
Programa
Engenheiro de dados Em Python
40 h
Em uma entrevista técnica, é comum o entrevistador começar pelo simples, focando na base do framework do Airflow e seus conceitos centrais antes de avançar para perguntas mais complexas e técnicas.
Ao responder, procure não só citar detalhes técnicos, mas também como isso se conecta a um fluxo de trabalho de engenharia de dados e/ou dados corporativos.
Resposta: Apache Airflow é uma ferramenta de orquestração de dados open source que permite definir pipelines de dados de forma programática com Python. O uso mais comum é por times de engenharia de dados para integrar o ecossistema de dados e extrair, transformar e carregar dados.
Conte mais: O Airflow é mantido sob a licença de software Apache (daí o “Apache” no nome).
Uma ferramenta de orquestração de dados oferece recursos para integrar múltiplas fontes e serviços em um único pipeline.
O que diferencia o Airflow é o uso de Python para definir pipelines, oferecendo extensibilidade e controle que outras ferramentas de orquestração não oferecem. O Airflow conta com diversos recursos nativos e de provedores para integrar qualquer stack de dados, além da possibilidade de criar integrações próprias.
Para começar com Airflow, confira este tutorial da DataCamp: Getting Started with Apache Airflow. Se quiser ir mais fundo no mundo da orquestração de dados com Airflow, este curso Introduction to Airflow é o melhor ponto de partida.
Resposta: Um DAG, ou directed acyclic graph (grafo acíclico direcionado), é um conjunto de tarefas e os relacionamentos entre elas. Um DAG tem início e fim bem definidos e não possui “ciclos” entre as tarefas. No Airflow, o termo “DAG” é comum e, na prática, pode ser entendido como um pipeline de dados.
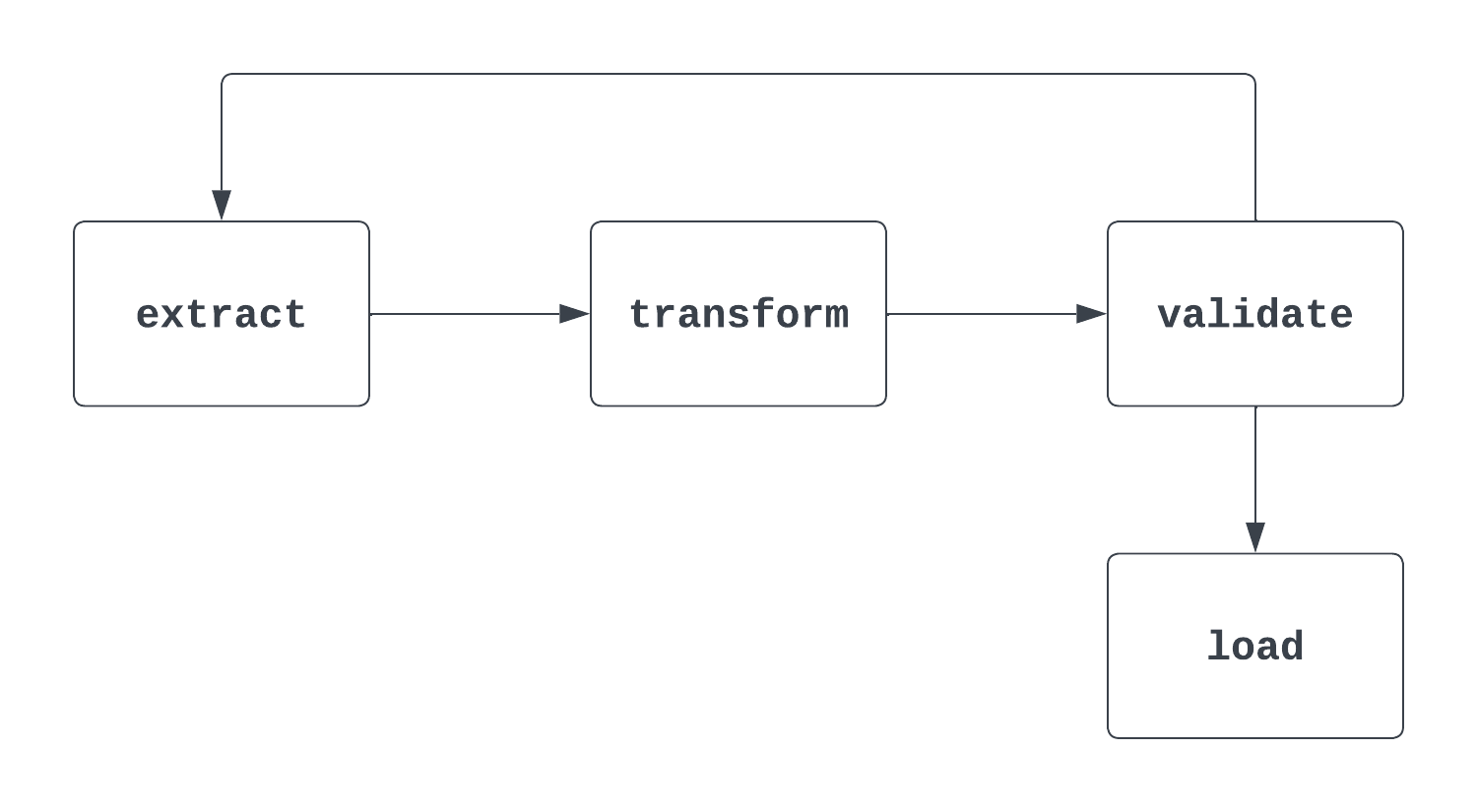
Conte mais: Essa pergunta é traiçoeira. Ao respondê-la, é importante abordar tanto a definição formal “matemática” de DAG quanto o uso no Airflow. Ao pensar em DAGs, um visual ajuda bastante. A primeira imagem abaixo é, de fato, um DAG: tem início e fim claros e não há ciclos entre as tarefas.

O segundo processo abaixo NÃO é um DAG. Embora exista uma tarefa inicial clara, há um ciclo entre as tarefas de extract e validate, o que torna incerto quando a tarefa de load será disparada.
Resposta: Para definir um DAG, é preciso informar um ID, start date e schedule interval.
Conte mais: O ID identifica exclusivamente o DAG e costuma ser uma string curta, como "sample_da." A start date é a data e hora do primeiro intervalo em que o DAG será acionado.
É um timestamp, ou seja, especifica ano, mês, dia, hora e minuto exatos. O schedule interval define a frequência de execução do DAG: pode ser semanal, diário, por hora ou algo mais personalizado.
No exemplo, o DAG foi definido com dag_id igual a "sample_dag". A função datetime da biblioteca datetime define a start_date como 1º de janeiro de 2024, às 9h. Esse DAG rodará diariamente (às 9h), conforme o intervalo @daily. Intervalos personalizados podem ser definidos com expressões cron ou com a função timedelta da biblioteca datetime.
with DAG(
dag_id="sample_dag",
start_date=datetime(year=2024, month=1, day=1, hour=9, minute=0),
schedule="@daily",
) as dag:
…
Resposta: As tasks são a menor unidade de execução no Airflow. Cada task normalmente encapsula uma única operação em um pipeline de dados (DAG). Elas são os blocos de construção dos DAGs, e os relacionamentos entre tasks determinam a ordem de execução. Três exemplos de tasks:
Em um pipeline ETL, os relacionamentos seriam:
Conte mais: As tasks podem ser bem genéricas ou bastante personalizadas. O Airflow oferece duas formas de defini-las: operadores tradicionais e a TaskFlow API (mais adiante).
Um dos benefícios do open source é a contribuição da comunidade — não só por indivíduos, mas também por players como AWS, Databricks, Snowflake e muitos outros.
É bem provável que já exista um operador para a task que você precisa. Se não, é fácil criar o seu. Alguns exemplos: SFTPToS3Operator, S3ToSnowflakeOperator e DatabricksRunNowOperator.
Resposta: São quatro componentes principais: scheduler, executor, banco de dados de metadados e webserver.
Conte mais: O scheduler verifica o diretório de DAGs a cada minuto e monitora DAGs e tasks para identificar o que pode ser disparado. O executor é onde as tasks rodam. A execução pode acontecer localmente (no scheduler) ou remotamente (fora do scheduler).
É no executor que ocorre o “trabalho” computacional exigido por cada task. O banco de metadados guarda todas as informações sobre os DAGs e tasks do projeto Airflow em execução, incluindo histórico, conexões, variáveis e muito mais.
O webserver permite renderizar e interagir com a interface do Airflow durante o desenvolvimento, a operação e a manutenção de DAGs.
Este é só um panorama rápido dos componentes arquiteturais do Airflow.
Você já mostrou que conhece a base do framework e da arquitetura do Airflow. Agora é hora de testar seus conhecimentos em autoria de DAGs.
PythonOperator? Quais os requisitos para usá-lo? Dê um exemplo de uso do PythonOperator.Resposta: O PythonOperator permite executar uma função Python como uma task do Airflow. Para usá-lo, é preciso passar uma função Python no parâmetro python_callable. Um exemplo típico é chamar uma API para extrair dados.
Conte mais: O PythonOperator é um dos operadores mais poderosos do Airflow. Além de executar código customizado dentro do DAG, os resultados podem ser escritos em XComs para uso por tasks downstream.
Ao passar um dicionário em op_kwargs, você envia argumentos nomeados para a função, permitindo ainda mais customização em tempo de execução. Além de op_kwargs, há vários outros parâmetros que ampliam a funcionalidade do PythonOperator.
Abaixo está uma chamada de exemplo do PythonOperator. Normalmente, a função passada para python_callable é definida fora do arquivo do DAG, mas aqui foi incluída para dar contexto.
def some_callable(name):
print("Hello ", name)
...
some_task = PythonOperator(
task_id="some_task",
python_callable=some_callable,
op_kwargs={"name": "Charles"}
)
Resposta: Há várias formas. Uma das mais comuns é usar o operador bit-shift >>. Outra é o método .set_downstream() para definir que uma task está downstream de outra. A função chain também é útil para dependências sequenciais. Três exemplos:
# task_1, task_2, task_3 instanciadas acima
# Usando operadores bit-shift
task_1 >> task_2 >> task_3
# Usando .set_downstream()
task_1.set_downstream(task_2)
task_2.set_downstream(task_3)
# Usando chain
chain(task_1, task_2, task_3)
Conte mais: Definir dependências pode ser simples ou bem complexo. Para execução sequencial, é comum usar o bit-shift pela verbosidade. Ao usar a TaskFlow API, a definição de dependências pode parecer diferente.
Se houver duas tasks dependentes, você pode indicar isso passando a chamada de uma função como argumento de outra, em vez das técnicas acima. Saiba mais sobre dependências de tasks em um artigo à parte.
Resposta: Task groups servem para organizar tasks dentro de um DAG. Isso facilita agrupar tasks semelhantes na interface do Airflow. Eles são úteis, por exemplo, ao extrair, transformar e carregar dados de times diferentes dentro do mesmo DAG.
Task groups também são comuns ao treinar múltiplos modelos de ML ou interagir com várias fontes semelhantes em um único DAG.
Ao usar task groups no Airflow, a visualização do grafo pode ficar assim:
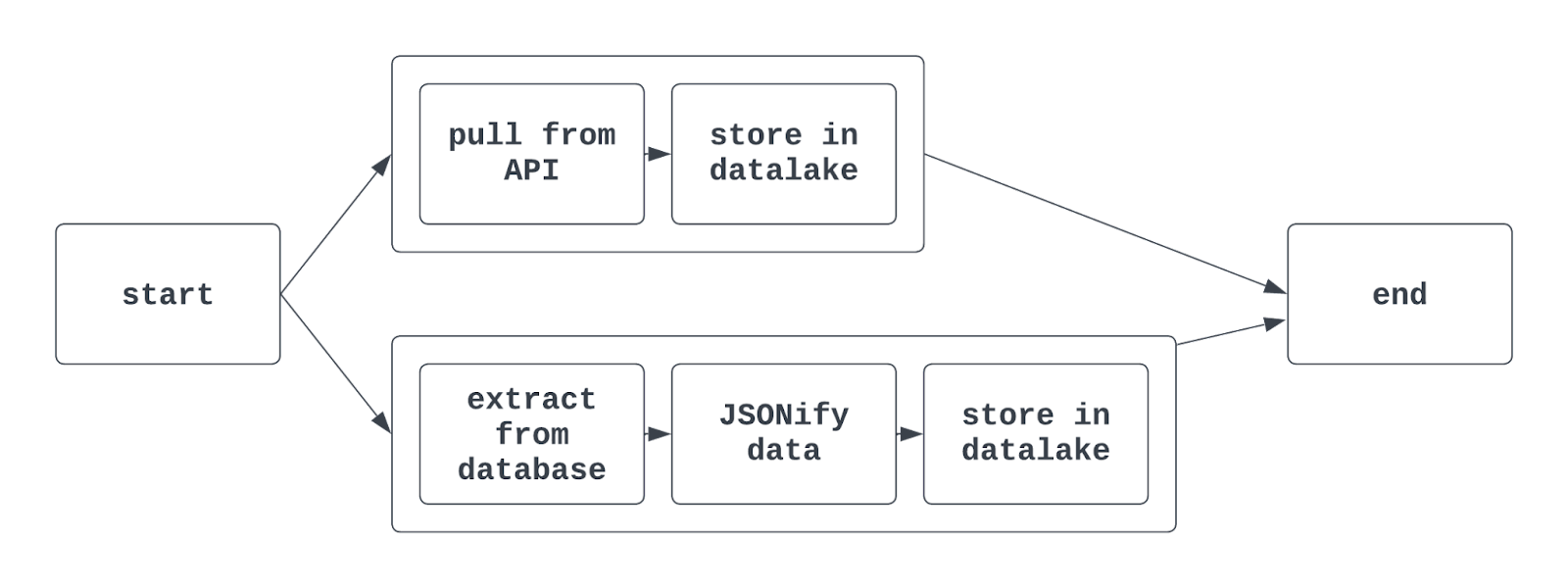
Conte mais: Na sintaxe tradicional do Airflow, usa-se a função TaskGroup para criar task groups. Eles podem ser gerados de forma explícita ou dinâmica, mas precisam ter IDs únicos (como os DAGs).
Porém, task groups diferentes no mesmo DAG podem ter tasks com o mesmo task_id. A identificação única será a combinação do ID do task group com o task_id. Com a TaskFlow API, o decorator @task_group também pode criar um task group.
Resposta: Gerar DAGs dinamicamente é uma técnica útil para criar vários DAGs a partir de um único “bloco” de código. Um exemplo é a extração de dados de múltiplos locais. Se você precisa extrair, transformar e carregar dados de três aeroportos com a mesma lógica, gerar DAGs dinamicamente agiliza o processo.
Há várias formas de fazer isso. Uma das mais simples é usar uma lista de metadados para iterar e, dentro do loop, instanciar um DAG. É importante lembrar que cada DAG deve ter um ID único. O código pode ser algo assim:
airport_codes = ["atl", "lax", "jfk"]
for code in airport_codes:
with DAG(
dag_id=f"{code}_daily_etl"
start_date=datetime(2024, 1, 1, 9, 0),
schedule="@daily"
) as dag:
# Restante da definição do DAG
...
Esse código criaria três DAGs, com IDs atl_daily_etl, lax_daily_etl e jfk_daily_etl. Mais adiante, as tasks poderiam ser parametrizadas com o mesmo código de aeroporto para garantir a execução correta de cada DAG.
Conte mais: Gerar DAGs dinamicamente é comum em ambientes corporativos. Ao decidir entre criar task groups programaticamente em um único DAG ou gerar DAGs dinamicamente, pense nos relacionamentos entre operações.
No exemplo acima, se um único aeroporto causar uma exceção, usar task groups faria o DAG inteiro falhar. Já com DAGs dinâmicos, esse ponto único de falha não derrubaria os outros dois DAGs.
Iterar sobre um iterável em Python não é a única forma de gerar DAGs dinamicamente — definir uma função create_dag, usar variáveis/conexões para criar DAGs ou aproveitar um arquivo de configuração JSON também são opções comuns. Ferramentas de terceiros como gusty e dag-factory oferecem abordagens adicionais baseadas em configuração.
Entender e comunicar os fundamentos do Airflow e de desenvolvimento de DAGs geralmente atende ao esperado para posições júnior. Mas dominar Airflow vai além de escrever e executar DAGs.
As perguntas e respostas abaixo demonstram um entendimento mais profundo de funcionalidades complexas do Airflow — normalmente exigidas em cargos mais seniores.
data_interval_start e um data_interval_end, quando um DAG é executado?Resposta: Como o nome sugere, data_interval_start e data_interval_end são os limites temporais da execução do DAG. Se um DAG estiver sendo backfilled e o horário atual for maior que data_interval_end, o DAG será imediatamente enfileirado para execução.
No entanto, em execução “normal”, um DAG só roda quando o horário atual é maior que o **data_interval_end**.
Conte mais: Esse conceito é difícil, especialmente pela forma como as execuções são rotuladas. Pense assim: você quer puxar todos os dados de 17 de março de 2024 de uma API.
Se o intervalo é diário, o data_interval_start dessa execução é 2024-03-17 00:00:00 UTC, e o data_interval_end é 2024-03-18 00:00:00 UTC. Não faz sentido rodar o DAG em 2024-03-17 00:00:00 UTC, já que os dados do dia 17 ainda não existem. Em vez disso, o DAG é executado no data_interval_end, em 2024-03-18 00:00:00 UTC.
Resposta: O parâmetro catchup é definido ao instanciar um DAG. Ele aceita True ou False (padrão é True). Se True, todas as execuções entre a start date e o momento em que o DAG foi ativado serão executadas.
Suponha que a start date seja 1º de janeiro de 2024, com agendamento diário e catchup=True. Se a data atual for 15 de abril de 2024 quando o DAG for ativado, a execução com data_interval_start de 1º de janeiro de 2024 rodará primeiro, seguida pela de 2 de janeiro de 2024, e assim por diante.
Isso continua até o DAG “alcançar” o presente, retomando então o comportamento normal. Esse processo é chamado de “backfilling”. Ele pode ser rápido: se cada execução leva poucos minutos, dá para rodar meses de histórico em algumas horas.
Se False, nenhuma execução histórica será feita, e a primeira execução começará no fim do intervalo em que o DAG foi ativado.
Conte mais: Poder fazer backfill sem mudanças significativas de código ou esforço manual é um dos grandes pontos fortes do Airflow. Imagine que você está integrando uma API para recuperar todas as transações do último ano.
Depois de construir seu DAG, basta definir a start date desejada e catchup=True para recuperar esses dados históricos facilmente.
Se você não quiser fazer backfill ao ativar o DAG, sem problema! Há várias formas de disparar backfills de forma sistemática, via API do Airflow e via CLI do Airflow (e Astro CLI).
Resposta: XComs (cross-communications) são um recurso do Airflow que permite armazenar e recuperar mensagens entre tasks.
Eles são armazenados como pares chave-valor e podem ser lidos e escritos de várias formas. Com o PythonOperator, os métodos .xcom_push() e .xcom_pull() podem ser usados dentro da função para “enviar” e “puxar” dados dos XComs. XComs servem para armazenar quantidades pequenas de dados, como nomes de arquivos ou um flag booleano.
Conte mais: Além de .xcom_push() e .xcom_pull(), há outras maneiras de interagir com XComs. No PythonOperator, definir do_xcom_push=True grava nos XComs o valor retornado pela função.
Isso não se limita ao PythonOperator; qualquer operador que retorne um valor pode gravá-lo em XComs com o parâmetro do_xcom_push. Por baixo dos panos, a TaskFlow API também usa XComs para compartilhar dados entre tasks (veremos a seguir).
Para saber mais sobre XComs, confira este excelente post do próprio “lenda do Airflow”, Marc Lamberti.
Resposta: A TaskFlow API oferece uma forma mais intuitiva e “pythônica” de escrever DAGs. Em vez de operadores tradicionais, funções Python recebem o decorator @task e as dependências podem ser inferidas sem definições explícitas.
Uma task escrita com a TaskFlow API pode ser assim:
import random
...
@task
def get_temperature():
# Puxa uma temperatura e retorna o valor
temperature = random.randint(0, 100)
return temperature
…
Com a TaskFlow API, fica fácil compartilhar dados entre tasks. Em vez de usar XComs diretamente, o valor de retorno de uma task (função) pode ser passado como argumento para outra. Nesse processo, XComs ainda são usados nos bastidores, então grandes volumes de dados não devem ser compartilhados entre tasks, mesmo com TaskFlow API.
Conte mais: A TaskFlow API faz parte do esforço do Airflow para simplificar a escrita de DAGs, ampliando o apelo a cientistas e analistas de dados. Embora não atenda todos os requisitos de times de Engenharia de Dados ao integrar um ecossistema em nuvem, ela é especialmente útil (e intuitiva) para ETLs básicos.
A TaskFlow API e operadores tradicionais podem coexistir no mesmo DAG, combinando a integrabilidade dos operadores com a facilidade da TaskFlow. Para mais informações, veja a documentação.
Resposta: Idempotência é a propriedade de um processo/operação que permite executá-lo várias vezes sem alterar o resultado final. Em outras palavras: se você rodar um DAG uma vez ou dez vezes, o resultado deve ser idêntico.
Um fluxo comum onde isso falha é a inserção de dados em bancos SQL. Se a inserção ocorrer sem chave primária e o DAG rodar várias vezes, a tabela resultante terá duplicidades. Padrões como delete-insert ou “upsert” ajudam a implementar idempotência em pipelines.
Conte mais: Isso não é específico do Airflow, mas é essencial ao projetar pipelines. O Airflow oferece recursos que facilitam a implementação, porém a maior parte da lógica precisa ser concebida, desenvolvida e testada por quem está construindo o pipeline.
Para cargos mais técnicos, o entrevistador pode perguntar sobre como gerenciar e monitorar uma implantação de Airflow em nível de produção, parecida com a que o time usa. Essas perguntas são mais difíceis e exigem mais preparação.
Resposta: Há algumas formas de testar um DAG depois de escrito. A mais comum é executá-lo para garantir que roda com sucesso. Você pode subir um ambiente local de Airflow e usar a UI para disparar o DAG.
Depois de disparado, monitore para validar o desempenho (sucesso/erro do DAG e de cada task, além do tempo e dos recursos consumidos).
Além do teste manual por execução, DAGs podem ter testes unitários. O Airflow oferece ferramentas via CLI, ou você pode usar um test runner padrão. Esses testes podem cobrir a configuração e execução do DAG, bem como outros componentes do projeto, como funções (callables) e plugins.
Conte mais: Testar DAGs é uma das tarefas mais importantes de um Data Engineer. Se um DAG não foi testado, ele não está pronto para produção.
Testar pipelines é especialmente desafiador; há casos de borda e de canto pouco comuns em outros cenários. Em entrevistas mais técnicas (especialmente para Lead/Senior), destaque a importância de testar o DAG de ponta a ponta junto com testes unitários e documentação dos resultados.
Resposta: Ninguém gosta de falhas, mas saber lidar com elas com calma diferencia você como Data Engineer. Felizmente, o Airflow tem muitas ferramentas para capturar, alertar e corrigir falhas. Primeiro, a falha aparece na UI. O estado do DAG muda para “failed” e a grid view mostra um quadrado/retângulo vermelho para aquela execução. Em seguida, você pode analisar os logs dessa task na UI.
Normalmente, os logs trarão a exceção que causou a falha e informações para a triagem.
Depois de identificar o problema, atualize o código/configuração do DAG e rode novamente. Dá para limpar o estado do DAG e defini-lo como “active”.
Se um DAG falha com frequência, mas funciona ao tentar novamente, vale usar retries e retry_delay. Esses parâmetros permitem reexecutar uma task em caso de falha um número definido de vezes após um intervalo. Isso ajuda, por exemplo, ao puxar um arquivo de um SFTP que pode atrasar.
Conte mais: Para um DAG falhar, alguma task falhou. É importante triar a task, não o DAG inteiro. Além dos recursos da UI, existem muitas outras formas de monitorar e gerenciar desempenho.
Callbacks oferecem customização praticamente ilimitada ao lidar com sucesso e falha. Com on_success_callback e on_failure_callback em um operador, você executa uma função à sua escolha quando o DAG/Task tem sucesso ou falha. Essa função pode enviar uma mensagem para ferramentas como PagerDuty ou gravar o resultado em um banco para alertas posteriores — aumentando a visibilidade e acelerando a triagem.
Resposta: Uma das ferramentas mais úteis do Airflow são as “connections”. Elas permitem armazenar e acessar informações de conexão (host, usuário, senha etc.) sem hardcode no código.
Há várias maneiras de armazenar connections; a mais comum é pela UI do Airflow. Depois de criada, a connection pode ser acessada no código via “hook”. Muitos operadores tradicionais que interagem com sistemas externos têm um campo conn_id (ou similar) que recebe uma string e cria a conexão com a fonte desejada.
Connections ajudam a manter dados sensíveis seguros e facilitam o armazenamento e a recuperação dessas informações.
Conte mais: Além da UI, a CLI pode criar e recuperar connections. Em empresas, é comum usar um “secrets backend” para gerenciar credenciais. O Airflow oferece vários backends compatíveis. Quem usa AWS pode integrar o Secrets Manager para armazenar e recuperar informações sensíveis. Se necessário, connections também podem ser definidas por variáveis de ambiente.
Resposta: Implantar um ambiente de Airflow para produção pode ser desafiador. Ferramentas em nuvem como Azure e AWS oferecem serviços gerenciados para isso, mas exigem conta na nuvem e podem ter custo elevado.
Uma alternativa comum é usar Kubernetes para implantar e rodar o Airflow em produção. Isso dá controle total dos recursos subjacentes, mas também traz a responsabilidade de gerenciar a infraestrutura.
Fora das ofertas nativas de nuvem e de clusters próprios, a Astronomer é o provedor gerenciado de Airflow mais popular no mercado.
Ela oferece diversas ferramentas open source (CLI, SDK, muita documentação) além do PaaS “Astro” para tornar o desenvolvimento e a implantação do Airflow o mais tranquilos possível. Com o Astro, alocação de recursos, controle de acesso e upgrades de Airflow in-place são suportados nativamente — permitindo focar no desenvolvimento dos pipelines.
Embora não sejam extremamente técnicas, as perguntas por cenário são das mais importantes em entrevistas sobre Airflow. Respostas detalhadas e bem pensadas demonstram domínio não só do Airflow, mas também de arquitetura e princípios de design de dados.
Resposta: Essa é boa! Em uma pergunta assim, você tem bastante liberdade. O mais importante: ao descrever o processo, escolha ferramentas e processos do pipeline legado com os quais você tem familiaridade. Isso demonstra expertise e torna sua resposta mais embasada.
É uma ótima chance de mostrar suas habilidades de gestão de projetos e liderança. Comente como estruturaria o projeto, como interagiria com stakeholders e outros engenheiros, e como documentaria/comunicaria os processos. Isso evidencia foco em gerar valor e facilitar a vida do time.
Se a empresa usa uma ferramenta específica (por exemplo, Google BigQuery), pode fazer sentido discutir como refatorar a solução para sair de algo como Postgres e migrar para BigQuery. Isso demonstra consciência e conhecimento não só do Airflow, mas também de outros componentes da infraestrutura.
Resposta: Para desenhar esse DAG, primeiro você chamará a API para extrair os dados. Isso pode ser feito com PythonOperator e uma função customizada. Dentro dessa função, persista os dados em um armazenamento na nuvem, como AWS S3.
Depois de persistir, você pode usar um operador pronto, como o S3ToSnowflakeOperator, para carregar os dados do S3 para o Snowflake. Por fim, rode um job do DBT com o DbtCloudRunJobOperator para transformar os dados.
Agende o DAG na frequência desejada e configure-o para lidar com falhas de forma elegante (mas com visibilidade). Veja o diagrama abaixo!
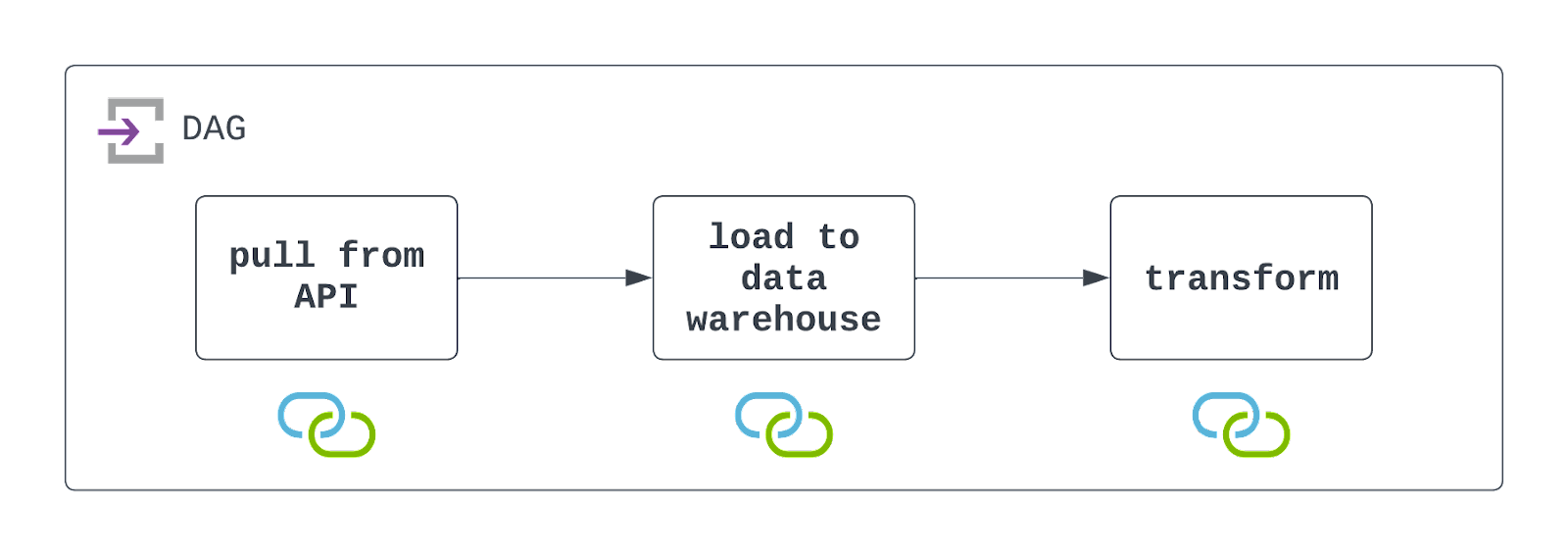
É importante lembrar que o Airflow interage tanto com um sistema de arquivos em nuvem quanto com um data warehouse. Para o DAG rodar com sucesso, esses recursos precisam existir e as connections devem estar definidas e sendo usadas. Isso é indicado pelos ícones sob cada task no diagrama acima.
Conte mais: Essas são algumas das perguntas mais comuns em entrevistas, focadas mais no design e implementação de alto nível do DAG do que em minúcias técnicas. Ao respondê-las, tenha em mente:
DbtCloudRunJobOperator, cite-o, mas não precisa detalhar (a menos que perguntem).Resposta: A extensibilidade e a popularidade do Airflow o tornaram ferramenta de referência além da Engenharia de Dados. Data Scientists e Machine Learning Engineers usam o Airflow para treinar (e retreinar) modelos e executar todo o ciclo de MLOps. AI Engineers já estão usando o Airflow para gerenciar e escalar modelos de IA generativa, com novas integrações para ferramentas como OpenAI, OpenSearch e Pinecone.
Conte mais: Prosperar fora dos pipelines tradicionais talvez não fosse a visão inicial dos criadores do Airflow. Mas, ao apostar em Python e no open source, o Airflow evoluiu para atender às necessidades do espaço de dados/IA em rápida transformação. Sempre que tarefas programáticas precisam ser agendadas e executadas, o Airflow pode ser a melhor ferramenta para o trabalho!
Mandou bem! Você chegou ao fim. As perguntas acima são desafiadoras, mas cobrem boa parte do que aparece em entrevistas técnicas centradas em Airflow.
Além de revisar as questões acima, uma das melhores formas de se preparar para uma entrevista sobre Airflow é construir seus próprios pipelines com Airflow.
Encontre um conjunto de dados que te interesse e comece a montar seu pipeline ETL (ou ELT) do zero. Pratique com a TaskFlow API e com operadores tradicionais. Armazene informações sensíveis com connections do Airflow. Experimente reportar falhas com callbacks e teste seu DAG com testes unitários e fim a fim. Acima de tudo, documente e compartilhe o que você fez.
Um projeto assim mostra não só competência em Airflow, mas também vontade de aprender e evoluir. Se ainda precisa de um aquecimento nos princípios básicos, confira nosso curso Introduction to Airflow in Python, nossa comparação entre Airflow e Prefect e o tutorial Getting Started with Apache Airflow.
Boa sorte e bom código!
Continue hoje sua jornada em engenharia de dados!
Programa
Curso
Curso