervalo programado @daily. Se pueden establecer intervalos de programación más personalizados utilizando expresiones cron o la función timedelta de la biblioteca datetime.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Contesta: Las tareas Airflow son la unidad de ejecución más pequeña del marco Airflow. Una tarea suele encapsular una única operación en un canal de datos (DAG). Las tareas son los bloques de construcción de los DAGs, y las tareas dentro de un DAG tienen relaciones entre ellas que determinan en qué orden se ejecutan. Tres ejemplos de tareas son:
En una canalización ETL, las relaciones serían:
Cuéntame más: Las tareas pueden ser muy genéricas o bastante personalizadas. Airflow proporciona dos formas de definir estas tareas: los operadores tradicionales y la API TaskFlow (más sobre esto más adelante).
Una de las ventajas del código abierto es la contribución de la comunidad en general, que está formada no sólo por colaboradores individuales, sino también por actores como AWS, Databricks, Snowflake y muchos más.
Lo más probable es que ya se haya creado un operador de Flujo de Aire para la tarea que te gustaría definir. Si no, es fácil crear el tuyo propio. Algunos ejemplos de operadores Airflow son SFTPToS3Operator, S3ToSnowflakeOperator y DatabricksRunNowOperator.
Contesta: Hay cuatro componentes básicos en la arquitectura de Airflow: el programador, el ejecutor, la base de datos de metadatos y el servidor web.
Cuéntame más: El programador comprueba el directorio DAG cada minuto y supervisa los DAG y las tareas para identificar cualquier tarea que pueda activarse. Un ejecutor es donde se ejecutan las tareas. Las tareas pueden ejecutarse localmente (dentro del programador) o remotamente (fuera del programador).
El ejecutor es donde tiene lugar el "trabajo" computacional que requiere cada tarea. La base de metadatos contiene toda la información sobre los DAG y las tareas relacionadas con el proyecto Airflow que estás ejecutando. Esto incluye información como detalles históricos de ejecución, conexiones, variables y mucha otra información.
El servidor web es lo que permite representar la interfaz de usuario de Airflow e interactuar con ella al desarrollar, interactuar y mantener los DAG.
Esto es sólo una rápida visión general de los componentes arquitectónicos básicos de Airflow.
Has dejado claro que conoces los fundamentos del framework Airflow y su arquitectura. Ahora, es el momento de poner a prueba tus conocimientos de autoría DAG.
PythonOperator? ¿Cuáles son los requisitos para utilizar este operador? ¿Cuál es un ejemplo de cuándo querrías utilizar la función PythonOperator?Contesta: PythonOperator es una función que permite ejecutar una función Python como una tarea Airflow. Para utilizar este operador, hay que pasar una función Python al parámetro python_callable. Un ejemplo en el que te conviene utilizar un operador Python es cuando accedes a una API para extraer datos.
Cuéntame más: El PythonOperator es uno de los operadores más potentes que ofrece Airflow. No sólo permite ejecutar código personalizado dentro de un DAG, sino que los resultados pueden escribirse en XComs para ser utilizados por tareas posteriores.
Al pasar un diccionario al parámetro op_kwargs, se pueden pasar argumentos de palabras clave a la llamada Python, lo que permite aún más personalización en tiempo de ejecución. Además de op_kwargs, hay una serie de parámetros adicionales que ayudan a ampliar la funcionalidad de PythonOperator.
A continuación se muestra un ejemplo de llamada al PythonOperator. Normalmente, la función Python que se pasa a python_callable se define fuera del archivo que contiene la definición del DAG. Sin embargo, se ha incluido aquí por verbosidad.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Contesta: Hay varias formas de hacerlo. Una de las más comunes es utilizar el operador >> de desplazamiento de bits. Otra es utilizar el método .set_downstream() para colocar una tarea a continuación de otra. La función chain es otra herramienta útil para establecer dependencias secuenciales entre tareas. Aquí tienes tres ejemplos de cómo hacerlo:
# task_1, task_2, task_3 instantiated above
# Using bit-shift operators
task_1 >> task_2 >> task_3
# Using .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Using chain
chain(task_1, task_2, task_3)
Cuéntame más: Establecer dependencias puede ser sencillo, ¡mientras que otras pueden llegar a ser bastante complejas! Para la ejecución secuencial, es habitual utilizar los operadores de desplazamiento de bits para hacerla más verbosa. Cuando se utiliza la API TaskFlow, establecer dependencias entre tareas puede parecer un poco diferente.
Si hay dos tareas dependientes, esto se puede denotar pasando una llamada de función a otra función, en lugar de utilizar las técnicas mencionadas anteriormente. Puedes obtener más información sobre las dependencias de tareas Airflow en otro artículo.
Contesta: Los grupos de tareas se utilizan para organizar las tareas juntas dentro de un DAG. Así es más fácil indicar tareas similares juntas en la interfaz de usuario de Airflow. Puede ser útil utilizar grupos de tareas cuando se extraen, transforman y cargan datos que pertenecen a diferentes equipos en el mismo DAG.
Los grupos de tareas también se suelen utilizar cuando se hacen cosas como entrenar varios modelos ML o interactuar con varios sistemas fuente (pero similares) en un único DAG.
Cuando se utilizan grupos de tareas en Airflow, la vista del gráfico resultante puede tener este aspecto:
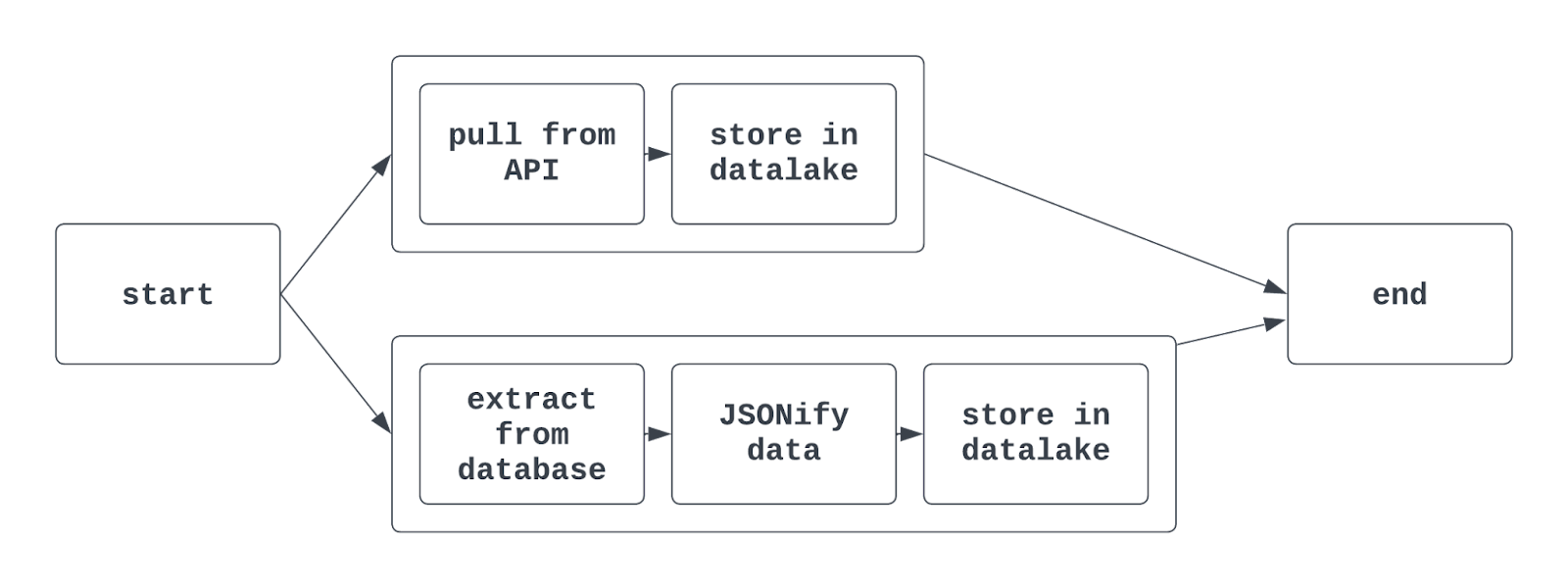
Cuéntame más: Utilizando la sintaxis tradicional de Airflow, se utiliza la función TaskGroup para crear grupos de tareas. Los grupos de tareas pueden generarse explícita o dinámicamente, pero deben tener identificadores únicos (similares a los DAG).
Sin embargo, diferentes grupos de tareas de un mismo DAG pueden tener tareas con el mismo task_id. La tarea se identificará unívocamente mediante la combinación del ID del grupo de tareas y el ID de la tarea. Al aprovechar la API TaskFlow, también se puede utilizar el decorador @task_group para crear un grupo de tareas.
Contesta: Generar DAGs dinámicamente es una técnica práctica para crear varios DAGs utilizando un único "trozo" de código. Extraer datos de varias ubicaciones es un ejemplo de lo útil que resulta crear DAG dinámicamente. Si necesitas extraer, transformar y cargar datos de tres aeropuertos utilizando la misma lógica, la generación dinámica de DAGs ayuda a agilizar este proceso.
Hay varias formas de hacerlo. Una de las más sencillas es utilizar una lista de metadatos sobre la que se pueda hacer un bucle. Luego, dentro del bucle, se puede instanciar un DAG. Es importante recordar que cada DAG debe tener un ID de DAG único. El código para hacerlo podría ser algo parecido a esto
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Rest of the DAG definition
...
Este código generaría tres DAG, con los ID de DAG atl_daily_etl, lax_daily_etl, y jfk_daily_etl. A continuación, las tareas podrían parametrizarse utilizando el mismo código de aeropuerto para garantizar que cada DAG se ejecuta como se espera.
Cuéntame más: Generar DAGs dinámicamente es una técnica muy utilizada en el entorno empresarial. Al decidir entre crear programáticamente grupos de tareas en un único DAG, o generar DAGs dinámicamente, es importante pensar en las relaciones entre las operaciones.
En nuestro ejemplo anterior, si un único aeropuerto está provocando que se lance una excepción, el uso de grupos de tareas provocaría el fallo de todo el DAG. En cambio, si los DAG se generan dinámicamente, este único punto de fallo no provocaría el fallo de los otros dos DAG.
Hacer un bucle sobre un iterable de Python no es la única forma de generar DAGs dinámicamente: definir una función create_dag, utilizar variables/conexiones para generar DAGs o aprovechar un archivo de configuración JSON son opciones habituales para lograr el mismo objetivo. Herramientas de terceros como gusty y dag-factory proporcionan enfoques adicionales basados en la configuración para generar DAG dinámicamente.
Comprender y comunicar los fundamentos del desarrollo de Airflow y DAG suele bastar para satisfacer las expectativas de un puesto de datos de nivel junior. Pero dominar Airflow significa algo más que escribir y ejecutar DAGs.
Las preguntas y respuestas que figuran a continuación te ayudarán a mostrar al entrevistador un conocimiento más profundo de las funciones más complejas de Airflow, que suelen ser necesarias para puestos de mayor responsabilidad.
data_interval_start y data_interval_end, ¿cuándo se ejecuta un DAG?Contesta: Como su nombre indica, data_interval_start y data_interval_end son los límites temporales de la ejecución del DAG. Si un DAG se está rellenando, y el tiempo de ejecución del DAG es mayor que data_interval_end, entonces el DAG se pondrá inmediatamente en cola para ejecutarse.
Sin embargo, para una ejecución "normal", un DAG no se ejecutará hasta que el tiempo de ejecución sea mayor que **data_interval_end**.
Cuéntame más: Se trata de un concepto difícil, sobre todo por cómo se etiquetan las ejecuciones DAG. He aquí una buena manera de pensar en ello. Quieres extraer todos los datos del 17 de marzo de 2024 de una API.
Si el intervalo de programación es diario, el data_interval_start para esta ejecución es 2024-03-17, 00:00:00 UTC, y el data_interval_end es 2024-03-18, 00:00:00 UTC. No tendría sentido ejecutar este DAG en 2024-03-17, 00:00:00 UTC, ya que ninguno de los datos estaría presente para el 17 de marzo. En su lugar, el DAG se ejecuta en el data_interval_end de 2024-03-18, 00:00:00 UTC.
Contesta: El parámetro catchup se define al instanciar un DAG. catchup toma el valor True o False, por defecto True cuando no se especifica. Si True, se ejecutarán todas las ejecuciones del DAG entre la fecha de inicio y el momento en que el estado del DAG se cambió por primera vez a activo.
Supongamos que la fecha de inicio de un DAG se fija en el 1 de enero de 2024, con un intervalo de programación diario y catchup=True. Si la fecha actual es el 15 de abril de 2024, cuando este DAG se active por primera vez, se ejecutará la ejecución del DAG con data_interval_start del 1 de enero de 2024, seguida de la ejecución del DAG del 2 de enero de 2024 (y así sucesivamente).
Esto continuará hasta que el DAG se "ponga al día", momento en el que reanudará su comportamiento normal. Esto se conoce como "relleno". El relleno puede producirse con bastante rapidez. Si la ejecución de tu DAG sólo te lleva unos minutos, unos meses de ejecuciones históricas de DAG pueden ejecutarse en sólo unas horas.
Si False, no se ejecutará ninguna ejecución histórica del DAG, y la primera ejecución comenzará al final del intervalo durante el cual el estado del DAG se estableció en ejecución.
Cuéntame más: Poder rellenar las ejecuciones DAG sin cambios significativos en el código ni esfuerzo manual es una de las características más potentes de Airflow. Supongamos que estás trabajando en una integración para extraer todas las transacciones de una API del último año.
Una vez que hayas construido tu DAG, todo lo que tienes que hacer es establecer la fecha de inicio deseada y catchup=True, y te resultará fácil recuperar estos datos históricos.
Si no quieres rellenar tu DAG cuando lo configures como activo por primera vez, ¡no te preocupes! Hay otras formas de activar sistemáticamente los rellenos. Esto puede hacerse con la API Airflow y la CLI Airflow (y Astro).
Contesta: Los XComs (que significa comunicaciones cruzadas) son una característica más matizada de Airflow que permite almacenar y recuperar mensajes entre tareas.
Los XComs se almacenan en pares clave-valor, y pueden leerse y escribirse de varias formas. Si utilizas PythonOperator, puedes utilizar los métodos .xcom_push() y .xcom_pull() dentro de la llamada para "empujar" y "extraer" datos de XComs. Los XComs se utilizan para almacenar pequeñas cantidades de datos, como nombres de archivo o una bandera booleana.
Cuéntame más: Además de utilizar .xcom_push() y .xcom_pull(), hay otras formas de escribir y leer datos de los XComs. Si utilizas PythonOperator, al pasar True a los parámetros de do_xcom_push se escribe en XComs el valor devuelto por la llamada.
Esto no se limita a PythonOperator; cualquier operador que devuelva un valor puede hacer que ese valor se escriba en XComs con ayuda del parámetro do_xcom_push. Entre bastidores, la API TaskFlow también utiliza XComs para compartir datos entre tareas (lo veremos a continuación).
Para más información sobre los XComs, echa un vistazo a este impresionante blog de la mismísima leyenda de Airflow, Marc Lamberti.
Contesta: La API TaskFlow ofrece una nueva forma de escribir DAGs de una manera más intuitiva y "pitónica". En lugar de utilizar los operadores tradicionales, las funciones Python se decoran con el decorador @task, y pueden inferir dependencias entre tareas sin definirlas explícitamente.
Una tarea escrita utilizando la API TaskFlow puede tener este aspecto:
import random
...
@task
def get_temperature():
# Pull a temperature, return the value
temperature = random.randint(0, 100)
return temperature
…
Con la API TaskFlow, es fácil compartir datos entre tareas. En lugar de utilizar directamente XComs, el valor de retorno de una tarea (función) puede pasarse directamente a otra tarea como argumento. A lo largo de este proceso, los XComs se siguen utilizando entre bastidores, lo que significa que no se pueden compartir grandes cantidades de datos entre tareas aunque se utilice la API TaskFlow.
Cuéntame más: La API TaskFlow forma parte del impulso de Airflow para facilitar la escritura de DAG, ayudando a que el marco resulte atractivo para un público más amplio de científicos y analistas de datos. Aunque la API TaskFlow no satisface las necesidades de los equipos de Ingeniería de Datos que buscan integrar un ecosistema de datos en la nube, es especialmente útil (e intuitiva) para tareas ETL básicas.
La API TaskFlow y los operadores tradicionales pueden utilizarse en el mismo DAG, proporcionando la integrabilidad de los operadores tradicionales con la facilidad de uso que ofrece la API TaskFlow. Para más información sobre la API TaskFlow, consulta la documentación.
Contesta: La idempotencia es una propiedad de un proceso/operación que permite que ese proceso se realice varias veces sin cambiar el resultado inicial. Dicho de forma más sencilla, si ejecutas un DAG una vez, o si lo ejecutas diez veces, los resultados deben ser idénticos.
Un flujo de trabajo habitual en el que esto no ocurre es al insertar datos en bases de datos estructuradas (SQL). Si se insertan datos sin aplicar una clave primaria y se ejecuta un DAG varias veces, este DAG provocará duplicados en la tabla resultante. Utilizar patrones como borrar-insertar o "upsert" ayuda a implementar la idempotencia en los conductos de datos.
Cuéntame más: Éste no es del todo específico de Airflow, pero es esencial tenerlo en cuenta al diseñar y construir canalizaciones de datos. Por suerte, Airflow proporciona varias herramientas para facilitar la aplicación de la idempotencia. Sin embargo, la mayor parte de esta lógica tendrá que ser diseñada, desarrollada y probada por el profesional que utilice Airflow para implementar su canalización de datos.
Para puestos más técnicos, un entrevistador podría buscar preguntas sobre la gestión y supervisión de un despliegue de Airflow de nivel de producción, similar a uno que pudieran ejecutar en su equipo. Estas preguntas son un poco más complicadas y requieren un poco más de preparación antes de la entrevista.
Contesta: Hay varias formas de probar un DAG después de haberlo escrito. Lo más habitual es ejecutar un DAG para asegurarse de que se ejecuta correctamente. Para ello, crea un entorno Airflow local y utiliza la interfaz de usuario de Airflow para activar el DAG.
Una vez que se ha activado el DAG, se puede supervisar para validar su rendimiento (tanto el éxito/fracaso del DAG y de las tareas individuales, como el tiempo y los recursos que tardó en ejecutarse).
Además de probar manualmente el DAG mediante la ejecución, los DAG pueden probarse unitariamente. Airflow proporciona herramientas a través de la CLI para ejecutar las pruebas, o se puede utilizar un ejecutor de pruebas estándar. Estas pruebas unitarias pueden escribirse tanto contra la configuración y ejecución del DAG como contra otros componentes de un proyecto Airflow, como callables y plugins.
Cuéntame más: Probar los DAG de Airflow es una de las cosas más importantes que hará un Ingeniero de Datos. Si un DAG no se ha probado, no está preparado para soportar flujos de trabajo de producción.
Probar canalizaciones de datos es especialmente complicado; hay casos límite y de esquina que no suelen darse en otros escenarios de desarrollo. Durante una entrevista más técnica (especialmente para un Ingeniero Jefe/Senior), asegúrate de comunicar la importancia de probar un DAG de extremo a extremo junto con la escritura de pruebas unitarias y la documentación de los resultados de cada una.
Contesta: A nadie le gustan los fallos de DAG, pero manejarlos con gracia puede diferenciarte como Ingeniero de Datos. Por suerte, Airflow ofrece una plétora de herramientas para capturar, alertar y remediar los fallos del DAG. En primer lugar, el fallo de un DAG se captura en la interfaz de usuario de Airflow. El estado del DAG cambiará a "fallido", y la vista de cuadrícula mostrará un cuadrado/rectángulo rojo para esta ejecución. Después, los registros de esta tarea se pueden analizar manualmente en la interfaz de usuario.
Normalmente, estos registros proporcionarán la excepción que causó el fallo y proporcionarán a un Ingeniero de Datos información para realizar un triaje posterior.
Una vez identificado el problema, se puede actualizar el código/configuración subyacente del DAG y volver a ejecutarlo. Esto puede hacerse borrando el estado del DAG y poniéndolo en "activo".
Si un DAG falla regularmente pero funciona cuando se vuelve a intentar, puede ser útil utilizar las funciones retries y retry_delay de Airflow. Estos dos parámetros se pueden utilizar para reintentar una tarea en caso de fallo un número especificado de veces después de esperar un determinado periodo de tiempo. Esto puede ser útil en situaciones como intentar extraer un archivo de un sitio SFTP que puede tardar en aterrizar.
Cuéntame más: Para que un DAG falle, debe fallar una tarea específica. Es importante triar esta tarea en lugar de todo el DAG. Además de las funciones integradas en la interfaz de usuario, hay montones de otras herramientas para supervisar y gestionar el rendimiento del DAG.
Las devoluciones de llamada ofrecen a los Ingenieros de Datos una personalización básicamente ilimitada a la hora de gestionar los éxitos y fracasos del DAG. Con las retrollamadas, se puede ejecutar una función a elección del autor del DAG cuando un DAG tiene éxito o falla utilizando los parámetros on_success_callback y on_failure_callback de un operador. Esta función puede enviar un mensaje a una herramienta como PagerDuty o escribir el resultado en una base de datos para ser alertado posteriormente. Esto ayuda a mejorar la visibilidad y a poner en marcha el proceso de triaje cuando se produce un fallo.
Contesta: Una de las herramientas más prácticas de Airflow son las "conexiones". Las conexiones permiten al autor de un DAG almacenar y acceder a la información de conexión (como el host, el nombre de usuario, la contraseña, etc.) sin tener que codificar esos valores en el código.
Hay varias formas de almacenar conexiones; la más común es utilizar la interfaz de usuario de Airflow. Una vez creada una conexión, se puede acceder a ella directamente en código utilizando un "gancho". Sin embargo, la mayoría de los operadores tradicionales que requieren interacción con un sistema fuente tienen un campo conn_id (o de nombre muy similar) que toma una cadena y crea una conexión con la fuente deseada.
Las conexiones de flujo de aire ayudan a mantener a salvo la información confidencial y facilitan su almacenamiento y recuperación.
Cuéntame más: Además de utilizar la interfaz de usuario de Airflow, se puede utilizar la CLI para almacenar y recuperar conexiones. En un entorno empresarial, es más habitual utilizar un "backend de secretos" personalizado para gestionar la información de conexión. Airflow proporciona varios backends secretos de apoyo para gestionar las conexiones. Una empresa que utilice AWS puede integrar fácilmente Secrets Manager con Airflow para almacenar y recuperar información sensible y de conexión. Si es necesario, las conexiones también pueden definirse en las variables de entorno de un proyecto.
Contesta: Desplegar un entorno Airflow para que funcione en un entorno de producción puede ser difícil. Las herramientas en la nube, como Azure y AWS, ofrecen servicios gestionados para desplegar y gestionar un despliegue de Airflow. Sin embargo, estas herramientas requieren una cuenta en la nube y pueden ser algo caras.
Una alternativa habitual es utilizar Kubernetes para desplegar y ejecutar un entorno Airflow de producción. Esto permite un control total de los recursos subyacentes, pero conlleva la responsabilidad adicional de gestionar esa infraestructura.
Si miramos fuera de las implantaciones de Kubernetes nativas en la nube y de cosecha propia, Astronomer es el proveedor de servicios gestionados de Airflow más popular en el espacio.
Proporcionan una serie de herramientas de código abierto (CLI, SDK, montones de documentación) además de su oferta "Astro" PaaS para que el desarrollo y despliegue de Airflow sea lo más sencillo posible. Con Astro, la asignación de recursos, el control de acceso a la plataforma y las actualizaciones in situ de Airflow se admiten de forma nativa, devolviendo la atención al desarrollo de la tubería.
Aunque las preguntas basadas en escenarios no son excesivamente técnicas, son algunas de las más importantes en una entrevista de Airflow. Proporcionar respuestas detalladas y bien pensadas demuestra una profunda competencia no sólo con Airflow, sino también con la arquitectura de datos y los principios de diseño.
Contesta: ¡Esto es divertido! Con una pregunta como ésta, el mundo está al alcance de tu mano. Lo más importante es lo siguiente: cuando recorras el proceso, asegúrate de elegir herramientas y procesos del canal de datos heredado con los que estés familiarizado. Esto demuestra tu experiencia y hará que la respuesta a tu pregunta esté mejor fundamentada.
Es la oportunidad perfecta para demostrar también tus habilidades de gestión de proyectos y liderazgo. Menciona cómo estructurarías el proyecto, cómo interactuarías con las partes interesadas y otros ingenieros, y cómo documentarías/comunicarías los procesos. Esto demuestra un énfasis en aportar valor y facilitar la vida a tu equipo.
Si una empresa tiene una herramienta determinada en su pila (digamos, Google BigQuery), podría tener sentido hablar de cómo puedes refactorizar este proceso para pasar de algo como Postgres a BigQuery. Esto ayuda a demostrar la conciencia y el conocimiento no sólo de Airflow, sino también de otros componentes de la infraestructura de una empresa.
Contesta: Para diseñar este DAG, primero tendrás que acceder a la API para extraer datos. Esto puede hacerse utilizando la dirección PythonOperator y una llamada personalizada. Dentro de ese callable, también querrás persistir los datos en una ubicación de almacenamiento en la nube, como AWS S3.
Una vez persistidos estos datos, puedes aprovechar un operador preconstruido, como el S3ToSnowflakeOperator, para cargar datos de S3 en un almacén de datos Snowflake. Por último, se puede ejecutar un trabajo DBT para transformar estos datos utilizando el DbtCloudRunJobOperator.
Querrás programar este DAG para que se ejecute en el intervalo deseado y configurarlo para que gestione los fallos con elegancia (pero con visibilidad). ¡Echa un vistazo al diagrama de abajo!
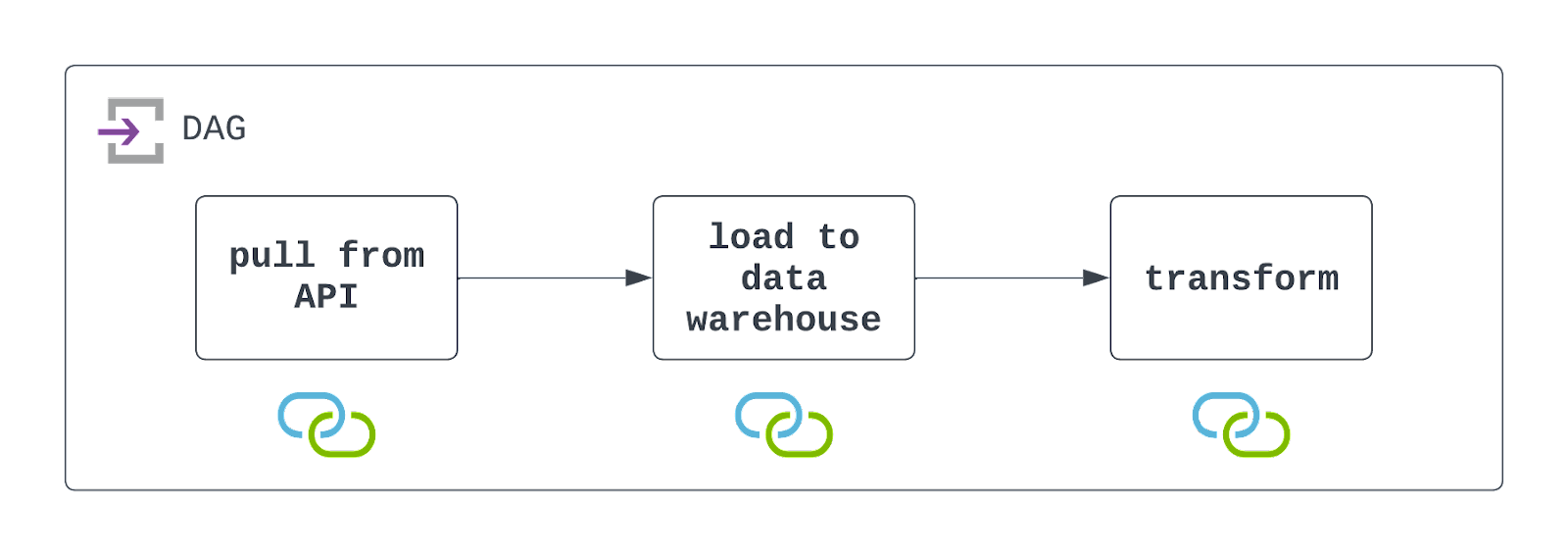
Es importante tener en cuenta que Airflow está interactuando tanto con un sistema de archivos de almacenamiento en la nube, como con un almacén de datos. Para que este DAG se ejecute con éxito, será necesario que existan estos recursos, y que se definan y utilicen las conexiones. Se indican con los iconos que hay debajo de cada tarea en el diagrama de arquitectura anterior.
Cuéntame más: Éstas son algunas de las preguntas más habituales en las entrevistas sobre Airflow, que se centran más en el diseño y la implementación de DAG de alto nivel que en los detalles técnicos más minuciosos. Con estas preguntas, es importante tener en cuenta algunas cosas:
DbtCloudRunJobOperator, menciona esta herramienta, pero no sientas la necesidad de elaborar mucho más que eso (a menos que te lo pidan).Contesta: La extensibilidad de Airflow y su creciente popularidad en la comunidad de datos lo han convertido en una herramienta a la que no sólo acuden los ingenieros de datos. Los científicos de datos y los ingenieros de aprendizaje automático utilizan Airflow para entrenar (y volver a entrenar) sus modelos, así como para realizar un conjunto completo de MLOps. Los ingenieros de IA incluso están empezando a utilizar Airflow para gestionar y escalar sus modelos de IA generativa, con nuevas integraciones para herramientas como OpenAI, OpenSearch y Pinecone.
Cuéntame más: Puede que prosperar fuera de los conductos tradicionales de ingeniería de datos no fuera algo que previeran los creadores iniciales del Airflow. Sin embargo, aprovechando las filosofías de Python y del código abierto, Airflow ha crecido para satisfacer las necesidades de un espacio de datos/AI en rápida evolución. Cuando hay que programar y ejecutar tareas programáticas, Airflow puede ser la mejor herramienta para el trabajo.
¡Buen trabajo! Has pasado por el aro. Las preguntas anteriores son desafiantes, pero captan gran parte de lo que se pregunta en las entrevistas técnicas centradas en Airflow.
Además de repasar las preguntas anteriores, una de las mejores formas de prepararte para una entrevista con Airflow es construir tus propios conductos de datos utilizando Airflow.
Encuentra un conjunto de datos que te interese, y empieza a construir tu canal ETL (o ELT) desde cero. Practica utilizando la API TaskFlow y los operadores tradicionales. Almacena información sensible utilizando conexiones Airflow. Prueba a informar de los fallos mediante devoluciones de llamada, y prueba tu DAG con pruebas unitarias y de extremo a extremo. Y lo que es más importante, documenta y comparte el trabajo que has hecho.
Un proyecto como éste ayuda a demostrar no sólo competencia en Airflow, sino también pasión y deseo de aprender y crecer. Si aún necesitas una introducción a algunos de los principios básicos, puedes consultar nuestro curso Introducción a Airflow en Python, nuestra comparativa Airflow vs Prefect y nuestro tutorial Introducción a Apache Airflow.
Mucha suerte y ¡feliz codificación!
¡Continúa hoy tu viaje en Ingeniería de Datos!
programa
Curso
Curso
blog
Abid Ali Awan
15 min
blog
Nisha Arya Ahmed
15 min
blog
Josep Ferrer
15 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
15 min
blog
Austin Chia
15 min

